
基于解耦空间异常检测的人脸活体检测算法
2022-02-10 12:06徐姚文毋立芳刘永洛王竹铭
信号处理 2022年12期
徐姚文 毋立芳 刘永洛 王竹铭 李 尊
(北京工业大学信息学部,北京 100124)
1 引言
人脸活体检测是一个典型的开集识别问题,攻击手段层出不穷且日新月异[1]。现有的数据集几乎不可能包含所有攻击类型,尽管有研究者在收集数据时尽可能全面地考虑并设置攻击类型,但依旧存在新的攻击方式未被发现,并且用于呈现人脸的欺骗媒介也有无穷无尽的样式,包括不同的材质(电子显示屏、打印纸张、三维面具等)、不同分辨率(屏幕分辨率、打印机分辨率等)、不同色彩表现(色彩饱和度、亮度、对比度等)。因此,现有的人脸活体检测方法是在有限的数据上学习和推理活体与假体间的差异,并尝试推广到未知的数据上进行人脸活体检测。
近些年,主流方法从两个方面进行研究:一种是探索鲁棒的泛化性能好的特征,另一种是收集或者生成更多数据来提高模型的域适应能力。在第一类工作中,研究者探索了有判别力的信息作为活体检测的重要依据,例如人脸深度[2]、远程光电容积描记[3]和欺骗噪声[4]。还有研究者借助了其他的硬件设备获取了一些鲁棒的信息,如使用近红外相机得到红外图像[5]、使用光场相机[6]获取目标反射光在空间中的位置以及方向等信息、使用深度相机[7]直接获取目标的不同区域与相机的距离。这些线索和信息确实能够很大程度上的提高人脸活体检测的性能,但是面对复杂的应用场景、多变的攻击类型和不受控制的采集环境,这些信号可能会淹没在一些图像中,或者成为误导信号,面对复杂场景的人脸活体检测性能有限。在第二类工作中,研究者们结合多个数据库来探索域无关的活体信息。文献[8]通过学习多个数据库中共同的可区分性特征,并在判别器的对抗学习机制下使特征生成器生成的特征不具有域的特征,即判别器分不清特征的来源。文献[9]则通过生成式对抗网络(GAN)生成了更多的基于数字媒介的假体攻击人脸,模拟真实的采集场景,由此来提高模型泛化能力。这种利用多个数据库或者生成更多数据来提高模型泛化能力的方法,本质上是一种数据驱动的方法。当数据可以涵盖所有场景时,强特征表达能力的深度学习模型可以取得不错的性能,但在人脸活体检测中,数据增强或者采集仍然无法涵盖所有可能的攻击形式,人脸活体检测系统仍然面临被未知欺骗类型攻破的危险。
在人脸活体检测中假体攻击具有多样性,这种多样性使得假体样本很难在特征空间中形成一个紧凑的类,而且也会导致活体样本和假体样本之间的有效决策边界建模不准确。此外,已知的假体样本学习的决策边界应用在未知的假体样本上性能不佳。为了应对这一问题,研究者们借鉴了异常检测(anomaly detection)的想法,将假体攻击看作是异常样本,将人脸活体检测定义为一个单类特征(活体特征)的识别问题。文献[10]指出人脸活体检测的单类识别的特点:1)由于只有正样本(活体)被用来建立特征模型,假体攻击的多样性对检测性能的不良影响被最小化;2)通过增加正样本数量就可以提高系统性能,更容易的扩展训练数据;3)异常检测系统只要当观测结果偏离正常特征(活体人脸)时,就将其标记为异常(假体攻击),因此基于异常检测的人脸活体检测系统有能力检测出未见过的攻击。文献[11]使用混合高斯模型(Gaussian mix⁃ture model,GMM)建模特征分布并使用EM 算法优化,得到活体人脸特征分布进行异常检测。文献[12]组合多个单类分类器、多种CNN 特征提取器以及人脸的多个区域,并使用遗传算法优化融合权重。文献[13]则使用高斯模型建立了一个伪负类特征帮助正样本的单类训练。文献[14]使用深度特征进行单分类,提出了用户特定模型。这些基于异常检测的方法仅使用活体人脸数据构建单类特征。原始异常检测的单类训练方法无法将异常检测的优势发挥在人脸活体检测任务中。将异常检测应用于人脸活体检测面临了问题(1):仅利用活体人脸数据训练的异常检测方法性能有限,如果使用现有的假体攻击数据辅助异常检测模型建立正常样本(活体人脸)的特征空间,该如何确保假体人脸数据对异常检测的影响最小化?
异常检测是基于观测样本偏离正常样本(活体人脸)的程度来做推断的,因此保证活体人脸的特征准确表达以及跨域时保持特征的一致性非常重要。活体人脸在活体检测中不具备多样性,数据是一个闭集,这一点符合异常检测的基本假设,但考虑环境、采集设备等因素,活体人脸数据又是一个开集,这一点不利于异常检测。实际上,现有的基于异常检测的方法都没有考虑环境、采集设备等因素,然而这些不确定因素又确实存在于不同数据库之间,并且影响算法的泛化能力。所以基于异常检测的人脸活体检测面临了问题(2):异常检测的性能取决于正常样本(活体人脸)的特征表达,如何保证来自不同域的活体人脸特征不受环境、采集设备等因素影响而保持一致性?
本文提出了基于解耦空间异常检测的人脸活体检测算法,其中包括单中心对比损失和特征解耦两个关键技术。为了解决上述问题(1),本文设计的单中心对比损失实现了假体样本参与的异常检测模型训练方式,并且确保了假体样本特征分布的多样性。主要原理是使活体样本特征靠近正常样本中心,并使假体样本特征远离正常样本中心。单中心对比损失约束下,活体样本可以形成簇,而异常样本在簇外且特征分布不受约束。推理阶段根据与正常样本中心的距离来判断异常与否。为了解决上述问题(2),本文还引入了特征解耦学习,利用特征解偶的方法将活体人脸数据中的活体无关信息剔除,进而确保基于活体人脸聚类中心的异常检测方法的有效性。
2 研究现状
2.1 传统手工特征的方法
人脸活体检测的早期工作主要研究手工设计的活体检测特征。基于手工特征的方法通常设计特征提取器来提取人脸图像中的分类线索,例如纹理、运动和图像质量。然后,利用机器学习技术,例如支持向量机(support vector machine,SVM)、线性判别分析(linear discriminant analysis,LDA)和随机森林(random forests,RF),进行人脸活体检测的二元分类。
研究者使用各种特征描述子提取纹理特征,如局部二值模式(local binary pattern,LBP)[15]、方向梯度直方图(histogram of oriented gradient,HOG)[16]、灰度共生矩阵(gray-level co-occurrence matrix)[17]和高斯差分函数(difference of Gaussians)[18]。文献[19]为了评价假体人脸的失真程度设计了25 种图像质量评价指标。文献[20]设计了14 种特征来提取图像质量方面的差异。文献[21]在分析镜面反射、图像模糊和颜色分布等图像畸变的基础上,提取了人工特征。
另一些工作设计了运动线索提取器,利用眨眼、嘴唇抖动和头部运动[22]等特征来检测活体人脸。活体人脸具有血液流动导致的肤色周期变化、眨眼、面部肌肉不自主微运动等生命特征,而大多数假体人脸很难完全模仿这种生命特征[23]。文献[24]使用条件随机场来检测输入图像序列中的人眼是否具有开闭的动作,以确定其是否为活体人脸。文献[25]分析了活体人脸嘴唇的无意识微运动来进行活体检测。文献[26]利用远距光容积描记术(remote photoplethysmography,rPPG)信号检测被测者是否有心率,判断被测者是否是活人。基于前景和背景的运动差异,在文献[27]中利用三维真实图像和平面假体图像之间运动模式不同的事实提出了一种结合光流的人脸活体检测技术。
这些基于手工特征的方法可以提取某一些特定线索,但这些线索容易在类间相似度高的人脸样本中丢失。在实际应用的野生环境下,不受控制的采集设备、光照、假体媒介等因素导致活假体人脸的手工特征很难被区分。
2.2 基于深度学习的方法
深度学习在许多计算机视觉任务上已被证明优于其他学习范式。深度学习在人脸活体检测中也得到了广泛的应用。大多数基于深度学习的方法将人脸活体检测视为二分类问题,训练时使用0/1的二元交叉熵损失监督。Yang等人[28]首次将卷积神经网络(CNN)应用到人脸活体检测中。研究者对人脸图像进行预处理再使用CNN 提取特征并分类[29]。文献[30]先提取人脸边缘信息,然后应用CNN 提取分类特征。文献[31]使用剪切波(Shearlet)变换提取的图像质量信息作为CNN 的输入进行活体检测。文献[32]使用rPPG 信号的傅立叶谱作为CNN 的输入进行活体分类。文献[33]通过卷积神经网络联合长短时记忆网络(long-short term memory,LSTM)的架构从连续多帧人脸图像中提取的空间和时间信息进行活体推断。文献[34]利用三维卷积神经网络(3D CNN)从连续的多帧人脸图像中提取时空深度特征。
除了以上二元交叉熵损失监督外,还有一些深度学习的方法使用逐像素监督方式。根据人脸活体检测中攻击类型(打印攻击、重放攻击)没有人脸深度的先验知识,文献[2]首次将深度估计算法估计的人脸深度图像作为网络训练的监督信号,使CNN 的输出为深度图像(假体样本深度全为0)。论文使用双流CNN 分别学习局部特征和人脸深度特征,最终融合局部特征和深度图特征进行活体检测。文献[3]提出了一个CNN 联合循环卷积网络(recurrent neural network,RNN)的模型来学习空间特征(人脸深度)和时间特征(rPPG 信号),使用从二维人脸图像中估计出的人脸三维形状和从人脸视频中提取的rPPG 信号代替二值标签分别监督CNN和RNN。这些模型最终会专注于学习人脸深度和rPPG 信号的提取。文献[4]是第一个将噪声模式建模为辅助信息的工作,提出了人脸噪声分离的概念。文中讨论了来自颜色失真、图像降质、呈现伪影和成像伪影的噪声模式,证明了二次成像后的假体人脸图像相当于活体人脸图像经过乘性噪声和加性噪声后的人脸图像。
基于深度学习的方法在训练数据的驱动下可以得到一个拟合程度更好的深度特征,在分类性能上较传统方法有明显提升。但这些深度学习方法的性能优势取决于数据,大部分方法没有关注到活假体本质差异,当遇到新的攻击类型时,很难获得优秀的检测性能和泛化性能。
3 单中心对比损失的异常检测实现
3.1 单中心对比损失
经典的异常检测模型仅对正常样本进行无监督学习,并将其表达到一个紧凑的特征空间,根据特征分布区分异常样本。表1中的实验结果证明正常样本单类别学习的异常检测应用在人脸活体检测上的性能不佳,在相同数据集内基于单类的方法性能远不如二分类的性能。本文提出的单中心对比损失使用已知的假体攻击数据辅助模型表达正常样本(活体人脸)的特征空间,既保持了活体与假体特征的可分性,又保证了用于异常检测的活体特征的紧凑分布,如图1所示。

图1 单中心对比损失应用于异常检测示例图Fig.1 The sample graph of single-center contrast loss applied to anomaly detection

表1 单类方法与二分类方法的ACER(%)对比Tab.1 The ACER(%)result comparisons between one-class and two-class method
异常检测的基本假设是正常样本属于一个闭集,而异常样本是该闭集以外的异常值并且属于开集。因此,本文单中心对比损失将特征空间中活体样本拉到一个紧凑区域内,而将假体样本推出这个区域。假设活体样本中心的特征向量是c,令D(∙,c)表示与活体样本特征中心的距离。给定一个批次(batch)的数据,包含Nl个活体样本的特征向量(x1,x2,…,xNl)和Ns个假体样本的特征向量(s1,s2,…,sNs),对活体样本的拉力为最小化目标函数Lpull,对假体样本的推力为最大化目标函数Lpush:

其中Lpull计算了活体样本与中心c的距离误差,使活体样本特征尽可能靠近中心。Lpull受启发于中心损失[36],可以得到更加紧凑的特征表达,但不同的是,中心损失为每一个类别均设置了一个中心特征,而本文中仅设置一个活体特征中心。Lpush更加倾向于使假体样本与活体特征中心保持一定的距离,不对假体样本特征的做聚类性约束,便于从中学习到特征的多样性表达。
单中心对比损失包括了对活体样本的拉力损失Lpull和对假体样本的推力损失Lpush。本文设置了以活体样本特征中心c为锚点的距离度量方式,训练时不需要成对样本,只需将每个批次的所有样本与活体中心c计算距离。式(1)和式(2)中使用欧氏距离(euclidean distance)对L2 范数归一化特征进行度量。参考对比损失[37]对推拉力的计算方式,单中心对比损失的计算式如下:
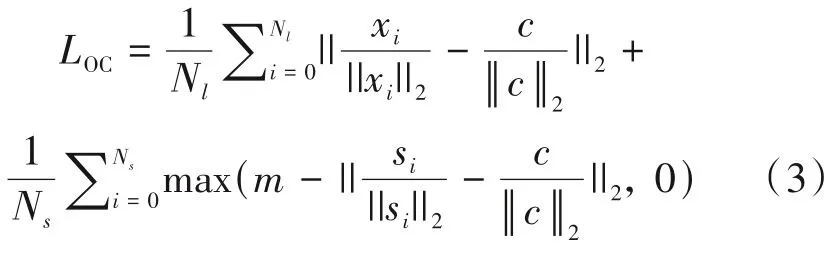
其中活体样本特征中心c是在迭代中动态更新。也就是说,训练中除了用每一个批次的特征计算出单中心对比损失Loc来优化特征提取模型,还使用每一个批次中的活体样本特征来更新中心特征c。活体样本特征中心c的误差优化算法式如下:
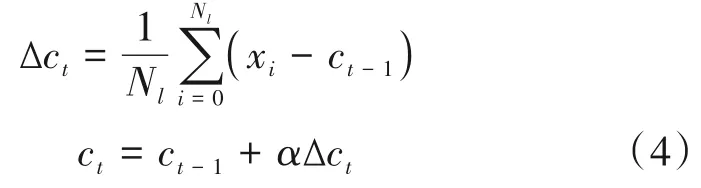
活体样本特征中心c的更新策略是在每次迭代中计算活体样本与中心样本差值的平均值来确定中心特征移动的方向和幅值。为了避免小批量样本中不准确的样本对中心造成的扰动,本文设置了超参数α来控制中心特征的学习率。
3.2 网络架构
本文所提出的单中心对比损失在人脸活体检测的网络模型上进行了应用。CDCN[38]模型在捕获图像像素语义信息和图像梯度详细信息方面表现出不错的能力。本文以CDCN 模型为基准,将单中心对比损失应用到整个网络的三种不同层次的特征上,整体结构如图2所示。

图2 应用单中心对比损失的人脸活体检测网络Fig.2 A face anti-spoofing network using single-center contrastive loss
CDCN 模型有三个主要的特征提取区块,每个区块包括三个3 × 3 的CDC 卷积核和一个最大池化层,分别得到三种不同分辨率的特征。CDCN 的输入是单帧活体人脸图像IL或者假体人脸图像IS,对应的标签是深度图或全零图,使用均方误差和对比深度损失(分类损失LCDC表示两者之和)对模型优化[18],使输出图像具有活体分类的特性。在本文中,单中心对比损失LOC优化CDCN模型表达中间层特征的正常和异常特性。LCDC和LOC共同作用在CDCN 模型上,并设置了系数λ平衡两个损失函数的贡献。总损失表达式为:

4 基于解耦空间异常检测的人脸活体检测网络
4.1 特征解耦表示
在人脸活体检测任务中,活体判别特征很容易受到人脸身份、环境光照、采集设备等带来的噪声干扰。而基于异常检测的人脸活体检测非常依赖活体人脸特征,与活体无关的信息将会降低算法检测性能。为了确保活体人脸特征在不同域间具有一致性的表达,本文采取特征解耦表示的方式,将特征空间解耦为两个子空间:活体检测特征空间、活体无关特征空间。其中活体检测特征空间包含活体检测特征,活体无关特征空间是不包含活体类别属性的特征空间,包括其他的人脸身份、背景、环境光等特征。整体框架如图3 所示,包含一个自编码器(autoencoder)和一个浅层卷积神经网络CNN,其中自编码器由一个解码器Dec和两个不同的编码器Ep、En构成,编码器分别是活体检测特征编码器Ep和无关特征编码器En。本文旨在解耦活体人脸的活体检测特征用于异常检测,故使用包含活体人脸图像的两张图像(活体—活体或活体—假体)进行交叉解耦。给定两张用于交叉解耦的图像x1,x2,活体检测特征编码器Ep和无关特征编码器En分别提取活体检测特征zp1,zp2和噪声特征zn1,zn2。编码器用于从一个活体检测特征和一个噪声特征中重构人脸图像:

若活体检测特征和噪声特征来自同一张图像,则重构图像和原图像一致。若进行交叉解耦,活体检测特征和噪声特征分别来自不同人脸图像,则重构的人脸图像具备与编码活体检测特征图像相同的活体属性,具备与编码噪声特征图像相同的身份、环境等信息。特征交叉解耦除了满足上述要求外,还应满足重构图像再次编码后可以准确还原活体检测特征和噪声特征的要求。理想状态下,表达式为:

为了区分活体检测特征与噪声特征,浅层CNN对活体检测特征进行了活体类别约束,同时活体检测特征编码器Ep中还引入了第1 章的异常检测特征学习方法。在测试阶段,活体检测特征会经过浅层CNN得到活体与假体的类别推断。
活体检测特征编码器Ep和浅层CNN 连接起来实际上是一个完整的人脸活体检测网络,网络结构见图2,Ep对应特征提取器,浅层CNN 对应分类器。无关特征编码器En和解码器Dec 是辅助特征解耦的其他网络模型,详细网络架构如图4 所示。网络中所有卷积层为普通卷积,卷积核大小均为3×3。无关特征编码器En中的卷积层后都有一个批次归一化层BN 和一个ReLU 激活层。解码器Dec 中的卷积层后除最后一层外都有一个实例归一化(in⁃stance normalization)[39]和一个ReLU 激活层。解码器Dec 中的上采样层(upsample)使用最近邻插值法(nearest neighbor)进行两倍尺寸放大。

图4 无关特征编码器En和解码器Dec的网络架构Fig.4 Architecture of feature-independent encoder and decoder
4.2 损失函数
本文提出了一个基于解耦空间异常检测的人脸活体检测算法,该算法包含了三个内容:特征解耦、异常检测、活体检测。活体检测特征编码器分别从这三个方面学习活体检测特征的表达。相应地,本文设置了三种损失函数帮助模型训练优化,分别是特征解耦损失LDR、单中心对比损失LOC、活体分类损失LFAS。
从同一张图像中得到的活体检测特征和噪声特征相加后可以由解码器Dec重构出人脸图像。为了确保解码器重构的有效性,本文使用自编码器的自监督学习方式,对输入图像xi和重构图像进行L1约束,图像重构损失式如下:

成对图像(活体—活体或活体—假体)编码后共得到四个特征:活体检测特征zp1,zp2和噪声特征zn1,zn2。两组交叉特征zp1+zn2和zp2+zn1解码再编码应还原各特征编码,利用交叉重构损失进行特征重构:

本文算法中使用单中心对比损失LOC对活体检测特征编码器Ep进行约束,每个批次中所有输入到Ep的样本参与异常检测特征训练,详情见第1 章,LOC表达式见式(5)。算法对重构前后的活体检测特征进行有监督学习,根据活体类别标签lpi计算活体分类损失:

其中LCDC计算见文献[18]。本文提出的算法整体损失函数是特征解耦损失LDR、单中心对比损失LOC、活体分类损失LFAS的加权和:

其中λ1、λ2为平衡各损失函数的权重值。
5 实验设置与结果分析
5.1 数据库与评价指标
数据库本文算法在5 个公开人脸活体检测数据库上进行评估,分别是:Replay-Attack[40]、CASIA-FASD[41]、OULU-NPU[42]、SiW[3]和CASIASURF 3DMask[43]。Replay-Attack 数据库分辨率为320×240,CASIA-FASD 数据库包含640×480、480×640 和1280×720 三种分辨率。这两个数据库发布于2012 年,属于低清数据库,包含重放攻击和打印攻击。很多算法已经在这两个数据库的库内测试上取得了0 错误率,因此现在主流的实验是进行交叉跨库实验。OULU-NPU 数据库包含5940 个分辨率为1920×1080 的视频,SiW 数据库包含4620 个分辨率为1920×1080的视频。这两个数据库是高清数据库,包含重放攻击和打印攻击。与前两个老数据库不同的是,这两个数据库考虑了更多的不可控因素,包括不同的采集设备、不同采集环境以及不同攻击呈现设备。OULU-NPU和SiW 数据库的库内测试分别设置了4 个和3 个协议,用于从不同角度考察算法的性能和泛化性。CASIA-SURF 3DMask 数据库则是一个3D 面具攻击数据库,包含288个活体视频和864个高清的面具攻击视频。数据库采用了高质量的面具,并设计了正常光、逆光、前照光、侧照光、户外阴影光和户外光6种光照条件,充分增加活体检测难度。通常,在OULU-NPU 和SiW 数据库上训练的模型在该面具攻击数据库上进行跨攻击类型测试,验证算法应对未知攻击类型的能力。
评价指标为了与其他工作公平对比,本文严格按照相同的评价指标对模型进行评估。OULUNPU 数据库以及SiW 数据库的库内测试,以假体人脸分类错误率(APCER)和活体人脸分类错误率(BPCER)[44]的形式报告结果,并计算两者的平均分类错误率(ACER)比较整体性能。与其他工作中的跨库测试一样,CASIA-FASD 和Replay-Attack 之间的跨库测试以及CASIA-SURF 3DMask 数据库的跨库测试报告半总错误率(HTER)[24]。
5.2 实验细节
数据库中所有视频帧使用人脸检测算法S3FD[45]检测到人脸框,训练中适当的缩放人脸框以包含少量背景并得到不同比例的人脸。人脸框以人脸位置随机缩放到1.2~1.4 倍大小来裁剪人脸,并将裁剪的人脸大小统一调整为256×256。除了不同人脸比例的数据增强外,本文算法还使用了随机水平翻转、随机擦除、像素加值增强以及对比度调整四种数据增强方法。算法训练以小批次数据进行训练,在单张NVIDIA Titan X 显卡上训练的批次大小是12。网络参数使用Adam 优化器更新,初始学习率为0.001,随着迭代次数的增加,学习率下降50%。
除了数据和训练的细节,还有一些算法细节。本文单中心对比损失的中心特征初始化规则是使用第一个批次中活体样本特征的均值初始化,之后每一个批次都按照式(4)更新中心特征,其中学习率α取值为0.5。算法中使用的交叉解耦训练方式是在每个批次的数据中进行的。一个批次的样本经过编码器得到编码特征后,批次中的数据随机两两匹配,保留含有活体样本的特征,进行交叉组合并解码再编码等计算。损失函数中的超参数λ1、λ2分别取值为0.5、0.005。
5.3 消融实验
中心特征学习率 本文提出的单中心对比损失依据样本与活体样本特征中心的距离优化模型,其中活体样本特征中心也随着模型的优化而更新。式(4)给出了中心特征的误差优化算法,其中超参数α控制每个批次活体样本特征的贡献度。本文根据经验预先设置了几个可能的取值,并进行实验对比不同α取值对特征学习的影响,在OULU-NPU 数据库协议4 上的实验结果如图5 所示。实验结果表明,不同学习率α的测试性能相对稳定。整体上来看α值大于0.5 时比小于等于0.5 时的性能差。α值越大意味着每个批次中活体样本特征对中心特征影响越大,小批量样本中不准确的样本对中心特征造成的扰动更加明显,特征学习不稳定。根据实验结果本文算法中心特征学习率 α 取值为0.5。

图5 不同α取值在OULU-NPU数据库上的性能Fig.5 Performance of different values α on OULU-NPU database
此外,我们还尝试使用参数学习法替代本文中心特征的更新策略。首先随机初始化中心特征,并将中心特征视为可学习的参数,如CNN 卷积核参数一样,放入Adam 算法优化器进行自动优化。在训练中中心特征和网络其他参数一起以相同的学习率进行优化,最终在OULU-NPU 数据库协议4 上的ACER 为8.95%。实验结果表明使用参数学习法的性能均不如不同α取值的误差优化算法,这一点证明了直接根据每批次活体样本与中心特征的误差优化中心特征的优势。
损失函数平衡权重本文算法模型使用式(12)的损失函数优化,其中包含两个超参数λ1、λ2。活体分类损系数固定为1,λ1用来平衡用于异常检测的单中心对比损失,λ2用来平衡用于解耦表示的特征解耦损失。本文进行实验探讨不同数量级的权重系数的敏感程度。实验中固定一个权重参数,逐一训练测试另一个参数不同取值的性能,图6 展示了不同取值下ACER错误率的对比。实验结果显示λ1、λ2分别在0.5 和0.005 上取得了最优性能,不过两种的值太大会导致性能急剧下降,λ2在0.001~0.01的范围内模型性能保持稳定。

图6 权重系数不同取值在OULU-NPU数据库上的性能Fig.6 Performance of different weight coefficients on OULU-NPU database
异常检测与特征解耦的优势本文提出了一个基于解耦空间异常检测的人脸活体检测算法,算法包括异常检测和特征解耦两个关键技术。为了直观的体现这两个技术对于活体检测的帮助,本文进行了消融实验,共分为四组:基准网络(baseline)、仅使用特征解耦(w/DR)、仅使用异常检测(w/OC)、同时使用特征解耦和异常检测(w/DR+OC)。实验在最具挑战性的OULU-NPU 数据库协议4 上进行,协议4 有6 个实验分别对6 个不同采集相机进行了留一法交叉验证,表2 给出了每个方案全部六次的实验结果并报告了ACER的均值和标准差。实验结果表明异常检测或者特征解耦对人脸活体检测性能都有提升作用,不过本文提出的单中心对比损失学习的异常检测特征比解耦表示特征更加有效。当同时引入两种技术,人脸活体检测错误率相当于基准网络的检测错误率下降了超过一半。消融实验证明了本文提出的利用活体解耦特征进行异常检测学习的人脸活体检测算法的先进性。

表2 异常检测与特征解耦的消融实验结果ACER(%)Tab.2 Ablation experiment results ACER(%)of anomaly detection and feature disentangling
5.4 库内测试实验
为了进一步证明本文算法的先进性,本文与现有的先进方法进行了对比实验。本文首先在公开数据库OULU-NPU 的库内测试协议上进行实验,严格遵循OULU-NPU 的四个测试协议来评估算法在各种场景和采集条件下的性能表现。在协议3 和4中,分别有6次不同的采集相机交叉验证的测试,最终以6次实验结果的平均值和标准差来报告总体的性能。表3展示了本文算法与最先进的方法的实验结果对比,以ACER指标来评估整体性能,值越低表示性能越好。实验结果显示本文方法的性能在大部分协议上都优于对比方法,仅在协议3 上略逊于MA-Net,而MA-Net实际上在其他协议1、2、4上的性能与最优方法相差甚远。而且,本文方法在协议1上以绝对性的优势超过了其他先进方法,这个协议验证了算法的人脸活体检测分类准确率。更重要的是,本文方法在协议4 上取得了新的突破。协议4是最具挑战性且与实际应用场景最接近的测试协议。测试数据与训练数据在用户身份、采集环境、采集设备、欺骗介质方面均不相同,是完全未知的数据。协议4性能的突破得益于用解耦特征来异常检测的抗干扰能力。

表3 OULU-NPU数据库的库内测试结果对比Tab.3 Comparison of intra-database test results of OULU-NPU database
本文还在SiW 数据库的三个协议上进行了实验。三个协议分别评估算法对姿态、欺骗媒介、攻击类型这三种变化的鲁棒性,尤其是协议三从重放攻击到打印攻击(或打印攻击到重放攻击)的跨攻击类型的性能评估颇具挑战。表4展示了本文方法与其他先进方法的性能对比,错误率ACER 用来衡量算法整体性能。实验结果显示本文在协议1和协议3 上的性能优于其他方法,协议2 的性能位于第二。协议二中性能最好的RSGB+STPM 方法仅比本文方法降低0.02%错误率,而本文方法在其他两个协议比RSGB+STPM 方法分别降低了0.32%、1.17%错误率,并且取得了突破性的性能。由此可见,本文方法应对不同因素干扰的能力较为全面。此外,本文算法在协议三取得的性能证实了本文提出的基于解耦空间异常检测来应对新攻击类型的可靠性,这种优势来源于不特定假体样本的异常检测思路。下一节进行跨库测试实验进一步验证算法应对未知攻击类型的能力。

表4 SiW数据库的库内测试结果对比Tab.4 Comparison of intra-database test results of SiW database
5.5 跨库测试实验
跨数据库测试旨在评估相关模型的泛化能力。目前,很多方法在Replay-Attack 和CASIA-FASD 数据库上进行跨库测试。为了公平比较,本文使用相同的数据库和评估指标进行交叉测试的跨库实验。表5报告的结果表明本文模型在跨库测试的对比中处于领先位置,从CASIA-FASD 到Replay-Attack 的跨库测试优于所有对比方法。这种跨库实验验证了算法对未知数据的判断能力,其中包括未知的人脸身份、环境、设备等,本文算法的低跨库检测错误率证实了特征解耦对无关信息的抗干扰能力。

表5 Replay-Attack和CASIA-FASD数据库的交叉跨库测试的HTER(%)结果对比Tab.5 Comparison of HTER(%)results of cross-database testing between Replay-Attack and CASIA-FASD databases
以上跨数据库测试中训练和测试数据使用了相同的攻击类型,为了验证算法应对新的攻击方式的能力,本文还进行了跨攻击类型测试。在这个协议中,算法模型在OULU-NPU 和 SiW 数据库上一起训练,然后在CASIA-SURF 3DMask数据库上进行测试。训练集中仅含有重放攻击和打印攻击,而测试数据为3D 面具攻击,而且两者数据采集环境不同,这是一个非常具有挑战性的测试协议。实验结果如表6 所示,本文方法在这种同时跨库和跨攻击类型的测试中取得了相对于对比方法更好的错误率。本文方法相对于第二名的Auxiliary 方法降低了5.41%的错误率,相对于经典的ResNet50 网络降低了21.21%的错误率。这种大幅度的性能提升可以归功于本文提出的基于异常检测思想的单中心对比损失。单中心对比损失的设计初衷正是避免活体特征受训练集中有限的假体样本的影响,可以成功应对更多新的攻击类型。

表6 CASIA-SURF 3DMask数据库的跨库、跨攻击类型测试结果Tab.6 Cross-database and cross-type test results of CASIA-SURF 3DMask database
5.6 实验可视化与分析
本文提出的基于解耦空间异常检测的人脸活体检测算法在多个数据集上进行了验证,各评价指标的结果证明了算法的先进性。为了进一步直观的展示本文算法的优势,本文对模型中的特征以及特征分布进行了可视化对比。
本文使用经典的可视化算法t-SNE[62]对本文算法中的特征提取器Ep提取的活体检测特征以及分类器CNN 的分类结果进行可视化。为了体现特征解耦与异常检测结合的特征学习方法的优势,本文还可视化了不使用特征解耦与异常检测的CDCN网络从相同数据提取的相应特征的分布情况。图7展示了两模型的特征提取器与分类器在OULU-NPU协议4 的一个测试上的特征分布结果。图(a)和图(b)为基准网络CDCN 的两种特征分布,图(c)和图(d)为本文算法模型的两种特征分布。图(a)和图(c)为两个模型同一层次特征的对比,本文算法模型提取的特征(c)相比于CDCN 的特征(a)多应用了单中心对比损失约束和特征解耦学习。从图中可以看出两个模型虽然在验证集(val)上都获得了明显可分的活体与非活体的特征,但是图(a)中测试集(test)的活体与非活体特征聚在一团,与验证集特征分布不一致。然而,图(c)中测试集与验证集保持了相同的特征分布,并且活体可分,这种特征具有更强的泛化能力。不仅如此,图(c)中活体样本特征更加紧凑,向本文设置的活体特征中心靠拢。再对比分类器的结果分布图(b)和图(d),本文算法的特征仍然能够保持验证集和测试集同分布。要知道在OULU-NPU协议4上测试集是完全未知的数据,验证集和测试集的同分布体现了模型应对新样本的高泛化能力。不仅如此,本文算法特征的活体(绿色标记)与非活体(其他颜色标记)分界更加明显,活体检测错误率更低。
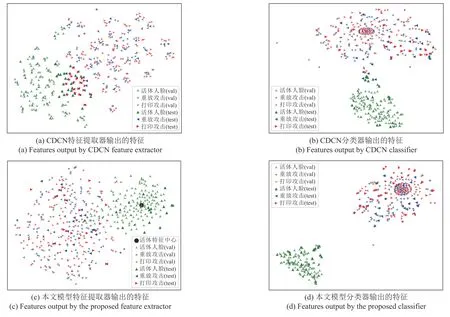
图7 模型特征t-SNE二维可视化Fig.7 t-SNE 2D visualization of model features
除了对比特征分布情况,本文还直接可视化了中间层特征进行对比。图8展示了本文算法模型与CDCN 基准模型的同一层次特征对比。本文算法活体检测特征编码器Ep输出的特征zp共384 个通道,图中以单通道图像形式显示了部分通道的特征图。图(a)为训练集中单中心对比损失使用的活体特征中心,图(b)和图(c)分别是测试集中一张随机采样的活体人脸的特征和一张随机采样的假体人脸的特征。通过对比可以发现,活体人脸特征与活体特征中心非常相似,与假体人脸特征差距较大。这一点充分证实本文算法提取的特征用于活体检测的有效性。图(d)和图(e)分别是基准模型提取的与图(b)、(c)对应的活体样本和假体样本的特征。这两张特征图的对比差异很小,这种不明显的差异使得模型的分类性能受损。本文算法提取的活体与假体的特征差异显然大于基准模型提取的特征差异。通过差异对比,可以得出结论:本文引入解耦特征进行异常检测的方法显著地提高了活体检测性能。

图8 本文算法与基准模型的特征(部分通道)对比Fig.8 Comparison of output features(partial channels)between the proposed model and the benchmark model
为了进一步确定未来研究方向,本文对实验中出现的问题进行分析。本文算法在库内测试中取得了很好的性能,跨库测试的性能虽然有所提升,但仍然有待提高,尤其是从OULU-NPU 和 SiW 数据库跨库到CASIA-SURF 3DMask 数据库上的测试结果。图9 展示了成功和失败的案例,并和训练数据进行了对比。该跨库测试中,大部分错误结果发生在活体样本,主要原因是测试数据中的活体人脸与训练数据相差较大,存在面部光照暗淡、光照极度不均衡以及面部姿态角度极大的问题。鉴于异常检测用于鉴别异常的思路,测试数据中无论真假与训练数据中活体人脸相差较大均会被判断为假体。因此,不同数据库中活体人脸之间的差异仍然是异常检测的最大障碍。尽管特征解耦可以缓解差异,但人脸光照和姿态的极大差异仍然没有被很好的解决。
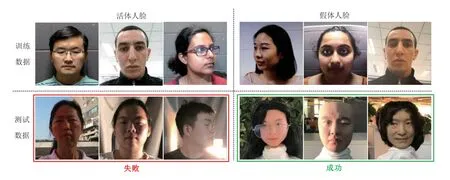
图9 跨库测试中的成功与失败案例Fig.9 Success and failure in cross-database test
6 结论
本文提出了一种基于解耦空间异常检测的人脸活体检测算法。本文设计了单中心对比损失对活体样本进行异常检测特征的学习,在不限制假体样本分布的情况下,拉近活体特征之间的距离并推远活体特征与假体特征的距离。本文还对活体人脸进行了特征解耦,将其特征分为两个子空间:活体检测特征空间、活体无关特征空间。在活体检测特征空间上,活体人脸特征不受其他无关因素的影响。解耦模型学习到的活体人脸特征可以覆盖更多的身份、环境、设备不同的活体样本。解耦后的活体人脸特征更加有助于异常检测(不符合活体人脸特征分布的样本即是假体样本),因此解耦特征与异常检测思想的结合可以更好地抵抗新的攻击类型。本文设置了消融实验、库内实验、跨库实验、跨攻击类型实验验证算法检测性能和泛化能力。大量实验表明,本文提出的基于解耦空间异常检测的人脸活体检测算法在检测性能和泛化性能上均优于其他方法。在未来的工作中,包含活体人脸样本的其他相关领域数据集(如人脸识别数据集、伪脸检测数据集)可以用来扩展用于异常检测的正常样本数据,这是一个低成本的数据扩充方法。在充足的数据基础上更好的基于异常检测的人脸活体检测模型值得被研究。
猜你喜欢
基层中医药(2022年1期)2022-07-22
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
昆明医科大学学报(2021年1期)2021-02-07
华人时刊(2020年21期)2021-01-14
保健医苑(2020年1期)2020-07-27
电子制作(2019年10期)2019-06-17
动漫星空(2018年9期)2018-10-26
中华骨与关节外科杂志(2016年6期)2016-05-17
百科探秘·航空航天(2015年10期)2015-11-07
