
结合日志与深度学习的网络软件异常检测算法
2022-02-09 02:21刘杰逾王晓辉
计算机仿真 2022年12期
刘杰逾,王晓辉
(1. 成都文理学院,四川 成都 610401;2. 河南中医药大学,河南 郑州 450046)
1 引言
随着计算机技术在航空航天、国民经济等重要领域被广泛应用,现如今社会的发展已经离不开计算机系统,而这种离不开主要是对不同功能软件的依赖[1]。由于应用需求的不断扩大,软件功能需求也不断深化,软件系统设计越来越复杂,难免会出现软件缺陷,给用户造成严重的损失。如何构建可信软件,对软件的安全性与可靠性进行分析成为国内外研究的重点。
软件可信[2]是指通过对不正常行为产生的信息结果,采取相应的措施,并进行及时地控制,降低交互过程中异常行为对各种应用系统造成的严重影响[3-5]。如果检测的软件行为与正常行为间存在显著差异,则软件行为有异常,通过对不同软件行为数据差别的计算,判断某一类是否异常。文献[6]在日志系统分析方面深入探究深度学习CNN-text,为了对CNN-text算法的优越性进行分析,采用CT与系统日志相结合的方法对机器模型SVM和决策树对比值进行研究,分析CT对特征的处理方式,实验结果表明,该方法明显提高了模型的准确率、召回率和查准率。文献[7]同时对日志的时间序列特征和参数空间位置特征进行兼顾,为了避免日志异常特征被淹没,将拼接映射方法进行融合处理,基于Hadoop日志数据,在对模块的可行性分析后,对SVMC、CNN模型的分类效果进行验证,实验结果表明,该方法检测准确度较好,泛化能力较强,但对异常行为检测稍有延迟。文献[8]将深度学习与规则匹配和黑白名单相结合,通过对日志的分析,检测出软件中的异常行为,同时采用分布式的存储与计算系统,分析离线和实时日志模式,实验结果表明,该方法在一定程度上能够检测出0day攻击,具有较好的识别能力,但安全检测能力需要进一步提高。
基于以上研究,本文设计了基于日志与深度学习的网络软件异常检测方法。将CNN与RNN相结合,通过分类器对文本特征分类,采用半定长的方式降低模型的时间复杂度,用SPLEE方法对日志进行结构化处理,结合设计的深度学习模型捕捉日志的上下文关系,构建出异常检测模型。
2 深度学习模型
通过深度学习模型,对网络软件系统日志信息进行学习与分析,达到实时监控运行系统的目的。机器学习模型的稀疏矩阵与传统机器学习的样本、词汇量有关,用公式可表示为
Mspa∝Snum×Vnum
(1)
其中,Snum表示样本数量;Vnum表示词汇数量。随着词汇数量的增多,样本空间随之增大,稀疏矩阵模型的训练会更加困难。深度学习所消耗的空间较小,对词汇进行嵌入,输入模型的张量用公式可表示为
Min∝Snum×Lmax×Demb
(2)
其中,Lmax表示最长句子长度;Demb表示词语的嵌入维度。此时模型的训练与词汇量没有任何关系,深度学习的空间使用相对较少,解决了机器学习占用空间大的问题。
将CNN与RNN相结合对文本进行分析,首先通过CNN将文本中的重要特征抽取出来存在池化层中;然后通过RNN对池化层进行学习,并预测出最终的结果。通过CNN与RNN的结合有效避免了序列较长而产生的遗忘效应。通过分类器对文本的主要特征进行分类,由于词嵌入是把整个词向量视作为一个整体,经过卷积核的运算后特征能够被明显地提取出来,因此这种半定长的方式很适合文本的特征提取,可以极大地降低模型的时间复杂度,用公式可表示为
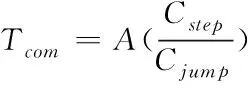
(3)
其中,Cstep表示卷积核步数;Cjump表示卷积核跳跃次数。传统的神经网络模型并不注重序列的特征关系,但网络日志文件的词语主要由字符决定,因此应对词汇序列特征更为注重。本文使用CNN的卷积核和特征向量及池化向量对文本向量进行遍历和权重的提取,并将池化向量代入RNN中。基于卷积原理,池化层的各个向量间通过线性关系变换,用公式可表示为
Play∝Wmax
(4)
其中,Wmax表示最大权重特征值,这样可以方便地将CNN的注意力集中在文本信息的重要特征上。将RNN放在池化特征前,由于RNN每次的转移输出结果受上一次影响,那么在RNN中进行最后一次转移的结果用公式可表示为
RRNN=αRNN(a·RT-1+b·Cin_T)
(5)
其中,αRNN表示参数;a和b表示在RNN中αRNN的单次处理过程;T表示传递次数;RT-1表示倒数第二次RNN的输出结果;Cin_T表示最后一次输入特征。将RT-1无限展开,用公式可表示为
RRNN=βRNN(αRNN(αRNN(…Wmax…)))
(6)
由此可见,决定样本各类特征向量的子矩阵间具有正交关系,对含有正交关系的特征训练能降低模型受样本数量的影响程度,因此本文提出的模型在一定程度上能够避免文本数据不均衡产生的影响,能够更好地训练文本。在数据输入模型上选择Tf-Idf模型矩阵,基于概率和信息熵原理对文本特征进行筛选,用公式可表示为
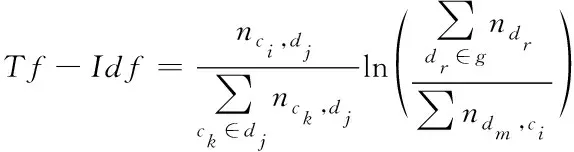
(7)
其中,nci,dj表示dj文档中单词ci的数量;ck表示dj文档中包含的单词;ndm,ci表示包含单词ci的文档在语料g中的个数。若一个单词在某个文本中出现的频率高,在其他文本中出现的频率低,那么这个单词的Tf-Idf值越高,该单词在文本越重要。
SVM是一种通过建立超平面对数据进行监督的分类器,以二分类文本为例,SVM超平面用公式可表示为
(8)
其中,Pa和Pb表示两个类别的边界超平面;Pb表示分类超平面;δT表示系数项;xi表示样本特征;φ表示超平面偏置。那么SVM的优化实质用公式可表示为
(9)
其中,d表示各个分类边界超平面Pa和Pb之间的距离。综上所述,规划矩阵大小由样本特征数量决定,样本特征也会对超平面的系数和偏置造成影响,因此特征工程的正确选择很重要。
3 日志异常检测
异常检测是计算机系统的重要任务,指在数据中没有找到符合预期的行为模式。而日志中记录了系统和软件中各关键点的重要信息,通过这些信息可以对故障的原因和系统的性能进行分析与调试,因此系统日志是异常检测的数据来源。然而系统异常检测主要存在日志解析困难、异常类型繁多、时效无法保证和日志上下文间较为依赖等四方面难题,为此本文使用SPLEE方法对原始非结构化的日志进行结构化处理,然后利用深度学习模型捕捉日志的上下文关系,构建异常检测模型。
系统生成的日志是非结构化的,每条日志均由常量和变量两部分组成,因此在系统生成非结构化日志之前需要对其进行解析,转化成结构化日志。本文使用SPELL方法对日志进行结构化处理,日志消息用公式可表示为
SP=(Ccon,ListID,Pvar)
(10)
其中,Ccon表示公共常量;ListID表示日志消息ID列表;Pvar表示变量。通过分隔符将日志消息转化为单序列,然后将单序列与日志消息列表中的公共常量进行匹配,匹配完成后,解析剩余的变量。
根据系统日志向量序列的有限性,解析为向量的日志均执行一条路径,所设计的路径日志异常检测由输入层、嵌入层、隐藏层和输出层4部分组成。隐藏层是深度学习的核心部分,该层中的每个节点都是记忆模块,用公式可表示为
Ht=(χl+Pl·[Ot-1,ut])φ
(11)
其中,Ot-1表示t-1时刻的输出;ut表示t时刻的输入;Pl为线性变量。状态更新后,将当前与历史时刻的记忆叠加,可计算出深度学习在时间序列上的输出,由此得出每个日志的条件概率为
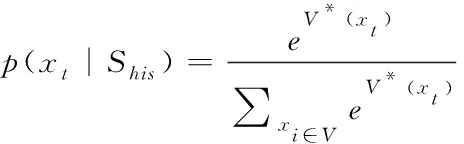
(12)
其中,xt表示当前日志状态;Shis表示历史输入序列;V*(x)表示Softmax层输出向量。模型的损失函数使用交叉函熵,通过对各个时刻损失值的叠加处理,达到模型训练的要求,损失值最小化用公式可表示为
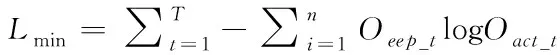
(13)
其中,Oexp _t表示期望输出;Oact_t表示实际输出。在训练过程中,选择Adam优化算法,使目标函数取得最小值。一、二阶动量用公式可表示为
(14)
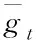
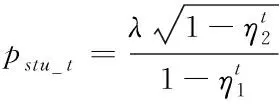
(15)
其中,t表示时间步。综上所述,Adam优化算法的更新权重参数用公式可表示为
(16)
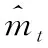
日志参数值是描述系统与软件的重要状态变量,对于没有偏离正常路径的异常,可通过参数值进行异常的判断。参数异常模型将时间戳差值视为日志中的一个参数,不同的日志生成不同的参数向量,因此可将参数异常检测转化为多变量时序问题。将数据输入隐藏层中进行模型训练,通过预测值与输出层的实际输出值之间的差异性,判断日志是否异常。
一般情况下,训练好的模型可判断出异常日志,但在数据集较大时,模型可能出现误判。因此构建在线更新模型,通过反向传播对权重参数进行实时更新,更新模型采用增量更新方法,在更新的过程中不需要对原来的模型进行训练,仅对权重参数进行更新,这大大提高了参数的更新效率。
4 异常检测模型的评估
为了验证结合日志与深度学习异常检测模型的准确性和有效性,分三部分完成异常检测试验,分别为执行路径异常的检测、参数异常的检测和在线更新模型的评估。异常检测模型中采用精确率、召回率和综合指标三个衡量标准,公式分别表示为
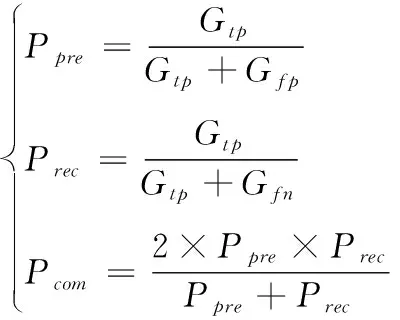
(17)
其中,Ppre表示准确率;Gtp表示日志异常,且被模型检测出异常;Gfp表示日志异常,但被模型检测出正常;Gfn表示日志正常,但被模型检测出异常。
4.1 路径异常检测
采用PCA、IM方法与本文方法进行对比。选择HDFS日志作为模型的数据集,该数据集中包含约2240万条日志,其中异常数据占3%,实验中只要有一条日志异常,则被视为异常,并且选择1%的日志的正常会话作为异常检测模型的训练集。各个异常检测方法的性能指标仿真结果如图1所示。

图1 性能指标结果
从图中可以看出,PCA方法的准确率较好,但召回率和综合性能指标均低于其他两种方法。IM方法的三个性能指标比较均衡,但均低于本文设计的方法,相对而言本文方法实验结果更好。
在训练时间和预测时间方面将本文方法与传统机器学习方法进行对比,训练时间和预测时间对比结果如表1所示。

表1 时间性能对比
从表中可以看出,两种方法准确率相似的情况下,训练和预测时间均有大幅度提升,提高了将近98.4%。根据结果比较可知,所提方法在时间性能方面明显优于机器学习,具有良好的模型学习效率。
4.2 参数异常检测
对于参数异常检测,本文使用客户端日志作为实验数据集,只要客户端执行任务,客户端与服务器间便产生通信,生成用户日志。在实验测试中通过不断的切断网络制造通信异常,来模拟实际情况。该过程得到日志1348行,日志数据集为590424行。该实验异常检测仿真结果如图2所示。
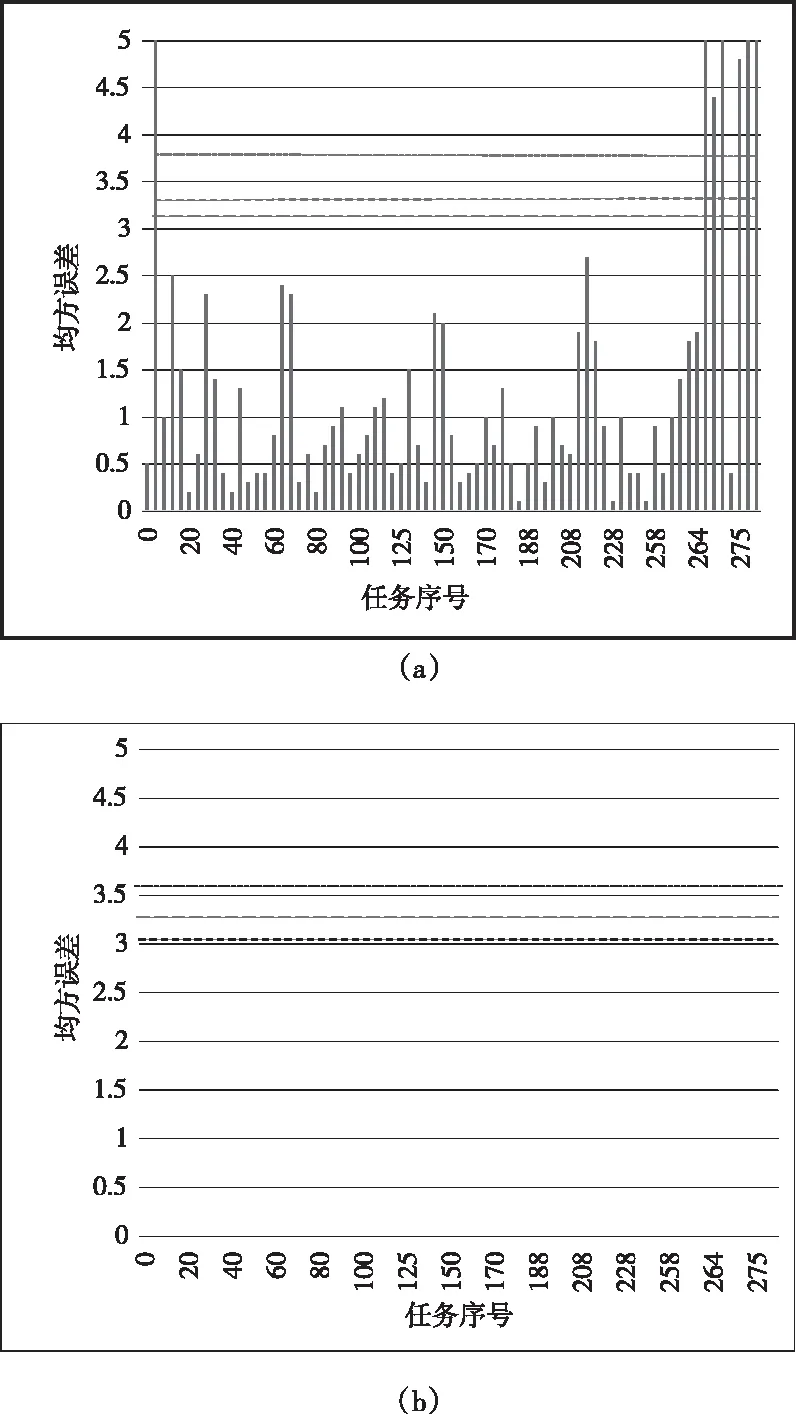
图2 参数异常检测结果
从图中可以看出,当日志均方误差超过97.30%的阈值时,参数值是异常的,且有7次任务存在参数值异常,这7次任务的原始日志对应的参数值均较大,是由网络波动延迟导致的,而图b的检测结果,可以看出该日志参数向量均是正常的,说明该日志不涉及通信问题,都是本地运行代码产生的日志,通过异常数据集ID可以方便的查找出异常日志。综上所述,本文异常检测模型可以识别出所有参数值异常的日志,准确率达到100%。
4.3 在线更新
为了防止异常路径影响检测结果,本文将在线更新前后的性能进行比较,验证在线更新模型检测结果的准确性与有效性。两种模型的对比结果如图3所示。
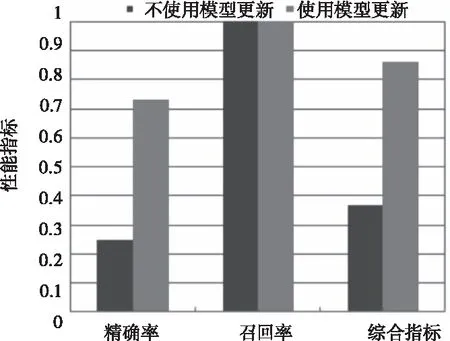
图3 在线更新模型对比结果
从图中可以看出,在不使用模型更新时,精确率和综合指标较低,分别为25%和36%。而使用在线更新模型后,准确率为71%,综合指标为86%,均有明显地提高。说明在线更新模型不仅能够解决训练集较大时出现错误检测的情况,还可以大幅度提高模型异常检测的准确率。
5 结束语
针对网络异常、数据冲突等导致的软件崩溃问题,提出基于日志与深度学习的网络软件异常检测算法。将深度学习网络用于系统日志数据中进行异常检测与性能的比较,对日志的执行路径异常、参数异常情况进行检测,并采用在线模型更新检测结果。实验结果表明,本文异常检测模型不仅可以识别路径异常和参数值异常的日志,而且三种性能指标较高,通过在线更新模型可以大幅度提高对异常错误检测的情况。
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
华人时刊(2021年13期)2021-11-27
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
心声歌刊(2020年4期)2020-09-07
数学物理学报(2019年1期)2019-03-21
思维与智慧·上半月(2018年9期)2018-09-22
中学生数理化·高一版(2018年6期)2018-07-09
