
改进ISA关系的网络本体语义相似度仿真
2022-02-09 02:21高慧星
计算机仿真 2022年12期
高慧星,杨 蕊
(燕山大学里仁学院,河北 秦皇岛 066000)
1 引言
相似度主要是用于衡量文本中某个词语能够用其它词语替换的程度。语义相似度这一概念具有较强的主观性,不同语义之间存在的相似度均存在不同程度的差异[1]。语义之间的相似度通常较为复杂,仅用数值进行衡量的难度较高[2]。因此,相关学者对语义相似度计算问题进行了深入探索,并得出了一系列方法。
翟社平[3]等人首先在句长、词序、词形等方面提取句子的特征,并通过层次分析法对权重进行分配,在此基础上对结构相似度进行计算,根据计算结果获取语义相似度。该方法没有分析本体之间在网络中的ISA关系,计算结果的皮尔逊相关系数较低,导致方法存在计算精度低的问题。关晓菡[4]等人建立句子交互序列,在Siamese模型输入侧改善交互问题,并对交互序列进行卷积处理,利用处理后的交互序列提取句子特征,在更新后的Siamese模型中输入提取的特征,实现语义相似度的计算。该方法无法获取本体的ISA关系,导致计算结果的斯皮尔曼相关系数较低,计算精度差。朱文跃[5]等人通过结构相似度、时间要素、时间名称、集合相似度等因素计算语义相似度,该方法计算语义相似度所用的时间较长,存在计算效率低的问题。
为了解决上述方法中存在的问题,提出基于ISA关系的网络本体语义相似度计算方法。
2 ISA关系
基于ISA关系的网络本体语义相似度计算方法的ISA关系提取过程为:对无关页面进行预处理,用分类问题代替ISA关系生成问题,经过预处理后,提取web页面的特征构成训练集,在分类模型中输入训练集,通过权重学习和评分函数在模型学习过程中对分类模型进行训练,通过模型获得ISA关系。提取网络链接结构特征、实体-标签依赖特征和标签特征,根据提取的特征建立ISA关系分类模型[6]。
通过下述流程获取ISA关系:
1)标签长度:当用户自定义标签过长时,表述过于具体,当用户自定义标签过短时,表述过于笼统,将标签长度定义为f1(c)=L(c),其中,函数L(c)的主要作用是对标签c对应的长度进行计算。
2)标签中心词POS标注:有效标签指的是网络中存在的名词或短语等,通过自然语言处理技术(词性标注方法和分词标注方法[7]等)获取标识标签c和中心词在网络中的词性。将其作为网络特征f2(c),常用的方法包括词性标注和分词标注等:
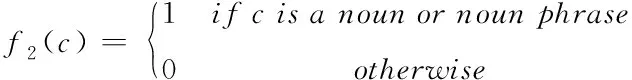
(1)
3)概念性词语:“政治”、“经济”等概念性词语不能对实体类别进行区分,因此基于ISA关系的网络本体语义相似度计算方法选取的词典为概念性词语,对标签c和标签c中心词是否存在于词典中进行判断,并将其作为网络特征

(2)
4)中文语言模式f4(c):
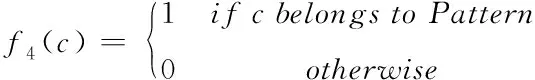
(3)
5)实体-标签的公共序列
可能重复出现在中文标签和实体中的公共序列即为实体-标签的公共序列,将公共序列是否出现在网络中作为特征,用f5描述。
6)公共序列-中心词匹配
描述的是在公共序列中重复出现的标签中心词,用f6进行描述。
7)标签混杂度
设置实体集合Ec,由网络页面构成,设purity代表的是标签c对应的混杂度,当实体在集合Ec中越相似时,属于标签混杂度purity的概率越低,属于有效标签的概率越高。标签混杂度purity的计算公式如下

(4)
式中,L代表的是实体标签集合的命名,El、Ec分别代表的是标记为l和c的实体集合。
设置阈值τ,当标签混杂度purity(c)大于阈值τ时,判定其为有效标签特征,用f7描述。
8)标签局部主体相关性
相关页面在网络中的关联通过页面跳转实现,属于主题相关,在网络中存在关联的页面形成了关联网络结构。
页面标题即为节点,也被称为候选实体e,所有实体e在网络中都存在着对应的用户自定义标签,可用标签集合C表示。网络结构中的边存在两种,分别是出边OutLink和入边InLink,其表达式分别如下

(5)
式中,lc、le均代表的是网络结构的边;集合Lin(e)由入边构成,属于入边集,集合Lout(e)由出边构成,属于出边集。上式描述的是实体e的两种边与c重合时构成的链接集合,标签主题相关的概率随着重合频次的升高而增大,通过上述分析,将重合频次作为局部特征,利用下式进行计算
f8(e,c,L(t))=|{InLinke,c|Lin(e)∈L(t)}|
+|{outLinke,c|Lout(e)∈L(t)}|
(6)
9)标签全局主题相关性


(7)
式中,LinkGraphin、LinkGraphout分别代表的是入边和出边在关联网络中构成的集合,结合上述公式计算结果,建立全局特征f9(c,LinkGraph)
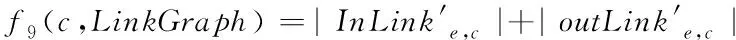
(8)
10)入边、出边主题权重
在出边和入边上对重合频次进行归一化处理[8],在主题相关性中分析该标签的贡献程度,并将其作为主题权重f10、f11
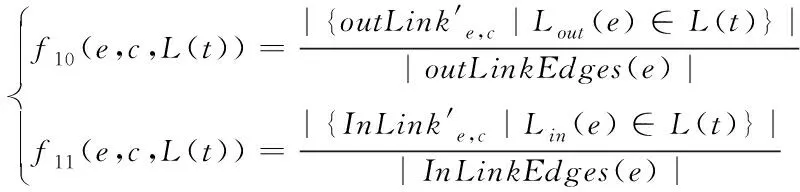
(9)
式中,outLinkEdges、InLinkEdges分别代表的是e的全部出边和全部入边。
11)实体主题相关性
实体e与网络中其它节点之间的关联程度随着实体e在关联网络LinkGraph中存在的边数的增多而增强,实体主题相关性f12(e,LinkGraph)可通过下式计算得到
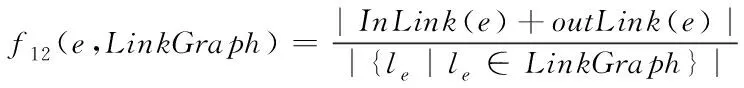
(10)
为了获取网络本体之间的ISA关系,对上述获取的特征进行划分,分为F1
f(e,c,L(t))=w1F1(c)+w2F2(e,c)+
w3F3(e,c,L(t))+w0
(11)
当评分函数的值为负数时,表明不存在ISA关系,当评分函数的值为正数时,表明存在ISA关系。式中,w1、w2、w3分别代表的是在划分ISA关系过程中F1、F2、F3特征集合产生的作用,w0代表的是特征权重。
3 网络本体语义相似度计算
根据上述过程获得网络本体之间存在的ISA关系,设IF代表的是信息量因子,D代表的是距离因子,P代表的是属性因子,L代表的是层次因子,基于ISA关系的网络本体语义相似度计算方法根据本体之间的ISA关系对上述因子进行线性加权组合,进而计算网络本体语义相似度Similarity(c1,c2)

(12)
式中,参数α、β、γ、θ的总和为1。
3.1 距离因子
语义距离在网络本体语义相似度计算过程中产生的影响较大,语义距离直接影响着两个概念之间的语义差异程度,概念之间的相似度随着语义距离的增大而降低[9,10]。设置距离因子D,其主要作用是衡量语义距离在计算过程中对相似度结果产生的影响。
设Distance(c1,c2)代表的是概念c1、c2之间存在的语义距离,其计算公式如下
Distance(c1,c2)=edge_count(p,c1)+edge_count(p,c2)
(13)
式中,∀p∈LCA(c1,c2),LCA(j,k)={h,n},j、k代表的是概念节点,h、n代表的是祖先节点;edge_count(p,c)代表的是最短路径长度。
3.2 层次因子
用Levelparent(c1,c2)描述概念之间在网络中对应的层次因子。根据本体图的特性可知,在网络中概念之间存在多个共同祖先的可能性较大,在本体图中计算共同祖先所处层次对应的最小值Levelparent(c1,c2)=min{Level(a)},其中a∈LCA(c1,c2)。
本体在网络中的具体化程度可通过本体图的深度Depth进行描述,其计算公式如下
Depth=max{MaxSimplePathLen(thing,c)}+1
(14)
在归一化处理层次因子之前,需要用熵形式表示层次因子,如式(15)所示

(15)
3.3 属性因子
概念之间的相似性与共同属性之间呈正相关,设置属性因子P,其主要作用是描述共同属性在语义相似度计算过程中产生的影响[11,12]。
设P(c1,c2)代表的是在所有属性中概念c1、c2共同属性的比例,其计算公式如下

(16)
式中,property代表的是属性集合。
3.4 信息量因子
用IF(c1,c2)描述概念c1、c2在网络中的信息量因子,其实质是网络中信息量的大小,可通过下式计算得到

(17)
式中,IC(a)、IC(b)均代表的是信息量。参数ICDishIn(LCA(a,b))的计算过程如下
1)获取ICDishIn(LCA(a,b))在网络结构中的共同祖先;
2)计算共同祖先parent在网络结构中到概念c1和概念c2的独立路径数量,用m1和m2分别描述其对应的独立路径数量,祖先parent对应的路径特征feature可通过数量m1和m2计算得到feature=|m1-m2|,此时获得多个特征featurei和多个祖先parenti构成的二元组
3)对上述获取的featurei大小进行对比,删除信息量小的featurei,保留信息量大的featurei,设置集合c(parent),由信息量大的祖先节点parent构成。
4)ICDishIn(LCA(a,b))=avg{IC(parenti)},parenti∈c(parent)。
4 实验与分析
为了验证基于ISA关系的网络本体语义相似度计算方法的整体有效性,需要对基于ISA关系的网络本体语义相似度计算方法进行测试。
分别采用基于ISA关系的网络本体语义相似度计算方法(方法1)、多特征融合的句子语义相似度计算方法(方法2)和基于双向字交互卷积网络的语义相似度计算方法(方法3)进行如下测试:
1)皮尔逊相关系数PPC的主要作用是对数据间的线性相关性进行衡量,其值越高,表明方法的语义相似度计算越精准,PPC可通过下式计算得到

(18)
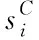
方法1、方法2和方法3的皮尔逊相关系数PPC如图1所示。

图1 皮尔逊相关系数测试结果
对图1中的数据进行分析可知,方法1的皮尔逊相关系数随着数据量的增多而降低,但降低幅度较小,且当数据量超过200个后,方法1的皮尔逊相关系数基本保持不变;方法2和方法3的皮尔逊相关系数随着数据量的增大而降低,与其它两种方法相比,方法2的下降趋势较大,经对比发现在数据量相同时,方法1的皮尔逊相关系数均高于方法2和方法3的皮尔逊相关系数,验证了方法1的整体有效性。
2)斯皮尔曼相关系数SRCC的主要作用是对数据间在网络中的排序相关性进行衡量,其值越高,表明相似度计算结果越精准,SRCC可通过下式计算得到
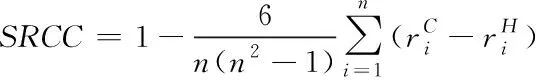
(19)
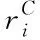
方法1、方法2和方法3的斯皮尔曼相关系数SRCC测试结果如图2所示。
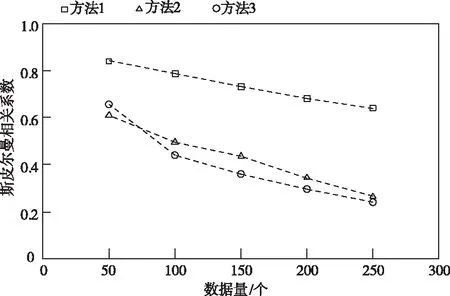
图2 斯皮尔曼相关系数测试结果
根据图2可知,数据量与斯皮尔曼相关系数之间存在线性关系,随着数据量的增加,斯皮尔曼相关系数不断减小,对比方法1、方法2和方法3的测试结果可知,方法1的斯皮尔曼相关系数最高,因为方法1对网络本体语义相似度进行计算之前,对网络本体之间存在的ISA关系进行了分析,在此基础上对其语义相似度进行计算,提高了计算结果的精度。
3)分别采用方法1、方法2和方法3对网络本体语义相似度进行计算,对比不同方法的计算时间,测试结果如表1所示。
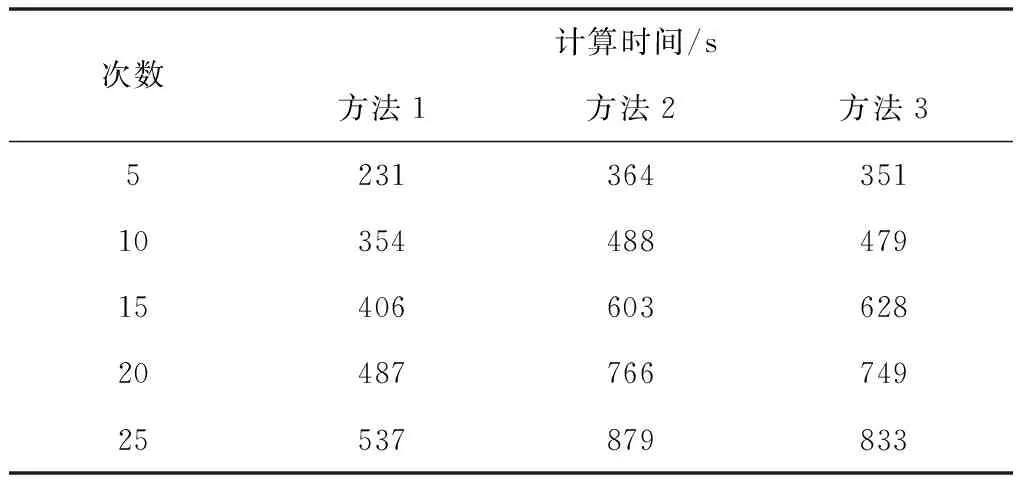
表1 计算时间测试结果
根据表1可知,随着测试次数的增加,三种方法的计算时间不断增加,但经过对比发现,在相同次数下,方法1的计算时间均少于方法2和方法3的计算时间,表明方法1可在较短时间内完成网络本体语义相似度的计算,具有较高的计算效率。
5 结束语
在信息领域技术研究过程中语义相似度计算属于热点研究方向,在信息检索和文本分类等领域中得到了广泛地应用。在计算精度和效率方面目前语义相似度计算方法还存在一些问题和不足,提出基于ISA关系的网络本体语义相似度计算方法,首先对网络本体之间存在的ISA关系进行分析,根据分析结果对语义相似度进行计算,实验结果表明在计算精度和计算效率方面基于ISA关系的网络本体语义相似度计算方法进行了优化和改善,可在较短的时间内精准的完成网络本体语义相似度的计算。
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05
客联(2021年5期)2021-09-10
哈哈画报(2021年10期)2021-02-28
开放教育研究(2020年2期)2020-03-31
制造业自动化(2017年2期)2017-03-20
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
中国医学影像学杂志(2015年9期)2015-12-15
导航定位与授时(2014年2期)2014-04-27
