
基于改进YOLOv5s和TensorRT部署的鱼道过鱼监测
2022-02-08 13:31李健源柳春娜卢晓春吴必朗
农业机械学报 2022年12期
李健源 柳春娜 卢晓春 吴必朗
(1.三峡大学水利与环境学院, 宜昌 443002; 2.中国水利水电科学研究院, 北京 100038;3.中国水利水电科学研究院流域水循环模拟与调控国家重点实验室, 北京 100038)
0 引言
大坝的修建会导致河流纵向连通性消失,产生大坝阻隔效应,影响上下游种群基因交流[1]、降低河流生物多样性[2],尤其对洄游性鱼类产生的负面影响最为直接[3-4]。根据水利水电工程建设项目环境保护要求,需要建立减缓筑坝影响的环境保护措施[5],实施生态补偿,恢复河流生态系统健康。近些年,水利水电项目逐步开始建设鱼道工程作为大坝的连接通道,以协助鱼类洄游产卵、促进上下游种群基因交流[6-8],在鱼道的运行过程中需要开展过鱼监测[9],对验证鱼道的过鱼效果、提高鱼道的过鱼效率、优化运行方式,实现鱼道的科学管理,促进鱼类资源保护具有重要的理论意义。
目前,已有不少国内外学者开展了鱼道过鱼监测研究[10-14]。总体来看,国内外鱼道过鱼效果按监测方式可分为直接法和间接法两大类,其中人工观测、张网法、堵截法等属于直接法[15],虽然可以判断过鱼种类和数量[16],但过度依赖人工操作,效率和准确率较低、对鱼类干扰大,成本高。而声学和PIT遥测法等属于间接法[17-18],通过深度分析采集的数据,开展过鱼效果评估,其中过鱼数量的准确性取决于数据分析方法[19]。在分析现阶段常采用的监测技术方法差距后可以看出,现有监测技术方法难以满足过鱼监测的准确率和效率要求。
随着计算机视觉等多个领域取得重大突破[20],越来越多的深度学习算法在众多领域得到应用[21-23],为提高鱼道过鱼目标监测的准确率和效率提供了可行性。张亦弛等[24]通过卷积神经网络对水下声呐探测到的图像进行检测,但网络比较单一,检测的准确率比较低;王蓉蓉等[25]基于水下目标检测特征提取困难、目标漏检等问题,提出了一种改进的CenterNet算法,但模型检测速度较低,仅有7 f/s;强伟等[26]基于SSD目标检测算法,提出用ResNet网络代替VGG网络作为算法的特征提取网络,提高对水下复杂环境的检测精度和速度;李宝奇等[27]针对水下光学图像目标检测精度低的问题,提出了SSD-MV2SDB网络,有效提升了水下检测精度;陈宇梁等[28]针对光学图像在水中衰弱严重等问题,提出了YOLOv5s-underwater模型,有效提高了检测精度。但以上方法都是基于单一背景下的目标检测,在鱼道工程环境里,水下成像背景复杂,存在泥沙、树枝树叶等杂质漂浮物,大幅增加鱼道过鱼目标的检测难度。而且过鱼季节的天然河流水体浊度高,自然光在水体传播时易受吸收、反射和散射等影响,普遍存在成像效果对比度低、模糊等问题,导致鱼类特征信息匹配困难。同时,鱼道内的水流具有一定流速,在过鱼季节时,鱼类高速上溯通过鱼道,常伴有密集鱼群遮挡通过等问题,为动态目标的快速检测造成了难度。裴倩倩等[29]采用YOLOv3目标检测模型实现了鱼道内的检测,但不能解决复杂水体环境下的鱼类动态目标快速捕捉、密集鱼群遮挡识别问题,造成漏检、误检等现象。漏检和误检不利于科学评估鱼道过鱼效果,鱼道中常会通过一些珍稀物种[30],需要在其游动状态对目标进行快速准确检测。为提高检测网络精度,往往会在模型中添加注意力机制[31-32]或加深网络结构深度[33]来提升准确率,但随着添加注意力机制和网络的加深,模型的计算参数也会大幅度增加,导致模型处理速度下降[34-37],满足不了工程现场中实时检测的需求。
基于上述问题,本文针对鱼道水下环境复杂、特征信息匹配困难、准确率和效率低等问题对YOLOv5s网络模型进行改进。首先,针对鱼道工程现场复杂水体环境造成的图像模糊、过鱼目标检测困难的问题,提出将Swin Transformer (STR)作为检测层,提高模型对全局信息的捕获能力,加强对鱼类特征信息解码,以进一步优化模型的检测性能。其次,针对水下密集鱼群相互遮挡时,被遮挡目标易出现漏检的问题,提出ECA注意力机制作为C3的Bottleneck,提高网络对目标特征信息的提取能力,增强不同网络层之间特征信息的传递,提升模型检测精度,降低漏检率。然后,针对水下光学图像存在对比度低,检测目标定位差,造成模型不收敛的问题,利用Focal and efficient IOU loss(FIOU)作为模型损失函数,获得更加精确的框定位和使训练损失得到更快收敛,优化模型整体性能。最后,为提高模型的处理速度,将训练好的模型使用TensorRT框架部署进行优化,使模型达到最大的推理吞吐量和效率,以实现模型推理加速。
1 模型算法
1.1 YOLOv5模型
YOLOv5为一种高效、快速的单阶段目标检测算法,主要由输入端、主干提取网络、颈部网络、检测端4部分组成。输入端(Input)主要是图像的输入以及Mosaic数据增强。主干提取网络(Backbone)由卷积层(Conv)、瓶颈层(C3)和快速空间金字塔池化(Spatial pyramid pooling-fast,SPPF)构成。颈部网络(Neck)采用实例分割框架下的路径聚合网络结构(Path aggregation network,PANet)对网络进行特征加强。检测端(YOLO Head)将得到的特征图进行解码预测,输出检测目标的类别和位置。
1.2 改进YOLOv5模型
鱼类在水体中的姿态、形状会随着游动在不同时刻发生不同变化,为实现复杂水体环境下的动态目标快速检测,对YOLOv5模型进行改进,如图1所示,具体方案为:①在Neck结构,以Swin Transformer模块作为模型的检测层,增强模型对特征信息解码能力。②将C3模块的Bottleneck用ECA注意力机制代替,提高对图像有效特征信息的提取能力。③使用FIOU作为模型损失函数,优化模型回归性能。
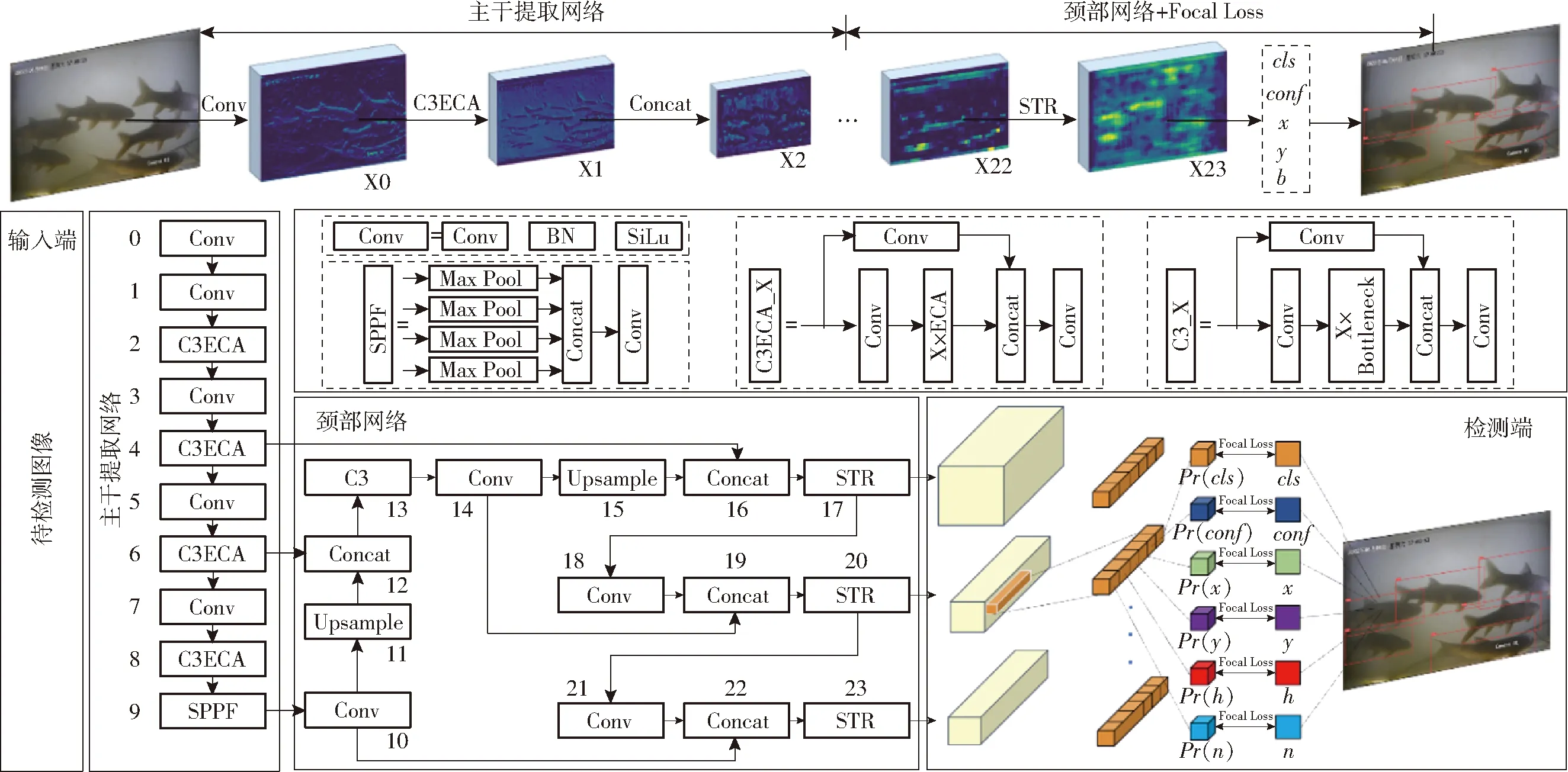
图1 本文算法框架Fig.1 Framework of algorithm model
1.2.1Swin Transformer模块
Swin Transformer[38]是一种窗口注意力模块,由窗口多头自注意力模型(Window multi-head self-attention modules,W-MSA)和滑动窗口多头自注意力模型(Shifted-window multi-head self-attention modules,SW-MSA)构成,是Transformer[39]结构的变体,如图2所示。其中LN表示层归一化,MLP是多层感知器,相邻块之间分别使用了W-MSA和SW-MSA模块,其利用多头自注意力机制有效运用同层次的多维度信息,有利于在复杂多样的目标场景中检测多尺度目标。因此,本文以Swin Transformer作为模型的检测层,通过该结构提高模型对于目标识别的泛化性。自注意力机制是STR的核心部分,计算公式为

图2 Swin Transformer 模块Fig.2 Swin Transformer module
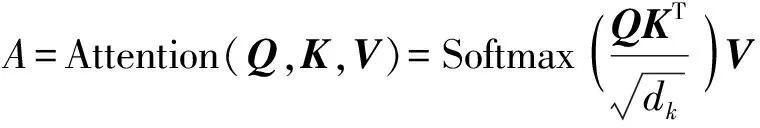
(1)
Z=contant(A1,A2,…,Aj)W
(2)
其中
(3)
式中Q——图像注意力查询向量
K——图像注意力键向量
V——图像注意力值向量
dk——向量Q和K的维度
W——线性化系数矩阵
Z——多头自注意力机制结合不同独立特征空间信息得到的深层次特征
A——自注意力机制
Softmax(t)——归一化指数函数
N——多类分类器类数
contant(A1,A2,…,Aj)——不同自注意力机制容器
1.2.2ECA结构
鱼群通过时,易相互遮挡,被遮挡目标有效信息少,为充分挖掘有限信息,减少漏检现象,本文将Efficient channel attention(ECA)[40]代替主干网络C3模块的Bottleneck。ECA(图3,图中χ表示特征图)是一种极其轻量级的通道注意模块,主要提出了一种不降维的局部跨信道交互策略和自适应选择一维卷积核大小的方法,可以减少模型的计算参数量并提升检测精度。自适应卷积核k的计算式为
(4)
式中 |t|odd——距离t最近的奇数
C——通道数

图3 ECA注意力机制Fig.3 ECA attention mechanism

图4 TensorRT优化流程图Fig.4 TensorRT optimization process
1.2.3Focal and efficient IOU loss
YOLO作为典型的one-stage网络模型,为了提高检测速度[41],相对于two-stage目标检测模型[42],舍弃了生成候选框这一阶段,缺少了对anchor box的筛选过程,导致目标定位生成的锚框正负样本不平衡,而且YOLOv5原本使用的Generalized intersection over union loss (GIOU)[43]在预测框和真实框重合时,无法区分预测框和真实框的位置关系,预测框与真实框之间的误差较大。因此本文使用Focal and efficient IOU loss(FIOU)[44]作为模型损失函数,其通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本,优化目标框定位,提升收敛速度,FIOU损失计算式为
LFIOU=IOUγLEIOU
(5)
其中
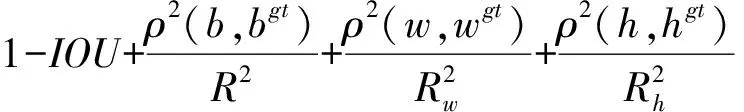
(6)
(7)
式中IOU——边界框与真实框进行交并比
b——预测框中心点
bgt——真实框中心点γ——超参数
w——预测框宽度wgt——真实框宽度
h——预测框高度ρ——两点间欧氏距离
hgt——真实框高度
Rw、Rh——能够同时包含预测框和真实框的最小闭包区域宽度、高度
R——能够同时包含预测框和真实框的最小闭包区域的对角线距离
1.3 TensorRT的加速网络
为提高模型的处理速度,采用TensorRT框架部署进行优化。TensorRT是NVIDIA推出的高效推理引擎,其包含2个阶段:构建(build)和部署(deployment)。在构建阶段,TensorRT对神经网络图(Neural network graph)进行了几个重要的转换和优化:①消除未使用的输出的层以避免不必要的计算。②将Convolution、Bias和ReLU层融合形成单个层,主要是垂直层融合和水平层融合,减少计算步骤和传输时间,如图4所示。在部署阶段,TensorRT以最小化延迟和最大化吞吐量运行优化了的网络。将训练好的.pt权重通过C语言转换为引擎文件.engine和动态库.dll,将其部署在网络中可使模型获得加速推理。
2 数据集与模型评价方法
2.1 复杂水体数据集
深度学习目标需要大量的数据集支撑,且在所需检测场景下,数据采集对该场景的目标检测效果往往具有决定性作用。因此本文数据集分别在西藏自治区某鱼类增殖站、水产科学研究所和某水电站自行采集所得,采集后的数据集经过人工剔除冗余、像素质量差图像,共3 000幅鱼类图像。将图像数据使用LabelImg标注后使用脚本转换为YOLOv5训练格式文件,并将其按比例8∶2随机构建训练集和验证集。
2.2 评价指标
为客观评价不同模型算法对鱼类目标的检测性能,采用准确率(Precision)、召回率(Recall)、平均精度均值(mAP)、参数量(Params)以及单幅图像平均处理时间综合衡量模型。准确率可以衡量模型预测正确的比例;召回率衡量模型预测正确的目标比例;平均精度均值衡量模型的整体性能;参数量衡量计算内存资源的消耗;图像平均处理时间衡量模型的实时性。
3 实验
3.1 实验平台
实验基于Windows 10,CPU处理器为Intel(R)i7-11800H、GPU为GeForce RTX3080显卡(显存为16GB),在Pytorch 1.9深度学习框架进行训练,选用YOLOv5s模型进行实验,具体环境配置和模型训练参数见表1。
3.2 消融实验
为验证本文研究对YOLOv5s提出3种改进策略的有效性和先进性,在相同实验平台的基础上,进行8组消融实验,并采用同一验证集进行验证,评估不同改进对模型性能的影响。
通过表2可以看出不同的改进策略对原YOLOv5s模型性能均有不同程度的提升,结果表明,模型B召回率虽有微小降低,但准确率得到大幅提高,mAP较模型A提升2.3个百分点,计算参数量减少0.62 MB,使得处理时间减少2.7 ms,证明将ECA注意力机制作为主干特征提取网络中C3结构的Bottleneck在减轻模型计算参数量的同时可以更好地提取目标特征信息,提升检测精度。将STR作为检测层,模型召回率得到改善,mAP提升3.3个百分点,模型解码能力得到加强,提升了模型对目标的检测能力。从图5a可以看出,模型用FIOU作为模型损失函数后,目标框训练损失值得到了有效降低,虽然mAP没有得到提高,但检测速度得到了大幅提升,解决了模型不收敛、定位框不准确的问题。从图5b可以看出,本文改进的算法较其它模型,整体的mAP达到最优,为91.9%,较YOLOv5s提升4.8个百分点,且没有为提升检测精度而牺牲检测速度,模型单幅图像检测时间为10.4 ms。

表1 实验平台参数配置Tab.1 Parameter configuration of experimental platform
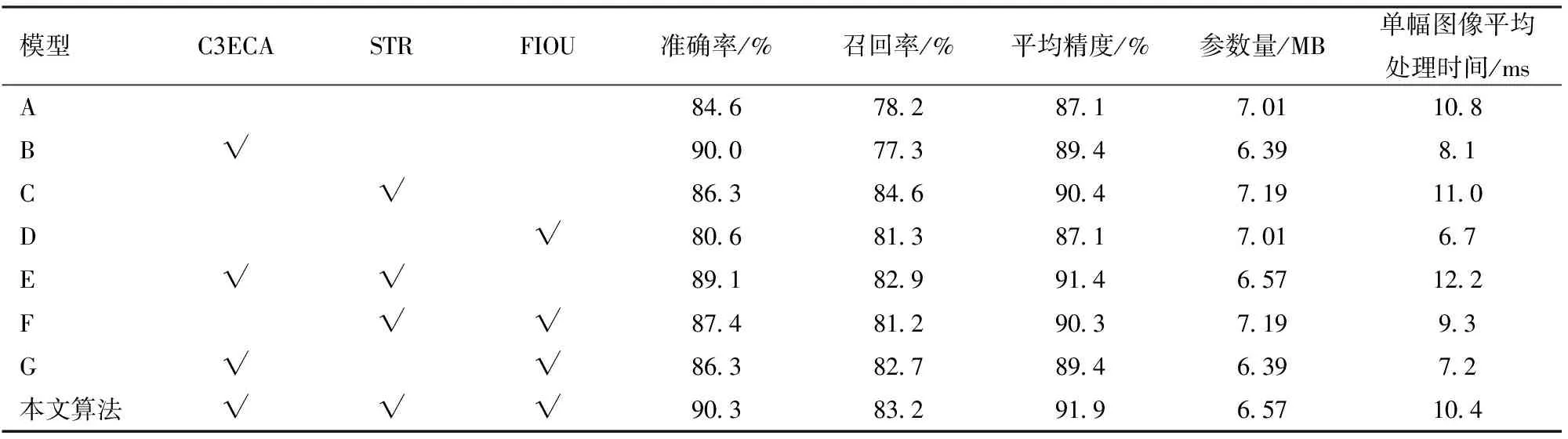
表2 消融实验评估Tab.2 Evaluation form of ablation experiment
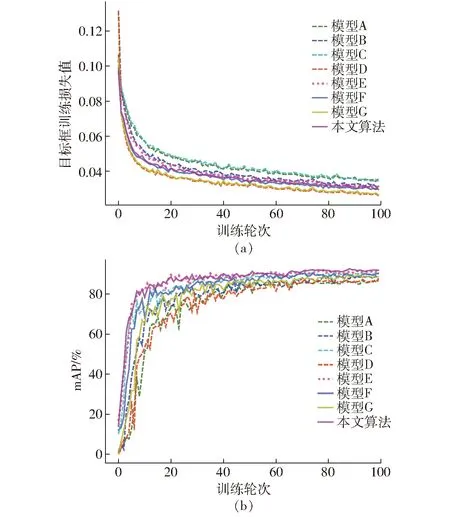
图5 消融实验训练损失值和mAPFig.5 Ablation experiment training loss and mAP

图6 YOLOv5s和本文算法检测效果对比Fig.6 Comparison between YOLOv5s and proposed algorithm
3.3 算法准确性分析
为检验本文算法改进的准确性,随机抽取某水电站鱼道过鱼季节图像作为YOLOv5s和本文算法的测试集。图6为该水电站鱼道过鱼实际拍摄图的检测结果,图6a在密集鱼群相互遮挡时,因图像信息少,YOLOv5s产生漏检的情况,而本文算法并未发生漏检;图6b在微小目标模糊场景下,YOLOv5s未能检测出图像中间模糊的小目标鱼类,本文算法成功的检测出小目标鱼类;在图6c水下场景复杂,树枝等杂质漂浮物与目标鱼类重叠,容易将鱼类与杂质混淆,在水体浊度较大的情况下,YOLOv5s将左下的树枝阴影识别成鱼类,而本文算法则完成了正确的检测和识别。
综上,本文算法有效提高了算法在浑浊水体下对目标的检测能力,减少了因鱼群遮挡、模糊和有效信息少造成漏检的情况,并有效提升了模型精度,鲁棒性更强,能够适应复杂的水下环境。
3.4 算法对比实验分析
为进一步验证本文提出的改进算法在复杂水体下鱼道过鱼监测识别能力优于其它目标检测算法,使用相同复杂水体数据集对SSD、Faster R-CNN、YOLOv4、YOLOv5s和YOLOv5x在同一实验平台进行训练和验证,主要测试其检测精度和速度,结果如表3所示。从表3可以看出,与其它算法相比,本文提出的改进YOLOv5s算法在mAP取得了最优值。YOLOv5x通过增加网络的深度使得模型的mAP得到一定的提升,但模型参数计算量也随着模型深度的增加而增加,导致模型处理速度比YOLOv5s增加了一倍。而本文算法在保证处理速度的前提下,提高了模型的mAP等各项指标,进一步证明了本文算法在检测性能上具有更高的优势,更适合完成复杂水体下鱼道过鱼目标检测。
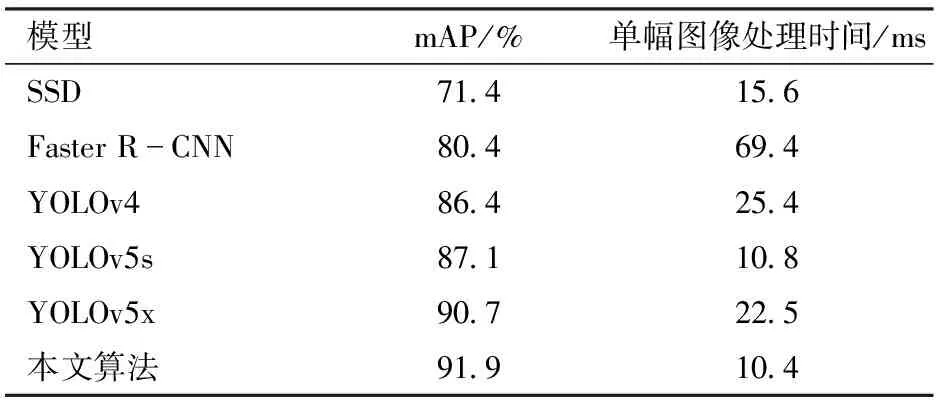
表3 主流算法实验评估结果Tab.3 Experimental evaluation results of mainstream algorithms
3.5 TensorRT部署
目前YOLOv5网络模型转TensorRT有两种方式:①直接使用YOLOv5自带的转换脚本转换成onnx形式后直接生成.engine文件(方式1),这种比较便捷直接,但模型推理速度优化有一定局限性。②本文的转换方式,首先通过C语言对YOLOv5进行编译,然后生成.engine引擎文件和.dll动态链接库进行部署(方式2)。选取100幅图像分别对推理加速前、方式1推理加速以及方式2推理加速进行测试,得到的推理效率结果见图7。从图7可以看出,将模型部署为TensorRT后推理速度均可得到大幅提升。原始YOLOv5s模型每幅图像平均推理时间为10.8 ms,本文算法为10.4 ms,使用方式1的方法将模型部署为TensorRT后,2个模型的推理速度分别提升2.6倍和2.3倍,而使用本文的方式将模型部署为TensorRT,推理速度达到2.6、2.3 ms,相比转换前,模型推理速度提高4倍多,该方式可以有效解决模型检测速度慢或者因改进模型而降低处理速度的问题,优化计算损耗。

图7 TensorRT部署推理时间对比Fig.7 Comparison of TensorRT deployment reasoning time
3.6 讨论
本文对YOLOv5s进行了改进,检测精度和处理速度均为侧重点,表2为消融实验验证不同改进对算法的影响。每个改进模块对模型提升的效果均不一样,YOLOv5s在添加ECA模块后(模型 B),其准确率大幅度提升,对目标的特征匹配能力增强,但召回率有所下降。召回率衡量实际为正的样本中被预测为正样本的概率,是不可忽略的一部分。而实验中发现,YOLOv5s将STR作为检测层后能有效提高模型的召回率(模型 C),因此将两者组合起来后,进行了互补,模型(模型 E)的精确度mAP得到了进一步提高,但模型的平均处理速度却降低了,虽然在准确率和召回率提高的情况下,推理速度增加的时间是可以接受的,并不影响在鱼道工程中的过鱼实时检测。但为了不牺牲检测效率提升模型精度,本文对模型的损失函数进行了更换(模型 D),发现FIOU作为损失函数后模型的精度提升可以忽略不计,但处理速度却提高1.6倍。因此将3种改进措施进行组合(本文算法),实验结果表明,本文算法在检测精度、能力、计算消耗和处理速度4个指标上均优于YOLOv5s,在恶劣环境下本文算法具有更好的性能,可以很好地解决水下环境复杂、特征信息匹配困难、准确率和效率低等问题。如图6所示,在鱼群遮挡、图像模糊、有效信息少的情况下,与YOLOv5s相比,本文算法在目标定位和检测能力等方面都有很大提升。然而,当环境过于复杂、目标鱼类较小时,本文的模型仍然可能存在漏检。如图8所示,图像中左边的鱼类头部没有被检测出来。且在实验的过程中发现,虽然对树枝等杂质漂浮物误识别的概率大幅度降低,但该现象还会偶尔发生。出现这种现象可能的原因有:①数据集不够丰富,对训练中没有出现的微小目标鱼类识别困难。②数据集中没有添加负样本,导致将树枝等杂质容易识别成目标鱼类。未来,针对微小目标鱼类识别困难的问题,可以对数据集进行扩充,针对性的添加微小目标鱼类图像,通过提高样本类型的丰富性和实时性来提高模型的鲁棒性;针对误识别的问题,可以在训练集中添加负样本,如添加各种杂质和漂浮物(特别是树枝和树叶)样本,可以避免误检,提高目标鱼类的检测精度。

图8 YOLOv5s和本文算法漏检现象Fig.8 Missing detection of YOLOv5s and proposed algorithm
此外,本文通过C语言转换的方式对模型进行TensorRT部署,避免不必要的计算,使推理速度大幅度提升。图9为本文算法使用TensorRT部署前后的检测效果,可以看出两者的检测性能和推理生成的定位框几乎没有任何的差异,故本文方法将模型部署为TensorRT不会影响其检测精度。

图9 TensorRT部署前后检测效果Fig.9 Detection effect before and after TensorRT deployment
4 结论
(1)为解决传统鱼道监测方式过度依赖人工、对鱼类干扰大以及现阶段技术对复杂水体下的鱼道过鱼监测效率低、准确率差等问题,提出了一种基于YOLOv5模型改进的复杂水体鱼道检测算法,并将其部署在TensorRT上,相比其它算法模型,本文算法在各指标均表现出强大的优势。
(2)针对水下环境复杂,检测目标困难的问题,将STR作为模型检测层,提高了检测能力;将轻量级注意力ECA作为C3模块Bottleneck,加强模型特征提取能力,减轻了计算参数量并提升了模型检测精度;使用FIOU作为损失函数,使模型预测框更精确;将本文算法部署于TensorRT,优化模型结构,降低计算损耗,处理速度得到大幅度提升。
(3)实验结果表明,本文算法的准确率、召回率、平均精度均值均有提升,mAP达到91.9%,较YOLOv5s提升4.8个百分点,具有更好的检测性能,使用TensorRT部署后模型处理时间可以达到每幅图像2.3 ms,提高4.5倍。
猜你喜欢
海洋信息技术与应用(2022年1期)2022-06-05
农业工程学报(2022年4期)2022-04-24
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
河北农业大学学报(2020年6期)2021-01-08
儿童时代·幸福宝宝(2020年9期)2020-09-08
卷宗(2020年16期)2020-08-10
科教导刊·电子版(2020年13期)2020-08-09
中国交通信息化(2018年5期)2018-08-21
