
基于Pix2Pix 的人脸素描图像生成方法研究
2022-02-07 09:19:46陶知众王斌君崔雨萌闫尚义
智能计算机与应用 2022年12期
陶知众,王斌君,崔雨萌,闫尚义
(中国人民公安大学 信息网络安全学院,北京 100038)
0 引言
图像风格转换是指将一幅图像从所在的原图像域转换到目标图像域,使其在保留图像原本内容的同时又能具有目标图像域风格的一种图像处理技术。图像风格转换在社交娱乐和艺术创作领域具有十分广阔的应用前景,因此受到学术界和企业领域的高度关注。早期的图像风格转换被看作是图像纹理生成问题,即通过设置一定的约束条件,使生成的图像既包含了原图像的语义内容,又具有目标图像域的纹理特征[1]。而自深度学习问世以来,很多基于深度学习的图像处理算法也已相继提出,利用深度学习来处理图像风格转换问题的各种研究也陆续展开。Gatys 等人[2]提出了一种基于卷积神经网络的图像风格转换方法,通过预训练的VGG-19[3]模型提取输入图像的内容特征图和风格特征图,并使用在此基础上定义的内容损失函数和风格损失函数生成图像,该方法生成的图像效果优于许多传统的机器学习算法。Goodfellow 等人[4]提出的生成对抗网络(Generative Adversarial Networks,GAN)因其生成图像质量高、易于实现、兼容各种网络模型等优点而倍受关注,很多基于GAN 的风格转换模型也取得重大突破,其中包括CycleGAN[5]、StarGAN[6]及Pix2Pix[7]等。研究可知,CycleGAN 模型通过添加循环一致性损失函数,解决了在图像风格转换任务中缺少监督训练数据集的问题。StarGAN 模型则解决了多个图像领域间风格转换的问题,使其可以只经一次训练便可实现多个图像风格间的转换。Pix2Pix 模型则在cGAN[8]的基础上,将U-Net[9]作为生成器,PatchGAN 作为鉴别器,如此一来则可以生成质量较高的图像,并且因为其结构简单,易于训练等特点,目前在图像生成领域比较流行。
由于人脸图像细节较为丰富,而采用Pix2Pix模型很难捕捉到这些细节中所包含的信息,导致生成的人脸画像在五官、脸部轮廓等细节丰富部位会出现模糊、信息缺失等问题。文中针对该问题,提出一种改进Pix2Pix 模型。在Pix2Pix 基础上,研究的主要创新点包括:
(1)在原Pix2Pix 模型的生成器和鉴别器中引入自注意力模块(Self-Attention Mechanism,SAM),使模型能够更好地学习到人脸的空间轮廓特点,从而解决生成图像在人脸五官等部位细节模糊或缺失等问题。
(2)在原Pix2Pix 生成器的损失函数中引入了内容-风格损失函数,使生成器生成的素描图像在不丢失原图像细节内容的同时,在观感上更接近手绘素描图像。
(3)针对原Pix2Pix 模型训练难度大、难以收敛等问题,提出了改进的训练方法,进而降低模型整体训练难度,加速模型收敛。
1 相关基础理论
1.1 Pix2Pix
GAN 是一种由生成器(Generator)和鉴别器(Discriminator)共同构成的深度学习模型。其中,生成器负责学习训练集输入数据的概率分布规律并生成具有相似概率分布的输出数据;鉴别器负责评估输入数据来自训练集或生成器的概率。训练过程中生成器和鉴别器一同训练,鉴别器的训练目标是能够正确区分输入数据是来自训练集或者生成器,而生成器的目标是尽量使鉴别器做出错误的判断。通过让2 个模型进行对抗训练,使生成器生成数据的概率分布更接近真实数据,而鉴别器对生成数据和真实数据的鉴别能力也随之提高,并最终达到一种平衡状态。目前,GAN 越来越受到学术界重视,尤其是在计算机视觉领域,许多基于GAN 的深度学习模型也逐渐进入学界视野,并已广泛应用在如图像风格转换[4-6]、超分辨率[10-11]、图像复原[12-13]等图像处理任务上,继而不断向着其他领域扩展,具有广泛的应用前景[14-15]。
Pix2Pix 是由Isola 等人[7]提出的一种专门用于处理图像翻译问题的条件生成对抗网络模型。该模型包含了一个生成器和一个鉴别器,其中生成器可以根据输入图像生成其在目标图像域的对应图像,而鉴别器则是尝试分辨输入图像的真实性。Pix2Pix 模型结构如图1 所示。

图1 Pix2Pix 模型结构示意图Fig. 1 Structure of Pix2Pix module
图1 中,x,y分别表示2 个不同图像域X,Y中的图像。在训练生成器G时,将x输入到生成器中,生成具有Y图像域风格的图像y' =G(x)。在训练鉴别器D时,则将y或y'和x一同输入到鉴别器D中,D输出图像来自生成器G的概率。
Pix2Pix 模型的损失函数主要由条件对抗生成损失函数lcGAN和L1损失函数lL1两部分组成,其中lcGAN的表达式见如下:

式(1)中,生成器以输入的真实图像作为条件,试图生成符合真实图像分布的对应虚假图像并欺骗鉴别器,因此生成器的训练目标是尽量减小;而鉴别器则在观察真实图像的基础上试图分辨输入的对应图像的真实性,因此鉴别器的训练目标是尽量增大。损失函数的表达式如式(2)所示:

损失函数用来确保生成器在生成虚假对应图像时,除了要考虑使虚假对应图像在概率分布上更接近真实对应图像外,还应使其在像素层面更接近于真实图像。因此,Pix2Pix 模型的最终损失函数具体如下:
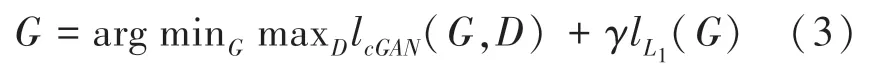
其中,参数γ为损失函数的权重,控制着条件对抗生成损失函数和损失函数的相对重要性。
Pix2Pix 的生成器采用了U-Net 框架。相较于传统的编-解码器框架,Pix2Pix 生成器网络在第i卷积层和第n -i卷积层之间增加了直连路径,其中n是生成器网络总层数,每一个直连路径会将第i层各信道信息拼接在第n -i层各信道之后。通过增加直连路径,Pix2Pix 的生成网络可以使输入图像和输出图像共享低层信息,同时也确保了梯度信息能够在深层网络中有效传播,改善深层网络性能。同时,Pix2Pix 生成器网络还在某些层中使用了Dropout,以取代GAN 中作为输入的噪声。生成器的网络结构如图2 所示。
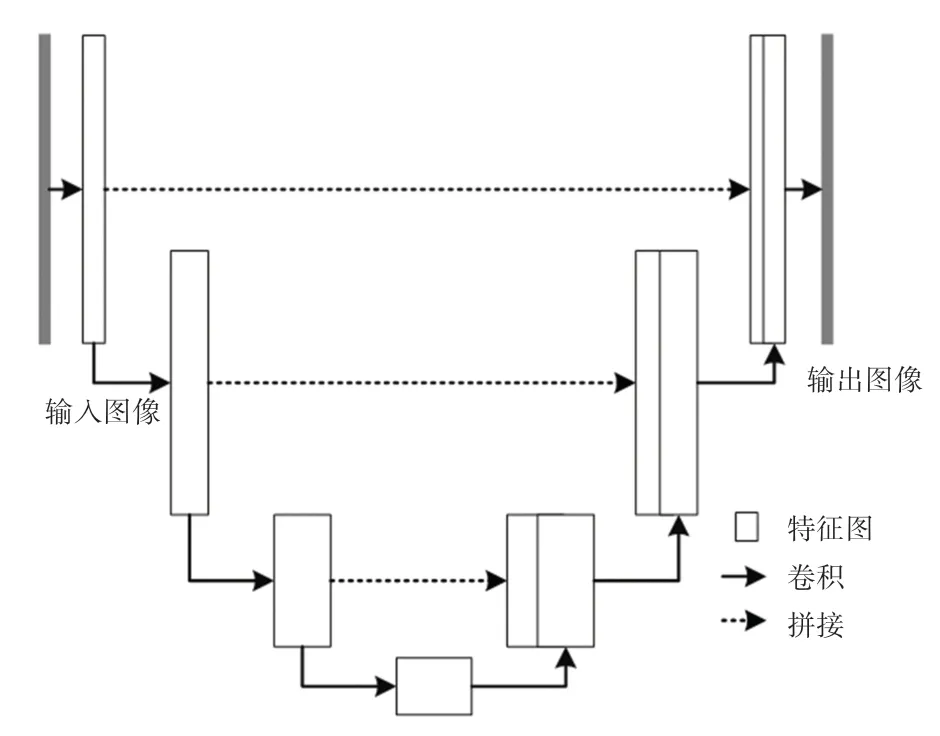
图2 Pix2Pix 模型的生成器网络结构Fig. 2 Generator network structure of Pix2Pix model
Pix2Pix 的鉴别器使用的是PatchGAN 结构。不同于传统鉴别器,PatchGAN 的输出是一个n × n的矩阵,矩阵中每一个元素的值代表对输入图像对应图像区块的判别结果,训练过程中,再通过将鉴别器产生的矩阵元素均值作为整幅图像的最终判别结果,PatchGAN 通过将鉴别器的注意力集中在图像各个子区块的方式,使鉴别器可以更好地处理图像高频部分,同时,采用PatchGAN 结构的鉴别器相较于传统分类网络具有更少的参数,更短的训练周期,并且通过调整n的大小,PatchGAN 可以应用于任意尺寸的图像,并使生成的图像保持较高质量。
1.2 自注意力机制
注意力机制(Attention Mechanism,AM )是一种改进神经网络的方法,主要是通过添加权重的方式,强化重要程度高的特征并弱化重要程度较低的特征,从而改善神经网络模型的性能[16],注意力机制得到的权重既可以应用在信道上[17-18],也可以应用在特征图或其它方面[19-20]。
自注意力机制是由Zhang 等人[21]提出的一种专门用于生成对抗网络中的注意力机制变体,其结构如图3 所示。针对卷积层的信息感受能力会受到卷积核大小的影响而无法高效捕捉到各个图像中同类物体的具体特征(如某种动物的毛发纹理特征、人的肢体结构特点等)这一问题,自注意力机制通过计算输入特征图中每一个位置在整个特征图中的权重,使整个网络可以更快注意到不同输入图像中各物体的空间和纹理特征,从而针对输入图像的不同部位分配不同的权重,达到增强生成图像质量的效果。鉴于在人脸素描生成任务中,输入人脸照片和输出的人脸素描图像在结构上具有高度的关联性以及相似性,因此自注意力机制可以帮助神经网络更快地定位人脸细节丰富区域,并且更好地学习到各部分的统计特征,从而提高最终生成的人脸素描图像的质量。
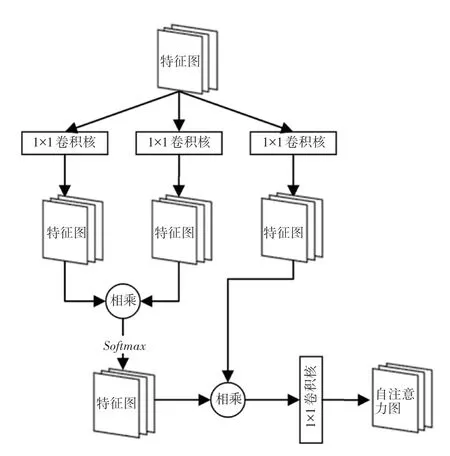
图3 自注意力机制模块图Fig. 3 Structure of self-attention mechanism
1.3 内容-风格损失函数
内容-风格损失函数(Content -Style loss Function)是由Gatys 等人[2]在2016 年提出的一种专门用于图像风格转换问题上的损失函数,其原理是使用预训练的神经网络分别对内容图像、风格图像和生成图像进行特征提取,通过计算提取到的特征图像之间的差异来衡量生成图像在内容和风格上与对应图像的差异。内容-风格损失函数由内容损失函数和风格损失函数两部分组成。其中,内容损失函数计算公式可表示为:
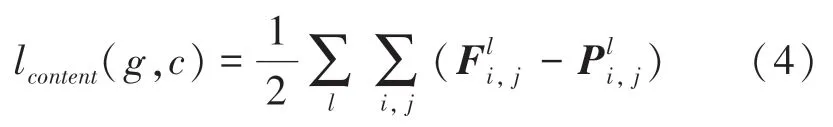
其中,g为生成图像;c为内容图像;Fl和Pl分别为预训练神经网络第l层提取的生成图像g和内容图像c的特征图矩阵。
风格损失函数计算公式可表示为:
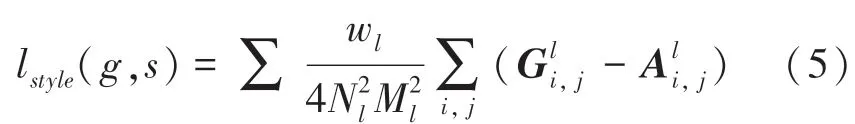
其中,g为生成图像;s为风格图像;Gl和Al分别为生成图像和风格图像在预训练神经网络第l层的风格特征矩阵;N和M为第l层风格特征矩阵的行数和列数。Gatys 等人[2]将图像在神经网络第l层的风格特征矩阵定义为该层特征图的格拉姆矩阵(Gram matrix),其计算公式可表示为:
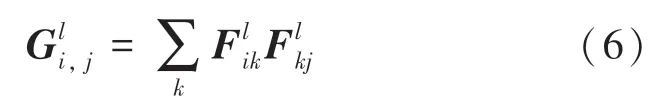
最终,内容-风格损失函数计算公式可表示为:
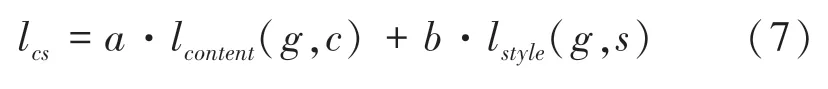
其中,a和b分别为内容损失函数和风格损失函数的权重。
2 基于自注意力机制和风格迁移的Pix2Pix
2.1 模型结构
鉴于自注意力机制能更好地发现图像中大范围特征间的依赖关系,所以,在空间尺寸越大的特征图上、自注意力机制发挥的作用也就越大,但与此同时更大尺寸的特征图也会显著增加模型训练的时间成本。因此本文将自注意力机制添加到生成器网络中最后3 层之间,以达到在增强生成图像质量目的同时尽量减小网络训练成本。文中提出的改进Pix2Pix 模型的生成器网络模型如图4 所示。
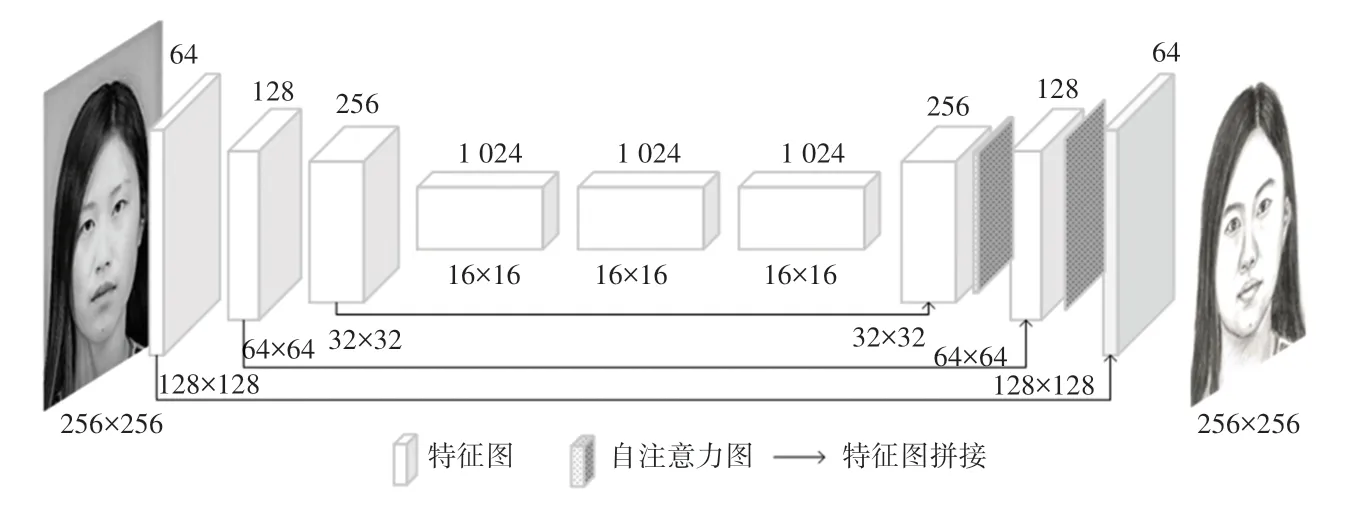
图4 基于自注意力机制的Pix2Pix 生成器网络结构Fig. 4 Network structure of Pix2Pix generator based on self-attention mechanism
生成器的编码器卷积层参数设置均为:卷积核尺寸为4×4,步长为2,特征图边缘填充为1,填充方式为镜像填充,激活函数使用LeakyRelu,其参数设置为0.2;解码器反卷积层参数设置为:卷积核大小为4×4,步长为2,特征图边缘填充为1,填充方式为镜像填充,激活函数使用ReLu函数,前两层卷积网络使用Dropout,概率设置为0.5。鉴别器网络模型如图5 所示。
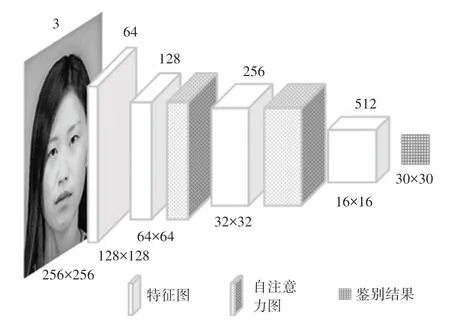
图5 基于自注意力机制的Pix2Pix 鉴别器网络结构Fig. 5 Network structure of Pix2Pix discriminator based on selfattention mechanism
鉴别器卷积层参数设置为:卷积核尺寸为4×4,特征图边缘填充为1,填充方式为镜像填充,前三层卷积核步长为2,后两层卷积步长为1。所有卷积层都采用LeakyReLu为激活函数,其参数设置为0.2。
由于在图像风格转换问题中,生成图像的风格主要依赖于风格图像的对比度信息,因此生成器在生成图像时应该尽量屏蔽内容图像中的对比度信息,而批归一化(Batch Normalization)[22]并不能很好地消除来自内容图像中的对比度信息,因此在改进的Pix2Pix 模型的生成器网络和鉴别器网络中,使用实例归一化(Instance Normalization)[23]代替了批归一化。对于输入的一组特征图,IN 对每一特征图的每一信道进行归一化处理,从而更好地消除了每个特征图中包含的特殊信息,减少了图像生成过程中的干扰,并加快了生成器网络的收敛过程。
2.2 损失函数
改进Pix2Pix 模型的损失函数的具体表达式为:
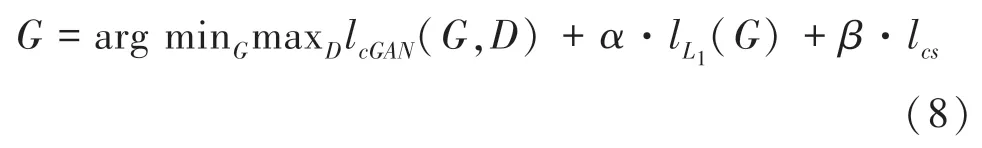
其中,lcGAN(G,D)为Pix2Pix 模型中生成器和鉴别器的对抗损失函数;lL1为Pix2Pix 生成器生成图像和手绘人脸图像的L1损失;lcs为内容-风格损失函数,这里a设为1,b设为0.1;α和β分别为控制损失函数和内容风格损失函数的权重,α设为100,β设为1。在计算内容损失函数lcontent(g,c)时,本文选择VGG16 网络第二层中的第二个卷积层来提取生成素描和人脸照片的内容特征;而在计算风格损失函数lstyle(g,s)时,则选择VGG16 网络中第四和第五层中的第一个卷积层来提取生成素描和对应手绘素描的风格特征。
2.3 改进训练方法
GAN 的训练是一个生成器和鉴别器互相博弈的过程,在这个过程中生成器试图生成与实际数据尽量相似的数据骗过鉴别器,而鉴别器则试图区分输入数据是否是真实数据,理论上,随着训练的进行,二者性能逐渐提高,并最终达到一种稳定状态。但在实际训练过程中,由于生成器和鉴别器网络训练难度不同、所采用的优化算法、学习率设置和数据集等因素影响,很难使2 个网络同时收敛或达到纳什均衡,造成生成器部分或完全崩溃,以及某一模型收敛过快导致另一模型梯度消失等问题。因此,为了使GAN 训练过程更稳定,文章采用的策略可做阐释论述如下。
(1)在生成器网络和鉴别器网络中使用谱归一化(Spectral Normalization)。根据Ulyanov 等人[23]的研究,在生成器和鉴别器网络中使用谱归一化可以约束每层网络参数的谱范数,从而使网络参数在更新过程中变化更平滑,整个训练过程更加稳定。
(2)生成器和鉴别器采用不同的初始学习率及学习率调整策略。由于鉴别器的训练难度比生成器低,导致其损失很快收敛到一个非常低的值,无法为生成器梯度更新提供有效信息。因此,为了使生成器和鉴别器能够在训练过程中保持一种较为平衡的状态,让两者能够互相学习,在训练开始时分别为两者设置不同的学习率,并在随后的训练过程中根据具体训练效果采用不同的学习率更新策略。
3 实验结果与分析
实验的硬件平台为QEMU Virtual CPU Version 2.5+,使用NVIDIA Tesla V100-SXM2-32 GB 进行加速处理。数据集使用CUFS(CUHK Face Sketch Database),该数据集共包含606 对人脸-素描图像。实验选取CUFS 数据集中594 张素描人脸图像作为训练数据集;选取CUFS 数据集中12 张学生人脸图像作为测试图像;将所有训练图像和测试图像的大小缩放为256*256 像素,并通过以50%的概率对人脸图像-素描对进行水平翻转和亮度随机调整的方式对数据集进行增强。生成器和鉴别器的优化器采用Adam 算法,用于计算梯度以及梯度平方的运行平均值的参数beta1 和beta2 分别设置为0.5 和0.99,生成器的初始学习率设置为1e-3,鉴别器的初始学习率设置为1e-4。训练过程中,当生成器的损失函数无法下降、并超过10 个epoch时,其学习率下降10 倍;当鉴别器的损失函数无法下降、并超过30 个epoch时,其学习率下降10 倍。训练共进行200 个epoch,训练结束时生成器的学习率为1e-8,鉴别器的学习率为1e-8。
为更好地展示改进Pix2Pix 模型在人脸素描图像生成任务上的有效性,本文将改进模型的生成人脸素描图像与Pix2Pix 模型和CycleGAN 模型生成的人脸素描图像进行对比,上述所有模型在相同实验平台上训练了200 个epoch。
3.1 改进训练方法效果比较
为验证本文提出的改进GAN 训练方法的有效性,将原Pix2Pix、分别采用谱归一化和不同学习率更新策略的Pix2Pix 以及采用本文训练方法的Pix2Pix 在实验数据集下分别训练150 个epoch,并观察在每个epoch后生成器损失函数值变化情况。最终结果如图6 所示。
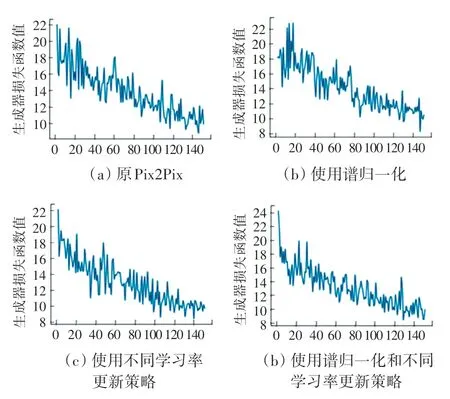
图6 原Pix2Pix 和采用不同训练方法后的Pix2Pix 在150 个epoch内损失函数变化对比Fig. 6 Comparison of loss function changes of original Pix2Pix and Pix2Pix after using different training methods within 150 epochs
从图6 可以看出,采用谱归一化和不同学习率更新策略的Pix2Pix 相比于原Pix2Pix 生成器在训练过程中损失函数下降更快,但下降过程中仍然波动较大,而采用本文训练方法的Pix2Pix 生成器在训练过程中不仅损失函数下降相比原Pix2Pix 更快,下降过程中其波动也比其它3 种更小,从而证明本文改进GAN 训练方法的有效性。
3.2 生成图像质量比较
为更好地验证文中改进Pix2Pix 模型在人脸素描生成任务中的有效性,除将其与原Pix2Pix 模型进行对比外,还选择了GycleGAN 模型与其进行对比分析。GycleGAN 模型作为图像翻译领域中另一经典模型,因其训练时不需要成对数据集、易于实现以及生成图像质量高等特点,一经提出便受到了广泛关注,因此选择将其作为参照对象可以使参照实验结果更具有代表性。
改进模型生成图像与其它模型生成图像对比如图7 所示,通过对比发现,文中提出的改进Pix2Pix模型生成的人脸素描比Pix2Pix 和CycleGAN 生成的图像人脸轮廓更清晰,细节部分保留更完整,表情更明显,噪点更少,同时在整体观感上更接近人工绘制素描。

图7 生成图像质量对比Fig. 7 Generated images quality comparison
3.3 生成图像量化比较
为量化评价改进Pix2Pix 模型生成的图像质量,本文采用特征相似度(Feature Similarity Index Measure,FSIM)作为系统评价指标[24]。相较于SSIM[25]和MS -SSIM[26],FSIM充分考虑了图像视觉信息的冗余性和人类视觉系统主要通过低级特征来理解图像的特点,并且更偏向于清晰度较高的图像[27]。FSIM通过计算2 幅图像的相位一致区域和图像梯度幅值来评价这2 幅图像在人类视觉系统中的相似度。其中,相位一致区域用来寻找一张数字图像在人类视觉系统中会被认为是“信息量丰富”的区域,而图像梯度幅值用来弥补相位一致性无法感知图像局部对比度变化对图像整体视觉效果产生影响的不足。在测试集上各模型所得FSIM分数见表1。由表1 数据可知,改进Pix2Pix 模型在测试集上得分为0.648 3,相比原Pix2Pix 模型和CycleGAN模型分别提高了0.020 6和0.027 6,从量化指标上进一步说明了文中提出的改进Pix2Pix 模型在人脸素描生成任务中的有效性。此外,相比于原Pix2Pix和CycleGAN 模型更低的分数方差也说明除生成的素描图像质量更好之外,改进Pix2Pix 模型在稳定性上相较于其它对比模型也更有优势。
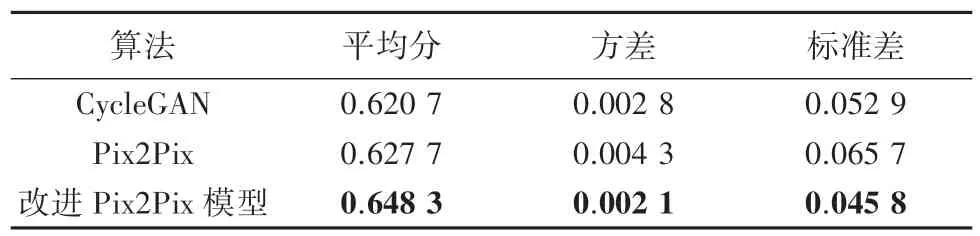
表1 各模型在测试集上FSIM 得分Tab.1 FSIM score of each model on the test set
3.4 消融实验
本文通过消融实验对比分析,进一步验证了文中提出的改进Pix2Pix 模型中各改进点在人脸素描生成任务中的优化效果,实验结果见表2。从表2数据可知,原Pix2Pix 在测试集上FSIM得分为0.627 7,引入自注意力机制后,增强了原Pix2Pix 模型细节特征提取能力,将测试集上FSIM分数提高了0.108;而通过在生成器的损失函数中加入内容-风格损失函数,亦提高了模型在测试集上的表现。综合上述2 种改进后,相较于原Pix2Pix 模型,本文提出的改进Pix2Pix 模型有效地提高了生成的人脸素描图像质量,说明了改进Pix2Pix 模型在人脸素描生成任务中的有效性。

表2 消融实验Tab.2 Ablation experiments
4 结束语
文中主要对Pix2Pix 的生成器模型进行改进,将自注意力机制用于生成器和鉴别器网络中,减小无用信息对生成器的影响,加强生成器对输入图像中的人脸重要部分的学习,提升生成的人脸素描图像的质量;并在生成器损失函数中引入了内容-风格损失函数,使生成网络在生成人脸素描图像时既保留人脸照片中的细节部分,又能使图像更接近素描风格。同时,量化比较实验表明,改进Pix2Pix 在测试集上的FSIM得分比Pix2Pix 和CycleGAN 分别高出了2%和2.7%,进一步说明了改进Pix2Pix 在人脸素描生成任务中的有效性。但与此同时,该改进模型依然存在一些问题,如对非正面拍摄的人脸图像效果较差。因此今后的工作便是提出能针对各种不同场景下不同角度的人脸图像也能生成质量较高的人脸素描图像的生成方法。
猜你喜欢
通信学报(2022年10期)2023-01-09 12:33:40
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
江苏安全生产(2021年6期)2021-08-05 07:47:22
歌剧(2020年4期)2020-08-06 15:13:32
雨露风(2020年8期)2020-04-26 19:55:51
国防科技大学学报(2019年4期)2019-07-29 03:40:14
动漫星空(2018年9期)2018-10-26 01:17:14
读者(2016年23期)2016-11-16 13:27:55
系统工程与电子技术(2016年5期)2016-11-02 00:37:48
发明与创新(2015年33期)2015-02-27 10:40:09
