
基于分布式3D R-Tree索引的轨迹查询方法研究
2022-02-16 12:10王丽明
无线互联科技 2022年23期
王丽明,熊 文
(云南师范大学 信息学院,云南 昆明 650000)
0 引言
随着现代城市公共交通系统的发展,数以十万计的出租车、网约车和公共汽车每天为城市居民提供日常出行服务。这些车辆均部署了GPS终端设备,时刻采集并上报车辆的GPS轨迹数据。如何管理和分析这些轨迹数据,用来提升运营水平和服务质量是管理部门面临的首要问题。如何对数以亿计的GPS轨迹进行索引和快速响应是一个极具挑战的难题。
对于GPS轨迹的存储和查询,通常采用构建索引等方法来提高查询效率。Ding[1]利用时空索引(ST-Index)和连接索引(Con-Index)减少轨迹数据冗余的访问操作。Hanan[2]使用递归分解的四叉树建立索引,当节点达到最大容量时,可以进行分裂,缺点是如果对象分布不均匀,将会形成不平衡四叉树,导致查询效率急剧下降。此外,还有一些R-Tree的改进版本,如IR2-Tree[3],利用叠加文本和R-Tree相结合来处理指定位置和关键字的查询。
这些方法都在单节点实现,在数据规模较小时可以较好地解决查询效率的问题。但是,当数据规模上升以后,这些方法性能会持续下降。因此,本研究尝试借助大数据和分布式索引来解决该问题。本文借助大数据计算引擎的Spark的核心组件RDD,对3D R-tree[4]进行分布式的实现,并使用3个经典查询,包括轨迹点、子串和区域查询,分析运行时间并对比了空间网格分区和时空网格分区方法下3种查询类型的性能。
1 背景与动机
以深圳市为例,截至2019年12月,该市拥有公交车1.9万辆,巡游出租车3万辆,网约车8万辆。假设每辆车每30 s产生一条GPS记录。这些车辆每天可以产生3.7亿条GPS记录。传统的索引方式在单机环境下显然没有能力处理如此规模的GPS轨迹数据。因此,本研究尝试借助Spark的RDD组件构建分布式的时空索引来应对大规模轨迹查询需求。
经典轨迹查询有轨迹点、子串和区域查询。本文对轨迹点查询形式化定义如下:给定一个轨迹集合S,一个查询时间范围T=
Point_query(S,T,q)={tri∈S|∃pk∈tri^
pk=q,timemin≤pk.t≤timemax}
(1)
本文对子串查询形式化定义如下:给定一个轨迹集合S,一个查询时间范围T=
Substring_query(S,T,q)={tri∈S|q⊆tri^
pk∈q,timemin≤pk.t≤timemax}
(2)
本文对区域查询形式化定义如下:给定一个轨迹集合S,一个查询时间范围T=
Range_query(S,T,q)={tri∈S|∃pk∈tri,
timemin≤pk.t≤timemax^latmin≤pk.lat≤
latmax^lngmin≤pk.lng≤lngmax}
(3)
2 数据预处理
车辆所处的位置例如隧道、高楼对信号传输影响,以及由GPS设备自身测量精度导致的局限,导致GPS轨迹数据质量存在一定的偏差。具体表现是车辆轨迹中部分GPS点不在对应的路网上。因此,需要对GPS轨迹进行校准,本文使用FMM[5]方法对GPS数据进行地图匹配。
3 索引的建立
3.1 数据分区
RDD是一个分布式的数据结构,以一个分区规则将数据集合划分为多个分区。本研究建立分布式索引,以实现大规模轨迹数据查询。本研究使用空间网格和时空网格两种分区方法。
3.2 空间索引
空间索引是指将空间对象按一定的规则进行排列组织,在查询时可以筛选掉大量与特定对象无关的空间对象,提高查询的速度。本文建立全局索引和局部索引,划分全局索引的依据是轨迹所在的网格编号,每个RDD分区存储轨迹的部分片段。在每个分区内部对轨迹数据构建3D R-tree为局部索引。查询时,通过全局索引定位局部索引,在局部索引树中执行具体查询。
4 实验结果与分析
4.1 数据集
本次实验的数据集是以深圳市30 747辆出租车累计一周的GPS轨迹数据,约2.97亿条数据,来建立索引和进行查询。
4.2 实验对比
测试在两种分区方法下,位于大鹏区、坪山区、龙华区、龙岗区和南山区的轨迹点查询时延。查询时延是指从提交查询请求到返回查询结果所消耗的时间。结果如图1所示,在不同位置查询,时延不同。在空间网格分区方式下,综合平均时延为2.79 s。在时空网格分区方式下,综合平均时延为2.33 s。
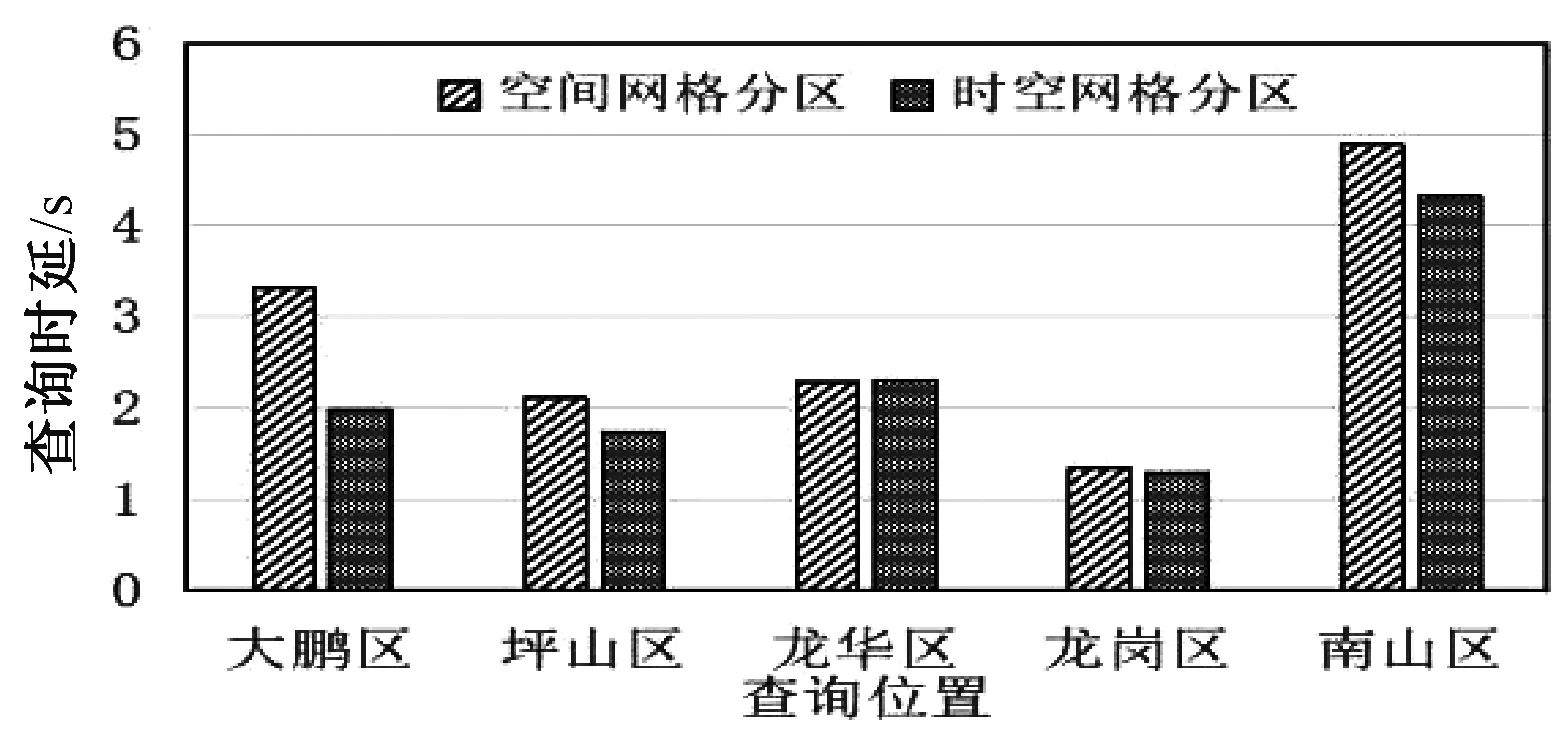
图1 轨迹点查询
测试在两种分区方式下,子串查询长度分别为5,10,15,20,25个轨迹点时,子串查询所需的查询时延。结果如图2所示,在空间网格方法下,查询分别需要1.42 s、4.32 s、4.48 s、4.75 s、4.81 s,综合平均时延为3.96 s。在时空网格分区方式下,查询分别需要1.35 s、3.73 s、3.80 s、3.84 s、3.96 s,综合平均时延为3.33 s。查询时延都随着查询子串长度变长而变长。
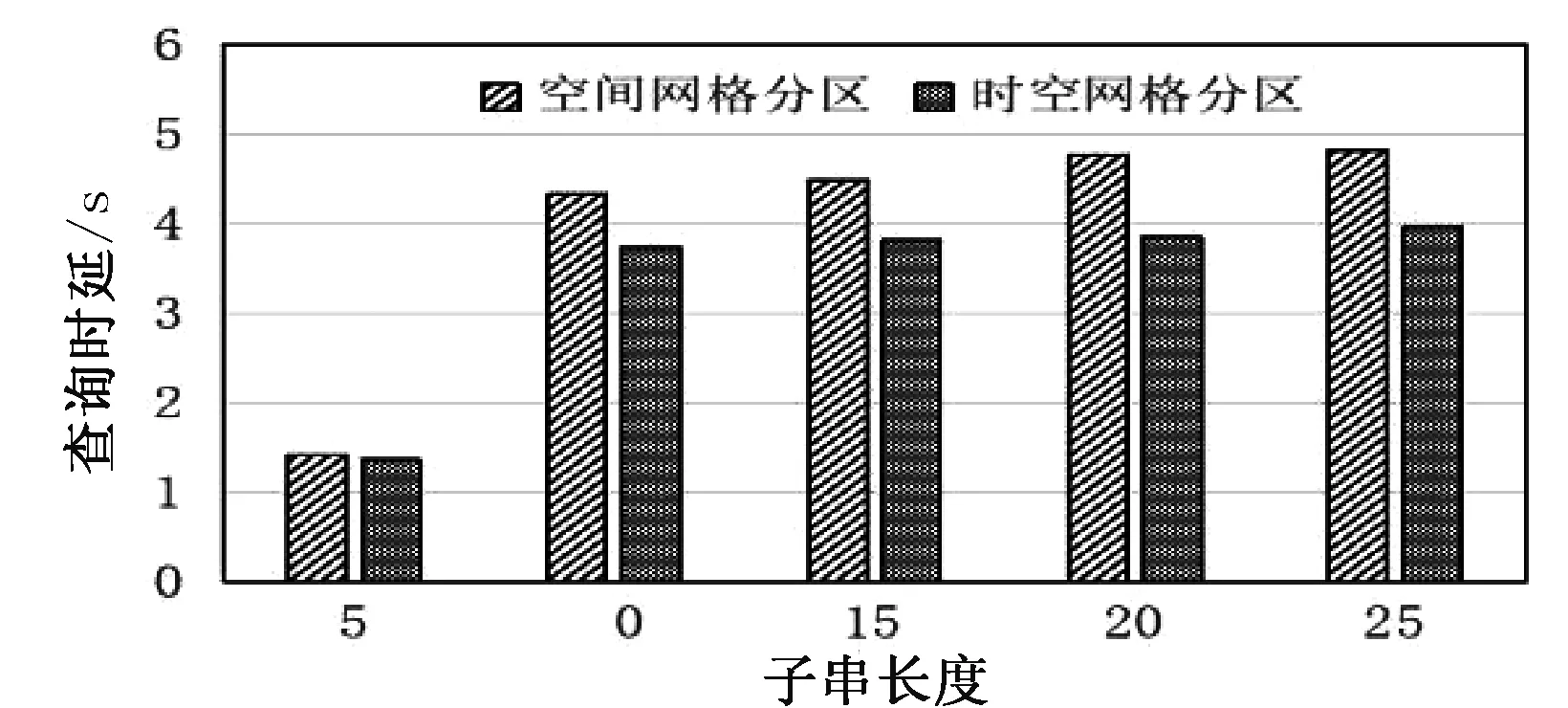
图2 子串查询
测试在两种分区方式下,区域查询范围分别为1×1 km2、2×2 km2、3×3 km2、4×4 km2、5×5 km2时,统计查询所需时间。结果如图3所示,空间网格方法查询,分别需要13.79 s、14.04 s、14.36 s、14.93 s、15.33 s,综合平均时延为14.49 s。在时空网格分区方式下,查询分别需要2.90 s、4.89 s、6.43 s、8.62 s、11.57 s,综合平均时延为6.88 s。查询时延都随着查询范围的扩大而变长。
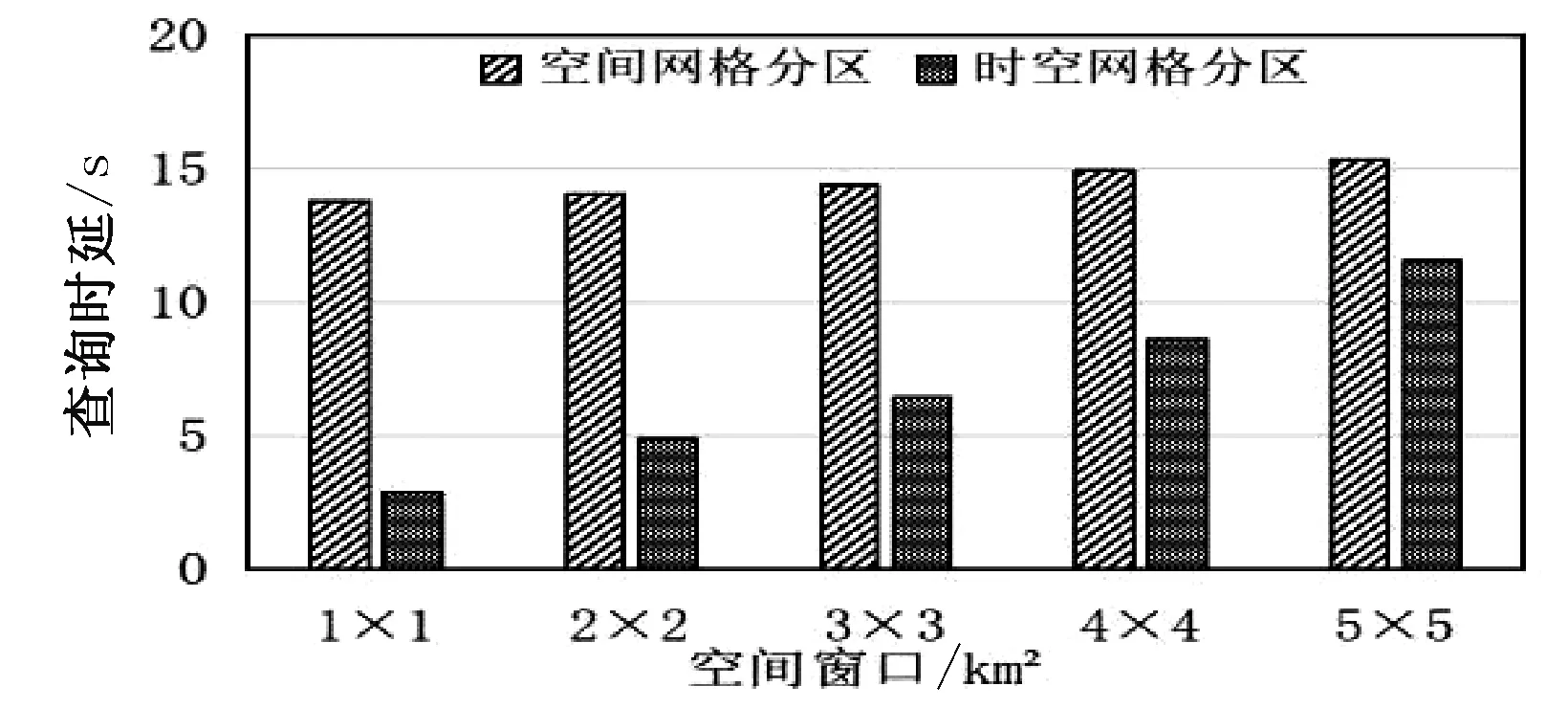
图3 区域查询
5 结语
本文利用Spark平台实现了基于3D R-Tree的出租车轨迹数据查询,对比了空间网格和时空网格两种分区方式。实验表明,在轨迹点查询下,不同的位置查询时延不同;在子串查询下,查询轨迹长度越长,查询时延越长;在区域查询下,查询的范围越大,查询时延越长;用时空网格分区方法比用空间网格分区方法的查询时延短。在下一步的工作中,本研究计划在Spark streaming流式处理框架实现基于3D R-tree的流式轨迹数据查询。
猜你喜欢
环球时报(2022-03-29)2022-03-29
小学生学习指导(低年级)(2020年11期)2020-12-14
电子制作(2019年23期)2019-02-23
作文大王·低年级(2018年10期)2018-12-06
测控技术(2018年6期)2018-11-25
知识经济·中国直销(2018年7期)2018-07-27
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
