
基于CNN和Transformer混合融合骨干的改进型DETR目标检测方法研究
2022-02-16 12:10金祖亮
无线互联科技 2022年23期
金祖亮
(重庆交通大学,重庆 400074)
0 引言
随着深度神经网络的发展,目标检测[1]领域涌现出高精度、低延迟的目标检测算法。目标检测算法提供目标的类别和位置完成对目标的分类和定位,这为自动驾驶、医疗领域等提供了技术帮助。
目前,目标检测算法主要可以分为one-stage模型和two-stage模型。早期目标检测方法基于two-stage,例如Region-CNN(R-CNN)系列,其中Faster-RCNN[2]提出通过一个单独的RPN网络提供region proposal,对RPN中提取的ROI区域传递进分类头进行分类,并在回归头中定边界框位置。然而基于two-stage的方法精度很高,但速度却很慢,并不满足实时需求。
单阶段的方法由一个端到端的网络组成,并不包含RPN网络,而是将所有位置视为潜在的proposal。单阶段模型主要可以分为anchor-based和anchor-free检测器,其中anchor-based需要使用anchor框辅助预测。最为熟知的方法就是YOLO[3]。YOLO将图像特征视为网格,网格中心负责预测落在该网格的预测框,YOLO系列可以在保证预测精度的前提下,有着实时的检测速度。anchor-free的模型不使用事先定义的anchor锚框,采用基于关键点的方式,通过预测关键点和宽高来回归预测框,如FOCS[4]等。
但是,无论是anchor-based还是anchor-free的方法,都依赖于复杂的后处理如非极大值抑制的影响,这对目标检测性能表现有着巨大影响。Detection Transformer[5](DETR)作为真正的端到端网络,不依赖于非极大值抑制后处理这种耗时的操作,DETR利用Transformer强大的全局建模能力,将目标检测看成集合预测的问题。DETR使用ResNet作为骨干网络提取特征,但ResNet作为CNN网络在全局信息提取能力上存在不足。但目标检测需要更强的全局建模能力,DETR通过在CNN骨干后使用Transformer网络编码器全局建模,但这带来更大的计算量和复杂度。因此本文提出一种基于CNN和Transformer混合融合骨干的改进型DETR目标检测方法,该方法主要包含两个关键设计:使用Swin Transformer[6]作为特征提取网络提取全局信息,并在每个模块的分支上并联ConvNeXt[7]块提取局部信息,使用特征金字塔结构对输出的多尺度特征融合;借鉴使用DETR目标检测解码器和预测头完成目标检测任务。
1 算法设计
1.1 网络整体设计
本文提出的网络结构整体如图1所示,第一部分采用改进的Swin Transformer模型作为骨干网络,其主要思想是在特征图像块融合的层级输出上并联一个ConvNeXt块,用于提取特征的局部信息,因此经过卷积神经网络ConvNeXt块的多尺度特征图拥有更好的全局信息和局部信息的融合。第二部分采用特征金字塔结构对多尺度特征图融合生成具有浅层特征信息和深层特征信息融合的特征图。最后一个部分借鉴DETR网络,由于本文使用的骨干网络已经具有强大的全局建模能力,输出的特征图带有全局信息,因此本文仅使用DETR的解码器和预测头。
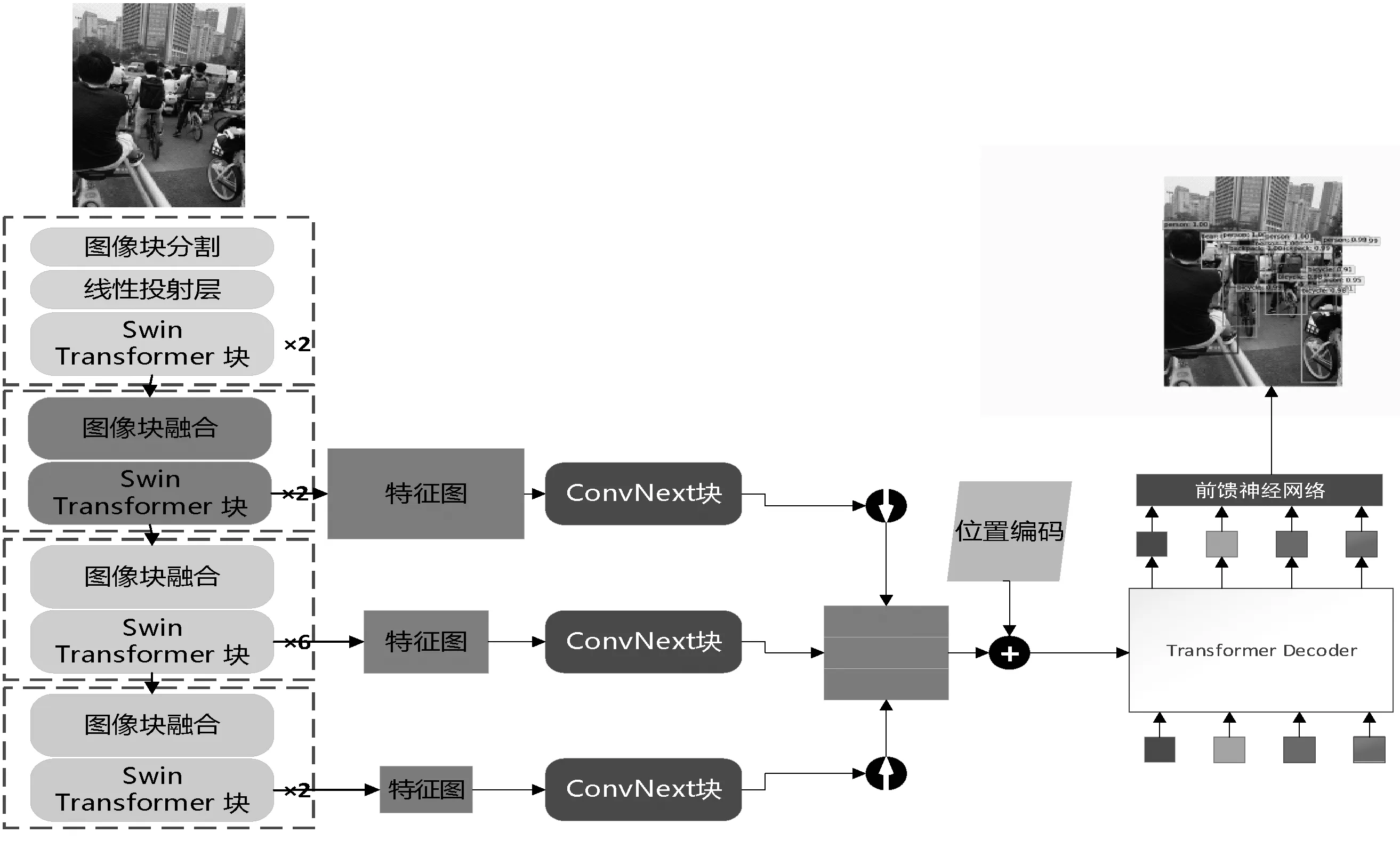
图1 网络整体设计
1.2 骨干网络改进
本文骨干网络基于Swin Transformer模型改进,Swin Transformer块包含一个窗口自注意力(Windows Multi-head Self-Attention,W-MSA)模块和一个移动窗口自注意力(Shifted Windows Multi-Head Self-Attention,SW-MSA)模块。W-MSA模块就是在一个小窗口内进行多头自注意力操作,SW-MSA能够获取窗口之间的信息,通过移动窗口、特征移动和mask3部分,使不同窗口之间的特征进行交互。通过W-MSA模块和SW-MSA模块,骨干模型有着媲美VIT的全局建模能力,并且由于窗口注意力的存在,模型的局部建模能力也相当优秀,但相较于CNN系列网络仍有不足。
本文选择在层级结构的输出上通过ConvNeXt网络增强局部信息的表达能力,从而为下游的检测任务提供更好的特征表现。ConvNeXt块在使用一个N×N的卷积后,通过多层感知机将特征通道数放大到原来的4倍,通过非线性激活函数GeLU后再连接一个全连接,恢复到原始通道数后与原始输入残差连接。因此ConvNeXt块使用了和ResNet块结构完全相反的架构,ConvNeXt块的多层感知的隐藏维度为输入的4倍,而ResNet则为输入的1/4。
本文的特征金字塔不采用复杂的结构,如改进特征金字塔、加权双向特征金字塔[11]等,这是因为特征金字塔结构可能会需要较大的计算量,从而导致推理速度变慢,本文的特征金字塔主要融合模块2-4的输出。
1.3 DETR解码器和预测头
DETR解码器将目标检测任务看成集合预测任务,每个解码器并行解码N个对象查询(Query,Q)。DETR解码器首先会使N个对象查询进行自注意力操作,接着N个对象查询,会与骨干网络的特征转换而成的键(Key,K)和值(Value,V)进行交叉注意力操作。
最后的预测头是由一个带有非线性激活单元的ReLU激活函数、通道数为D层的3层感知机和1个线性投射层组成。预测头的输出包含图像的中心坐标和预测框的宽高,同时预测标签由softmax函数激活获得。DETR的解码器和预测头不需要手工设计较为复杂的锚框,也不需要复杂的非极大值抑制后处理,因此可以认为是一定意义上真正的端到端网络。
2 实验
2.1 数据集
COCO2017数据集包含11.8万个训练图像和5 000个验证图像。每个图像都用边界框和全景分割进行标注。COCO2017数据集包含80个类别,平均每幅图像有7个实例目标,其中在训练集上,同一幅图像上最多有63个实例目标,并且实例目标也有大有小。
2.2 实验设置
本文使用AdamW优化器,学习率使用1e-4,权重衰减为1e-7。模型的框架使用Pytorch1.12.1+Cuda11.6,模型训练采用的硬件设备为Intel i5-13600kf CPU,GeForce RTX 3090 GPU ,32 G内存,操作系统为Ubuntu20.04。本文遵循DETR的训练策略,使用缩放增强,调整输入图像的大小,使短边至少为480个像素,最多为800个像素,长边最多为1 333。同时在DETR解码器上对象目标查询N被设置为100,解码器层数设置为6层。
2.3 实验结果
本文提出的方法在不同环境场景下的预测如图3所示。由图可知,本文基于CNN和Transformer混合融合骨干的改进型DETR目标检测方法,无论在密集场景还是昏暗环境都取得了不错的推理结果。本文提出的方法相较于DETR原始模型,能更好地预测小目标,这归结于强大的特征提取混合骨干对局部信息和全局信息的把握。

图2 模型推理结果
同时本文对比了和DETR和Faster RCNN在模型性能上的表现如表1所示。
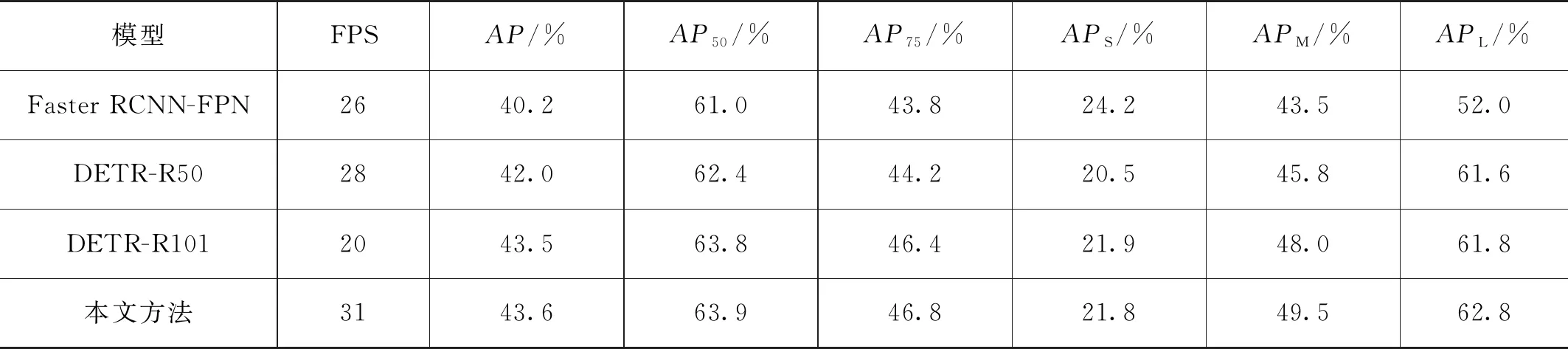
表1 COCO数据集模型对比结果
由表1可知,本文提出的方法,无论在小目标还是大目标上,都优于DETR-R50的表现,在AP上至少提升3.8%,同时速度相较于更快的DETR-R50也是有所提升,超过了30FPS。尽管Swin Transformer相较于ResNet50模型有着更大的计算量和复杂度,但改进的骨干网络拥有强大的全局建模能力,从而使本文的方法并不使用复杂的DETR的编码器,能够更加有效地降低模型的计算量和复杂度。
3 结语
本文提出的基于CNN和Transformer混合融合骨干的改进型DETR目标检测方法,在骨干模型上对DETR进行改进,通过融合Swin Transformer和ConvNeXt模型的优势,有效地融合了全局信息和局部信息,同时对层级结构输出的特征图通过特征金字塔融合深层和浅层特征,因此在目标检测任务中比原始的DETR模型能够取得更好的检测结果。
相较于速度更快的DETR-R50,本文提出的模型在AP上提升1.6%,在FPS上提升10.7%,有更好的性能表现。而且本文提出的方法由于有着更好的特征提取能力,因此能够在小目标上比DETR模型有更好的表现,同时在昏暗的环境仍有着不错的性能表现。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
当代水产(2019年11期)2019-12-23
家庭影院技术(2019年8期)2019-12-04
金桥(2018年4期)2018-09-26
知识经济·中国直销(2017年5期)2017-06-15
中国卫生(2014年5期)2014-11-10
