
高光谱结合优化算法的多品种高粱混合的淀粉含量检测
2022-02-08 04:04:00补友华姜鑫娜田建平胡新军黄浩平罗惠波
中国粮油学报 2022年11期
补友华,姜鑫娜,田建平,胡新军,黄浩平,高 剑,黄 丹,罗惠波
(四川轻化工大学机械工程学院1,宜宾 644000)四川轻化工大学生物工程学院2,宜宾 644000) (四川酿酒专用粮工程技术研究中心3,宜宾 644000)
高粱作为一种生禾本科植物,在发展中国家约有5亿人将其作为主食[1]。高粱除了用来作为主食,由于高粱中淀粉含量高,大约占高粱的65%~70%,蛋白质、单宁、脂肪等含量也适当,也常用于酱香型白酒的酿造[2]。高粱中的淀粉由直链淀粉和支链淀粉组成,它们是产生酒精的来源和发酵微生物的物质[3]。对于不同品种的高粱,其直链淀粉和支链淀粉含量也不相同,酒厂常使用多种混合品种的高粱作为酿造原料。由于不同比例配比下高粱的直链淀粉和支链淀粉含量会影响白酒的品质和风味,因此检测不同比例配比下高粱的直链淀粉和支链淀粉含量尤为重要。目前,高粱淀粉含量的检测主要采用化学分析方法和无损检测方法。化学方法中常使用碘亲和力滴定法和双波长分光光度法对淀粉含量进行测定,但是此类方法耗时长,且属于破坏性检测[4, 5];无损检测中常用近红外光谱技术对淀粉含量进行非破坏性测定[6, 7],但只能实现单点检测且检测精度不高;因此需要一种快速无损方法获取不同混合比例配比下高粱的淀粉含量。
高光谱成像技术作为一种新兴检测技术,可以同时获取待测样本的图像和光谱信息,可用来全面、客观地分析样品,这使得它在食品的安全检测和控制方面比传统光谱技术和图像技术更具有优势[8]。该技术已被广泛用于各种物质含量检测,如大曲的酸度、水分和还原糖含量[9-11],花生仁的脂肪含量[12],大米、水稻籽粒和马铃薯的淀粉含量[13-15]。用高光谱成像技术对淀粉含量和其他物质含量检测方面的研究均取得较好的结果,为使用高光谱技术检测不同混合比例配比下高粱的淀粉含量提供了可行性。
本实验以不同混合比例配比下的高粱样本作为研究对象,使用可见光高光谱成像系统采集高粱样本的高光谱图像,使用基于扩展极大值变换改进后的分水岭算法对光谱图像进行了高粱籽粒分割,并提取了籽粒的光谱数据;对不同预处理方法后的光谱数据分别建立了偏最小二乘法回归(PLSR)模型,确定了最佳预处理;使用主成分分析(PCA)、PLSR算法提取了光谱特征;基于遗传算法-BP神经网络(GA-BPNN)和粒子群算法-支持向量机回归(PSO-SVR)分别建立了高粱淀粉含量的预测模型。
1 材料与方法
1.1 样本制备
由于酱香型白酒主要以红缨子糯高粱作为主要酿造原料[16],然后混合小比例的其他糯高粱品种,因此本研究选用贵州某高粱育种中心的红缨子(HYZ)作为被混合的高粱品种,选择四川、山东某高粱育种中心的美国高粱(MG)及铁杆(TG)2个品种作为混合的高粱品种。将3个高粱品种进行两两组合得到3组混合样本(MG+HYZ、TG+HYZ、TG+MG)。每组混合样本的总质量为15 g,按照5种不同的混合比例(10%、16.67%、23.33%、33.33%、43.33%)配比的高粱进行样本制备,每个混合比例的样本制作20个平行样本,共制备300个样本(3×5×20 = 300)作为淀粉含量预测模型的训练集和预测集。另外制备了10个样本作为外部验证集用于验证最优模型的稳当性和准确性(MG+HYZ、TG+HYZ不同混合比例各1个)。样本制备完成后,所有高粱样本在未采集数据前都进行常温密封保存。不同混合比例配比的高粱样本具体信息如表1所示。
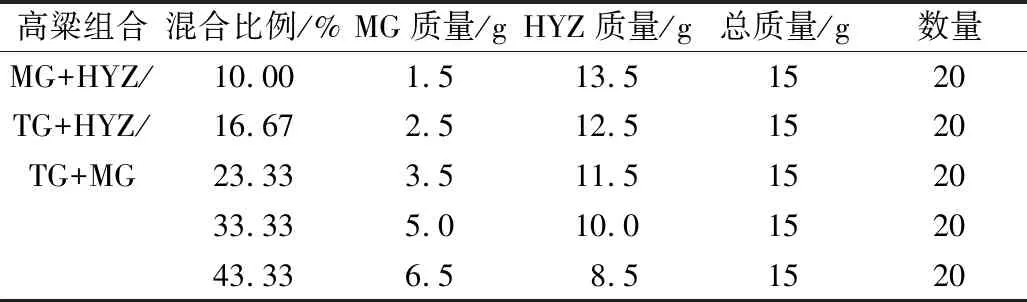
表1 不同混合比例配比的高粱样本制备
1.2 仪器与设备
高光谱成像的采集设备使用美国推扫式成像系统,采集软件为LUMO-scanner。该系统主要由Specim FX10系列高光谱相机、2组150 W的卤素灯光源、电控移动平及平台支架组成。高粱质量的测定设备使用OHAUS精密天平,量程为320 g,精度为0.001 g。高粱淀粉含量测定的主要仪器有BJ-800A多功能粉碎机,BGZ-140电热鼓风干燥箱,TG-16高速离心机,UV Professional分光光度计,BSC-400恒温恒湿箱等。
1.3 高光谱图像采集及校正
使用高光谱成像系统前,为了获得稳定的高粱样本的高光谱图像,需要在数据采集系统设置最佳采集参数。在使用高光谱相机采集数据时,将采集参数白板标定峰值调整为3 616,相机的曝光频率和曝光时间分别设置为50 Hz和4.02 ms,移动平台扫描速度设置为16.57 mm/s。采集参数设置完成后,将高粱样本平铺在直径为150 mm的培养皿中,然后放在电控移动平台进行数据采集。
为了减少相机探测器的暗电流对样本的整体影响,并消除环境光照不均匀对高粱颗粒的影响,需要利用白色参考图像和暗电流参考图像对原始高光谱图像进行校正对原始高光谱图像进行图像校正[17]。对高粱的原始光谱图像用式(1)进行校正。
(1)
式中:Ir为校正前的原始光谱图像;Iw为白色参考图像;Id为暗电流参考图像;Ic为校正后的参考图像。
1.4 高粱直链、支链淀粉测定
高粱样本的高光谱数据采集完成后,使用GB 7648—1987测定每个高粱样本的直链、直链淀粉含量。其测定原理为淀粉遇碘生成淀粉-碘复合物,且直链淀粉遇碘生成深蓝色复合物,支链淀粉遇碘生成棕红色复合物。当淀粉总量不变时,不同比例的直链、支链淀粉分散液在一定的波长与酸度条件下与碘作用生成由紫红到深蓝的一系列颜色,使用分光光度计可以测定分散液中的直链、支链淀粉的含量。
1.5 数据处理方法
1.5.1 高光谱数据提取及处理
由于高粱样本的高光谱图像包含了无关的背景信息和高粱籽粒的信息,并且高粱籽粒之间存在粘结现象。为了剔除无关的背景信息和分割存在粘结现象的高粱籽粒,故对高粱样本的图像采用图像处理技术中形态学方法和分水岭算法[18],确定样本中所有高粱籽粒的位置,然后精确提取高粱籽粒感兴趣区域(ROI)内的光谱数据。根据式(2)对每颗高粱籽粒ROI的光谱数据取平均值作为得到高粱籽粒的平均光谱数据[19]。
(2)

在提取了高粱样本中每颗高粱籽粒的光谱数据后,将样本中所有高粱籽粒的光谱数据取平均值作为每个高粱样本的光谱数据,用于后续数据分析。
1.5.2 光谱预处理及样本划分
为了消除高粱样本颗粒在培养皿中分布不均匀,且高粱颗粒大小的不同而引起的散射对其光谱的影响,采用多元散射校正(MSC)对高粱颗粒的光谱数据进行处理,从而获得理想的光谱[20]。为了提高光谱的信噪比,减少随机噪声对光谱的影响,使用Savizky-Golay滤波器(SG)对高粱样本的光谱进行平滑处理[21]。也采用MSC与SG结合的方式光谱进行预处理[22]。另外,本研究采用光谱-理化共生距离(SPXY)[23]对高粱样本进行样本集划分,将300个高粱样本按照4∶1的比例划分为校正集和预测集,用于后续淀粉含量的定量预测模型的训练和预测。
1.5.3 光谱特征提取方法
采用2种方法提取高粱光谱数据的特征。使用PCA算法分别计算高粱光谱数据的主成分,然后选择累计贡献率最大的几组主成分对应的得分矩阵作为光谱特征[24]。使用自变量(高粱样本的光谱数据)和因变量(高粱样本的淀粉含量)建立PLSR模型[25],然后选择PLSR模型累计贡献率最大的前几组潜在变量对应的得分矩阵作为光谱特征,用于后续预测高粱淀粉含量模型的建立。
1.5.4 高粱淀粉预测模型建立
1.5.4.1 GA-BPNN预测模型
BPNN算法是一种经典的多层前馈算法,可用于解决相对复杂的非线性问题,在光谱分析中得到了广泛的应用[26]。BPNN的网络结构由一个输入层、多个隐藏层和一个输出层组成。该算法的基本原理:在学习过程由输入信号(光谱数据)的正向传播与误差的反向传播两个过程组成。本研究将GA算法和BPNN神经网络结合起来,对神经网络的初始的权值和阈值进行整体优化[27]。其中种群规模设置为100,遗传迭代次数为50,交叉概率为0.6,变异概率为0.05。
1.5.4.2 PSO-SVR预测模型
SVR以其优异的泛化能力被广泛用于解决光谱数据的分类与回归问题[28]。SVR作为支持向量机里的一个分支,常用于回归分析。SVR的基本原理是通过使用核函数,将低维空间的非线性问题映射到高维空间,在高维空间中构造线性决策函数来实现原空间中的非线性决策,从而实现线性回归[29]。由于惩罚系数c和松弛系数g的取值直接决定了SVR模型的泛化能力,所以通过PSO算法对SVR模型的惩罚因子c和核函数参数g进行参数寻优[30]。
1.5.5 模型评估
本研究基于全波长和特征光谱分别建立了预测高粱的淀粉含量GA-BPNN和PSO SVR模型。通过校正决定系数(Rc2),校正均方根误差(RMSEC),预测决定系数(Rp2),预测均方根误差(RMSEP)来综合评价模型的性能,选择最优的预测模型。通常RMSEC、RMSEP反映了模型的预测精度,其值越接近0说明模型精度越高;Rc2、Rp2反映了对数据变化的解释程度,其值越接近1代表模型的解释程度越高[31]。
2 结果与分析
2.1 高粱样本的淀粉含量测定值统计
将高粱样本的光谱数据和对应的直链、支链淀粉含量划分为校正集、预测集。划分样本后的淀粉含量统计结果如表2所示,预测集的淀粉含量范围(0.902 3~2.163 1 g)分布在校正集的淀粉含量范围(0.906 4~2.213 2 g)之内,且校正集和测试集内直链淀粉含量的均值、标准差基本一致,说明划分的样本分布均匀,划分结果较为合理。
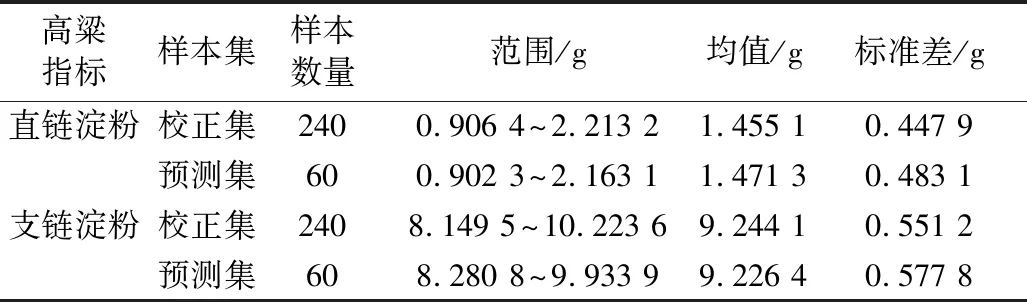
表2 高粱淀粉含量参考值统计
2.2 高粱样本的图像处理及光谱提取
首先,对高粱样本的RGB图像进行灰度变换,使得高粱籽粒的目标区域和背景区域明显分开;然后对灰度图像进行二值化,再对其二值图像使用基于扩展极大值变换改进后的分水岭图像分割算法,找到高粱籽粒的分水岭脊线;最后,将分水岭脊线图像反色,再与二值图像进行与运算,得到分割后的高粱籽粒,高粱样本图像的关键处理过程如图1所示。将分割后每个高粱籽粒作为ROI,提取每个高粱籽粒ROI的平均光谱数据,再对每个高粱籽粒ROI的平均光谱数据取平均,得到高粱样本的平均光谱数据。

图1 高粱样本的图像处理过程
2.3 高粱样本的光谱分析
不同混合比例配比下的高粱样本的可见光光谱如图2所示。不同混合比例配比下高粱样本的光谱曲线呈现相同的趋势。光谱在500 nm附近有轻微的吸收峰,在其余的波段位置没有明显的吸收峰,但是反射率具有明显的差异。
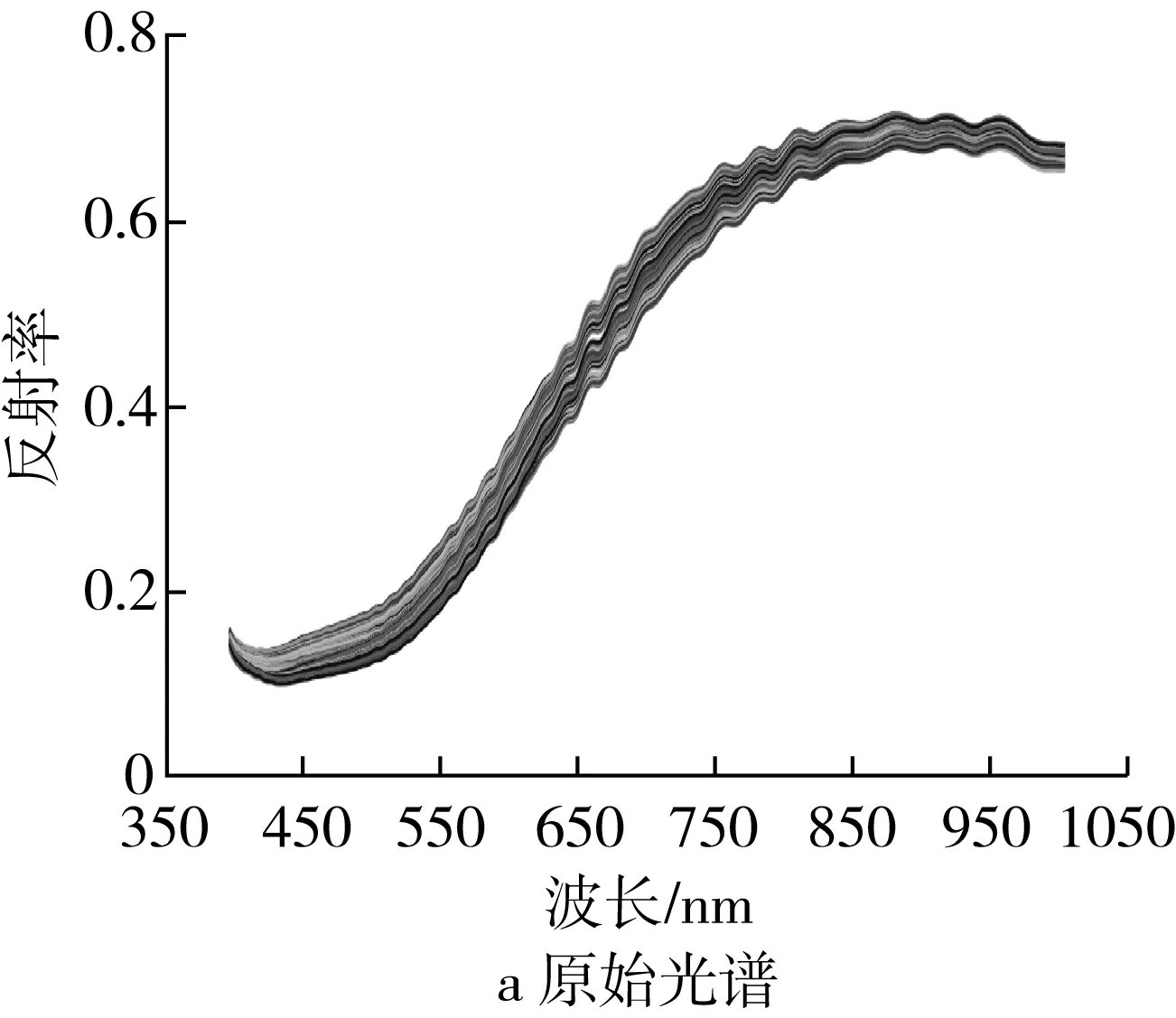
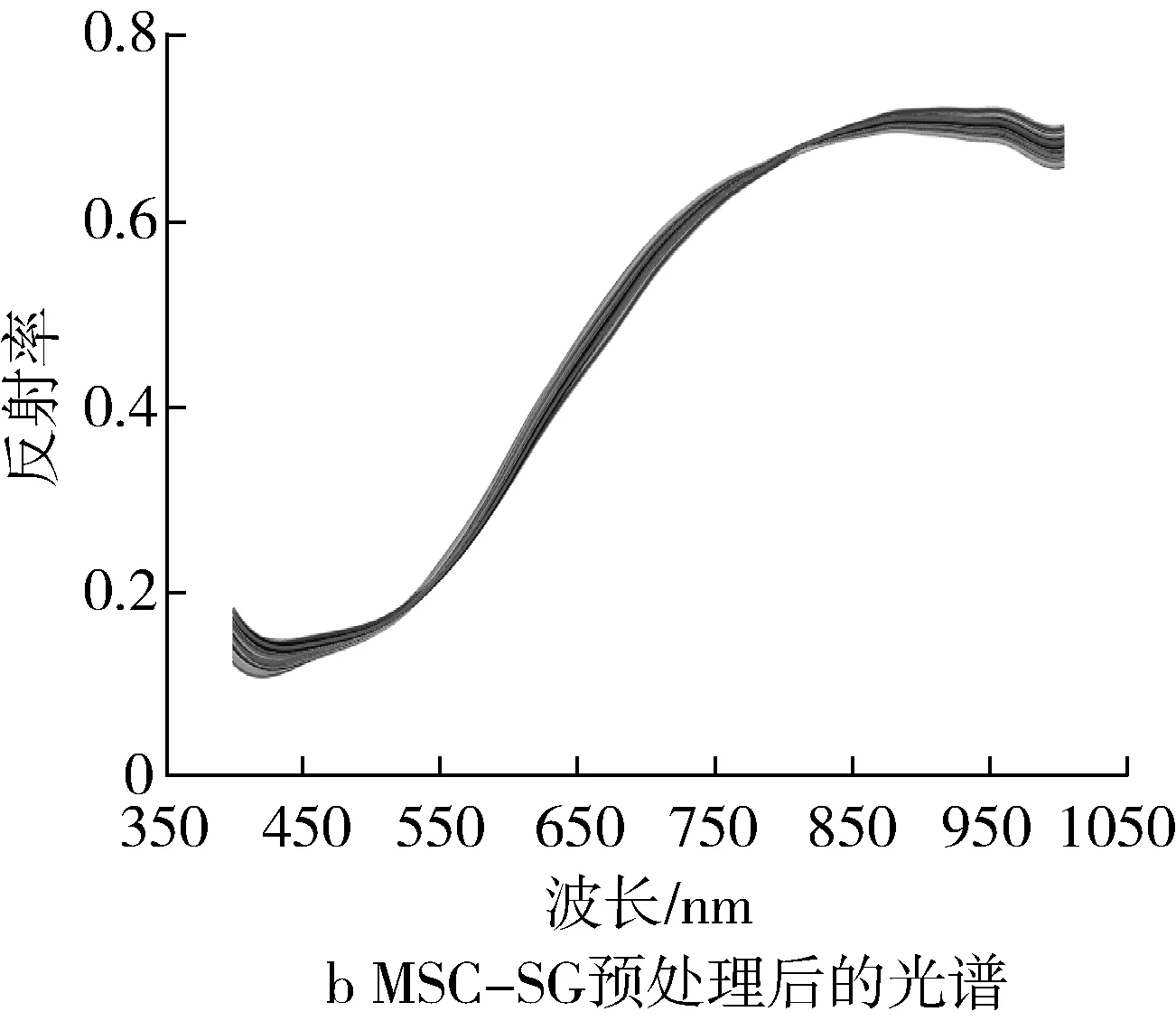
图2 高粱光谱曲线
2.4 光谱数据的预处理分析
利用MSC、SG、MSC-SG预处理方法对不同混合比例配比下的高粱样本的光谱数据进行预处理,将预处理后的光谱数据结合PLSR建模预测高粱的淀粉含量,预测效果如表3所示。经比较发现未使用预处理的光谱数据建立的预测直链淀粉含量的PLSR模型预测能力最好,RMSEP=0.045 1,Rp2=0.989 7;发现使用MSC-SG预处理后的光谱数据建立的预测支链淀粉含量的PLSR模型预测能力最好,RMSEP=0.206 7,Rp2=0.871 0,这可能是因为MSC-SG可以降低高粱颗粒大小的不同而引起的散射对其光谱的影响,且减少光谱噪声。因此后续研究选取未预处理和MSC-SG预处理后的光谱数据分别作为高粱直链淀粉和支链淀粉含量预测的光谱数据预处理手段。MSC-SG预处理后光谱曲线如图2b所示。
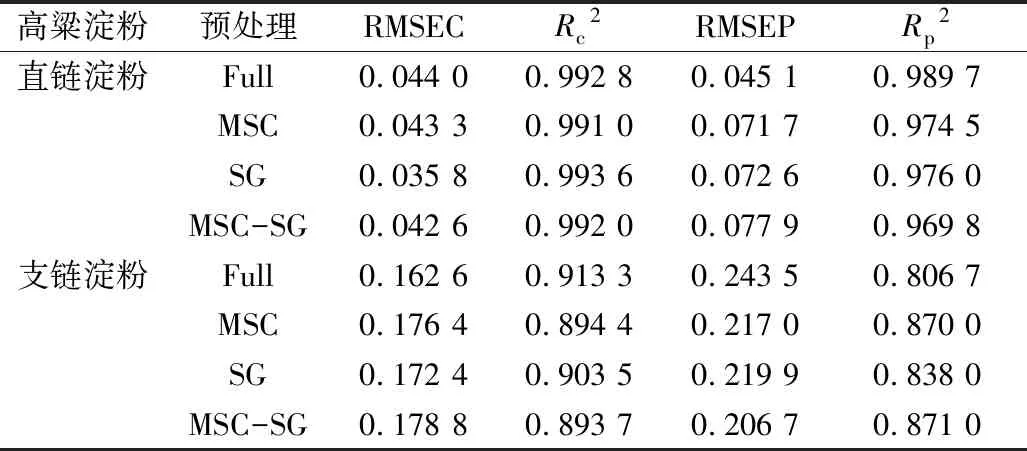
表3 光谱数据预处理后的建模效果
2.5 光谱特征提取
2.5.1 PCA算法提取光谱特征
在可见光光谱范围内,采集的光谱数据包含了448个波段,其存在大量的冗余和共线性信息的问题,使得模型的精度和运算速度降低。为了消除光谱数据中的冗余和干扰变量,简化模型,因此需要对光谱数据进行降维。该研究使用PCA算法对光谱数据进行主成分分析,光谱数据的前4个主成分的累计贡献率达到99.87%(PC1:54.36%、PC2:42.09%、PC3:3%、PC4:0.42%)。因此提取了前4个主成分对应的主成分得分矩阵(300×4)作为光谱特征用于后续多元模型的建立。
2.5.2 PLSR算法提取光谱特征
PSLR算法是一种基于特征变量的回归方法,其实质是按照协方差极大化准则,在分解自变量数据矩阵X(高粱光谱数据)的同时,也在分解因变量数据(淀粉含量),并且建立相互对应的潜在变量与因变量数据之间的回归关系方程。如图2所示,该研究初始选择35个潜在变量数建立预测高粱淀粉的PLSR模型,然后通过十折交叉验证,根据最小的均方根误差(RMSE)选择最佳的潜在变量数。由图3a可知,当潜在变量数为7时,预测直连淀粉含量的RMSE值达到最小为0.028 75,由图3c可知,前7个潜在变量的累计贡献率达到了97.63%,因此选择前7个潜在变量对应的得分矩阵(300×7)作为光谱特征用于后续建立直连淀粉含量的预测模型。同样,对于支链淀粉的光谱特征提取,由图3b可知,当潜在变量数为5时,预测支链淀粉含量的RMSE值达到最小为0.1779 8,由图3d可知,前5个潜在变量的累计贡献率达到了84.11%,因此选择前5个潜在变量对应的得分矩阵(300×5)作为光谱特征用于后续建立支链淀粉含量的预测模型。
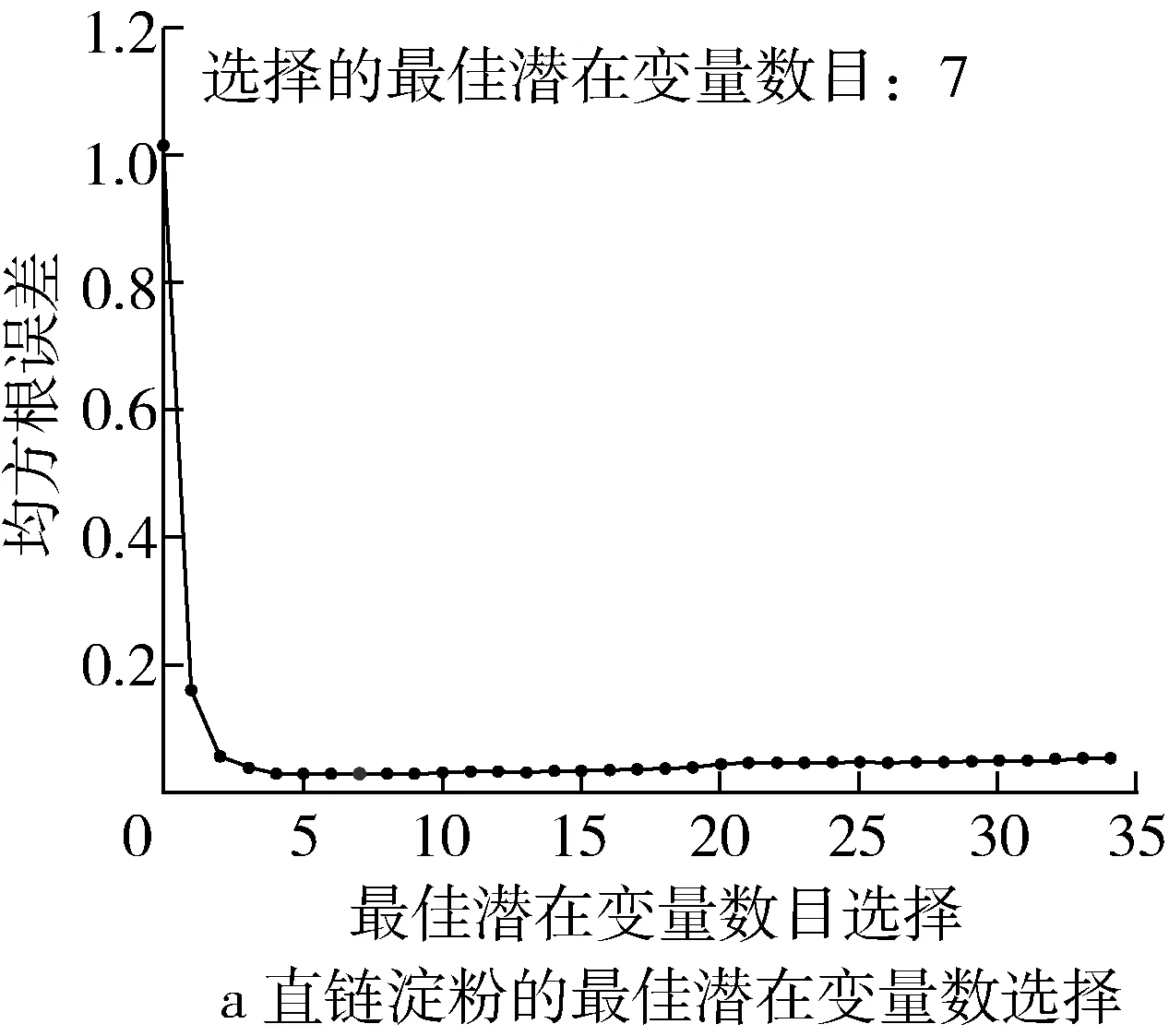
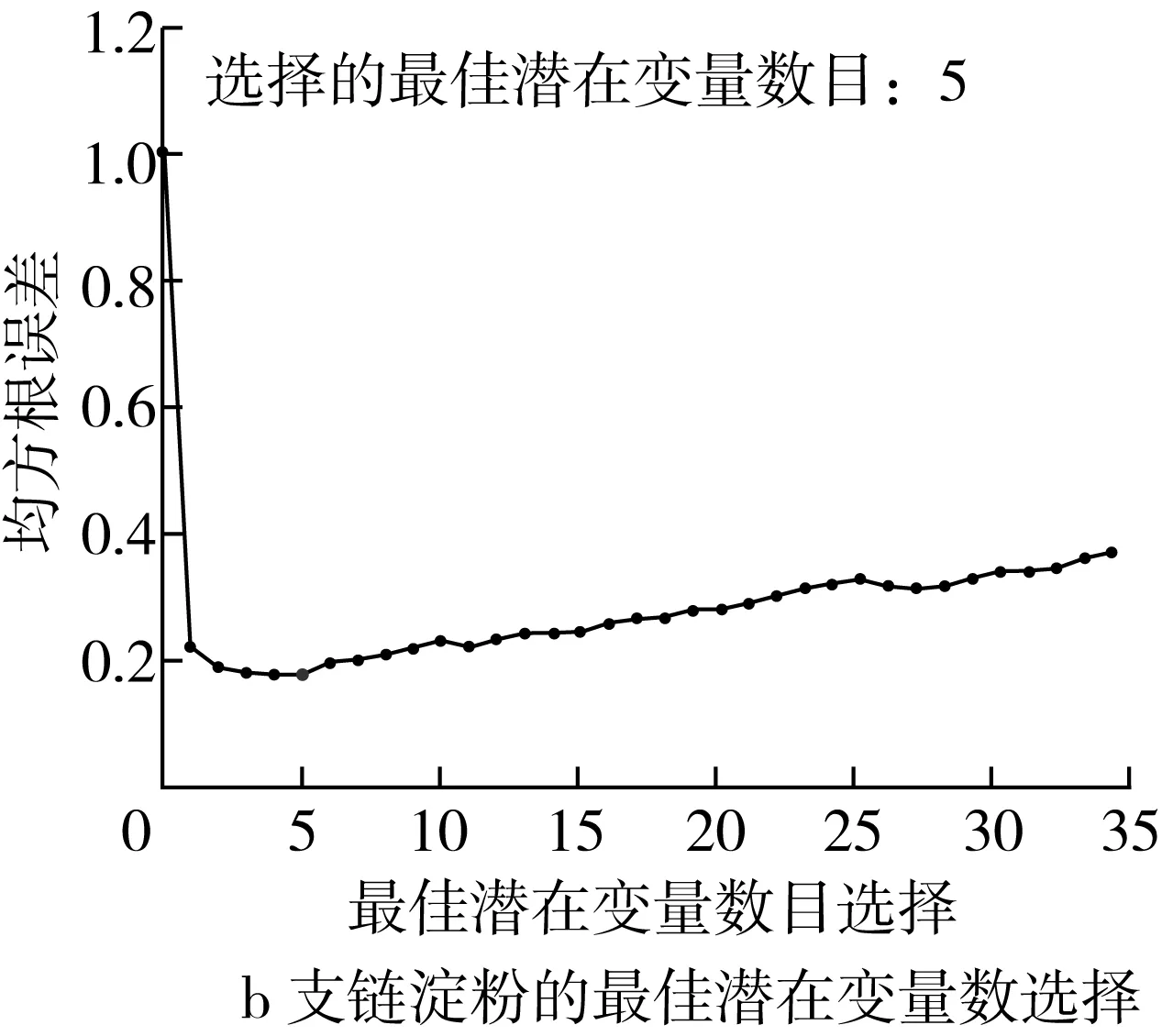
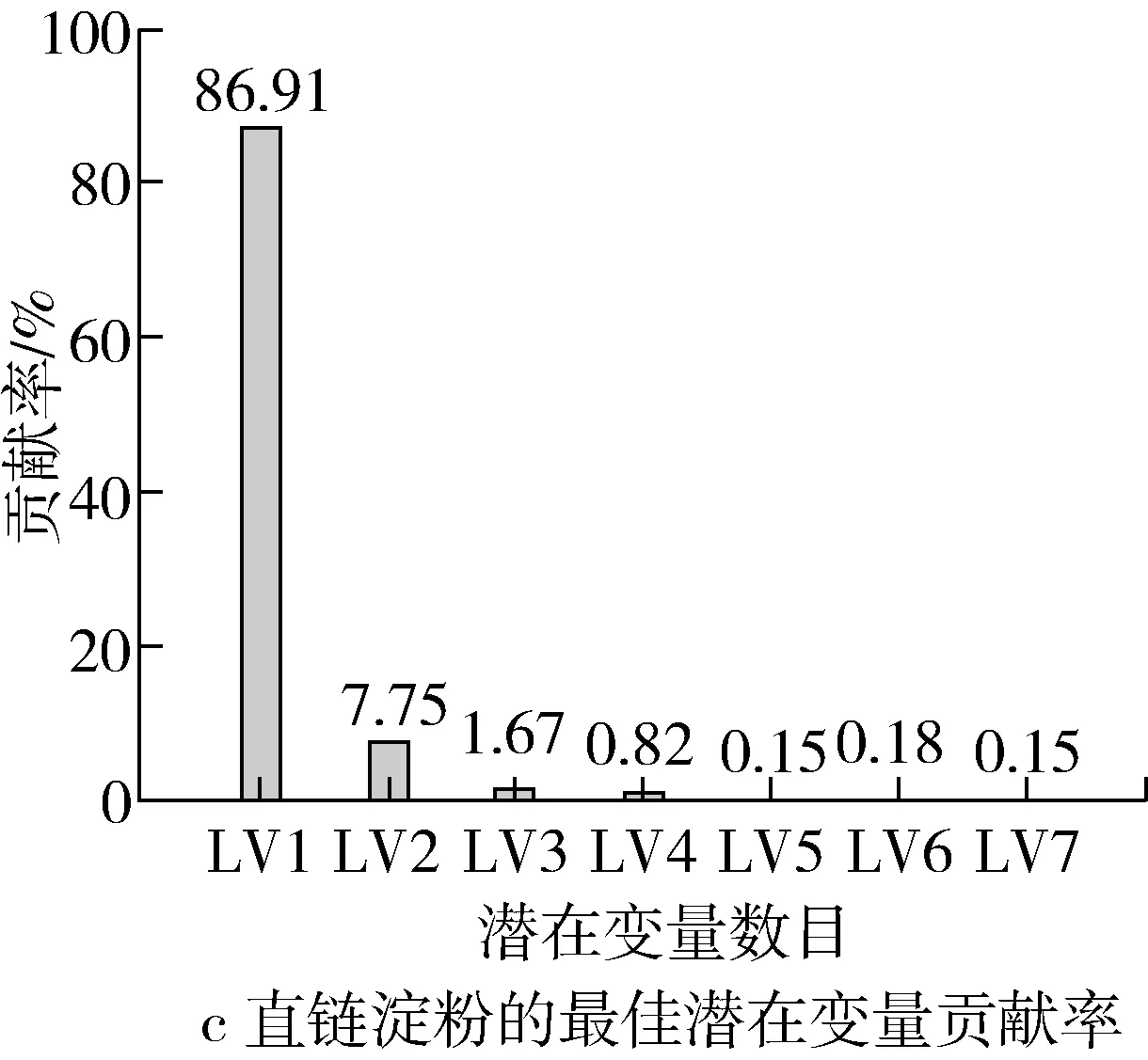
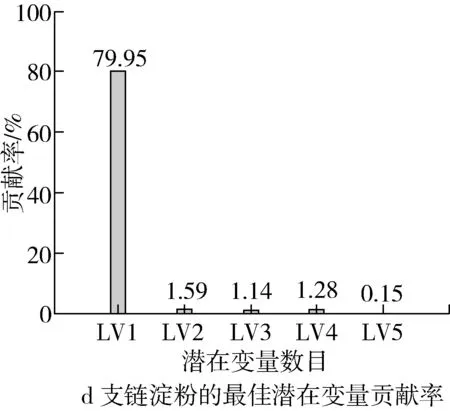
图3 PLSR模型的潜在变量
2.6 多元模型分析
基于全波长的光谱数据、PCA和PLSR提取的光谱特征,利用未预处理和MSC-SG预处理后的光谱数据分别建立了GA-BPNN和PSO-SVR模型,预测不同混合比例配比下高粱的淀粉含量。对于GA-BPNN的网络结构和参数设计:确定trainlm为神经网络的训练函数,隐含层为1层带有15个点神经元,确定tansig为隐含层节点的传递函数,purelin为输出层节点传递函数,网络学习函数为BP学习规则learngdm,学习率为0.001,迭代次数为1 000,训练目标为4.43e-7。对于PSO优化SVR模型的参数:粒子群的种群数N=20,粒子速度范围[0.1,1.0],最大的迭代次数Gmax=200,学习因子C1和C2为1.5和1.7,建模结果如表4所示。
从表4中可见,对于高粱直链淀粉含量的预测结果,在GA-BPNN模型中使用PCA提取的光谱特征建立的模型效果最佳,其RMSEP,Rp2分别为0.014 6,0.992 2;在PSO-SVR模型中使用PLSR提取的光谱特征建立的模型效果最佳,其RMSEP,Rp2分别为0.044 7,0.991 0。以上2种模型效果相对于全波长建模的效果来说,在保证模型的预测精度的前提下不仅简化了模型,也提高了模型的预测精度;GA-BPNN和PSO-SVR这2种模型之间,采用PCA提取的光谱特征建立的GA-BPNN模型效果最好。对于高粱支链淀粉含量的预测结果,同样是采用PCA提取的光谱特征建立的GA-BPNN模型效果最好,其RMSEP,Rp2分别为0.151 9,0.933 6。这是因为PCA算法对光谱数据进行主成分分析,前4个主成分的累计贡献率高达99%以上,因此提取前4个主成分对应的得分矩阵作为光谱特征,能够很好的解释光谱数据的差异性,因此PCA提取的光谱特征建立模型效果最好;而PLSR算法的最佳潜在变量的累计贡献率低于98%,导致PLSR提取的光谱特征建立模型效果略差。
图4展示了基于PCA提取光谱特征建立的GA-BPNN的模型预测集和训练集的拟合结果。
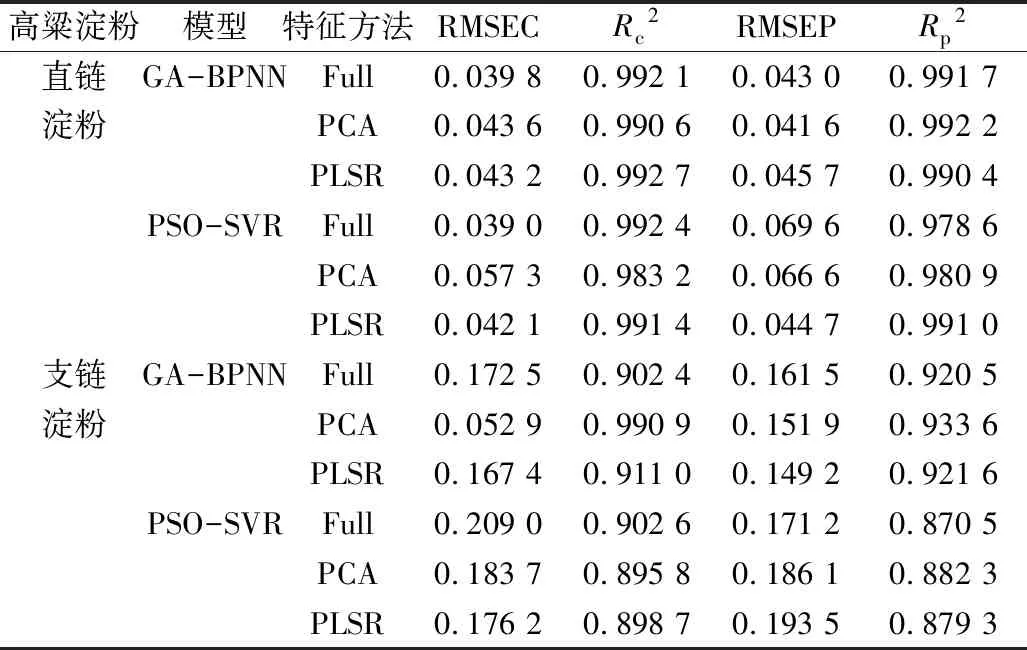
表4 多元模型的效果
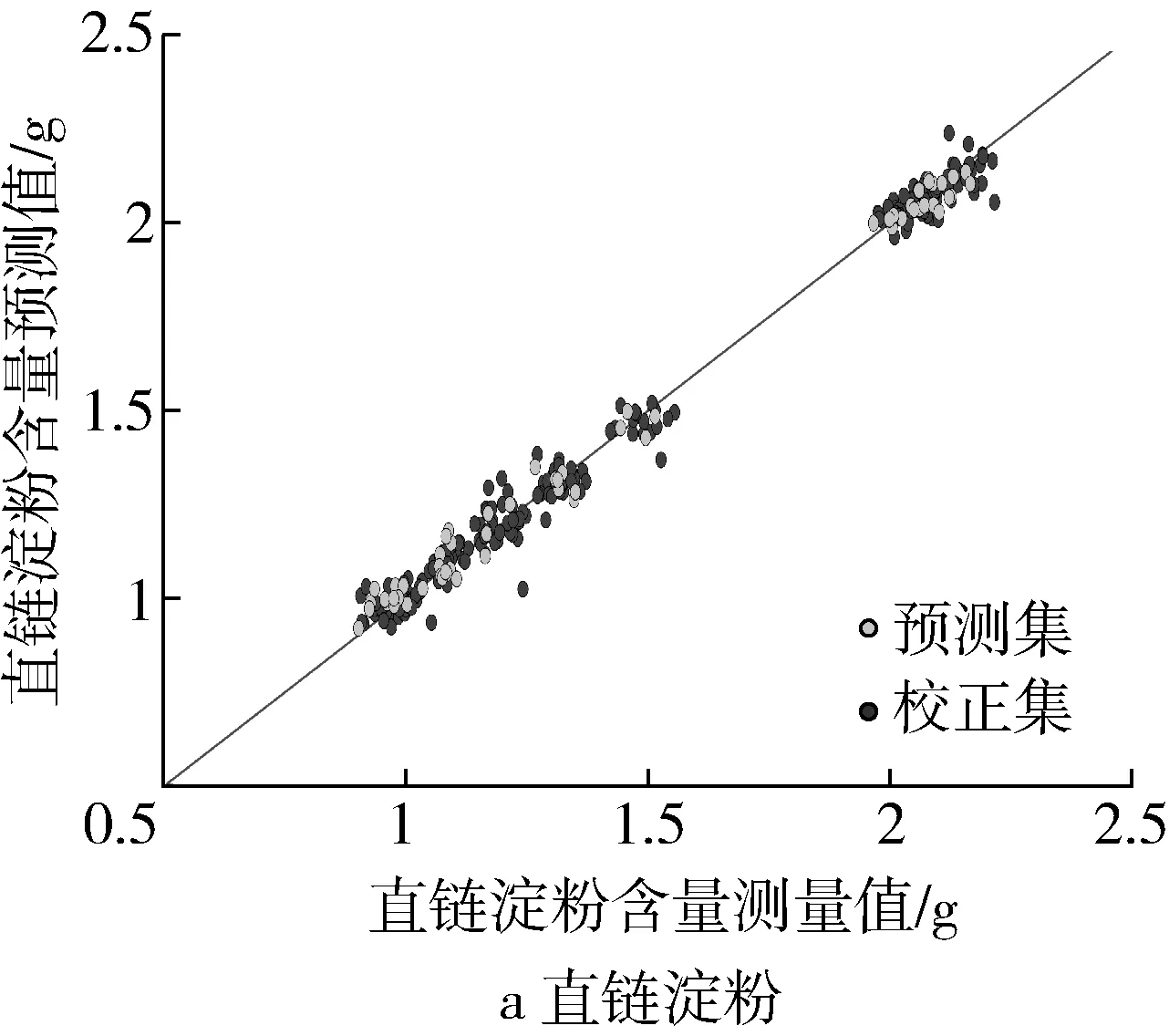
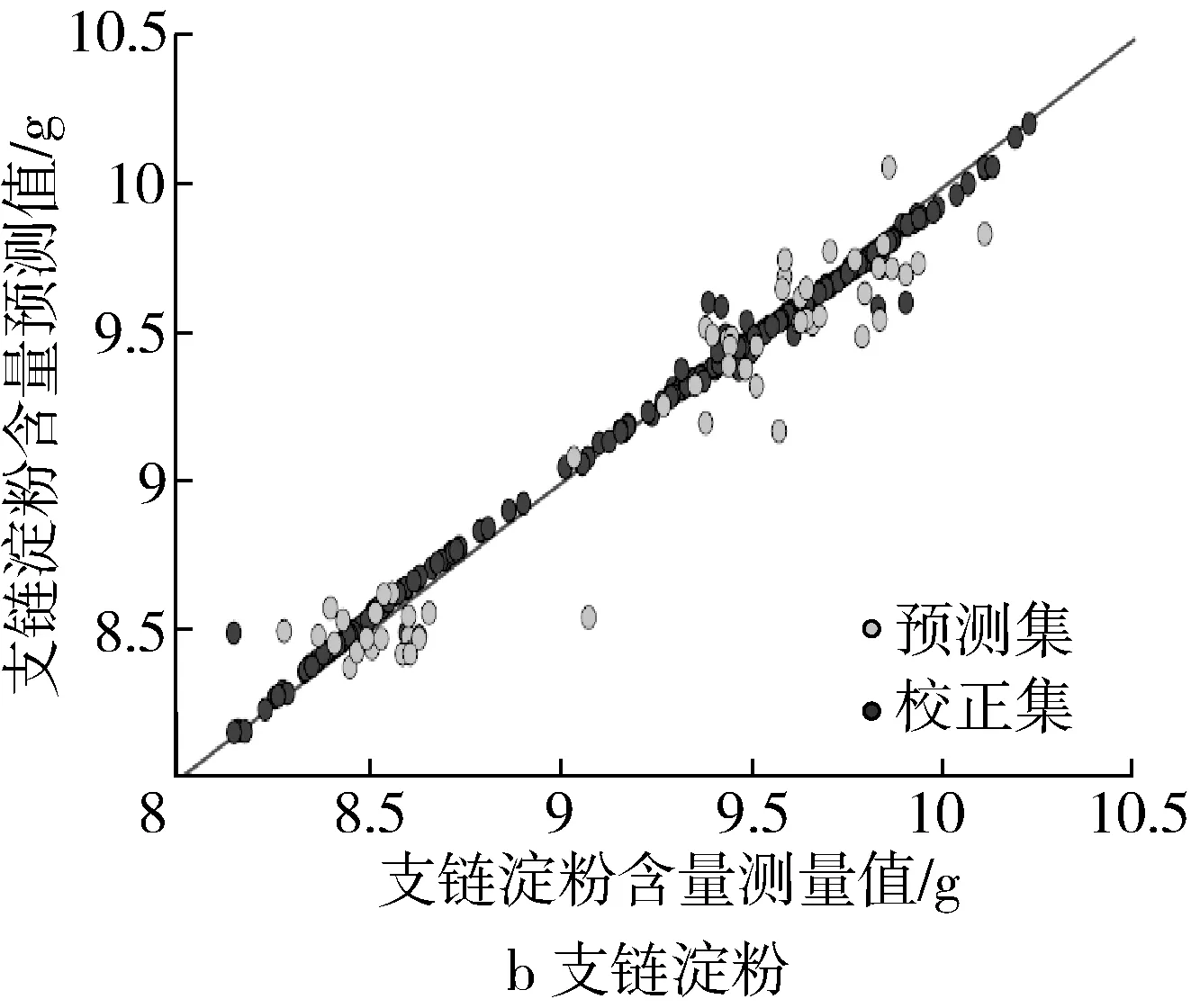
图4 预测集和校正集的拟合效果
可以看出高粱直链淀粉含量的拟合效果较好,其淀粉含量的测量值和预测值均分布在红色斜线附近,说明直链淀粉含量的预测误差小。高粱支链淀粉含量的拟合效果略差,其淀粉含量的测量值和预测值均分布在红色斜线的较远区域,这是因为支链淀粉含量在8~10.5 g,支链淀粉的预测值与测量值的误差略大。
2.7 最优模型外部验证
为了进一步验证最优模型的准确性和稳定性,采用外部验证方式验证模型效果,将未参与建模10个外部验证集代入最优模型进行预测,同时与测量值进行比较,对比结果见表5。
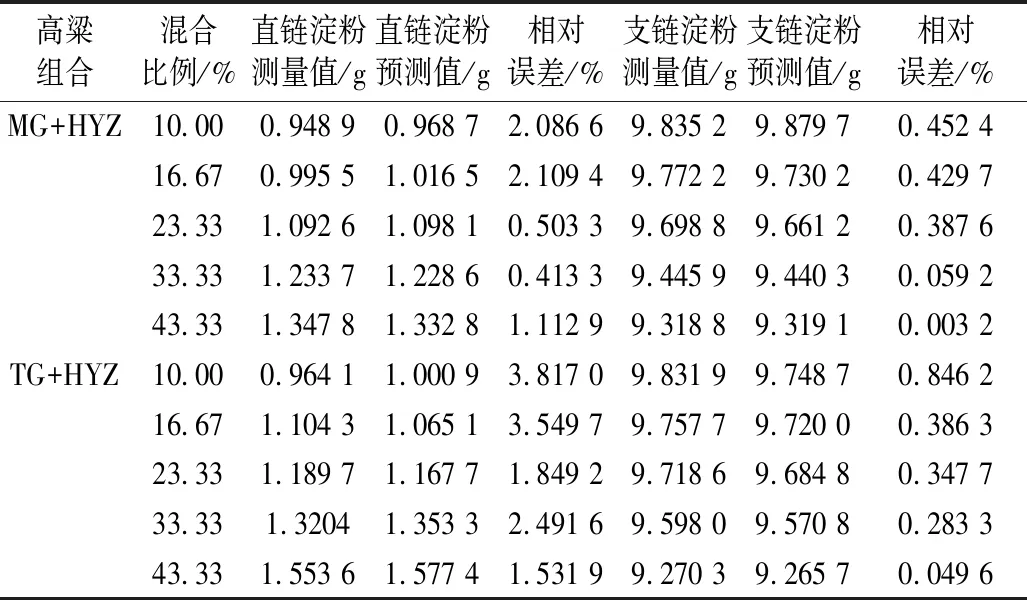
表5 淀粉测量值与预测值结果对比
3 结论
本研究探讨了可见光高光谱成像技术在不同混合比例配比下高粱的淀粉含量检测中的应用,结果表明可见光高光谱成像技术结合优化算法能够准确地检测不同混合比例配比下高粱的淀粉含量。利用原始和不同预处理方式(MSC、SG、MSC-SG)处理后的光谱数据建立PLSR模型预测高粱淀粉含量,发现MSC-SG建立的模型预测高粱支链淀粉含量的效果最好(Rp2=0.871 0,RMSEP=0.206 7)。利用PCA算法从高粱样本的光谱数据提取了300×4的特征光谱矩阵;利用PLSR算法对于直链淀粉和支链淀粉分别提取了300×7和300×5的光谱特征矩阵。基于全波长的光谱数据、PCA和PLSR提取的光谱特征建立了GA-BPNN和PSO-SVR模型预测高粱样本的淀粉含量,发现用PCA提取的光谱特征建立的GA-BPNN模型最优(直链淀粉:Rp2=0.992 2、RMSEP=0.041 6;支链淀粉:Rp2=0.933 6、RMSEP=0.151 9),有效简化了模型,提高了模型精度。总体研究结果表明,可见光高光谱成像技术结合优化算法能够快速获取高粱的淀粉含量,同时也可以为检测其他谷类的淀粉含量提供一种新的方法。
猜你喜欢
快乐作文(1.2年级)(2023年9期)2023-05-12 11:31:34
古今农业(2022年2期)2022-08-15 01:39:52
青年文学家(2022年1期)2022-03-11 12:27:39
中国粮油学报(2019年4期)2019-07-12 09:06:32
中国塑料(2016年2期)2016-06-15 20:29:57
实用手外科杂志(2015年2期)2015-08-28 09:50:56
饲料博览(2015年4期)2015-04-05 10:34:14
北京航空航天大学学报(2014年1期)2014-12-19 08:58:38
食品科学(2013年22期)2013-03-11 18:29:45
食品科学(2013年19期)2013-03-11 18:27:27
