
基于主成分分析的电站锅炉受热面灰污监测方法
2022-02-02 08:48邝艺文鲁曼田
湖北电力 2022年5期
邝艺文,鲁曼田,谭 鹏,张 成
(1.广东省能源集团有限公司沙角C电厂,广东 东莞 523936;2.华中科技大学能源与动力工程学院,湖北 武汉 430074)
0 引言
2022年在全球原材料价格上涨的大背景下,随着“碳达峰”目标的提出,火电厂的电力生产面临越来越大的压力。我国燃煤机组的发电煤耗已经达到世界平均水平,且明显低于印度和澳大利亚等相对落后的国家,与欧洲等国家水平接近,但与日本等处于领先水平的国家还存在约25 g/(kW·h)的差距[1-2],说明我国燃煤机组的煤耗水平还有一定的下降空间。加强火电厂精细化管理,提高火电生产的经济性,是缓解全国电力资源紧张的重要途经。由于煤质的变化,混煤掺烧会影响锅炉的积灰结渣特性,导致了受热面积灰结渣的现象[3]。如不及时清除积灰,会降低火电生产的经济性,因此需要对锅炉的各个受热面进行灰污监测,并根据不同受热面的污染情况进行针对性地吹灰[4]。
火电厂在线性能监测模型涵盖了电厂机组的性能计算模块,收集现场的实时数据,运用性能计算模型,计算包括锅炉、汽轮发电机及各个辅机的经济性能指标[5]。目前常用的灰污监测板块主要是计算基于机理建模的洁净因子、热阻或污染率,然后由此对受热面灰污情况进行监测分析或者预测报警。Tong等[6]提出了一种受热面灰层热阻在线监测模型,其设计的支持向量回归(SVR)模型可以对低温过热器热阻去噪后进行在线预测。Kumari等[7]设计了一个基于动态非线性回归的洁净因子监测模型,从而得到优化的吹灰策略来确定临界洁净因子和吹灰循环的持续时间。刘经华等[8]根据烟气压降设计了一种受热面表面积灰厚度的计算模型,可以对对流受热面积灰厚度进行在线监测。Zhang等[9]提出了一种声学系统,用于监测锅炉水冷壁附近的温度变化,并建立反应积灰状况的新清洁系数,采用该方法对积灰结渣情况进行监测。李孟威等[10]采用清洁因子作为健康指标监测锅炉受热面健康状况,并提出融合经验模态分解(EMD)和长短期记忆网络(LSTM)的模型来预测未来锅炉积灰。钱虹等[11]提出了基于生产数据挖掘和证据融合的吹灰需求度置信规则库研究,利用数理统计、贝叶斯理论、均值聚类等相关方法确定规则库相关参数,使置信规则库的吹灰需求度结果更加接近积灰程度的表达。综上所述,这些基于机理分析建立的灰污监测模型需要全面而完整的参数数据,计算量大且复杂,而由于各电厂实际情况不一样,有些电厂可能没有相关测点数据,从而导致建模困难,使得模型的通用性较差。
设备状态在线监测与预警诊断系统直接影响着电厂设备的安全运行和电能的平稳生产[12]。由于监测系统中采集的数据众多,如果直接分析处理,工作量较多,因此减少数据维数,尽可能多地提取出可以反映原始变量信息的数据就显得非常重要[13]。主成分分析(Principal Component Analysis,PCA)是一种将多指标变量转换成综合指标来进行判断的统计方法。通过正交变换将可能存在相关性的变量转换为线性不相关且能最大程度区分每个变量的正交基,转换后的这组变量被认为是主成分[14-16]。主成分分析的基本思想是数据降维和特征提取,其实际应用十分广泛,比如人口统计学、分子动力学模拟、数学建模、数理分析等学科中均有应用,是一种常用的多变量分析方法[17]。Makis 等人[18]对考虑交叉和自相关的动态主成分分析法进行研究,以减少风险比例回归模型中协变量的数量。杨国田等[19]利用主成分分析法对火电厂DCS 系统数据进行特征提取,消除各特征变量间的耦合性,然后结合神经网络的输入,得到火电厂NOx排放预测模型。许壮等[20]将主成分分析(PCA)和随机森林(RF)相结合建立了SCR脱硝反应器出口NOx质量浓度预测模型,结果表明:与SVM和BP神经网络模型相比,RF算法得到的SCR系统模型具有更好的预测效果。李杨等[21]基于PCA 提取主成分,利用PSO 算法优化模型参数,建立了PCA-PSOLSSVM 锅炉效率预测模型。Misra 等[22]在化工锅炉的生产过程,采用多尺度主成分分析进行了故障监测与诊断的研究。王文标等[23]提出了基于改进交叉分段PCA的工业锅炉故障监测系统,实例监测结果表明该方法比传统PCA 方法的故障检测效果更好。Swiercz 等[24]基于多通道主成分分析方法对某蒸汽锅炉管道系统泄漏进行故障检测,提高了电厂锅炉的安全性。朱少民等[25]采用主成分分析(PCA)技术对主泵的传感器进行状态监测,使用某核电厂主泵的运行数据建立PCA监测模型,并利用该模型对传感器的小漂移故障和共模故障进行识别,仿真结果表明该模型对主泵传感器具有很好的监测效果。张弛等[26]文中提出了一种基于PCA和优化参数SVM的智能变电站故障诊断方法,该方法首先利用PCA分析影响因素,从而实现数据降维,然后构建出多分类SVM分类器,并通过ICA进行参数寻优,最后利用优化的SVM分类器对筛选后的样本数据进行训练与测试,测试结果得到了理想的效果。综上,PCA方法不需要对过程机理进行深入了解,通过样本数据就能建立有效的模型。因此本文提出一种基于主成分分析法的电站锅炉受热面灰污监测方法,对电站锅炉的各个不同受热面的灰污程度进行实时监测。
1 研究方法
1.1 PCA分析
PCA 的基本思想是数据降维和特征提取,在数学上的本质是找到“合适的”基向量对矩阵进行线性变换,是一种基于线性映射的特征提取技术[27]。通过一定变换将高维数据变换到一个新的低维空间,使高维数据的最大方差投影在第一个低维空间的坐标(即第一主成分分量)上,第二大方差投影在第二个低维空间的坐标(第二主成分分量)上,以此类推[28-29]。PCA 分析将获取样本数据以矩阵的形式记录为X={xij}m×n,m和n分别是该矩阵的行数和列数;将数据划分为训练集和测试集;为了避免数据集的不同属性取值量级变化对数据分析处理的影响,将所有属性进行标准化。根据训练集的均值及方差对训练集进行标准化处理,测试集的标准化处理与训练集相同。标准化处理的具体过程如下:
首先计算训练集的协方差矩阵C:

然后对其进行特征值分解,即可求解得到协方差矩阵的特征值特征向量,特征值分解为:

式(2)中,A为特征值构成的对角矩阵(对角元素满足λ1≥λ2≥… ≥λn);V∈Rm×n为正交矩阵(单位正交化后的特征向量矩阵);P为V的前a列,包含了所有主元信息。计算前a个特征值的累计贡献率:
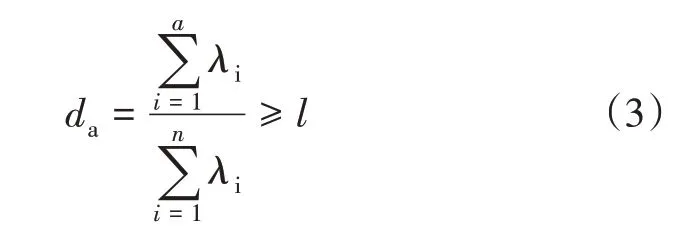
式(3)中,l为累计贡献率下限,若前a个特征值的累计贡献率da小于l,则继续增加主元个数a,直至满足条件。
1.2 统计量检验
对标准化的数据进行统计量校验,分别计算训练集和测试集降维后数据的SPE 统计量,并计算训练集SPE统计量的控制限。表示数据在主元空间和残差空间投影的变化程度,将其与相应的控制限值进行比较就可以判断出过程中是否有故障发生[30]。
具体计算公式如下:
SPE统计量的计算公式为:

式(4)中,X为标准化后的训练集,P为训练集的协方差矩阵特征值分解后由特征向量的前a列构成的矩阵。
SPE统计量的控制限计算公式为:
将计算好的测试集的SPE统计量与训练集SPE统计量的控制限进行比较,由此可以判断对象的故障情况。
2 数据处理及数据分析
本文以某电厂660 MW 燃煤机组的运行数据为例,对其锅炉受热面灰污情况进行诊断,并验证了所提出方法的有效性。机组运行参数的历史数据从该厂的DCS系统中获取,数据的采样周期为1 min,覆盖机组3个月的运行数据。基于主成分分析法的灰污监测具体流程如图1所示。
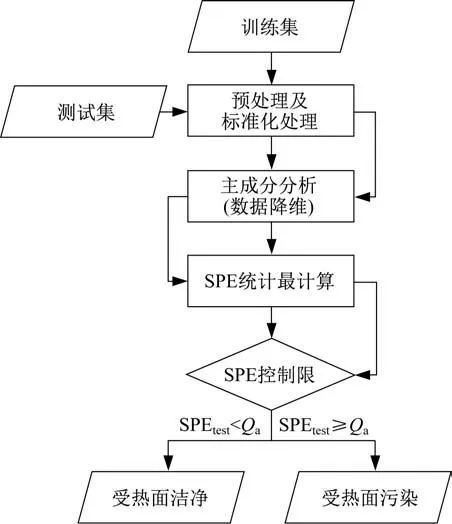
图1 PCA流程图Fig.1 PCA flow chart
2.1 数据预处理

2.2 灰污监测结果分析
本文选取与锅炉积灰结渣相关和受热面传热相关的运行参数。对于对流受热面、半辐射半对流受热面和空气预热器选择的运行参数包括负荷、受热面进出口蒸汽压力与温度以及受热面进出口烟气温度等;对于空气预热器选择的运行参数还可以是负荷、给煤率、排烟氧量、进口烟气压力、出口烟气压力等。对于超临界与超超临界锅炉辐射受热面(即炉膛水冷壁)选择的运行参数包括负荷、给水压力、给水流量、一级减温水流量、二级减温水流量、给水温度、低过入口蒸汽温度等。对于亚临界锅炉辐射受热面(即炉膛水冷壁)选择的运行参数包括负荷、给水压力、给水流量、一级减温水流量、二级减温水流量、给水温度、汽包压力、汽包水位等。
以某660 MW 电厂屏式过热器为例,根据机组实际测点,选取机组负荷、屏过进出口蒸汽温度、屏过进出口烟气温度、屏过出口蒸汽压力6 个运行参数的数据。数据预处理后,由于吹灰器进行吹灰后,受热面洁净程度较高,故将吹灰器吹灰后一段时间的数据作为训练集Xtrain,其中Xtrain∈R35177×7。再选取任意两天数据作为测试集Xtest,其中Xtest∈R2880×7。对训练集与测试集进行标准化处理,并进行主成分分析。
分别计算标准化处理后训练集与测试集的SPE统计量,选择置信度为95%即α= 0.05 的SPE 统计量控制限Q0.05。当测试集的SPE统计量SPEtest<Q0.05则认为受热面污染程度较低,暂时不需要进行吹灰,反之若SPEtest≥Q0.05,则认为受热面污染程度较高,需要进行吹灰。
如图2 所示,横轴为采样数,竖轴为SPE,图中竖线为吹灰器的吹灰动作,位于上方的曲线为洁净因子曲线,接近0 的曲线为SPE 曲线,横线为95%控制限。对同一数据源进行洁净因子计算,用以对比判断PCA方法的准确性和有效性。从分析结果来看,PCA 方法得到的SPE 曲线与计算得到的洁净因子曲线的变化趋势基本符合规律,即洁净因子降低时SPE 升高,洁净因子极小值点附近也即SPE 位于极大值点附近或超过SPE控制限(即SPEtest≥Q0.05)时,此时则应进行吹灰;同时,从图2中可以看到在第一次吹灰前存在SPE超过控制限的时间段,其洁净因子也处于下降趋势,表明在该时间段受热面的洁净程度较低,而此时吹灰器并没有吹灰,存在吹灰不及时行为,降低了受热面的换热效果。
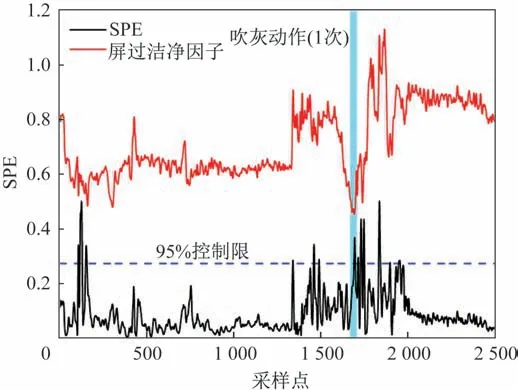
图2 屏式过热器PCA法与洁净因子灰污监测对比Fig.2 Comparison between PCA method of screen superheater and clean factor dust monitoring
同理以低温再热器和高温再热器为例,根据机组实际测点,选取相关运行参数数据。划分训练集及测试集,并对训练集与测试集进行标准化处理后,进行主成分分析建模。
该电厂高、低温再热器的主分析法SPE 统计量与洁净因子灰污监测对比曲线,如图3-图4 所示,可知,PCA方法得到的SPE曲线与洁净因子曲线的变化趋势基本相同;同时,从图中可以看到,吹灰进行之前洁净因子存在下降趋势,且SPE曲线位于控制限临界区域,说明此时吹灰的必要性;但吹灰动作之后,存在SPE曲线超过控制限和洁净因子较低的采样点,说明此时受热面比较脏污,而此时吹灰器并没有吹灰,反应了前期吹灰效果不理想,后期吹灰不及时的问题,影响了受热面的换热效果。综上可验证基于主成分分析法对电站锅炉受热面灰污监测的有效性,为电厂吹灰提供一定的指导意见。

图3 低温再热器PCA法与洁净因子灰污监测对比Fig.3 Comparison of low temperature reheater PCA method and clean factor ash pollution monitoring
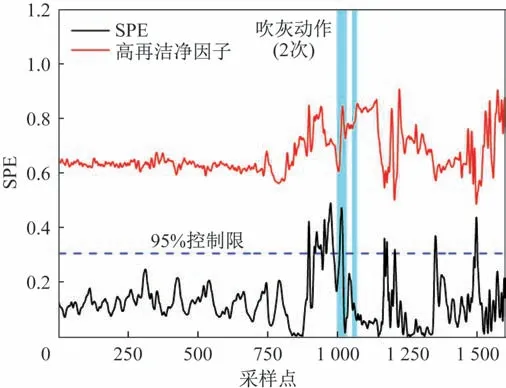
图4 高温再热器PCA法与洁净因子灰污监测对比Fig.4 Comparison of high temperature reheater PCA method and clean factor ash pollution monitoring
3 结语
本文针对燃煤机组实际运行数据所提出的数据预处理方法,能有效地剔除运行数据中的异常值,保证了后续PCA 分析时数据的有效性;采用PCA 方法,选择置信度为95%,即α= 0.05 的SPE 统计量控制限Q0.05作为受热面灰污情况的判断依据,通过对比机理建模的洁净因子,验证了基于主成分分析法的受热面灰污监测方法的准确性;由于各个电厂的和锅炉结构和运行参数测点不一,导致基于机理建模的模型出现计算困难或者不准确的问题。相较于机理建模需要全面而完整的数据,PCA 法可为燃煤电厂提供灵活且可靠的灰污监测结果。
猜你喜欢
湖南电力(2022年2期)2022-05-08
数学物理学报(2021年4期)2021-08-30
应用能源技术(2020年11期)2021-01-26
中等数学(2020年1期)2020-08-24
昆钢科技(2020年6期)2020-03-29
文化创新比较研究(2020年8期)2020-01-02
特别健康(2018年3期)2018-07-04
山东工业技术(2016年15期)2016-12-01
现代冶金(2015年4期)2015-02-06
中国特种设备安全(2014年12期)2014-09-04
