
基于改进Faster R-CNN 的算式检测与定位
2022-02-07 09:20:22周庆华
智能计算机与应用 2022年12期
王 巍,周庆华
(长沙理工大学 物理与电子科学学院,长沙 410004)
0 引言
小学四则混合运算题一般由加、减、乘、除、括号和数字组成,数字又包含印刷体和手写体两种类型。从广义上来讲,用机器视觉方法对这种基础算式的检测与识别,属于光学字符识别(Optical Character Recognition,OCR)。传统OCR 技术主要分为文字区域定位、行列分割、分类器识别等几个步骤,其中文字区域定位、行列分割在本质上就是文本检测与定位。研究可知,文字区域定位是对文字颜色、亮度、边缘等信息进行聚类,进而分离出文字区域与非文字区域。一般情况下多是采用投影法[1]进行行列分割,行列分割的目的是提取出单字,主要方法是利用文字在行列间存在间隙的特征,由此来找出行列分割点。在背景单一、数据简单、容易分割的情况下,比如车牌识别[2-3]和身份证识别[4-5]等,传统OCR 方法一般都能达到较好的效果。然而,在自然场景中的图像文本检测[6]时,往往存在背景复杂、有噪声干扰、字符之间有粘连/重叠等情况。具体来说,本文研究的算术题题卡一般是由家长自行打印,打印纸中会有背景图案干扰,手写答案也会有粘连/重叠的情况,使得传统OCR 方法的区域定位和行列分割准确度大打折扣。在此背景下,近年来提出的深度学习[7]OCR 技术就表现出明显优势。
与传统OCR 方法相比而言,深度学习OCR 算法无需进行文字的单字分割,可以直接对整行文字进行识别[8]。因此,在深度学习的OCR 技术中,使用合适的目标检测算法对文本进行检测与定位是至关重要的一个环节。Ren 等人[9]在2017 年提出了Faster R-CNN,被证实是一种较高效的目标检测算法。由于Faster R-CNN 的检测对象只是PASCAL VOC 2007 数据集上的20 类目标,故对其它特定目标的检测效果并不理想。因此,后期又相继提出了基于Faster R-CNN 的改进算法[10~13]。冯小雨等人[14]对Faster R-CNN 算法进行改进,将其专门用来检测空中目标。黄继鹏等人[15]提出面向小目标的多尺度Faster R-CNN 检测算法,提高了Faster RCNN 在小目标检测任务上的平均精度。王宪保等人[16]提出了一种分裂机制的改进Faster R-CNN 算法,获得了比原始Faster R-CNN 更好的检测效果。黄宁霞等人[17]增加基础网络的深度,采用双线性插值和soft-NMS[18]等方法改进Faster R-CNN,在不同场景的人行道障碍物检测中获得了不错的鲁棒性。
然而,本文处理的基础算式具有长短不一、手写数字随机、定位要求高等特点,上述改进算法不适用于算式的检测与定位。考虑到基础算式的上述特点,本文提出了一种基于聚类的快速区域卷积网络(faster region based convolutional neural network based on clustering,CF R-CNN)算法,CF R-CNN 算法主要有2 方面的改进:
(1)用K-means 聚类算法[19]得出更适合的anchor 参数,使模型收敛更快。
(2)参考Mask R-CNN[20]的处理方法,把ROI Pooling 改为ROI Align,避免了ROI Pooling 中2 次量化带来的影响,提高了检测精度。实验表明,在基础算式检测定位中,本文提出的CF R-CNN 有更好的性能。
1 数据集
为了完成用于基础算式检测定位的CF R-CNN网络的训练,研究制作了一个包含每个算式定位框信息的题卡数据集。考虑到教师和家长制作题卡并进行识别的常见场景,每页题卡采用每行2 个算式、每页25 行、A4 纸打印的形式。研究中以随机的方式生成了500 页的口算题,数据集的一个样本页如图1 所示,每个算式由2~3 个整数或小数的四则混合运算组成,部分含有括号、铅笔书写答案,用手机摄像头拍照。

图1 数据集样本示例Fig. 1 Sample of the dataset
2 CF R-CNN 算法
CF R-CNN 的网络结构如图2 所示。选择Faster R-CNN 作为基础的网络框架,主要由特征提取网络、区域建议网络、ROI Align 和分类回归网络组成。对此拟做阐释分述如下。

图2 CF R-CNN 网络结构框架图Fig. 2 Frame of CF R-CNN
2.1 特征提取网络
图片输入进来,先归一化到800×600 像素,接下来是选取VGG16 的前面部分层的基本结构作为特征提取网络,具体见图2。由图2 看到,主要由13个卷积层(Conv Layer)、13 个激励层、4 个池化层(Pooling Layer)组成,卷积层全部采用3×3 大小的卷积核,步长为1(stride =1),填充1 圈0(pad =1);所有激励层采用修正线性单元函数(the rectified linear unit,Relu);所有池化层采用最大池化(Max Pooling),2×2 大小的池化核,步长为2(stride =2),不填充(pad =0)。经过一次池化层尺寸会变为原来的一半,因此最终得到的特征图(feature map)尺寸变为原图的1/16。
2.2 改进的区域建议网络
为了减少参数数量,节省训练时间,改进的区域建议网络(Region Proposal Network,RPN)与分类回归网络共享特征提取网络,在特征图上做3×3 的滑动窗口,把每个滑动窗口的中心映射到原图,生成k种不同的锚框来得到期望的目标建议框,原始Faster R-CNN 采用k =9 种锚框,如图3(a)所示,这9 个锚框由3 种长宽比[1 ∶2,1 ∶1,2 ∶1],3 种尺寸[1282,2562,5122]组成,锚框长宽比和尺寸均不能适用于本文的算式检测与定位。为了找到适合算式检测定位的锚框,本文采用K-means 聚类算法,在第3 节实验与分析得出k =nw × nr =16、共16 种锚框(nw =4 种宽度值[64,80,96,112]和nr =4 种高宽比例[0.20,0.25,0.30,0.36]),如图3(b)所示。
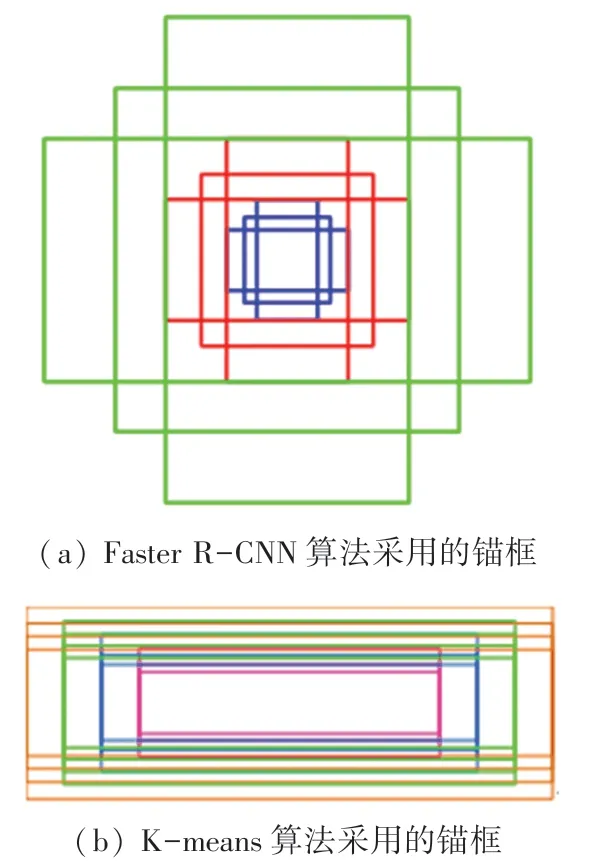
图3 锚框Fig. 3 Anchors
生成的锚框(anchor boxes)中有一些是超出图片边界的,把这部分锚框去除,利用非极大值抑制(Non-Maximum Suppression,NMS)[21]去除重叠的框。对剩下的锚框分2 条路线处理。线路一负责判断是否为目标对象,线路二负责计算目标对象的锚框(anchor boxes)与真实框(ground truth)在原图中的偏移量,最终得到区域建议框(region proposal)。
2.3 ROI Align
原始 Faster R -CNN 在 RPN 后使用 ROI Pooling,用来接收 RPN 输出的区域建议框(proposal)和原始特征图(feature map)。该过程可详见图4 中的虚线流程,假如原图(image)为800×800 大小的正方形,目标建议框为665×665 大小的正方形。第一步,特征提取下采样16 倍,得到边长为[800/16]=50 的正方形特征图(其中,[·]表示向下取整),同时,建议框(proposals)映射到特征图(feature map),边长大小变成[665/16] =41。第二步,把尺寸池化到统一大小7×7,进入分类回归网络的全连接层,每块的边长为41/7 =5.86,是浮点数,做取整操作,取[41/7]=5。
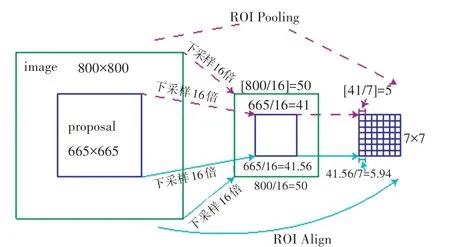
图4 ROI Pooling 和ROI AlignFig. 4 ROI Pooling and ROI Align
以上2 步都存在取整操作,此后映射回原图时会带来坐标的偏差,使得最终的检测框出现偏差,导致定位不准确,为了解决定位偏差的问题,研究采用ROI Align 替代ROI Pooling。ROI Align 不采用取整操作,而是直接利用浮点数来进行操作。该过可详见图4 中的实线流程。在第一步中,特征图(feature map)中的建议框(proposals)边长为665/16 =41.56;在第二步中,池化到7×7 大小时,每块的边长为41.56/7 =5.94。ROI Align 有效避免了取整带来的量化误差,使得映射回原图的定位框更精确。
2.4 分类回归网络
ROI Align 得到的7×7 建议框特征图(proposal feature maps)进入分类回归网络的全连接层,后分2路同时进行。一路进行框坐标值的回归,得到更精确的目标检测框;另一路利用softmax函数进行计算,判断出目标的种类。
3 实验与分析
本次研究采用图2 中的基本网络框架,通过聚类方法得出nw种宽度值和nr种高宽比,把单个锚点的锚框数目记为k(k =nw ×nr),不同的nw,nr值决定了不同的k值。通过实验得到网络在不同k值下的性能,取综合性能最佳者作为CF R -CNN 网络,并将其与原始的Faster R -CNN 进行对比验证。实验中,把数据集分为训练验证集和测试集,分别占比80%和20%,训练50 轮:前40 轮学习率为0.001,后10 轮学习率衰减为0.000 1。
3.1 实验环境
实验均在Ubuntu18.04 LTS 操作系统下进行,电脑的中央处理器为Intel(R)Core(TM)i7-10870H,运行内存16 GB,一块NVIDIA GeForce RTX 2060显卡,使用CUDA 10.0 并行计算架构,cuDNN7.4 深度神经网络GPU 加速库以及TensorFlow1.13 深度学习框架,所用的编程语言为Python。
3.2 k 值的确定
考虑到特征提取网络的16 倍下采样,对25 000个算式的宽度值除以16,作为新的宽度值,对其进行聚类分析,得出宽度值分布在4~7 之间(一共4个整数值:4,5,6,7)。考虑到取1~2 种宽度值,数目过少,因此,仅选取nw =3 和4 两个值。取nw =3时,宽度值为4.5、5.7、6.7,选取5、6、7 这3 个值;取nw =4 时,宽度值为4.3、5.3、6.0、7.0,选取4、5、6、7这4 个值。接着对高宽比进行聚类分析,高宽比的值分布在0.2~0.4 之间。分别按3~6 类进行聚类,得出数据见表1。选取表1 中的几种nw ×nr的组合做对比测试,得出训练时间及AP值。综合考虑选择k =nw ×nr =4×4 的组合作为CF R-CNN 网络参数。
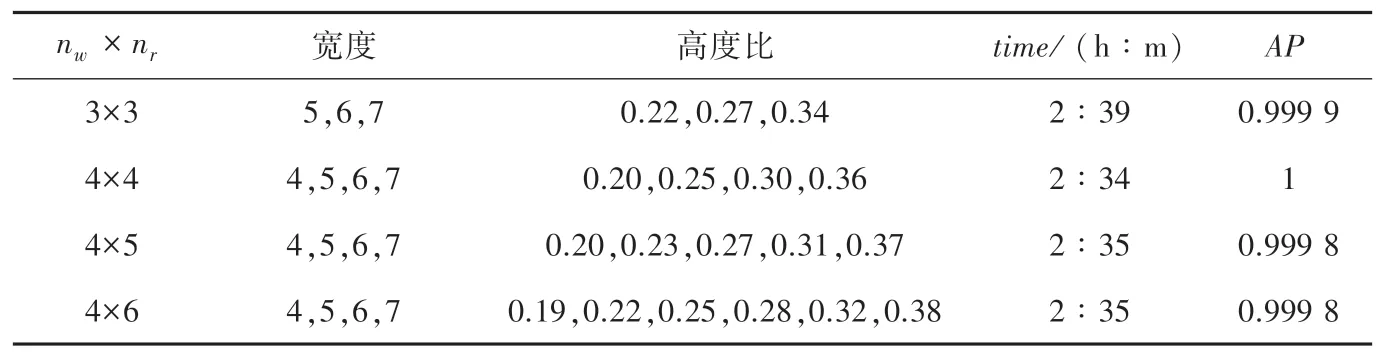
表1 不同k 值组合的参数及性能对比Tab.1 Performance comparison of different k-value combinations
3.3 性能对比分析
实验得出Faster R-CNN 的训练时间和AP值,并与CF R-CNN 进行对比,对比结果见表2。图5为二者的损失曲线。由图5 可以看出,CF R-CNN的训练时间更短,收敛更迅速,准确度更高。对CF R-CNN 与Faster R-CNN 进行对比测试,测试结果如图6 所示。图6 中,图6(a)是部分的实验结果,图6(b)是基于同样的图片,运用Faster R-CNN 得到的实验结果。
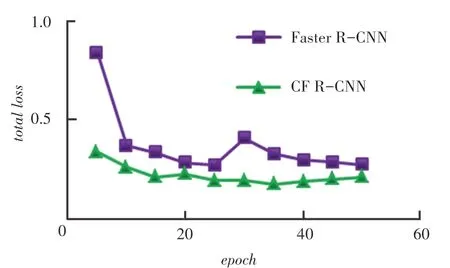
图5 CF R-CNN 与Faster R-CNN 损失曲线Fig. 5 Loss curve of CF R-CNN and Faster R-CNN

表2 不同组合的训练时间和AP 值Tab.2 Training time and AP values for different combinations
从图6 对比可以看出,CF R-CNN 的检测效果更好,把所有的基础算式都定位出来,而Faster RCNN 每张图都存在没有检测出来的算式(算式35和算式48)。主要原因是Faster R-CNN 的锚框与基础算式匹配度太低,而CF R-CNN 选用了更准确的锚框尺寸和比例,使得检测效果得到提升。
在定位准确度方面,从图6(b)可以看出,算式37 中手写数字9 的上部落在了定位框外;图6(b)的算式49,最后一个数字2 全部都处于定位框之外。这些定位的不准确都会带来后续的识别偏差,从而造成最终批改系统的错误判别。分析主要原因应为ROI Pooling 的2 次量化造成偏差,使得定位框不够准确,而用ROI Align 替换ROI Pooling 后,消除了这部分偏差,这样一来定位就会更加准确。

图6 测试结果对比图Fig. 6 Comparison chart of test results
4 结束语
为了提高基础算术题检测与定位的准确度,研究提出了基于改进Faster R-CNN 的CF R-CNN 方法。由于传统的Faster R-CNN 中RPN 的3×3、共9种锚框,与基础算式匹配度不高,不再适用于基础算式检测定位。通过创建数据集,并对基础算式的尺寸和比例进行聚类分析,得出多种初始组合,进行实验对比分析,最终选择效果最佳的4×4 的16 种组合。用ROI Align 替换ROI Pooling,有效避免了ROI Pooling 两次量化带来的偏差。在500 张基础算式的图片数据集上进行训练测试,相比于传统的Faster R-CNN,CF R-CNN 的收敛速度更快、损失更小、定位更准确,为后续的基础算式识别和自动批改提供保障。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
孩子(2019年5期)2019-05-20 02:52:44
电子制作(2018年19期)2018-11-14 02:37:08
数位时尚(幼儿教育)(2017年12期)2018-01-05 01:23:30
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
测绘科学与工程(2014年6期)2014-02-27 07:06:23
