
基于MuGNN模型的互联网医疗知识融合研究
2022-01-26 08:23廖开际
河南科学 2021年12期
廖开际, 王 莹
(华南理工大学工商管理学院,广州 510641)
随着人们健康意识的不断提高,现有医疗服务水平已不能满足人们的需求,医疗系统智能化刻不容缓.智能医疗的建立需要科学强大的知识体系来支撑,于是医疗知识库应运而生. 医疗知识库的应用使得非结构化的知识被有效地管理和利用,简化了患者看病的流程,减轻了医生的工作量,提高了医生的工作效率.医疗知识库常用于疾病诊断决策、医疗知识检索等. 由于医疗知识分布广泛,且不同数据源所获取的知识也是有差异的,因此多来源医疗知识库中的知识冗余问题比较严重. 为了减少医疗知识库中的知识冗余,知识融合工作不可或缺.
知识融合是将来自多个数据源的属于同一实体或者概念的描述信息融合起来,以获得较单一数据源更加完全、准确、可靠的知识库. 知识融合目前已在各个领域得到应用,如Freebase[1]、Google知识图谱[2]等,它们通过知识的链接和融合来实现知识库的大规模化,从而使知识发挥最大的价值.
知识图谱是一个结构化存储知识的知识库,其保存的知识是以三元组的形式存在的. 知识图谱KG由实体E、关系R、关系三元组Tr构成,即KG=(E,R,Tr),其中Tr=(h,r,t),h和t代表实体,r代表实体间的关系. 对来自多个数据源的知识图谱进行实体对齐的目的是找出多个知识图谱中所有语义相同的实体,即为KG生成实体修剪后的邻接矩阵A,其中A=(ei,ej),ei∈KG1,ej∈KG2,ei=ej,ei和ej分别代表KG1和KG2中的实体.
实体对齐是指从异构数据源的知识图谱中,找出表述不同但对应现实世界同一指代的实体,是知识融合最主要的工作. 现有的实体对齐方法分为以下三种:一是基于概率模糊匹配的方法,如支持向量机SVM[3];二是基于距离度量的方法,如计算字符串余弦相似度[4];三是基于嵌入式的方法,如2013年Bordes等[5]提出的将实体关系看作头实体到尾实体间翻译的TransE模型.
早期实体对齐方法主要是以概率匹配和字符串相似度作为对齐依据. Monge 和Elkan[6]在2014年提出了通过计算实体对字符的编辑距离来判断两者是否为同一实体的方法. Volz等[4]在2009年制定了一套计算相似度的度量标准,包括数字相似度、字符串相似度、URL相似度等. 但是这类方法都需要依赖人工定义的标签,应用场景范围狭窄,无法迁移至其他场景,而随着数据的大规模化,其准确率及效率都逐渐下降.
目前,基于嵌入式的实体对齐方法已成为研究主流,其主要思想是将不同的知识图谱的实体和关系均映射到同一向量空间后计算实体间的距离. 除了基础的翻译模型TransE外,IPTransE模型[7]和BootEA模型[8]都是采用迭代的方式来提高对齐效果,前者是对置信度较低的对齐实体赋予低权重,后者是对可能错误的对齐实体标签进行重新编辑标记. JAPE 模型[9]则是通过引入属性三元组填补信息来增强实体表示的. 虽然以上这些翻译模型的性能都不错,但是超参数过多,训练过程较繁琐.
随着图神经网络(Graph Neural Network,GNN)的兴起,许多学者开始根据GNN模型进行实体结构建模.图神经网络(Graph Neural Network,GNN)模型是由Scarselli等[10]提出的一种作用于图结构的神经网络,该模型通过迭代更新节点的隐藏状态来捕捉图中每个邻居节点的状态. 为了增强GNN模型对结构特征提取的能力,Thomas和Kipf[11]提出了利用卷积核抽取特征的图卷积神经网络(Graph Convolutional Network,GCN)模型,该模型将卷积操作定义在节点的连接关系上. 为了放大图结构中最重要部分的作用,Veliokovie等[12]在2018年首次提出图注意力网络(Graph Attention Network,GAN)模型,现已被广泛应用在众多领域. 基于图神经网络的方法在利用图神经网络进行实体表示的同时可直接进行实体对齐. Wang等[13]提出的GCN-Align模型是应用图卷积神经网络对实体之间的等价关系进行建模,在利用关系三元组的基础上加入实体属性特征信息生成实体嵌入. GMNN模型[14]是将初始化矩阵定义为实体名称的词向量矩阵,而不是随机进行初始化,因此该模型的性能大大提升. HMAN模型[15]则是将实体的多个视图进行统一并提出新的框架来进行实体表示.
嵌入式的实体对齐方法通常是假设两个知识图谱的同种实体具有相同或相似的邻居结构,然而现实生活中它们是存在结构异质性的,这就给实体对齐带来了一定的难度. 另外,嵌入式的实体对齐方法认为实体的所有关系邻居在对齐过程中都发挥着同样的作用,但是在知识图谱中某些实体的共有邻居的区别并不够大,因此这些方法可能会忽略对对齐真正有影响的实体.
有部分学者对图结构的异质性问题进行了深入研究并提出了一些新的模型,如MuGNN模型、AliNet模型、NMN模型. MuGNN模型[16]利用AMIE+诱导出规则增加关系三元组以补全图结构,同时还引入了跨图注意力机制以修剪图结构. AliNet 模型[17]通过引入远距离邻居对实体邻居结构的重叠部分进行扩展,并使用门机制对直接邻居和远距离邻居信息进行聚合. NMN 模型[18]先采用图采样方法为实体提取有判别力的邻居,然后采用基于注意力的交叉图邻居匹配模块对实体子图进行鲁棒对齐,最终取得了较好的实体对齐效果.
本研究首先构建了基于不同医疗网站的乳腺疾病实体关系库,然后采用MuGNN模型进行实体对齐,并与JAPE模型、GCN-Align模型的实体对齐效果进行了对比,之后完成了互联网医疗实体关系库的知识融合,最后通过Neo4j图数据库对融合后的互联网医疗知识图谱进行可视化处理. 本研究可为多源知识图谱的构建与补全提供一定的参考.
1 互联网医疗知识融合的流程
互联网医疗知识融合的流程如图1所示,具体分为以下两个阶段:
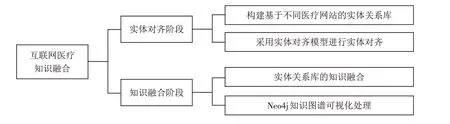
图1 互联网医疗知识融合的流程Fig.1 Process of internet medical knowledge fusion
1)实体对齐阶段. 首先从不同医疗网站中爬取并抽取得到实体,然后构建基于不同医疗网站的实体关系库,最后采用实体对齐模型进行实体对齐.
2)知识融合阶段. 首先将基于不同医疗网站构建的实体关系库进行知识融合,然后通过Neo4j图数据库对融合后的互联网医疗知识图谱进行可视化处理,以知识图谱的形式将疾病、症状、药物等实体类别及其关系进行关联.
2 实体对齐阶段
2.1 实体对齐模型
本研究采用的实体对齐模型为MuGNN 模型,实体对齐步骤如下:首先,将跨图注意力引入到图卷积神经网络中以修剪多余的实体;然后,为区分邻居实体的重要性,采用图注意力网络对实体关系进行赋权;最后,将进行上述处理后的两种实体进行嵌入聚合,并基于对齐种子训练对齐. MuGNN模型由输入层、跨图注意力GCN层、图注意力网络GAT层、池化层和对齐层五个部分组成,该模型的整体结构如图2所示.
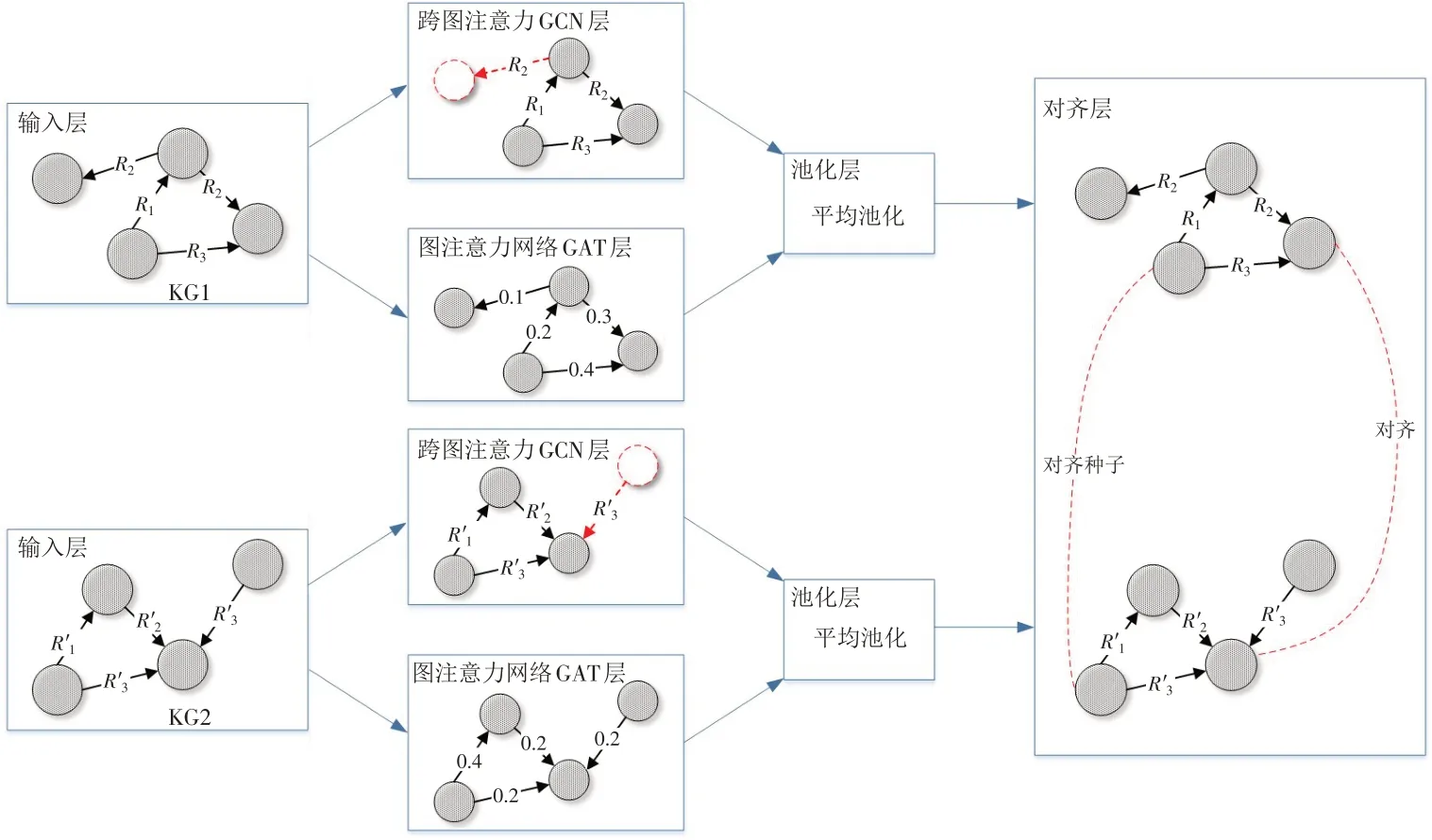
图2 MuGNN模型的结构示意图Fig.2 Structure diagram of MuGNN model
2.1.1 输入层 输入层主要负责将多个不同数据来源的知识图谱输入到模型中.
2.1.2 跨图注意力GCN层 跨图注意力GCN层主要负责将使用跨图注意力机制进行实体修剪后的图谱输入到图卷积神经网络中以得到增强的实体嵌入. 受人类视觉注意力机制(即当人类观察某事物时,通常不会观察该事物的整体而是把目光聚焦在其重要的部分)的启发,许多学者开始对注意力机制进行研究. 注意力机制允许模型动态地去关注对决策更有帮助的信息,可降低模型对其余信息的关注、忽略噪声信息,从而使模型更为高效地完成任务. 注意力机制最早被应用于图像识别领域[19],随着自然语言处理的兴起,其相关模型被大量应用于机器翻译、情感分析问题当中[20].
由于结构异质性的存在,两个不同数据来源的知识图谱的对齐实体不一定具有相似的邻居结构. 以实体“乳腺癌”为例,图3分别给出了来自医疗网站“39健康网”(http://www.39.net/)和“寻医问药网”(https://www.xywy.com/)的部分关系子图,可以看到KG1和KG2拥有不同的邻居实体以及关系结构. 结构异质性的存在会给实体对齐过程引入大量噪声实体,降低对齐效果. 但是通过使用跨图注意力机制[16],选取两个图谱中具有公共部分的关系子图就可以忽略对对齐任务有负面影响的噪声邻居,最终可为KG生成实体修剪后的邻接矩阵A1,实现结构调节. 邻接矩阵A1的计算公式如式(1)所示.

图3 从两个不同医疗网站获得的部分关系子图的结构差异Fig.3 Structural differences of partial relationship subgraphs obtained from two different medical websites

图卷积神经网络(GCN)由多层图卷积层堆积而成(图4),其作用是从图中提取特征后得到图嵌入表示.GCN模型通过级联的层来感知邻居的特征,层与层之间的参数共享. GCN 模型以图的节点特征矩阵XN×D和图的结构特征邻接矩阵A1作为输入,N代表图中的节点数量,D代表特征维度. 与GNN 模型相比,GCN 模型通过增加单位矩阵来将节点对自己的作用考虑进去,并通过引入拉普拉斯矩阵对邻接矩阵A1进行归一化. GCN模型中l+1层的输出公式如下:
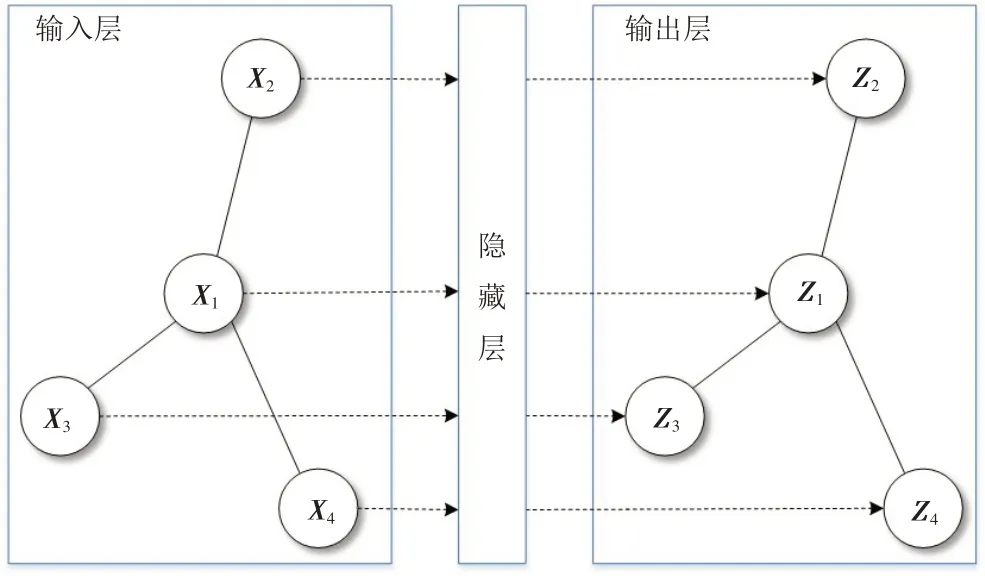
图4 图卷积神经网络的结构示意图Fig.4 Structure diagram of graph convolutional neural network
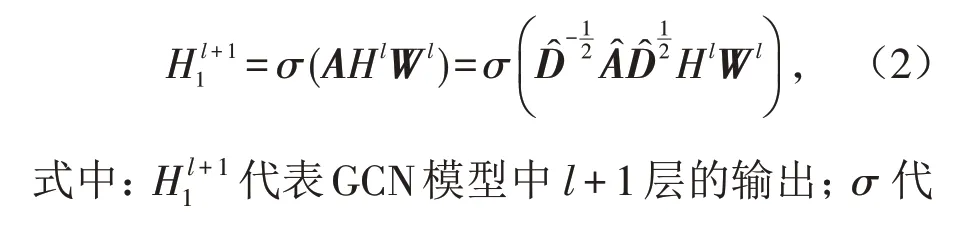
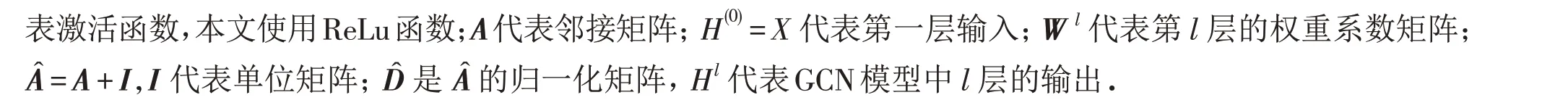
2.1.3 图注意力网络GAT层 图注意力网络GAT层主要负责使用GAT模型进行图谱结构的构建,并为每个实体关系赋予权重. 实体对齐中每个邻居节点的重要性不同,比如治疗“乳腺癌”的药物“枸橼酸他莫昔芬”同样对疾病“乳腺增生”起作用,但与专门治疗“乳腺癌”的药物在实体对齐中的作用是不一样的. 为了更好地区别各个实体在实体对齐中的作用,MuGNN模型采用图注意力网络赋予每个实体关系不同的权重值,并为每个实体捕获到信息最丰富、最有判别力的邻居.
GAT模型是在GCN模型的基础上引入带有掩码的隐藏自注意力层对图结构进行处理,它由多层图注意力层堆积而成,通过计算邻居节点的特征对当前节点的影响来为每个实体关系分配权重. 与GCN 模型相比,GAT模型对不同的邻居节点的重要性进行预测,它不依赖对全局图结构的预先访问,不需要对其进行人工先验,也无需繁琐的矩阵计算,降低了算法的复杂度,因此它可使MuGNN模型具有更好的性能.

GAT 模型中邻接矩阵A2的计算方式如式(4)所示. 为了使注意力互相关系数易于计算和比较,引入softmax函数对所有节点i的邻居节点j进行正则化.
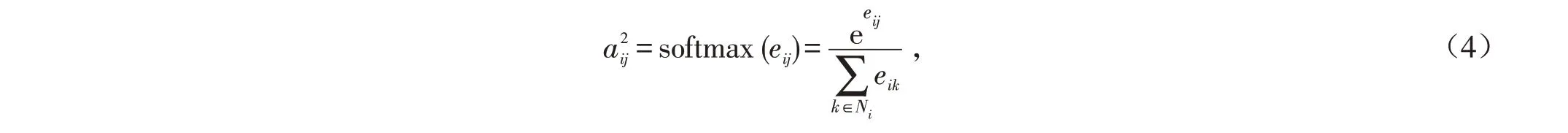
为了防止过拟合现象的产生,利用GAT模型计算多个相互独立的注意力后进行集成. GAT模型中l+1层的输出计算公式如下:

2.1.4 池化层 池化层主要负责将通过跨图注意力GCN层和图注意力网络GAT层建模得到的增强实体嵌入分别进行平均池化聚合. MuGNN 模型通过跨图注意力GCN 层和图注意力网络GAT 层进行图结构的构建,为了降低卷积层(跨图注意力GCN层、图注意力网络GAT层)输出的特征向量维度,防止过拟合现象的发生,采用平均池化将跨图注意力GCN 层和图注意力网络GAT 层建模得到的增强实体嵌入进行聚合.MuGNN模型中l+1层的聚合实体嵌入的计算公式如下:

2.1.5 实体对齐层 实体对齐层负责通过对齐种子和最小化代价函数将两个知识图谱嵌入同一空间进行训练. 首先利用对齐种子将两个知识图谱(KG1和KG2)的实体和关系嵌入到同一个低维度的向量空间中并计算实体之间的距离,然后利用最小化等价实体距离、最大化非等价实体距离的思想来训练模型.采用L2范数计算实体之间的距离,计算公式如下:

式中:ei和ej分别代表两个图谱(KG1和KG2)中的实体;h(ei)和h(ej)分别代表实体ei和ej的特征向量,D(ei,ej)代表实体ei和ej之间的距离.
采用最小化实体对齐损失函数来训练模型,最小化实体对齐损失函数计算公式如下:
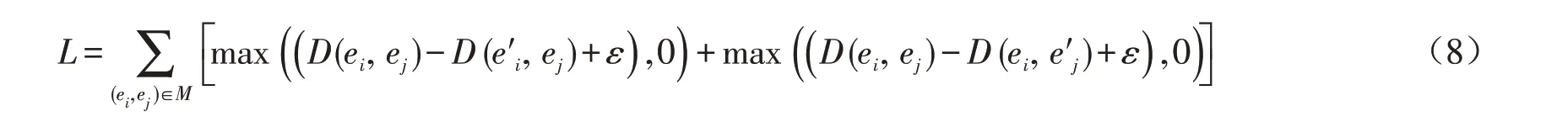
式中:L代表损失函数,当损失函数趋近于0时,模型性能最优;e′i和e′j是随机替换ei和ej得到的负样例;ε代表正样例与负样例间的最小间隔.
2.2 互联网医疗知识实体关系库的构建及实体对齐
2.2.1 互联网医疗知识实体关系库的构建 首先对互联网医疗知识的文本特点进行分析,然后根据文献[21]中的分类规则,将互联网医疗知识的实体类别分为7 大类(表1),实体关系类别分为14 大类(表2). 由于互联网医疗知识包含的疾病种类很多,为了能简单地说明问题,本研究仅选取与乳腺疾病相关的互联网医疗知识进行研究. 首先从医疗网站“39 健康网(http://www.39.net/)”和“寻医问药网(https://www.xywy.com/)”的乳腺疾病板块中对文本进行爬取清洗,然后依次进行实体识别和关系抽取操作,最后得到两个网站中与乳腺疾病相关的实体集和实体关系集,并构建来源于两个不同医疗网站的乳腺疾病实体关系库.
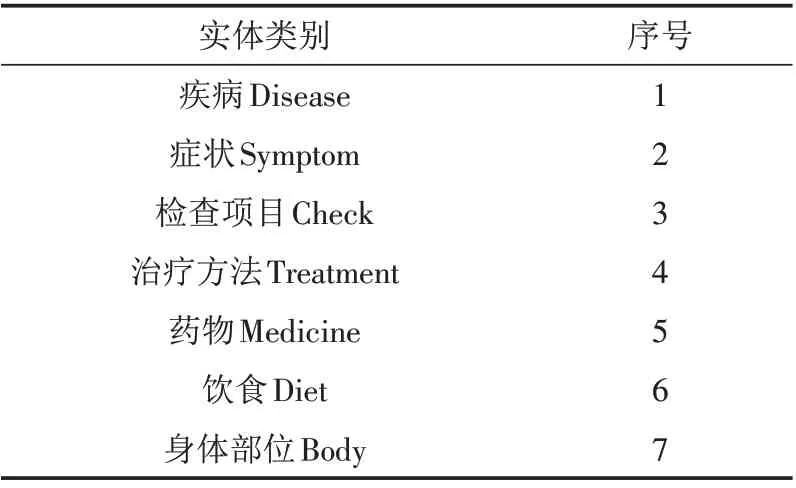
表1 互联网医疗知识的实体类别Tab.1 Entity categories of internet medical knowledge
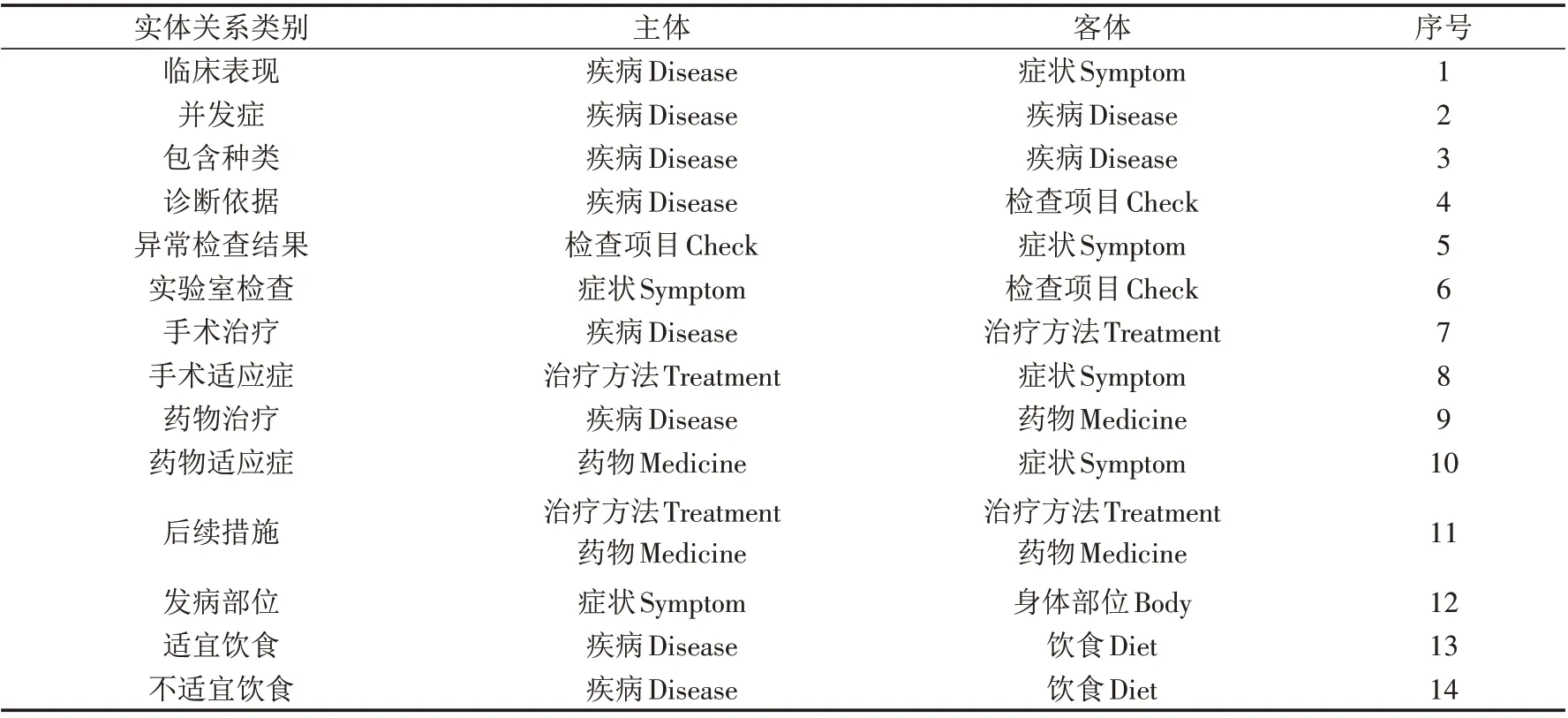
表2 互联网医疗知识的实体关系类别Tab.2 Entity relationship categories of internet medical knowledge
2.2.2 互联网医疗知识实体关系库的实体对齐 对本文2.2.1 小节构建的乳腺疾病实体关系库进行数据统计,如表3 所示. 分别采用MuGNN 模型、JAPE 模型和GCN-Align 模型对构建的两个乳腺疾病实体关系库进行实体对齐. 首先以比例seeds_ratio 抽取部分已对齐实体作为对齐种子,然后随机生成错误的对齐实体和关系三元组以更好地训练模型,最后随机选取70%的对齐实体作为训练集,其余30%的对齐实体作为测试集.

表3 乳腺疾病实体关系库的数据统计Tab.3 Data statistics of entity relationship databases of breast diseases
在Windows10平台下使用Python3.7.9语言在pytorch1.6.0深度学习框架下进行实体对齐. 三种实体对齐模型均采用相同的参数,模型的主要参数设置如表4所示.
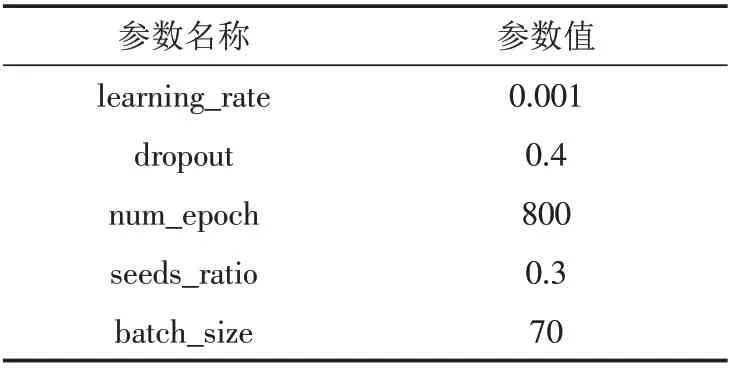
表4 实体对齐模型的参数设置Tab.4 Parameter setting of entity alignment model
采用前n项命中率Hits@n和平均倒数排名MRR 作为评价指标,计算公式如下:

式中:Hits@n表示目标实体排在前n位的比例,Hits@n的值越大表示命中率越高;MRR 表示目标实体排名倒数和的平均值,MRR 的值越大表示实体对齐效果越好;Ranki表示第i个目标实体在结果列表中的排位;I(⋅)代表指示函数,当输入为True时,I(⋅)=1,当输入为False时,I(⋅)=0;N表示目标实体数量.
根据式(9)和式(10)求得测试集在各模型上的Hits@1、Hits@10、Hits@50、MRR,结果如表5所示.

表5 测试集在各模型上的Hits@1、Hits@10、Hits@50和MRRTab.5 Hits@1,Hits@10,Hits@50 and MRR of the test set on each model
由表5 可知,测试集在MuGNN 模型上的Hits@n和MRR 的值均比在JAPE 模型和GCN-Align 模型上的大,其中测试集在MuGNN 模型上的Hits@1 的值分别比在JAPE 模型和在GCN-Align 模型上的高16.43%和8.51%. 以上结果表明,无论是以前n项命中率Hits@n作为评价指标,还是以平均倒数排名MRR作为评价指标,综合多种注意力机制和图卷积神经网络的MuGNN模型的实体对齐效果均优于JAPE模型和GCN-Align模型的实体对齐效果.
图5为通过MuGNN 模型得到的乳腺疾病各实体类别的Hits@n和MRR. 由图5可知,疾病Disease 和药物Medicine这两个实体类别的Hits@n和MRR均相对较低,分析原因可能是实验数据中这两个实体类别的数量相对较少,关系矩阵较为稀疏,给实体对齐效果带来了一定的负面影响.

图5 通过MuGNN模型得到的乳腺疾病各实体类别的Hits@n和MRRFig.5 Hits@n and MRR of entity categories of breast diseases obtained by MuGNN model
3 知识融合阶段
3.1 知识融合及知识图谱的可视化
知识融合是将多数据源中指向同一实体或者概念的描述融合起来的过程,是在实体对齐的基础上,通过冲突检测以及冲突消解对知识进行关联和合并,最终形成一个完整一致的知识库. 知识融合过程具体分为数据层融合和数据模式层融合两部分. 数据层融合多指实体间的知识融合;数据模式层融合则包括概念和属性的融合. 知识融合可丰富完善已有的语义信息、挖掘更多图谱知识、提高知识表示的性能,进而可以提供更优质的知识服务. 通过Neo4j图数据库对知识图谱进行可视化处理后,可将知识库中的实体和关系以图形化的方式展示出来,用户则可通过简单的查询语句来获得具体实体之间的关系,可增强知识库的可理解性.
3.2 互联网医疗知识实体关系库的知识融合及知识图谱的可视化
为了研究MuGNN 模型对互联网医疗知识融合的效果,对本文2.2 小节中构建的乳腺疾病实体关系库(已完成实体对齐)进行知识融合. 为了提升融合的准确率,在实体对齐的基础上加以人工校正,消除语义重复的实体及对应的关系三元组,实现多源知识的融合. 同时,使用Java语言将融合后得到的实体集和关系三元组集输入到Neo4j图数据库中,以实现乳腺疾病知识图谱的可视化.
图6a 是在Neo4j 图数据库中通过match 语句查询疾病“乳腺癌”所得到的症状,图6b是在Neo4j 图数据库中通过match语句查询检查项目“乳腺B超”所得到的疾病. 其中,不同颜色代表不同类别的实体,如红色代表“疾病Disease”,黄色代表“症状Symptom”,蓝色代表“检查项目Check”. 通过知识图谱的可视化,我们可以清晰简明地看到实体之间一对一以及一对多的联系.
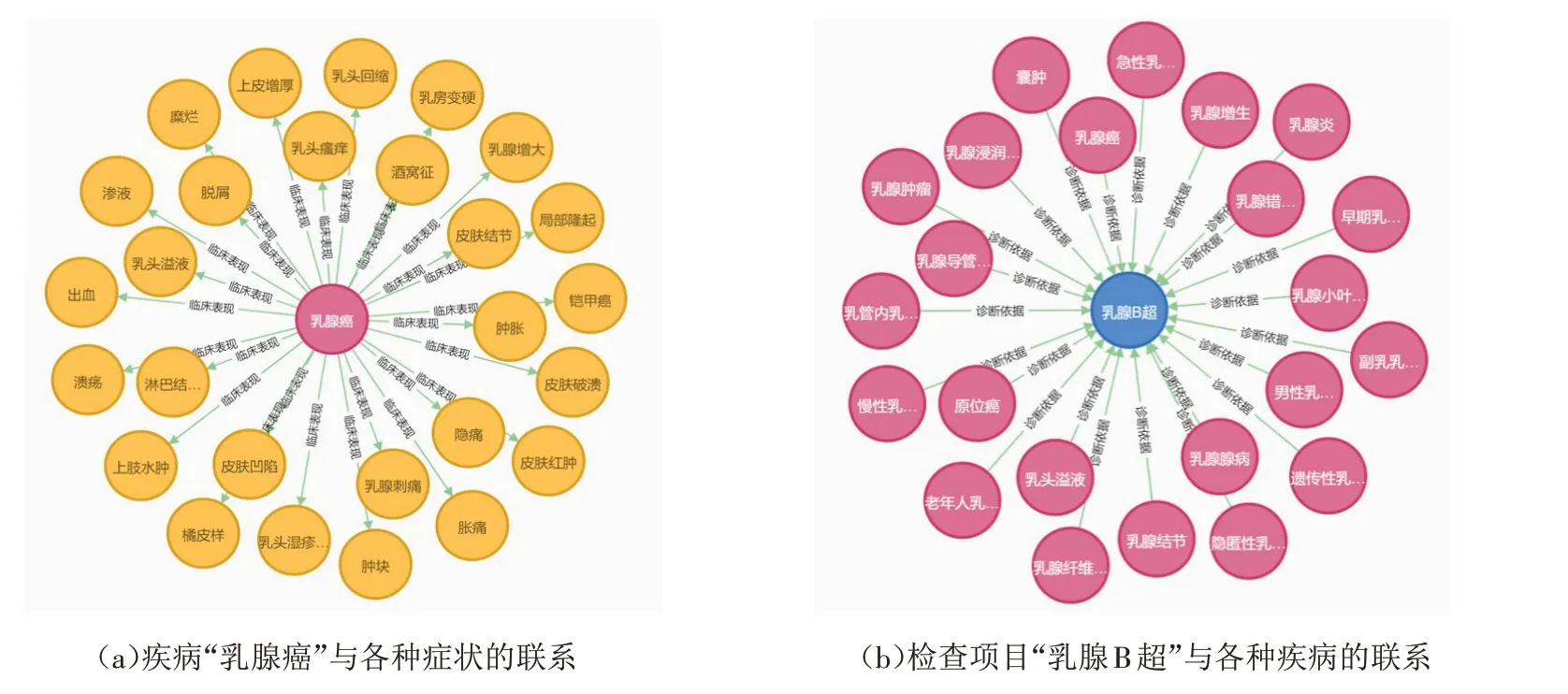
图6 乳腺疾病知识图谱可视化结果的示例Fig.6 Example of visualization results of breast disease knowledge map
通过Neo4j图数据库结构化存储乳腺疾病的实体及关系,不仅可以使用户高效快速地了解与乳腺疾病预防和饮食习惯等相关的知识,也可以使用户根据症状查询自己可能患有的疾病以及对应的检查方式,同时还可以为用户的初步自我诊断提供辅助手段.
4 结论
以乳腺疾病为例,首先构建了基于不同医疗网站的乳腺疾病实体关系库,然后利用MuGNN模型完成了实体对齐,同时与JAPE模型和GCN-Align模型的实体对齐效果进行了对比,最后通过Neo4j图数据库对融合后的互联网医疗知识图谱进行可视化处理,得出结论如下:
1)综合多种注意力机制和图卷积神经网络的MuGNN模型首先利用跨图注意力机制和GCN模型对图结构进行表示学习,然后利用GAT模型对实体关系进行赋权,最后将实体嵌入进行聚合后对齐. MuGNN模型不仅可以有效解决图结构的异质性问题,还可以为每个实体捕获到信息最丰富、最有判别力的邻居.2)无论是以前n项命中率Hits@n作为评价指标,还是以平均倒数排名MRR作为评价指标,综合多种注意力机制和图卷积神经网络的MuGNN 模型的实体对齐效果均优于JAPE 模型和GCN-Align 模型的实体对齐效果.3)通过MuGNN模型成功实现了基于不同医疗网站的乳腺疾病实体关系库的知识融合,并利用Neo4j图数据库对融合后的知识图谱进行了可视化处理. 知识图谱的可视化可将实体类别和实体关系以图形化的方式展示出来,通过简单的查询语句即可获得具体实体之间的关系,可增强知识库的可理解性,有助于提供更优质的知识服务.本研究虽然取得了一定的成果,但是也存在一些不足之处,如仅选取了与乳腺疾病有关的互联网医疗知识作为实验数据进行研究,其关系三元组不够多,存在一定的数据稀疏问题. 下一步研究可以考虑扩大疾病的选取范围,同时可以尝试利用词向量作为神经网络的初始矩阵,以进一步提高MuGNN模型的性能.
猜你喜欢
军事文摘(2022年24期)2022-12-30
小雪花·成长指南(2022年1期)2022-04-09
昆明医科大学学报(2022年2期)2022-03-29
昆明医科大学学报(2021年10期)2021-12-02
世界科学技术-中医药现代化(2021年7期)2021-11-04
健康之家(2021年19期)2021-05-23
少先队活动(2020年12期)2021-01-14
甘肃教育(2020年22期)2020-04-13
中国生殖健康(2019年5期)2019-01-06
第二课堂(课外活动版)(2016年2期)2016-10-21
