
基于改进用户画像的协同过滤推荐算法
2022-02-09 02:21姜久雷李盛庆
计算机仿真 2022年12期
凌 坤,姜久雷,李盛庆
(1. 北方民族大学计算机科学与工程学院,宁夏 银川 750021;2. 常熟理工学院计算机科学与工程学院,江苏 苏州 215500)
1 引言
随着Internet技术的发展,网络数据逐年增加[1]。为了更好地解决客户的复杂需求和海量信息之间的矛盾,诞生了个性化推荐系统[2],该系统可运用到很多领域中,例如,产品推荐[3],电影推荐[4],音乐推荐[5],社交网络推荐[6]和许多其它行业。个性化推荐技术[7]会根据客户在科学研究中的兴趣和偏好,强烈推荐客户所需的各种资源。在许多强烈推荐的技术中,协作过滤算法现在是更流行的技术。与传统的基于内容过滤的强推荐方法不同,协作过滤算法通过分析客户的兴趣和偏好,在消费者群体中寻找与目标客户相似的客户,并为不同的新客户提供相似的客户评级。对于新项目,对该最新项目的目标客户的偏好水平进行了预测分析,并根据相反方向的排名得分获得了强烈的推荐结果。
根据用户喜好将相应的作品推送给用户的算法,即协同过滤算法。实际上,它们可以分为三类:基于用户的[8,9],基于新项目的[10,11]和基于物理模型的[12]。协同过滤算法。协同过滤算法可以过滤这些复杂的叙事内容,可以解决不能完全自动化的信息过滤问题,并且具有强烈推荐新信息的功能。但该算法并不是完美的。在信息量持续扩大的情况下,它存在评分矩阵稀疏的问题[13]。
关于传统强烈推荐算法的稀缺性问题,来自世界各地的许多学者介绍了与用户画像有关的算法,并从不同角度进行了科学研究。Bertani等[14]处理了传统的强推荐算法不能合理利用用户信息的问题,并明确提出了一种基于用户资料的用户肖像强推荐算法。该算法通过学习用户的个人信息并整合对象的新颖性和时尚性来开发智能推荐。经过实验研究后发现,与其它算法相比,该算法获得的效果更为理想。姚等[15]明确提出了一种基于爱好识别和个人行为的智能推荐算法。该算法基于用户的爱好标识和历史时间访问记录来构建用户肖像,并强烈推荐用户感兴趣的电影。Hu等[16]经过研究后,以肖像特征为基础,提出相应的推荐算法。该算法使用酒店餐厅的消费者信息和房间总数来构造用户画像,以开发针对酒店房间及其酒店餐厅服务项目的智能推荐。Abri等[17]明确提出了一种基于主题风格用户画像的智能推荐实体模型。实体模型使用K-means聚类算法为用户执行聚类算法,并在每种主题样式中使用普遍的方法来考虑用户之间的相似性,提高最终用户得分排名,并解决用户的冷启动问题。黄等[18]明确提出了一种针对人性化广告的强力推荐算法。该算法根据每个用户的历史浏览记录建立用户肖像,并直观地表达用户的广告偏好。对于这些不常见的广告,请使用广告的特征和用户头像来提出强烈的建议。杨等[19]结合马尔科夫链,设计出智能推荐算法。该算法使用马尔可夫链获得用户之间的相似度,并根据用户分数开发相关信息。Ahmadian等[20]以信任为基础提出的推计算法将信任度分数与社交媒体中的信任度紧密集成在一起,并通过增加用户之间的信任度来改善强推荐功能。上述研究表明,在用户肖像协同过滤方面已经取得了一些研究成果,但仍存在数据稀缺,强推荐精度低的问题[13]。
针对目前还存在的用户评分矩阵稀疏性问题,本文提出了一种基于用户画像的协同过滤推荐算法(CPCF),该算法将用户评分矩阵转化为用户特征矩阵,采用用户画像产生的特征权重与传统相似度相结合,计算得到CPsim相似度公式,最后利用改进的权重聚合公式(DFM)得到评分矩阵,有效填充了评分矩阵中的缺失值,部分解决协同过滤算法在相似度计算阶段由于用户评分数据稀疏性引起的推荐准确率不高的问题。经在movieslens和数据集上与UBCF等推荐算法进行对比分析,实验结果表明,相比UBCF等算法平均绝对误差(MAE)降低了13%,精确率、召回率和F1-Score分别提高了11%、3%和4%。
2 传统协同过滤推荐模型
2.1 基于奇异值的相似性推荐算法
2012年Bobadilla等人[21]提出了一种SM(similarity measure based on singularity)相似度量模型。其分析用户相关性,根据分析来获得实际相似度。根据相关性把所有内容分为两部分:正相关、负相关,若相关性过低,则属于负相关,可定义为与用户喜好相反的项目,在实际操作时,尽可能减少该类项目的推荐。分析相关性时,可利用评分的方法来表示分析结果。对每个项目均进行一次评分,最高为5分,最低为1分,若分值低于3(含3分),则可将该项目归类到负相关。该过程中,得到的所有正相关项目存放到Zi集合内,负相关存放至Fi集合,则奇异值的计算公式

(1)

(2)
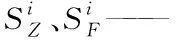
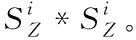
以下通过三步来计算目标用户对项目的评分。
首先利用MSD(Mean Squared Differences)进行相似度计算,见式(3)

(3)
Iu和Iu′表示用户u和用户u′的项目,rui为用户u对于项目i的评分。
对式(3)进行改进,将之前计算的奇异值加入MSD公式,得到了SM相似度量模型,见式(4)

(4)
rui为用户u对于项目i的评分,ruj为用户u对于项目j的评分。
随后结合上述表达式,设定阈值为k,若计算结果高于该值,则可将该项目设置为邻居用户。确定所有邻居用户后,分析其与目标用户间的相似性,从而得到该项目的最终分值预估值。这里利用改进的权重聚合公式进行评分预测,见式(5)

(5)
以上表达式内,各参数涵义如下:s(u,u′)——目标用户及u的相似度;rui——u对项目评分值;ru——u平均分值。
根据以上计算的最终分值,确定该项目奇异值,并融合其与评分矩阵后,计算后得到的结果即为相似度,通过这种方法可避免矩阵中存在数据稀疏的问题。但是SM算法的不足之处在于用户评分矩阵奇异值稀疏问题,导致计算结果不准确并且影响相似度结果,最终影响推荐的性能。
2.2 基于用户协同过滤推荐算法
在许多推荐算法方法中,基于用户协同过滤的强推荐算法是第一个问世。用户协同过滤算法是在1992年明确提出的,并用于电子邮件过滤设备[22]。两年后出现了有关该算法使用的相关报道。到2000年,该算法已成为业界最知名的算法。
实际上人们不管是在购物还是做其它事情,都会无意识根据自己的喜好来选择,如在商场内购物时,通常都是基于自己的喜好或结合朋友推荐来购物。而本文中提出的协同过滤算法,就是以该思想为基础而设计的,其首先采集用户信息,判断该用户的喜好,再根据该结果搜索到喜好较为相似的邻居用户,结合邻居用户评分值,来预估目标用户对该项目的评分,并根据该评估结果,给用户推荐相应的Top-N项目。将其运算过程用结构图描述出来,如下图,项目a、b、d都为用户A的喜好,而B仅喜好c,用户C则喜好a、d,由此,项目a、d都为用户A、C的喜好,表明两用户喜好较为接近,根据算法思想,可得项目b可能为用户C的喜好,因此可将该项目推荐给C,这就是该算法的基本原理。

图1 基于用户协同过滤算法原理
该算法虽然具有较高的准确率,但其也有一定的缺陷。随着用户的增加,相似度测量和得分矩阵的成本非常高,导致矩阵的稀缺性增加。另外,由于新用户在历史上的个人行为较少,因此在协作过滤强推荐算法中仍然存在无法立即对新用户进行智能推荐的问题。
针对算法中存在的该问题,人们经过不断研究后也提出了相应的解决方法。用户画像可以准确提供用户的偏好信息,根据偏好信息构建用户画像并填充稀疏矩阵,部分改进传统协同过滤算法具有的数据稀疏问题,可以提升推荐性能,所以本文重点研究基于用户画像的协同过滤推荐[23]。人像的定义[24]首先是人机交互的发起者艾伦·库珀(Alan Cooper)明确提出的。用户肖像指的是基于用户的相关特征,偏好,生活方式,个人行为和其它信息的带有标签的抽象用户实体模型。本文使用用户的性别,年龄和工作特征来构建用户肖像,并使用改进的CPsim来衡量用户的相似性。即采集用户的相关信息,如职业、性别等,利用这些信息得到对应的用户画像。
3 基于改进的用户画像协同过滤算法
3.1 生成用户特征
Bobadilla在基于奇异值的相似性模型中提出的SM模型[21],根据用户-项目评分矩阵,计算奇异值权重,从而获得对应的画像。本章基于SM模型进行用户特征权重的计算。对于不同的用户信息进行分类,并且计算每一类别相应的特征系数与特征权重,从而生成用户画像进行推荐。用户的基本信息包括性别、年龄和职业,以用户性别信息为例,将用户评分矩阵转换为用户性别矩阵,计算性别系数以及性别权重,得到用户性别矩阵,见表1。

表1 用户性别矩阵
M=男性特征
W=女性特征
其中,M、W分别为男、女性特征。如U1与I1对应的用户性别矩阵中为M,则表示对项目I1感兴趣的用户U1为男性用户。如果一个项目中的某一性别的用户越多,则该项目更加受这一性别人群的喜爱。
计算用户的特征系数,通过用户性别矩阵选取相应的性别特征集合。该系数中包含男性、女性两部分,计算公式如下:

(8)
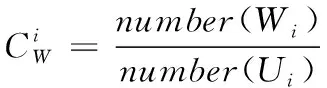
(9)

结合以上得到的计算值,获得相应的性别权重,进而确定性别特征。用户特征反应了某一性别的用户对于该项目的偏好程度,性别特征计算见式(10)(11):
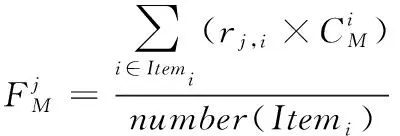
(10)

(11)

上述即为性别特征的分析方法。根据性别系数来判断权重值,从而获得对应的特征。其它的用户特征计算方法与用户性别特征计算方法相类似,年龄、职业等特征不再具体描述。
3.2 用户画像生成
2.1节以用户性别特征为例介绍了用户特征计算方法,本节将用户的信息进行明确的划分并计算信息特征,然后通过信息特征权重构建用户画像。
对于用户的年龄和职业信息来说,信息的种类比较复杂,无法直接利用公式进行计算。因此在计算前,需把职业、年龄分为两个不同的特征。比如,将用户的年龄信息按照不同的年龄阶段分为青少年、青年、中年、老年,将用户的职业信息按照不同的职业种类分为技术人员、学术人员、事务人员、经管人员及其他人员。
将用户的信息分类完成,利用之前的分类结果设立相应的特征系数及特征标签,具体标签见表2。
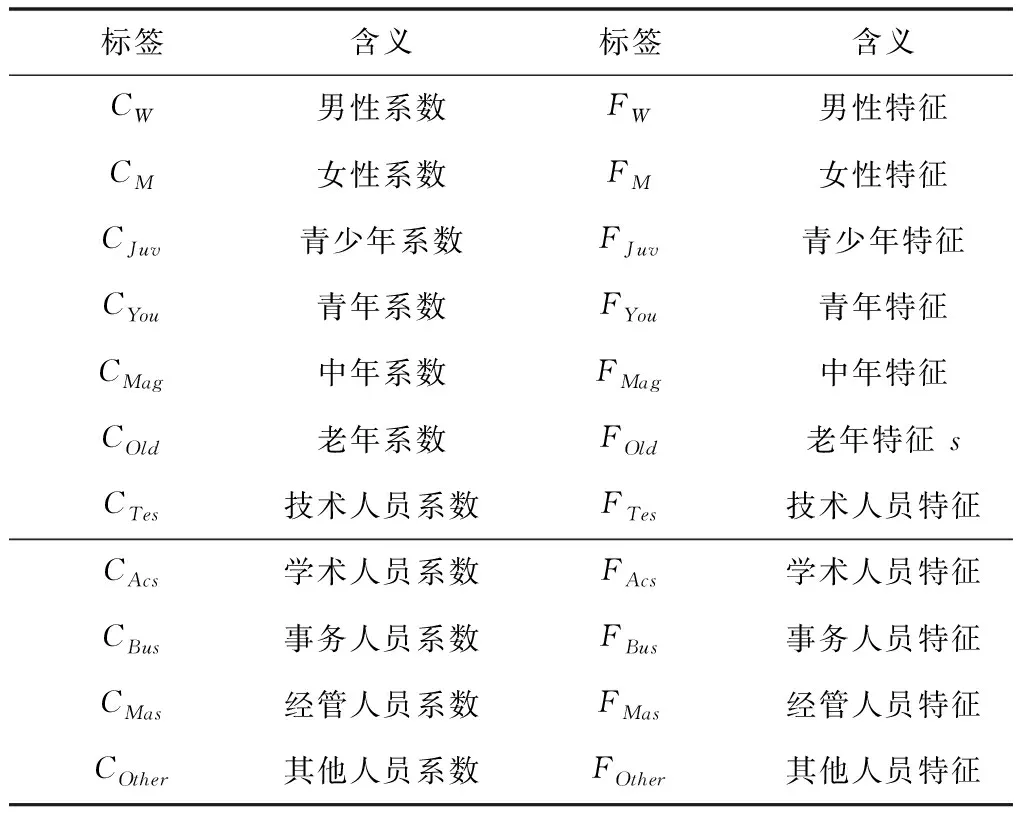
表2 用户特征含义
对用户的基本信息设立相应的标签,然后对用户的标签进行数值化,将相应的年龄段以及职业转化为数值形式。具体的年龄转化方法为:1:0-18岁,18:18-24岁,25:25-34岁,35:35-44岁,45:45-49岁,50:50-55岁,56:56岁以上。具体的职业转化方法为:0-20:未知,老师,艺术者,行政,学生,服务人员,医生,管理人员,农民,家庭主妇,青少年,律师,IT人员,退休人员,销售者,科学家,个体户,工程师,技术人员,待业人员,作家。其特征标签如表3所示。

表3 特征标签
下面通过分类产生新的用户信息表,将用户项目评分矩阵转换为项目特征矩阵,具体转换方法如式(12)所示。根据得到的矩阵,结合评分矩阵,即可获得对应的特征矩阵,转换公式如下
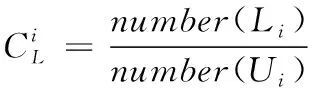
(12)
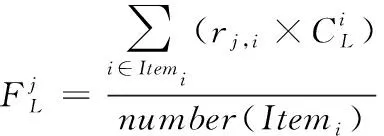
(13)

4 CPCF推荐算法
为解决传统推荐算法用户评分矩阵稀疏、推荐精度不足、无法有效利用用户信息问题,本文采用改进的权重聚合方法(DFM)进行评分,提出基于用户画像的协同过滤推荐算法,。本文算法以用户-特征矩阵作为原始数据,把整个推荐过程分为改进用户项目评分矩阵、改进的相似性计算方法和评分并产生推荐结果三部分。
4.1 改进用户-项目评分矩阵
根据上文中提出的矩阵转换公式,采集到用户基本信息后,利用生成的矩阵融合特征,即可获得对应的特征矩阵,这就是评分矩阵的优化方法。用户特征矩阵即为用户画像,通过用户画像中每一个特征对应的权重值可以观察出该项目受哪些用户的喜爱。
4.2 改进的相似性计算方法
通常情况下,可利用余弦相似度、Pearson相关系数两种方法,对用户相似度展开计算。1994年,Resnick明确提出应用Pearson相关系数[25](PCC)来测量用户之间的相似度,请参见式(14)

(14)
相关参数含义如下:Iu——u进行过评分的全部项目集合;i——评分项目;ru——u的评分均值。
余弦相似度[26],即判断空间中任意2向量角度的余弦值,根据该值来分析两者差异。若两者计算得到的余弦值与1相差越小,表明两向量存在的差异非常小,相似度极大。将其运用到推荐算法内,可将向量设置为用户针对该项目给出的评分值,以此来计算相似度
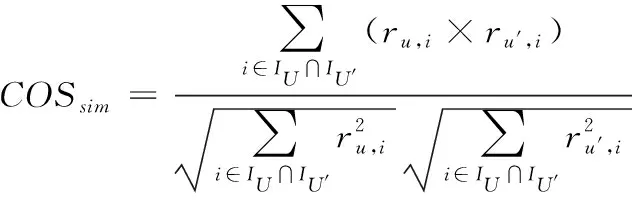
(15)
下面分三步得到CPsim相似度公式。
首先将用户画像融入皮尔逊相关系数公式得到改进的皮尔逊相似度(PCCstrsim),见式(16)所示。在该公式中加入画像权重后,得到的表达式为(17),即余弦相似度。将完善后的两个相似度结合,即可获得CPsim相似度,即表达式(18)。这里将用户画像融入皮尔逊以及余弦相似度公式,可以利用用户的特征信息代替传统相似度的评分,通过用户准确的画像信息获取相似度可以更加准确的观察用户之间的相似程度。最后将两种改进的相似度公式进行加权,从两种不同角度统一去判定用户间的相似程度,有效提高了推荐的准确性。

(16)
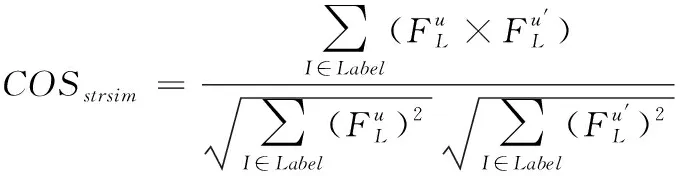
(17)
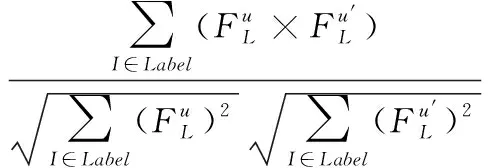
(18)
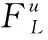
4.3 评分并进行推荐
结合实际情况,利用实验的方法寻找最实用的评分法,本次设计中对比WS、DFM两种算法下获得的MAE值来选择相应的评分法,最终确定使用DFM法来获得相应的评分值。结合表达式(16),对相似度展开计算,获得邻居用户。随后通过下表达式来预估用户对该项目的评分值

(19)
以上内容介绍了CPCF推荐的三个主要步骤,具体的推荐流程如图2所示。

图2 CPCF推荐算法流程
首先根据数据集提供的用户评分矩阵,利用性别系数、职业系数以及年龄系数计算公式计算每一个用户的特征系数,从而获得项目特征矩阵。获得特征矩阵后,即可获得该用户的画像。下面将用户画像融入PCC相似度和COS相似度,获得改进的PCCstrsim相似度以及COSstrsim相似度,并对两种相似度加权求和生成CPsim相似度。其次利用CPsim相似度和改进的权重聚合评分公式获取用户评分。以降序的方式,将得到的所有分值进行排列,并把排列在前k的用户提取出来。
算法描述:

Algorithm 1 Recommendation based on user profile INPUT: Train_User_Item_Rating_MatrixTest_User_Item_Rating_MatrixUser_Profile_Matrix,Label_setOUTPUT: Scoring_Matrix1) for every user in Train_User_Profile_Matrix:2) for every label in Label_set:3) Use improved similarity formula4) Generate user similarity_matrix5) for every user in Test_User_Item_Rating_Matrix:6) for every item in Test_User_Item_Rating_Matrix:7) find the nearest neighbor8) use dfm score prediction formula 9) generate user_item score matrix Return Scoring_Matrix
5 实验结果分析
本次实验中获得的所有数据通过MoviesLens-1M进行收集。在这两个数据集通过与UBCF等算法进行对比实验分析,验证所提推荐算法的性能。在Windows10系统、8G内存、Intel Core i5-4570@2.20GHz处理器条件下完成所有操作。将F1-Score、召回率、MAE、精确率设置为评价指标。
5.1 数据集
本文中所进行的实验通过MoviesLens-1M、Book-Crossing数据集完成,前者中包含评分、电影、用户三部分,而实验中所研究到的职业、年龄、性别等均属于用户信息。而评分文件内,评分次数达到一百万次,总用户数为6040,电影数量3952,表明该文件中,每位用户评分过的电影最少有20部。而Book-Crossing数据集由Cai-Nicolas Ziegler在经过4周的爬取,在人类系统 首席技术官Ron Hornbaker的允许下,从Book-Crossing社区中收集。其中包含了278858个用户对271379个项目的1149780次评分,其中包括用户信息、书目信息和评分信息。
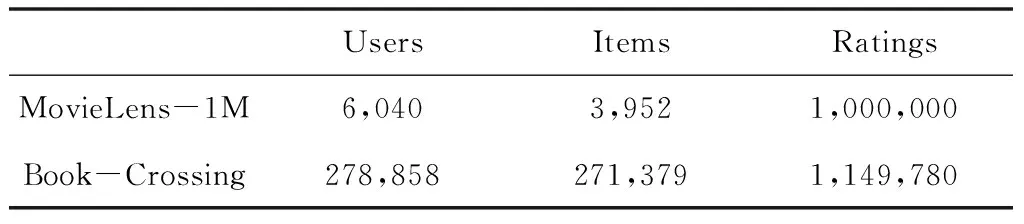
表4 数据集
5.2 评价指标
为了更好地考虑所提出方法的特性,本文将平均绝对误差(MAE),精度,均方误差和F1-Score用作评估指标值。MAE指标值表示预测分析与特定值之间的平均偏差。若获得的该指标值相对较小,表明该算法推荐的精准率越高。若{ac1,ac2,…,acn}表示为真实评分集合,{pr1,pr2,…,prn}表示为预估分值,则可利用以下表达式来计算MAE
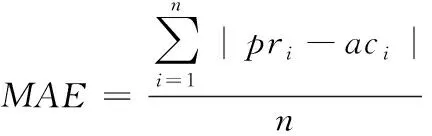
(20)
在所有推荐的项目中,用户实际喜欢的项目占总推荐项目的比例,即为精确率,因此可根据该指标值的大小,来判断系统给出的推荐是否精确。而推荐准确的项目数、测试集内所有项目的比值,即为召回率,根据召回率大小可判断系统所使用的算法是否合适,从而判断其推荐精度。通常在计算这两个指标的时候,首先需要根据评分值,把测试集内的项目划分为正相关、负相关,分值较高的部分,为正相关;而评分后项目集合内,也需要划分为推荐、不推荐项目。精确率是针对预测结果而言,表示为被推荐的相关项目数量与被推荐的项目总数之比,具体见式(21)所示

(21)
与精确率不同,召回率针对的是原来的样本,表示为被推荐的相关项目数量与所有相关项目的总数量,具体见式(22)所示
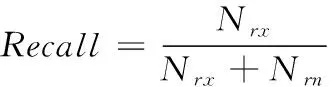
(22)
其中,Nrx——相关项目中,被推荐数;Nbx——不相关项目中,被推荐数;Nrn——相关项目中,未推荐数。
利用算法设计推荐系统时,为提高推荐精度,不仅要分析其精确率,还需要对召回率展开计算,通常可根据两者加权调和后得到的均值来结合分析,即计算F1-Score值。当得到的值较高时,表明该系统推荐的项目较为准确。其计算公式为
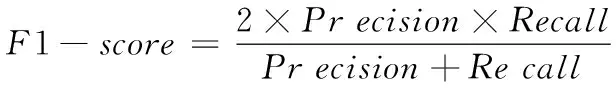
(23)
5.3 实验结果分析
将操作中采集到的全部数据划分为5类,其中测试集占比20%,剩余为训练集。为了增强结果的稳定性,本文使用不同的划分进行多轮交叉验证,并把每次的结果取平均值,本文实验进行了五重交叉验证。
本文选取邻居数为5到195,依次递增10,分别对UBCF算法、SM算法以及本文所提算法的MAE进行比较,比较结果如图3所示。

图3 三种算法在不同k值的MAE
图3中对比了两个数据集中三种算法的MAE值,从图中MAE的变化趋势可以看出,3种算法的MAE都会随着邻居数量的变化而变化。当邻居数量选取较少时,由于只参考了少数人的意见,导致预测评分受个人因素影响较大,CPCF和SM算法中不能给出准确的预测,所以MAE偏高,但是UPCF算法基于用户进行评分,所以当用户数较少时也可以给出准确的预测,MAE低于另两个算法;当邻居数量逐渐增多时,由于融入更多用户的参考意见,会有效的改进预测效果,导致MAE有所降低,并且随着邻居数量达到峰值,MAE值达到最低。但是由于MoviesLens数据集的数据相较于Book-Crossing数据更加稀疏,导致用户对于同一项目的评分过多,真实评分的数量降低,所以Book-Crossing上的MAE值要低于MoviesLens。从以上分析来看,本文提出的CPCF算法的MAE值较UBCF等算法最多降低了13%,在推荐性能方面要优于其它两种算法。
对比不同算法下获得的召回率、准确率,结果如下图,前者为横轴,图中的点为推荐数值。推荐数值越高,表明该算法下获得的两指标值越大。从图中可以看出,两个数据集上CPCF均在SM的上方,而SM在UBCF的上方,综合看来,CPCF算法的准确率与召回率较其它两种算法依次提高了11%和3%,推荐准确性有所提升。
精确率与召回率在某种程度上是相互矛盾的,如果精确率很高,那么相应的召回率就会很低。两种评价指标对于算法性能的评价还有所弊端,所以这里利用F1-score综合两种评价指标的优缺点,更全面的评价三种算法的性能。对不同算法下计算的F1-score值展开对比分析。

图4 三种算法在不同k值的准确率-召回率

图5 三种算法在不同k值的F1-Score
从图5可以看出,在两个数据集上随着k值的增加,三种算法的F1-score均逐渐上升,k为9时F1-score达到最高点。两个数据集的CPCF与SM的F1-score差异很小,但是都要优于UBCF算法,说明随着邻居数量的增加,UBCF算法整体性能较差。但是MoviesLens数据集更加稀疏,所以Book-Crossing的F1-score要优于MoviesLens。Book-Crossing中CPCF性能最优,较UBCF等算法提高了4%,表明该算法在整体性能方面要优于其它两种算法。
6 结语
本文针对传统协同过滤推荐算法面对稀疏数据计算相似度不准确,导致推荐效果不佳的问题,利用用户的年龄、性别、职业三种基本信息,将用户特征进行数值化,计算用户特征系数。根据相应的公式计算特征系数,进而获得相应的用户特征,该特征即可作为用户画像输入到系统内。然后将用户画像融入改进的皮尔逊相关系数和改进的余弦相似度中,进行线性加权得到CPsim相似度。最终利用改进的权重聚合公式(DFM)进行评分得到推荐结果。
在两个数据集上的实验表明,该算法较UBCF等算法平均绝对误差降低13%,精确率提高11%、召回率和F1-score分别提高了3%和4%,有效改善了推荐性能。在现实生活中用户特征会随时间的推移有所变化,导致推荐结果受到一定影响,因此在后续工作中考虑将时间特征信息中的数据融入CPCF算法,进一步提高推荐效果。除此之外本文构建信息标签时只考虑了用户性别、年龄和职业信息,未考虑其它重要特征,今后的研究中可以考虑加入家庭住址、兴趣爱好、学历以及有无配偶等信息,丰富用户画像,从而改善推荐性能。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
小哥白尼(神奇星球)(2022年3期)2022-06-06
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
当代陕西(2019年10期)2019-06-03
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
