
基于嵌入式FPGA 的航拍目标检测解决方案
2022-02-13 09:59吴李煜张紫龙张华君
现代电子技术 2022年2期
吴李煜,张紫龙,张华君,田 野,常 胜
(1.武汉大学 物理科学与技术学院,湖北 武汉 430072;2.湖北航天飞行器研究所,湖北 武汉 430040)
0 引言
近年来,随着深度学习技术的发展,其在终端应用领域的需求越来越广泛。以低空航拍为应用场景切入点,目标检测能有效提升飞行器的感知能力。目标检测算法也是计算机视觉重要分支,研究检测算法在嵌入式终端领域下的部署具有重要意义。区别于传统检测算法的应用场景,低空航拍的视场大、图像背景复杂、目标小而多,检测算法需要在现有结构上进行针对性的优化与训练。将算法部署于远程服务器的传统方案一般要求高清且稳定的远程图像通信,实时性通常较差,而终端平台的计算力有限,往往难以定制,研发周期长。
终端应用领域中,嵌入式FPGA 有着可靠性强、集成度高、功耗低、可并行计算等优点,因此本文选择嵌入式FPGA 为开发平台,提出了全流程的解决方案。算法基于经典的SSD 检测框架优化网络结构,以此提高精确度、减少参数和计算量。硬件开发上,基于Vitis 工具链以及高层次综合技术有效缩短硬件的研发周期。应用程序上,多线程运行且兼容动态链接库的Python 主机程序兼具通用性和开发快捷性。OpenCL 层次的硬件调用也有效地节省了驱动开发耗时。
1 目标检测算法优化
本项目的训练集和测试集由无人机针对目标场景定向采集制作,按照VOC2007 目标检测数据集标注,共19 个场景和9 类检测目标。
网络框架的设计出发点是降低终端硬件的计算量和减少参数。因此选择计算量和参数量较小的GhostBM 和FPN。检测方案的出发点是提高精度,本文基于经典的SSD 框架,针对检测目标尺寸跨度较大的问题,为保证相应的有效感受野完全覆盖目标且携带语义信息,设置了4 个不同尺寸的输出stage,每个stage 都对应一个分类概率anchor 和一个检测坐标anchor。采用基于anchor area 的K⁃means 聚类方法生成了8 个不同面积的anchor 超参。由于有效感受野小于理论感受野,所以网络结构整体上按照理论感受野的面积是anchor area 4 倍的标准设计。输出特征图的尺寸分别为56×96,28×48,14×24,7×12,可保证所有目标均可以找到与之对应的默认框。
检测网络算法结构如表1 所示,其中是GhostBM中通道增大比例,为输出通道数,为卷积步长,为模块重复次数,Sn 为输出Stage 编号,相同编号的输出会经过元素相加后进入Head。

表1 检测网络算法结构
2 系统架构设计
本文硬件开发平台为Zynq UltraScale+MPSoC ZCU104 开发套件,平台核心为ZU7EV 器件芯片,该芯片集成了4 核ARM Cortex⁃A53 处理器与FPGA,平台配套了4 GB DDR4 内存。硬件在Vitis 2020.1 平台下编译,并与预定义的操作系统、驱动程序和根文件系统的ZCU104 Base 2020.1 嵌入式基础平台连接,生成定制化的硬件平台镜像。
图1 为本系统的设计框架图,本系统软硬协同地实现图像检测功能,检测算法的计算流程交给计算能力更强的PL(Programmable Logic)部分。卷积网络推断本体由DPU 计算,输入图片的预处理、输出分类矩阵的Softmax 计算与定位矩阵的解码操作由定制的HLS 计算核来处理。PS(Processing System)用于部署控制性质的任务,负责运行多线程的Python 主机程序和用于调度硬件的动态函数库,并且负责图像的输入和输出。

图1 系统框架图
3 硬件设计
3.1 DPU 卷积核定制
本项目卷积算法网络硬件加速核由Xilinx 官方DPU IP 核定制生成,它是专用于卷积神经网络且高度优化的可配置计算引擎。
结合ZCU104 开发平台的硬件资源和实际网络速度的需求,本文规划部署2 个定制DPU 核,设置其硬件架构为B4096,其计算并行度体现在3 个维度上,分别对应像素并行度为8,输入通道并行度为16,输出通道并行度为16。由于DPU 核的DSP 部分采用了Double Data Rate(DDR)技术,工作在2 倍于控制部分时钟的时钟域下,因此对于控制部分时钟,其峰值每时钟周期可做4 096 次计算。针对性地设置为低RAM 高DSP 模型,并开启深度卷积和ReLU6 的硬件支持。
本系统DPU 的两个输入时钟分别设置为300 MHz和600 MHz。
3.2 HLS 功能核设计
3.2.1 预处理核
预处理模块负责将读取的图片由硬件进行并行化处理,输出满足网络推断格式要求的数组。该模块主要包含图片Resize、减均值、BGR 通道转RGB 通道以及图像量化,量化值为固定值0.5。输出的数组尺寸为448×768×3,数值分布于0 值两边,数据类型为8 位整型,数值范围为-128~127。
图2为预处理的设计方案。接口部分输入输出数据位宽均为8,同时所有模块按照3 通道的2 个像素并行处理,并行处理的数据位宽为48。由于预处理核的计算并非瓶颈,故未额外增大并行度。为了匹配ZYNQ 的高性能数据接口的位宽,外部接口设置为两条128 位的Axi Master 数据总线,通过高性能接口连接DDR。设置一条Slave_axilite 控制总线连接Arm 核,设置输入输出的尺寸与3 组均值寄存器,时钟设置为150 MHz。模块设计分为连接模块和处理模块,所有模块流水线式同步运行,内部模块间的连接设置为2 深度的FIFO(队列)。连接模块负责数据总线与FIFO 的相互转化以及数据位宽的转化。预处理核的Resize 处理模块使用Xilinx 官方的视频库函数。减均值、移位与通道转化处理模块以流水线方式执行,执行间隔为一个时钟周期。

图2 预处理核模块与数据流
3.2.2 Softmax 核
Softmax 在深度学习中用于求输出矩阵的分类概率,在本系统中负责计算Class⁃Head 输出矩阵的分类概率。其计算公式如下:

图3 为Softmax 核的设计方案。接口部分,输入为量化后的8 位整型数据,输出为32 位浮点数据,分别有2 条数据总线、1 条控制总线,可设置处理数组的长度和量化比例。时钟设置为150 MHz。模块并行同步工作,模块间以FIFO 连接。

图3 Softmax 核模块与数据流
图4 为Softmax 计算模块的流程图,左半部分8 位宽的数据不间断读入,乘上量化值恢复成浮点型,指数计算后存储在指定的寄存器内同时做求和,直到一个求和轮次结束后保存进SUM 寄存器。同时右半部分同步计算上一个求和轮次中各个指数值与上一次和的商,得到分类概率输出给FIFO。该模块通道间以流水线执行,间隔等同于通道长度值,平均处理一个数据的间隔为一个时钟周期。

图4 Softmax 核计算模块的流程
3.2.3 Decode 核
Decode 在检测算法中用于将检测位置矩阵通过anchor 来解码成检测框的实际坐标,负责将Local⁃Head的输出矩阵解码,其计算公式如下:

网络的位置输出通道为4,分别为,,,,anchor 提供了,,,这4 个参数矩阵。输出的,,,这4 个通道数据分别代表了检测框下框线值、左框线值、上框线值、右框线值,该值为所在图像中的比例坐标值,乘上图像长宽则为绝对坐标值。
图5 为Decode 核的设计方案。输入为DPU 输出的8 位整型数据,32 位浮点型anchor 数据,其中和维度的数据由于并行需要合并了位宽,和维度的数据长度固定且运算复用,可一次性读入。输出为32 位浮点型结果。所以接口部分设有4 条数据总线、1 条控制总线,可设置处理数组长度与量化比例。时钟设置为200 MHz。模块并行同步执行,以2 深度FIFO 连接。

图5 Decode 核模块与数据流
图6 为Decode 计算模块设计。图中以坐标的解码计算为例,模块最开始会一次性从内存接口读入和维度anchor 数据;然后按照图示不断从FIFO 中读入数据,4 个通道并行计算后输出。该模块的流水线间隔为一个时钟周期。

图6 Decode 核示意图
4 软件设计
4.1 DPU 执行库生成
DPU 的执行库基于Vitis AI 组件生成。图7 为生成网络算法执行程序的操作流程。
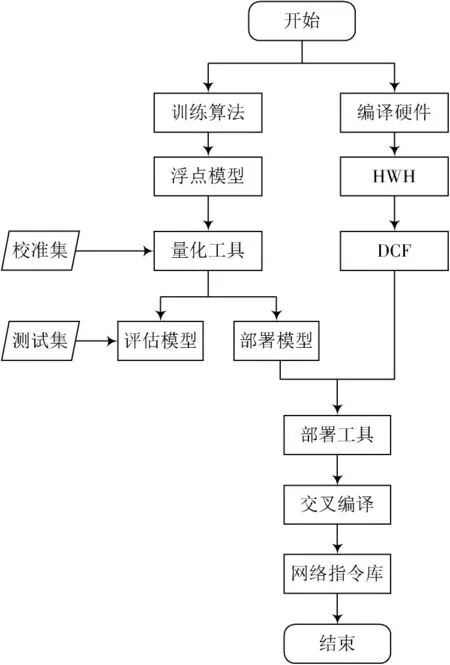
图7 DPU 执行程序生成流程
网络基于tensorflow 训练,训练完成后的权重和阈值为浮点数,计算也为浮点运算,不适合FPGA,需要量化。经验表明,8 位量化产生的精度损失较小,对计算力和存储的要求却能大大下降,因此采用了8 位量化。流程上,首先需要将网络浮点模型固化成静态图,输入校准集,使用量化工具将整个网络量化,生成部署静态图和评估静态图。
根据图1,可以看出关于混合式教学在中小学领域应用的研究文献最早出现在2007年,并且文献的数量一直在持续增长,原因除了科学发展支撑,还有国家政策引领——在2015年,国务院倡导大众创业万众创新,建立线上和线下、国内与国外、政府和企业合作等一系列的创新机制,越来越多的教育模式应运而生,如创科教育、STEAM教育等[7]。智能机、平板、电脑普及,人人都可以随时随地的使用不同终端进行学习,传统的教学模式得以改变,混合式教学也应运而生,随着科技进步的飞速发展,越来越多的研究者将视角转到了中小学,混合式教学关于中小学应用的研究文献的数量不断增长。
随后生成部署程序。网络部署工具可以根据该硬件描述文件与部署静态图,将量化后的算法网络模型映射到高度优化的DPU 执行序列中,构造一个内部计算图,可交叉编译生成网络指令库文件。主机程序可以通过DNNDK 的n2cube 库调度该指令库来控制DPU 的运行。
4.2 HLS 调用库设计
在ARM 核的Linux 操作系统上,基于Xilinx Runtime 环境,可以通过OpenCL 异构调用的方式缩短驱动设计流程,实现对硬件的调用。
该库包含初始化函数和执行函数两部分外部函数。初始化部分,执行基本的OpenCL 初始化函数,为HLS 硬件申请内核对象,申请内存对齐的全局变量。创建Buffer 对象,完成虚拟地址与物理地址的映射,并将该物理地址设置为HLS 核的数据总线启动地址。执行部分,设置执行时改变的HLS 核寄存器,负责主机数据与全局变量的搬移与HLS 核的硬件执行。
通过交叉编译,该OpenCL 程序可以编译成可供上级主机程序调用的外部函数库。
4.3 主程序设计
主程序基于Python 编写,有利于直接移植算法设计环境的函数。通过ctypes 库来实现C/C++兼容,完成库程序的调用。主程序基于多线程方案实现,其设计方案如图8 所示。

图8 主程序设计
图像输入借助OpenCV 库,可从存储卡中读取图片或者通过VideoCapture 获得USB 摄像头的数据。HLS硬核可通过第4.2 节生成的外部函数库调用执行,DPU程序可通过DNNDK 库与第4.1 节生成的指令库调用执行,由于DPU 推断网络并不构成速度瓶颈,故只使用了单DPU 做推断。软件后处理为排序操作,不涉及计算,负责检测框筛选,将检测框在原图描述出来并标注类别和概率。图像借助千兆网口和SSH 工具输出,在远程主机上直观显示。当然,也可以为了减少网络带宽,不输出图片,改为直接输出检测分类结果与坐标位置。
线程间分别设置了深度为3 的线程队列,允许线程流水线式并行执行,线程间内存共享,故不引入额外内存搬移消耗。
5 测试与分析
本项目在ZCU104 开发板上完成测试。测试集由无人机对目标场景针对性拍摄而成。
5.1 占用资源情况
FPGA 的资源消耗如表2 所示。可以看到,本系统充分地利用了平台硬件资源。

表2 FPGA 的资源消耗
5.2 检测准确性
基于完整软件测试集,分别对浮点模型和量化后的评估模型对于目标检测的均值平均精度(mean Average Precision,mAP)指标进行测试。表3 为测试结果,一般可以认为量化评估模型图的运行结果能基本代表硬件结果。从表中可以看到本项目有比较高的检测精度。

表3 检测精度
图9 示意了2 个场景下的目标检测结果。

图9 两个场景的目标检测结果图
5.3 运行速度
运行的耗时由1 000 次图像输入计算平均值得到,线程耗时项排除了队列等待时长。基于SD 卡读入的图像尺寸为1 280×720,基于摄像头读入的图像尺寸为640×480。为了形成对比,专门测试了使用ARM 核运行预处理核后计算的情况,如表4 所示。

表4 内核耗时 ms
根据表4 结果可以发现,多线程运行总耗时一般取决于最大耗时线程,由于HLS 核由线程锁阻塞执行,其线程耗时求和可影响总耗时。对比表中SD 卡读入的2 种情况,由ARM 核做网络的前后处理的计算会形成速度瓶颈,使用HLS 硬件加速则可以有效提升运行速度。
以由HLS 核加速的SD 卡读入测试为例,该方案总耗时约为50 ms,计算可得速度约为20 f/s。
6 结语
本文针对低空航拍的目标检测场景,提出了其终端部署的全流程解决方案。经过测试,该方案在测试集上检测精度为0.55,处理速度约为20 f/s,检测精度高、运行速度快,满足了终端运行的实时性要求。该方案利用多种高层次技术,实现快速部署,缩短了定制周期且易于移植,并且可推广至其他深度学习的嵌入式部署设计。
猜你喜欢
数学小灵通·3-4年级(2021年9期)2021-10-12
少先队活动(2021年4期)2021-07-23
小学生学习指导(低年级)(2020年10期)2020-11-09
环球市场(2017年36期)2017-03-09
数学大王·中高年级(2017年2期)2017-02-08
学苑创造·A版(2016年4期)2016-04-16
沈阳医学院学报(2015年1期)2015-12-27
医学教育管理(2015年3期)2015-12-01
都市快轨交通(2014年4期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
