
基于大米特征矿物元素产地鉴别建模方法比较研究
2022-02-08 04:04陈明明符丽雪李殿威钱丽丽
中国粮油学报 2022年11期
陈明明,符丽雪,李殿威,左 锋,2,钱丽丽,2,3
(黑龙江八一农垦大学食品学院1,大庆 163319 ) (国家杂粮工程技术研究中心2,大庆 163319) (黑龙江省农产品加工与质量安全重点实验室3,大庆 163319)
黑龙江土质肥沃,土壤类型丰富,盛产优质水稻。水稻自身不能合成矿物元素,其矿物元素含量和组成主要受产地环境和人类活动两方面的影响[1,2],不同的土壤类型矿物元素种类和含量不同,影响着水稻矿物元素含量和种类[3]。近年来国内外外学者通过探究已形成矿物元素分析技术用于产地判别是可行的统一共识。目前矿物元素分析技术已普遍运用于西洋参[4]、大豆[5,6]、蜂蜜[7,8]、葡萄酒[9-11]、茶[12,13]、枸杞[14]、松茸[15]等的产地判别。矿物元素分析技术因具有灵敏度高、线性范围宽、稳定性强等优点被认为是产地判别有效的方法[16-19],在植源性食品的产地判别中广泛应用[20],但验证筛选到的矿物元素指标的有效性是利用该技术进行产地判别成功的关键。科研工作者尽可能以多年连续采集多个样本数量为对象构建大米产地判别模型,并比较不同模型的适用性,进而验证筛选矿物元素判别指标的有效性。Butikofer等[21]利用判别分析和人工神经网络预测模型对欧洲地区奶酪进行了分类,2种方法分别正确区分了95%和91%的样本。Francisco等[22]基于线性判别分析和人工神经网络对西班牙矿泉水进行地理分类,神经网络预测模型判别能力达到94%。黎永乐等[23]利用Ca、Cu、Fe、K、Mg、Mn、Zn、Ni、As、Sr、Cd、Ba、Mo和Se对五常和非五常大米进行Fisher线性判别和人工神经网络判别,结果表明通过人工神经网络法建立的判别模型具有更优的判别能力,判别准确率为96.4%。夏立娅等[24]运用近红外光谱技术结合BP-人工神经网络对响水和非响水大米进行网络训练,建立了理想的网络误差收敛曲线,分类正确率可达100%。因此,利用线性判别分析和人工神经网络进行产地判别是可行的。产地溯源模型所采用的分析方法不同,建立产地判别模型的判别效果也不同。目前基于线性判别分析和人工神经网络的产地溯源建立过程所用到的仅为单一样本年份,以连续采集多年份的大米样本产地溯源判别研究具有重要的意义。
本实验以前期筛选得到的与产地和母质土壤直接相关的23 种特征矿物元素为依据,并以连续3 年的随机采集的查哈阳、五常和建三江274 份样本作建模对象,分别建立Fisher模型和人工神经网络预测模型进行产地判别,验证产地鉴别效果并比较2种建模方法的适用性。
1 材料与方法
1.1 实验材料
选择2016—2018 年水稻随机采集样本。样品来自于黑龙江省建三江地理标志大米保护区、五常大米地理标志保护区和查哈阳大米地理标志大米保护区。所用样本具体信息如表1所示。
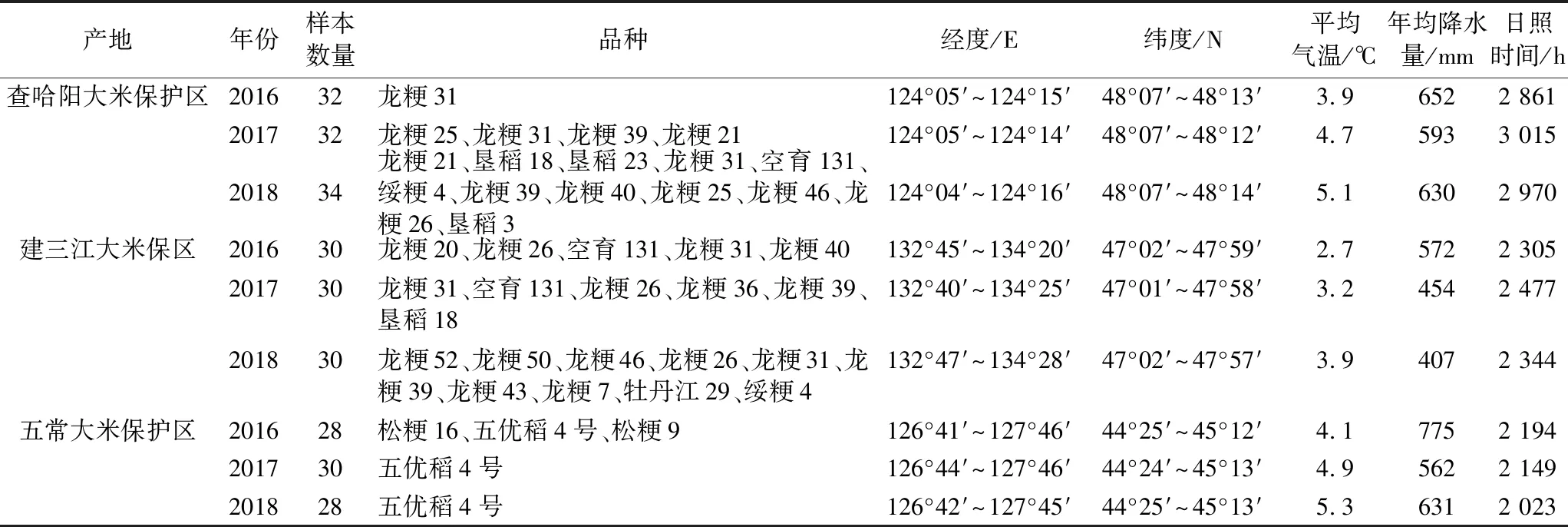
表1 2016—2018年样本信息表
1.2 主要试剂和仪器
7700a电感耦合等离子体光质谱仪,FC2K砻谷机,VP-32碾米机,Mara 240/50微波消解仪,DV4000精确控温电热消解仪,Milli-Q超纯水机,LM-3100旋风磨,DHG-9123A型电热恒温鼓风干燥箱,X68 GPS。
浓硝酸(65%)、过氧化氢:优级纯;多元素标准溶液5183-4688、多元素标准溶液、8500-6944多元素标准溶液、8500-6948内标(Bi、Ge、In)、粳米加工精度标准样品(二级):ZW001;生物成分分析标准物质-大米:GBW10010(GSB-1);无水乙醇溶液;苏丹-Ⅲ:分析纯。
1.3 实验方法
1.3.1 样品采集
在水稻成熟期,依据代表性采样原则,采用棋盘式采样法,每块地随机设置5 个重复点,每个采集点沿植株中部割取稻穗1 m2左右,每个区收集1~2 kg稻穗,并记录样品信息。
1.3.2 样品预处理
将采集回来稻谷样品在通风处晾晒至含水量14%以下,要求晾晒场地无扬尘、整洁、透光。对稻穗进行脱粒、砻谷、碾米获得二级精米,二级精米参照GB/T 5502—2018染色法判定大米加工精度。并对精米旋风磨粉碎处理,重复过100 目尼龙筛,得到米粉样本。所有样本采用统一处理方式。
1.3.3 样品元素测定
参考GB 5009.94—2012《植物性食品中稀土元素的测定》和GB 5009.268—2016《食品中多元素的测定》[25,26]和相关文献[27-30]采用电感耦合等离子质谱仪对大米样品和标准物质中元素测定,准确称取0.25 g的大米粉样品,置于消化管中加入6 mL浓硝酸(70%,BV3级)和2 mL双氧水(30%,BV3级),放入MARS微波消解仪中进行消解。微波设置程序为8 min内从0 W增到1 600 W,温度升到120 ℃,保持2 min;在5 min内从温度120 ℃升到了160 ℃,保持5 min;在5 min内再从160 ℃升到180 ℃,并在此温度下消解15 min;然后冷却20 min,将微波消化管取出,于通风橱内打开塞子将微波消化管置于精确控温电热消解器中进行赶酸。超纯水(>18.2 MΩ·cm)洗涤样品,定容至100 mL,采用同样方法进行空白样品和大米标准物样品消解。
ICP-MS工作参数为射频功率1 280 W,雾化室温度2 ℃,冷却水流量1.47 L/min,载气流量1.0L/min,补偿气体流量1.0 L/min,仪器测定3 年样品和大米标准物中Mg、Ca、Cr、Mn、Zn、As、Rb、Sr、Ag、Cd、Sb、Te、Ba、La、Nd、Sm、Gd、Dy、Ho、Er、Yb、Pb、U 23 种元素。实验过程中每个样品重复测定3 次,选用Ge、In和Bi作为内标元素,保证仪器的稳定性。当内标元素的RSD>5%重新测定样品。
元素的检出限和定量限见表2。
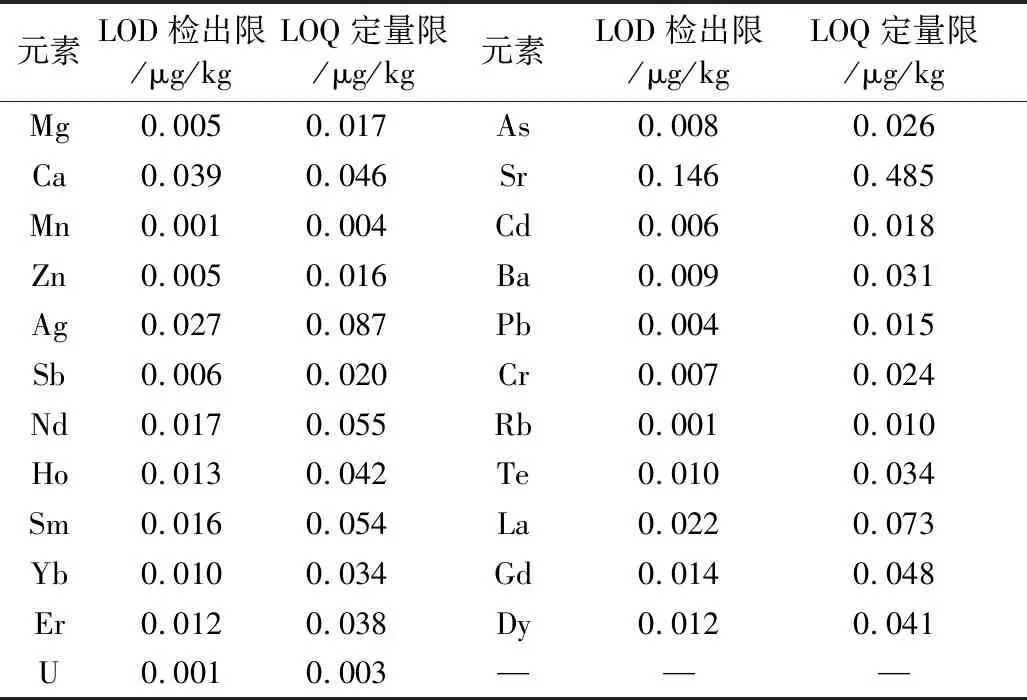
表2 ICP-MS仪器测定多种矿物元素的检出限和定量限
1.4 数据处理
采用SPSS26.0软件对数据进行方差分析、相关性分析和判别分析(Fisher判别分析)。采用MATLAB神经网络工具箱进行建模仿真。
1.4.1 基于前馈神经网络的产地判别分类结构
利用3年随机采集样本,分别建立4层神经网络并进行组合模型,考虑到影响大米矿物元素含量因素较多,属于难以解决的精确数学建模问题,利用神经网络的归纳推理机制和自适应学习能力,能够以任意精度逼近一个非线性函数的优势,将其作为一种解决大米矿物元素产地判别分类模型,实现采集样本产地分类识别。建立4层前馈神经网络结构,如图1所示。
从拓扑结构上可以看出,前馈神经网络是典型的分层网络结构。包括输入层、隐含层和输出层,层与层之间为互连方式,同层单元之间不存在相互连接,网络各层分别有nI,nh和no节点数。
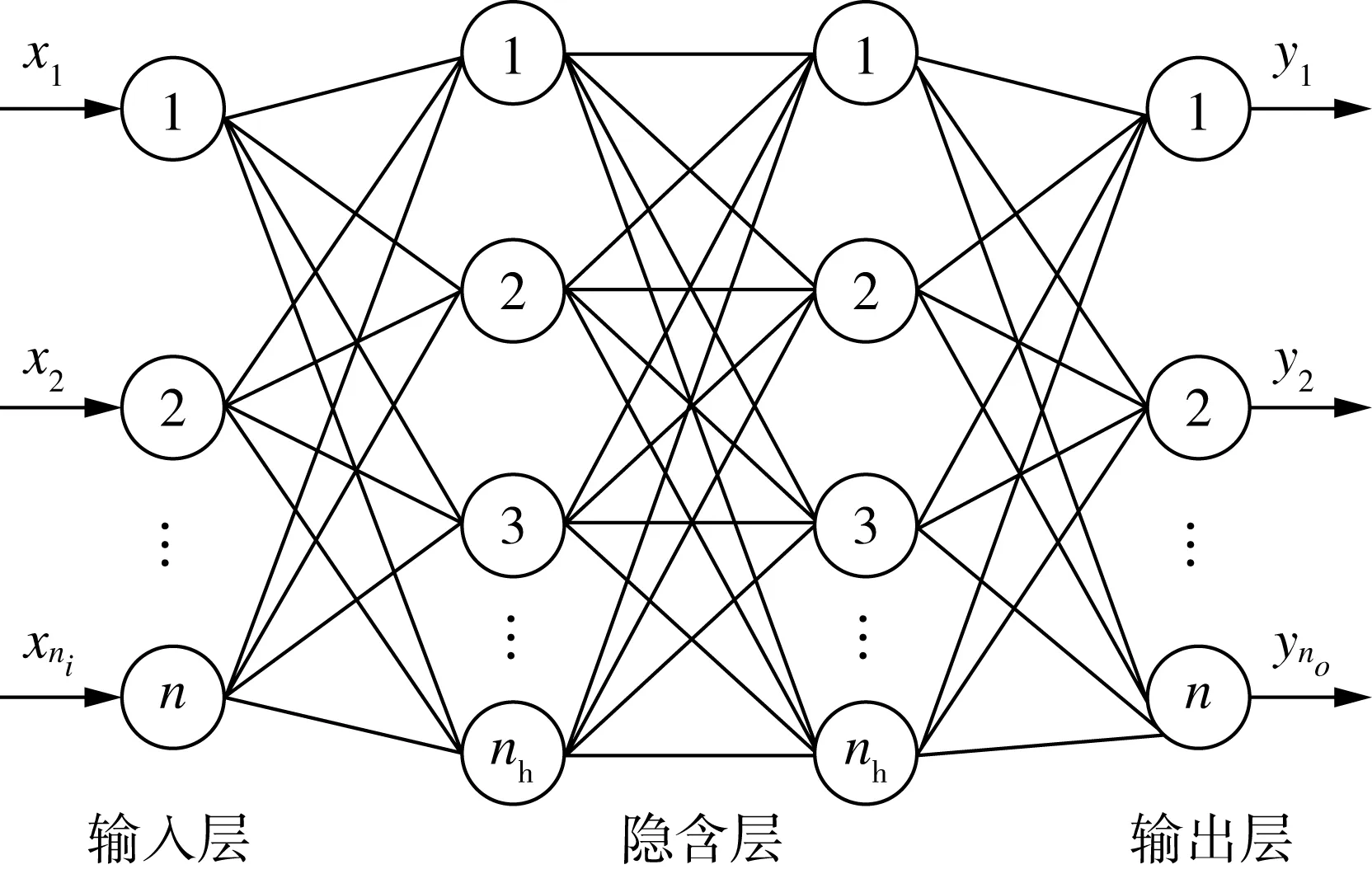
图1 网络结构示意图
本研究建立了一种前馈神经网络,利用其自适应性和稳定快速收敛特性,作为矿物元素大米产地分类的智能识别模型。在实际应用中,可以通过改变各层连接方式和激励函数,获得新的网络结构,实现不同的非线性映射关系。基于筛选的大米产地特征元素,应用到3 年随机采集样本数据中进行大米产地分类验证依据。
1.4.2 基于前馈神经网络的产地判别分类学习方法
设共有M样本,第p个样本,对应的期望实际输出为dp,计算网络输出为yp,网络各个输出总误差为
若记wjk数,即连接权值和阈值(θ和φ),则学习规则为:
式中:η为学习速度;α为惯性系数;t为学习次数。
2 结果与分析
2.1 不同产地大米样品矿物元素含量的Fisher判别分析
为了验证筛选的产地特征矿物元素的判别效果,将与产地直接相关的元素Mg、Ca、Cr、Mn、Zn、As、Rb、Sr、Ag、Cd、Sb、Ba、La、Sm、Dy、Ho、Er、Pb、U和与母质土壤直接相关的元素Mg、Sr、Te、Nd、Gd、Yb、U(见表3)结合一起引入模型,建立Fisher判别模型。274 份样品分成训练集和测试集,选择2/3的样本用于作为训练集建立模型,选择1/3的样本作为测试集建立模型,得到判别结果见表4。
利用此判别模型对训练集内部判别结果表明,建三江、五常和查哈阳大米样品得正确判别率分别为62%、97%和86%,整体正确判别率为82%,交叉判别率79%。对测试集建三江、五常和查哈阳大米样品得正确判别率分别为83%、100%和80%,总体正确判别率为86%。

表3 2016—2018年不同产地大米样本中矿物元素含量
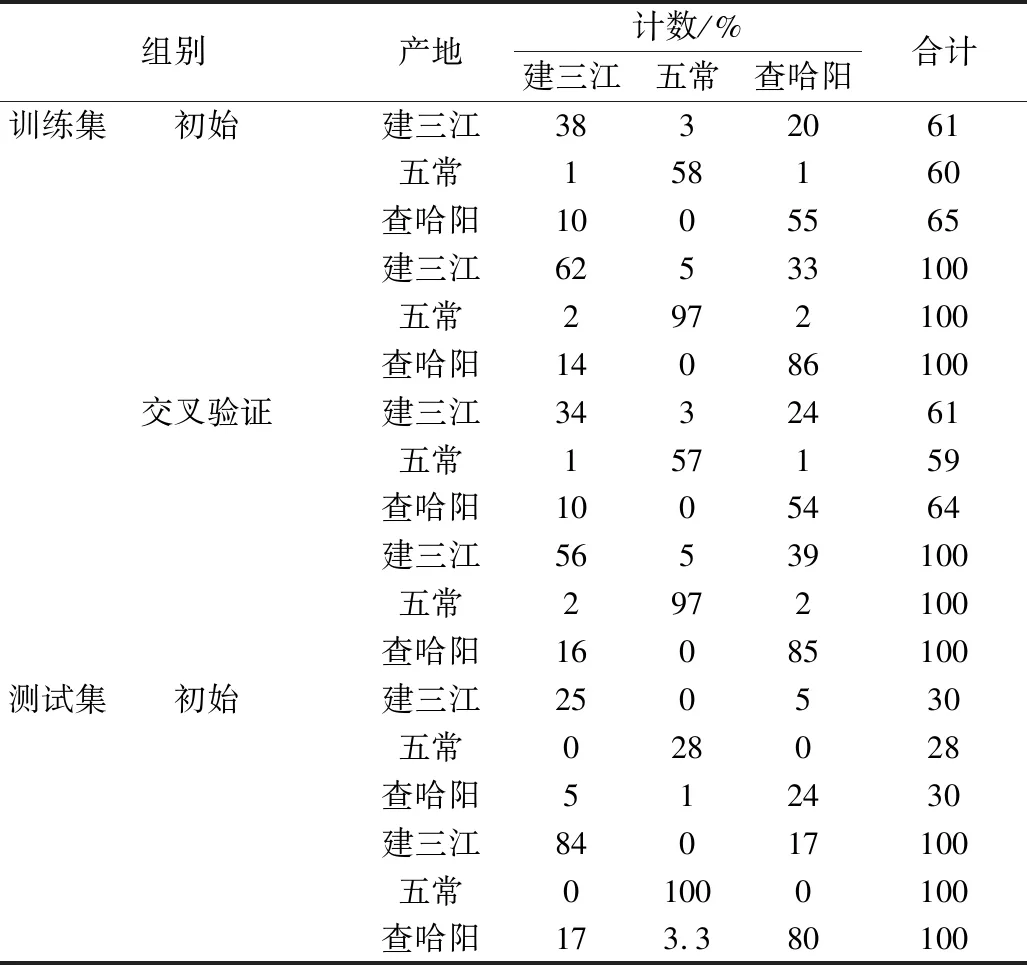
表4 不同产地Fisher判别函数分类结果
利用判别函数得分进行作图,由图2可以看出,五常大米分布区域比较清晰,查哈阳和建三江大米产地分布区域较为接近,有交叉现象。可能是由于SPSS判别分析属于有监督模式的线性分类算法,不能够准确有效的反映本研究检测的元素与大米产地之间存在的非线性映射关系,同时影响大米中元素含量因素多且复杂,与产地相关的因素还包括降水、气温、光照等因素。因此,仅从产地与元素之间的线性关系判别不能很好的体现因果关系和信息间的相互影响,为了更有效处理这些特征元素,采用更为具有非线性映射能力的人工神经网络建立预测模型进行产地判别。
2.2 基于前馈神经网络的产地判别分类仿真应用与结果分析
本研究选取实验得到的3类大米产地,其中1~93为建三江大米样本,94~177为五常大米样本,178~274为查哈阳大米样本,共计274 组实验样本,如表5所示。其中274用于该方法的训练,274 组用于测试。
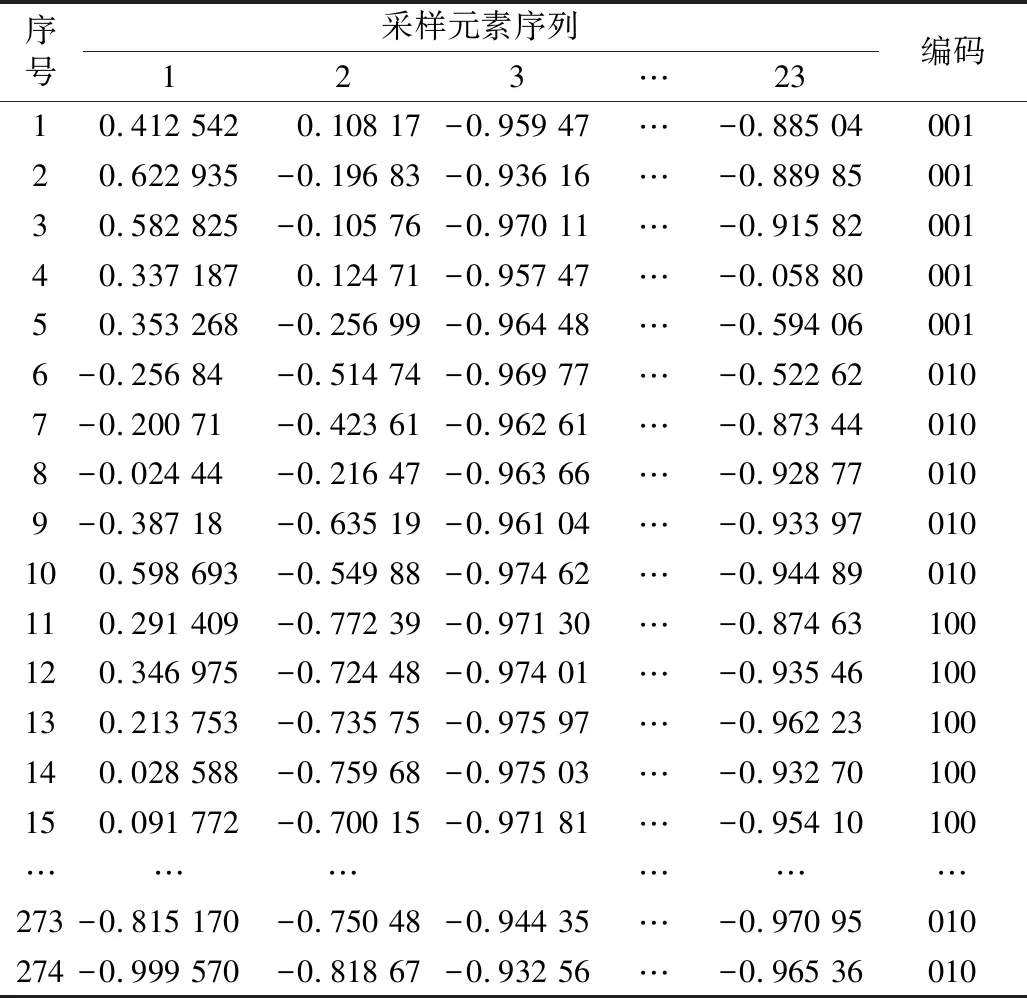
表5 样本信号(归一化)
2.2.1 确定网络结构和参数
对3类大米产地样本中矿物元素数据采集,由于提取了23 个有效特征空间的维数,即网络输入层节点数为23;输出层的节点数由分类类型空间的维数决定,研究中将类型分类的编码为100、010和001,分别表示查哈阳大米、五常大米和建三江大米,因此,输出节点数为3;根据Kolmogorov定理和大量实际训练经验,确定第一隐含层神经元节点为36 个,第二隐含层神经元节点为28 个;所以基于神经网络的大米产地识别分类的神经网络的拓扑结构为23-36-28-3 型。
2.2.2 网络训练学习过程
利用梯度下降算法求解最优解,选定274 组样本,定义训练目标迭代精度为0.01,学习速度0.8,惯性系数0.5,最大学习次数4 000 000,收敛情况如图3所示。
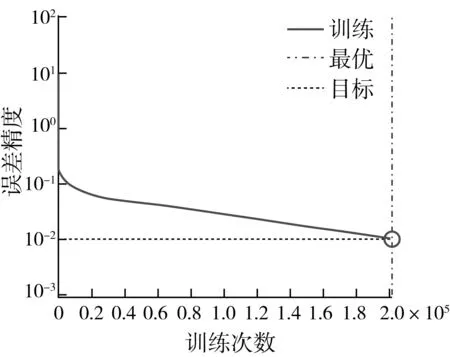
图3 大米产地分类网络收敛曲线
从训练效果上看,前馈神经网络迭代次数为201 412次,满足精度误差为0.01。在网络学习过程中,学习算法都是使网络达到设定精度,网络收敛比较稳定,并且符合误差限制要求。
2.2.3 仿真实例与结果分析
利用训练好的神经网络的大米产地自动分类方法,将274 组待测数据的筛选23 种矿物元素含量输入网络,并进行大米产地识别结果如表6所示。
从表6识别结果上看,274组数据的相对误差平均值为17.14%,网络的计算输出值和期望输出值的误差较小;3个产地的整体识别准确率为100%。实验表明:网络相对检测误差分散性较小,具有较好的泛化性和稳定性,是一种有效的大米产地识别方法。
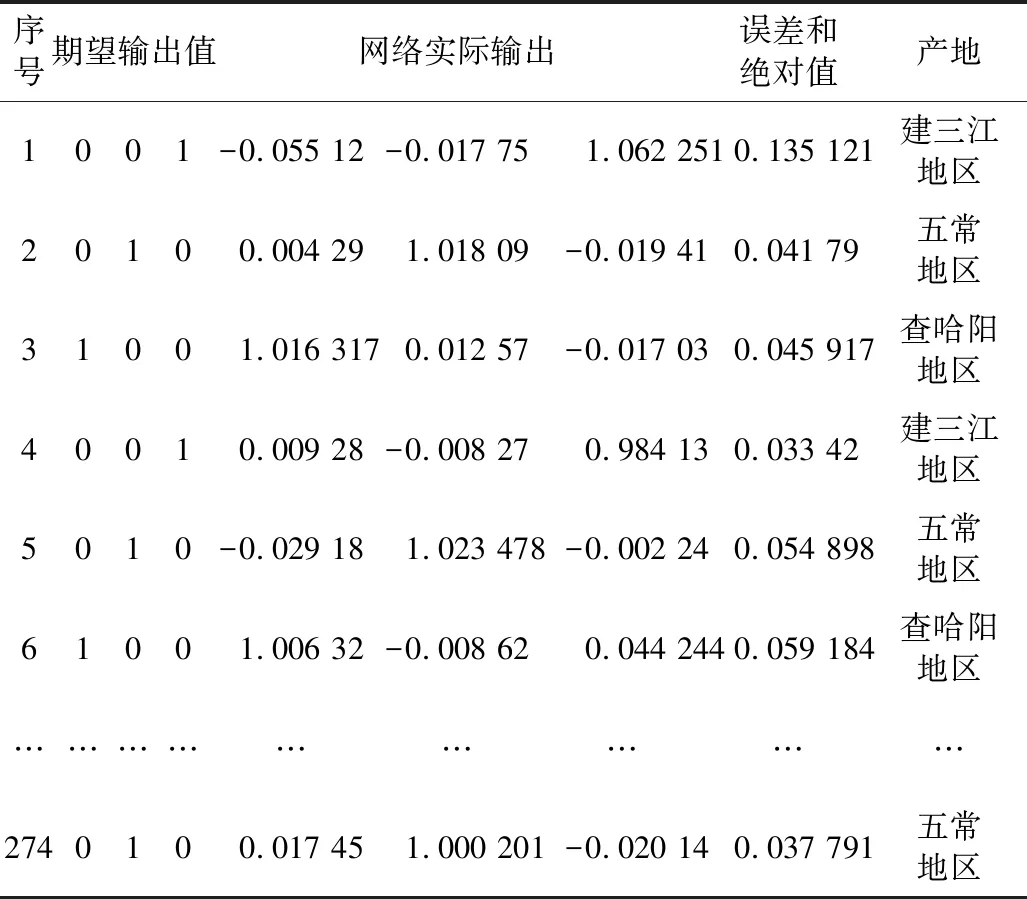
表6 大米产地识别结果
3 结论
研究通过连续3 年随机采集的五常、查哈阳和建三江地理保护区274 份样本,基于前期实验筛选到的与产地和母质土壤直接相关的23 种特征矿物元素分别建立了Fisher线性判别模型和前馈神经网络模型。
利用Fisher判别模型对训练集检验正确判别率为82%,交叉检验正确判别率为79%,测试集总体正确判别率为88%。前馈神经网络模型具有自适应性和稳定快速收敛特性。通过四层网络训练,得到拓扑结构为23-36-28-3 型前馈神经网络模型。该前馈神经网络对3个产地大米样本识别效果较好,解决了小距离相似自然环境产地样本难以识别的问题。
通过对比2种模型的判别效果得出,以筛选的23 种元素为依据,前馈神经网络模型较Fisher判别模型更具有适用性,可作为大米产地的智能识别模型。在下一步的研究中,将通过增加每一年的数据信息,修正模型参数,获得新的模型,验证大米不同产地的识别应用稳定性。
猜你喜欢
中国土壤与肥料(2021年5期)2021-12-02
空间科学学报(2020年4期)2020-04-22
活力(2019年17期)2019-11-26
电子制作(2019年10期)2019-06-17
中国外汇(2019年22期)2019-05-21
意林·全彩Color(2018年9期)2018-10-12
中成药(2018年8期)2018-08-29
中成药(2017年4期)2017-05-17
北京航空航天大学学报(2016年3期)2016-02-27
中国工程咨询(2016年2期)2016-02-14
