
半监督卷积神经网络的词义消歧
2022-02-11 08:41:48张春祥唐利波高雪瑶
西南交通大学学报 2022年1期
张春祥 ,唐利波 ,高雪瑶
(哈尔滨理工大学计算机科学与技术学院, 黑龙江 哈尔滨 150080)
词义消歧 (word sense disambiguation,WSD)是自然语言处理领域的一个重要研究问题.Michael将歧义词的上下文内容分别与每个语义类在词典中的定义进行匹配,将匹配覆盖率最高的语义类视为真实语义[1].因此,歧义词上下文与歧义词之间的相似性可以作为一种有效的判别条件,其中:杨安和Franco等[2-3]提出了一种基于特定领域关键词信息的消歧方法,将上下文语境词汇向量化,与不同领域关键词向量作相似度判别,找到语境词汇所属领域,从而确定歧义词汇所在的领域.唐共波等[4]利用知网(HowNet)对歧义词及其上下文语境词汇的义原信息进行向量化,根据相似度计算结果来确定歧义词汇的语义类别.Arab等[5]将歧义词汇作为结点,根据词典来获取语义类和歧义词之间的依赖关系并作为边,计算边的权重来找到最重要的结点,从而完成词义消歧任务.孟禹光等[6]计算上下文语境的词汇向量与歧义词向量之间的相似度,将相似度最高的语义类别作为歧义词汇的语义类.鹿文鹏和Duque等[7-8]利用上下文语境词汇和领域关键词来构建图模型,使用歧义词汇对图模型进行调整,选择权重最大的领域关键词作为歧义词汇所属的领域,从而实现词义消歧.Tripodi等[9]提出了一种基于进化博弈论的词义消歧模型,利用分布信息来衡量每个单词对其他单词的影响,利用语义相似性来度量不同选择之间的兼容性.由于有标签数据的获取较为昂贵,而无标签数据获取较为容易,所以利用无标签数据扩充有标签数据的半监督方法便应运而生,其中:Xu和杨陟卓等[10-11]提出了一种扩充训练语料的方法,利用词典对有标注歧义词及其上下文语境进行翻译,并将其加入训练语料中,从而使词义消歧的性能有所提高.Cardellino和Huang等[12-13]提出了一种扩充语料库的词义消歧方法,即利用少量有标签语料训练消歧模型计算相似度,找到高置信度的无标签语料并将其添加到训练语料中,提高词义消歧效果.Mahmoodvand等[14]整合多个基础消歧模型,结合协同学习思想从无标签语料中选取高置信度语料添加到训练语料中,从而实现高质量的词义消歧.随着人工智能的发展,机器学习技术被广泛地应用到自然语言处理中[15-16].薛涛和 Pesaranghader等[17-18]提出了基于深度学习的词义消歧模型,利用深度学习算法来提取语料中的关键特征,从而确定歧义词汇的语义类别.Bordes等[19]以神经网络为基础,结合多关系图来实施词义消歧.Chen等[20]通过构建情感词汇网络,结合上下文来扩展训练语料,使得词义消歧的质量有所提高.
本文利用Word2Vec工具对歧义词汇左右各2个词汇单元的词形、词性和语义类进行向量化处理,提取有标签语料中的聚类信息,结合卷积神经网络 (convolutional neural networks, CNN)从无标签语料中选出高置信度的语料来扩充训练语料,使得CNN不断优化,最终获得高质量的词义消歧模型.
1 构建消歧特征向量
本文提取歧义词左右各2个词汇单元的词形、词性和语义类作为消歧特征.消歧特征提取过程如图1所示.
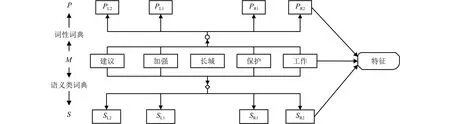
图1 特征提取Fig.1 Feature extraction
图1中:M代表词形,P代表词性,S代表语义类;PL1、PR1和PL2、PR2分别为歧义词汇左、右侧第 1个和第2个邻接词的词性;SL1、SR1和SL2、SR2分别为歧义词汇左、右侧第1个和邻接词的语义类.
对包含歧义词汇“长城”的句子,其消歧特征的提取过程如下所示:
汉语句子——文物保护组织的专家建议加强长城保护工作.
分词结果——文物 保护 组织 的 专家 建议 加强 长城 保护 工作.
去停用词和标点符号——文物 保护 组织 专家建议 加强 长城 保护 工作.
词性、语义类标注——文物/n/Ba02 保护/v/Hi37组织/n/Di10 专家/n/Al02 建议/v/Hc14 加强/v/Ih10长城/n/Bn07 保护/v/Hi37 工作/n/Hi11.
使用Word2Vec进行向量化处理:
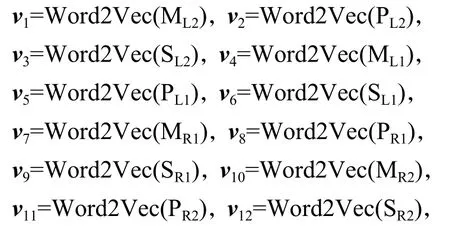
式中:Word2Vec(·)为向量化函数;ML1、MR1和ML2、MR2分别为歧义词汇左、右侧第1个和第2个邻接词的词形.
消歧特征矩阵为V=(v1,v2,v3,v4,v5,v6,v7,v8,v9,v10,v11,v12).
2 卷积神经网络词义消歧模型
卷积神经网络词义消歧模型是以前向传播的消歧过程和反向传播的优化过程为基础来构建的.
2.1 前向传播
通过输入层、卷积层、池化层和输出层的运算,最终获得歧义词在不同语义类下的概率.
2.1.1 输入层
歧义词c有l个语义类S1,S2, ···,Sl.对于c共提取了12个消歧特征.利用Word2Vec工具将消歧特征向量化,每个特征向量作为行向量,可构建一个大小为12 × 100的特征矩阵,输入到CNN消歧模型.针对以上例子,歧义词“长城”的特征矩阵构建过程如图2所示.
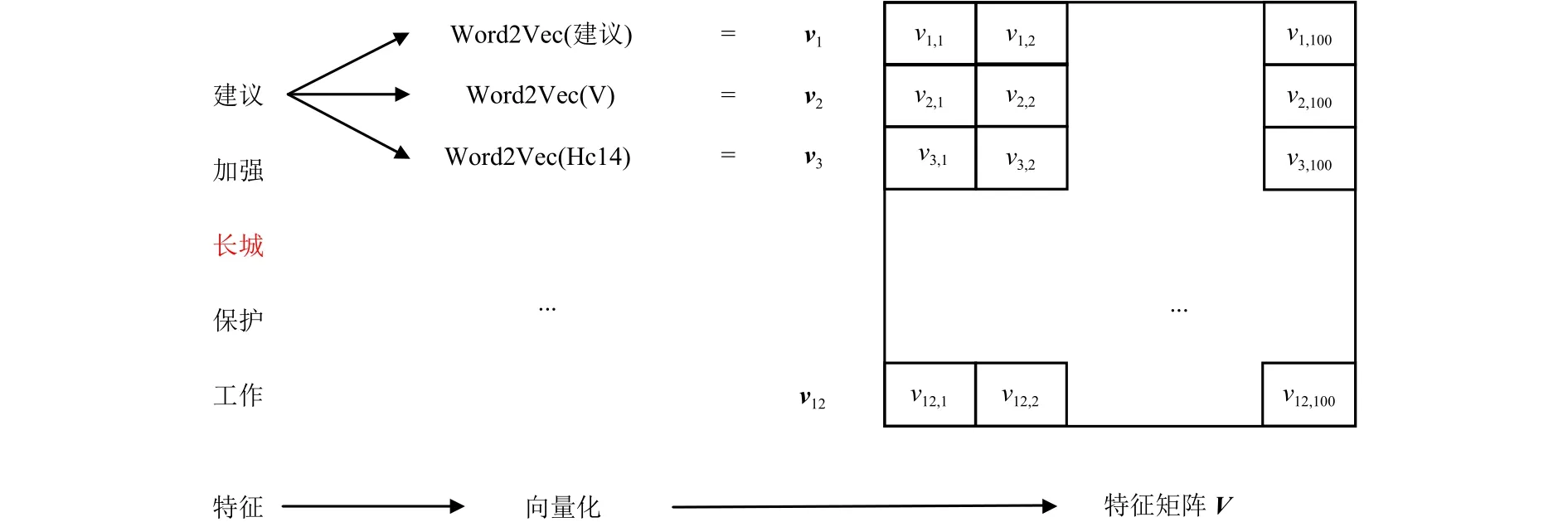
图2 特征矩阵构建过程Fig.2 Construction process of feature matrix
2.1.2 卷积层
对于歧义词汇c,经过输入层可以得到消歧特征矩阵V=(vij)12×100.使用一个大小为h×k的卷积核w在V中由上至下进行滑动,并与特征矩阵对应位置进行卷积操作.其中:h为每次卷积的特征向量的数量,1≤h≤12;k为每次卷积的特征向量的维度,1≤k≤100.卷积操作如式(1)所示.

式中:zi:j为第i个卷积核wi的第j次卷积获得的特征;vj:j+h-1为第j个到第j + h -1 个特征向量;b为偏置量;f(·)为激活函数,此处使用的是收敛效果较好的Relu函数.
每次选取 2 个消歧特征向量vj和vj +1作为特征子矩阵进行卷积,1≤j≤11.利用式(1)计算得到zi:j.zi=(zi:1,zi:2,··,zi:11),zi为第i个卷积核所提取的特征集合.通过设置不同的卷积核,可以提取不同属性的特征.设卷积核的数量为n,可以得到n组不同属性的特征,卷积层的输出结果为z={z1, z2,··, zn}.
2.1.3 池化层
此处,采用最大池化(max-pooling)方法来提取最关键的特征,如式(2)所示.
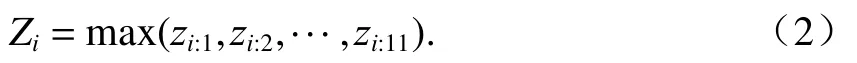
经过输入层和卷积层的操作,得到由n个卷积核提取的n组不同属性的特征z={z1, z2,··, zn},利用式(2)计算不同属性中的关键特征,则池化层最后的输出为Z=(Z1, Z2, ··, Zn).
2.1.4 输出层
在词义消歧模型中,输出层采用两层结构.
第1层是全连接层,如式(3)所示.

式中:y为净激活;W为全连接层的权重矩阵;B为全连接层的偏置量矩阵.
第2层为softmax层,输出歧义词c所属不同语义类的概率值,如式(4)所示.

式中:yd为歧义词c属于语义类Sd的净激活值;D为簇数.
在输出层中,经过全连接层和softmax层,最终输出歧义词“长城”所属不同语义类的概率,计算过程如图3所示.
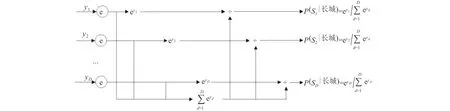
图3 softmax 层Fig.3 softmax layer
选取最大概率值对应的语义类作为歧义词c的语义类,如式(5)所示.

2.2 反向传播
反向传播通过不断调整权重和偏置量,逐步提高CNN消歧模型的泛化能力.
经过前向传播,CNN消歧模型输出歧义词c属于不同语义类的概率P(Sd|c).计算输出结果与真实结果的损失函数,如式(6).

式中:Y为歧义词c的真实语义类的One-hot表示.
根据损失函数J更新全连接层的权重W和偏置量B,然后更新卷积层的权重w和偏置量b.
3 半监督卷积神经网络消歧模型
半监督卷积神经网络消歧是利用聚类方法选取高置信度无标签语料来扩充训练语料,以优化CNN词义消歧模型.首先,对包含歧义词c的有标签语料AL进行聚类,抽取训练语料每个实例的特正量构建D个簇C1,C2,···,CD.计算每个簇的中心点和簇内各点到中心点的距离集合.根据簇内点到中心点的距离集合来设定簇内的阈值.然后,利用AL来优化CNN消歧模型.从无标签语料AU中,取出任意实例.利用优化后的CNN模型对该实例进行语义类预测,其语义类别p.判断该实例与Cd中心点的距离是否小于Cd的簇内阈值.若满足,则将该实例和其语义类别加入AL;否则,将该实例加入AU.重复上述步骤,直到有标签语料AL不发生扩充为止,循环结束.得到的CNN为优化后的词义消歧模型.训练过程如下所示.
输入包含歧义词汇c的有标签语料AL={(,其中:为有标签的特征量,qg为人工语义类标注,g= 1,2,···,mL,mL为有标签语料数;包含歧义词汇c的无标签语料为无标签的特征量,e=1,2,···,mU,mU为无标签语料数;阈值T∈{Tmax,Tmim,Tmed,Tavg},其中:Tmax、Tmim、Tmed和Tavg分别为特征量距离的最大值、最小值、中值和平均值.
输出优化后的CNN模型.
1)while (AL发生扩充){
for (inte=1;e<=mU;e+ + ){
① 根据语义类别将AL划分为D个簇,获得C1,C2, ··,CD.
② 计算簇Cd的中心点ud,如式(7)所示.

式中:xt为簇Cd内第t点的特征量,t= 1, 2, ··· ,|Cd|.
③ 计算获得簇Cd内点到中心点ud的距离集合Ld,如式(8)所示.
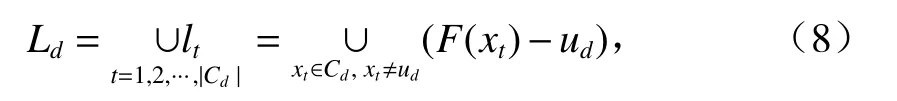
式中:F(xt)为取二元序对的第1分量.
④ 获得Ld={l1,l2,··,l|Cd|-1},对Ld由小至大进行排序,计算每个簇内的阈值:
当阈值T = Tmax= max(Ld)时,有

当阈值T = Tmin= min(Ld)时,有

当阈值T = Tmed= med(Ld)时(med(·)为中值函数),有
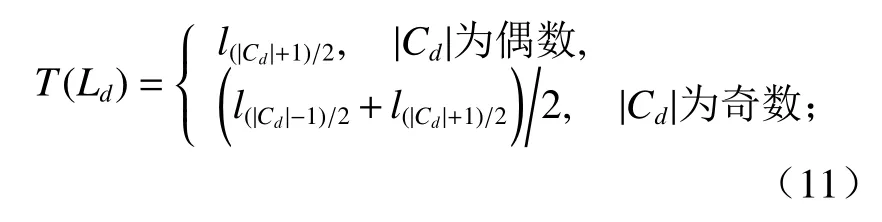
当阈值T = Tavg= avg(Ld)时,有
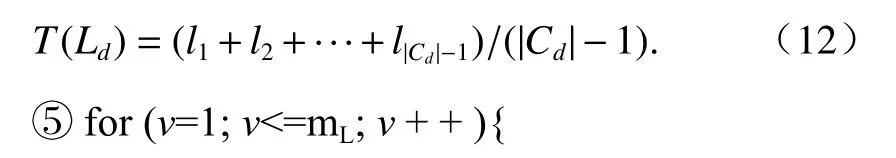
将有标签语料AL中的特征量输入到CNN模型得到歧义词汇c所属不同语义类的概率,根据式(6)计算与真实语义类的损失函数,通过不断反向迭代优化CNN模型的参数,直到损失函数收敛为止.}
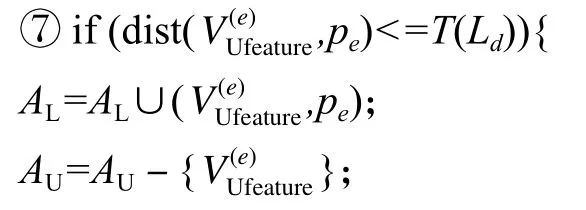
其中,dist(·)为欧式距离.
} } }
2)输出优化后的CNN模型.将包含歧义词c的消歧特征向量输入到优化后的CNN模型计算c的预测语义类为Sd的概率P(Sd|c).从中选取最大概率值所对应的语义类别为歧义词c的语义类.
4 实验分析
本文使用SemEval-2007: Task#5中的有标签语料作为训练语料和测试语料,使用哈尔滨工业大学无标注语料作为无标签语料.选取了20个具有代表性的歧义词汇进行实验.对比了深度信念网络(deep belief network,DBN)模型、CNN 模型和本文提出方法的消歧效果,共进行了3组实验.
实验 1分别设置阈值T为Tmax、Tmim、Tmed和Tavg,采用本文的半监督卷积神经网络方法进行词义消歧,实验结果如表1所示.从表1可以看出:当T=Tavg时,本文所提出方法的性能最好.
对表1中的歧义词根据类别数进行归类,计算在不同阈值下的平均消歧准确率,如图4所示.

表1 不同阈值的平均消歧准确率Tab.1 Average disambiguation accuracy of different thresholds %
从图4中可以看出:语义类别数为2的平均消歧准确率要比语义类别数为3和4的要高,其原因是:随着语义类别数的增加,预测结果具有更多的可能性,使得消歧模型更容易出错.因此,当语义类别数增加时,平均消歧准确率有所下降.对于语义类别数为2和3的情况,当阈值为Tavg时,平均消歧准确率最高.对于语义类别数为4的情况,当阈值为Tavg时,平均消歧准确率低.但是,当阈值为Tavg时,整体平均消歧准确率最高.其原因是:当阈值为Tmax时,有大量的无标签语料被误分类,从而使训练语料所对应的标签不准确,导致训练过程出现分类错误;当阈值为Tmin时,训练语料不能充分地扩充,从而导致训练语料不足;当阈值为Tmed时,由于部分数据分布较分散,从而使得中位数不具有代表性,导致训练过程不能达到最优;当阈值为Tavg时,既考虑了数据分布的不平衡性,又考虑了最具代表性的数据,因此训练效果最优.
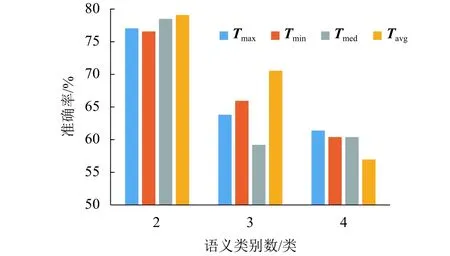
图4 不同阈值和类别数下的平均消歧准确率Fig.4 Average disambiguation accuracy at different thresholds and category numbers
实验2利用实验1获得的最优阈值,分别设置无标签语料与有标签语料的比率r.采用本文所提出的方法进行词义消歧,其消歧性能如表2所示.
从表2可以看出:随着r值的增加,平均消歧准确率呈现了一个先下降后上升的趋势.其原因是:随着无标签语料的引入,会增加很多噪声,导致消歧性能下降.当r= 100 时,平均消歧准确率上升达到最大值.其原因是:无标签语料的引入增加了大量的消歧知识,它对消歧性能的贡献已经超过噪声的影响.
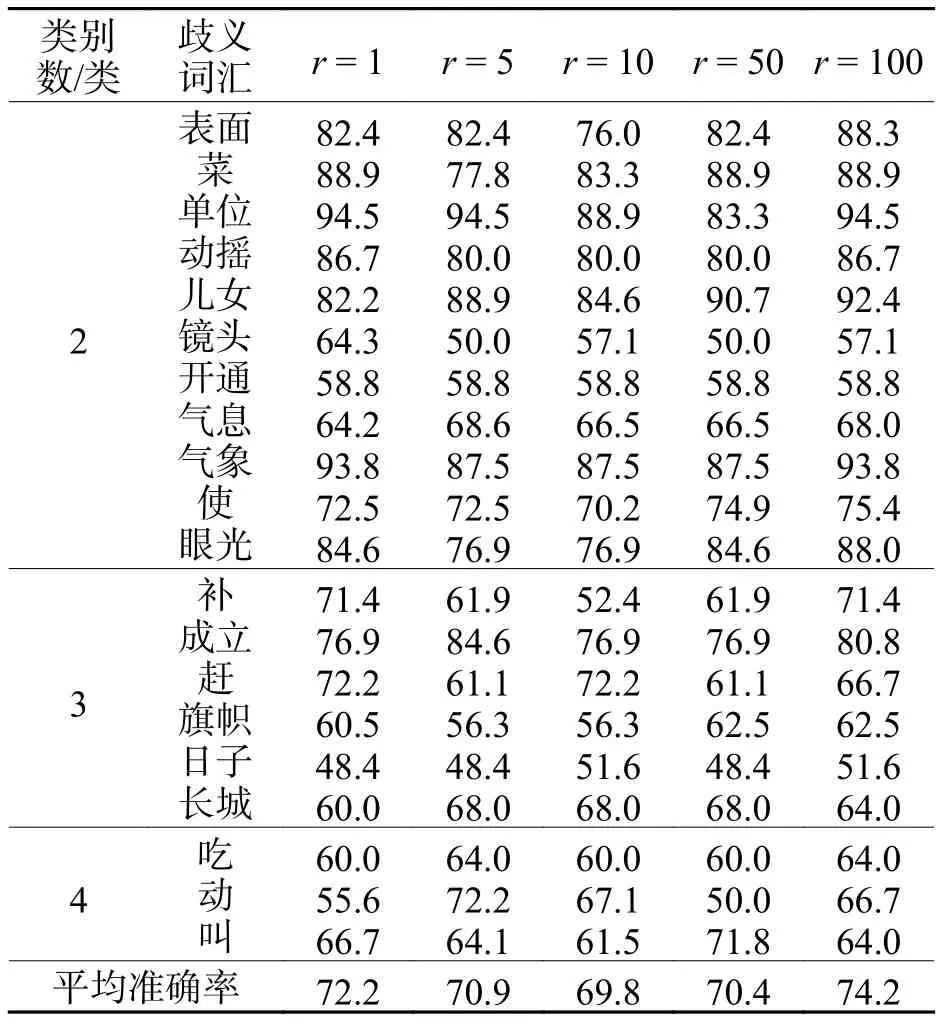
表2 不同比率下的平均消歧准确率Tab.2 Average disambiguation accuracy of different rates %
对表2中的歧义词根据类别数进行归类,计算每一类在不同比率下的平均消歧准确率,如图5所示.
从图5中可以看出:语义类别数为2的平均消歧准确率要比语义类别数为3和4的高,其原因是:随着语义类别数的增加,预测结果具有更多的可能性,使得消歧模型更容易出错.因此,当语义类别数增加时,平均消歧准确率有所下降.对于语义类别数为2和3的情况,当比率为100时,平均消歧准确率最高.对于语义类别数为4的情况,当比率为100时,平均消歧准确率排在第2位.但是,当比率为100时,整体平均消歧准确率最高.其原因是:添加无标签语料在引入消歧知识的同时,也会引入噪声.但是,在添加大量无标签语料之后,消歧知识的影响已经超过了噪声的影响.

图5 不同比例和类别数下的平均消歧准确率Fig.5 Average disambiguation accuracy at different ratios and category numbers
实验3对比了DBN模型、CNN模型和本文所提出方法的消歧效果.通过有标签语料来训练DBN模型和CNN模型,并利用优化后的DBN模型和CNN模型对测试语料进行消歧,与本文所提出方法进行对比,消歧结果如表3所示.

表3 3 组实验的平均消歧准确率Tab.3 Average disambiguation accuracy of three groups of experiments %
从表3可以看出:本文提出方法的平均消歧准确率比DBN消歧模型和CNN消歧模型高,相对于CNN消歧模型而言,本文方法的消歧准确率提高了3.1%.其主要原因是:在全监督训练过程中,只能利用少量的有标签语料来优化模型.在本文提出的方法中,利用聚类方法从无标签语料中选取高置信度语料来扩充训练语料,充分地利用了无标签语料中的语言学知识,使得消歧模型可以更好地被优化.因此,本文所提出方法的消歧效果更好.
5 结 论
本文抽取词形、词性和语义类作为消歧特征,利用词向量工具将消歧特征向量化.同时,引入半监督学习思想,利用聚类方法从无标签语料中选取高置信度语料来扩充训练语料,优化CNN消歧模型,从而有效地利用无标签语料中的语言学知识.实验结果表明:相对于监督DBN和CNN,本文所提出方法的消歧性能有所提升.
猜你喜欢
计算机与数字工程(2021年12期)2022-01-15 06:24:02
哈尔滨工程大学学报(2020年8期)2020-11-13 01:53:32
中国外汇(2019年12期)2019-10-10 07:26:58
电脑与电信(2018年12期)2018-03-23 02:37:20
疯狂英语·新悦读(2017年2期)2017-04-08 01:31:27
海外华文教育(2016年1期)2017-01-20 08:21:58
海南师范大学学报(社会科学版)(2015年7期)2015-12-28 08:17:40
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
