
基于Python-OpenCV图像处理技术的小麦不完善粒识别研究
2022-01-26 06:25张玉荣王强强祝方清
河南工业大学学报(自然科学版) 2021年6期
张玉荣,王强强,吴 琼,祝方清
1.河南工业大学 粮油食品学院,河南粮食作物协同创新中心,粮食储藏安全河南省协同创新中心,河南 郑州 450001
2.湖北大学知行学院,湖北 武汉 430011
小麦是我国的三大储备粮食之一,做好小麦品质的检测工作对于国家稳定以及经济的平稳发展具有重要意义[1]。目前,在小麦品质检验工作中,不完善粒的检测完全是由检验员感官检测,工作量大、费时费力且主观性强[2]。小麦不完善粒定义为受到损伤但尚有食用价值的籽粒,包括破损粒、生芽粒、虫蚀粒、病斑粒和霉变粒[3-8]。为克服人工检验的不足以及实现小麦不完善粒快速无损检测的要求,利用图像处理技术与深度学习的小麦不完善粒识别研究一直是粮食品质检测领域的研究热点[9]。国内研究中,曹婷翠等[10]将小麦粒以无粘连的方式整齐摆放在透明的载物板上进行图像采集和处理,建立图像数据库 WheatImage,设计并实现2个卷积层、2个池化层和1个全连接层的卷积神经网络模型的小麦不完善粒识别,较传统的机器识别方法识别率提高了15%,对于加入噪声干扰的图像,识别率也达到 90%以上,有效解决了传统小麦不完善粒识别中提取特征复杂等问题,但深度模型的结构浅、图像信息单一。张博[11]使用MATLAB、Python软件,对采集的整齐无粘连的小麦图像进行处理,通过对单籽粒图像进行旋转、翻转操作,扩容样本,建立传统 SVM 模型和经典CNN网络模型,识别结果表明,传统 SVM 模型和经典 CNN 模型对小麦籽粒的正确识别率分别为80.2%和90.6%,深度学习识别模型可有效用于小麦不完善粒分类识别中,但旋转与翻转的样本扩容操作在深度模型训练中就可实现,扩容操作导致图像数据冗余,模型学习效率低。国外研究中,Thomson等[12]对小麦籽粒进行逐粒扫描生成小麦三维图形图像,对小麦的完善粒和发芽粒进行分类识别,识别率分别为83%、89%。Neethirajan等[13]通过人工提取小麦籽粒的55个特征,使用BP人工神经网络进行分类识别,整体识别准确率达到 95%。此外对基于高光谱图像的机器视觉在小麦不完善粒识别中的应用进行了探索,光谱信息和图像特征相结合可有效提高小麦不完善粒的识别准确率[14-15]。这些研究方法处理的小麦图像大都是排列整齐、方向一致,虽然具有较高的识别准确率,但并不适合实际工作中小麦不完善粒在小麦籽粒堆中随机分布的检测识别。
OpenCV计算机视觉库作为常用的图像处理库,支持目前先进的图像处理技术且功能完善,采用Matlab、Python结合Visual Studio调用OpenCV函数库进行不同类型图像的滤波运算,可显著提高处理效率,降低编程设计成本[16-19]。Dominguez等[20]将ImageJ(用于生命科学的图像分析程序)和OpenCV计算机视觉库结合开发了一个可用于生物医学图像有效处理且可公开使用的IJ-OpenCV库;吴林辉等[21]以Java编程语言为基础,使用OpenCV图像技术定位车牌、分割车牌,接着应用Tensorflow成功识别车牌字符,但编程烦琐、识别单一、移植性差。Python语言较Visual Studio和Java语言语法简洁清晰,具有丰富和强大的库,能够快捷调用OpenCV 库中的函数进行实时图像处理[22]。李清洲等[23]使用Python-OpenCV函数库设计车牌识别系统,充分利用计算机视觉类库OpenCV对图像的处理功能,完成多种类型的汽车车牌识别。此外深度学习和支持向量机被广泛应用于图像处理和分类识别[24-26]。尚未见OpenCV函数库在小麦不完善粒中应用方面的研究。作者采用Python-OpenCV函数库对小麦籽粒方向、位置随机的原始图像进行处理,然后在Python环境下应用基于Keras框架的卷积深度模型做小麦不完善粒识别测试,可有效解决OpenCV函数库在C语言或Java语言环境下不易配置与调用的问题,同时保证了小麦不完善粒识别的准确性。
1 材料与装置
1.1 原料与试验平台
采用河南中储粮质量检测中心提供的不同储藏年限和不同品质的1 000余份小麦小样,从样品中挑出完善粒、生芽粒、破损粒、虫蚀粒和病霉粒(病斑粒和生霉粒)。
图像采集平台:自主设计;计算机:戴尔有限公司;48MP相机:小米有限公司;Anaconda3 2019.10、Python 3.7.4、PyCharm 2019.3.1、Numpy 1.16.5、Matplotlib 3.1.1、Pandas 0.25.1、Keras 2.4.4、Tensorflow_gpu 1.13.1软件。
1.2 图像采集
为克服传统图像采集时采集到的图像不能实时传输到计算机及时标记处理、镜头与载物板之间距离不易控制、光源不均、籽粒必须整齐摆放等问题,本研究设计开发了一个采集小麦图像的简易装置,如图1所示,黑色吸光布与载物盘相结合组成接料盘,黑色吸光布具有不反光、质地软、摩擦大等特点,既能使采集到的原始图像没有反光阴影干扰又能使从一定距离落下的小麦籽粒不易弹起和滚动,可避免籽粒黏结和区域籽粒聚集的现象,使小麦籽粒均匀、随机地散落在接料盘上。

注:1.计算机; 2.相机; 3.光源; 4.限位槽; 5.载物盘;6.黑色吸光布; 7.底座; 8.右挡光板;9.左挡光板。
图像采集时,将一个高10.0 mm、每个内孔直径为4.5 mm的蜂窝式自由落料器置于接料盘上方5.0 mm处,小麦籽粒通过落料器的不同孔下落到接料盘的黑色吸光布上,推到相机下方进行拍照,传输到计算机以JPG格式保存,完成小麦籽粒原始图像采集。
2 Python-OpenCV图像预处理
对采集到的小麦原始图像使用Python-OpenCV函数库进行图像预处理,步骤如图2所示。

图2 OpenCV图像处理的步骤
2.1 图像导入与图像增强
2.1.1 图像导入与格式转换
OpenCV图像处理时函数cv2.imread()用于读取图像文件,cv2.cvtColor()函数进行颜色空间转换得到RGB格式的小麦图像,之后对图像进行灰度化处理使图像特征增强,运行结果如图3所示。从图3可以看出,原始图像为RGB格式,灰度化格式图像(图3c)并不是通常意义上的黑白图像。

图3 图像格式转换结果
2.1.2 图像去噪
对小麦原始图像进行去噪处理,可去除图像中的噪声干扰,使小麦籽粒在视觉上容易与背景区分。通过OpenCV图像处理技术中常用的均值滤波cv2.blur()、高斯滤波cv2.GaussianBlur()、双边滤波cv2.bilateralFilter()、中值滤波cv2.medianBlur()[27]4种滤波器对小麦图像进行滤波操作,结果如图4所示。从图4可以看出,均值滤波(图4c)的处理效果最优。

图4 图像4种滤波结果
2.1.3 图像二值化
对小麦籽粒图像进行二值化处理,可将图像目标物与图像背景分类,以用于后续的分割识别处理。Otsu′s二值化是对图像进行一个双峰直方图计算,根据直方图自动计算出一个阈值数值,即双峰的中间值,函数cv2.THRESH_OTSU根据这个阈值数值对图像进行二值化处理,运行结果如图5所示,该直方图具有明显的双峰,图像的自动阈值数值计算结果为115。Otsu′s二值化的图像结果较简单,阈值二值化(阈值设置为80)图像结果更优。
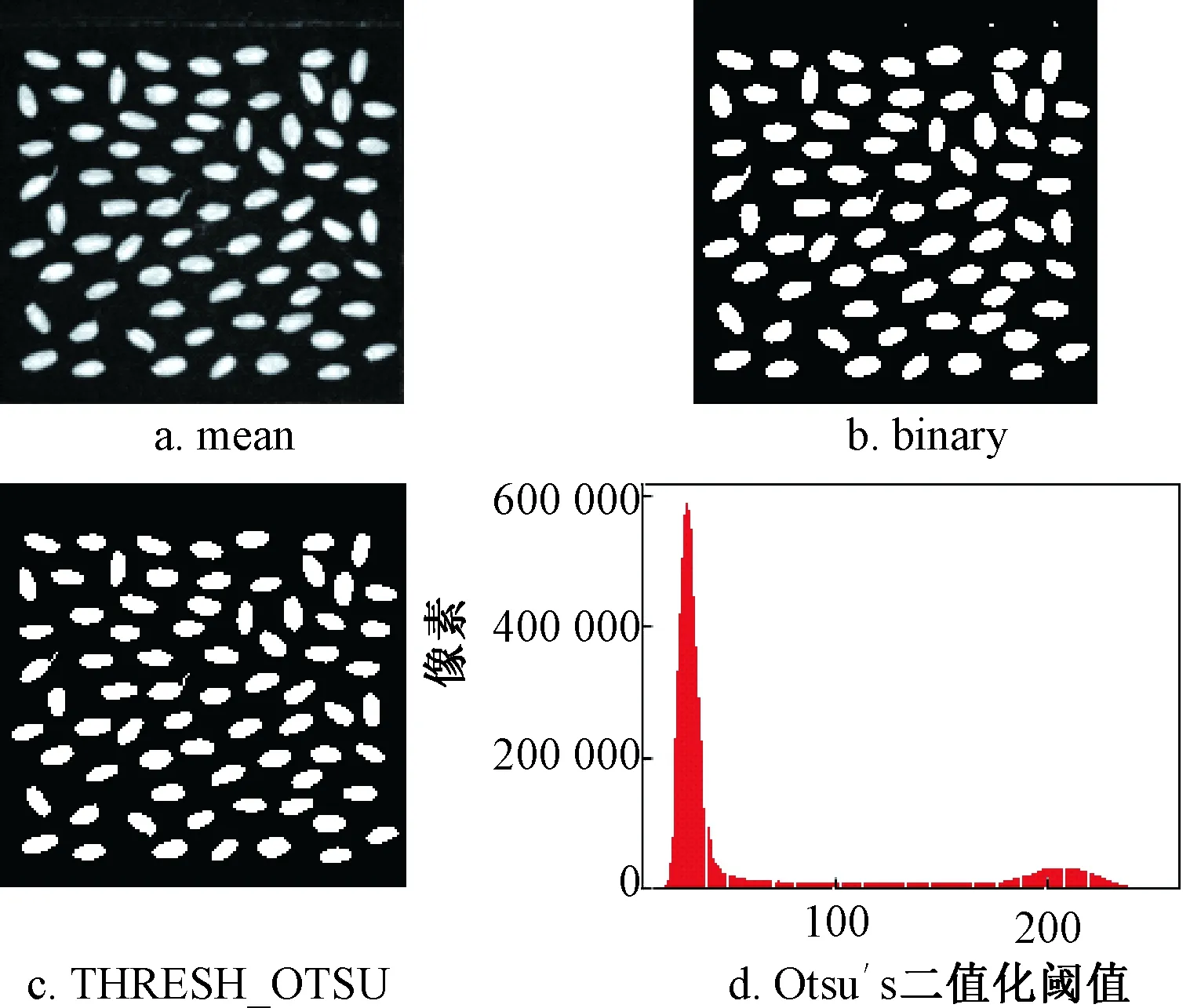
图5 去噪Otsu′s二值化
2.2 图像形态学处理
小麦籽粒原始图像经过灰度化处理、均值滤波去噪、图像二值化处理后,籽粒图像的许多细节信息得到了增强,对比度增加,但小麦籽粒图像上仍存在少量的噪声信息,如籽粒边缘上存在一定细小的毛刺、断裂或者边界图像信息模糊不清。运用图像形态学处理的图像细化、像素化和修剪毛刺等技术在图像后处理中进一步优化图像,成为图像增强的有力补充。OpenCV中膨胀、腐蚀、开运算以及闭运算的函数如表1所示。

表1 OpenCV形态学处理函数
去噪小麦籽粒二值图像形态学处理的结果如图6所示,经过均值滤波运算后的小麦二值化图像腐蚀操作后部分籽粒边缘信息被掩盖,膨胀操作后籽粒毛刺和黏结被放大,开闭运算处理后的图像、噪声得到了有效去除,人的视觉已可以清晰地观察到籽粒形态。
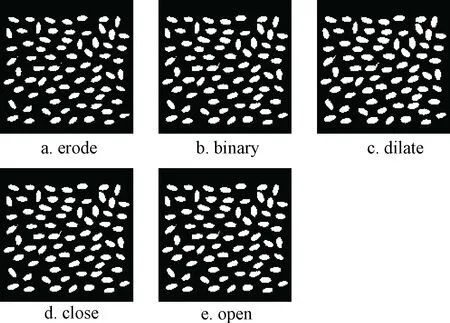
图6 去噪图像形态学处理
2.3 图像分割
用于图像分割的常用方法有2种:一种是基于卷积神经网络和图像处理技术的图像分割新方法,具有粗糙图像分割(CIS)算法和精细图像分割(FIS)算法[28];另一种是通过k-最近邻方法进行的k均值聚类数据分类,即k均值聚类图像分割[29]。本研究采用k均值聚类图像分割,首先对小麦完全预处理后的图像进行掩膜处理,然后对图像中的籽粒进行轮廓检测,将检测到的轮廓用一个矩形边框包起来,最后通过计算矩形方框的矩阵坐标将其剪裁保存下来完成图像的分割。
在Python-OpenCV图像处理中,掩膜的概念是从PCB版制作过程借鉴而来,通过掩膜操作,用选定的图像对需要处理的图像进行遮挡,来控制图像,使被分割处理的区域在剪裁时不被波及,从而保留完整的单籽粒信息。掩膜运算函数cv2.bitwise_and()是一种图像到图像的“与”关系,运算结果如图7所示。完成小麦图像掩膜操作后,使用cv2.findContours()函数对图像中的籽粒进行轮廓检测,经过参数试验,以生芽粒图像为例,在图像掩膜处理后得到的轮廓检测效果如图8所示,用cv2.minAreaRect()函数与cv2.boxPoints()函数对经过轮廓检测的图像进行最小矩形标记处理用于图像分割,结果如图9所示。

图7 掩膜操作

图8 轮廓检测

图9 矩形边框
完成矩形边框标记后,通过计算矩形方框的4个顶点矩阵坐标值,据此坐标将其剪裁保存下来完成图像的分割,矩形方框矩阵坐标计算方法如图10所示,以整幅图像像素点为基准建立坐标轴,将图像中每一个最小矩形方框的左上角顶点定义为坐标(x,y),右下角顶点坐标定义为(x+w,y+h),使用crop_img和cv2.imwrite()函数将每一个剪裁到的小麦籽粒保存到指定文件夹下。
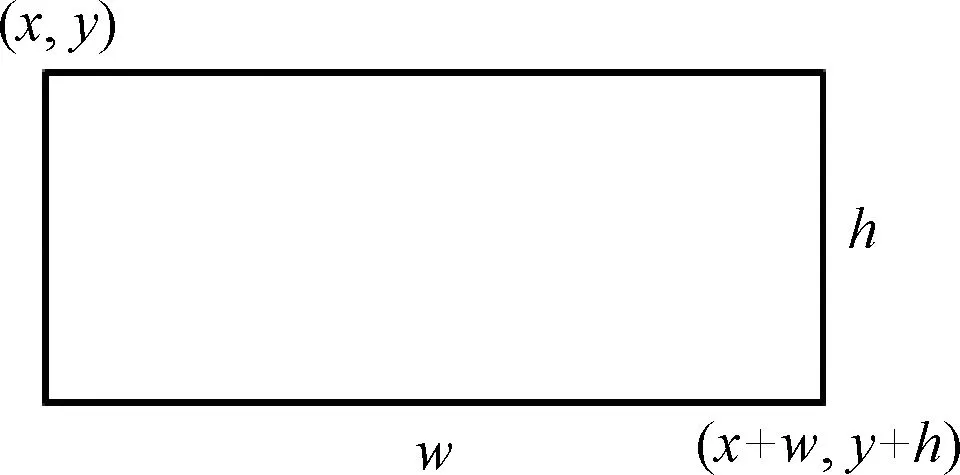
图10 像素矩阵坐标计算方法Fig.10 Pixel matrix coordinate calculation method
OpenCV函数库中,k均值聚类函数cv2.kmeans()与相关参数构成基于k均值聚类算法的图像分割,执行结果如图11a所示,由图11可知,原始图像中小麦籽粒方向、位置的随机性导致执行k均值聚类图像分割后得到的小麦单籽粒图像大小不一,采用OpenCV图像缩放函数cv2.resize()对单籽粒图像进行统一处理,结果如图11b所示,从图11可知,5类小麦籽粒图像外观特征得到了抽象化的增强,且与小麦籽粒原始形态一一映射。
3 基于VGG16模型的小麦不完善粒识别测试
3.1 基于Keras框架的VGG16模型
Keras是一个由Python语言编写的高度模块化的深度学习框架,使用Keras框架时,只需调用Keras已经封装好的函数,在程序中就可以查看神经网络模型结构,也可通过model.summary()函数输出神经网络模型的结构。Keras框架下常用的卷积神经网络有AlexNet、VGGNet、GoogLeNet和ResNet,AlexNet的模型结构含5个卷积层、3个池化层和3个全连接层,训练快,学习能力弱;VGGNet模型的经典代表是VGG16,其结构含13个卷积层、5个池化层和3个全连接层,训练慢,深度深,学习能力强;GoogLeNet和ResNet都是模块化的大规模卷积神经网络,其规模是AlexNet和VGG16的数十倍,一般分类识别问题不宜采用。综合比较4种神经网络模型的深度和参数,VGG16模型的识别精度和运行效率最佳,本研究采用VGG16神经网络模型,以(224,224,3)的RGB图像作为输入数据。
3.2 小麦籽粒图像数据库
采用直接读取图像数据的方法,建立小麦不完善粒图像数据库,数据库文件夹下设3个数据集:训练集、验证集、测试集,每一个数据集分别包含5类小麦不完善粒图像数据文件,3个数据集的图像数据各自独立、互不交叉。图像数据库数据如表2所示。

表2 图像数据库数据Table 2 Image database
3.3 训练与验证
训练与验证同时进行,小麦图像数据库梯度增加,由VGG16模型结构可知,输入的单个小麦图像数据均为(224,224,3),训练过程中的数据参数如表3所示。

表3 训练数据与参数Table 3 Training data and parameters
本研究采用的GPU内存为0.0/7.9GB,VGG16模型运行按93MB/img进行计算,batch_size的值为16、32、64,每个数据库参与迭代10、100、500次得出训练模型。data15迭代100次中训练与验证的精度和损失变化如图12所示。

图12 data15迭代100次中训练与验证的精度和损失变化
3.4 测试与分析
使用同一个测试集分别对4个训练模型进行测试,测试集(N)共5类,每类200个图像数据,data15和data18测试结果如表4和表5所示。由表4和表5可知,同一数据库不同迭代次数训练得到的预测模型测试结果随着迭代次数的增加而提高,data15迭代100次较10次的总体正确率提升了3.1%,data18迭代500次较100次的总体正确率提升了3.8%;不同数据库同一迭代次数训练得到的预测模型测试结果随着数据库图像数据增加而提高,迭代100次时,data18较data15的总体正确率提升了7.4%。分析表明,随着模型训练迭代次数的增加,训练参数通过去差留优逐渐优化,预测模型识别准确率提高;数据库图像数据增多,图像信息更全面,预测模型识别准确率提高。结果表明,Python-OpenCV图像处理得到的小麦图像分类识别会随着小麦图像数据与训练迭代次数的增加,训练参数不断优化,图像信息增多,预测模型的识别正确率提高,且不会因籽粒图像信息单一而出现模型训练过拟合现象。

表4 data15测试结果Table 4 Data15 test results

表5 data18测试结果Table 5 Data18 test results
4 结论
通过Python-OpenCV图像处理函数库对小麦图像进行处理后小麦籽粒图像外观特征得到了增强,对于深度学习而言,增加了小麦方向、位置随机分布以及resize化小麦单籽粒信息,模型训练时不会因图像数据信息单一而过拟合。整齐排列的小麦图像处理方式,虽然少量的数据就能快速训练出来识别度较高的分类检测模型,但不具备广泛的实用性。本研究结果表明,在小麦籽粒随机分布的情况下使用该图像处理技术处理完成的小麦籽粒图像,图像信息多变,深度模型训练会随着训练数据与迭代次数的增加,模型信息越来越广泛且不会训练过拟合,不完善粒的识别准确率也会逐步提高,以此种图像数据库初步训练到的神经网络模型对小麦不完善粒的总体识别准确率达到85.4%。本研究中的Python-OpenCV图像处理方法,既有效增加了小麦籽粒的空间随机性,又符合小麦不完善粒的实际场景检测识别,可为小麦不完善粒的智能、快速、无损检测设备的研发提供理论支撑。
猜你喜欢
今日农业(2022年16期)2022-11-09
华北农学报(2022年3期)2022-07-11
中国农学通报(2022年13期)2022-05-31
电脑知识与技术(2022年9期)2022-05-10
现代临床医学(2022年2期)2022-04-19
计算技术与自动化(2022年1期)2022-04-15
今日农业(2021年8期)2021-11-28
金桥(2021年10期)2021-11-05
今日农业(2021年13期)2021-08-14
作文·小学低年级(2021年10期)2021-01-25
