
函数型数据广义线性模型和分类问题综述
2022-01-28 09:23:04白德发王国长
广西师范大学学报(自然科学版) 2022年1期
白德发, 徐 欣, 王国长*
(1.暨南大学地方研究总院, 广东广州510632; 2.暨南大学经济学院, 广东广州510632)
随着科技和经济的发展,尤其是计算机储存技术的快速发展,在线观测成为现实,使得当今观测的数据量越来越大,维数越来越高,且相邻观测间高度相关,导致很多经典的统计分析方法不再适用,它们逐渐被推广到函数型数据[1-3]。本文从函数型数据发展的数据形式、函数近似包括基底展开和主成分、函数广义线性模型和分类等问题的发展历程及未来发展方向等方面进行详细的综述。
1 函数型数据的发展
函数型数据的研究可追溯到20世纪50年代,Grenander[4]研究了随机过程的理论性质及估计方法的问题;Rao[5]应用函数型数据分析方法处理儿童的生长曲线数据,得到了十分显著的应用效果。本文从研究的数据形式和函数型数据具体研究的内容和进展两个方面进一步综述函数型数据的发展。
1.1 研究的数据形式
函数型数据把整个曲线x(t)t∈T看成是来自Hilbert空间里的一个元素,假设x1(t),…,xn(t)是来自总体随机过程x(t)的一组样本。在实际问题中,由于x1(t),…,xn(t)无法在整个区间T上观测到,通常是观测到离散的点,如{xtij},i=1,…,N,j=1,…,Mi,其中,T是R上的一个紧区间,tij为第i个个体的观测点。在函数型数据发展历程中,根据Mi的大小和取值,将函数型数据分为超稠密型数据、平衡稠密型数据、非平衡稠密型数据、稀疏数据、超稀疏数据、流形数据和图像数据,具体如下:
(a)超稠密型数据:对于每一个个体i而言,Mi都很大(成千上万个观测),且不同个体可能的观测点也不同,即tij对不同的个体i取值不一样。
(b)平衡稠密型数据:对每一个个体都有相同的观测,且观测点也一样,即M1=M2=…=Mn=M,且每个个体的观测点也一样。通常M足够大,每一个个体仅用自身的观测点就能很好地拟合出自身的曲线。
(c)非平衡稠密型数据:对于不同的个体i,Mi和观测点都不尽相同,但是每一个Mi都足够大,足以很好地把个体i这条曲线拟合出来。
(d)稀疏数据:对于不同的个体i,Mi和观测点都不尽相同,且Mi数值不大,仅利用Mi个观测点不能把整个曲线拟合出来,需要借助不同个体的观测点来进行曲线拟合。
(e)超稀疏数据:对于每一个i而言,Mi都很小,需要借助其他个体来拟合曲线。
(f )流形数据:如地球上的运动轨迹。
(g)图像数据:主要以FRI和CT数据等为研究对象,一般可以看成是2维或多维的函数型数据。
超稠密型数据的研究起步较晚,Zipunnikov等[6]提出将重复测量的高维观测值的观测可变性分解为随机截距、斜率、偏差3个相加分量的方法,解决了使用高维纵向数据主成分分析(HD-LFPCA)在多次访问数据中的探索和分析高维图像种群的问题。Xiao等[7]研究了高维函数数据基于三明治平滑器的快速协方差平滑估计,让高维数据的计算速度提升了一个数量级。王德青等[8]则从聚类分析的角度出发,厘清了函数型数据聚类分析的研究现状,明确了原始数据直接聚类、两步法串联聚类、非参数距离聚类、自适应模型聚类,这4种可以将高维函数数据降维的函数型聚类方法。Xue等[9]开发了用于后正则化推理的技术,并基于一个能够在函数空间中,分离主要参数和干扰参数的不相关分数函数,提出了一种新式的超密集函数线性回归测试方法。
函数型数据最开始的研究是以稠密型数据为主,主要的分析工具是借助于基底展开,包括样条、小波和傅里叶等基底来拟合曲线,具体可以参考由Ramsay等[10]撰写的函数型数据书籍,而相关的程序实现可以参考文献[11]和R语言程序包fda。函数型数据非参数估计方法的研究可以参考Ferraty等[12]撰写的函数型数据书籍,而相关的程序可以从网址https:∥math.univ-toulouse.fr/staph/npfda/下载。函数型稀疏数据被广泛地研究,包括国内外众多知名学者,如Hall等[13]、Delaigle等[14]、Yuan等[15]Cai等[16-17]、Chiou等[18-19]、Yao等[20-21]、He等[22]、entürk等[23]、Müller等[24]、Wang等[25]等。主要应用的工具为随机过程的Karhunen-Loeve,源于Ash等[26],相关程序可以参考网址http:∥www.stat.ucdavis.edu/PACE/。James主要提出基于随机效应模型的样条估计,其相关程序可以参考网址http:∥faculty.marshall.usc.edu/gareth-james/Research/Research.html。
稀疏数据的时间序列模型研究可以参考Horváth等[27]。超稀疏数据的研究相对甚少,Zhang等[28]从理论上研究了超稀疏数据估计的大样本性质。
流形数据的研究始于2018年,Dai等[29]首次研究了光滑黎曼流形函数型数据的主成分分析RFPCA(Riemannian functional principal component analysis),并研究了主成分得分和主成分函数的理论性质。Lin 等[30]推导了黎曼随机过程上的Karhunen-Loeve展开,并给出了intrinsic RFPCA(iRFPCA)和RFLR(intrinsic Riemannian functional linear regression)等的估计方法,推导了相关的理论性质,模拟和实际数据分析进一步证实了IRFPCA和IRFLM 方法的优越性。Lin等[31]在黎曼流形和李群空间上研究了函数型数据的加性模型,并给出了非参数估计的最优收敛速度和参数估计的渐近正态性。关于这方面研究的程序可以从网址http:∥www.stat.ucdavis.edu/PACE/下载。图像数据或者二维函数型数据的研究主要应用于医学FMRI和CT数据。Zhu等[32]建议采用空间变系数模型分析具有跳跃点的神经影像数据。Goldsmith等[33]建议用空间贝叶斯变量选择方法估计函数图像回归参数,通过控制潜在的二值指示地图和内在的高斯马尔可夫随机域控制非零系数的光滑程度,从而进行变量选择。Wang等[34]采用Haar小波分析来分析一维反应对3维脑图像数据的回归问题,并采用非参数贝叶斯的方法,能够自动地鉴别附近像素的空间信息。
1.2 函数型数据研究的内容
Ramsay等[3]第一次提出了函数型数据分析的概念,并应用到加拿大35个气象站年降雨量数据的预测中。Silverman[2]把主成分分析推广到函数型数据分析,通过引入正则项得到光滑的主成分基底函数估计。James等[1]采用样条近似预测曲线和随机效应模型估计稀疏函数型数据的主成分。Yao等[35]利用局部线性核估计和条件期望估计稀疏数据的基底函数和主成分得分,研究了相关理论性质。Peng等[36]采用限制极大似然估计来估计函数主成分问题,并推导了相关理论性质。Chen等[37]在局部区间里考虑了函数主成分分析,并推导了相关理论性质。Leurgans等[38]首次推广向量的典型相关分析到函数型数据,指出对于无穷维的函数型数据,采用基底展开的方式来估计典型相关函数必须对待估函数加上正则化的惩罚才能得到有意义的结果。He等[39]基于 Karhunen-Loeve[26]展开来估计函数典型相关分析,He等[40]列举了函数典型相关分析的具体应用。函数回归模型是被研究最多的模型,包括线性模型和非线性模型,其中,被研究最多的线性模型有如下几种:
②反应是函数,预测是随机变量或向量:Y(t)=XTβ(t)+,
④函数变系数模型:Y(t)=α(t)+x(t)β(t)+(t),
⑤函数方差分析模型:Ymg(t)=α(t)+αg(t)+xmg(t)β(t)+mg(t),
线性模型①是被研究得最早和最广泛的模型之一,Cardot等[41]首次研究了该线性模型的计算问题,Cardot等[42]基于样条基底展开和主成分降维的估计,推导了基于样条展开估计的渐近收敛性质。Müller等[43]研究了基于主成分得分的函数加性模型的估计和理论性质,Yao等[21]研究了函数型数据二次回归模型。Cai等[16]在理论上推导了函数线性模型预测的收敛速率,在一定条件下,得出了预测能达到参数收敛速率的结论。Hall等[13]提出在不考虑截断误差的情况下,函数主成分是最优的基底,并给出了回归参数函数的最优收敛速率。在再生核希尔伯特空间上, Yuan等[15]提出惩罚估计相对于主成分回归能在较弱的条件下达到最优收敛速率。 Cai等[17]在再生核希尔伯特空间里研究了预测的最优收敛速率和自适应性。Delaigle等[14]建议应用偏最小二乘估计的基底函数来估计函数线性模型,并推导了回归参数函数的收敛速度。Wang等[44]提出了基于函数充分性降维基底来估计函数的线性模型,并推导了相关理论性质。
由Chiou等[18]率先提出的乘法效应模型可看成是模型②的推广,并在其中推导了相关理论性质。Chiou等[19]研究了带有光滑随机效应的函数拟似然回归模型,并研究相关理论性质。这一情形函数线性模型的检验问题也引起了很多学者的关注,如:Faraway[45]、 Shen等[46]和 Yang等[47]。
Ramsay等[3]最早研究线性模型③,并将其应用到加拿大35个气候站年降雨量的估计中。Yao等[20]针对稀疏函数数据,提出基于主成分的估计方法,并推导了具体的收敛速度。He等[22]研究基于函数典型相关基底的函数估计方法,并研究了相关理论性质。与基于主成分基底估计相比,典型相关基底能够有效利用预测和反应曲线的线性信息。为了克服典型相关基底和主成分基底需要选择正则化参数和估计中含有无界算子的逆等导致估计不稳定的问题,Yao等[21]提出基于奇异值成分的函数回归估计方法,并研究相关的理论性质。
对于变系数模型④,Fan等[48]提出两步估计法,即首先在任意时刻点t的局部领域内,采用最小二乘估计得到初始估计,然后再采用非参数方法光滑初始估计,得到最终的估计,并给出估计的渐近估计。entürk等[23]把回归函数在相应过程的协方差算子和方差算子的特征函数上,进行基底展开来近似回归参数函数,并推导了估计的理论性质。
函数方差回归模型⑤可以参考Ramsay等[10]第14章,其建议用函数方差分析来研究年降雨量的问题。函数广义线性模型⑥和分类方法研究是本文研究的主体,将在第3章进行详细阐述。
自从2000年以后,研究者逐渐关注函数型数据非参数和半参数的回归方法,包括函数型数据非参数核估计[12,49]、函数型数据加性模型[43,50]、函数单指标模型[24,51-52]、函数多指标模型和函数充分性降维方法[24,53-58]、函数部分线性模型[58-62]等。
自从函数型数据得以研究以来,函数时间序列模型得到广泛研究,如Bosq[63]定义了在Hilbert空间和巴拿赫空间里的函数自回归模型(functional autoregression model, FAR) 和函数自回归滑动平均模型(functional ARMA model,FARMA),并从理论上研究了估计方法、估计存在的条件及估计的大样本性质等问题。Hörmann等[64]推广了诺贝尔计量经济学奖获得者Engle[65]在1982年发表的autoregressive conditional heteroskedasticity model (ARCH)及函数ARCH 模型( functional ARCH, FARCH),并研究了FARCH模型的估计方法和渐进性质;Aue等[66]研究了函数广义ARCH模型(functional generalized ARCH,FGARCH)及相关理论性质,FGARCH可以看成是Bollerslev[67]广义ARCH(generalized ARCH, GARCH)的推广。至今,基本的函数时间序列模型都得以建立,并被广泛应用到经济、金融等高频数据分析中,取得了显著的应用效果,如:Müller等[68]基于函数主成分,研究了函数扩散模型,并应用函数扩散模型分析了S&P 500指数一天内盘中波动的情形及相关的理论性质。Horváth等[69]应用函数动态因子模型分析了一天内盘中价格曲线的问题,并研究了估计的大样本性质。Kokoszka等[70]应用动态函数回归模型研究股票收益率的面板数据,并推导了相关估计的收敛速度和渐近正态性。Dette等[71]研究了self-normalization方法的函数时间序列模型检验方法,并研究了相关理论性质。
函数聚类分析也是函数型数据研究的重点及热点问题,包括:基于原始数据的聚类[72-74]、基于基底展开或主成分基底降维后的聚类[75-82]、基于距离的非参数聚类[49,83-86]、自适应模型聚类[87-88]等。
多变量的函数曲线估计方法和回归模型也引起了广大研究者的广泛关注,Lian[56]研究了基于主成分展开的多变量函数回归模型的变量选择方法。Petersen等[89]对多变量函数数据提出了采用 Frechet 积分和距离选择等方法来估计协方差函数。关于函数型数据的书籍可以参考Ramsay等[10,90]、Ferraty等[12,91]和 Horváth 等[27]。
2 函数型数据的近似方法
函数型数据通常将整个曲线或图像看成是希尔伯特空间里的一个点,但是,实际观测数据是离散的。因此,首先需要将离散数据通过非参数的方法把曲线或曲面估计出来。常用的方法有核回归估计、基于基底展开的非参数估计、函数主成分分析基底和基于函数充分降维基底等。核回归估计方法可以参考有关非参数估计的相关书籍,本文详细讲述基于2种基底展开的方法:①基于已知基底展开;②基于主成分基底展开。
2.1 基于已知基底展开
设x1(t),…,x(t)是随机过程x(t)t∈T的独立样本,通常情况下无法观测到整个样本,只能在有限个点上观测,而且观测通常含有测量误差,观测数据y(t)如下(本章仅考虑平衡稠密数据):
yitj=xitj+ij,i=1,…,n,j=1,…,M。
在非参数估计中,常用的基底函数有傅里叶基底、样条基底和小波基底。每一类基底适应的数据类型各不同,如傅里叶基底一般适用于周期数据,如天气数据;小波基底适用于脉冲数据;样条基底尤其是B样条基底是比较常用的基底函数,其理论上与核回归是等价的。本文以B样条基底为例讲述估计基于已知基底展开的函数估计方法。
样条是利用一组给定点集(节点)来拟合曲线,并通过其将观测区间划分为子区间来构造。首先,需要给定L个内节点,记为τ1,…τL,数据观测的端点为τ0和τL+1,τ1,…,τL,通常可以等间隔或按观测点分位数来选取。其次,需要给定样条的次数R,通常选取R=3,即采用3次样条来拟合函数,那么样条基底的个数为K=L+R,记K个基底为φ1(t),…,φk(t)。以x1(t)为例,接下来详细阐述估计的具体步骤。
①构建基底函数:给定L个内部节点τ1,…τL和样条函数的次数R,K=L+R+1,R程序包fda构建B样条基底函数的函数为:BBas=create.bspline.basis(c(τ0,τL+1),K,R+1,c(τ0,τ1,…τL+1))。
②计算基底函数φ(t)=φ1(t),…,φK(t))T,在t1,…,tM上的值记为:

③计算基底函数二次导数平方的积分矩阵:
具体计算R语言程序为:H=inprod(BBas,BBas, Lfdobj1=2, Lfdobj2=2)。
④通过最小化如下目标函数:
Y=(y1(t1),…,y1(tM))T。
⑥光滑参数λ的选取,采用最小化GCVλ,令
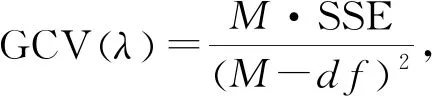
2.2 基于主成分基底展开

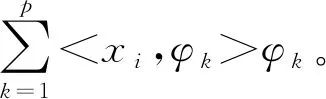
具体估计算法如下:
①由离散数据得到函数曲线,即通过基底展开或者其他的方式得到函数目标。
具体程序如下:BBas=create.bspline.basis(c(τ0,τL+1),K,R+1,c(τ0,τ1,…τL+1)),其中,τ0,…,τL+1,K,R
定义见2.1节。
Data.fd=data2fd(data,t1,…,tM,basisobj=BBas),
②计算主成分基底函数、特征值和主成分得分。
Pca=pca.fd(Data.fd,nharm=3,centerfns=TRUE),其中,nharm表示需要估计的主成分个数,centerfns=TRUE表示计算的特征函数和主成分得分是中心化后计算得到的。
④采用方差解释率来选择主成分的个数。
这里讲的是稠密均衡数据的主成分分析和实现程序,关于稀疏函数主成分数据分析方法和程序实现可以从以下2个网址下载:http:∥www.stat.ucdavis.edu/PACE/;http:∥faculty.marshall.usc.edu/gareth-james/Research/Research.html。
3 函数型数据广义线性模型及分类
3.1 广义线性模型
函数型数据中被广泛研究的是回归模型,在众多回归模型中,广义线性模型与其他回归模型存在着显著不同。James[92]首次研究了预测式函数的广义线性模型,首先采用函数主成分对函数进行降维,然后研究了反应与主成分得分之间的关系,理论、模拟和实际数据分析表明该方法的优势。Escabias等[93]研究了基于基底展开和主成分展开两种方式的Logistic 回归模型估计方法。Cardot 等[94]研究了函数预测与Scalar随机反应间的广义线性模型,从理论框架及模型可识别等方面研究函数广义线性模型的相关理论性质,并基于样条基底展开来近似函数预测,采用惩罚似然估计方法来估计回归系数,并研究了回归参数函数的收敛速度。Müller等[95]针对稀疏函数型数据,研究了方差函数已知和未知情形下的函数广义线性模型,对函数预测采用稀疏数据主成分基底近似,对基底系数采用估计方程的方法进行估计,该估计方法包含普通的函数线性模型、函数Poission回归和二值回归等作为特例,并可以应用于函数数据分类模型。为了克服大气数据高维和高度相关等问题,Escabias等[96]应用函数Logistic回归分析大气数据,并取得了良好的应用效果。为了克服预测函数是无穷维的问题,通常通过把预测函数和回归参数函数在同一个已知基底上展开,把无穷维问题转化为有限维问题,但是,这样的基底展开所得到的设置阵通常也存在共线性问题,从而导致参数估计不精确。为了克服这一问题,函数主成分基底被广泛地应用到回归模型中,但是主成分基底仅与预测函数有关,与反应变量无关,很难保证对预测重要的基底亦对反应变量重要。为了克服主成分的缺陷,Escabias等[97]提出了基于偏最小二乘基底的Logistic回归模型估计方法,使用模拟数据和实际数据证明了基于偏最小二乘基底的优越性。Aguilera等[98]应用函数Logistic回归模型分析全身性红斑狼疮,与采用纵向数据分析的方法相比,函数型数据取得了更好的预测效果。Zhu等[99]对含有多条预测曲线的函数Logistic回归模型进行变量选择,并应用到宫颈癌的数据分析中,取得了显著的应用成果。Gertheiss等[100]研究了函数广义线性模型的变量选择问题。文献[101]研究函数广义加性模型。Matsui[102]研究了多分类函数Logistic回归模型,并考虑了变量和函数边界的选择等问题。Fan等[103]应用函数广义线性模型分析基因组的关联学习。Shang等[104]对函数广义线性模型提出了一个正则化的非参数推断,并在再生核希尔伯特空间的框架下,构建了回归均值的渐近置信区间和检验样本的预测区间等。Fan等[105]应用广义线性模型分析复杂疾病的基因水平meta分析,并取得很好的应用效果。Jadhav等[106]检验了预测是否对多元反应变量具有显著的影响,通过主成分降维和广义估计方程估计模型参数,并建立参数的渐近正态性,基于渐近正态性构建显著性检验,并取得了显著的应用效果。Scheffler等[107]应用广义函数线性模型分析EEG数据,建议的方法能够对typically developing (TD)和autism spectrum disorder (ASD)儿童提供显著的区别。为了提高模型估计和预测的精度,Zhang等[108]对广义线性模型提出了基于Cross-validation的模型平均方法,与单一方法相比,模型平均能够显著地提高估计和预测精度。
3.2 分类模型
Stone[109]和Devroye等[110]研究发现最近邻分类应用于函数数据时与有限维情形存在显著不同。James等[1]把经典的线性判别分析推广到函数型数据,提出了函数线性判别分析(FLDA),FLDA在曲线只部分被观测到的情况下效果明显,还给出了函数二次判别分析和正则化的函数判别分析。 Ferraty等[111]提出了采用非参数核估计的方法估计后验概率P(δ=1|X=x),并基于后验概率对多分类反应变量进行分类。Biau等[112]为取值于无穷维希尔伯特空间的随机曲线建立了最近邻分类方法的弱相合性,通过把函数预测在Fourier基底上进行展开后,对其系数采用KNN分类,并应用到语音识别中去。Leng 等[113]应用函数主成分和Logistic 回归模型对酵母细胞周期数据进行分类,并与对预测进行B样条展开后的判别分析进行比较后,发现基于主成分基底的Logistic回归模型具有一定的优越性。Abraham等[114]研究了函数型数据二分类moving window 分类方法,并证明了在一定条件下moving window 分类是收敛的。Rossi等[115]研究了函数型数据支持向量,并研究了核支持向量机,探究了分类的相合性。Wang等[116]应用小波基底来近似预测函数,提出Bayesian Logistic回归模型。为了克服已知基底和主成分基底展开无法充分应用反应变量信息的缺陷,Preda等[117]提出使用基于偏最小二乘基底的函数判别分析方法。Gomez-verdejo等[118]考虑到函数型数据的分类需要在初始集合中选择一个特征的缩减子集,提出了一种用于分类任务的交互信息估计方法,解决了交互信息准则虽可以在这种情况下使用,但很难通过有限的样本集进行估计的问题。Rossi等[119]综述了函数SVM分类方法,指出目前大部分函数SVM分类都是直接采用观测曲线进行分析,提出一种新的基于函数导数的SVM分类方法。Li等[120]结合经典线性判别分析和支持向量机,提出了分段函数判别分析(FSDA)方法,该方法特别适用于稀疏函数型数据,尤其是包含空间异方差和局部凸起的曲线。Berlinet等[121]采用小波基近似函数预测,并通过适当数据相关阈值将整体无穷维降为有限维,同时对非零系数进行有限维分类,通过数据分割和经验风险最小化,自动选择维数和分类器。Delaigle等[14]证明在函数数据分类问题中,利用函数数据固有的高维性质,通过线性方法能够实现完美的渐近分类。在有限样本的函数型数据中,通过投影到偏最小二乘法或主成分基底上实现的线性截断可以获得良好的分类性能。Rabaoui等[122]提出了一种将生成模型和函数型数据分析方法相结合的非参数方法,基于改进后的贝叶斯分类器对音素信号进行识别分析,并与函数型支持向量机方法进行对比,发现该非参数方法具有一定的优越性。考虑到函数型数据分类方法的结果容易受选择距离的影响,Chang等[123]针对图像数据,提出了一种基于小波阈值的距离分类方法,实际数据分析表明该方法有很好的分类效果。Berrendero等[124]对函数分类问题提出了基于距离相关进行变量选择的方法。为了克服函数型数据无法进行Bayes分类的困难,Dai等[29]通过主成分基底降维把函数型数据分类转变为基于主成分得分的问题,对主成分得分采用Bayes 分类。函数可以通过与类中心的距离远近进行分类,Darabi等[125]提出一种基于加权函数投影距离进行分类的新方法,通过选择具有最优分类结果的投影函数,使该方法具有最优的分类结果。
4 总结和展望
函数型数据由于其自身无限维的特点,符合大数据时代下对数据信息丰富性和结构复杂性的要求,使其在近几年来无论在实际的应用中还是在理论探究中,一直是统计研究的热点。本文以函数型数据为主要研究对象,从数据观测时间点的数量大小和数据取值形式的角度,将函数型数据划分为7类。根据模型中响应变量和协变量关于函数型数据不同的组合方式,将模型主要分为6种,并梳理了这6种函数型数据模型具体研究的内容及进展。从基选取的角度出发,讨论了基于已知基底展开和基于主成分基底展开的函数型数据近似方法。最后,为了填补目前仍缺少有关函数广义线性模型和分类问题的综述或书籍的空白,本文对函数广义线性模型和分类问题进行了较为详细的综述。
根据函数型数据无限维的特征,基于对现有研究内容的剖析和总结,函数型数据未来的研究方向主要可以分为以下几个方面。
1)超稀疏数据的研究。现阶段对超稀疏数据的研究仅停留在估计的大样本性质上。超稀疏数据中含有有限个个体且每个个体观测数据都很少。基于此特点,其可能包含许多更为复杂的数据,例如:多元数据、相关数据,或是包含图形形状信息的数据等。这会导致下一代新函数型数据的产生,为函数型数据在数据特征和回归分析的研究上提供新思路。
2)空间函数型数据的研究。现如今研究的函数型数据的应用主要集中于时序数据,而缺乏在区域空间数据上的一般性讨论。但实际的函数型数据往往与区域的空间信息相关,例如某地区的农作收成记录、天气记录、交通运输记录等。
3)流形数据及图像数据的研究。流形数据和图像数据的研究还相对较少,如流形半参数模型至今还未研究。图像数据的研究主要是基于医学图像数据,但是相关理论研究甚少。
4)加强理论在各领域的应用与推广。现阶段对函数型数据的分析主要集中于生物医疗、气候预报、金融管理和系统工程等多个领域,但大多数的应用主要是套用在此研究领域已有的经验法则,缺乏在一定的应用背景下的理论创新。
附录
以B样条基底估计 y=2*sin(2*pi*t)+rnorm(p,0,sig)的程序实现
library(fda)#functional data analysis, spline,install.packages(fda)
p=100
t=seq(0,1,length=100)
sig=0.5
y=2*sin(2*pi*t)+rnorm(p,0,sig)
plot(t,y)
K=14
order=4
tfine=seq(0,1,length=1000)
betabasis=create.bspline.basis(c(0,1),K,order,seq(0,1,length=K+2-order))
Lfdobj <- 2
lambda <- 1e-3
Phi=eval.basis(t,betabasis)
R=inprod(betabasis,betabasis, Lfdobj1=2, Lfdobj2=2)
Chat1=solve(t(Phi)%*%Phi)%*%t(Phi)%*%y
Chat=solve(t(Phi)%*%Phi+lambda*R)%*%t(Phi)%*%y
betafd2=fd(matrix(Chat,K,1), betabasis)
yhat=eval.fd(t,betafd2,0)
plot(t,yhat)
betafd2=fd(matrix(Chat1,K,1), betabasis)
yhat1=eval.fd(t,betafd2,3)
plot(t,yhat1)
matplot(t,cbind(y,yhat,yhat1))
growfdPar <- fdPar(betabasis, Lfdobj, lambda)
xttm <- smooth.basis(t, y, growfdPar)$y2cMap
xcoef=xttm%*%(y)
betafd2=fd(matrix(xcoef,14,1), betabasis)
yhat2=eval.fd(t,betafd2,0)
matplot(t,cbind(yhat,yhat2))
loglam <- -15:15
nlam <- length(loglam)
dfsave <- rep(0,nlam)
gcvsave <- rep(0,nlam)
for (ilam in 1:nlam) {
lambda <- 10^loglam[ilam]
fdParobj <- fdPar(betabasis, Lfdobj, lambda)
smoothlist <- smooth.basis(t, y, fdParobj)
fdobj <- smoothlist[[1]]
df <- smoothlist[[2]]
gcv <- smoothlist[[3]]
dfsave[ilam] <- df
gcvsave[ilam] <- sum(gcv)
}
cbind(loglam, dfsave, gcvsave)
cbind(loglam, dfsave, gcvsave)
plot(loglam, gcvsave, type="b",xlab="Log_10 lambda", ylab="GCV Criterion",
main="gilr Smoothing")
plot(loglam, dfsave, type="b",xlab="Log_10 lambda", ylab="Degrees of freedom",
main="gilr Smoothing")
ind=which(gcvsave==min(gcvsave))
ind
growfdPar <- fdPar(betabasis, Lfdobj, (10^loglam[ind]))
xttm <- smooth.basis(t, y, growfdPar)$y2cMap
xcoef=xttm%*%(y)
betafd2=fd(matrix(xcoef,14,1), betabasis)
yhat=eval.fd(t,betafd2,0)
plot(t,yhat)
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:08:00
安徽师范大学学报(自然科学版)(2022年3期)2022-07-14 03:54:42
中国银幕(2022年4期)2022-04-07 21:28:24
中学生数理化·高一版(2021年2期)2021-03-19 08:32:06
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:34
制造技术与机床(2017年7期)2018-01-19 02:30:00
软件(2017年6期)2017-09-23 20:56:27
计算机测量与控制(2017年6期)2017-07-01 16:24:14
山东工业技术(2016年15期)2016-12-01 05:32:02
中国卫生标准管理(2015年7期)2015-01-27 05:24:31
