
基于孤立森林算法的电力用户数据异常快速识别研究
2022-02-17 12:10王燕晋易忠林郑思达刘岩孙海涛
电子设计工程 2022年3期
王燕晋,易忠林,郑思达,刘岩,孙海涛
(国网冀北电力有限公司营销服务中心(计量中心),北京 100032)
随着我国信息技术水平的不断提升,电力系统建设逐渐朝着信息化方向发展,由于电力用户数量庞大,所需采集和处理的信息量巨大,容易导致电力系统通信或电力设备出现异常状况,使得信息数据异常,为电力系统的数据采集和处理带来了诸多不便[1-2]。因此,对电力系统用户数据异常状况进行识别与检测就变得十分重要[3]。
该文针对这一问题,采用了孤立森林算法的相关知识,设计了一种新的电力用户数据异常快速识别方法,并通过实验验证了该方法的有效性。
1 电力用户数据异常信息挖掘
对电力用户数据异常信息的挖掘主要包括数据检测、数据理解、数据评估等步骤。电力用户数据异常信息挖掘流程如图1 所示。
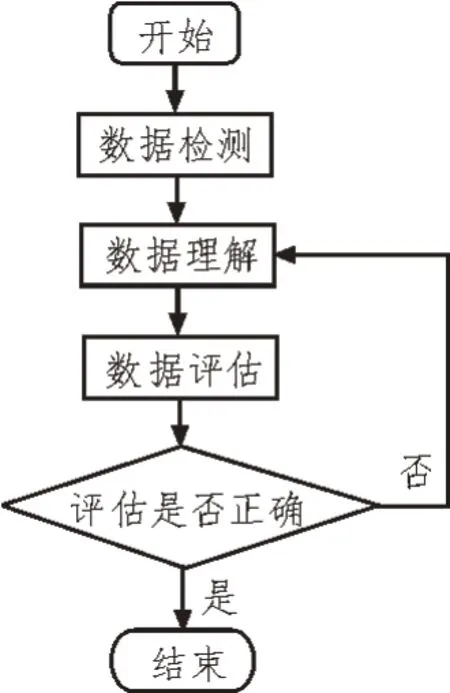
图1 电力用户数据异常信息挖掘流程
根据图1 可知,数据处理服务器需要在海量的电力系统网络数据中进行识别检测的首要任务是数据检测,根据数据特征利用序列数据检测法将采集到的电力用户信息数据进行分类,然后根据该类别的相关规则对数据进行基本的检测识别[4-5]。数据挖掘示意图如图2 所示。
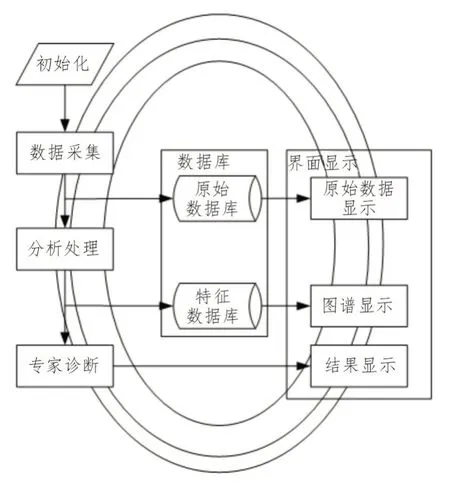
图2 数据挖掘示意图
观察图2 可知,由于部分数据可能会受到噪声等因素干扰,需要对其进行降噪处理,以保持数据源的真实性、完整性,然后需要对数据异常问题进行初步检测,排除正常数据,对可能存在异常的数据进行数据理解。数据理解就是对有待处理的问题数据进行更深层次的分析,在计算机能力范围内最大程度挖掘出该数据的所有相关信息,并对该数据可能存在问题的方面进行理解,同时搜寻关于该问题的相关解决方案和信息[6]。在此之后需要进行数据评估,根据相应的问题等级划分规则并根据该问题的风险程度对异常问题进行风险评估,电力信息系统根据异常状况的评估结果采取相应的处理方案,以对数据异常情况进行及时处理。
2 电力用户数据异常快速识别
基于孤立森林算法的电力用户数据异常检测示意图如图3 所示。
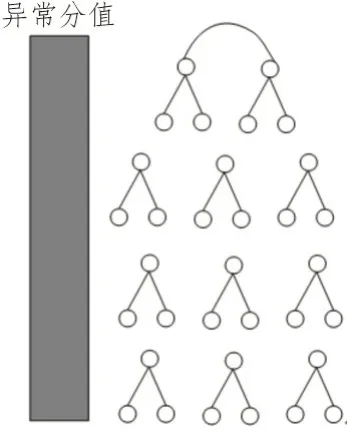
图3 基于孤立森林算法的电力用户数据异常检测示意图
2.1 孤立森林模型构建
由于不同电力系统具有不同的特征,因此需要有针对性地构建孤立森林算法模型。首先,根据电力系统用户信息数据的规模设定孤立森林模型的数据集,随机选取部分具有一定差异性的系统用户数据作为孤立森林构造树iTree的数据样本,并导入相关的电力用户信息数据集;然后对电力用户数据集进行预处理,将数据按照一定规则进行排列,选取适当数量的数据样本作为二叉树的根数据;在此基础上将其他训练数据进行分离,根据一定的特殊性和差异性将数据集分离成多个子数据集,一直分离到子数据集中只有一个数据点为止;然后随机选取一个数值范围作为数据抽取阈值,根据这一数值范围对数据森林进行切割,根据相应的判别标准对划分结果进行判别[7-8]。
观察图4 可知,正常数据应该被划分在高密度区,否则就会被划分在低密度区域,此时则表示该数据存在异常;如果检测结果不确定,那么需要重复该环节,循环进行数据训练集的分离与切割,直到所有数据异常情况检测完毕[9]。

图4 异常检测
2.2 基于孤立森林的异常数据识别检测
基于以上构建的孤立森林模型,结合电力系统的实际数据情况进行电力用户异常数据识别检测。在对电力系统中的电力用户数据进行异常检测时,首先要对数据源进行清理,减少或排除噪声数据及其他干扰因素对原始数据造成的影响,并对数据进行初步降重检测,删除重复或相似度过高的冗杂数据,保证孤立森林算法的原始数据真实、完整并且具有差异性[10-11]。
基于孤立森林的异常数据识别流程如图5 所示,主要有以下几个操作步骤:
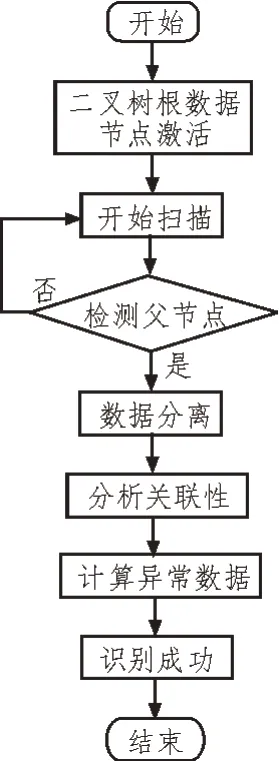
图5 基于孤立森林的异常数据识别流程
1)将原始数据集D导入到孤立森林模型中,根据二叉树模型中的根数据集设定情况,将电力用户数据对应放置在二叉树根数据节点中。
2)采用孤立森林算法进行随机的数据分离,使数据落在相应的二叉树叶子节点上。
3)根据用户信息数据的特殊性和差异性不断进行数据分离,直到子数据集只含有一个数据为止。
4)由于异常数据S往往比较稀少,与其他数据关联性较小,因此容易较早地被分离出来,而且能够比较容易地被识别出来。
5)计算异常数据S所在的叶子节点数据与根节点的距离和层级关系,如式(1)所示。
6)通过归一化公式计算所有二叉树的平均高度,估计异常数据S的异常指数,如式(2)所示,以进一步提高异常数据识别的准确性。

上述公式中,C(n)表示异常数据S(x,n)到根节点的距离,n表示异常数据在其所在的数据集D中的异常指数,H表示该运算过程中所有二叉树的平均高度,ξ是计算二叉树平均高度需要用到的欧拉指数[12-13]。
检测过程如图6 所示。

图6 检测过程
通过以上运算步骤能够较为精准地识别异常数据的位置和相关信息,并且利用归一化公式对异常数据进行了更精准的计算检测,所得结果越趋近于1,表示该数据是异常数据的可能性就越大;反之,计算结果越接近于0,那么该数据是异常数据的可能性就越小[14-16]。
3 实验研究
为了验证文中基于孤立森林算法的电力用户数据异常快速识别方法在实际应用中是否具有良好的使用效果,通过设计实验来对其进行性能检验,并选用了传统的基于K-means 算法的电力用户数据异常识别方法和基于LOF 算法的电力用户异常数据识别方法同时进行对比实验。
实验的基础设备是具备Windows10 运行系统和电力系统标配内存的计算机服务器,在该计算机设备上,构建二叉树棵数为100、样本数据量为128 GB、异常数值比例设定为0.05的孤立森林iTree 模型。将原始数据导入到孤立森林模型中,通过字段检测程序对数据集进行初步识别,然后根据二叉树模型进行数据分离和异常检验,并进行异常数据评估。3 种算法的误差数据检测精准度如表1 所示。

表1 3种算法的误差数据检测精准度
总结表1,得到检测精准度实验结果如图7所示。
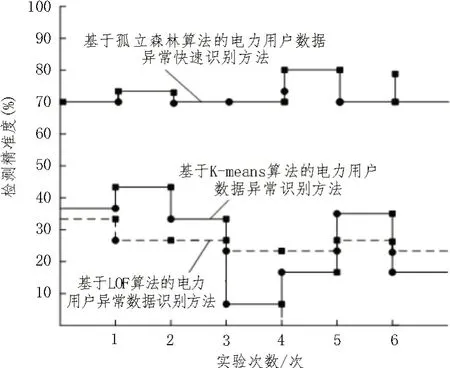
图7 检测精准度实验结果
上述实验结果表明,基于孤立森林算法的电力用户数据异常快速识别方法在数据异常识别中具有更好的应用效果。根据表1 数据所示,该文采用的孤立森林算法在同一检测数据集的情况下,检测结果精准度更高,最接近于1;而另外两种算法的识别检测精准度都在0.89 左右,相比于iForest 算法的精准度,传统算法的精准度水平并不是很理想。
3 种算法的识别耗时如表2 所示。

表2 3种算法的识别耗时
由表2 数据可知,iForest 算法对数据集进行异常数据识别所用时间为1.012 s,而K-means 算法用时达到了9.876 s,LOF 算法更是用了18.678 s,三者之间的识别消耗时间差距十分明显。对于目前的电力系统用户异常数据识别来说,检测速度越快越有利于保证电力系统整体安全。
综上所述,相比于传统的电力用户数据异常识别方法,基于孤立森林算法的电力用户数据异常快速识别方法在异常识别时间上具有很大优势,而且具有较高的精准度,进而有利于提高电力系统用户数据异常检测的整体效率。
4 结束语
该文针对传统的电力用户数据异常识别方法存在的不足进行了分析,并研究了基于孤立森林算法的电力用户数据异常快速识别方法。通过构建孤立森林算法和二叉树模型,加强了信息数据挖掘、检测、识别过程的运算精准度,完善了电力用户数据异常识别方法。然后将该文研究方法与传统的数据异常识别方法进行了对比实验,通过实验结果证明了该文研究方法在数据异常信息识别方面具有较高的精准度,而且识别速度明显比传统方法快,验证了基于孤立森林算法的电力用户数据异常快速识别方法的精准性和高效性。
猜你喜欢
电子制作(2022年16期)2022-09-23
舰船电子工程(2022年7期)2022-09-06
现代计算机(2021年14期)2021-07-09
计算机与数字工程(2020年8期)2020-10-14
当代陕西(2020年24期)2020-02-01
安阳工学院学报(2018年6期)2018-11-28
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
