
基于GAN的背景去除关键技术研究
2022-02-04 07:41司亚超
河北建筑工程学院学报 2022年3期
司亚超 董 振
(河北建筑工程学院,河北 张家口 075000)
0 引 言
图像背景去除技术在计算机视觉深度学习[1-3]领域占有非常重要的地位.例如在汽车驾驶[4]方面,对行人、车辆的等目标,需要精细的分割用于紧急避让等应用;在智能识物[5]应用上,需要物体整体的正确分割,在地理信息科学[6]方面,对街道、建筑、植被、山等物体,需要细致的小面积物体分割,可见图像背景去除在日常生活中具有十分重要的实际应用价值.
在具有不均匀背景元素的场景中进行图像分割是一项繁琐的任务,为了实现场景中完整的自动前景提取,提出了一种将语义分割和深度网络图像处理融合到单一网络中以生成高精度前景的方法.本方法将改进的Deeplabv3+[7]和对抗生成网络相结合.与一般的抠图技术不同,采用以多尺度判别器[8]为核心的生成对抗网络训练可以将前景边缘细节更好的优化,该网络通过无监督学习自适应地从真实数据和随机生成数据进行“博弈”,以获取高质量前景.
每个三通道图像都是在边缘像素分布都是类似的,在前景边缘处,其透明度并不是一个非0即1的像素值.为了背景去除便利性,对前景物体增加α通道(或称为Alpha通道,透明度),该通道代表了前景的透明度,像素值由0至255,在背景处其像素值为0,前景部分为1,但在过渡边缘处为0至255的值.由此作为研究方向可以更加精确地提取物体的前景.背景去除将一幅图像分成前景和背景,两者通过各自不同的透明度混合组成一幅图像:
C=αF+(1-α)B
(1)
(1)式中α代表该图像的不透明度,F代表图像的前景部分,B代表图像的背景部分,α值介于0~1之间,当α=0时,C表示背景图像;当α=1时,C表示前景图像,所以确定α值是背景去除的关键,以及计算前景和背景之间的边缘信息.在之前的抠图算法中都会使用三分图确定待抠区域,用单一的背景(绿屏抠图)来减少未知量,但是该方法工作量较大,并且由于人为因素,图像边缘可能会出现瑕疵,于是本文先通过一个语义分割网络获取二值化分割结果,再将该结果与原图等内容作为先验信息输入到生成对抗网络进行训练,非交互地准确地将原图的前景分离出来,并得到准确的前景边缘信息.
1 相关工作
使用Pascal VOC数据集作为训练数据,本文主要提出了基于一个深度学习的网络,以便于实现人像的前景自动分割的问题.算法流程主要为前景二值分割以及前景Alpha抠图.首先使用DeeplabV3+网络模型框架,将无关的背景类裁减掉,输出Trimap,然后使用Encoder-Decoder作为生成器,多尺度判别器作为判别器的生成对抗网络架构,以Trimap和原图为输入,通过编码和解码迭代训练,得到适用于人体背景去除的模型.
近年来出现了不少基于关于背景去除的方法,对于传统背景去除的方法,很多文献已经做过了综述,比如文献[9].其中,对于图像的背景去除方法,经典的方法有贝叶斯抠图算法、Robust Matting算法以及Grabcut法等,Grabcut算法通过人为加入前景、背景和过渡区域,来进行背景去除.其他算法例如贝叶斯抠图算法[10]该方法在对前景和背景中间的过渡区域对每个位置像素的近邻点进行聚类,不断迭代来求得最好的解,缺点是计算量很大,并且对三分图的要求非常精细.
深度学习领域中,通过使用深度学习网络学习图像的高级语义信息和低级特征,来对图像的进行背景去除,并且能够以像素的级别对图像的高级语义和低级特征信息进行背景去除.文献[11]对深度学习领域的图像分割文献给出了非常详细的的阐述.深度图像抠图方法(Deep Image Matting,DIM)[12]使用对称的Encoder-Decoder结构网络,获得α的值,达到背景去除目的.文献[13]通过深度学习网络学习低级和高级特征,也依赖于Trimap,并且对Trimap的质量要求较高.文献[14]使用CNN学习图像特征,用Trimap作为中间输入,但是由于三分图的制作须为人工操作,工作量较大,导致应用较局限.Lutz等[15]首次在背景去除问题中加入将对抗生成网络,并且最终结果也是不错的.文献[16-17]首次提出了非交互式的抠图算法,来减少工作量,并提高了应用范围和泛化性.文献[17]首先自动预测图像的Trimap,再进行Alpha抠图得到最终的掩码结果.在自动生成Trimap时,该方法需要对像素进行三分类标注及预测,本文最终达到的目的是自动分割,因此对于其他自定义数据集,仅需通过标记方法对前景进行标注即可.
2 算法实现
2.1 Deeplabv3+
Chen[7]提出deeplab V3+网络,主要应用于图像分割领域,该网络采用编码解码器结合以及改进的空间空洞金字塔模块来提高分割精度.如图1所示,网络的输入为三通道RGB图像,通过改进后的Xception模块进行特征提取,Xception模块分为输入流、中间流、输出流.作者增加了中间流特征提取层的重复次数,增加网络层数.并替换最大池化为深度可分离卷积,降低了参数量,以及在3×3卷积后添加BN和Relu.Xception网络输出特征图,并随后传入空间空洞金字塔模块,进行深度特征提取.继V3版本的ASPP模块提出后,V3+ 版本对ASPP进行改进,比如,在开头引入1×1卷积进行特征通道融合,增加通道交互性.经过ASPP模块后的特征图结束了编码层的特征提取工作,由于ASPP中合理空洞率的设计,保持了特征图分辨率大小不变性.通过短连接(Short Connection,SC)与编码层同分辨率低级空间信息进行级联,融合高层特征与低级特征,防止丢失低层信息.通过3×3卷积提取信息后进行上采样工作,获得分割图.

图1
如图2,通过可视化方式对deeplabv3+和改进后的分割效果进行评价,显而易见,经人像训练后的deeplab v3+模型可以很好的获得人像轮廓但是发现有目标缺失的情况,边缘分割不彻底.可能的原因有,空间空洞金字塔模块缺少各空洞分支的相关性,以及数据集标注问题.针对上述问题,本文对DeepLabv3+网络进行了改进.

图2
2.2 改进的DeeplabV3+网络
Deeplab v3+网络核心的空间空洞金字塔模块中的空洞卷积扩张率分别为6、12、18,由于普通卷积增加感受野可以通过增加卷积核的大小,但是无形之中也加大了参数量,使网络难以训练.而通过空洞卷积扩大感受野是在卷积核之间增加对应空洞率的0值,扩大卷积核大小,既保持了特征图的分辨率,也不增加参数量,最终的输出中,选择性输出非零值的采样结果.如果扩张率增加到一定程度,那么空洞卷积核就可能扩大到与特征图类似的大小,那么空洞卷积此时就会退化为1×1卷积,不仅网络没有提升,还会发生退化问题.并且在卷积核占比中,零值占比较多,空洞卷积并不能获取足够的信息,特征之间也没有相关性.
基于以上分析,通过对文献[19]的阅读,进行如下改进,通过感受野融合的方式,改进ASPP结构,以密集连接的方式将每层空洞卷积后的特征与原特征结合输入下一个空洞卷积,使得ASPP的特征更加密集,同时提高感受野,和特征的利用率.改进Deeplabv3+模型的网络结构如图3所示.
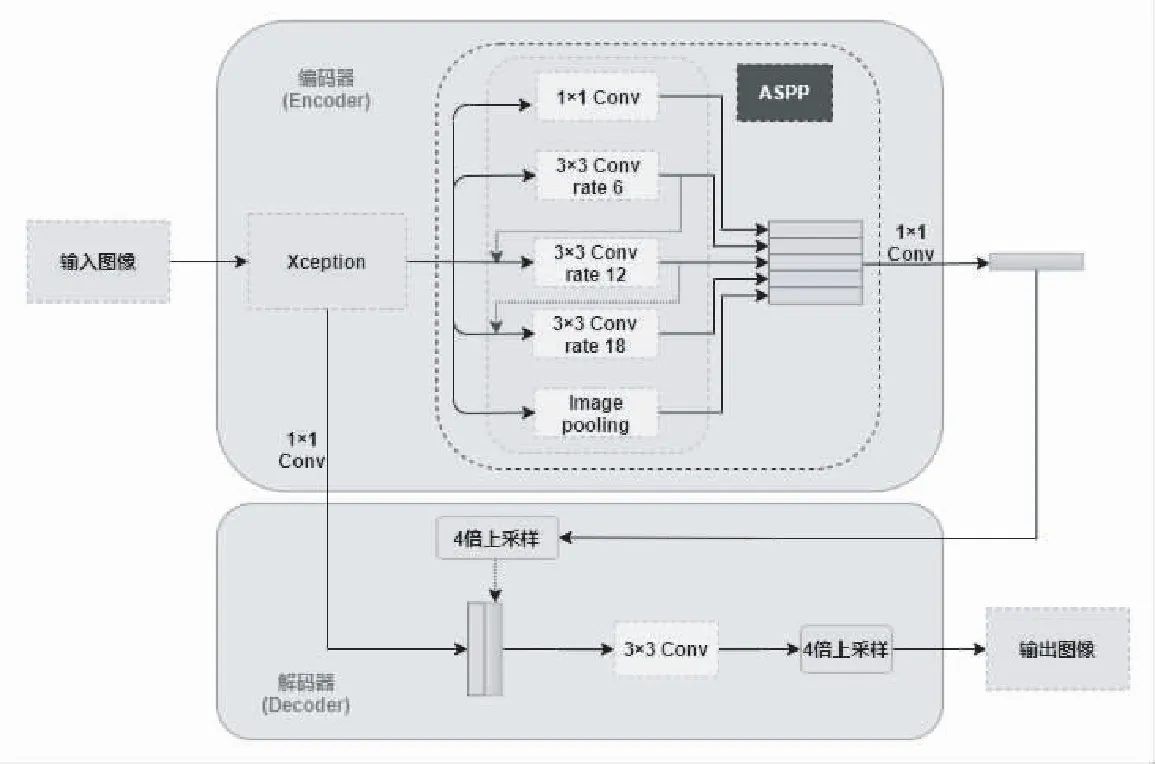
图3
ASPP结构中,空洞卷积扩张率为r=6的特征与Xception的输出进行通道拼接,然后输入到扩张率r=12的空洞卷积中得到特征图.将特征图与Xception的输出进行通道拼接,输入到扩张率r=18的空洞卷积中得到特征图.在ASPP的最后将特征图进行通道拼接.
2.3 基于多判别器的对抗生成网络
生成对抗网络(Generative Adversarial Networks,GAN)由生成器G(Generator)和判别器D(Discriminator)组成,之所以称之为对抗网络,是因为他的训练时由两个网络为达到各自的目的进行对抗训练.生成器接受噪声产生输出,判别器通过分辨生成器的生成结果,反向传播来优化生成器.生成器与判别器存在一定的差异,其不同点在于目的不同,生成器的目的是通过训练集的训练生成尽可能接近训练集的数据来欺骗判别器,而判别器的目的是判别生成器的生成效果如何,最终输出真假值.在训练过程中,生成器与判别器进行动态博弈,最终的理想结果就是判别器难以判别生成器的生成结果是否真实,而此时的生成器的效果就可以生成接近训练集的真实图像.在通常情况下生成器的输入通常带有条件C,由C来指导生成器进行训练,而本文的C即训练集,生成器生成的图像与训练集随机图像共同输入判别器D进行判别.判别器通过设置的损失函数判别真实样本生成样本的差异,同时,反馈机制会对生成器G与判别器D进行调节,经过多次迭代训练后,生成器网络的分割精度以及判别器网络的判别能力不断提高.
Pix2pix在GAN的一个分支cGAN的基础上做image translation,并在之后进行重要升级,成为pix2pixHD,可以实现高分辨率图像生成和图片的语义编辑.pix2pixHD的生成器和判别器都是多尺度的,多尺度判别器的每个尺度又使用了3个线性判别器.每个线性判别器都一个全卷积网络,由若干组卷积,BN和Leaky ReLU组成.判别器的3个尺度分别为:原图,原图的1/2,原图的1/4.不同尺度的判别器的优点在于越粗糙的尺度感受野越大,越容易判别全局一致性,而越精细的尺度感受野越小,越容易判别材质,纹理等细节信息.
3 实验过程及数据分析
3.1 实验配置和数据
本文算法基于Tensorflow框架,实验硬件配置为为处理器:Intel i9-9900k,内存64GB,显卡NVIDIA RTX2080TI.实验数据来自淘宝商品图,使用爬虫从电子购物网站爬取大量图片,并通过python语言使用数学方法筛选出符合训练集和测试集要求的共计千余张图片,作为网络输入,其中类别为1类.

表1
3.2 实验流程
按照DeeplabV3+官方要求,制作好训练集后,将训练集转化为TFrecord文件,以便适应TensorFlow网络框架.将TFrecord文件作为改进DeeplabV3+网络模型的输入,从而进行训练.再将获得的mask作为对抗生成网络的输入,进行训练.当模型的损失收敛至稳定后,使用测试集来测试改进后的网络是怎么样的效果.
3.3 在Pascal VOC数据集上的实验结果
我们训练了基于Adobe Image Matting(AIM)数据集的269人类样本和11个测试样本的训练集:通过将269个人类样本合成到1000个随机背景.在训练中我们将所有图像都重新缩放到512×512,使用Batchsize为4,学习率为1e-4的Adam优化器来进行训练,训练后验证的MIOU达到了0.947402.本方法改进前与改进后的实验结果如图4.

图4
通过对比发现,与改动前相比,本方法对背景的干扰具有更强的鲁棒性,训练后验证的MIOU达到了0.947402,较改动之前,边缘细节更完善.
4 结 语
本文提出了一种基于GAN的背景去除技术,通过网络设计和训练工作,在PASCAL VOC 2012公共数据集上进行评估对比,相较DeeplabV3+模型有一定的精度提升,并相较之前的背景去除工作,本文并不需要手动制作三分图,由深度学习网络框架Deeplab和对抗生成网络完成背景的自动去除.
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
建材发展导向(2021年6期)2021-06-09
上海金属(2021年2期)2021-04-07
今日农业(2020年17期)2020-12-15
学生天地(2020年18期)2020-08-25
红领巾·萌芽(2019年8期)2019-08-27
中国外汇(2019年11期)2019-08-27
中国与非洲(法文版)(2017年10期)2017-11-23
故事作文·高年级(2017年2期)2017-03-01
太空探索(2016年10期)2016-07-10
