
大数据情境下基于切片逆回归的抽样方法研究
2022-01-28 09:26:18贺建风
广西师范大学学报(自然科学版) 2022年1期
贺建风, 石 立
(1.华南理工大学经济与金融学院, 广东广州510006; 2.广州华商学院经济贸易学院, 广东广州511300)
随着计算机技术的发展和广泛应用,大数据情境已成为当前社会、经济、科技等领域储存各类数据的常态,但目前针对大数据进行直接计算与分析,还存在数据量庞大、运算效率不高等问题,而对大数据进行抽样运算则是解决这些问题的一个可行的重要途径。
大数据情境下,是否需要抽样调查以及如何开展抽样推断是近些年众多学者研究的热点问题。就具体抽样方法改进而言,代表性的有:Rivers[1]认为大数据中可以根据样本的关联性构建辅助信息进行辅助抽样,提出了样本匹配法选取样本;Orr等[2]进一步提出结合社交网络来选取大数据的样本;Kogan等[3]结合滚雪球抽样的思想,提出链接跟踪的方式选取样本。这些抽样方法能得到一些稳定的样本,提升抽样估计效果,但从个体的关联性选取样本,选取的样本可能只能反映总体中某类群体的情况,得到的常是总体中该群体的估计结果,与总体可能存在较大偏差。为了抽到总体的各不同子群体,贺建风等[4]提出了基于社交网络的聚类随机游走抽样算法,利用社交网络抽取同类关联个体,运用聚类随机游走抽取不同群体,可以得到与总体结构近似的样本。传统抽样方案中,为了推断的准确性,需要构造有代表性的抽样框,从中抽取一个与总体结构类似的样本,以实现根据一套样本就可以推断总体各种不同特征的目标。但在大数据情境下,抽样的核心已演变为从大量数据中筛选出代表性样本,故可以根据不同研究目的抽取不同样本,若某次抽样的目的是研究某个因变量Y,则如何抽取到对Y有代表性的样本则是大数据抽样需要解决的重要问题,Li[5]提出的切片逆回归法(sliced inverse regression, SIR)是能辅助解决这一问题的重要方法。
1 切片逆回归法
切片逆回归法先将数据按照因变量的取值排序并分组(也称为切片),找出与因变量值对应的自变量值,再用主成分法将自变量综合起来得到新的变量,从而使得新构成的自变量与因变量之间有对应关系(逆回归过程,即根据因变量构造新自变量),从而达到自变量中融入因变量信息的目的。
设因变量Y受自变量X1,X2,…,Xk影响,模型如式(1)所示,
Y=β0+β1X1+β2X2+…+βkXk+ε,
(1)
式中ε为经典误差项,即因变量Y由X1,X2,…,Xk解释,且β1X1,β2X2,…,βkXk包含有Y可以被解释的全部信息,故可以在给定Y的取值下,将对应的X1,X2,…,Xk进行主成分综合,使得综合后的新变量值包含有Y的信息[5]。
切片逆回归的具体步骤为:
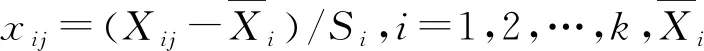

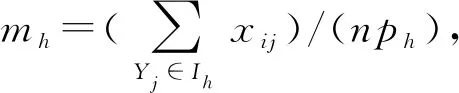
④构造切片内自变量的协方差矩阵V,见式(2)所示[5],并计算V的特征值与特征向量。
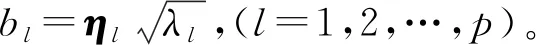
(2)
一些学者对切片逆回归法进行了改进,如Wang等[6]提出了基于等高线映射的切片逆回归法(CPSIR),Zhu等[7]提出累积切片逆回归法(CUMR),Dong等[8]为解决极端值的影响,提出了切片逆中位数回归(SIMR),这些改进使得切片逆回归法对某些数据的估计更加稳健。
切片逆回归法及其改进方法均主要解决了在自变量中融入因变量信息及实现自变量降维的问题,但并不能直接用于抽样,将其用于大数据抽样,仍需要解决两个关键问题。
问题1切片逆回归的降维过程中存在易遗漏变量重要信息的问题。
Li[5]提出的切片逆回归法中认为协方差矩阵V的多个较小特征值的平均数渐进服从χ2分布,故可以通过截断χ2分布的右尾来确定合适的降维维数,林海明等[9]证明这种做法容易遗漏部分变量的重要信息,特别是在大数据中,模型评价维度较多,这些维度从多个角度进行评价,导致各角度内部变量关联性较大,但各角度之间的变量关联性较小,只选用特征值较大的主成分很容易将那些重要但关联性较小的变量信息遗漏,故如何保证不遗漏变量重要信息来确定主成分个数,是切片逆回归需要进一步解决的关键问题之一。
问题2抽样过程中个体入样概率难以确定的问题。
切片逆回归法只解决了因变量信息融入自变量的问题,缺乏确定个体入样概率的环节。Ma等[10]结合重要性抽样的思想,从数据自身获取信息,引入帽子矩阵的Leverage分数作为各个体的入样概率,提出了Leverage重要性抽样法。但帽子矩阵基于自变量构成,并未引入所要研究的因变量信息,从而导致Leverage重要性抽样法的稳健性较差。秦磊等[11]尝试将切片逆回归法与Leverage重要性抽样法结合在一起,从切片逆回归的角度解决自变量中需要融入因变量信息的问题,从Leverage分数的角度解决各个体入样概率的问题。但在实际操作中,基于估计的平均帽子矩阵来确定Leverage分数会降低各个体入样概率的差异,使得个体的特征在抽样中无法识别,特别是对于极端值样本无法正确确定其权重。故如何全面考虑各个体差异来确定个体入样概率,是将切片逆回归方法用于大数据抽样需要解决的另一个关键问题。
本文提出一种基于切片逆回归的综合得分抽样法,先对切片逆回归法的原降维过程进行改进,再引入个体主成分综合得分作为入样概率,解决以上2个难题。
2 基于切片逆回归的综合得分抽样法
问题1的解决设切片逆回归中各切片xi的样本均值记作k维随机向量m=(m1,m2,…,mk)T,利用式(2)求得k个主成分z=(z1,z2,…,zk)T,各主成分zi与各变量xi关系如式(3)所示:
zi=η1ix1+η2ix2+…+ηkixk,i=1,2,…,k,
(3)

林海明等[9]认为被选用的每个变量都是包含重要信息的变量(指标体系的科学性是构建指标体系的前提),若该变量与其他变量高度相关,这些信息高度相关的变量会被综合成某个主成分,但如果该变量与其他变量均不高度相关,该变量的信息将无法被几个特征值大的主成分所代表,需要增加包含该变量主要信息的主成分以保证该变量信息不被遗漏,故可以根据主成分zi与变量mi是否有显著相关性来筛选主成分,从而确定主成分个数p(降维后的维度)。
根据特征向量ηi=(η1i,η2i,…,ηki)T、特征值λi可计算出所有变量与所有主成分的成分矩阵U,具体如式(4)所示。
(4)
成分矩阵U即是各主成分与各变量的相关系数矩阵[12],根据切片逆回归的片数H和设定显著性水平α(常取值为0.05),可得显著相关的临界值rα(H-2),据此来判断矩阵U各列是否有显著相关的相关系数,若有绝对值超过临界值的相关系数,则认为该主成分与变量存在显著相关,应选中该主成分,以此类推,共选中p个主成分zl(l=1,2,…,p),来保证模型的重要信息不被遗漏,问题1得以解决。该方案还可能将那些特征值较大,但不与任何变量存在显著相关的主成分予以剔除(这说明该主成分中没有包含有任何变量的重要信息),保证各主成分均有显著相关的变量,从而也保证了各主成分对变量的对应性以及各主成分的可解释性。
问题2的解决由于切片后的自变量包含有因变量的重要信息,因此自变量被降维后的主成分也包含有因变量的重要信息,综合得分是各主成分得分的加权平均,可以用来对个体进行排序和分类[13],故可以用综合得分作为研究因变量选取样本时各个体的入样概率。
各主成分得分和综合得分的计算过程为:p个主成分zl(l=1,2,…,p)的特征向量分别作为系数,乘以各个体标准化值xij,求得第j个个体的主成分得分如式(5),综合得分如式(6)。问题2得以解决。
(5)
Fj综=λ1z1j+λ2z2j+…+λlzlj/k。
(6)
综上,对切片逆回归法改进得到可用于大数据抽样的基于切片逆回归的综合得分抽样法,具体步骤如下:
1)对原始数据进行切片处理:①自变量正向化、标准化:为保证数据降维具有一致的方向,需要对自变量正向化处理;②将因变量取值从小到大切为H片,并计算各片中各自变量的平均值;③用切片后自变量的平均值计算各自变量间的协方差矩阵V(见式(2),注意:这里如果用相关系数矩阵,计算结果可能不一样,因为自变量标准化后进行合并平均,会导致计算结果有差异)。
2)主成分分析计算综合得分:①计算协方差矩阵V的特征值和特征向量;②构造成分矩阵(式(4)),确定降维维度(显著相关的主成分及其个数);③计算个体各主成分得分以及综合得分(式(5)、(6))。

3 数值模拟分析
本文的数值模拟分析过程在Python中通过编程实现。数值模拟分析中考虑差异化的比较,拟生成3个数据集:
数据集1Y=Xβ+e,β=(10,1,2,3,4,5,6,7,8,9)T,e~N(0,In),X~N(1,Σ),协方差Σ=Σij,Σij=0.5δ(i=j)(其中i=j时,δ(i=j)=1;i≠j时,δ(i≠j)=0);
数据集2Y=ln(Xβ+100)+e,由于Xβ可能含负值,无法取对数,这里加100后再取对数;
数据集3Y=eXβ+e,数据集2和数据集3的设定与数据集1相同,均为N=10 000,变量个数k=9。
3个数据集中X、β和e的设定均相同,不同之处为Y的取值设定不同,目的是为了观测Y的分散情况对模型结果的影响,对模拟的数据集Y取值进行简单描述统计分析如表1所示。从模拟数据集变量Y的描述统计分析看,数据集1分散情况适中,数据集2较集中,数据集3较分散。
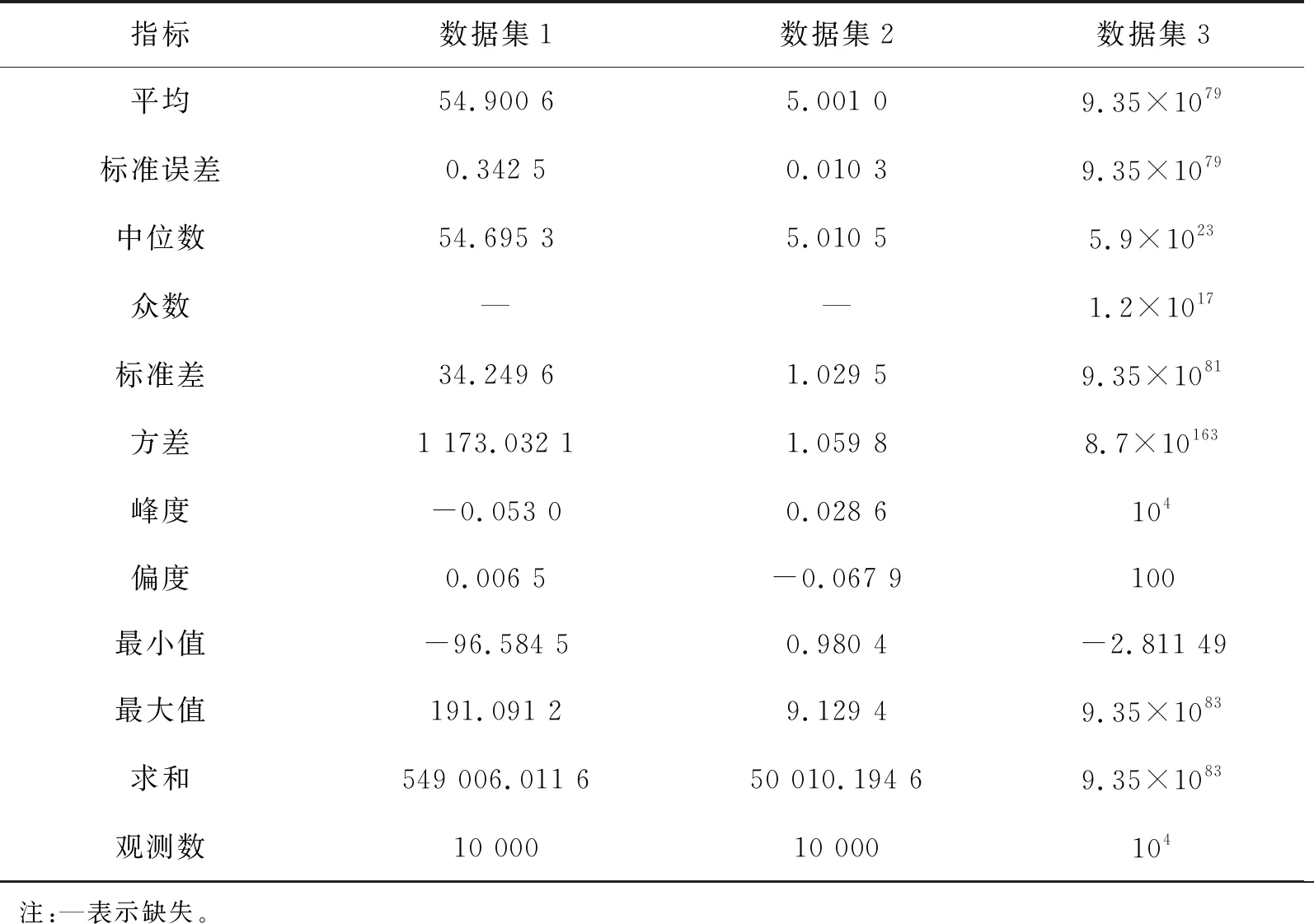
表1 各模拟数据集中Y的描述统计
对3个模拟数据集,分别采用两类抽样方式进行抽样:1)基于切片逆回归法的综合得分抽样;2)简单随机抽样。分别抽取样本n1=100、n2=500、n3=1 000、n4=10 000,各重复抽样30次,切片数为50;用所抽样本估计3个数据集中设定模型,对比两类抽样方式对估计模型的结果(不同数据集之间的拟合效果值不具有可比性),以模型拟合效果R2的平均值和标准差作为评价标准,其中R2的平均值越大表明模型拟合效果越好,标准差越大,表明模型稳健性越差(见表2至表4所示)。

表2 数据集1在2种方法上的模拟结果

表3 数据集2在2种方法上的模拟结果

表4 数据集3在2种方法上的模拟结果
对表2至表4的结果进行比较分析可知,n4=10 000是抽中全部总体计算的结果,与n1=100,n2=500,n3=1 000的情形相比,采用对总体进行抽样估计的结果均优于对总体直接估计的结果,且所抽样本越小,拟合效果越高,但拟合稳健性略微变差。比较两种抽样的估计结果,发现切片逆回归的综合得分抽样拟合效果大部分均优于简单随机抽样的结果,这说明对数据切片融入因变量信息,并对各个体计算综合得分赋权数抽样估计对提高模型估计效果是有效的。从不同数据集的结果对比发现,在因变量Y的分散程度较大的情况下,通过抽样进行估计会更容易改善模型拟合效果,这可能是因为Y的分散程度较大时,X对Y的影响更容易被模型检测到。综上,对大数据采用抽样估计常能得到更优的拟合模型,基于切片逆回归的综合得分抽样法较简单随机抽样具有更好的估计效果。
以上为设定的模拟数值分析结果,为验证以上结论的普遍性,下面进一步用实际数据进行分析。
4 实际数据的验证分析
选取UCI机器学习数据库中的Bike-Sharing-Dataset数据集[14]进行验证分析,分析过程在Python软件通过编程实现,以训练集数据构建变量ccnt(共享单车租赁总数)预测模型的拟合效果作为判断比较标准,同样采用基于切片逆回归法的综合得分抽样和简单随机抽样两类抽样方式进行比较。选用ccnt为因变量,hholi(节日)、wweekd(周末)、wworkd(工作日)、wweath(天气)、ttemp(温度)、aatemp(感应温度)、hhum(湿度)、wwindsp(风速)等8个变量为自变量,所有自变量先进行正向化处理。自变量正向化处理的具体过程为:hholi原始数据为正向数据,无需处理;wweekd将周一至周五调为0,周六和周日调为1;wworkd将原数据中1调为0表示工作日,原数据中0调为1表示非工作日;wweath原始数据为反向指标,将原取值1、2、3、4进行逆排序,分别调整为4、3、2、1,变为取值越大,天气越好;ttemp原数据为适度指标,取适度值为0.6进行正向化处理(采用公式:正向化值=1/(1+|原数据-适度值|)),正向化之后的结果表示取值越大,对因变量的影响越大;aatemp原数据为适度指标,取适度值为0.56进行正向化处理;hhum原数据为适度指标,取适度值为0.5进行正向化处理;wwindsp原数据为适度指标,取适度值为0.2进行正向化处理。设模型为
ccnt=β0+β1hholi+β2wweekd+β3wworkd+β4wweath+β5ttemp+β6aatemp+β7hhum+β8wwindsp+ε。
(7)
运用日周期的数据集,共获取N=731条数据,分别抽取样本n1=50,n2=100,n3=200,重复抽样30次,切片数为20个,模型判断标准与数值模拟分析中相同,所得结果如表5所示。

表5 实际数据集day在2种方法上的计算结果
为观察因变量的分散情况对模型结果的影响,将数据集中的变量ccnt分别取对数和指数(考虑到数据较大,这里以1.01作为底对其求指数)构造2个新数据集,与原数据集一起,3个实际数据集的因变量描述统计分析结果如表6所示。
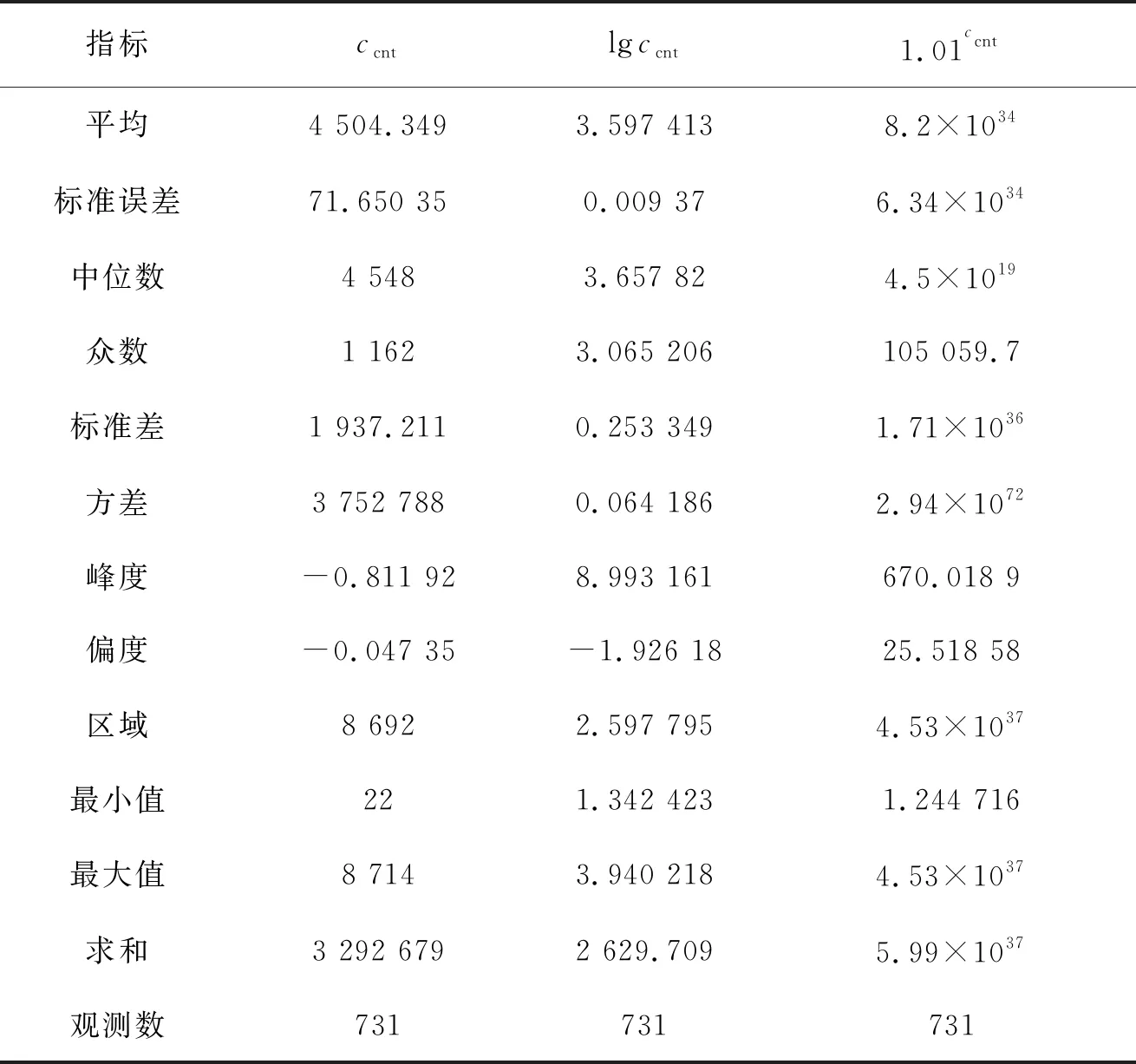
表6 实际数据集中因变量的描述统计
进一步用对数和指数后的ccnt新变量数据估计以上模型,采样类似的抽样方案,分别得到表7和表8的结果。

表7 实际数据集在两种方法上的计算结果

表8 实际数据集在两种方法上的计算结果
表5、表7和表8中n4=731是抽中总体计算的结果,进行表内对比和表间对比,可以得到以下几点结论:①对总体进行抽样估计的结果均优于对总体直接估计的结果,且所抽样本越小,拟合效果越高,但拟合结果的稳健性会略微变差;②基于切片逆回归综合得分抽样的估计结果要优于简单随机抽样的估计结果;③因变量分散程度越大,模型经过切片逆回归综合得分抽样估计的结果改善程度越大。此外,从表7可发现,在因变量较集中时,抽样估计的结果改善幅度较小。对比表5与表2的结果可知,当模型整体拟合效果较好时,采用抽样估计对模型的改善效果也较小。
进一步考察切片数H对抽样估计结果的影响,使用以上数据集(ccnt),分别设置H1=5、H2=10、H3=20、H4=50,设置抽样的样本量分别为n1=100和n2=200,重复抽样30次,得到表9的结果。
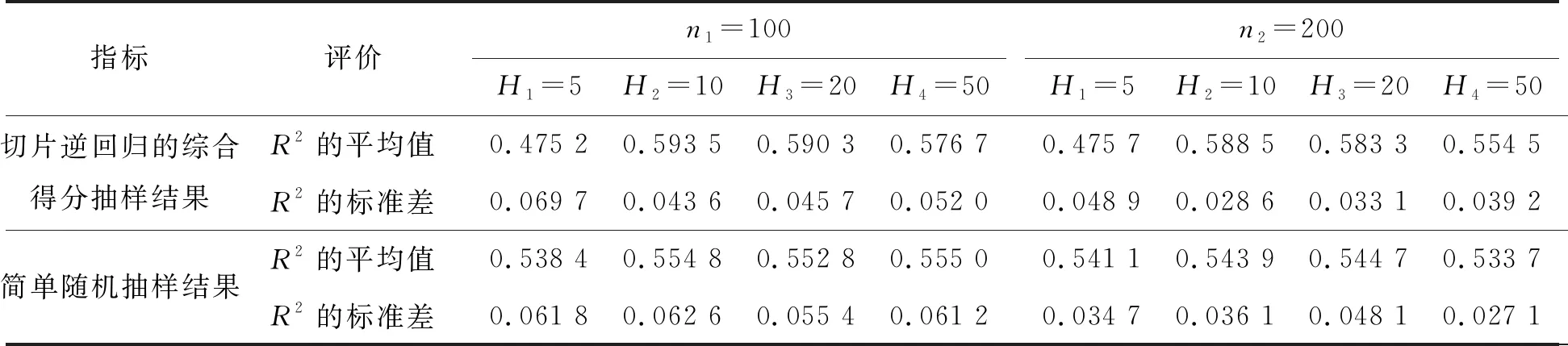
表9 实际数据集在切片数H不同时的计算结果
从表9仍然可以看出,基于切片逆回归综合得分的抽样估计结果大部分优于未赋权的简单随机抽样估计结果,切片逆回归的模型拟合效果R2普遍较高,且标准差较小(模型结果好,且稳健性更好),抽样样本量对估计效果的影响不大。比较切片数对模型估计结果的影响发现,模型拟合结果随着切片数的增加,存在先上升后下降的趋势。这是因为在切片数较小时,同一个因变量对应较多的自变量取值,将相同因变量信息同时融入较多自变量中,并不能起到通过因变量信息区别自变量的效果;随着切片数的增大,因变量对自变量的作用逐渐增大,起到区分自变量的作用;但随着片数的过大,每个因变量均对应较少的自变量,极端情形就是一个因变量取值对应一个自变量取值,这样无法将相同信息的自变量融合在一起,也不能起到自变量融合因变量信息的作用。在实际中,取一个比较适中的片数是比较恰当的,可以参考使用数据分组组数公式:H=1+log2N(其中N为数据集数据总数)。
5 结论
基于切片逆回归的综合得分抽样法,利用切片逆回归在自变量中融入因变量信息,通过对主成分降维过程改进得到的综合得分,可以作为各个体入样概率进行抽样。通过模拟数据分析和实际数据分析发现:①大数据情境下进行抽样估计的结果均优于对大数据直接估计的结果;②大数据抽样的效果随着所抽样本量的增大,拟合效果会变差,但稳健性逐渐变好,故选择合适的样本量抽样即可,无需追求过大的样本量;③基于切片逆回归的综合得分抽样法的估计结果优于简单随机抽样的估计结果;④因变量分散程度会影响模型估计效果,在因变量分散程度越大时,基于切片逆回归的综合得分抽样法的估计结果越好;⑤当总体数据对模型拟合效果较好时,采用抽样估计对模型的改善效果也较小,此时选用简单随机抽样即可;⑥切片数会影响基于切片逆回归的综合得分抽样法的估计结果,建议切片数不宜太大也不宜太小,可以参考数据分组组数的确定公式。
综上可得,基于切片逆回归的综合得分抽样法的估计具有更好的抽样效果,特别是大数据中各个体差别较大时抽样估计效果更好,可以作为对简单随机抽样估计的较好改进。
猜你喜欢
中国药房(2022年7期)2022-04-14 00:34:30
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
——与非适应性回归分析的比较
四川精神卫生(2019年2期)2019-06-18 02:45:00
文理导航(2017年20期)2017-07-10 23:21:03
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
中国当代医药(2015年17期)2015-03-01 02:03:38
新高考·高二数学(2014年7期)2014-09-18 00:42:02
