
基于CT图像和RAUNet-3D的玉米籽粒三维结构测量
2022-02-08 13:31杜建军李大壮廖生进卢宪菊郭新宇赵春江
农业机械学报 2022年12期
杜建军 李大壮 廖生进 卢宪菊 郭新宇 赵春江
(1.国家农业信息化工程技术研究中心, 北京 100097; 2.数字植物北京市重点实验室, 北京 100097;3.华中农业大学植物科学技术学院, 武汉 430070)
0 引言
玉米产量和品质与籽粒构成和相对比例直接相关[1]。玉米籽粒包含表皮、胚、胚乳和空腔等结构,这些结构和成分通常无法直接获取,只能通过破坏性方式观察内部结构,获取定性描述和有限的定量指标。一种直接的人工测量方式,是利用刀片来分离籽粒胚和胚乳,然后测量质量、体积等参数[2],该方式人工成本高、耗时长、精度低、主观性强。另一种破坏性测量方式,是仅切割出籽粒的特征断面,然后利用可见光成像方式获得断面图像,进而提取和分析该断面上籽粒胚和胚乳信息[3]。然而,这种方式只能获取二维指标,且对籽粒切割位置非常敏感,无法准确反映籽粒真实三维结构。另外,籽粒空腔也是反映籽粒物理和生理特性的重要性状,与籽粒耐破碎性、爆裂性和硬度等紧密相关[4-5],上述方式均无法测量。
目前,CT无损成像技术已在植物表型组学研究中逐渐推广应用[5-13],在玉米籽粒内部结构和成分的研究已有相关应用[14]。相关研究[4,15-17]大多使用Micro-CT进行单粒扫描来获取上百幅CT图像,然后通过人工逐层勾选目标轮廓,或者借助商业化软件进行半自动化分析,不仅耗时耗力,而且交互过程具有极大主观性。可以看出,CT成像已成为研究籽粒精细结构和成分的最重要手段,但迫切需要解决扫描成像效率低、表型测量自动化程度低和鲁棒性差等问题。
就CT扫描效率而言,对批量籽粒一次性扫描成像不仅可成倍提高扫描通量,而且保证了成像参数和环境条件一致性。因此,将获取的批量籽粒CT图像处理问题转化为单颗籽粒(实例)分割问题,即从粘连籽粒中准确拆分出高质量的单颗籽粒。就籽粒表型测量方法而言,对单颗籽粒成分分析也可转化为对籽粒内部特征最显著的胚和空腔成分的语义分割问题。目前,已涌现了大量基于卷积网络的二维分割网络(UNet[18]、SegNet[19]等)和三维分割网络(UNet-3D[20]、VNet[21]等),在植物学和医学的CT图像分析中取得了成功。如SOLTANINEJAD等[22]设计了多损失多尺度的3D卷积网络,能不需要交互地完全自动分割根系CT数据,GHAFFARI等[23]使用改进的级联密集连接UNet-3D从脑CT中自动分割出肿瘤。因此,训练、评估基于卷积神经网络的语义分割模型,构建全自动玉米籽粒表型分析管道,无损、高效、准确提取籽粒内部结构和成分,在玉米籽粒品种和品质精准鉴定以及表型-基因型的关联分析[24-25]方面均具有重要应用价值。
本文使用Micro-CT批量籽粒扫描方式获取CT图像,使用分水岭算法自动提取单颗籽粒,利用改进的UNet-3D网络提取籽粒胚,并整合为自动化表型分析管道,快速提取23项籽粒结构和成分性状,并用于不同玉米品种籽粒性状统计分析和表型鉴定。
1 数据获取
1.1 CT扫描
试验选取的玉米品种包括:登海605(DH605)、京科968(JK968)、先正达408(XZD408)和农华5号(NH5)。挑选表面无破损的120颗玉米籽粒,使用Micro-CT设备(SkyScan 1172,美国Bruker公司)获取籽粒CT图像。
使用批量扫描的方式提高籽粒成像效率。由于籽粒大小不同,每次在泡沫圆盘(直径30 mm)上放置6~8颗籽粒,用双面胶固定(图1a),并且籽粒之间尽可能保持分离,便于后续图像处理。在Mirco-CT扫描过程中,在每个旋转角度均可获得投影图(图1b),使用配套的重构软件CT Scan NRecon(美国Bruker 公司,版本1.6.9.4)进行断层图像重构和图像导出。本试验采用的扫描和重建参数如表1所示,对120颗玉米籽粒分批次扫描20次,每次可导出500幅1 000像素×1 000像素的8位BMP格式的图像序列(图1c)。平均单粒CT扫描成像时间为1 min。

图1 Micro-CT图像获取与三维可视化Fig.1 Image acquisition and 3D visualization based on Micro-CT
1.2 单籽粒拆分
CT图像中包含有多颗籽粒,本文使用三维分水岭算法[26]直接提取出每颗籽粒的三维CT图像。然而,直接在原始尺寸的籽粒三维图像上应用三维分水岭算法对内存要求太高,因此首先对原始图像2倍下采样,下采样后的三维图像尺寸为250像素×500像素×500像素。通过大津算法[27]自动确定阈值并二值化,并通过形态学操作移除籽粒内部的孔洞获得图像掩码(图1e),进而通过距离变换,将每个连通域标记为一个种子点,在图像掩码上实现三维分水岭分割(图1f)。分割结果与原图像进行“与”运算即可提取出单颗籽粒CT图像。120个单籽粒CT图像中最大籽粒尺寸为150像素×200像素×200像素,因此使用该尺寸从原图像中分别裁剪出籽粒图像(图1g)。使用光线投射算法[28]对单籽粒CT图像序列进行体绘制三维重建(图1h),可以观察到籽粒胚和胚乳间具有较明显的结构和形态差异。
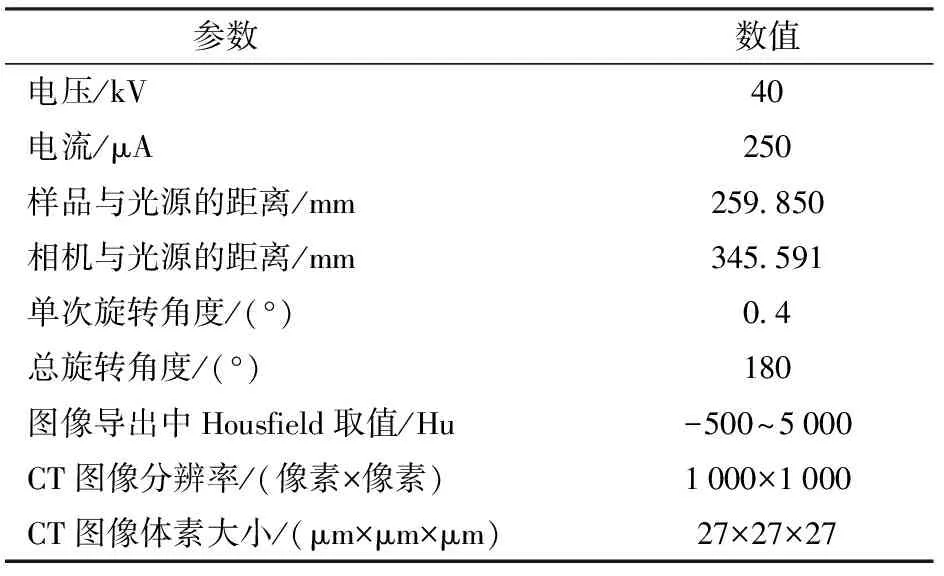
表1 Micro-CT扫描与重建参数Tab.1 Scanning and reconstruction parameters of Micro-CT
2 籽粒表型管道
基于单籽粒CT图像构建的玉米籽粒表型分析管道如图2所示,依次提取出籽粒、籽粒胚、胚乳和空腔结构,并计算其性状。在单颗籽粒CT图像中,胚的像素灰度较大,特征明显,易于识别和标注;胚乳和胚紧密相连,胚乳可通过胚来计算;而空腔为籽粒内部像素灰度极低的连通区域,可以设置阈值直接分割。因此,提出一种基于残差连接和注意力机制的三维分割网络Residual_ Attention_Unet-3D(RAUNet-3D),基于标注的少量籽粒胚数据,训练出较高精度的籽粒胚分割模型。进而,使用图像算术和形态学运算将单颗籽粒分解为胚、胚乳和空腔等语义的三维图像。最后,基于目标掩码图像和基于Marching Cube(MC)[29]算法表面重建后的目标表面模型,实现籽粒各语义对象的性状提取。
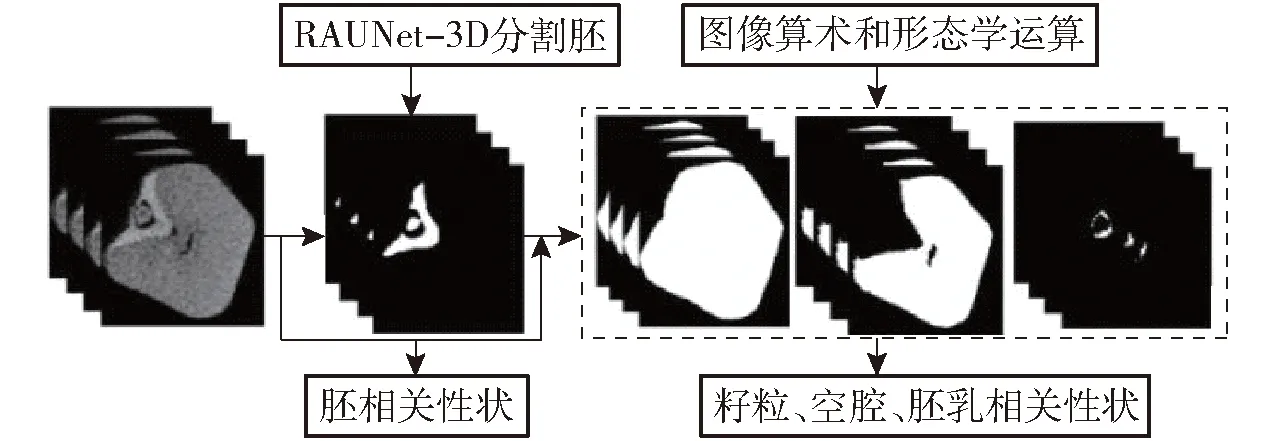
图2 籽粒表型管道主要流程图Fig.2 Main flow chart of corn kernel pipeline
2.1 RAUNet-3D分割胚
2.1.1数据标注
在120颗籽粒CT图像中,使用开源软件ITK-SNAP(3.6.0)对50颗籽粒图像中的胚进行人工交互式标注。标注流程如下:首先,人工选取胚所在区域(图3a中的红框),调整二值化阈值初步提取出胚(图3b);然后人工选择种子点进行区域增长,保证胚的完整性(图3c、3d);在此基础上,使用笔刷、形态学运算等工具逐层精细调整掩码(图3e);最后,导出籽粒CT图像(图3f)对应的胚标签(图3g)。使用随机旋转操作对标注好的50个籽粒CT及其标签图像进行数据增广,将数据集扩充至100个,并按照比例8∶2随机划分为训练集和测试集。
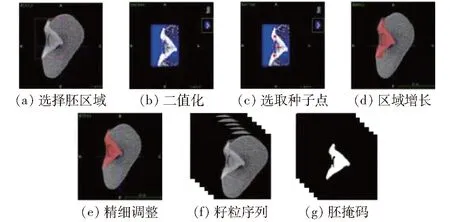
图3 使用ITK-SNAP数据标注过程Fig.3 Data annotation process using ITK-SNAP
2.1.2网络结构
图4 RAUNet-3D架构Fig.4 RAUNet-3D architecture
UNet-2D和UNet-3D是经典的基于UNet的二维和三维语义分割模型,均由编码器和解码器组成,通过在解码阶段合并相应的编码特征,有效提高语义分割精度,并且基于较少的训练样本数据集也能训练出精度较高的语义分割模型。UNet-2D和UNet-3D的区别主要在于特征抽取过程中是否利用了目标的图像层间信息。UNet-3D实现三维图像的端到端分割,使用3D卷积充分捕获目标空间信息,有效提高语义分割精度。本文提出的RAUNet-3D三维分割网络,主要是在原始UNet-3D网络基础上添加残差连接和注意力机制,网络结构如图4所示。该端到端网络由编码器和解码器组成,输入32×96×96的CT图像,输出32×96×96的胚掩码。网络分为4层,在编码阶段进行3次下采样,在解码阶段进行3次上采样,每层由通过残差相连接的两个Conv3D-BN-ReLU模块构成(图4中Residual Convolution模块),该残差模块能有效防止网络退化和加速网络收敛。每层卷积核数目分别为32、64、96和128。
在解码阶段中嵌入注意力模块,用于从合并过来的下采样特征中提取对恢复胚掩码较重要的特征。图4中的Attention Gate为注意力模块,g为解码阶段上采样的特征,x为编码阶段产生的需要合并至上采样过程中的特征。首先,对g和x应用1×1×1的卷积,将通道数调整一致(设置为32);然后,将张量对应位置元素相加,并通过ReLU激活;最后,利用1×1×1卷积为下采样特征x的每个通道训练一个权重,经过张量相乘后得到注意力模块输出的下采样特征。
RAUNet-3D中的基本运算包括3D卷积、Batch Normalization和ReLU。其中,3D卷积可以同时对连续多层CT图像进行特征提取;Batch Normalization在一个Batch的每个通道上对3D卷积后的数据进行归一化,避免数据分布过于分散;ReLU激活函数能增加网络的非线性拟合能力,相较于sigmod函数与tanh函数,ReLU计算简单且克服了梯度消失问题。下采样和上采样分别采用3D最大值池化(MaxPool3d)和逆卷积(ConvTranspose3d)的方式。
2.1.3网络训练
计算环境CPU为Intel(R) Xeon(R) E5-2699,256GB RAM,操作系统为Ubuntu 20.04.2,显卡为RTX2080Ti(11GB显存),深度学习框架为pytorch-gpu1.7,Python版本为3.8.8。Epoch设置为300,学习率设置为0.000 1,Batch_size为8,采用适应性矩估计(Adaptive momentum estimation,Adam)优化算法进行训练,损失函数采用Dice_Loss,公式为
(1)
式中X——预测像素点集
Y——真实像素点集
LDice——Dice_Loss函数
利用骰子系数(Dice similarity coefficient,DICE)和交并比(Intersection over union,IoU)评估网络精度,计算公式分别为
(2)
(3)
式中DICE——骰子系数IoU——交并比
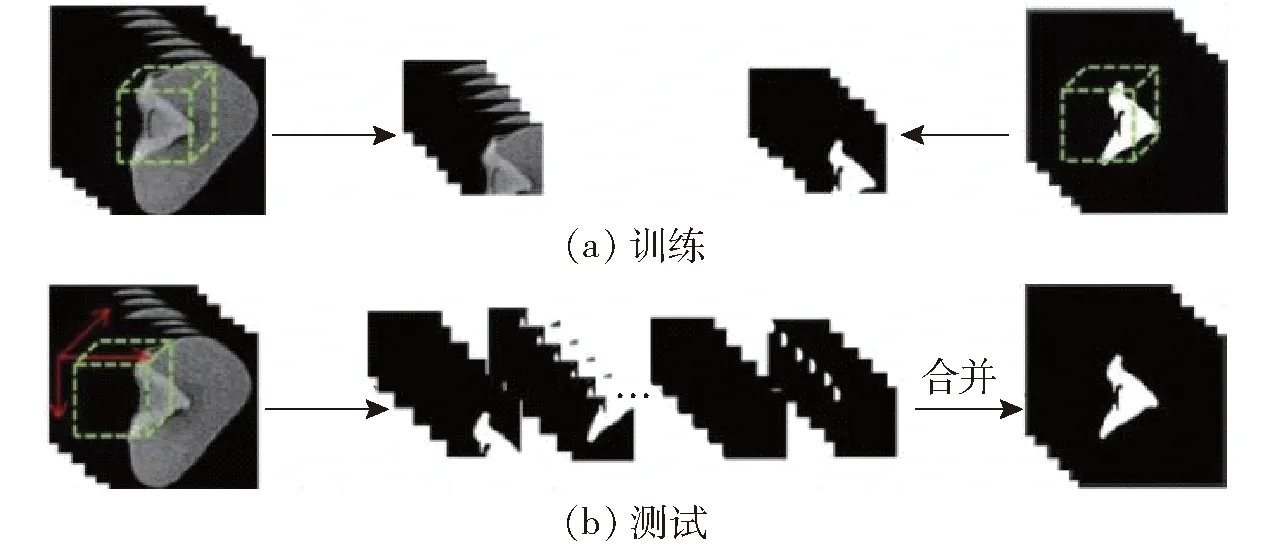
图5 训练和测试的数据处理Fig.5 Data processing for training and testing
在模型训练和推理阶段,均采用分块方式处理输入图像。在模型训练阶段,从原始CT图像和其标签中随机采样32×96×96的体数据输入网络(图5a)。在模型推理阶段,以(32,64,64)为步长从输入CT体数据中依次提取出32×96×96的体数据,输入分割网络进行推理,最后将分割结果按照实际位置合并,得到籽粒胚的掩码图像(图5b)。
2.2 籽粒胚乳和空腔分割
图6为从单颗籽粒中提取玉米内部成分和结构的流程图,图中红色、蓝色、紫色和绿色箭头分别表示胚、胚乳、空腔和籽粒的分割和表面重建流程。首先将单颗籽粒CT图像输入到RAUNet-3D网络,自动分割出胚掩码。然后,对单颗籽粒CT图像进行灰度直方图分析,利用大津算法确定二值化阈值并获得籽粒掩码图像,进而生成籽粒外轮廓包围的掩码图像。最后,通过上述掩码间算术运算分别得到胚乳和空腔的掩码图像。在当前图像分辨率条件下,籽粒表皮与胚乳几乎融为一体,经过多次实验,将籽粒腐蚀2个像素可去除表皮。
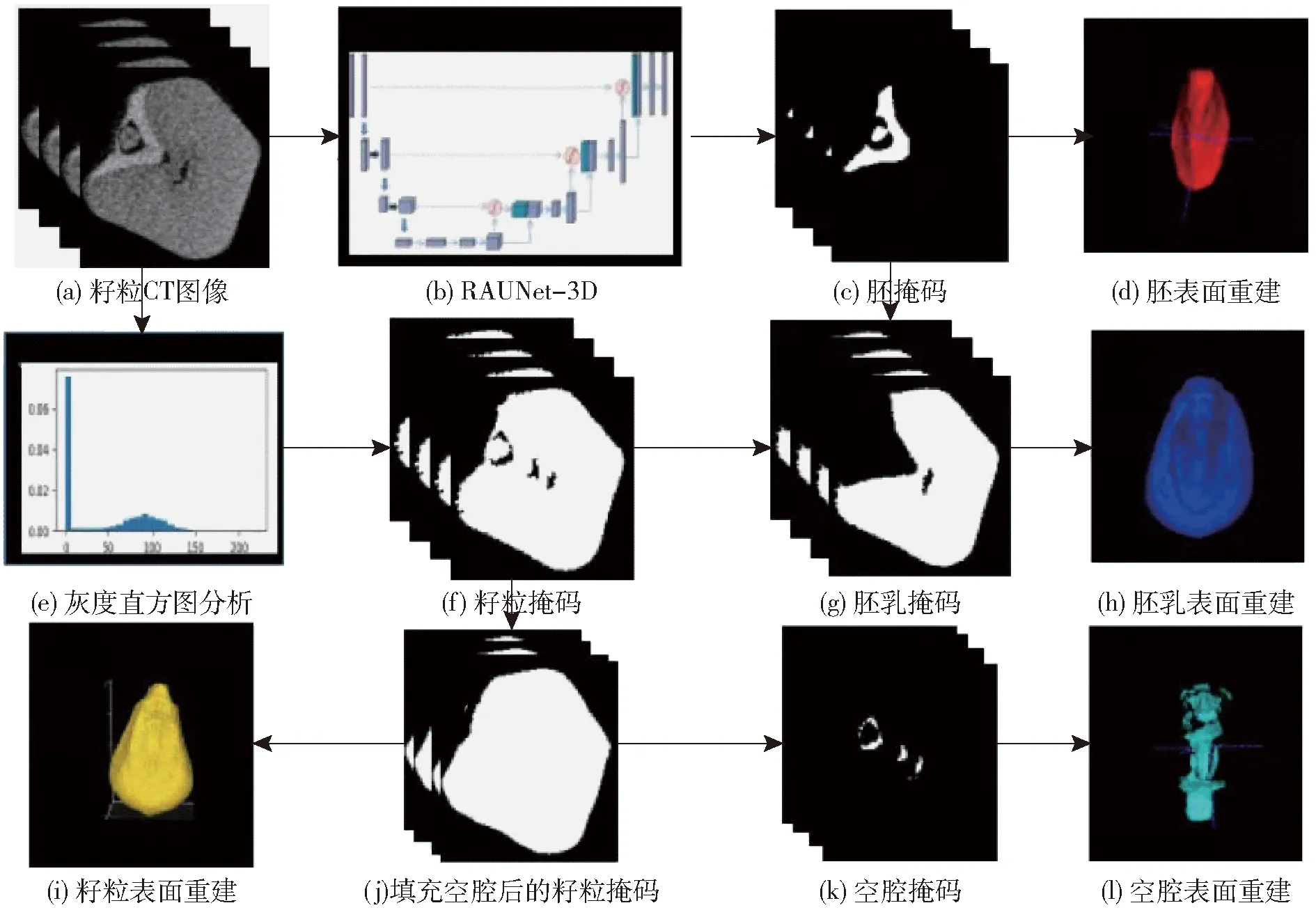
图6 籽粒三维性状提取管道Fig.6 3D structural analysis pipeline of corn kernel
2.3 籽粒表型提取
基于CT图像计算的籽粒及其内部结构的性状主要分为2类:像素灰度和几何形态。像素灰度反映物质对X射线的吸收特性[30],可使用灰度均值和灰度标准差表示。籽粒胚和胚乳的掩码分别与原始图像进行“与”运算,可以得到籽粒胚和胚乳图像。用于计算灰度均值和标准差。灰度均值GM和灰度标准差GSD计算公式分别为
(4)
(5)
式中g(i)——第i个体素的灰度
n——体素个数
几何形态性状包括表面积、体积以及粒长、粒宽和粒厚等。可以分别利用MC算法重建后的三维表面模型或者掩码的三维图像来计算。其中,籽粒、胚、胚乳和空腔的三维表面模型(图6l、6k、6j、6i)分别是掩码(图6g、6c、6d、6h)重建的结果,可用于计算表面积。计算过程为:设表面模型上单个三角形的顶点坐标分别为A1(x1,y1,z1)、A2(x2,y2,z2)、A3(x3,y3,z3),根据欧几里德公式计算三角形的边长为a、b和c,再由海伦公式计算三角形面积为s。三维表面模型的表面积为所有三角形面积之和S。计算式为
(6)
根据目标掩码三维图像直接计算目标体积,计算公式为
V=CobjVvoxel
(7)
式中Cobj——掩码体素数
V——目标体积
Vvoxel——单个体素体积,本文是27 μm×27 μm×27 μm
另外,矩形度和球形度分别用于衡量籽粒与球体、立方体的接近程度。粒长、粒宽和粒厚用籽粒表面模型的三维方向包围盒的3个边长表示(图6i),即最长边为粒长、次长边为粒宽、最短边为粒厚。本文籽粒表型提取效率为10 s/粒,可以获得23项表型参数,如表2所示。
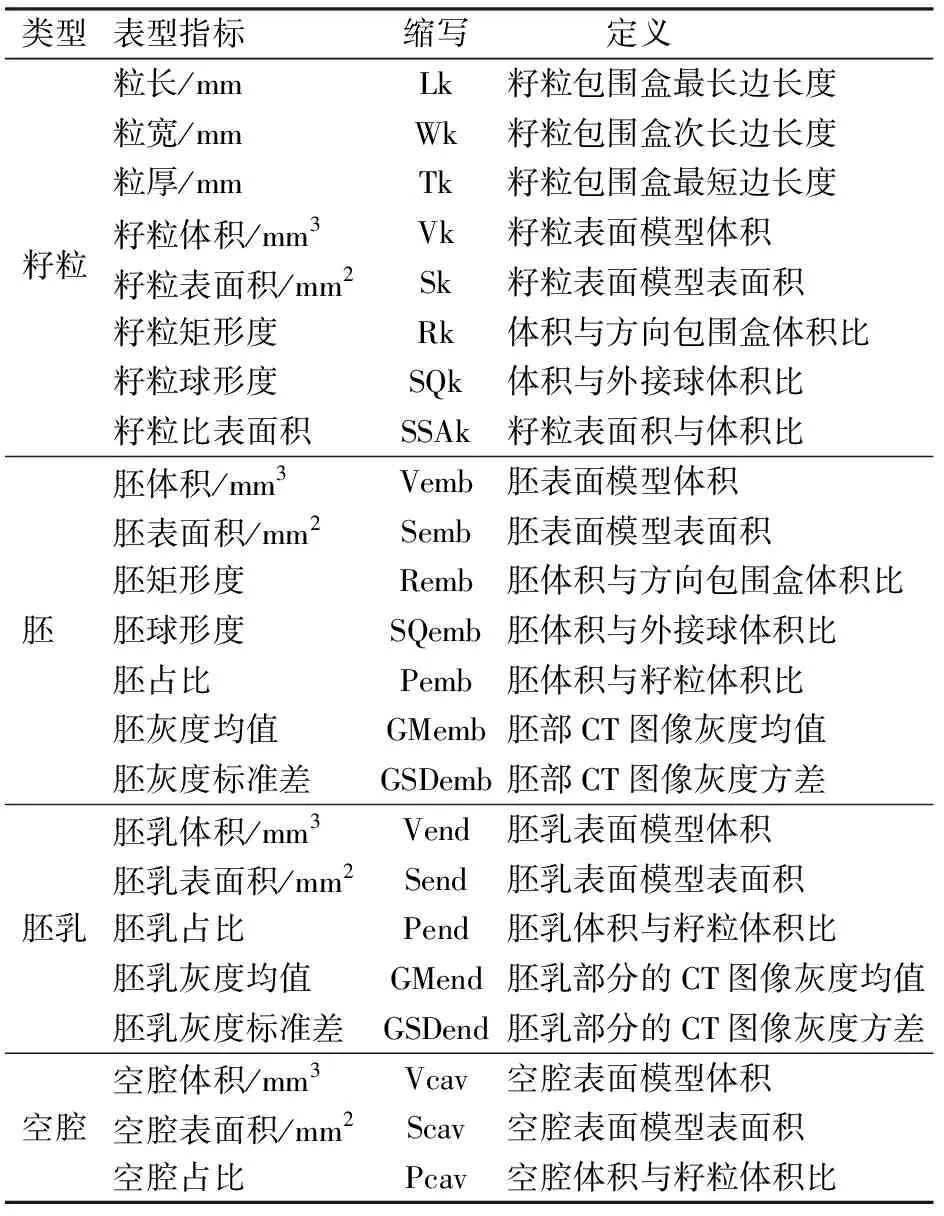
表2 籽粒及其内部结构表型Tab.2 Phenotypic traits of corn kernel and its inner structure
2.4 籽粒品种表型分析
获得4个品种籽粒的23个表型指标后,使用描述性统计方法调查各籽粒品种间的表型指标分布和差异情况;使用主成分分析(Principal component analysis,PCA)算法提取表型指标的前两个主成分,并进行聚类分析;利用经典的机器学习分类模型,包括K近邻(K-nearest neighbor,KNN)、支持向量机(Support vector machines,SVM)和随机森林(Random forest,RF)进行籽粒品种鉴定。上述分析分别使用R语言(4.1.1)和Python(3.8.8)实现,其中PCA分析使用prcomp函数,绘图使用ggplot2包,机器学习算法使用sklearn包。
3 结果与分析
3.1 表型管道性能评估
3.1.1语义分割网络精度评估
籽粒胚的分割精度至关重要,直接影响籽粒内胚乳和空腔量化。首先在训练集上评估UNet-2D、UNet-3D和RAUNet-3D的语义分割模型精度。不同模型的训练损失值和训练精度如图7所示。三维语义分割模型(UNet-3D和RAUNet-3D)的训练精度均高于二维语义分割模型(UNet-2D),说明3D网络利用CT图像层间关系,有利于提高模型分割精度。另外,经典的三维语义分割模型(UNet-3D)收敛速度较慢,而改进后的RAUNet-3D模型能够更快收敛且精度更高。
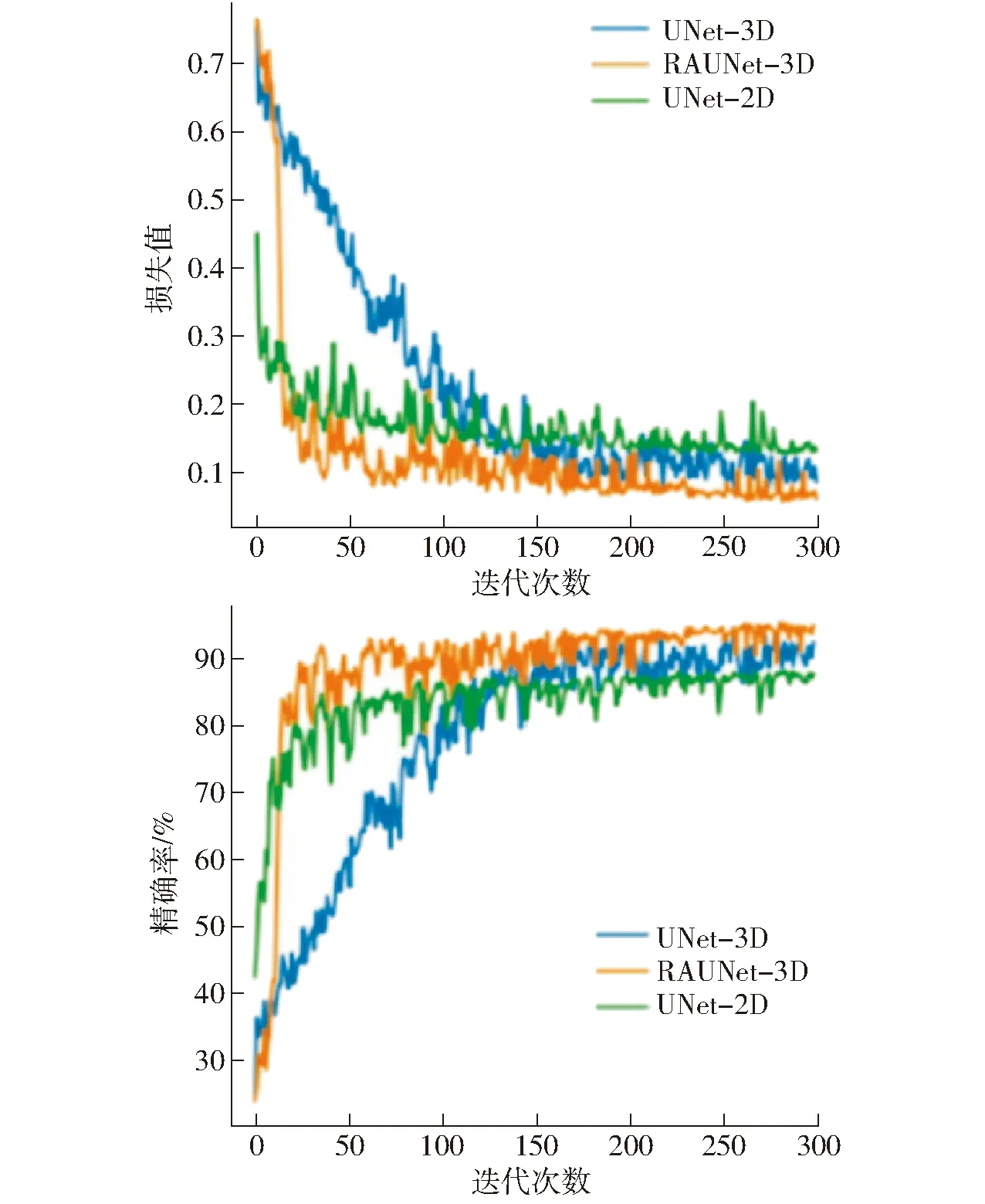
图7 训练集上不同模型的损失值和精确率曲线Fig.7 Loss and accuracy curves of different models on training sets
在测试集上评估3个模型的语义分割精度,分别采用DICE和IoU作为评价指标,结果如表3所示。整体上,三维语义分割模型比二维分割模型获得更高精度,RAUNet-3D、UNet-3D和UNet-2D模型的DICE和IoU依次增大。图8比较了UNet-2D、UNet-3D和RAUNet-3D语义分割结果,图中上3行分别表示一个籽粒CT不同的层,第4行表示三维可视化结果,红圈表示Unet-3D和RAUNet-3D胚边缘部分分割效果对比。可以看出,由于UNet-2D语义分割模型仅考虑了单层CT图像特征,某些层上的分割结果容易出现过分割和欠分割现象。将逐层分割结果合并为三维分割掩码并进行三维渲染,可以发现存在大量噪点或孤岛。
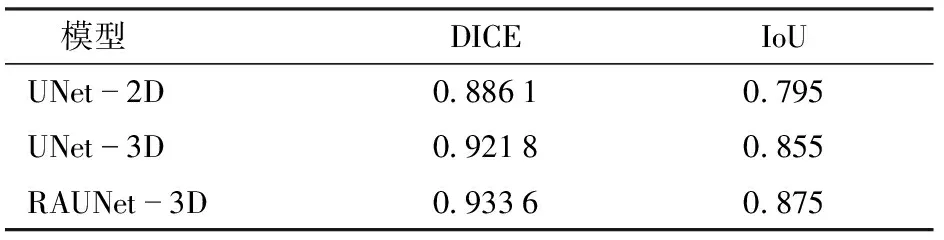
表3 测试集上不同深度学习模型的精度对比Tab.3 Accuracy comparison of different depth learning models on test set
由于UNet-3D和RAUNet-3D语义分割模型利用了图像层间关系,极大抑制了过分割和欠分割现象。RAUNet-3D在特征合并时引入了注意力机制,相较于UNet-3D,对目标的边缘部分分割得更加精准。因此,本文在籽粒表型管道中集成RAUNet-3D模型用于提取籽粒胚。
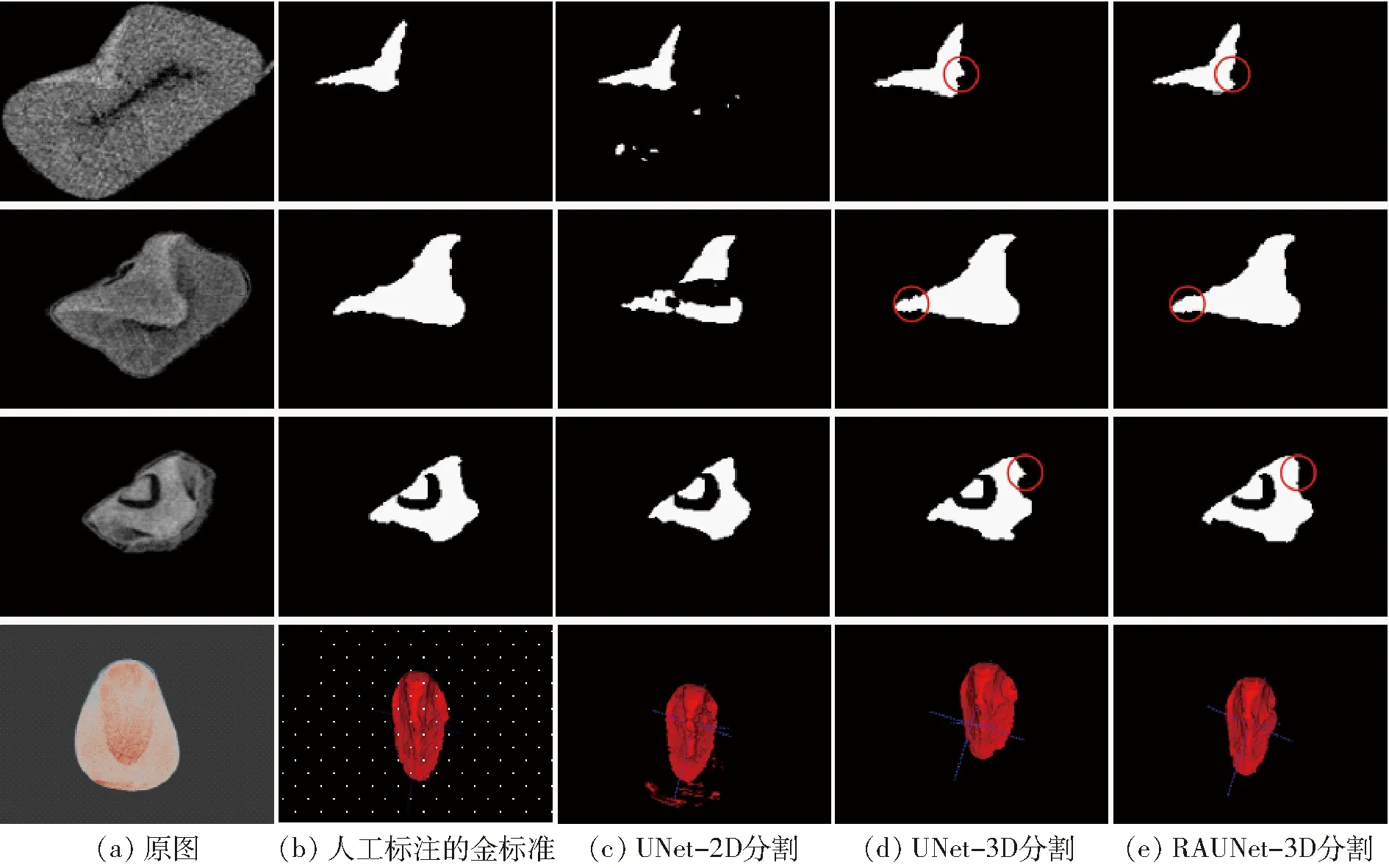
图8 不同模型分割结果比较Fig.8 Comparison of segmentation results of different models
3.1.2管道测量一致性评估
利用图6提出的表型计算管道,计算4个品种共120颗籽粒的23个表型指标。使用游标卡尺人工测量所有籽粒的粒长、粒宽和粒厚数据,采用决定系数R2和均方根误差(Root mean square error,RMSE)进行评估。
图9显示了粒长、粒宽和粒厚的本文方法测量值与人工测量值的关系。其中,粒长、粒宽和粒厚的R2分别为0.902、0.926和0.904,RMSE分别为0.325、0.253、0.258 mm。表明本文方法测量结果与人工测量值具有较好的一致性。
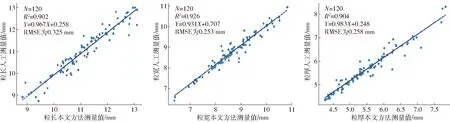
图9 管道计算值与人工测量值比较(粒长、粒宽和粒厚)Fig.9 Comparison between computed and manual measured values of kernel length, width and thickness
3.2 籽粒性状统计分析
对4个品种120颗籽粒的所有表型指标进行初步统计分析,计算出各项指标的均值、标准差、最小值、中位数和最大值,如表4所示。4个玉米品种籽粒的23项性状经过Z-score归一化处理,利用箱线图显示各个品种籽粒表型的分布差异(图10),图中灰色、黄色、蓝色和红色分别表示空腔、胚乳、胚和籽粒表型指标。从每个品种中选择2颗典型籽粒,分别显示籽粒及其内部结构的三维形态差异(图11),可以看出:①品种间籽粒空腔差异较大,XZD408和DH605的籽粒空腔要远大于JK968和NH5品种的籽粒空腔。②品种间籽粒、胚、胚乳和体积表面积差异较大,XZD408和NH5的籽粒个体、胚和胚乳的体积和表面积均较大,而JK968和DH605的籽粒个体、胚和胚乳的体积和表面积均较小。③DH605的胚和胚乳的灰度均值比其它3个品种小,表明该品种籽粒的密度较小,对X射线的吸收较弱。④从粒形上看,JK968和NH5偏扁平一些,球形度较小、矩形度较大。而DH605和XZD408偏圆一些,球形度较大、矩形度较小。⑤扁平籽粒的比表面积通常要大于圆形籽粒,相比于DH605和XZD408,扁平的NH5和JK968的比表面积较大。
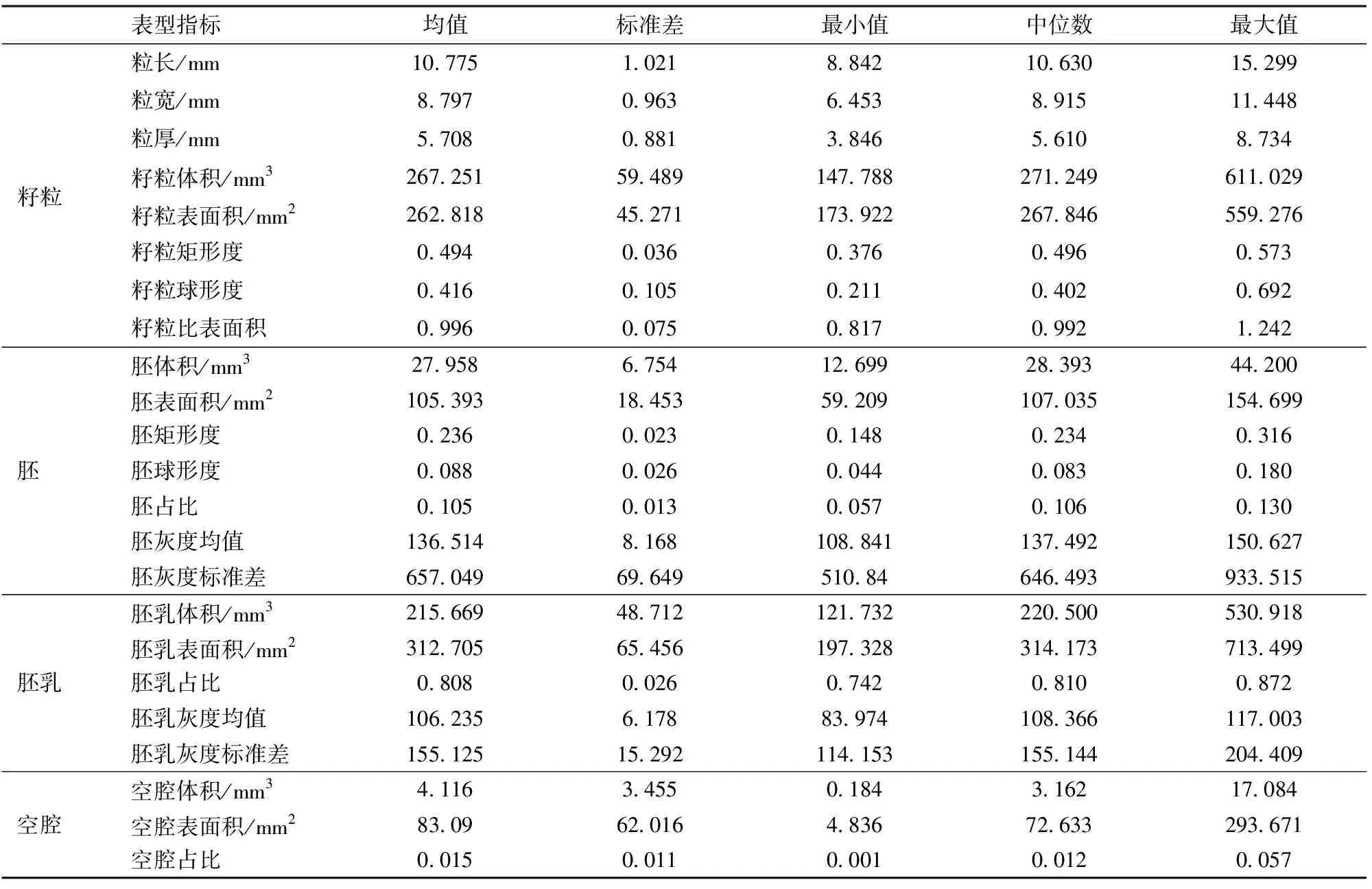
表4 籽粒表型的统计描述Tab.4 Statistical description of kernel phenotypes
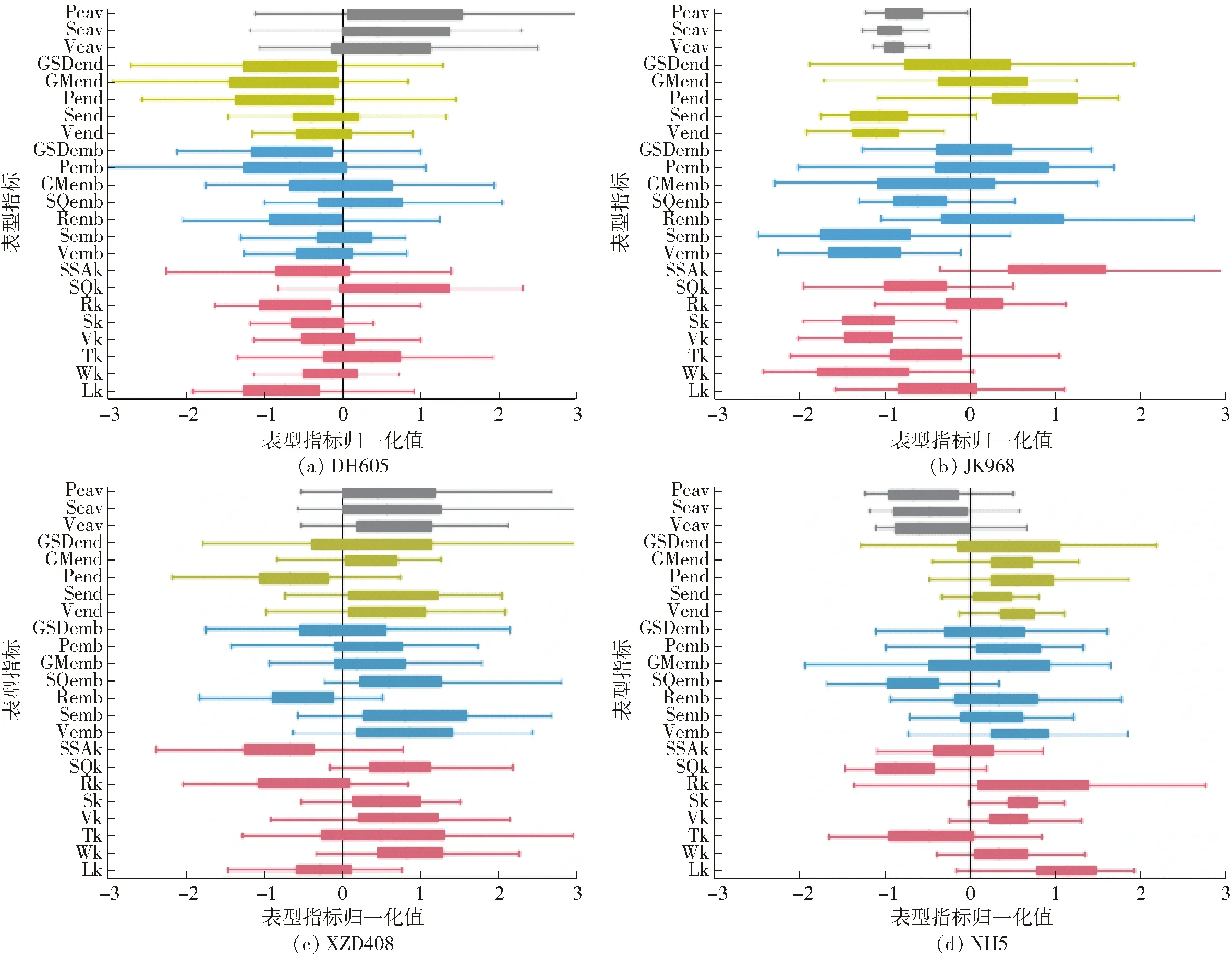
图10 4个品种的玉米籽粒表型箱线图Fig.10 Phenotypic boxplots of corn kernel of four varieties
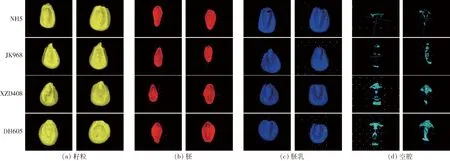
图11 不同品种的玉米籽粒三维结构Fig.11 3D structures of corn kernels of different varieties
3.3 籽粒表型鉴定
为了考察不同玉米品种籽粒表型间区分度,在所有籽粒的表型数据上进行PCA分析(图12),得到的前两个主成分分别解释了38%和21.5%的表型变异。从图12a可以看出,第1个主成分和第2个主成分能很大程度上区分出DH605、JK968、XZD408和NH5品种的籽粒。从图12b可知,第1个主成分与籽粒的几何形态特征相关(比如粒长、粒宽、籽粒体积、胚体积、空腔体积、籽粒表面积、胚乳表面积和胚表面积),第2个主成分主要与籽粒胚和胚乳的CT灰度性状相关。
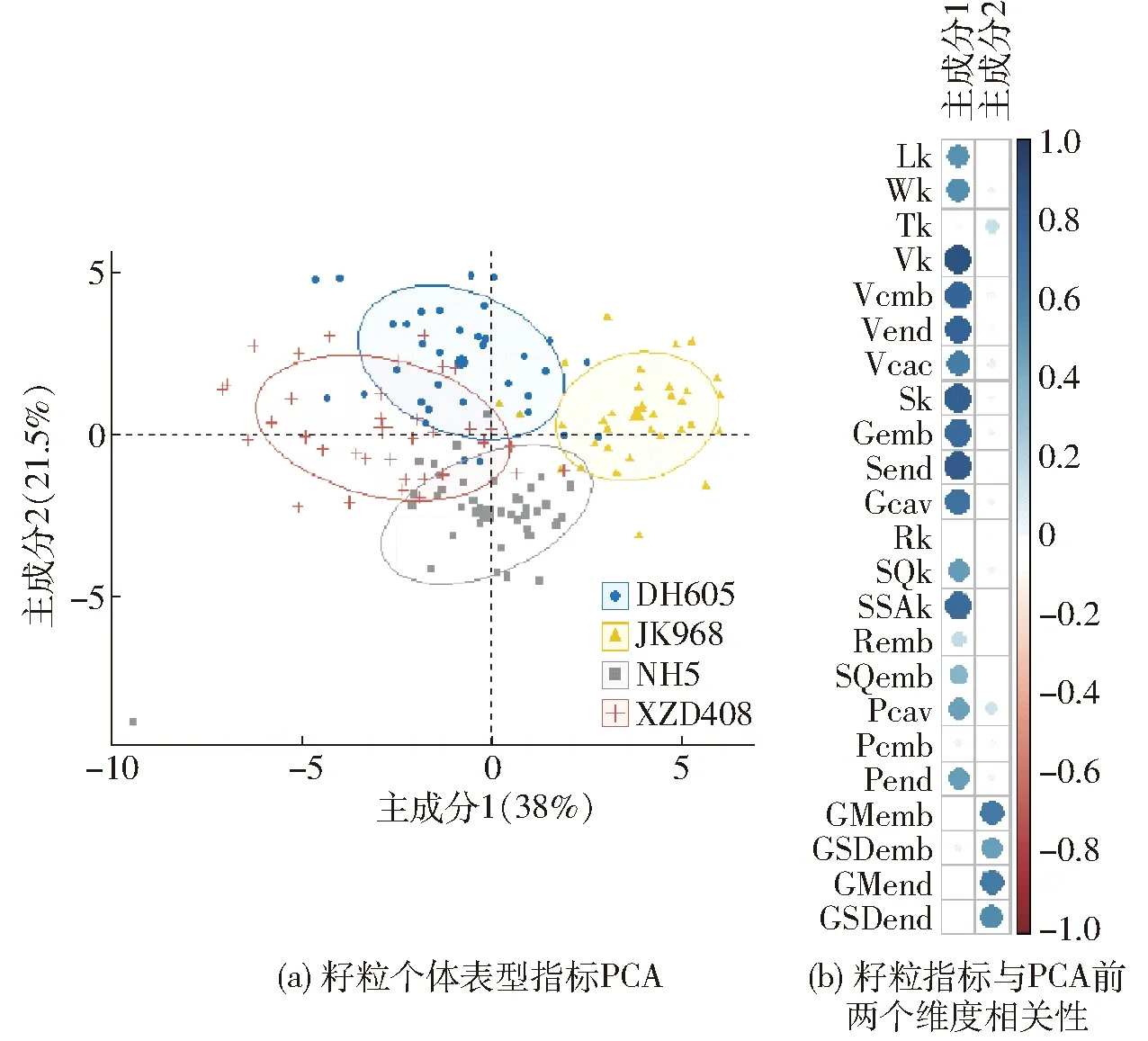
图12 籽粒主成分分析Fig.12 PCA analysis of corn kernel
进一步利用KNN、RF和SVM训练4类玉米品种的籽粒分类器。采用5折交叉验证来优选分类模型,3类模型精度及平均精度如表5所示。其中SVM 的平均识别精度最高,可达90.4%。这表明,基于本文方法提取出的籽粒及其内部结构表型对不同品种籽粒的分类和鉴定具有价值。
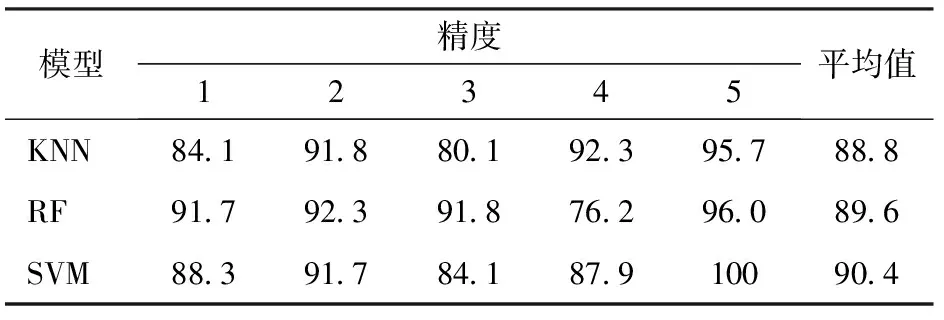
表5 不同机器学习模型的分类精度Tab.5 Classification accuracy of different machine learning models %
4 结论
(1)针对基于Micro-CT的玉米籽粒表型分析中存在的扫描成像效率低、表型测量自动化和鲁棒性差等问题,提出了自动化玉米籽粒三维表型分析方法,快速解析玉米籽粒及其内部结构的23项表型,粒长、粒宽和粒厚的R2分别为0.902、0.926和0.904。对4个品种共120颗玉米籽粒进行测试,籽粒表型提取效率为10 s/粒。
(2)对批量籽粒进行扫描成像,使用Watershed算法从批量籽粒CT图像中拆分出每颗籽粒,提高了Micro-CT对籽粒的扫描通量。
(3)基于残差连接和注意力机制的三维分割网络(RAUNet-3D)对籽粒胚的分割精度可达93.4%,为计算籽粒胚和胚乳等内部结构性状提供依据。
(4)籽粒及其内部结构的23项性状具有明显品种区分度,可用于玉米籽粒品种分类和鉴定。
猜你喜欢
东北农业大学学报(2022年11期)2022-12-27
辽宁农业科学(2021年1期)2021-03-17
装备制造技术(2020年11期)2021-01-26
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
发明与创新·中学生(2017年1期)2017-01-20
小学阅读指南·高年级版(2016年9期)2016-10-31
中国粮油学报(2016年5期)2016-01-23
电脑知识与技术(2015年12期)2015-07-18
原子能科学技术(2015年1期)2015-03-20
