
基于改进YOLOX模型的芝麻蒴果检测方法研究
2022-02-02 08:54:12赵恒滨李国强张建涛高桐梅赵巧丽郑国清
河南农业科学 2022年11期
王 川,赵恒滨,2,李国强,张建涛,高桐梅,赵巧丽,郑国清
(1. 河南师范大学 计算机与信息工程学院,河南 新乡 453007;2. 河南省农业科学院 农业经济与信息研究所/河南省智慧农业工程技术研究中心,河南 郑州 450002;3. 农业农村部黄淮海智慧农业技术重点实验室,河南 郑州 450002;4. 河南省农业科学院 芝麻研究中心,河南 郑州 450002)
芝麻是我国重要的油料作物之一,是农业结构调整的优势作物,也是传统的出口创汇作物[1-3]。我国芝麻常年种植面积在60 万hm2左右,总产60 万~70 万t,其总产和单产均居世界首位[4-5]。精确预估籽粒产量是芝麻育种和栽培生产的重要环节。在实际应用中,田间估产主要依据单位面积株数、单株蒴果数、蒴果粒数和千粒质量。目前,单株蒴果数的获取主要依靠手工统计,费时费力。因此,快速精确识别芝麻蒴果,将有助于提高芝麻考种效率和估产精度。
近年来,国内外学者利用机器视觉和图像处理技术,开展了不同农作物果实目标检测研究。PAYNE等[6]提出基于颜色空间特征和相邻像素纹理特征的分割方法,实现芒果果实的识别和产量预估,准确率达到74%。ZHANG 等[7]提出基于多特征融合和支持向量机(SVM)的检测方法,实现对石榴果实的识别,检测准确率为78.15%。李寒等[8]提出基于RGB-D 图像和K-means 优化相结合的自组织映射神经网络,实现番茄果实的识别与定位,准确率达到87.2%。LIU 等[9]提出基于颜色与形状特征的图像分割方法,实现对苹果果实的检测,召回率为85%。上述方法利用果实的颜色、形状、纹理等不同尺度特征进行识别检测,但是在果实间粘连重叠、枝叶遮挡等情况下的检测准确率并不高。
随着计算机视觉和深度学习等人工智能技术的快速发展,深度卷积神经网络(Deep convolutional neural networks,DCNN)比传统目标检测方法更有优势。基于深度学习的目标检测分为两类:一类是以R-CNN[10]、Fast R-CNN[11]、Faster R-CNN[12]为代表的双阶段算法,另外一类是以SSD[13]、YOLO[14]、Retina Net[15]为代表的单阶段算法。张文静等[16]通过改进Faster R-CNN 网络模型实现番茄果实的识别,检测准确率为83.9%。张伏等[17]通过改进轻量型YOLOv4 神经网络,实现密集圣女果的识别定位,网络召回率达到97.10%。刘天真等[18]提出一种基于SE Net 的YOLOv3 网络模型,实现自然场景下冬枣果实的检测识别,检测准确率为82.01%。郭瑞等[19]通过融合K-means 聚类算法与优化的注意力机制模块改进YOLOv4 检测算法,对大豆单株豆荚数检测准确率为84.3%。由上可知,DCNN 用于检测圣女果、冬枣、大豆豆荚等,具有较好的精度。而针对芝麻蒴果识别的研究未见报道,且针对此类尺寸更小、重叠遮挡严重,且密集度高的情景也少见报道。为此,以芝麻蒴果为检测目标,以YOLOX 为基准网络模型,通过改进优化路径聚合网络PANet 和引入注意力机制CBAM模块,提出基于YOLOX模型的芝麻蒴果检测方法,以实现密集场景下芝麻单株蒴果的准确检测,为高通量获取芝麻表型提供理论依据。
1 材料和方法
1.1 试验数据获取
2020—2021 年于芝麻生长季,在河南省农业科学院农业科技试验基地(113°57′E,35°3′N),利用数码相机(佳能Canon Power Shot G1),从植株的正面、侧面和仰拍等角度,拍摄芝麻蒴果照片。所拍摄的图片尺寸为2 448×4 352(像素),从原始图片中筛选出300张,包含顺光、背光、遮挡、粘连等各种芝麻蒴果田间生长图像。然后将采集图像统一裁剪为512×512(像素),经过筛选和预处理后获得芝麻蒴果高清图像数据集500张。
1.2 数据增强与标注
为提高训练模型的泛化能力,利用Pytorch框架中的Opencv软件对数据集进行数据增强,对采集数据进行明暗度变化、加入高斯噪声、50%概率水平翻转以及-45°~45°方向的随机旋转。增强后得到的数据集包含4 362 张图像。利用标注工具Labelimg,按照Pascal VOC 数据集的格式要求,对数据集进行人工标注,生成.xml 类型的标注文件。将数据集按照9∶1 比例划分,其中90%部分再按照9∶1 比例分为训练集和验证集,10%部分作为测试集。最终得到训练集、验证集和测试集的样本数量分别为3 532、393、437张。
1.3 YOLOX网络模型
YOLOX 网络结构主要包括CSPDarknet-53 主干网络、路径聚合网络(Path aggregation network,PANet)和预测头(Prediction head),如图1 所示。CSPDarknet53 为模型主干特征提取部分,由Focus、CSP1 和CSP2 三种模块组成。路径聚合网络PANet为自顶向下和自底向上的双向融合骨干网络,由特征金字塔FPN[20](Feature pyramid networks)和PAN(Path aggregation network)两部分构成。FPN 将主干网络提取的特征自顶向下进行特征融合,然后由PAN 自底向上进行路径增强。预测头用于检测目标的分类和回归,不同级别的任务需要不同的预测头。在预测头部分中,3 个平行分支分别用于预测框回归、类别划分和判断是否包含物体。

图1 YOLOX网络模型结构Fig.1 Structure of YOLOX network model
1.4 CE-YOLOX网络模型
由于芝麻蒴果尺寸较小,且互相遮挡,因此,直接利用YOLOX 模型检测芝麻蒴果时,会出现一定数量的错检、漏检等问题,不能很好地拟合蒴果检测任务。据此,将以YOLOX 模型为基准,重点优化细粒度特征信息和准确空间位置信息的提取性能。将改进后的模型称为CE-YOLOX 模型,其网络结构如图2所示。
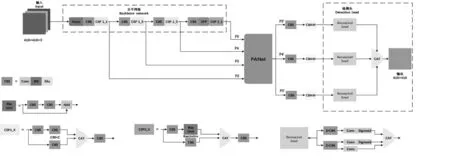
图2 CE-YOLOX网络模型结构Fig.2 Structure of CE-YOLOX network model
1.4.1 PANet模块改进 在YOLOX 模型中,经过主干网络得到13×13(特征层P5)、26×26(特征层P4)、52×52(特征层P3)3 种不同尺度的特征层。P5、P4依次经过CSP2-1、CBS 和Upsample 操作后,获得与其下一层相同尺寸和通道数的特征图,然后通过级联向下传递。PAN 模块将FPN 融合后得到的特征图依次经过CSP2-1 和CBS 模块降维,再与其上层特征图级联,最后输出P5′、P4′、P3′3 种特征层。改进前的PANet模块见图3a。
主干网络中的大尺度特征层具有丰富的细粒度特征信息,更加有利于小尺寸目标的检测[21]。通过引入大尺度特征层,融合深层特征的语义信息和浅层特征的细粒度信息,充分保留小目标细节特征,可有效提高芝麻蒴果的检测精度。据此,经主干网CSPDarknet的CSP1-1模块,获取104×104大尺度特征层,加入PANet中。改进后的PANet模块(图3b)保留了原模块中的P5、P4、P3 特征层,新增大尺度104×104(特征层P2)。特征层P3 经过CSP2-1、CBS 和Upsample 操作后,与特征层P2 融合,获得具有丰富语义信息和大量细节信息的特征图。然后又经过CBAM、CSP2-1 和CBS 模块进行特征强化和降维,随后与P3 级联并向上传递。为避免网络冗余,经过PAN 模块后,输出特征层P5′、P4′、P3′,不再输出104×104特征层。

图3 改进的PANet结构图Fig.3 Structure diagram of improved PANet
1.4.2 引入CBAM 注意力机制 CBAM 注意力机制是一种结合空间和通道的卷积注意力机制模块[22]。由通道注意力CAM 模块和空间注意力SAM 模块组成。通道注意力模块用于提取检测目标的重要轮廓特征,获取检测目标的主要内容。而空间注意力模块用于获取检测目标的空间位置信息,来实现对检测目标的精准定位。为了提高芝麻蒴果的检测效果,在CBS 模块后加入CBAM 模块(图2)。CBAM模块将对3种不同尺度输入特征图进行自适应特征细化,从而提高模型检测准确率。
1.4.3 引入Soft-NMS 算法 由于芝麻蒴果具有较高重叠度,采用传统NMS 非极大值抑制算法,将直接删除重合面积过大的先验框,造成部分有效先验框的损失,影响部分蒴果的检测效果。而Soft-NMS在进行非极大值抑制时,将同时考虑置信度和边框之间的重合程度[23],采用加权方式降低重叠度大于一定阈值的先验框置信度,并实时更新阈值,有效避免剔除正确先验框。因此,在CE-YOLOX 模型后处理阶段,本研究将NMS非极大值抑制算法替换为Soft-NMS非极大值抑制算法。
1.5 试验平台与评价指标
1.5.1 试验环境与参数设置 采用的硬件设备配置:Core i7-10700kf 3.9GHz 处理器,16 GB 运行内存,英伟达RTX 3080 10 GB 显卡。软件试验环境:Win10 操作系统,环境配置为pytorch 1.8.1、CUDA 11.1、cudnn 11.2 和Python 3.8。在CE-YOLOX 模型训练时,输入图片尺寸为416×416(像素),优化器采用Adam[24],初始学习率为0.001,动量因子为0.92,单次送入网络的样本数为4,设置总迭代次数为200次,每训练5次保存模型,最终选择在验证集上损失最小的模型为本研究试验模型[25]。
1.5.2 模型评价指标 为客观衡量网络模型对芝麻蒴果的检测效果,采用准确率(Precision,P)、召回率(Recall,R)、平均精度(Mean average precision,mAP)、调和均值F1(F1score)和误检率作为评价指标。计算公式分别为:
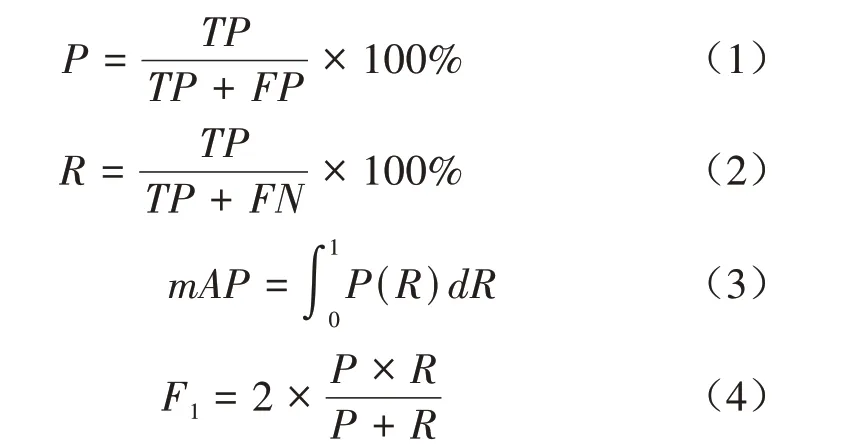
式中:TP为目标被正确识别的数量;FP为未识别或错误识别的正样本数量;FN为目标被错误划分到负样本的数量;P(R)为以召回率R为参数的函数。
2 结果与分析
2.1 CE-YOLOX模型训练结果分析
将改进后的CE-YOLOX 网络模型在芝麻蒴果数据集上进行训练,模型的损失值变化曲线如图4a所示。在前50次迭代,训练集和验证集损失值虽有不同程度振荡现象,但总体都呈现快速下降趋势,此时模型处于快速学习状态;在第50 次迭代之后,验证集和训练集损失值变化趋于平稳,模型达到收敛状态。
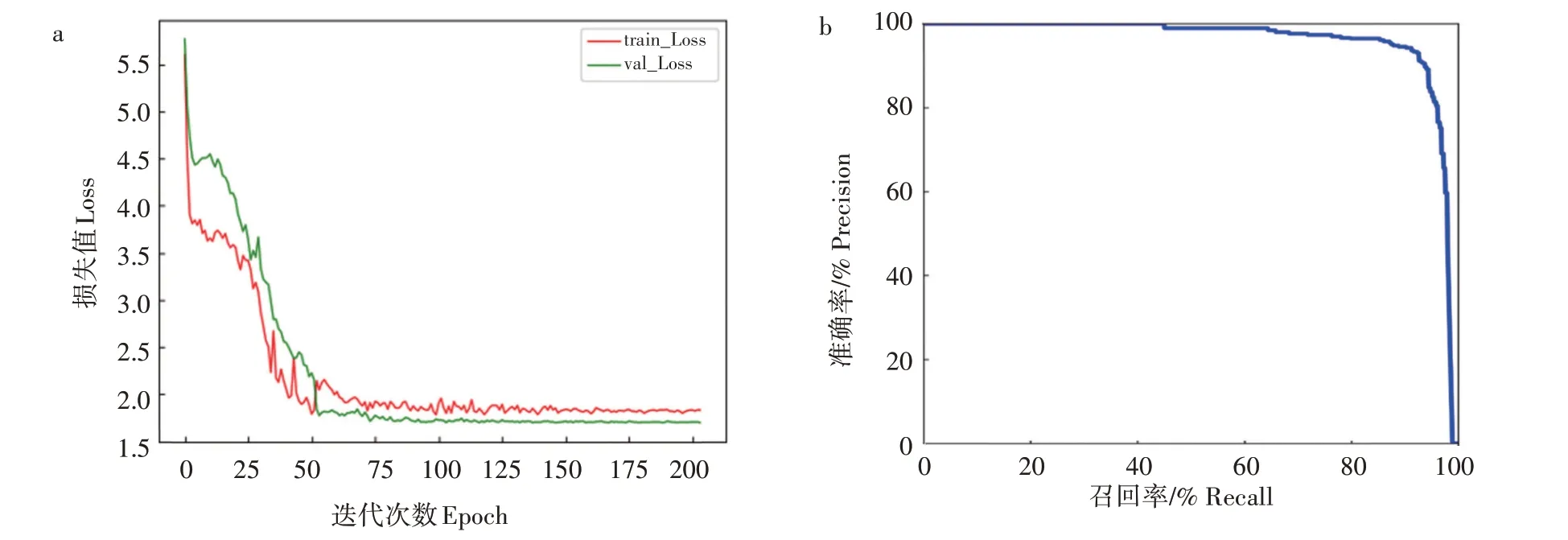
图4 损失值变化曲线(a)与PR曲线(b)Fig.4 Curves of loss value(a)and PR(b)
CE-YOLOX 模型的PR 曲线如图4b 所示,横轴为模型召回率,纵轴为准确率,曲线与坐标轴所围的面积为平均精度,PR 曲线在平衡点(准确率=召回率)时接近于坐标点(1,1),CE-YOLOX 模型的平均精度为99.71%。
2.2 不同改进方法的检测结果对比
为验证所采用不同改进方法的有效性,设计了消融试验进行对比。方法1 为YOLOX 模型,方法2为加入CBAM 注意力机制后的模型,方法3 为将104×104 特征层引入PANet 模块后得到的模型,方法4 为本研究模型。采用相同训练数据集和参数,分别训练4种模型,结果如表1所示。
由表1 可知,方法2 相较于YOLOX 模型平均精度提高1.25 个百分点,F1值提高0.01,权重增加0.94 MB,参数量增加0.37%。这说明引入CBAM 注意力机制能够抑制无用特征,保留更有效的轮廓特征和空间位置信息。方法3 相较于YOLOX 模型平均精度提高1.59 个百分点,F1值提高0.01,权重增加1.35 MB,参数量增加0.74%,这说明引入104×104 大尺度特征层,能更好地提取出蒴果目标的细粒度特征信息,有效提升模型对小目标的检测性能。方法4相较于YOLOX模型平均精度提高3.28个百分点,F1值提高0.05,权重增加2.29 MB,参数量增加1.11%,检测时间增加0.002 s。虽然模型4的参数量和检测时间略有增加,但平均精度明显提高。可知,将2种改进方法同时融合到YOLOX 模型中,能提升对芝麻蒴果识别与定位的精确性,由此也验证了CEYOLOX模型改进方法的有效性。

表1 不同改进方法检测结果Tab.1 Detection results of different improved structures
2.3 不同检测模型的检测结果对比
为进一步对比不同检测模型对芝麻蒴果的识别性能,在相同试验平台上用相同数据集分别在Faster R-CNN、YOLOv3[26]、YOLOv4[27]和YOLOX[28]4 种模型上进行同批次的训练。检测结果如表2 所示。由表2 可知,在5 种检测模型中,YOLOv3 和Faster R-CNN 模型的平均精度低于其他3 种模型,说明YOLOv3 对密集、小尺寸蒴果检测效果较差,Faster R-CNN 模型检测精度虽接近于YOLOv4 和YOLOX模型,但其召回率和检测速度低于这2 种模型。相比而言,CE-YOLOX 模型检测效果最好,其中,平均精度比YOLOv3、Faster R-CNN、YOLOv4、YOLOX 模型分别提高7.94、5.31、4.61、3.28 个百分点;召回率分别提高14.20、15.46、9.00、6.27 个百分点;F1值分别提高0.11、0.12、0.08、0.05。从检测时间来看,CE-YOLOX 模型的检测时间虽高于YOLOX 和YOLOv3,但与Faster R-CNN 和YOLOv4相比具有良好的检测速度,以牺牲少量计算成本为代价,获得更高检测精度,因此,改进后模型更适用于密集、小尺寸芝麻蒴果的检测。
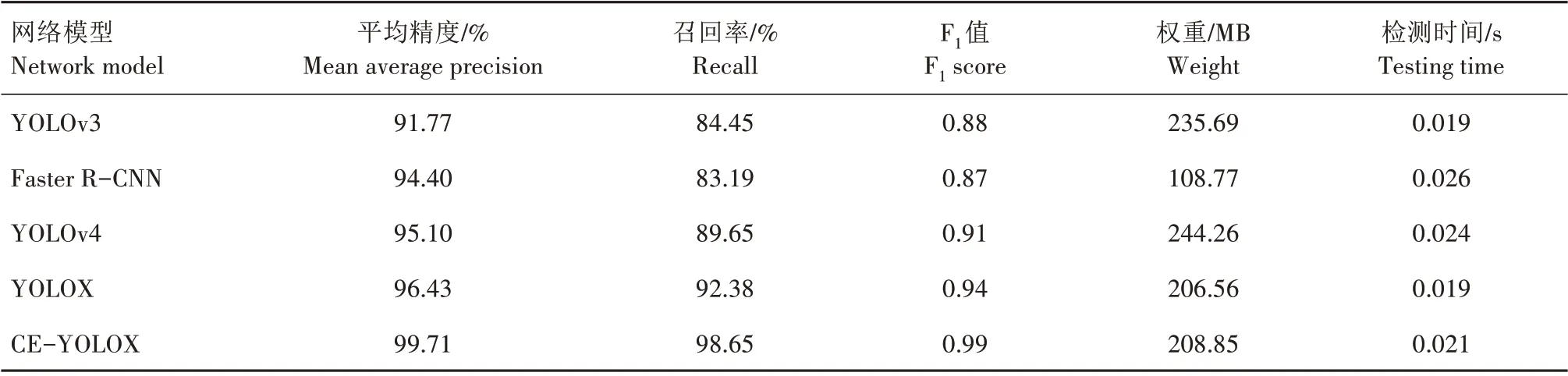
表2 不同网络模型检测结果Tab.2 Detection results of different network models
图5 对比了5 种不同模型对芝麻蒴果的识别结果,图5a 和b 中共含有73 个蒴果目标。YOLOv3 模型正确检出45 个蒴果,漏检25 个,误检3 个。Faster R-CNN 模型正确检出48 个蒴果,漏检23 个,误检2个。YOLOv4 模型正确检出57 个蒴果,漏检15 个,误检1 个。YOLOX 模型正确检出65 个蒴果,漏检8个。CE-YOLOX 模型正确检出72 个蒴果,误检1个。可知,YOLOv3、Faster R-CNN 和YOLOv4 3种模型均出现不同程度的漏检和误检,对于遮挡严重的蒴果检测时漏检较多;YOLOX模型并没有出现误检情况,但对较小尺寸蒴果也存在漏检情况;CE-YOLOX 模型也存在误检,但正确检出率高于上述4种模型。

图5 5种不同网络模型效果对比Fig.5 Comparison of the effects of five different network models
2.4 不同检测模型的蒴果计数对比
为进一步对比不同模型对芝麻蒴果的检测效果,随机选取100张测试集图片进行计数统计,人工统计共有总蒴果数2 879个。如表3所示,通过与其他4 种检测模型对比,可以看出,CE-YOLOX 模型检测计数准确率最高,正确检测出蒴果数2 788 个,漏检48 个,误检43 个,准确率为96.84%,误检率为1.49%。相比其他4种检测模型误差最低,具有较强检测性能,更适用于实际情况下的芝麻蒴果检测任务。
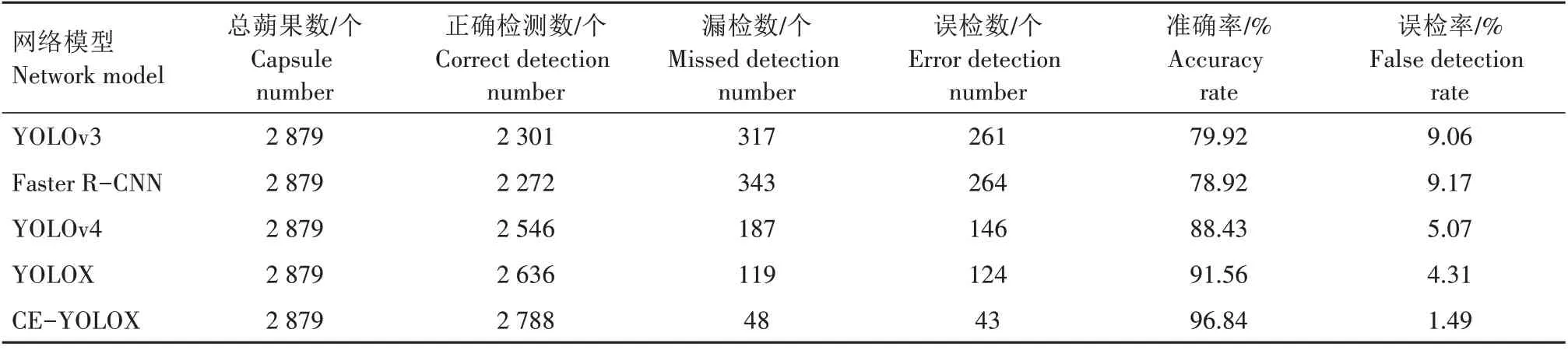
表3 不同网络模型计数结果Tab.3 Counting results of different network models
3 结论
针对芝麻蒴果尺寸小且存在互相遮挡情况,本研究提出了一种密集场景下芝麻蒴果检测模型CE-YOLOX。在YOLOX 模型基础上,首先优化PANet 网络,增加104×104 大尺度特征层,以提高小目标蒴果特征信息的提取效率;然后通过加入CBAM 模块,抑制无用特征信息,获取检测目标重要的轮廓特征和空间位置信息;最后,在后处理阶段,将NMS 非极大值抑制算法替换为Soft-NMS 非极大值抑制算法,以降低检测目标的漏检率。CEYOLOX 模型对芝麻蒴果检测的平均精度为99.71%,与原模型相比提高了3.28 个百分点,模型对单幅蒴果图片测试时间为0.021 s。在相同测试集上进行计数试验,CE-YOLOX 模型的计数准确率为96.84%。表明,对高度重叠、粘连遮挡的芝麻蒴果,CE-YOLOX 模型拥有高识别率、强鲁棒性和良好的泛化性能。
猜你喜欢
甘肃农业大学学报(2021年4期)2021-09-22 06:58:50
中老年保健(2021年3期)2021-08-22 06:51:16
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
扬子江诗刊(2018年2期)2018-11-13 13:08:03
动漫星空(2018年4期)2018-10-26 02:12:14
动漫星空(2018年2期)2018-10-26 02:11:02
动漫星空(2018年5期)2018-10-26 01:15:04
中国交通信息化(2018年5期)2018-08-21 03:37:40
