
基于卷积神经网络的魔芋病害识别
2022-02-13 14:53余顺园
湖北农业科学 2022年23期
雷 朦,余顺园
(安康学院电子与信息工程学院,陕西 安康 725000)
魔芋作为一种经济作物,具有较好的食用、药用价值以及工业价值[1,2],是中国中西部地区重要而具有特色的经济农作物之一。然而魔芋在种植过程中易感染各种病害[3],有效控制病害的前提条件是能及时准确地识别出病害种类。传统的魔芋病害识别主要依赖于人工,但是随着智慧农业的兴起[4],人工智能技术逐渐渗透到农业生产的各个环节,因此基于机器视觉的农作物病害研究受到了广泛关注[5-7]。本研究对卷积神经网络的魔芋病害识别进行分析,旨在及时发现魔芋病害,减轻劳动力强度,提高生产效率。
随着计算机技术在农业图像处理领域的渗透,学者们利用模式识别方法开展了一系列基于机器视觉的各类农作物病虫害分类方法研究。传统的诸如支撑向量机[8]、K-means 聚类分割[9]、遗传算法[10]等均依赖于特征,而特征提取具有不稳定性,易受环境影响等,为此深度学习应运而生,尤其是随着各类深层次结构网络的不断完善,如卷积神经网络(Convolutional neural network,CNN)、递归神经网络等使得图像识别在适应性和鲁棒性上均有较大提升,基于深度学习的农业领域病虫害自动识别也日益受到学者们的关注[11]。利用深度学习获取作物病害的多尺度特征,可以更精确地实现不同病害的特征表达,有利于作物病害的精确识别。基于CNN 的农作物病害识别具有较高的准确率[12-14],CNN 通过大量的训练样本数据提取特征,有效突破了传统算法特征提取的局限性。本研究以Inception V3 为卷积算法理论模型,使用CNN 对魔芋病害分类检测进行较深入的研究,并学习、训练、测试魔芋病害分类检测,得到了较好的结果。
1 卷积神经网络理论
本研究主要以Inception V3 为卷积算法理论模型,并以此为依据进行训练学习,在深度学习网络开发环境平台下进行试验。
1.1 深度学习及神经网络概述
深度学习不仅属于机器学习的一部分,也是其新领域的发展。数据D=(xi,yi),Δi≤m,D为二维的数据。
1)模型。F1={f(x,θ),θ≤Rn},其中,θ取值于n维欧式空间Rn,该模型为一个函数,函数可以是线性函数或是非线性函数,如线性函数y=f(x) =wτx+b,广泛线性函数y=f(x) =wτΦ(x) +b,非线性函数在人工神经网络(Artificial neural network,ANN)中最具代表性。
2)策略。在最小优化问题过程中,会在模型中加入损失函数L[y,f(x)]和正则项||θ||2,本研究对输入损失函数进行经验风险计算并引入了R(θ),因此优化结果可表示为:
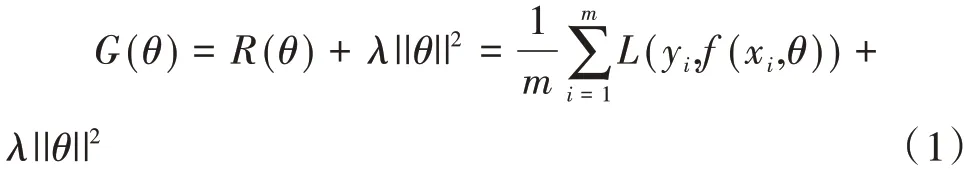
3)算法。用神经元结构算法并以神经元为基本单位建立神经网络。
深度学习是以DNN(深度神经网络)为模型,其结构包括输入层、输出层和隐藏层。单个神经元结构包含输入信号、处理功能、输出信号,如图1 所示,其中b为偏置项,x1~x4为输入数值,w1~w4为权重。对数据求和以后,经过激活函数f取得输出值y,即输出值为:


图1 神经元结构
深度神经网络结构见图2,包括1 个输入层和输出层和4 个隐藏层,可以为数据处理设计多层的网络结构,如图像的分类、魔芋病害分类识别等。

图2 深层神经网络结构
1.2 Inception V3 模型
Inception 体系构造的思想是利用密集成分来接近最好的局部稀疏结构,已有4 个版本,Inception V3 是其中比较有代表性的网络,属于较深的卷积网络。Inception V3 将1 个较大的二维卷积分为2 个较小的一维卷积,如7×7 卷积能够分成1×7 卷积和7×1 卷积。当然3×3 卷积也能够分成1×3 卷积和3×1卷积,这种非对称卷积结构拆分(图3)优于对称卷积结构,因为便于处理更多且更丰富的空间特征,特征多样性增加,同时减少了计算量。

图3 非对称的卷积结构拆分结果
2 魔芋病害分类识别研究
在魔芋病害分类识别试验中,基于InceptionV3在深度学习环境下进行试验,实现对魔芋病害分类识别。本研究使用的魔芋病害分类数据集由课题组自行采集,该数据集包括训练集和测试集,主要用来评估模型的准确率。在数据进行训练和测试前,进行适当的去噪、分割、细化、归一化等预处理。对模型进行深入剖析,对其内部特征进行可视化处理以及输出识别准确率分析。
2.1 网络模型结构及各层的特征图
魔芋病害分类模型的构架和Inception V3 大体相同,只是输入图片大小变成了28×28,卷积层和池化层大体一样[15]。在深度学习环境下训练该模型,为了适应该环境的配置,对Inception V3 模型进行了修改,将所有各层间的连接设为全连接的形式,如图4 所示。

图4 全连接形式
利用网络模型对测试图片数据进行训练,根据各层参数的定义及各层的连接关系确定网络模型的结构图,显示出各层间的连接,设置各层的参数。所使用的网络模型由两层卷积层、两层池化层和两层全连接层构成,能够输出损失率和准确率。
训练完成后,在运行终端进入Python 环境,输入代码,并对代码进行编译,得到所需建立的网络,读取测试图片,编写显示各层数据的代码并执行,在执行无误的情况下,显示出各层输出数据和权值特征图。图5 是第一次卷积的输出图和权值图,其中图5a是输出图,图5b 是权值图。

图5 第一次卷积输出与权值
经过卷积操作会使图片大小变为24×24,提取的特征变多,识别准确率增加。由图5 可知,卷积输出图由20 个小方块组成,代表输出的20 个特征图,权值图代表所用卷积核内部权值参数的大小。第一次卷积之后紧跟着一个池化层,池化窗口大小为2×2,池化移动步长为2,池化层功能一样,所以第一次和第二次池化的数值一样,如图6 所示,其中图6a 是第一次的输出图,图6b 是第二次的输出图。

图6 池化输出图
经过池化操作使得图片大小减少50%,但是其特征图的数量没有减少。接下一层是第二次卷积层,第二次卷积核的大小仍为5×5,卷积步长为1,则该层的输出数据图和权值参数如图7 所示。

图7 第二次卷积输出权值
2.2 绘制损失率和准确率曲线
为了训练数据集得到模型,首先,通过配置文件内的参数,运行训练模型的脚本文件,得到每迭代1次的数据,每训练迭代1 次就会输出训练损失率和测试准确率。由于本研究配置文件设置的是最大迭代次数10 000 次,全部显示数据量太大,故设置成每迭代100 次显示1 次训练损失函数值,每迭代500 次显示1 次测试准确率。
图8 为在学习中迭代次数与学习率、损失函数值之间的关系,图9 为在测试中迭代次数与测试准确率和测试损失函数值的关系。由图8 可知,训练过程的损失函数值在开始就急剧下降,基本保持在0 左右,学习率的大小变化是满足学习策略函数的。测试结果(图9)显示,损失函数值基本为0,准确率维持在90%以上,平均准确率为92.12%。

图8 训练学习率与损失函数值
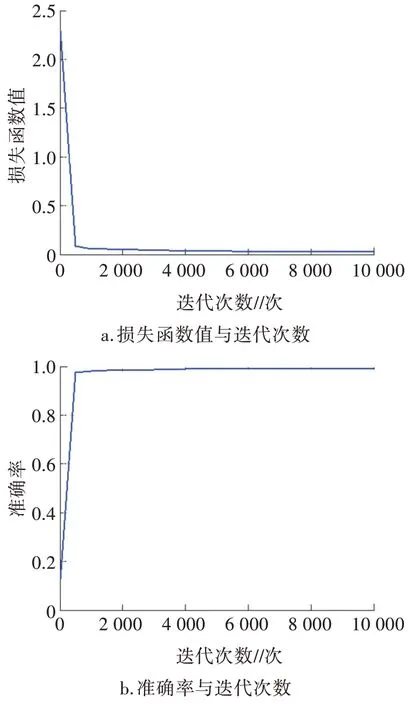
图9 测试损失函数值与准确率
3 模型性能分析及优化
通过调整模型结构和设置参数对模型进行优化,前后进行对比,尽量得出更适合、更精准的训练模型。加入卷积或是池化层改变结构,可通过参数调整改变卷积核和池化窗口的大小及步长,选择合适学习策略和激活函数均能改善模型性能。
3.1 池化(pooling)对性能的影响
为了降低从卷积层输出的特征向量的维度,完善结果,并避免过度拟合,池化一般在卷积后进行。池化可分为空间金字塔池化、一般池化和堆叠池化。可调整池化窗口的大小和平移步长。尺寸X 表示窗口的大小,stride 表示移动多少单位像素。本研究通过调节池化窗口大小和移动步长来分析模型性能的参数变化,运用控制变量法对其进行调整,以得到更好的结果。
3.2 学习策略对性能的影响
学习策略是指设置学习率变化规律的函数,在深度学习中,学习策略有很多种方法,需要选取适合的学习策略对模型进行训练。常用的学习策略函数有sigmoid、fixed、exp、inv、step、multistep、poly,各学习策略函数表达式如表1 所示。次数和进修率;

表1 激活函数表达式
表示取整
3.3 激活函数对性能的影响
激活函数是非线性函数,用于对每层数据进行计算,按照一定的原理对卷积阶段获得的特征进行删除和选择,由于线性模型存在表达能力不够的问题,本研究采用非线性变化方法。
将提取的数据作为输入,进行非线性变换R=h(y),一般采用的非线性函数有sigmoid、tanh、softsign 和ReLU。ReLU 相对于其他几种方式具有更快的收敛速度,因此训练网络的速度也比较快,会节省很多时间。
图10 为以上4 种非线性函数的曲线图,表2 列出了4 种非线性操作函数的表达式。
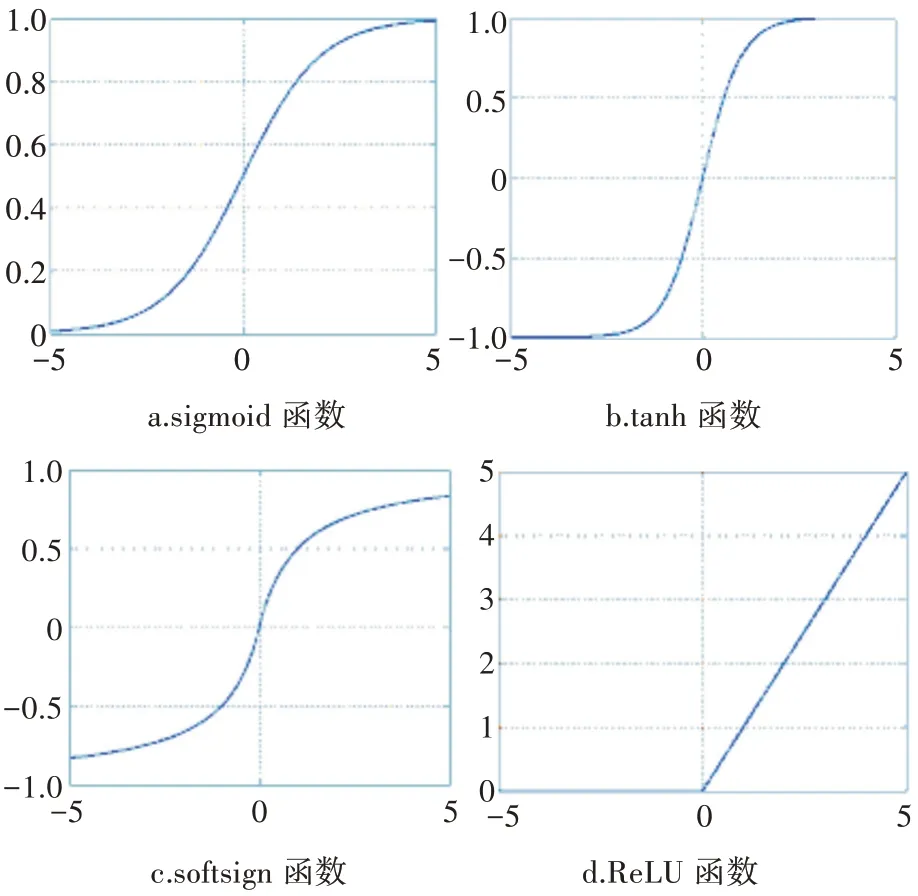
图10 4 种激活函数

表2 激活函数表达式
3.4 测试结果分析
基于上述模型,对7 种最常见的魔芋病害种类进行了识别测试,测试结果如表3 所示,测试数据里面包含无病害魔芋和有病害的魔芋。从试验结果、损失函数值及学习率来看,损失函数值基本保持在0 左右,学习率满足了学习策略函数,准确率维持在90%以上,基本能够满足病害识别的要求。若更改模型参数可以改变卷积核和池化窗口的大小以及步长,会得到不同的准确率。

表3 测试结果
对魔芋病害识别结果设计了简单的显示界面,如图11 所示,界面左侧是待识别的图片,右侧是识别的结果及相应病害特征的简单描述。

图11 魔芋病害识别界面
4 小结
为了实现基于机器视觉的魔芋病害种类自动识别,以Inception V3 为卷积神经网络算法理论模型,在深度学习开发环境下,采用神经元结构算法,以神经元为基本单位组建神经网络,实现了魔芋病害种类的识别。通过归一化和细化等预处理提升识别的精度和准确度,对模型内部及结果进行可视化处理以增加算法的实用性;在识别过程中通过调节各参数及层结构对模型进行优化,使模型能够较好地兼顾准确率和效率。测试结果表明,算法能够实现常见魔芋的自动病害识别,准确率达90%以上。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
医学食疗与健康(2021年27期)2021-05-13
今日农业(2019年14期)2019-09-18
计算机技术与发展(2019年1期)2019-01-21
中国交通信息化(2018年5期)2018-08-21
金色少年(奇趣科普)(2016年9期)2016-10-21
中国酿造(2016年12期)2016-03-01
食品科学(2013年17期)2013-03-11
