
基于改进YOLOv3的快速文本检测*
2022-02-12 03:39文洪伟
电讯技术 2022年1期
王 霏,黄 俊,文洪伟
(重庆邮电大学 通信与信息工程学院,重庆400065)
0 引 言
文字是人类文明特有的高度抽象的信息交流载体,广泛应用于自然场景。自然场景的文本检测与识别在智能交通、基于内容的图像检索和机器人视觉等领域有着广泛的应用,特别是移动互联网技术及智能移动设备的发展,提取图像中的文本成为移动应用中不可缺少的部分。
自然场景的文本场景检测主要分为传统的自然场景本文检测方法和基于深度学习的自然场景检测算法。传统方法大致由手工设计的特征提取器和分类器两部分组成,受限于手工设计特征提取器的能力,算法性能难以突破。基于深度学习算法的文本检测已经取得了长足进步,但深度学习算法带来算法性能上升的同时模型检测耗时越来越长,体积越来越庞大,模型训练和推理对计算机的存储和计算能力要求越来越高,给实际应用造成了困难。因此,研究实时性更好、模型体积更小的文本检测算法极其重要。
为使网络模型轻量化,一是可以对模型进行压缩,包括模型剪枝、模型量化[1]等方法,可以起到一定作用,但实现过程复杂;二是采用精简高效的模型,包括SqueezeNet[2]中的Fire module模块和Mobilenet[3]中的深度可分离卷积模块,可以起到明显作用,但需要设计者具有一定的经验。
YOLOv3[4]是单阶段检测算法,网络结构精简高效,与常用于文本检测的语义分割和SSD(Single Shot Detection)类方法相比具有较快的速度。鉴于现有文本检测过程繁琐、模型体积庞大、速度缓慢等问题,本文基于YOLOv3设计了一种自然场景文本检测器,实现了在速度上具有优势的文本检测算法mobile-text-YOLOv3。
1 YOLOv3与深度可分离卷积
1.1 YOLOv3算法思想
YOLOv3是一种直接回归的目标检测算法,采用特征提取网络Darknet-53。本文基于YOLOv3方法,相比于基于SSD、区域候选和分割类算法具有结构精简、检测过程简单的优点。
YOLOv3通过多层尺度特征图以适应不同尺度目标,多层尺度相互融合同时利用了高层特征中有利于分类信息和低层特征中有利于定位的信息。网络通过密集采样预测目标位置产生多个预测,通过非极大抑制算法(Non-Maximum Suppression,NMS)进行后处理并产生结果。
虽然YOLOv3检测速度快,检测过程简单,但直接应用于文本检测任务时效果不佳。原因在于文本区域的边缘密集,梯度信息明显,但没有明显的边界,特征分布密集,直接回归的算法容易误判文本边缘,造成性能下降。此外,YOLOv3计算量和参数量也有进一步降低的空间。
1.2 深度可分离卷积及其实验分析
深度可分离卷积相比常规卷积操作具有更少的参数和更低的运算成本。
对通道数越多卷积核进行改进可更多地减少模型参数量和计算量,但是深度可分离卷积在假设通道间的相关性和空间相关性可分离的前提下成立,因此本文根据实验分析了深度可分离卷积对本文检测性能的影响。本文分别将第3、4和5三个不同层次的残差中的卷积块替换为深度可分离卷积,经过重新训练后,对比实验结果如表1所示。
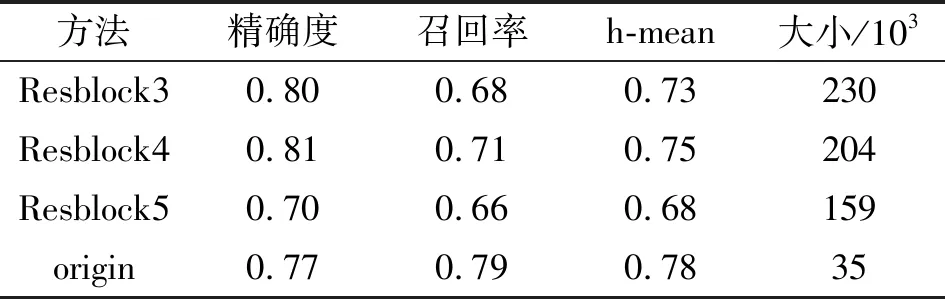
表1 不同深度应用深度可分离卷积对结果的影响
随着网络深度增加,卷积核的通道数成倍增加,Resblock5通道数可为所有层通道数量和的42.6%,深度可分类卷积在Resblock5的应用使得模型减小了约30%,h-mean下降了10%,原因在于深度分离卷积导致网络丧失了深层特征中全局信息。可分离卷积在Resblock4中的替换带来模型参数减少13%的同时缓解了高层特征中全局特征的损失,精确度提高了4%,但是召回率降低了8%。可分离卷积在Resblock3的应用使模型精度提高了3%,召回率下降了11%,模型减小了2%,原因在于对浅层特征的操作会影响深层特征,而且浅层特征通道数量有限因此压缩效果不佳,所以深度可分离卷积在浅层特征的应用往往得不偿失。由此可知,在深层和浅层特征之间应用深度可分离卷积比较合理。
2 mobile-text-YOLOv3算法
2.1 可变感受野卷积
YOLOv3对单词级别检测效果更好,但是字符分布密集,空间结构复杂,浅层特征容易被密集的边缘特征所干扰,导致YOLOv3对本文回归不理想。
在textboxes中深层卷积上引入1×5形状的异形卷积核可以有效地适应文本行长而窄的形状,减少方形卷积核带来的噪声,从而提高网络对文本的检测效果。
由此可见,改变卷积感受野形状适应目标几何结构有利于提高检测准确率。目前的卷积核具有固定的几何结构,相同卷积核单元让所有的感受野相同,一般目标检测都依赖于原始边界框的特征提取,不适用于具有复杂边缘形状的文本。能够适应检测对象尺寸、几何变形感受野的卷积十分必要。受到deformable convolution[5]中自适应ROI Pooling的启发,我们为卷积增加偏移层,实现可变感受野卷积。添加偏移层后可能发生的卷积核感受野形变如图1所示。
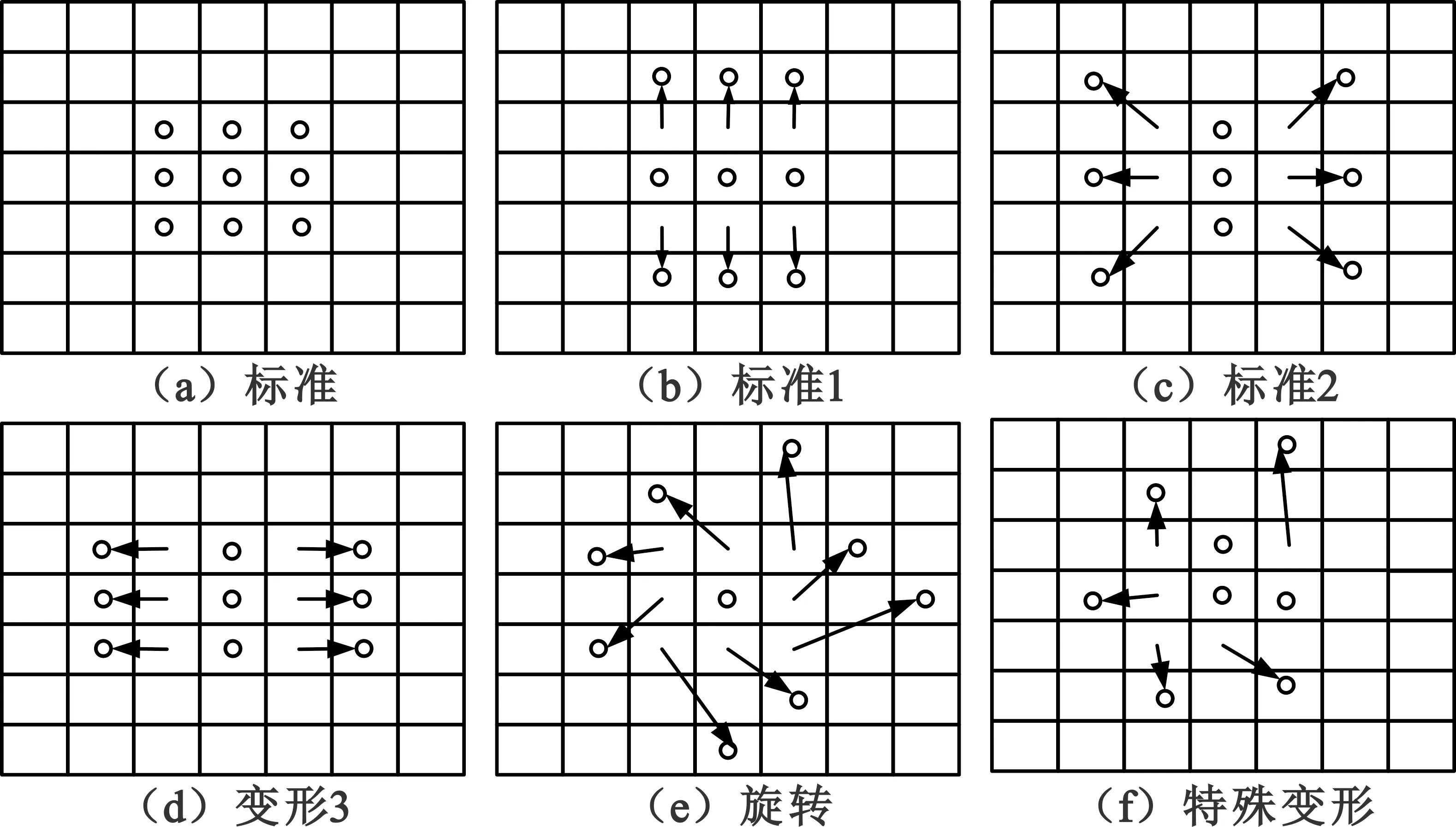
图1 变形卷积的几种方式
从标准卷积出发,由参数R={(-1,-1),(-1,0),…,(0,1),(1,1)}定义卷积采样点的变形。
对输入特征图位置p0的卷积过程如式(1)所示:
(1)
式中:w(pn)表示卷积核在位置pn处的值,x(p0+pn)表示特征图在位置p0+pn的值。添加偏移后,
(2)
{Δpn|n=1,2,…,N},N=|R|。
(3)
偏移Δp是在反向传播中学习得到的一个连续变量。通过双线性插值计算x,如式(4)~(5)所示。
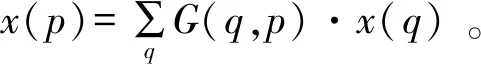
(4)
式中:p=p0+pn+Δpn;q是邻近四个点;G(q,p)是双线性插值的核,
G(q,p)=g(qx,px)·g(qy,py)。
(5)
式中:(qx,qy)和p(px,py)是p和q坐标表示。G(.)定义如式(6)所示:
g(a,b)=max(0,1-|a-b|)。
(6)
可变形卷积过程如图2所示,对输入特征图进行卷积得到偏移参数,偏移参数与原本求和由双线性运算得到实际值。
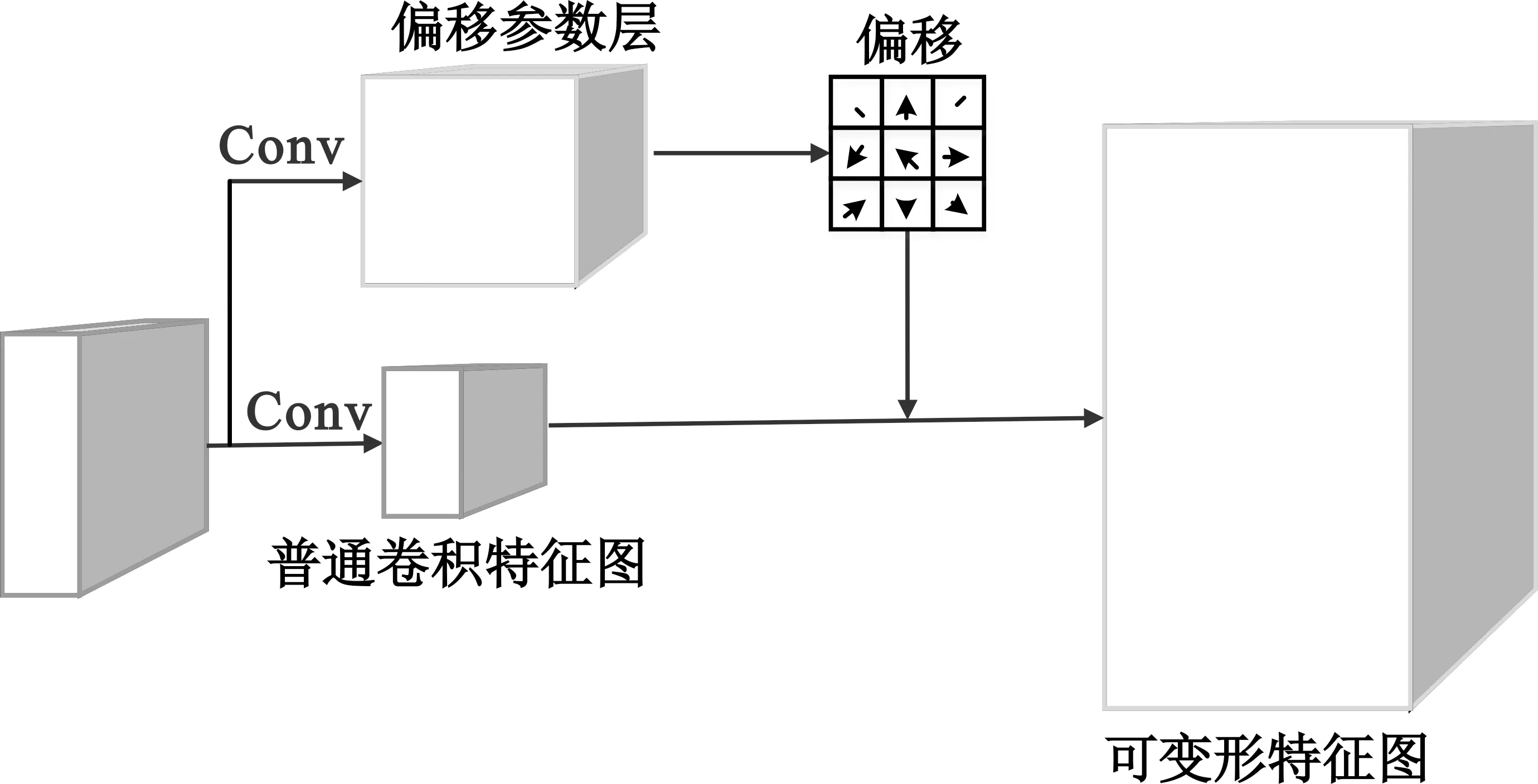
图2 卷积核感受野变化过程
偏移参数学习误差需要通过双线性运算进行反向传播,如式(7)所示:
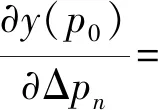
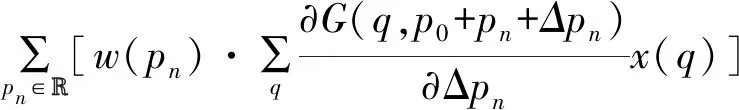
(7)
其中,参数的梯度由误差的双线性插值求得,如式(8)所示:
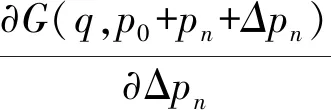
(8)
在不同卷积层添加可变形卷积的对比如表2所示。
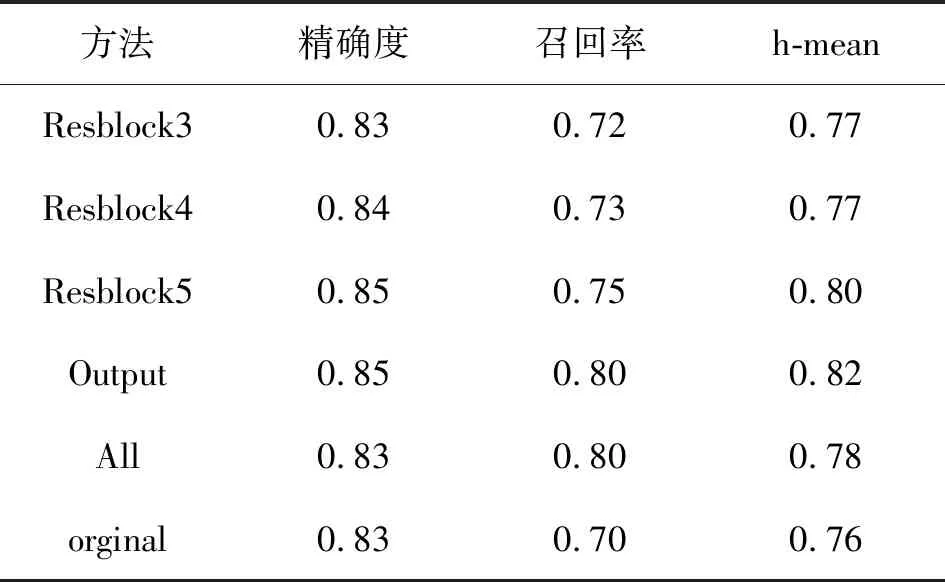
表2 不同卷积层添加可变形卷积对比
2.2 hard-swish激活函数
在YOLOv3中使用了激活函数ReLu,而在深层模型上swish的应用要优于ReLu,但是它的计算代价要比sigmod函数复杂得多,为此mobilenetV3[6]中通过ReLu函数实现了hard-swish,如式(9),同时也将sigmod函数改进为hard-sigmod。本文在make output层采用了该激活函数,在较少计算代价的情况将模型准确度提高0.01。
(9)
2.3 锚框距离
默认锚框是基于VOC数据集生成的,不适应本文中的文本检测任务。YOLOv3中通过K-means聚类得到针对文本数据集的锚框,距离度量为交并比(Intersection over Union,IOU),但是IOU与两个框之间的相交关系并不一一对应。
文本行长而窄的特点导致垂直方向锚框的稀疏,长与宽尺度差别,引起回归时的不平横,导致检测性能下降。
在textboxes中通过增加垂直偏移解决了垂直方向稀疏的问题,但是在YOLOv3训练中锚框匹配时只考虑形状,锚框位置被固定在目标中心所在网格左上角,因此不改变形状而只增加偏移的方法在YOLOv3中难以应用。采用IOU方法产生的锚框没有考虑到长与宽比例问题,加剧了锚框垂直方向的稀疏。为使锚框横向尺度更大,本文基于D-IOU[7]提出了v-IOU。由于锚框不考虑位置,删除了D-IOU损失惩罚项。v-IOU如式(10)~(12)所示。
dviou=1-IOU+av,
(10)
(11)
(12)
式中:h、w为锚框长与宽;hgt、wgt为grougth 框的长、宽;α参数用于平衡比例;v用于衡量anchor框和grounth之间长宽比一致性;长宽比平衡参数λ用于降低宽度距离、增加长度距离,使得锚框更靠近宽度较大锚框。通过此方法得到9个锚框分别为(36,17)、(42,53)、(84,27)、(87,129)、(161,48)、(201,479)、(310,91)、(665,171)、(1 481,404)。
应用调整锚框后文本准确率得到了进一步提高。
2.4 损失函数
本文对YOLOv3的损失函数进行一些改进。YOLOv3损失包括了位置损失Ll和形状损失Lwh、分类损失Lc和置信度损失Lf。
fLoss=Ll+Lwh+Lc+Lf
(13)
位置损失特征与通用目标检测一致,直接引用原有损失。
边界框的尺寸损失如公式(14)所示:
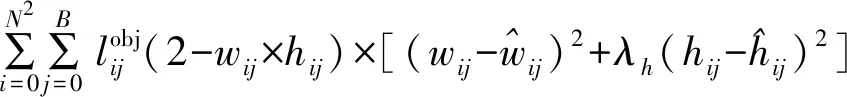
(14)
平方差损失函数的损失与目标绝对尺度正相关,不利于小尺度文本的定位。另外,文本行往往长与宽差别大,由长度与宽度造成的损失并不平衡,本文引入λh平衡这部分损失,缺省为0.8。
本文检测只针对文本单类,分类损失调整为概率二值交叉熵损失,同样通过objij屏蔽不匹配的先验框,如公式(15)所示:
(15)
对预测的置信度损失如公式(16)所示:
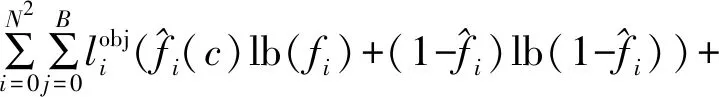
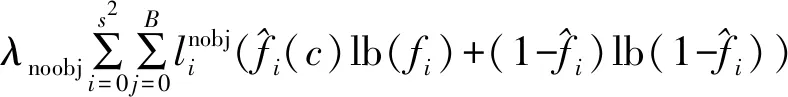
(16)
对置信度的损失意义是指示该特征点代表网格i对产生的预测与真实值的自信程度,计算损失时同样也将非目标区域纳入损失,但非目标区域数量更多,会造成更大损失,所以引入λnoobj用于平衡这部分损失。
2.5 mobile-text-YOLOv3整体结构
综上,本文在Reblock4和Reblock3第二个卷积部分改进为深度可分离卷积将模型轻量化,在深层网络采用可变形卷积更适合文本检测,在 Convlutional Set 中应用 hard-swish 激活函可提高模 型 性 能。mobile-text-YOLOv3模型采用了YOLOv3框架,借鉴了mobilenet的深度可分离思想,网络结构如图 3 所示。
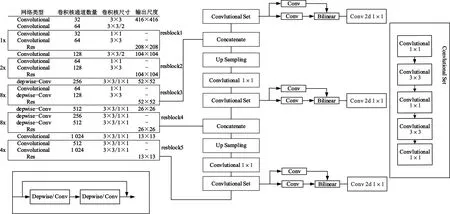
图3 mobile-text-YOLOv3 网络结构图
3 实验过程及分析
3.1 数据集
文档分析与识别国际会议(International Conference on Document Analysis and Recognition,ICDAR)是文本检测与识别领域的顶级会议,其举办的Robust Reading Competion所发布的数据集被广泛使用在文本检测与识别领域。为丰富样本,选用了ICDAR2015、ICDAR2017 RCTW(Reading Chinese Text in the Wild)、ICDAR MLT(Competition on Multi-lingual scene text detection)、Synthtext四种数据集。
ICDAR2015图片来自非对焦的拍摄方式,通过自然场景非刻意对焦拍摄图片,主要场景是城市街景,内容主要是水平方向的英文,标注格式是以单词为单位的矩形框。该数据集包含训练集图片1 000张和测试集图片500张。
ICDAR2017 RCTW主要是中文,包含了城镇街景、图像截屏、室内场景,标注格式为中文文本行的四边形四个顶点,包含12 263张图像,其中训练集图片8 034张,测试集图片4 229张。
ICDAR2017 MLT与RCTW相比,包含了中、日、韩以及拉丁和阿拉伯语,难度较大。
Synthtext是综合生成数据集,数据图像由文本和自然场景图片通过算法合成得到。
3.2 mobile-text-YOLOv3模型的训练
模型训练数据集由ICDAR2015、ICDAR2017 RCTW组成,一共包括9 263张图片。ICDAR2015、ICDAR2017 RCTW和MLT标签是四边形,原始标签为四边形的四个顶点和文本内容(x1,y1,x2,y2,x3,y3,x4,y4,text),本文通过求其最小外接矩形作为新的标签(xmin,ymin,xmax,ymax,f,c)。为便于训练,对图片进行了归一化处理;为避免出现过拟合,在训练过程中利用随机采样原始图片、变化图片的颜色、亮度、饱和度以及翻转等操作对数据进行增强和扩充,如图4所示。

图4 数据增强
采用coco数据集的预训练模型初始化darknet53。采用ADAM优化器,初始学习率采用默认值,每批大小(batch size)为16(GPU可接受),数据集中10%作为验证集,90%作为训练集,每轮(epcho)需要451次迭代(iteration)。在 ICDAR2017 RCTW整个数据集上完成90代(epcho),一共迭代40 590次。每当3个epcho(也就是675次迭代)损失没有下降时学习率减少原来的1/10,然后在ICDAR2013和ICDAR2015上进行微调训练。初始学习率设置为0.000 1,一共迭代43 344次。
训练环境为google colabrary平台高级版本,平台采用的是Telsa P100 GPU。训练耗时10 h。随着学习次数的增加,损失呈指数下降。由于预加载了YOLOv3训练的模型,使得初始损失在65左右,在50轮后模型损失开始快速下降,最后在70轮后现了反复,第9轮时收敛。训练过程如图5和图6所示,图5中蓝色表示训练集损失,橘色是验证集损失。图6是学习率迭代轮数下降曲线。由于google colab平台对计算资源的分配不稳定,训练程序异常停止多次,图5和图6记录的是包括模型收敛时的损失下降曲线。
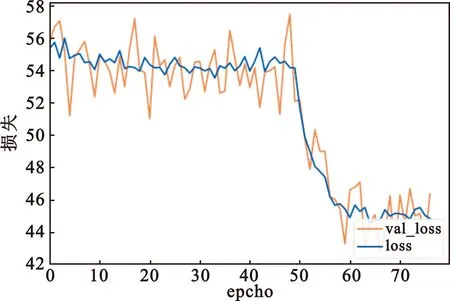
图5 损失下降曲线
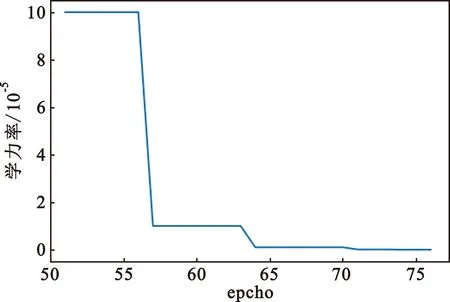
图6 学习率随轮数变化曲线
3.3 实验结果分析
测试环境是Ubuntu 16.04,内存8 GB,CPU为Intel(R)Xeon(R)Gold 6148@2.40 GHz,GPU为1080TI。采用python编程环境和keras深度学框架,部分采用pyTorch和paddle框架。
YOLO类算法应用广泛,目前出现大量针对YOLO改进,如文献[8]、Mobilnet-YOLO(M-YOLOv3)、文献[9]等,其中M-YOLOv3 将YOLOv3 特征提取部分替换为mobilnet[6],是两者的简单结合。
表3给出了YOLOv3及其改进算法在ICDAR2017 MLT数据集的表现。在YOLOv3基础上本文算法综合指标(h-mean)提高了0.07。文献[8]和文献[9]未考虑文本的形状和不明显的边缘导致算法性能提升不明显甚至下降(如文献[9])。与基于YOLOv3的同类模型相比本文模型体积更小,性能更优。与tiny-YOLOv36[10]、Mobilenet-YOLOv3(M-YOLOv3)相比本文轻量化版在算法性能上更优,由于tiny-YOLO本身足够轻量化所以没有再采用深度分离卷积。在检测部分采用可变形感受野的卷积导致参数增加,但对模型整体几乎没有影响。
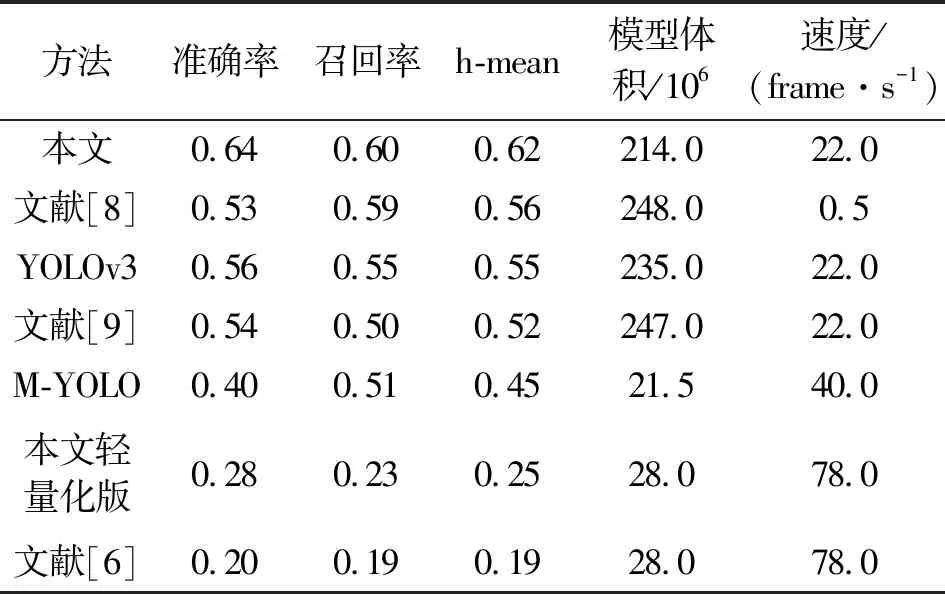
表3 本文方法与其他基于改进YOLOv3方法的比较
本文算法与其他快速自然场景文本检测算法在ICDAR2017 MLT数据集的对比如表4所示。
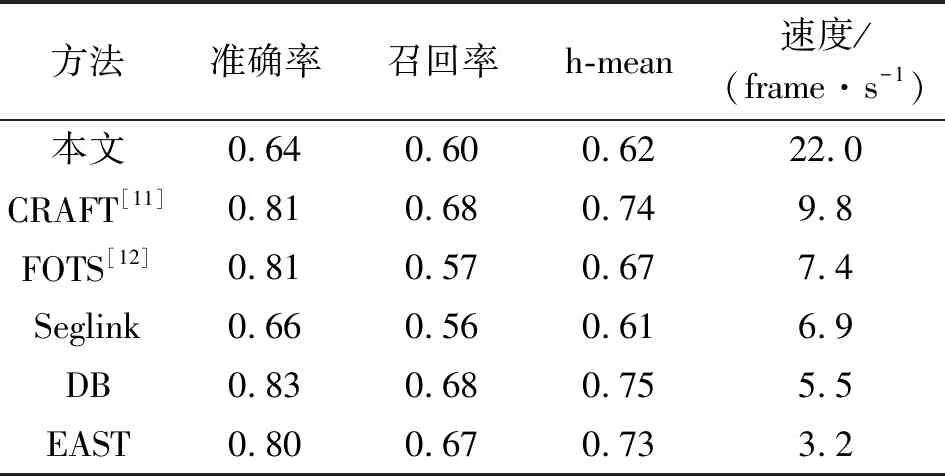
表4 其他自然场景文本检测对比
由表4可知,本文算法在速度上与现有方法相比至少提高了2倍。由于文本考虑到在常用交通指示牌、车牌和广告牌等常用场景中曲线和非矩形文本较为少见,为支持曲线型文本需要采用图像分割方法或者设计复杂的锚(anchor),导致算法的速度降低,所以本文算法的预测框为矩形框,导致文本算法在通用数据集上表现较差。本文算法在Synthtxt数据集的水平和垂直方向文本数据对比结果如表5所示,可知本文算法检测在垂直和水平文本数据上的h-mean上接近先进水平。
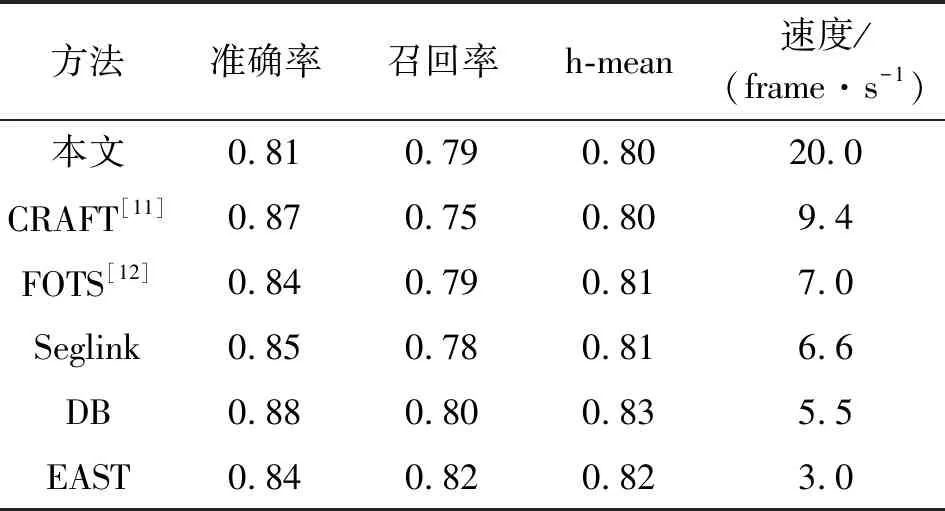
表5 在Synthtxt数据集中的水平和垂直方向文本数据对比
在模型体积(参数数量)方面,文本算法为整体大小2.14×108,其中特征提取部分体积为1.55×108,DB为1.44×108,DB为1.16×108,Seglink为1.78×108。本文整体体积较大,原因在于基于分割的方法(如DB、CRAFT等)根据深层特征图上采样至原图1/4尺寸,据此,单个特征图即可检测多种尺度目标。本文算法直接在深层特征图预测文本位置,深层特征的粒度较大,不利于小尺度目标检测,所以会有2倍的上采样和4倍的上采样,加上深层特征图原有输出,一共需要对三种尺度特征图同时预测目标,导致网络预测部分占比高,但三种尺度特征图之和也远远小于分割方式中的特征图。本文算法具有更简单的锚处理和后处理,因而相对于分割类方法具有更快速度。
本文算法对长文本行效果更好,不容易发生漏检,如图7所示。

(a)YOLOv3 (b)本文模型图7 长文本识别结果
在原有算法不发生漏检情况下本文算法准确率稍低,如图8所示。

图8 不漏检测情况下的测试结果对比
4 结束语
本文对YOLOv3算法进一步改进,使得其适用于文本检测,并通过结构化稀疏训练和剪裁加速了神经网络。本文算法的推理速度快、模型小,可以适应中英文文本。本文提出的文本检测算法与现有先进算法相比在检测速度上表现优越,可以快速有效检测常见场景中的文本,有利于在边缘平台中应用。
本文算法还可以实现非规则框、多方向文本的检测,同时还可以采用对网络模型进行二值化等更多压缩方法,进一步缩小模型体积。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
福建基础教育研究(2019年6期)2019-05-28
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
共产党员(辽宁)(2015年2期)2015-12-06
