
融合LDA与注意力的网络信息个性化推荐方法
2022-02-09 02:05张永宾赵金楼
计算机仿真 2022年12期
张永宾,赵金楼
(1. 哈尔滨工程大学经济管理学院,黑龙江 哈尔滨 150001;2. 黑龙江科技大学管理学院,黑龙江 哈尔滨 150022)
1 引言
随着各类资讯、短视频,以及购物平台的大量涌现,信息的传递和商品的推广变得越来越便利。平台和用户之间相互纠缠,为用户提供便捷生活的同时,平台和商家也能获得更多利益。为了更好的达到用户与平台利益最大化,信息挖掘与推荐成为至关重要的环节[1]。根据用户行为推测出其兴趣方向,并为其提供个性化推荐。能够促进平台的精准服务,提高用户的搜索效率。对于当前的各类网络平台而言,个性化推荐都是具有极大商业价值的技术板块。
为了反映用户的偏好,大部分推荐系统采用标签的形式进行资源整合。可以通过用户选择或者系统自动归纳的方法来为用户分配标签,而系统分配标签可以依据图或者关键词[2]。其中用户选择很容易影响体验感,并且容易出现标签稀疏与可信度较低等问题。系统分配标签则面临非结构化数据的处理问题。尤其是对主题和情感的挖掘处理,目前常见的分析方法有交叉熵[3]、TF-IDF[4]、PLSA[5]和LDA[6]等。LDA作为主题构建模型,能够采取无监督的方法和概率的形式对主题进行聚类。LDA不仅可以实现语义分析,还可以完成隐含主题的提取,以及文档间联系。但是,采取LDA生成模型的时候,容易产生语义缺失和兴趣影响,从而降低标签的准确性。在此基础上,文本标签自身也受多重因素影响,不同因素对不同标签的影响程度也存在差异,且这种影响权重难以确定。为此,一些推荐算法采取注意力模型来解决该问题。如文献[7]基于模型和训练得到标签之后,引入注意力来计算文本的特征,该方法的动态效果较好。同样,文献[8]也在网络学习的基础上融合了注意力机制,通过加权方式来描述对不同特征的关注度。
结合LDA与注意力机制的优点和特性,本文将其采取融合处理。利用LDA进行文档标签的提取,引入HowNet的分层机制来计算相似度,从而避免采用距离方式求解相似度对精度的影响。构建注意力模型,并进行注意力注入。通过实体与语义两部分的注入,有效挖掘隐藏兴趣主题与实体的对应关系。
2 LDA模型
LDA为文档构建模型,训练数据集文本采取one-hot编码后,作为LDA输入,经过模型训练后得到数据集对应的主题与词分布情况。LDA模型的处理过程描述如图1所示。其中,DT表示参与训练的数据集;di表示数据i;a表示训练数据的输入参数;θt表示文档t对应主题分布;nti表示单词的主题编号;wti表示主题分布;N表示主题数量;φn表示主题n的分布;b表示主题分布参数。
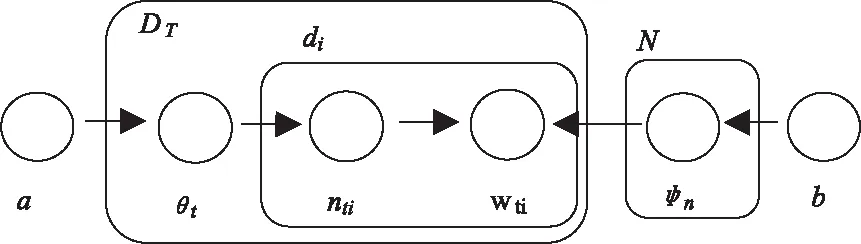
图1 LDA模型的处理过程
利用LDA模型,可以归纳出文档中主题与词的分布情况。但是,在这种框架下的主题单词选取一般具有局限性,无法保证单词选取的完整性,进而影响推荐效果。于是,这里引入HowNet来处理单词语义,增强算法的语义理解能力。HowNet库能够实现对中文词汇的处理,通过分层机制,将单词分解成以义原为最小单位来描述,这正好与LDA的“主题—文档—词”相对应。与其它词典相比,它能够不通过距离计算得到语义间的相似性。对于任意义原xi,其信息量的求解方式为
(1)
其中,n(xi)为xi的子节点数目;N为所有义原数目。根据最大信息量,义原xi与xj间的相似程度表示如下
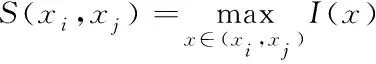
(2)
由于底层义原与上层概念之间为多对一关系,概念Ci与Cj分别为Ci={xi1,xi2,…,xim}、Cj={xj1,xj2,…,xjk}。于是,概念Ci与Cj相似程度的计算公式表示如下
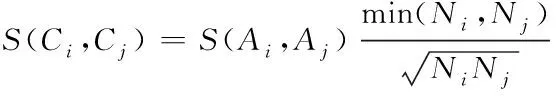
(3)
其中,S(Ai,Aj)代表Ci与Cj集合相似性;Ni与Nj依次代表Ci与Cj的记录个数。通过引入Ni与Nj相关项,可以对S(Ai,Aj)的计算过程进行偏差控制。
单词由多个概念描述构成,依据概念相似性,可以进一步求解得到单词的相似性。将单词wi与wj分别表示为wi={Ci1,Ci2,…,Cip}、wj={Cj1,Cj2,…,Cjq},那么wi与wj相似程度公式如下

(4)
利用HowNet分层结构,可以将相似单词采取分层做细粒度分析,从而改善单词与主题的映射精度。基于LDA的整体训练流程描述为:
步骤1:得到文档t的主题分布
θt=Dirichlet(a),t∈[1,DT]
(5)
步骤2:得到主题词分布
φn=Dirichlet(b),t∈[1,N]
(6)
步骤3:利用θt确定nti所属主题编码与词分布

(7)
步骤4:计算相似度。通过分层机制,结合义原与概念,计算得到任意两个单词wi与wj之间的匹配程度。
3 注意力设计
3.1 注意力模型
注意力机制能够更好的为关注事务服务,针对重点信息进行高效处理。此外,因为网络学习无法较好的体现各特征词的重要性,所以本文将注意力嵌入到网络层中,通过权值的改变,优化推荐内容的精确程度。
对于训练输入的文本,采取BOW编码,经过LDA处理得到每一个文本对应的主题分布情况。文本中的特征单词分布可以表示为
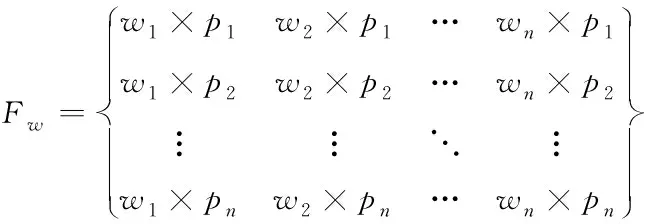
(8)
其中,[w1,w2,…,wn]是对应主题单词分布;[p1,p2,…,pn]是分布概率;n为主题单词数量。把文本与主题一起递交给HowNet,通过训练得到词向量。HowNet能够最大程度获取文本中的主题特征,并将词向量[w1,w2,…,wn]提交至网络学习。学习网络会利用传输层提取出上下文内容,并利用隐层求解出全部隐态结果,最终得到隐态输出为
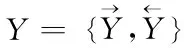
(9)
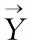
由于存在词间依赖,网络训练过程中需要考虑词间关联,于是引入Softmax层,在该层采取特性分类
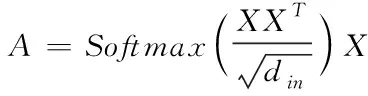
(10)
其中,X∈R为输入数据;din表示输入数据的维度。在Softmax层中,会取最大概率进行输出。
3.2 注意力注入
在推荐算法进行预测时,为了防止出现隐藏兴趣主题无法找到实体情况的发生,在注意力层中将其分为实体与语义两部分处理。其中,先启动实体部分,完成重要语义实体注入。再启动语义部分,根据传输路径的关注度,注入合理的相近实体。
由用户和实体间的关系,可以构建关于它们的图G={(u,e)|u,e∈U∪E},其中,U与E分别表示用户与实体集合。利用E中各元素的连接性,可以得到它们的关联路径
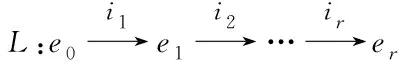
(11)
其中,l表示阶数;r表示实体关系。由u、e和r构成的三元组(u,r,e),确定评价函数如下
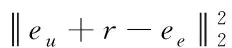
(12)
其中,eu、ee分别是用户和实体的映射,且eu+r和ee近似相等。评价函数Er(u,e)可以帮助更好的训练嵌入关系,但是,想要判断(u,r,e)是否合理,需要进行损失判断,方式如下
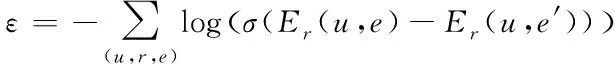
(13)
其中,σ(·)为sigmoid函数。利用(u,r,e)中实体导致的差异来实现无效元组的更新,增强e元素的信息强度。针对传输路径l而言,其上的实体注意力描述如下
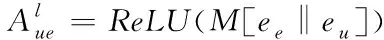
(14)
M为注意力向量;ReLU为激活方程。考虑到在网络学习过程中,任意传输路径上实体和用户的相互作用均具有非对称特征,在计算得到实体和用户关系后,紧接着采取归一操作。经过Softmax处理后,可以得到实体注意力加权因子如下
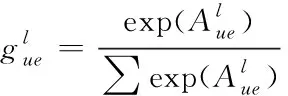
(15)

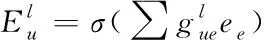
(16)

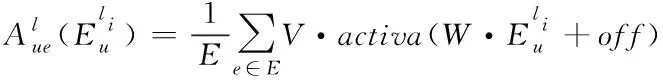
(17)
式中的E为实体集合;V、W依次为语义注意力和加权变量;activa(·)为非线性处理;off为偏移量。通过对V的非线性操作,突出重点语义的实体,对应的注意力加权因子表示如下
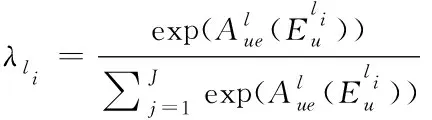
(18)
根据加权因子的大小,确定传输路径的重要程度,进而得到相似实体的关联程度。基于前述分析,最终的注入方程表示如下
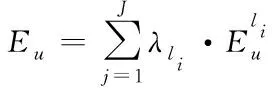
(19)
4 仿真与结果分析
4.1 实验数据集与参数设置
仿真选择Amazon开放的TH和SO数据集。其中,TH的用户数量为16638,项目数量为10217,用户与商品的评论文本中词量均值分别为903和1471。SO的用户数量为35598,项目数量为18357,用户与商品的评论文本中词量均值分别为738和1431。
实验过程中,设定LDA模型中主题数量N∈[0,100],Dirichlet的超参数a=N/50,b=0.04,词向量维数为100,训练次数为100。注意力模型中,参数V的维数是96,注入维数是54,传输路径的多跳限定为3。
4.2 评价指标
实验在衡量网络信息个性化推荐性能的时候,采取MSE、HR和NDCG三个指标。MSE代表推荐信息的均方差,利用估计量与实际量的差值累计得到,公式描述如下

(20)
其中,f′i表示估计量;fi表示实际量;n表示样本个数。MSE结果越小,意味着推荐结果的误差越小,反映推荐精度越高。
HR代表推荐的命中率,通过推荐结果内样本与全部测试样本的比值求解得到,公式描述如下

(21)
其中,Numberhit表示推荐结果内的样本数量;Numbertest表示测试样本的全部数量。HR结果越大,意味着推荐信息越满足用户意愿。
NDCG代表折损积累,该指标是通过推荐结果的折损值计算而来。公式描述如下

(22)
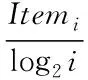
4.3 实验结果分析
对比模型选择文献[7]和文献[8],首先在TH和SO两个数据集下,分别测试得到三个算法推荐结果的均方差,如图2所示。
根据图2结果,本文算法在TH和SO两个数据集的MSE分别为0.934和0.982,都保持在1以内,相较对比算法,均方差得到明显降低,而且对于不同数据集,MSE维持在相似水平,表明算法对于不同数据集具有良好的适用性和泛化能力。

图2 MSE结果比较
为了比较各算法在不同推荐数量情况下的性能,将两个数据集合并,同时调整推荐数量分别为5、10、15,得到各自对应的HR和NDCG,结果比较如图3和图4。
根据HR结果得出,在推荐数量增加时,各算法的命中率都在提高,这种趋势是由于推荐数量的增加消除了模糊推荐的不准确性。所以在推荐数量为5的时候,各算法的命中率差异较大,本文算法较文献[7]和文献[8]依次高出1.6%和4.5%;在推荐数量为15的时候,各算法的命中率差异则相对变小,本文算法较文献[7]和文献[8]依次高出1.3%和1.1%。从整体来看,本文算法的HR值均好于其它算法,表明在推荐的准确度上较其它方法更具优势。

图3 HR结果比较
根据NDCG结果,在推荐数量增加时,各算法的折损增益均在增加,和HR具有相同规律。在推荐数量为5的时候,本文算法较文献[7]和文献[8]依次高出5.0%和4.2%;在推荐数量为10的时候,本文算法较文献[7]和文献[8]依次高出4.5%和3.8%;在推荐数量为15的时候,本文算法较文献[7]和文献[8]依次高出3.3%和3.4%。
通过三项指标结果,证明了本文算法在网络信息高维特征处理方面的优越性,以及良好的泛化性能,推荐的个性化信息能够高度符合用户需求。

图4 NDCG结果比较
5 结束语
考虑到标签稀疏与可信度低,以及网络非结构化数据处理等问题,采取LDA模型进行标签挖掘。同时引入HowNet,以义原为单位比较相似度。考虑到特征词的重要程度差异,采用注意力模型,并将注意力注入到网络层中,根据实体与语义来注入合理的相近实体。通过仿真实验,得到本文算法在TH和SO两个数据集的MSE分别为0.934和0.982,具有良好的均方偏差;此外,不管在何种推荐数量的情况下,HR和NDCG指标均优于对比方法,说明具有良好的推荐精度和泛化性能,个性化推荐结果更加合理准确。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
传媒评论(2017年3期)2017-06-13
中国修辞(2017年0期)2017-01-31
第二课堂(课外活动版)(2016年2期)2016-10-21
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
Coco薇(2015年11期)2015-11-09
