
基于改进EfficientDet 网络的疲劳驾驶状态检测方法
2022-02-01 12:36张光德
汽车安全与节能学报 2022年4期
宋 巍,张光德
(武汉科技大学 汽车与交通工程学院,武汉 430081,中国)
随着汽车保有量和驾驶人数的增长[1-2],交通安全问题也日趋严峻。汽车安全事故的发生与驾驶员的状态密切相关,其中疲劳驾驶最为普遍。当驾驶员感到疲倦时,驾驶员行为处置不当和反应力减弱,进而对人生安全和社会财产造成极大危害[3-5]。因此,驾驶员疲劳状况的实时监测是预防交通安全事故发生的重要手段,值得深入研究。其中,机器视觉与人工智能技术在人类状态与行为识别领域应用广泛,且效果显著。
随着成像技术与图形处理器(graphics processing unit,GPU)等软硬件的快速迭代,基于深度学习的图像识别技术应运而生,其以卷积神经网络(convolutional neural networks,CNNs)为特征提取器,克服了传统机器学习应用中的种种瓶颈,在驾驶员状态检测方面的研究日益增多。王政等[6]针对传统的、基于单一特征的疲劳检测方法误检率高、可靠性不强、无法适应复杂多变的行车环境等问题,提出了一种基于深度学习的驾驶员多种面部特征融合的疲劳驾驶检测方法,取得了相对优异的检测效果。李昭慧等[7]提出一种基于改进YOLOv4 算法的疲劳驾驶检测方法,测试中平均精度均值(mean average precision,MAP)达到97.29%,相较原YOLOv4 算法提高了1.98%,其中对眼睛部位的检测精度提高了6%。此外,仍有部分学者基于深度学习技术对驾驶员疲劳检测的应用效果进行测试,将不同特征提取网络、不同模型搭建方式的深度学习目标检测网络应用于实际的检测过程之中,取得了相对优异的检测结果[8-15]。
然而,大量特征点的定位与识别造成了计算数据量和难度大大提升,降低了实时检测效率。本文通过构建多类别疲劳驾驶状态图像数据库,以瞌睡度量方法判定驾驶员的疲劳驾驶状态,以EfficientDet[16-17]目标检测网络提取驾驶员面部图像特征,以k-means先验框边界聚类方法确定目标检测区域,并利用双向特征金字塔网络检测驾驶员状态,避免繁杂面部特征点的细致识别,实现驾驶员疲劳状态精确、高效检测。
1 疲劳驾驶状态检测网络
1.1 EfficientNet 特征提取网络
1.1.1 EfficientNet 架构
在基础CNNs 网络模型(如图1a 所示)的基础上提升层宽(如图1b 所示),即增加网络特征图个数可以使网络获得更高细粒度的特征,且降低模型训练难度。其次,增加网络层数(如图1c 所示),即搭建更深层次的网络使CNNs 模型有能力提取到更加丰富、复杂的特征,且提取到的特征能被有效应用于具体图像分类任务之中。此外,提高输入图像的分辨率(如图1d 所示)能够潜在的获得更高细粒度的特征模板,即在输入端提高CNNs 模型的分类性能。因此,若同时优化基础CNNs 宽度、深度及输入分辨率(如图1e 所示)则能最大程度上提升卷积神经网络的特征提取能力,进而优化模型的图像分类效果。
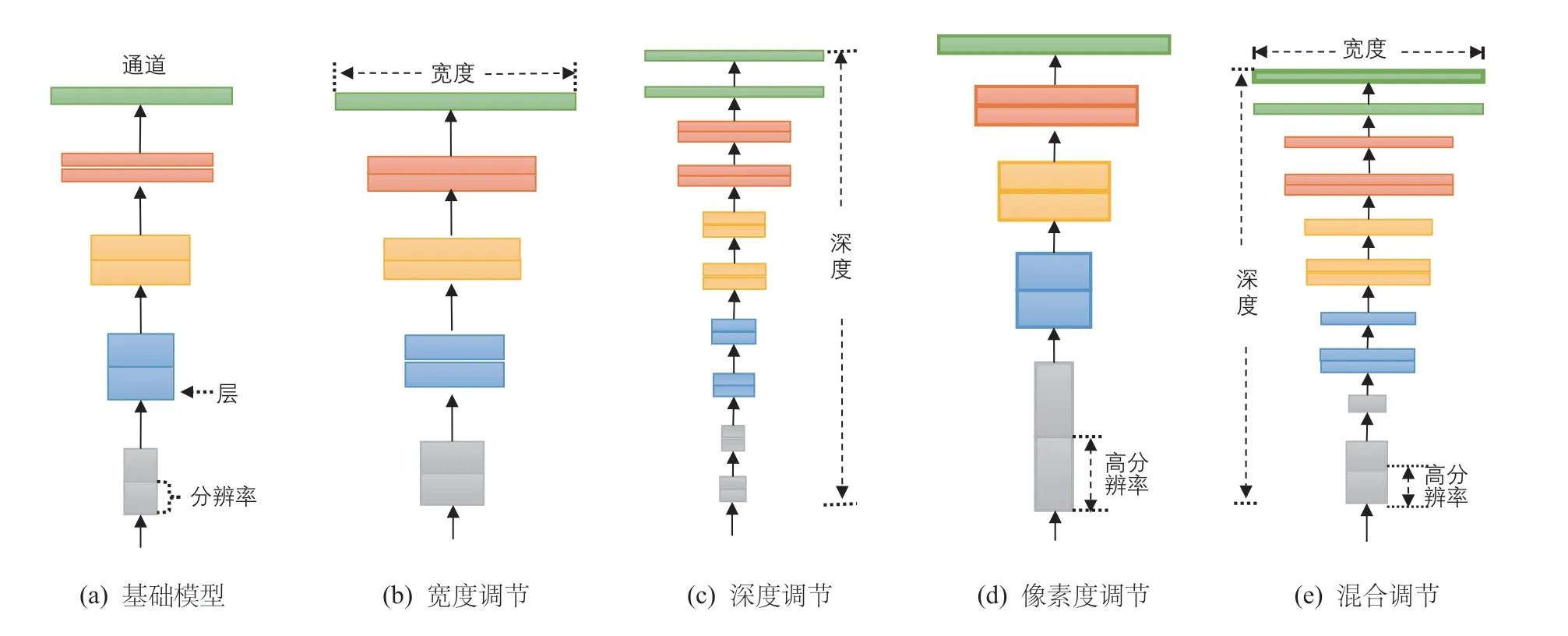
图1 EfficietNet 设计思路
1.1.2 视觉注意力机制
将视觉注意力机制融入于CNNs 模型中,是一种高效的特征提取方法[18]。在EfficientNet 中,采用“视觉注意力模块(或压缩和激励模块) (squeeze &excitation block,SE block)”来实现注意力增强。SE 模块的结构如图2 所示。

图2 SE 视觉注意力模块
SE 视觉注意力模块是一种基于注意力的特征图运算。首先对输入特征图进行Squeeze 操作,并在通道维度方向上进行全局平均池化(global average pooling)运算,以获得输入特征图在通道维度方向上的全局特征。其次,SE 模块对全局特征图进行Excitation 操作,以学习图像中各个通道之间的关系。最终,SE 模块通过sigmoid 激活函数获得不同通道所占的权重,并将各通道权重与输入特征图相乘以获得最终注意力增强后的特征图像。
1.2 改进EfficientDet 目标检测网络
EfficientDet 主要由EfficientNet 特征提取网络与双向特征金字塔网络(bidirectional feature pyramid network,BiFPN)所组成[19]。
1.2.1 双向特征金字塔网络(BiFPN)
特征金字塔网络(feature pyramid network,FPN)将CNNs 特征提取网络中较为抽象的顶层特征图像进行上采样运算,并将上采样运算结果通过横向连接与特征提取网络中其他层级所提取的相同特征大小的特征图像进行融合,在不显著增加模型计算量的前提条件下显著提升了深度学习目标检测网络对不同尺度目标的检测性能。启发于基础FPN,研究人员对特征提取网络中不同层级所提取的特征图像进行融合实验,而路径聚合网络(path aggregation network,PANet)[20]则是其中一项特征融合效果较优的变体网络。PANet 在PFN 的基础上提出为特征融合网络提供自下而上特征融合路径的方法,进而提升了目标检测模型对多尺度目标的整体检测性能,但PANet 的参数量与计算消耗也较大。
为进一步提升PANet 的深度学习目标检测技术在多尺度目标检测任务中的性能,并降低特征融合网络的计算消耗,EffiicentDet 将跨尺度连接和加权特征融合应用于网络搭建之中,进而提出全新的特征融合网络BiFPN,如图3 所示。
以图3中P6融合特征输出为例,其运算过程如式(1)和式(2)所示。
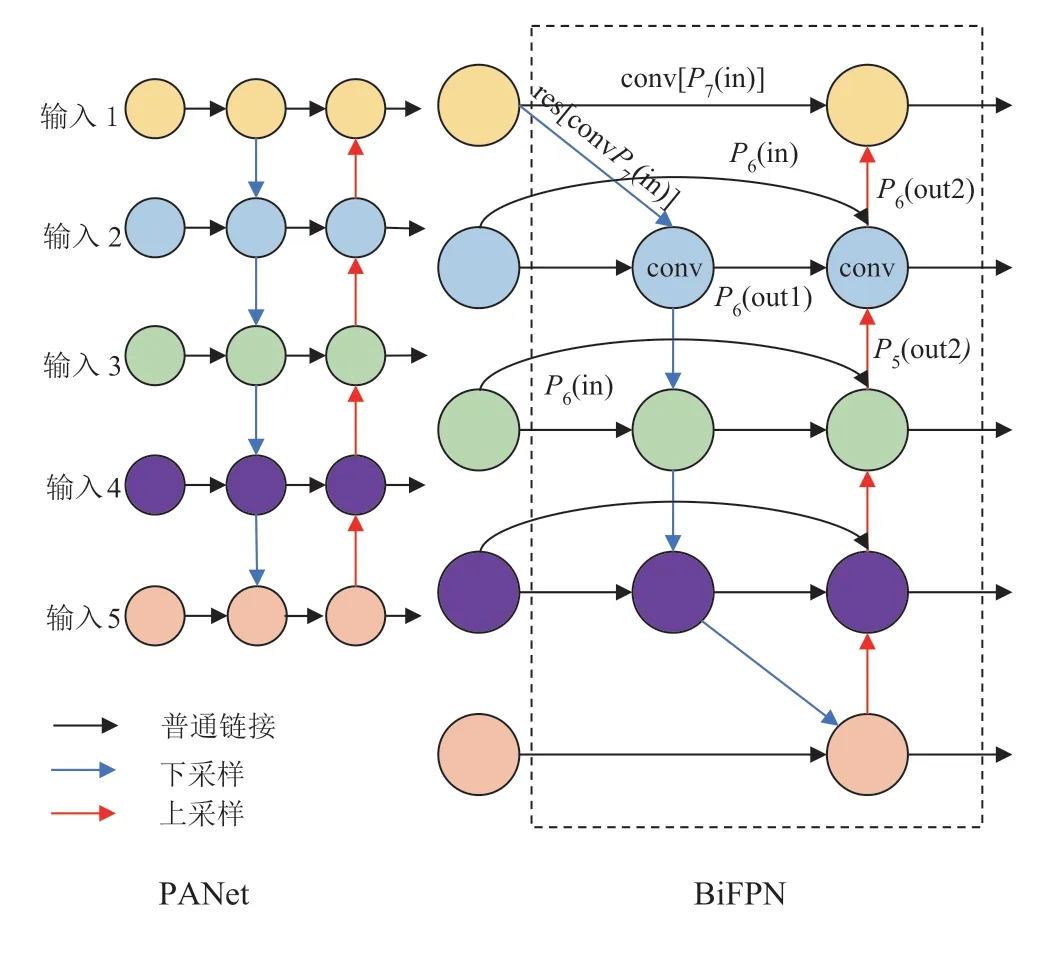
图3 特征金字塔网络结构

式中:代表经过加权运算后的代表经过加权最终输出;代表对应特征层所被赋予的权重;ε为预设参数,用于防止分母为0,本文预设ε=1×10-4。
1.2.2 EfficientDet 架构
EfficientDet 是一类基于EfficientNet 特征提取网络而提出的深度学习目标检测架构,其主要由图像输入端、特征提取网络、BiFPN 特征融合网络、类别预测网络与位置预测网络五个模块所构成,模型架构如图4所示。
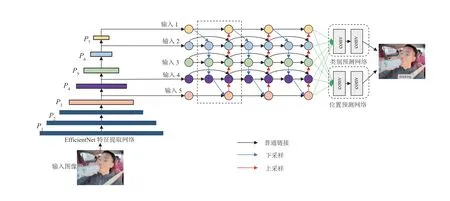
图4 EfficientDet 目标检测网络架构
在EfficientNet 特征提取网络中,模型通过初始阶段高效的下采样与通道维度扩张后获得P1、P2、P3、P4、P5等5 层的特征图像,且P5特征图像经过后续2 次下采样获得P6、P72 层的特征图像,其中P3、P4、P5、P6、P7被应用于BiFPN 的后续特征加权融合,而由于P1、P2特征图像所包含的语义信息较弱,未进行后续特征融合。其次,为精确定位输入图像中目标所在位置,EfficientDet 将BiFPN 所输出的具有语义和空间信息的特征图像划分为N×N个不同网格,以每个网格为锚点生成先验框,以用于目标定位。最终,类别预测网络与位置预测网络将分别对先验框内所包含目标的类别进行判断和先验框位置回归,进而确定输入图像中所包含的目标类别与目标位置,完成目标检测任务。
1.3 先验框边界聚类
在EfficientDet 目标检测网络中,先验框的高宽比(aspect ratios)由实验者手动设计,更加贴合具体检测任务实践的预设高宽比将有效提高模型的收敛速度与目标检测准确度。因此,为提高疲劳驾驶状态目标检测网络的模型收敛速度与检测准确性,本文提出采用k-means 聚类方法来确定预设先验框高宽比的优化方案。其中,k-means 主要通过以下步骤完成先验框高宽比聚类任务:
步骤1随机选取疲劳驾驶样本图像中的k个真实框作为初始化簇心,即anchor box。
步骤2顺序计算疲劳驾驶样本图像样本中每个真实框与k个anchor box 之间的距离,并将距离簇心最近的真实框样本划分为该类,其距离为
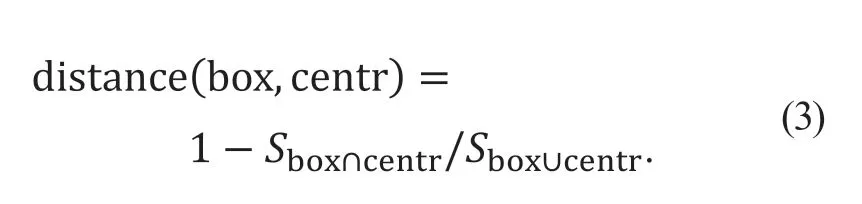
式中:box 为边界框位置;centr 为簇心点位置;Sbox∩centr为聚类中心与真实框相交区域面积;Sbox∪centr为聚类中心与真实框并集区域面积。
步骤3计算簇心除所有真实框的参数均值、更新簇心位置,并不断重复步骤2、步骤3 过程,直至簇心点确定。
因此,通过k-means 预设先验框高宽比聚类过程,其最终的高宽比能够有效反映图像数据集中的目标形状特征及大小,进而确定更为合理的预设先验框高宽比值,以优化目标检测网络的训练过程与检测效果。
2 实验验证
2.1 数据预处理与数据集制备
面向于驾驶员疲劳驾驶检测的实际任务,本实验选取正常驾驶状态及3 种疲劳驾驶状态下的图像为研究对象,其中,3 种疲劳驾驶状态图像包括闭眼样本、张嘴样本和低头样本。本数据由专业图像数据公司所采集,其摄像机部署位置在机动车左侧A 柱上方,该拍摄位置能够清晰、直观的获取驾驶员在驾车行驶过程中的行为,并对驾驶过程中疲劳驾驶状态下的图像进行采集,且选取各类别中2 张图像为示例,摄像机部署位置及图像拍摄效果如图5 所示。

图5 摄像机部署位置及疲劳驾驶图像数据集示例
在实验数据集准备阶段,采用8 : 1 : 1 划分疲劳驾驶图像训练集、测试集与验证集。同时,为避免模型训练过程中可能出现的训练数据量不足及组间数据量不平衡等问题,采用色彩变换、旋转等图像数据增强技术扩充数据集大小,经数据增强后的图像数据集中各类别的数据量如表1 所示。

表1 驾驶员疲劳驾驶图像数据集划分
2.2 实验条件与评价指标
采用平均精度均值(mean average precision,MAP),检测频率(每秒帧数,frame per second,FPS),召回率(Recall)和训练时间(Time,或t)等常用指标来评价EfficientDet 目标检测性能。其中,Recall 表征查全率,Time 表征训练难度。在MAP 值的计算过程中需要使用P(Precision)和R(Recall) 2 个指标:

式中:tp (true positive)为模型检测正确的驾驶行为数量;fp (false positive)为模型检测错误的驾驶行为数量;fn (false negative)为模型漏检的驾驶行为数量。
模型的平均检测精度(average detection precision,AP)代表了以P为横轴、以R为纵轴的P-R曲线下的面积,即

平均精度均值为
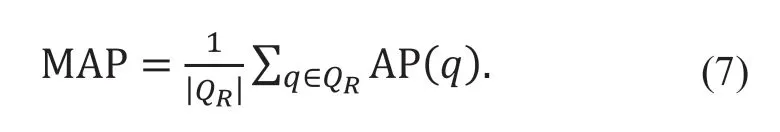
式中:QR为测试集中所包含图像个数。
实验过程中,通过Win10 系统Python 环境搭建疲劳驾驶图像检测模型,其训练环境条件如表2 所示。
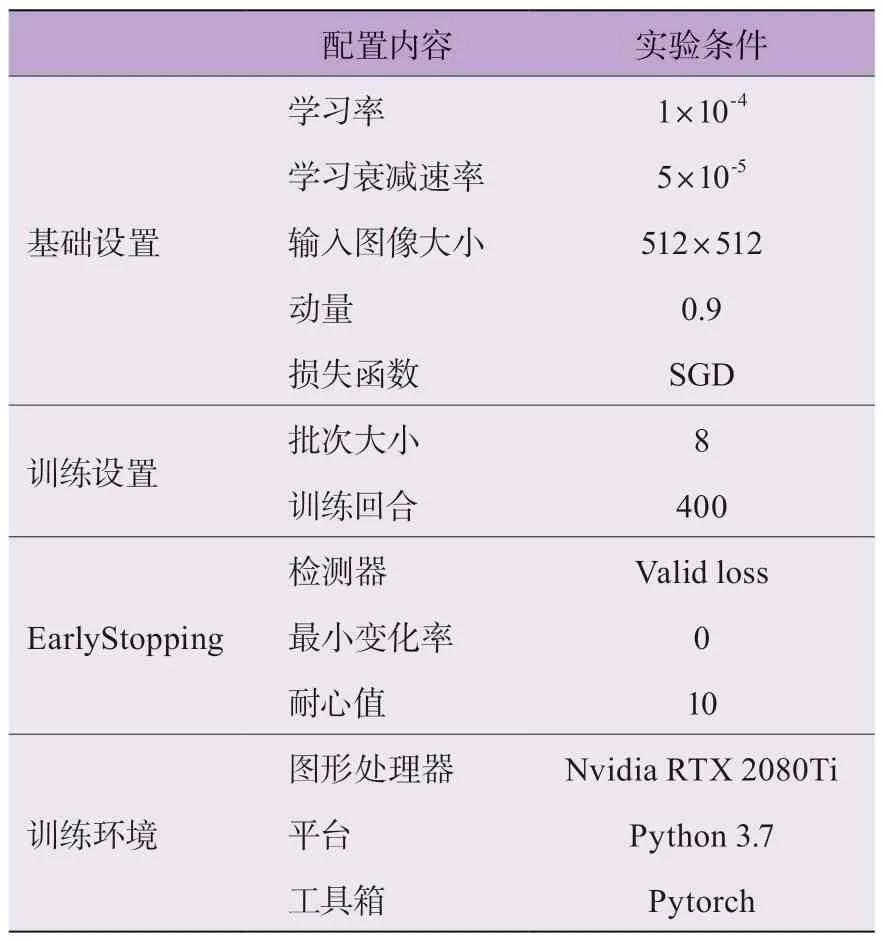
表2 实验模型训练环境条件
另外,采用Carnegie Mellon 研究所实验验证[21]的、用来判定驾驶员疲劳状态的瞌睡程度指数为

计算结果的疲劳驾驶评价标准如表3 所示。其中,疲劳状态帧数包括 闭眼、张嘴、低头 3 种表现形式的帧数;依照Perclos[21]的计算结果,可以划分为正常驾驶状态、轻微疲劳驾驶、严重疲劳驾驶 3 种驾驶状态。同时,在驾驶员疲劳驾驶状态的检测任务中,考虑实时性,检测时间总帧数设置为0.8 s,以此来判别驾驶员当前时段的驾驶状态。
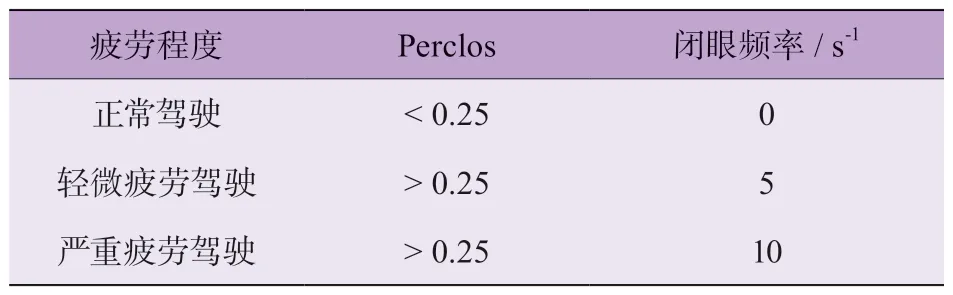
表3 疲劳驾驶评价标注
2.3 实验结果与分析
在本实验中,未使用k-means 先验框边界聚类算法时,使用平均精度均值MAP、召回率R、检测频率FPS、训练时间t等4 个评价指标来评估各阶段EfficientDet 疲劳驾驶目标检测模型。结果如表4 所示。
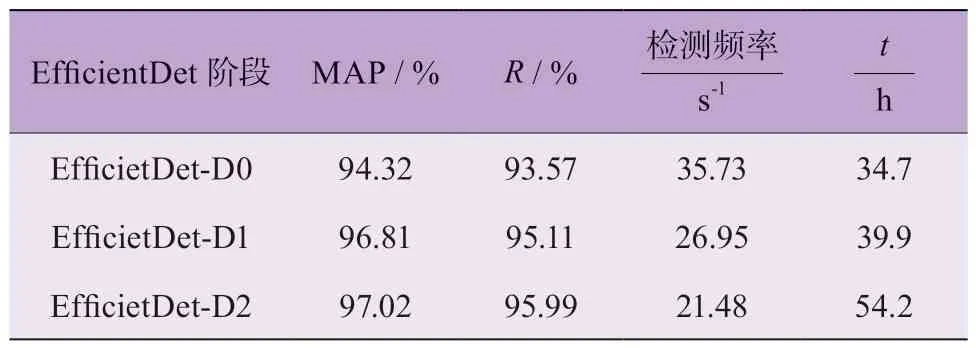
表4 未使用k-means 先验框边界聚类算法时各阶段EfficientDet 的检测性能
EfficientDet-D2 模型的平均检测精度相对更高;EfficientDet-D1 次之;EfficientDet-D0 平均 检测精度MAP 相对较低;其他3 个指数也展现出了类似的变化趋势,R指数、训练时长t随着特征提取网络的优化而逐渐增大,检测频率随着特征提取网络的优化而逐渐减小,主要原因在于不同模型的图像特征提取能力不同,影响了模型检测精度和效率。
使用k-means 先验框边界聚类方法实现先验框大小比例的预先决策。同时,在疲劳驾驶图像先验框边界聚类实验时,不改变特征层预设先验框尺度大小及个数的前提下,聚类类别k选定为3,即聚类出3 种符合驾驶员疲劳驾驶图像检测先验框分布的长宽比。之后,将各尺度大小的先验框各自分配聚类后,3 组长宽比能够在特征层上生成9 种先验框,且经过20 次聚类实验,所得聚类精确度最高的3 组先验框长宽比比例分别为(55,63)、(59,53)、(56,57)。
以上述3 组先验框长宽比例为先验框预设值,3 种EfficientDet 目标检测网络的评价指标,以及以相同数据集训练并测试的YOLO V3、Faster-RCNN 模型的实际检测效果,如表5 所示。
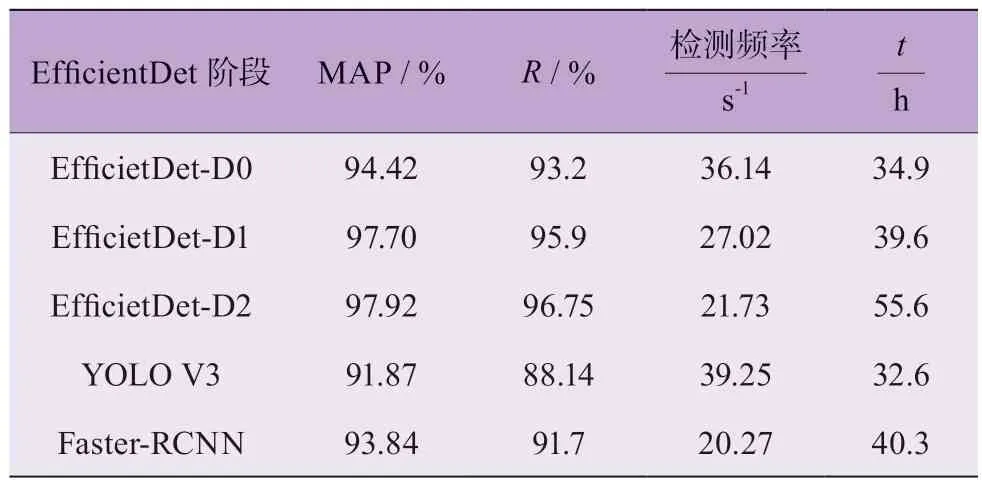
表5 使用k-means 先验框边界聚类算法时各模型的检测性能
对比于未使用k-means 先验框边界聚类算法时的检测性能,其检测精度均有一定幅度的提升,这表明k-means 先验框边界聚类算法的使用能在一定程度上优化目标检测网络的检测性能。YOLO V3、Faster-RCNN 模型的检测精度相比于EfficientDet 模型稍差,但YOLO V3 框架的检测频率较高,训练耗时较短,而Faster-RCNN 框架并没有明显优势。总体来说,本文所提EfficientDet-D2 模型检测精度最高,检测速度适中,综合检测效果较好。
选取除采样人员外的2 名测试人员进行驾驶测试,并录制对应视频。实验模拟真实驾驶环境,由实验人员侧前方摄像头实时采集面部信息,分别模拟出3 种疲劳驾驶状态。每位实验人员分别进行100 次模拟实验,共进行200 次模拟实验。其测试结果如表6所示。

表6 使用先验框边界聚类算法的视频检测效果
使用先验框边界聚类算法的EfficietDet-D2 在2 名实验人员拍摄视频中的检测过程如图6 所示。整体趋势上,使用先验框边界聚类算法的EfficietDet-D2 误检率及漏检率相对较低,且分类准确率相对较高。其次,正常驾驶状态下的检测精度较高,而在驾驶员轻微疲劳驾驶状态下的检测精度相对要低,这表明轻微疲劳驾驶状态仍是当下基于深度学习的疲劳驾驶检测算法的应用难点。此外,EfficietDet-D2 模型检测速度分别达到21.05 和20.98,即检测速度相对较快,且面对不同驾驶员时的检测速度相对接近。

图6 EfficientDet-D2 在2 名实验人员拍摄视频中的检测过程
3 结论
本文提出了一种基于改进EfficientDet 深度学习网络的疲劳驾驶视觉检测方法。通过深度可分离卷积与移动反转瓶颈卷积模块降低了特征提取网络部分的计算复杂度,提升了图像特征的提取效率;应用视觉注意力机制并构建挤压与激励模块,进一步加强整个检测网络的特征提取能力,并融合检测模型中低层位置信息与高层语音信息,增加了网络整体的信息流动性;同时,采用k-means 聚类算法对数据集中的真实框进行统计,设定更加符合具体任务需求的先验框,优化了网络特征提取方向,降低了模型对冗余信息的关注度。对比分析3 种不同深度、不同宽度、不同分辨率大小的改进EfficientDet 模型以及YOLO V3、Faster-RCNN模型检测效果。
结果表明:使用k-means 先验框边界聚类算法时的EfficientDet 模型检测精度和帧率均有一定幅度提升,其中EfficientDet-D2 模型检测效果较好,其平均精度和召回率分别达到97.92%和96.75%,误检率和漏检率分别低于2.39%和1.78%。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
中国卫生统计(2022年2期)2022-05-28
汽车实用技术(2022年7期)2022-04-20
汽车实用技术(2022年4期)2022-03-07
陕西理工大学学报(自然科学版)(2021年3期)2021-06-23
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
自动化学报(2017年5期)2017-05-14
自动化学报(2017年11期)2017-04-04
探测与控制学报(2015年4期)2015-12-15
