
基于XGBoost 的DDoS 攻击流量过滤算法
2022-02-07 07:57孙泽熙
江苏通信 2022年6期
孙泽熙
南京邮电大学计算机学院、软件学院、网络空间安全学院
0 引言
习总书记指出:“没有网络安全就没有国家安全,就没有经济社会稳定运行,广大人民群众利益也难以得到保障。”
DDoS(Distributed Denial of Service,分布式拒绝服务)攻击是目前最常见、危害最大的攻击手段之一。攻击者从多个不同位置同时发动拒绝服务攻击,占用目标的系统、应用、网络带宽等资源,妨害其正常提供服务。为增强效力,攻击者还会使用反射攻击、源IP 伪造等技术伪装攻击流量,进一步加大了溯源与防御的难度,其防治是研究的热点与难点。
目前,DDoS 攻击检测技术已具备相当高的准确率。然而攻击检测方法只能辨别攻击是否发生,无法缓解攻击造成的影响。本文提出了一种基于XGBoost 的DDoS 攻击流量过滤算法。模型通过攻击检测得到一个时间周期内的网络状态标签,随后使用流量特征与标签训练机器学习分类器,更新过滤器。模型能够较为准确地区分正常数据包和异常数据包,且过滤器的参数可以较为容易地转化为适用于包过滤防火墙或其他类似设备的过滤规则。
1 研究背景
DDoS 攻击的防御技术,大致可以分为三个方面:预防、检测及响应。
1.1 DDoS 攻击的检测
按检测对象划分,攻击检测可以分为流量检测,主机性能检测,用户行为检测。流量检测对受保护对象接收到的数据包和数据流进行分析,根据流量特征判断当前网络所处的状态,可部署在任意网络位置,技术相对成熟。主机性能检测与用户行为检测均仅能部署在近目的端,两者与流量检测互为补充。
根据检测策略的不同,攻击检测可以分为基于误用的检测和基于异常的检测。基于误用的检测将待测流量与事先收集的攻击流量进行特征比对,适合防备已知攻击,但灵活性与可移植性较差。基于异常的检测则对正常用户行为进行建模,有悖于常理的流量会被判定为攻击流量。它能够应对未知攻击,但建模难度更大,整体的精度可能有所欠缺。
传统的攻击检测算法主要有基于信息熵的算法和基于自相似性的算法。相关文献提供了一种基于熵的检测算法,并验证了算法在检测高速率和低速率攻击时的有效性。相关文献在传统的基于熵的检测算法的基础上加入了威胁等级,提高了算法在不同速率的攻击下的准确率。相关文献将基于自相似性的检测与小波变换结合,得到的新算法能够更为准确地区分攻击与繁忙业务。
随着人工智能的高速发展,许多机器学习模型,如随机森林、SVM 也被应用于攻击检测。
1.2 DDoS 攻击的响应
常用的DDoS 攻击响应技术有流量过滤、路径隐藏、资源重配置等。流量过滤是在受保护对象之前识别并抛弃异常数据包的技术,能够立刻削减攻击流量,是最直接的应对手段。目前,流量过滤一般使用专用的硬件防火墙,其过滤规则需要人工配置。
1.3 机器学习在DDoS 攻击防御上的应用
近年来,机器学习算法已被广泛应用于各行各业。DDoS攻击流量的过滤均属于标准的二分类问题,满足其使用条件。但问题在于:有监督的机器学习算法需要在一定量的已知标签(即正确的分类结果)的数据上进行学习,之后才能进行分类。然而现实的流量数据不存在标签,无法直接训练分类器。
关于这一问题有两种易得的解决思路:
其一是在事先准备好的人工标注的数据集上训练分类器,进行持久化部署。这种方法相较于人工设计过滤规则,可以提取更深层的信息,对已知攻击卓有成效,但灵活性欠佳。据绿盟全球威胁狩猎系统监测,约七成DDoS 攻击的持续时间不超过半个小时。在如此短的时间内,基本不可能通过有限的人力完成数据的标注,更遑论过滤规则的更新了。所以这种方式无法有效应对未知攻击。
其二是使用无监督学习算法,如聚类算法。这类算法无需标签即可工作,可以实现“自适应过滤”,但精度往往有所欠缺。并且聚类算法难以处理正负样本比例悬殊的数据,可能无法应对低速率攻击。此外,聚类算法还只能划分数据,而不能指明正样本与负样本,还需额外的处理工作。
综上所述,可见以上两种思路均未很好地平衡算法的准确率与灵活性,无法直接投入使用。
2 基于机器学习的DDoS 攻击流量过滤算法
为了兼顾流量过滤算法的精度和对未知攻击的检出率,本文提出了一种新的流量过滤算法设计思路。算法主要包括两个部分:特征提取模块et和分类器ct。该算法将实时流量迭代训练集,实时训练分类器,动态更新过滤规则以应对未知攻击,同时保留了分类模型精度较高的优点。流程如图1 所示。
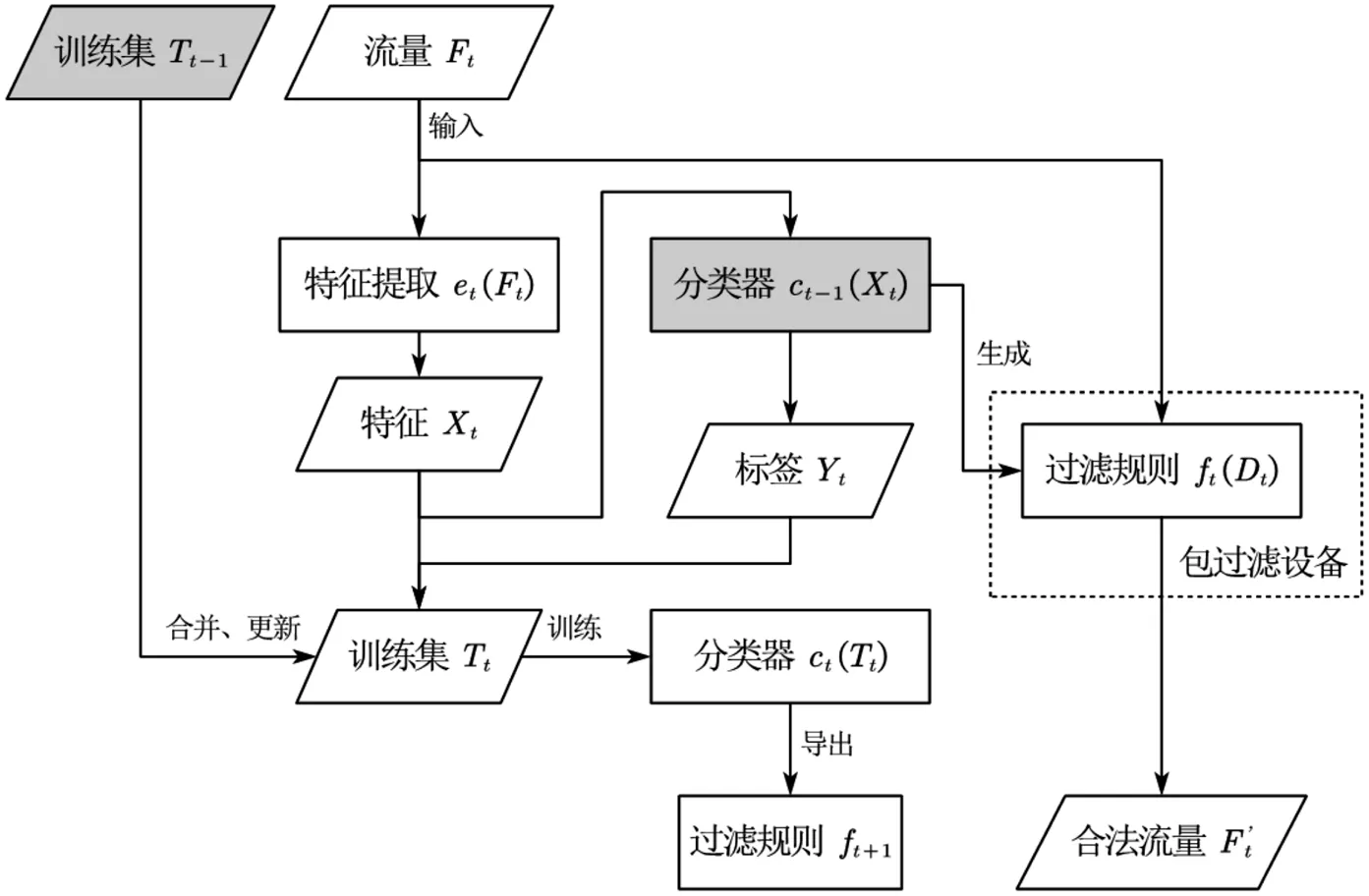
图1 算法流程
在时间周期t 内,首先将本周期的流量Ft输入特征提取模块et,得到特征数组Xt。随后将Xt输入前一周期训练好的分类器ct-1,得到标签Yt。再将Xt与Yt拼接,与上一周期的训练集一并组成新的训练集Tt,训练分类器ct;最后从训练完毕的分类器ct中导出包过滤规则ft以备下一周期使用。与此同时,算法使用上一个周期的分类器ct-1生成过滤规则,传递给包过滤设备,抛弃异常数据包,保留合法流量Ft′。
该算法在面临已知攻击时,分类器可以逐步纯化数据集,进而提高预测得到的标签准确率;遭遇未知攻击时,攻击样本会逐步进入训练集,分类器可以在极为有限的时间内习得新攻击的特征,做出针对性的相应,具有较好的鲁棒性。
3 实验及分析
本文使用了约750 万条真实TCP 样本进行了仿真实验,每条样本有80 个可用特征,包含数据包特征和数据流特征。其中非数值型的特征被编码并转换为整型,并进行归一化(Min-Max Scaling)处理。
3.1 评价指标
本文使用F2 分数作为模型精度的评价指标。根据二分类问题混淆矩阵,有:

Fβ 分数可视为精确率和召回率的调和平均。精确率(precision)反映了模型对正常流量的检测性能,精确率越高,误报(错误拦截正常流量)就越少;而召回率(recall)体现了模型对攻击流量的检测性能,召回率越高,漏报(错误放行攻击流量)就越少。
F2 分数赋予了召回率两倍于精确率的权重,符合面临DDoS 攻击时保护系统优先于保护业务的思想。
3.2 算法的调优
为了选取分类器,本文对八个常见分类模型进行了考察:朴素贝叶斯(NB),逻辑斯蒂回归(LR),KNN,决策树(DT),随机森林(RF),XGboost(XGBT),支持向量机(SVM),多层感知机(MLP)。
两个聚类模型:K-Means++,Agglomerative 被引入,作为对照。
(1)训练集的规模
将待选模型在不同规模的DDoS 数据集上分别进行了精度测试,结果如图2、图3 所示。
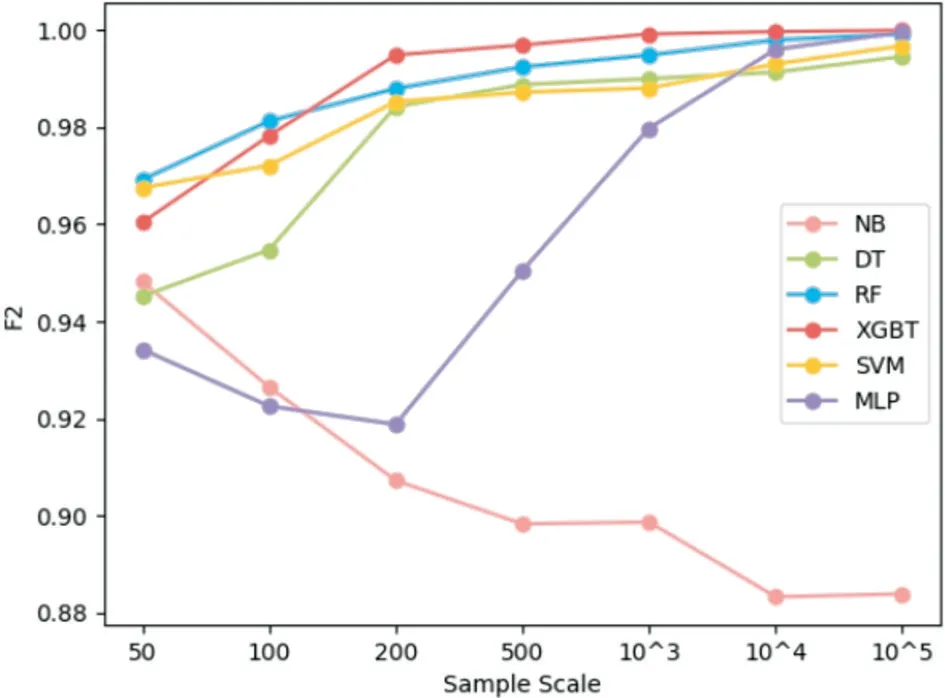
图2 分类模型精度-训练集规模曲线
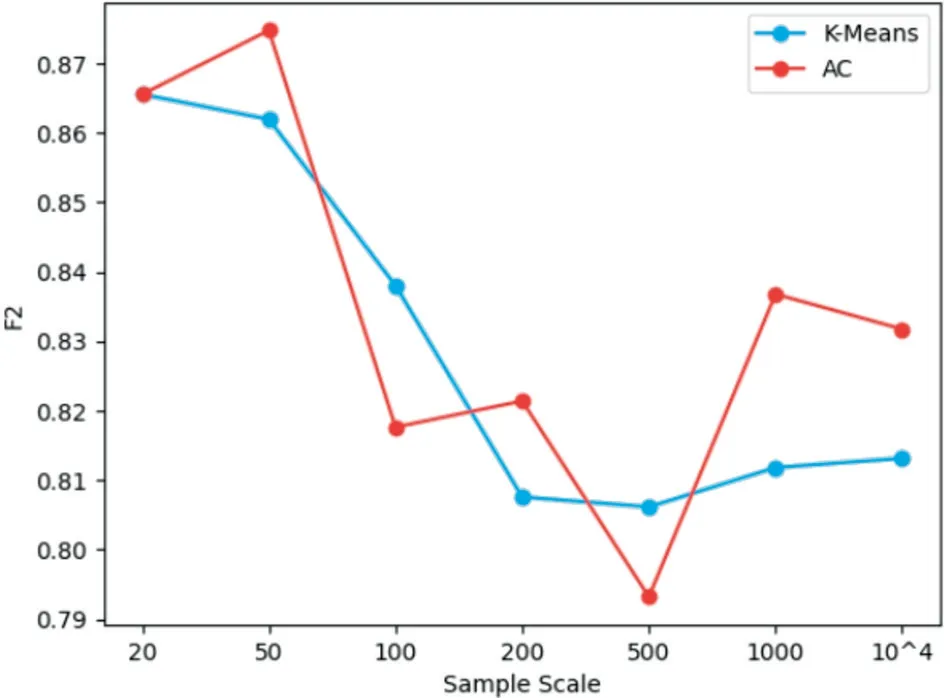
图3 聚类模型精度-训练集规模曲线
依图可见:除朴素贝叶斯外,其余分类器对训练集的规模敏感,其性能与样本量大致呈正相关。大部分模型精度的增长拐点在102 与103 之间,而深度学习所需的数据量极为庞大,即便最简单的多层感知机也需万条数据的支撑才能追平其它算法。聚类算法的性能与数据规模间没有明确的相关性,但其精度与分类算法存在较大差距。
根据拐点效应,算法中训练集的规模应设置为1000。
(2)模型的训练速度与推理速度
对分类模型的训练速度与推理速度进行了测试。训练集共103 条样本,验证集共106 条样本,所有模型均使用常用的python 库实现,使用的CPU 为i7-10700K。如表1 所示:KNN与SVM 训练极快,但推理速度落后其他模型两个数量级,需慎重使用。
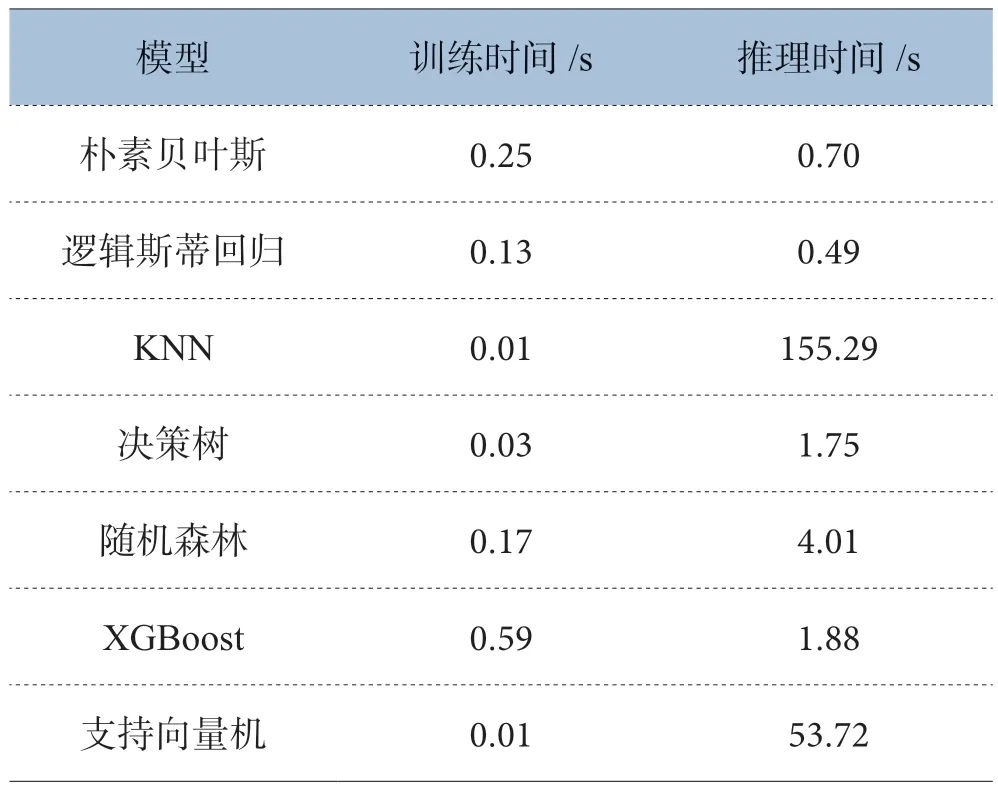
表1 模型的训练与推理速度
(3)模型对标签噪声的容忍能力
算法中,因为分类器的正确率不为100%,所以由前一个周期的分类器所生成的标签必然存在错误。这些标注错误的数据会与正常数据相拮抗,影响正常样本的表达,降低模型的精度。本文将一个基准数据集中的部分样本随机反转标签以模拟这种情况,随后考察了部分原始精度较高的算法在有标签噪声的数据上精度损失。其中,正确标签的占比记为α。如图4所示,模型中XGBoost的综合表现最好远优于其他算法。
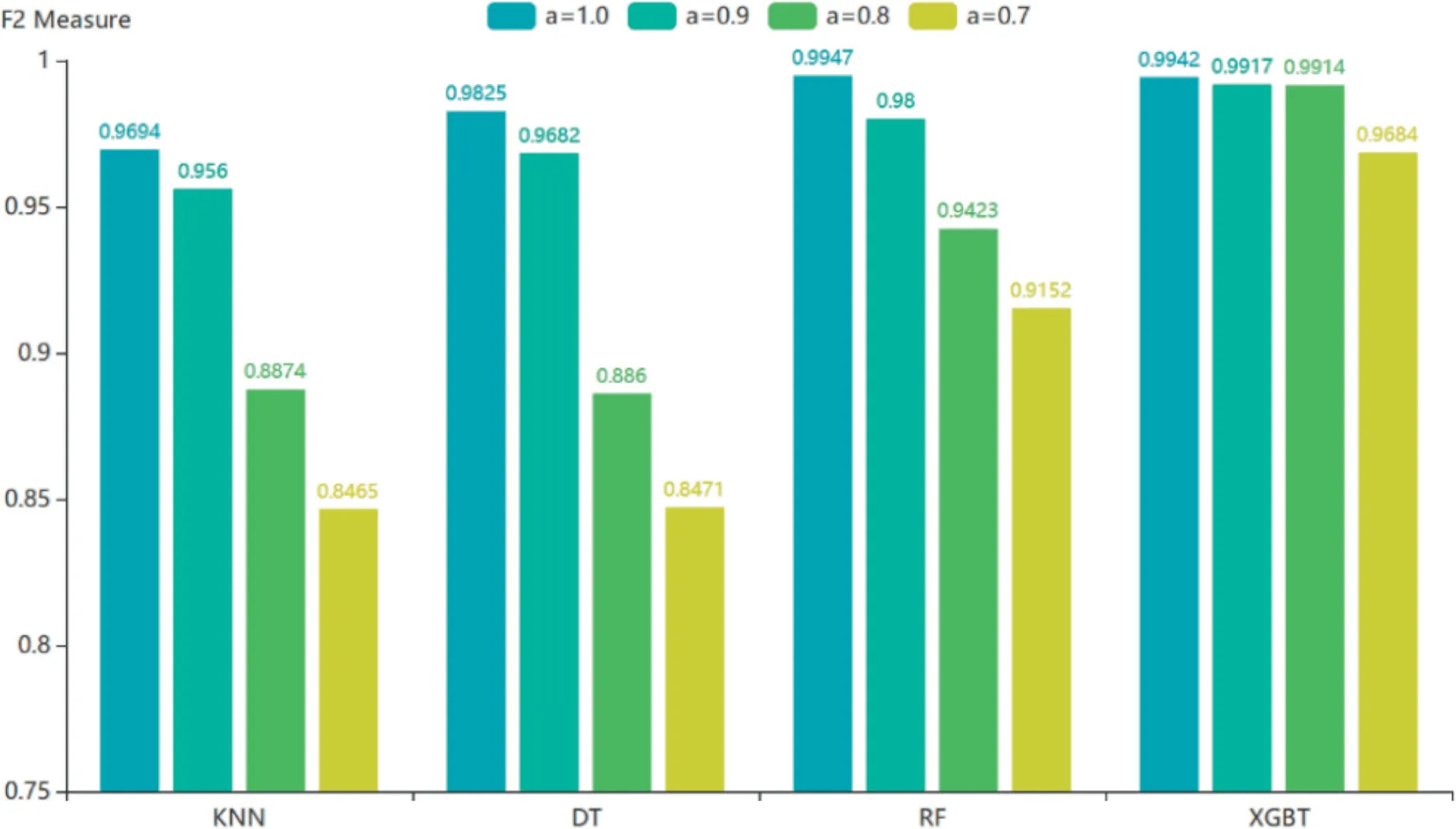
图4 部分模型在有标签噪声的数据上的精度变化
综上,认定XGBoost 为分类器的最优解。其基础准确率极高,训练与推理较快,能够支撑算法的精度与灵活性。作为集成学习算法,其能有效应对标签噪声,在处理新的流量特征时可以更快完成收敛。
3.3 实验结果
本文采用XGBoost 作为分类器。首先自数据集中随机取出10 组样本模拟10 个相邻时间周期的流量;随后随机初始化第一个标签数组,模拟算法应对未知攻击的情形;再按顺序依次生成预测标签训练分类器,更新训练集;最后根据数据集中的真实标签进行测试,记录每一个周期的分类器的F2 分数。结果如图5 所示。
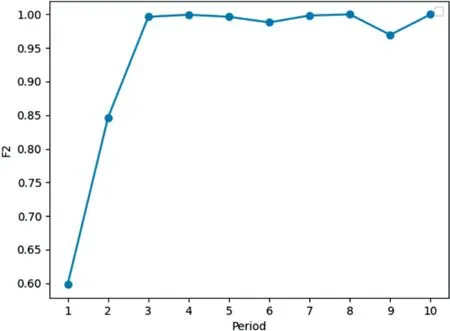
图5 算法F2 分数的时间序列曲线
观察图5,可知模型既具备较高的精度,又能够及时处理未知攻击,能够有效进行流量过滤:模型在第三个周期就完成了对未知攻击建模,随后的数个周期内,研判数据包的准确率均维持在0.95 以上。
4 结束语
DDoS 攻击依然是全球范围内最具威胁的攻击手段之一。对DDoS 攻击的防御和控制目前尚缺乏通用、有效的措施。本文对机器学习在防御DDoS 攻击的应用进行了介绍与探索,提出了一种兼具精度与灵活性的新的流量过滤算法。希望为新的流量过滤算法的设计提供帮助。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
民用飞机设计与研究(2020年4期)2021-01-21
物联网技术(2018年8期)2018-12-06
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
航天返回与遥感(2014年5期)2014-07-31
