
基于主题相似度改进的PageRank 算法研究*
2022-02-16 08:32黄树成
计算机与数字工程 2022年1期
刘 齐 黄树成
(江苏科技大学计算机学院 镇江 212000)
1 引言
随着互联网技术的快速发展,用户获取信息的途径越来越多,但面对庞大的信息资源,如何快速准确地获取对自己有用的信息成为一个难题。在Web数据挖掘技术的支撑下,个性化信息推荐技术已经成为提高信息利用率和信息服务水平的一种有效工具[1]。通过分析网页间的链接关系,结合用户搜索主题,能为用户提供更全面、更精确的信息。
在众多搜索引擎技术所采用的算法中,超链接分析技术是很多学者研究的方向,其中以Google采用的PageRank 算法最为著名。从实际应用来看,该算法能有效地帮助用户搜寻目标网页,提高了信息检索效率,但仍然存在主题漂移、偏重旧网页等不足[2]。
因此,本文提出了一种基于相似度和时间因子的改进算法,改进后的PageRank 算法能有效改善主题漂移和偏重旧网页两个方面的不足。
2 PageRank相关研究
2.1 PageRank算法
PageRank 算法是Google 用于搜索的网站排名算法,是根据网页超链接相互关系来衡量网页重要性的测量算法,其算法核心思想是:被许多网页或者比较权威的网页链接的网页也是重要的网页[3]。
PageRank 算法简单描述如下:假设Sv作为网页u的入链集合,页面v的出链数量为N,该网页的PageRank 值为PR(v),那么页面v每个出链的权值为PR(v)/N,然后将页面u所有入链网页的PR 值相加,就可得到该网页的PR 值[4]。计算公式如下:
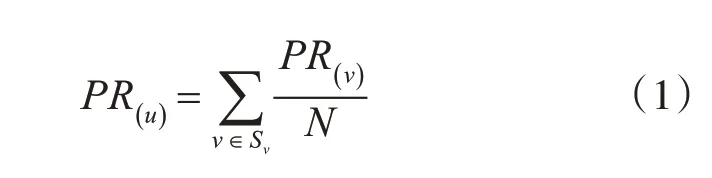
式(1)就是网页PR 值计算的基本公式。但在现实网络中,存在链入和链出为零或者环形链路的情况,这就会造成等级下沉(Rank Sink)和等级泄露(Rank Leak)的现象,导致PR 值异常[5]。为了解决这一问题,对PageRank 的计算公式进了改进,加入了随机跳转模型的概念,该模型假设用户浏览网页时,随机跳转到其他页面的概率为(1-d),用户继续在当前页面或者当前页面的链接中浏览的概率为d,则网页PR值计算公式如下:
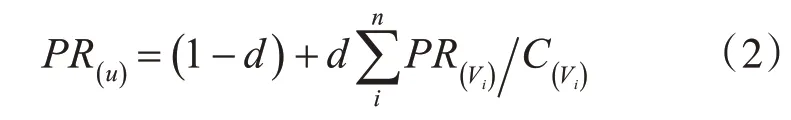
式(2)中,d也称为阻尼系数,一般取值为0.85。从计算公式可以看出,PageRank 算法判定网页的权威性仅依赖于网页的链接关系,忽略了主题内容、时效等方面的因素,虽然在一定程度上可以衡量出该网页的重要程度,而且各页面PR 值的计算过程是在离线时就已经完成,能有效提高查询效率和响应时间,但仍然存在主题漂移和偏重旧网页的不足之处。
2.2 PageRank算法现有改进
针对PageRank 算法存在的问题,越来越多的学者开始对该算法进行研究,对存在的不足之处提出了不同的改进方法。有学者提出基于用户兴趣的改进方法,收集分析用户的使用数据,判断用户的兴趣方向,能提高推荐内容的准确度;另一个改进方向是从页面相似度出发,目前主要分为两个类别,一种是利用空间向量模型对本页面和链入页面进行相似度计算,给相似度大的页面分配更多的权值,解决平均权值的问题;另一个方向是基于内容过滤的改进方法,对页面锚文本和HTML 标签等进行计算,使查询结果更加准确[6~8]。这些方法,都在一定程度上解决了主题漂移的问题。
3 改进的PageRank算法
本文在分析上述改进思想的基础上,从主题漂移和偏重旧网页两个方面进行改进,对页面和正向链接页面的关键字进行提取,引入新的BM25 概率检索模型进行主题相似度的改进,然后通过相似度给正向链接分配合理的PR值。
3.1 基于相似度的改进
网页的PR 值就是网页在排序时的重要依据,主要参考了链入网页数量和链入网页重要性两个因素,本文在此基础上增加了主题相似度的影响因子。改进的主要思想是:一个网页的主题内容与它正向链接的网页主题越相关,则分配的PR 值就越大[9]。
传统相似度的比较,大多使用空间向量模型(VSM)来计算,而本文选用了一种准确率更高的文本相似度计算方法——BM25 文本相似度算法,基于TF-IDF 改进而来[10]。该算法的基本思想是:计算查询内容和文档的相关度,先将查询内容进行语素解析,计算各个语素和查询文档的相关性得分,然后进行加权计算得到最终的结果。BM25算法的一般性公式如下:
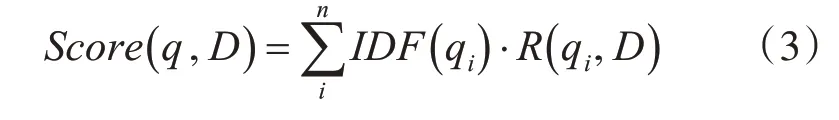
式(3)中,q是给定的查询内容,qi是其中的某一个语素,D是查询的文档。Score(D,q)就是所需要计算的评分。其中IDF计算公式如下:
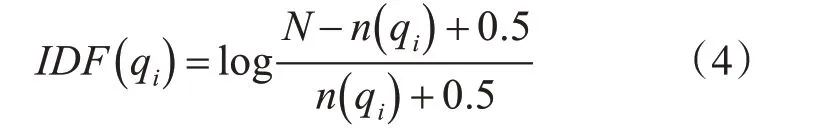
式(4)中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。式(3)中,R(qi,D)表示语素qi与文档D的相关性得分,其公式如下:
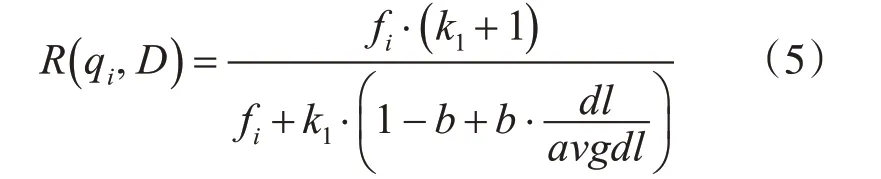
式(5)中,k1,b为调节因子,也称为经验参数,通常参数设置为:k1=2,b=0.75。fi为qi在文档D中出现的频率,dl为文档D的长度,avgdl为所有文档的平均长度。
综上可得,BM25算法的相关性得分公式为
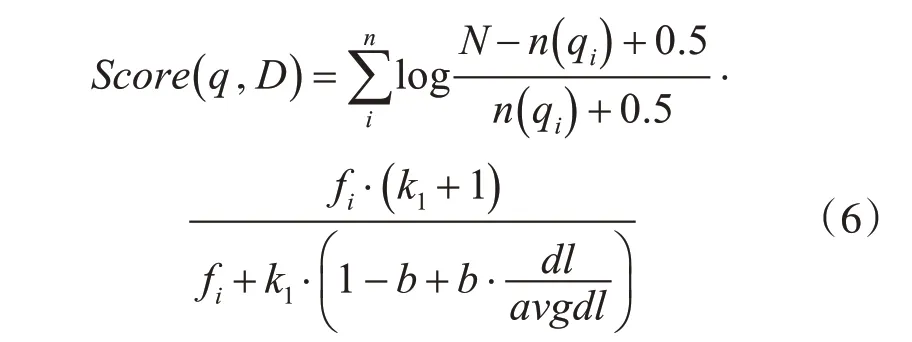
从BM25 概率检索模型的计算公式中可以看出,该算法在计算相似度的时候,不仅考虑了单词在查询文档中的权值,还考虑了单词在搜索内容中的权重[11]。用IDF 的值表示单词的权值,但词频和相关性不是线性关系,所以增加了单词和文档相关性的计算。每一个词对于文档相关性的分数不会超过一个特定的阈值,所以我们做了标准化的处理,即R(qi,D)的计算,得到单词在文档中的权重。对于两个页面来说,匹配词d 在文档Q 中的权重越大且出现的次数越多,则它们的主题越相关。Score(q,D)的值也就越大,但是由于受到阈值影响,一般会收敛于特定值。
3.2 基于时间因子的改进
针对新出来的高质量的网页,由于出现时间比较晚,链入它的网页自然较少,这会导致该网页的PR 值较低从而影响它最终的推荐顺序。针对这一问题,本文采用时间反馈因子对旧网页进行PR 值的补偿,即在PageRank 计算公式中加入时间反馈因子Wt,该方法的基本思想是:如果网页在同一搜索周期内被搜索到多次,也只算一次。这样对于新发布的网页来说,在计算PR值时,可以获得较大的时间因子,从而补偿因链入网页数量较少导致PR值过低的现象[12]。其计算公式如下:

式(7)中,e T即为网页时间反馈因子的计算表达式,表示网页被搜索引擎搜索到的频次,e通常取0.15n,n为网页总数,且e的大小不影响最后的PR值的分布,但影响算法迭代过程,能有效改善新网页PR值过低的情况。
3.3 改进后的算法
基于相似度和时间因子改进的基本思想为:根据当前网页及所链接网页的相似度分配PR 值,不采取平均分配的策略,同时加入时间反馈因子对新网页进行补偿。
改进后的计算公式如下:

式(8)中,Sv代表指向网页u的集合;Topic(Q,v)用来计算查询内容和查询结果相似度的评分,α是用来调节该评分影响权重大小的参数,一般取值为0.3;Wt为网页u的时间反馈因子。从改进后的计算公式可以看出,网页u的PR值,除了有链入网页v的贡献,还有检索排名的过程中,查询主题相关度和时间因子的贡献。
4 实验结果与分析
4.1 实验步骤
为了验证改进后的PageRank 算法的正确性和有效性,本文使用了Nutch、Lucene 和MyEclipse 等工具来搭建实验环境,从搜狐新闻门户网站(http://news.sohu.com/)爬取网页,作为实验数据,验证算法的综合效果[13]。主要步骤如下:
1)通过在Windows环境下安装Cgywin工具,使用Nutch 在网站上抓取约5000 个页面,进行去重、去除无效信息等预处理。
2)提取网页的页面内容、标题摘要及关键字等,为每个页面建立一个关键字列表,过滤没有关键字列表的页面。
3)用Java 语言分别实现传统的PageRank 算法和改进后的PageRank 算法,对每个网页计算其PR值。
4)使用Lucene 工具进行全文检索,模拟用户输入不同的关键字进行查询,比较两种算法下查询得到的页面排序情况。
4.2 实验方案
本文中的实验结果评估指标主要有两项:准确率和权威值[14]。
数据准备阶段,对门户网站上爬取的结果建立相关索引并将其存入数据库中,索引简历后对关键字进行搜索,并用传统的PageRank 算法和改进后的PageRank 算法计算网页的PR 值,将这些PR 值保存到数据库中。在模拟用户对关键字进行查询时,根据需要找到的文件,按照PR值的降序返回结果[15]。
设计三组对比试验来验证,首先,对主题“阅兵”搜索到的网页进行PR 值的计算,分别用原始PageRank 算法和改进的PageRank 算法,对比排序结果前八的网页的PR值分布情况;其次,对“阅兵”主题的排序结果进行准确度统计,统计两种算法下,推荐页面中符合查询结果的页面数量;最后,对多个主题进行准确度验证,检验多个主题下改进算法的准确度。
4.3 结果分析
实验一,以“阅兵”为主题查询结果选取前8 个页面,分别按照A-H 编号,各页面之间的链接关系如图1所示。

图1 以“阅兵”为主题的页面链接关系
利用传统PageRank 算法和改进后的PageRank算法计算得到的PR值如表1所示。
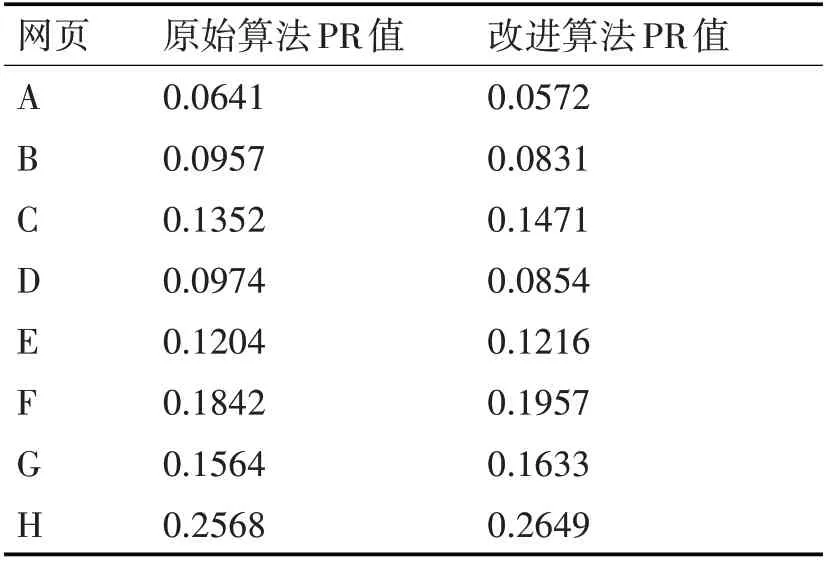
表1 两种算法得到的PR值
从图1和表1中可以看出来,所选页面里PR值最高的是H页面,其次为F、G。由表1可以看出,较原始算法,改进后的算法给每个页面的PR 值出现了变化,例如页面A、页面B和页面D等,PR值都有所降低,相反,页面H、页面F和页面G等PR值都有所升高。这是因为在采用根据相似度分配PR 值后,不再是平均权值,所以一些主题差异较大的页面获得的PR 值较之前更少,而相似度高的所获PR值较之前更多。
实验二,在实验一的基础上,针对“阅兵”主题,分析了传统PageRank 算法和加入主题相似度的算法、同时加入主题相似度和时间因子的算法的排序结果。计算返回的前N 个页面中符合要求的网页的数量分布情况。横坐标表示的是在返回结果中PR 值排在前N 张的网页;纵坐标表示的是在前N张网页中符合要求的网页数量。实验结果如图2。
从图2 中可以看出,随着返回结果页面数的增加,加入主题相似度的改进后,符合要求的网页数都要比原始PageRank 算法多,即准确率更高。而加入了时间反馈因子后,准确率小幅提高,这是因为排序结果中会出现一些PR值偏低的质量高的新网页,而时间因子的出现不会影响算法的迭代,只是在PR值上有所补偿。
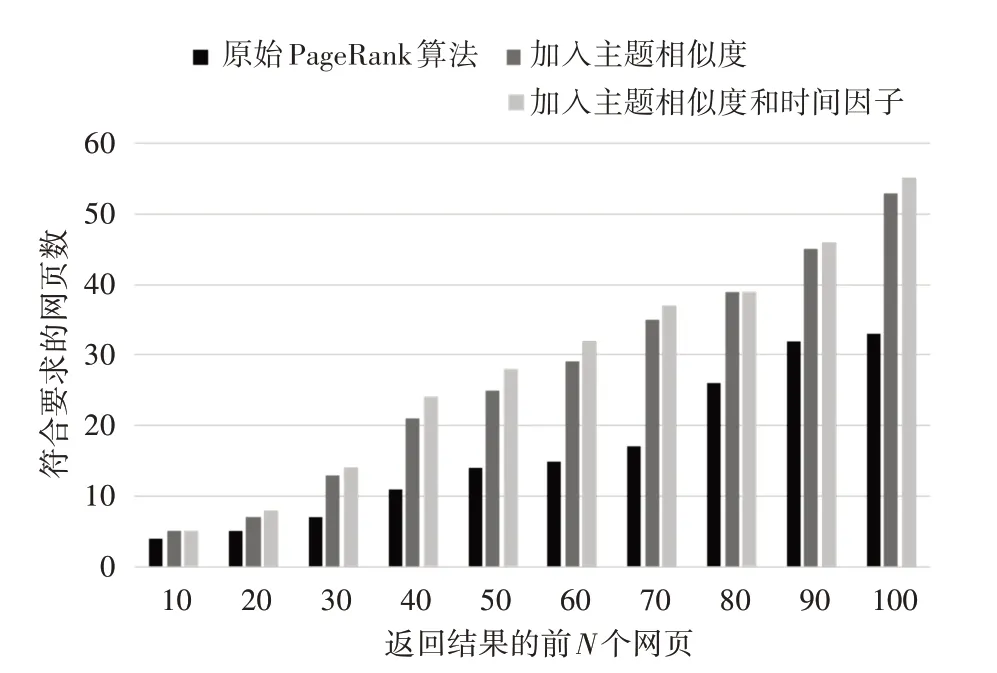
图2 改进因子对查询准确率的影响
实验三,对多个主题进行查询结果分析,对比原始算法、增加主题相似度和同时增加主题相似度和时间因子的结果,分别取各主题排序的前100 个页面,分析其返回结果符合主题的情况。实验结果如图3所示。
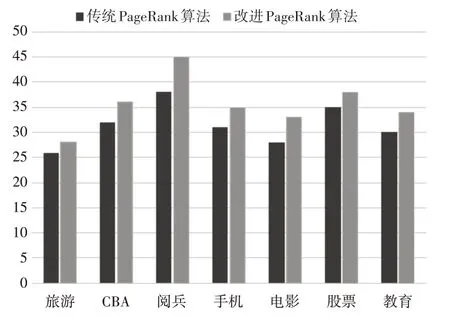
图3 不同主题符合查询结果分布情况
从图3的结果来看,本文改进后的PageRank算法与传统的PageRank 算法相比,改进后的算法在不同主题中返回的结果符合查询主题要求的网页数量都要多于传统算法,即准确率更高。
5 结语
本文在分析传统PageRank 算法存在的不足上,采用BM25 概率检索模型进行相似度的改进,在一定程度上优化了主题漂移的现象;加入时间反馈因子Wt,解决了偏重旧网页的问题。通过实验证明,改进后的算法在一定程度上提升了网页的准确度,改善了新网页PR 值分配偏低的问题。接下来在此基础上,会继续对改进的算法进行更深一步的研究,由于该算法在查询时需要计算相似度,在数据量更大的情况下,时间性能有待研究。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
魅力中国(2018年5期)2018-07-30
高中生学习·高二版(2017年9期)2017-10-25
中学科技(2016年7期)2017-05-16
电脑爱好者(2017年7期)2017-05-06
考试周刊(2016年44期)2016-06-21
新高考·高一物理(2014年4期)2014-09-17
智能计算机与应用(2007年4期)2007-08-25
