
多关键帧特征交互的人脸篡改视频检测
2022-01-26 13:10祝恺蔓徐文博卢伟赵险峰
中国图象图形学报 2022年1期
祝恺蔓,徐文博,卢伟*,赵险峰
1. 中山大学计算机学院, 广州 510006; 2. 中国科学院信息工程研究所信息安全国家重点实验室, 北京 100195;3. 中国科学院大学网络空间安全学院, 北京 100195
0 引 言
随着现代社交媒体的发展,各种各样的视频变得触手可得。“眼见为实”是一句广为人知的俗语,表示人们对世界的认知很大程度上依赖于视觉。然而随着图像编辑技术和视频篡改技术的发展,视觉信息也变得真假难辨。篡改技术在影响着人们对事物的判断的同时,更是引发了人们对个人隐私、社会稳定和国家安全的种种忧虑。经典的图像篡改技术包括复制粘贴、拼接等,对应的检测和定位技术(赖玥聪 等,2015;赵洁 等,2015)在研究者的共同努力下发展得较为成熟。视频上的篡改技术更为复杂,相较图像的篡改,也更难被人眼所识别。同时由于视频含有视觉与语音双重模态,能表达更丰富的信息,视频篡改引起的表达信息上的改变也较之图像篡改更大。传统的视频篡改技术包括插帧、删帧等,对此的检测技术包括利用光流一致性(Chao 等,2013)和多尺度内容相似度测量(Wei 等,2019)等。
随着人工智能和深度学习的发展,尤其是自编码器(Xu 等,2019)和生成对抗网络(Creswell 等,2018)的出现,使用生成手段进行伪造的篡改手段也随之出现。生成技术本身可被用于娱乐,如图像风格迁移等(Chen 等,2019),但其展现出的负面用途已然为网络安全敲响了警钟,其中,深度伪造“Deepfake”是近年兴起的具有极大威胁性的一类篡改。一般而言,深度伪造技术通过篡改图像或视频中人脸区域从而改变载体本身所表达的信息,篡改方式包括交换人脸图像、操控人脸动作以及篡改人脸表情和口型等。这一类的篡改技术需要使用大量的数据对模型进行训练,而在社交媒体发达的今天,获取大量的带有人脸的图像与视频数据是一件十分简单的事情,使得生成模型的训练也成为了一件容易的事情。此外,诸如FaceApp和ZAO一类商业篡改软件的存在与流通,使得普通人也能轻松进行深度伪造。
“Deepfake”一词最先源于2017年时在社交网站Reddit上一个名为“deepfakes”的用户。该用户使用了深度学习算法将明星的脸替换到了色情视频上,引起了人们的注意。此后,多个视频网站开始明确禁止此类换脸视频的流通。此类伪造视频对受害者的名誉权和个人隐私权带来了极大的危害。更值得担忧的是,如果将此类以换脸为代表的深度伪造手段应用在公众人物的公开发言的视频上,将会导致虚假新闻,引起社会恐慌;如果应用于政要人物的发言上,甚至会引起社会动乱和国家纷争,如Suwajanakorn等人(2017)就篡改了奥巴马的发言视频。虽然目前多国已经设立法律法规以遏制深度伪造内容的流通,但此类篡改视频依然在社交媒体上不断涌现。为了更好地消除此类篡改视频带来的个人安全及公众安全的威胁,广大研究者针对深度伪造视频的检测问题展开了一系列的研究。
在深度伪造中,人脸交换是目前公认危害最大,研究也最广泛的一类篡改方式,其使用目标图像的人脸替代原始视频或原始图像的人脸。为了更好地应对目前日新月异的篡改技术,研究者提出了许多数据集。根据篡改结果的视觉质量进行分类,可分为一代和二代两个阶段(Tolosana 等,2020)。一代的代表数据集有UADFV(Li 等,2018),DeepfakeTIMIT(Korshunov和Marcel,2018),Faceforensics(Rössler 等,2018),二代数据集包括DeepFakeDetection(Dufour 和Gully,2019),Celeb-DF(Li 等,2020b)等。在这些数据集的工作之上,研究者提出了不同的检测方案,从利用篡改图像中可见伪造痕迹,如异常瞳孔颜色(Matern 等,2019)、假脸视频中人物不眨眼的特性(Li 等,2018),到挖掘篡改图像中深层次的异常特征,包括篡改手段的指纹信息(Yu 等,2019)、色彩空间差异(Li 等,2020a)、频域差异(Durall 等,2019)以及更微观层面的信息(Afchar 等,2018)等。上述基于单帧的方法无法利用视频中原有的时间维度的信息,因此也有研究者通过捕捉帧间的时序关系和不一致性特征(Sabir 等,2019;Güera和Delp,2018;Ganiyusufoglu 等,2020;de Lima 等,2020),在多帧之间进行联合判断。但相对单帧的检测方法而言,结合时序信息或多帧的检测方法还处于研究的初级阶段。
另外,现有的模型往往只关注算法和模型上的性能,对样本的提取环节较为忽视。一般而言,帧级的算法由于本身只关注单帧上的性能,往往在提取样本的时候采取每秒取N帧的做法;而多帧上的算法大多数只关注连续帧上的性能,会选择从视频的图片序列中截取一定长度的连续帧片段。以上从视频中提取样本的方法存在3个问题:1)随机提取的小规模帧序列并不能充分代表视频所表达的信息;2)从视频中提取帧需要事先将视频流进行解码,解码的过程需要消耗一定的时间,不利于现实情况中实时检测;3)连续帧之间变化程度较小,存在较多的冗余信息,而差异化的互补信息较少。
在视频编码中,当图像内容变化较大,相关性减少时,为了能充分描述视频中的图像背景和运动主体,会插入独立编码的I帧,后续相邻相关的帧则参考I帧进行帧间编码从而减少冗余。因此,直接使用视频的关键帧为样本可以充分解决上述3个问题。关键帧即视频编码中的I帧,其本身包含了视频的总体变化信息,能充分代表视频;其获取的过程无需帧间解码,处理的数据量和处理时间大幅减少,有助于实际的高效检测。提取关键帧也可被认为是一种较大时间间隔的采样策略,如Liang等人(2020)指出,这种采样策略可以捕捉更丰富的视频信息,如多种面部表情和头部姿态。对真实视频而言,无论间隔,属于同一视频的帧之间存在内在的一致性信息;而对于篡改视频,相邻帧之间内容上本就相似,篡改手段可通过优化算法进一步减少篡改带来的不一致性,干扰在连续帧上的检测,但在大间隔帧上,不一致性信息相对保留得更多,使得真假视频的特征之间更有区分度。
为了解决对人脸交换篡改视频的高效检测问题,本文提出了一种基于视频多个编码关键帧上特征交互的检测框架。该框架利用关键帧的提取无需帧间解码的特性降低预处理的时间复杂度,并在此基础上,设计模型;结合人脸识别领域的指导性先验知识,提取紧密的人脸特征;进一步利用视频帧间的关联性,进行帧间的特征交互,并使用一个指示向量综合多帧的信息进行真假判决。实验中发现,在此框架下,关键帧之间的差异化信息能够相互补充,提高检测的性能。所提的基于关键帧的检测框架在DeepFakeDetecion数据集上达到了97.09%的准确率,在Deepfakes、FaceSwap和FaceShifter数据集(Rössler 等,2019)上均达到了96.97%以上的准确率,在Celeb-DF数据集上达到99.61%的准确率。在使用连续帧为输入的情况下,所提模型同样展现出了优良的性能,在Celeb-DF数据集上达到了98.64%的检测准确率,证明了无论是否使用关键帧为输入,所提模型均优于所对比的其他模型。此外,关于检测的消耗时间的实验进一步证明了本文所提的对人脸交换视频检测的框架的高效性。
1 相关工作
1.1 视频人脸深度伪造生成技术
随着视频人脸深度伪造生成技术的快速发展,出现了大量深度伪造生成的开源项目和商业软件。主流的深度伪造生成技术包括基于变分自编码器的深度伪造生成技术、基于DeepFake算法的深度伪造生成技术和基于Face2Face算法的深度伪造生成技术等。对视频人脸进行交换篡改的过程如图1所示。

图1 视频篡改流程图Fig.1 Flow chart of face swap manipulation on videos
VAE(variational autoencoder)是基于自编码器的生成式模型,包含编码器和解码器两个部分。编码器的作用是将输入数据映射为均值向量和标准差向量,然后利用这两个统计量生成隐含变量并加入高斯噪声。解码器的作用是对隐变量进行重建得到输入样本的重建样本,进而计算重建样本和原始样本的均方误差,对网络参数进行调整。由于VAE没有使用对抗网络,产生的图像分辨率低,视觉质量较差。
DeepFake是一类基于编解码网络、生成对抗网络的人脸交换篡改技术,该深度伪造技术结合人脸检测、视频编解码技术构建了一个端到端的人脸篡改模型。基于编解码网络的DeepFake深度伪造生成技术,通过训练两对编码器和解码器实现人脸交换,其中不同人脸的编码器共享权重参数进而学习到五官等人脸的通用特征,而解码器具有不同的权重参数以捕获人脸的差异化特征。将原始视频的人脸图像输入编码器并使用目标人脸图像训练的解码网络,便可得到篡改的人脸图像,进而通过背景融合、视频合成得到篡改视频。基于生成对抗网络的DeepFake深度伪造技术,利用对抗的方式提高人脸篡改视频的质量,可以生成较为逼真的深度伪造人脸篡改视频,对硬件设备的计算能力有较高的要求。
Face2Face是一种用于人脸表情转换的深度伪造生成技术,该技术将原始视频中人物的表情迁移到目标视频的人物中。其利用聚类的方法,从目标视频帧中选取与原始视频人物嘴形最为适配的视频帧来合成新目标脸,将合成的新目标脸替换目标视频中的人脸。该方法设计巧妙,具有很好的性能,目前已经可以进行实时的视频人脸表情迁移(Thies 等,2016)。
1.2 视频人脸篡改检测技术
为了应对深度伪造技术对公共安全的影响,科研工作者们提出了多种视频人脸篡改检测技术,其中以深度学习的方法为主(Bonettini等,2021;Guo等,2020)。将人脸视频篡改检测技术分为基于单帧的检测技术、基于片段的检测技术和视频级的检测技术。
基于单帧的人脸视频篡改检测技术通过捕捉视频每一帧的篡改痕迹,实现对视频单帧真实性的取证,部分工作会进而将帧上的预测结果进行平均来预测视频的真实性。这一类方法大多利用单帧的空域特征或频域特征进行篡改检测。Afchar等人(2018)提出了一种MesoNet方案,利用卷积神经网络(convolutional neural network,CNN)自动学习视频人脸的介观特征,进而训练分类器对真假视频单帧进行区分。Matern等人(2019)提出使用假脸中五官的不对称(如眼睛、牙齿等)的生物信息来区分视频的真假。Yang等人(2019a)提出利用局部估计的头部姿态与全局估计的头部姿态的不一致性,作为视频人脸篡改检测的依据,取得了较好的检测效果。Yang等人(2019b)观察发现生成模型缺乏全局约束会导致生成的五官存在配置异常,从而利用人脸标志点的坐标区分真假视频帧。李旭嵘和于鲲(2020)以EfficientNet作为主干网络设计了双流网络,将视频帧以RGB格式和噪声流作为输入,在空域和噪声域提取特征区分真假视频帧。这些方法利用单帧进行深度伪造视频检测,忽略了时序和帧之间的有效信息。
基于片段的视频人脸篡改检测技术将视频连续帧分段作为样本,利用帧间的不连续性特征进行检测。Li 等人(2018)提出使用眨眼特征对深度伪造视频进行检测,将帧序列作为输入,提取帧的眼部区域,输入长期循环卷积网络(long-term recurrent convolutional networks,LRCN)检测视频中人物是否存在眨眼状态,进而实现对视频序列的检测。Güera和Delp(2018)和Sabir等人(2019)利用CNN提取帧内特征,利用循环神经网络(recurrent neural networks,RNN)提取帧间人脸区域的不一致性,对帧序列的真伪进行判断。Chen 等人(2020)在进行人脸交换视频检测时也使用了类似的模型,但在空间特征提取后引入了篡改掩膜的学习来辅助决策。张怡暄等人(2020)同样使用了捕捉相邻帧之间差异的思想,首先尝试了局部二值模式和方向梯度直方图作为单帧特征检测框架,进而使用基于孪生网络的方法提取人脸细微特征进一步提升检测效果,基于相邻帧样本对的相似度均值计算视频的标签。Xu等人(2021)提出了一种基于集合的视频人脸篡改检测框架(set convolutional neural network,SCNN),将多个视频帧作为集合,利用骨干网络计算帧级特征,再通过集合降维汇集帧级特征,最终将帧级特征和集合级特征作为判别依据。Ganiyusufoglu等人(2020)将原来为行为识别设计的3D CNN网络用于深度伪造检测的任务中,并证实3D CNN的模型比其他时序模型有更好的泛化性能。为使得3D模型与深度伪造任务更适配,同时面向现实的应用部署,Liu等人(2021)设计了一个轻量化的3D CNN模型。
对一个完整的视频进行检测时,基于多帧片段的视频人脸篡改检测技术需要选取长度适中的帧序列,对视频提取多个样本分别检测,最后对结果进行综合。这类方法难以均衡检测性能和计算复杂度,常见的均值和最大值等综合方法也无法充分利用同一个视频的样本间的关联性。
视频级篡改检测技术通过从视频中提取有代表性的帧集合作为样本,从中学习联合特征对视频进行检测。Liang等人(2020)对视频的帧序列进行较大时间间隔的均匀采样,并利用2D卷积神经网络进行帧内的特征提取,然后使用1×1卷积提取帧间和视频级特征,进而综合利用3个不同层次的特征判断视频的真假。其提出提取较大间隔的离散帧集合能从视频中获取更有意义的场景,更适合深度伪造视频检测,但依然忽视了解码整体帧序列带来的时间和计算上的消耗。
1.3 视频编码技术
视频存储和传输的过程中,为了减少内容的冗余,经常对视频进行编码。为了保证不同视频编码产品的兼容性,国际上制定了通用的音视频编码标准,其中最具代表性的是国际电信联盟(International Telecommunication Union,ITU)制定的H.26x系列标准,包括H.261、H.262、H.263、H.264和H.265,以及动态影像专家组指定的MPEG-x系列标准,包括MPEG-1、MPEG-2、MPEG-3和MPEG-4。此外,我国也在2006年2月正式颁布《信息技术 先进音视频编码 第2部分:视频》(国家标准号GB/T 20090.2-2006,简称AVS标准),摆脱了国内多媒体产业受制于国外编码标准的状况。
本文实验阶段的数据集涉及到H.264和MPEG- 4两种视频编码标准。H.264标准中,将视频帧分为I帧、P帧和B帧。I帧是包含了完整内容的独立帧,在编码过程中只进行帧内编码,视频帧组的第1帧便是I帧,I帧可直接进行解码,因此又称为关键帧。P帧中记录的是当前帧与前一帧(I帧或P帧)的差异,借助运动估计进行帧间编码,又称为预测帧,解码过程需要参考前一个的I帧或P帧。B帧中记录的是本帧与前后帧的差异,又称为双向预测编码帧,解码B帧需要参考前后的I帧或P帧(章毓晋,2012)。MPEG- 4标准吸纳了H.264标准,实现了低比特率下的多媒体通信。
以往的检测方法通常先将视频进行解码,得到完整的视频帧序列再进行取证。本文所提检测框架为了使得检测过程更高效,直接抽取关键帧作为检测样本,对视频真伪进行判定,减少了视频流解码的计算量,在保证检测准确率的基础上加快了检测速度。
2 本文算法
本文所提出的人脸交换篡改视频检测框架中包括关键帧提取与检测模型两部分,模型中含有人脸空间特征提取以及帧间特征交互两个模块。该检测框架旨在不完全解码视频流的情况下,使用模型提取并融合多个关键帧的人脸特征信息,实现高效的对人脸交换篡改视频的检测。
2.1 关键帧与人脸区域提取
在获取视频流数据后,解析器会对码流信息进行初步的解析,并将数据划分成包结构,此时可以得知每一个数据包中对应的帧是否为关键帧。给予视频流的上下文一个“跳过非关键帧”的用户指令后,在解码阶段,解码器将会丢弃所有非关键帧的包,完成解码后只会输出关键帧的图像。
由于只使用人脸区域的图像,在提取关键帧后,使用人脸检测器MTCNN(multitask cascaded convolutional neural networks)(Zhang 等,2016)进行人脸检测。为模拟真实情况下检测时对待测样本的存储,确定帧上所有可能的人脸位置后提取人脸区域图像,其中保留宽度为80的边缘背景区域,使得保存的图像本身在数据库中具有一定的区分度。在使用样本时,再次使用MTCNN对上一步的获取的图像进行人脸定位,不同的是这次仅提取紧密的人脸区域,并因后续检测模型要求放缩至160×160像素。通过二次检测可以避免检测器在第1次对非人脸区域的误检并使得不同样本间人脸提取区域相对原图像范围更一致。总体的样本提取流程如图2所示。
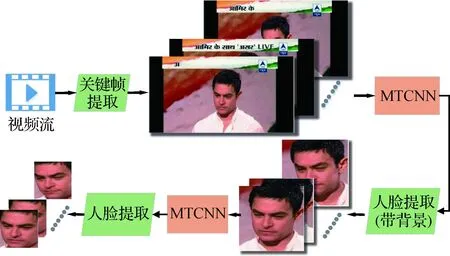
图2 样本提取流程图Fig.2 Flow chart of sample extraction
2.2 检测模型
该检测模型包括人脸空间特征提取和多帧间特征交互两部分,首先通过神经网络将人脸映射到高维特征空间,然后利用基于自注意力机制的编码单元使特征之间相互学习,并引入指示向量获取全局信息,最终对样本进行判决。
2.2.1 人脸空间特征提取
现有的人脸交换篡改技术无法完美交换人脸,比如在自编码器的交换模型中,原始视频人脸图像输入到目标人脸的解码器中,指导目标人脸五官情态变化的同时不可避免引入原始视频人脸图像自身的信息。如图3所示,交换结果的面部轮廓、鼻子形状与原始视频人脸的更为接近,而其他则更符合目标人脸的特征。因而在人脸聚类嵌入空间中,交换结果人脸与目标人脸之间的距离应当大于与原始图像自身的距离,同时篡改手段带来的内在伪造痕迹为篡改人脸的嵌入特征带来异常信息,使得篡改人脸的特征分布与真实人脸的特征分布不一致。

图3 真实人脸图像与交换结果示例图Fig.3 An example of real faces and their swap result((a)target face;(b) source image face;(c)swap result)
使用网络结构Inception-ResNet-v1(Szegedy 等,2016)对每个关键帧的人脸在特征空间中生成512维的特征向量。该网络在Inception的结构上进行了简化,并引入了残差结构等加快了网络的训练,在一系列的卷积操作后通过均值池化与线性层生成512维的向量。Kumar等人(2020)在图像上的人脸篡改检测中尝试了将人脸识别领域的经典系统FaceNet(Schroff 等,2015)的模型与训练方法,首次与人脸识别领域关联。受其启发,本文使用在大型人脸数据库通过FaceNet方法预训练的模型参数对特征提取网络进行初始化,在训练中进行端到端的更新。后续的消融实验表明,引入人脸识别领域的先验知识对网络的更新有很强的指导作用。
使用预训练参数对模型进行初始化在图像或视频的分类任务中较为常见,在人脸篡改检测的部分的工作中也延续这种做法,主要使用了在ImageNet(Russakovsky等,2015)上进行分类任务上的预训练参数,如Rössler等人(2019)使用的XceptionNet模型、Ganiyusufoglu等人(2020)使用的EfficentNet-B3模型和I3D-RGB模型、Chen等人(2020)所设计模型的主干网络等。Ganiyusufoglu等人(2020)还对R3D-18模型使用了在Kinetics-400(Carreira和Zisserman,2017)数据集上进行行为识别任务的预训练参数进行初始化。然而ImageNet和Kinetics- 400包含大量人脸无关的信息,而人脸识别任务中的预训练参数能对人脸篡改检测任务提供人脸特征信息相关的指导,并使网络更早关注图像中的人脸成分而非其他细节。
2.2.2 帧间特征交互
本文旨在进行视频级的人脸交换篡改的检测,在提取了关键帧并得到特征向量后,得到了离散的序列信息。通过使用自注意力机制(Vaswani等,2017),使每个关键帧之间都可以相互关注,学习到有意义的内在共通信息,从而使得视频的区分性信息可以充分聚合。此外,在现实情境下,视频帧序列的长度不稳定,许多基于3D卷积的模型只能处理固定长度的序列,这样会造成信息的损失或干扰,同时检测效率较低,而基于自注意力机制的结构可以处理任意长度的帧序列,并且可以通过并行化的方式实现,效率较高,更适合现实的检测。本文模型通过多层的基于自注意力机制的学习和线性变换进行一步提取篡改伪造留下的特殊特征信息。计算的总体流程如下:
1)将一个有N个有效关键帧并经过特征提取的样本设为X={X1,…,XN},并引入维度相同的可学习全局分类指示向量X0拼接在样本特征X1之前,即拼接后的样本特征集为X′={X0,X1,…,XN};
2)对特征经过LayerNorm归一化后使用多头自注意力机制(multi-head self-attention mechanism)进行特征的更新。Xi通过3个不同的带偏置的可学习线性变换WQ,WK,WV∈Rd′×d生成3个新特征:Query向量Qi=WQXi,Key向量Ki=WKXi,Value向量Vi=WVXi,其中d表示Xi向量的维度数目,d′表示所生成的新特征的维度数目。每个帧上的特征都生成如上3个向量,假设与Xi进行交互的另一帧为Xj,计算Xj对于Xi的相关性系数
(1)
(2)
(3)
自注意力机制的计算如图4所示,图中虚线箭头表示来自其他帧的特征经过线性变换后与关于第i帧的注意力系数点乘后的计算结果,⊕表示向量加法,⊗表示向量乘法。

图4 自注意力机制计算示意图Fig.4 Self-attention mechanism calculation schematic diagram

(4)
3)对自注意力机制的计算结果进一步经过线性变换和非线性变换,得到最终对Xi的更新向量X′i。其中,每一部分之间都使用残差连接和归一化加速网络的收敛。一层编码单元的整体计算流程如图5所示(其中GELU为激活函数)。
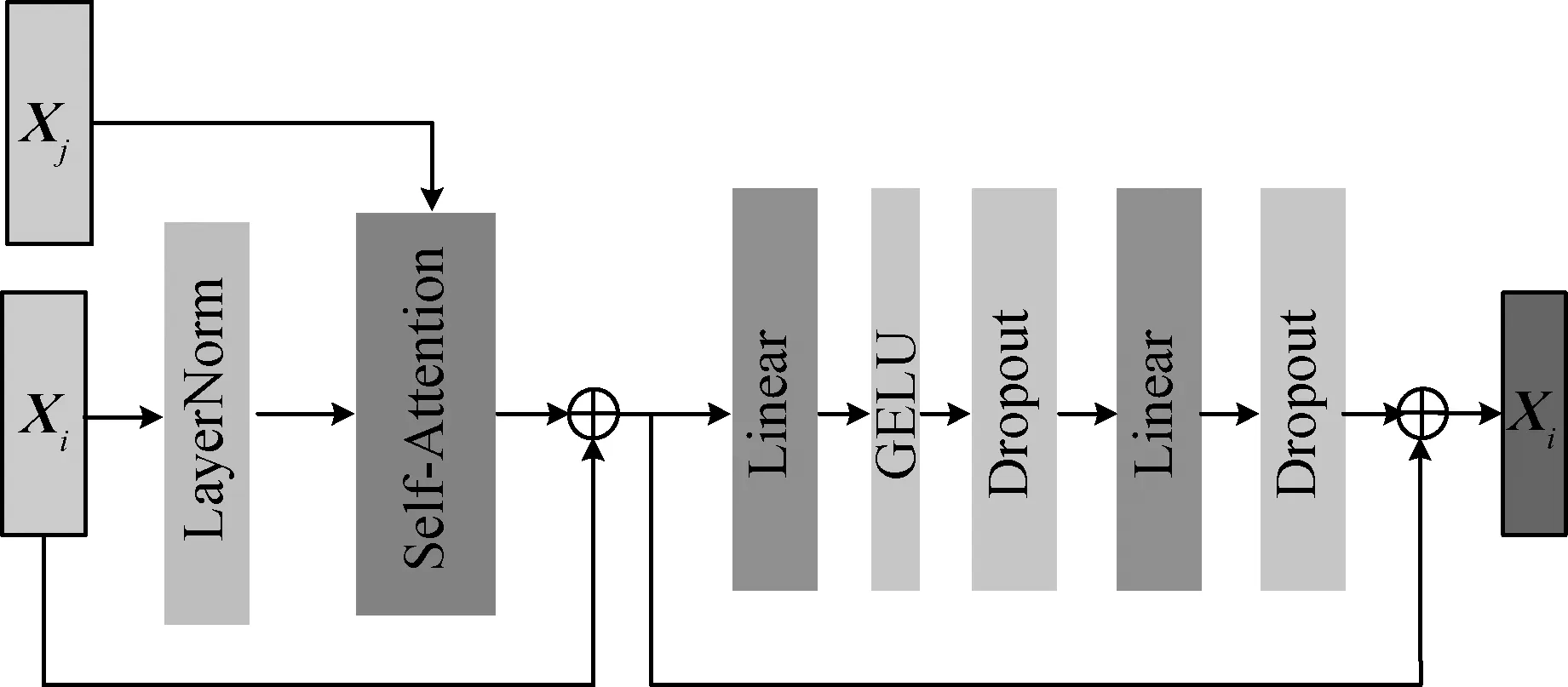
图5 一层编码单元计算流程示意图Fig.5 Flow diagram of an attention encoder
4)上述两步骤为使用一层编码单元进行特征更新,实际应用中使用多层上述结构以提取更深层次的特征信息,并最终通过指示向量经过线性变换获取检测结果。
2.3 整体框架
本文人脸交换篡改视频的检测框架如图6所示(其中CLS为可学习的全局分类指示向量)。在获取关键帧并提取有效的人脸图像作为样本后,使用所提的层级检测模型进行处理和判别。先从视频流中提取所需要数量的关键帧,对完整图像使用MTCNN确定所有可能的人脸位置,并提取带有一定背景信息的人脸图像;再次使用MTCNN检测人脸并提取紧密的人脸区域;检测模型首先使用卷积神经网络对每一帧的人脸进行特征提取,将人脸图像映射到统一的特征空间,然后使用多层的基于自注意力机制的编码单元每一帧特征之间能够相互学习与更新,在线性与非线性变换的帮助下,进一步提取篡改带来的异常信息;在此过程中,使用一个额外的可学习的指示向量获取全局信息,并最终通过该指示向量对样本进行判决;最后通过最小化交叉熵损失函数来指导网络进行端到端的参数更新。
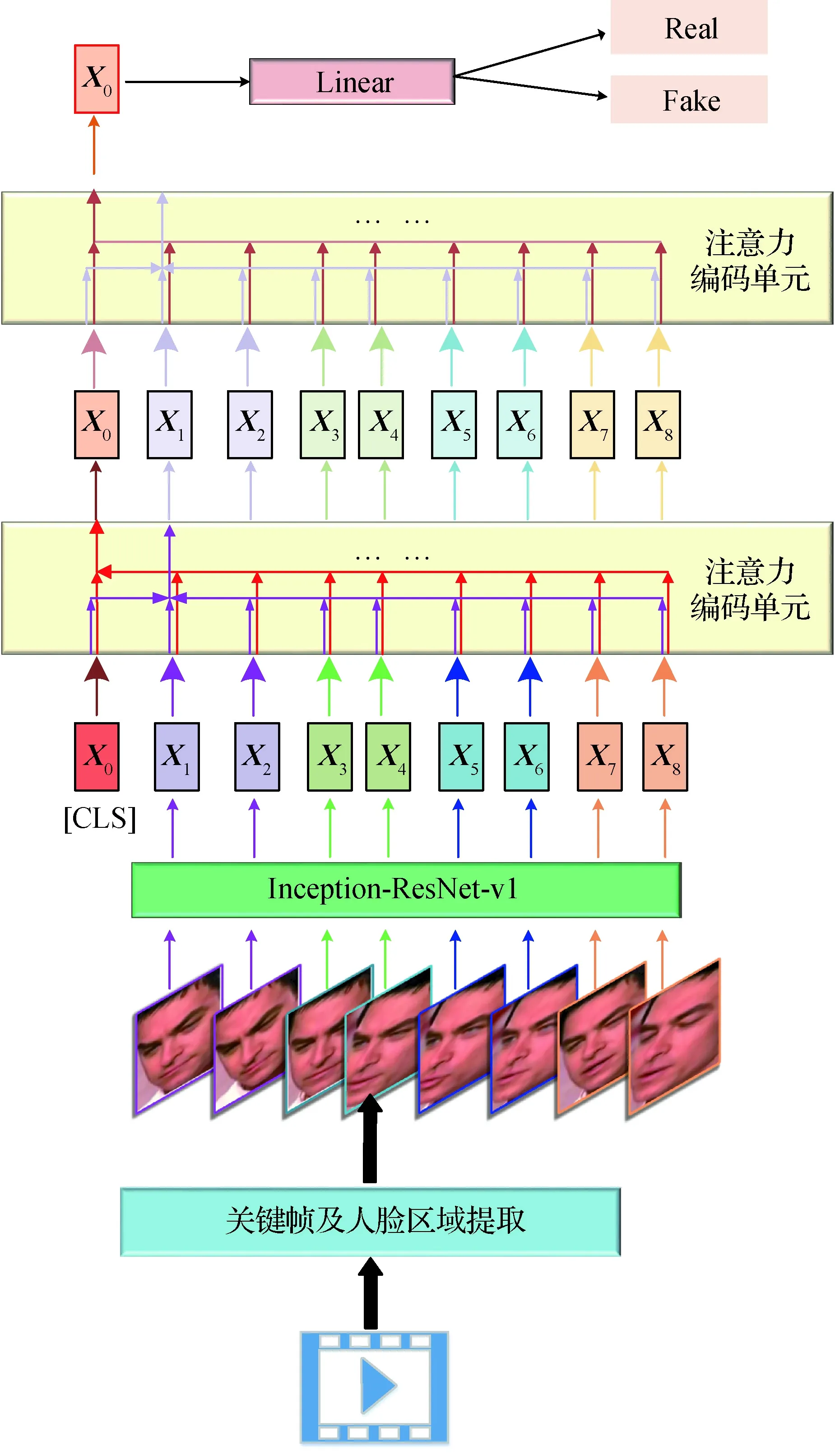
图6 本文所提人脸交换篡改检测框架流程图Fig.6 Flow diagram of the proposed face swap manipulated video detection framework
3 实验及分析
3.1 数据集及实验细节
使用Faceforensics++(Rössler 等,2019)、DeepfakeDetection(Dufour 和Gully,2019)和Celeb-DF(Li 等,2020b)数据集进行对比实验。
Faceforensics++(简称FF++)使用H.264标准进行编码,目前包含了1 000个来源于YouTube的真实视频和在其之上使用5种人脸篡改方法生成的各1 000个伪造视频。该数据集为每个视频提供了3种压缩级别:C0无压缩、C23低压缩、C40高压缩,其中C23的压缩结果几乎无损,在社交媒体上更具有代表性。本文只关注人脸交换篡改视频的检测,因此只使用其中低压缩版本的由DeepFakes、FaceSwap和FaceShifter这3种换脸篡改手段生成的视频。
DeepFakeDetection(简称DFD)包含来源于28个演员在16种不同场景下的363个原始视频和从中生成的3 068个人脸交换视频,同样使用H.264标准进行编码,并提供3种压缩率版本。
Celeb-DF包含590个从YouTube获取的真实视频和在其上使用改进的DeepFake方法生成的5 639个人脸交换的伪造视频以及另外搜集的300个从YouTube上获取的真实视频,均以MPEG4.0格式编码。
使用Pytorch库搭建模型,利用Adam优化器通过批梯度下降法更新网络参数,初始学习率为0.000 1,并随着训练轮次增加而衰减。检测模型使用FaceNet下在“VGGFace2”(Cao 等,2018)数据集上训练好的模型参数对空间特征提取网络Inception-ResNet-v1进行初始化,使用2层各16个自注意力机制的编码单元。实验的评估指标包括:代表篡改视频的识别准确率TPR(true positive rate),代表真实视频的识别准确率TNR(true negative rate),代表在整体数据集上的准确率Acc(accuracy),计算为
(5)
式中,TP表示标签为篡改并且被检测为篡改的样本的数量,TN表示标签为真实并且检测为真实的样本的数量,FP表示标签为真实但被检测为篡改的样本的数量,FN表示标签为篡改但被检测为真实的样本的数量。
3.2 对比实验及分析
将本文检测框架在以上3个数据库的5个数据集下进行单独实验。

从表1中可以看出检测框架在5个数据集下达到96.79%以上的准确率,在Celeb-DF数据集上效果最好,8帧达到98.64%的准确率,而在Deepfakes上达到了97.50%,在FaceSwap上达到了97.14%,直观原因是FF++上训练集的样本数的不足以及关键帧数较少。在FaceShifter上由于篡改手段的挑战性,性能稍微下降,仅达到96.79%。在DFD上由于视频图像的环境条件更为复杂,为检测框架带来了更大的挑战,仅达到了97.09%的准确率。一般而言,使用注意力机制的网络需要较大规模的训练数据来充分捕捉与学习样本的成分之间的关系。对于本文所提模型,Celeb-DF的数据量能较好满足训练需求。另外,关键帧的数目也对检测效果有着很大影响,后续会进一步对帧数的影响进行分析。

表1 本文检测框架在不同数据集上的检测结果Table 1 Detection result of the proposed Deepfake detection framework on different datasets /%
表2将使用16个关键帧为输入的本文检测模型与以下几个基准模型在Celeb-DF数据集上进行比较:C3D(convolutional 3D)(Tran 等,2015)、I3D(inflated 3D convnet)(Carreira 和Zisserman,2017)、R3D(3D ResNets)(Tran 等,2018)原为动作识别任务所设计,后来被Ganiyusufoglu 等人(2020)与de Lima 等人(2020)用于人脸篡改视频的检测任务中,通过学习空间与时间的联合特征捕捉假视频的连续帧中由逐帧篡改带来的时间上不一致的伪造特征。R3D和C3D使用16个关键帧,其余设置与所提框架一致。I3D模型本身结构需要使用64个关键帧并将输入的图像大小调整为224×224像素,显然,使用I3D需要进行大量的填充操作。

表2 不同模型在Celeb-DF上的检测结果(关键帧)Table 2 Result of detection on Celeb-DF with different models using key frames /%
L3D是Liu等人(2021)为深度伪造检测所提出的轻量化3D卷积模型,利用了3D卷积可以很好地提取时空联合特征的特性;使用了通道变换模块,在学习更深度特征的同时,尽可能地减少了参数量。按其网络要求,每个视频使用4帧作为输入样本。
Conv-LSTM是在(Sabir 等,2019)所提的人脸篡改视频检测模型上进行修改的模型。本文去掉了脸部对齐等预处理操作,同样使用ResNet50提取空间特征,但将后续处理时序信息的RNN的结构替换为一层双向的长短期记忆网络(long short term memory,LSTM),将最后一个时间步的结果经过线性层进行预测。Güera和Delp(2018)也有使用类似的架构,但空间上的特征提取网络有所不同。该方案同样使用16个关键帧进行实验。
此外,本文也在输入为连续帧的情况下对模型的检测能力进行了验证,结果如表3所示。为使得在输入不同的情况下的检测结果具有可比性,只使用视频最初的前N个连续帧(N=4、6、64)作为样本,使得表2和表3的实验样本数相同。
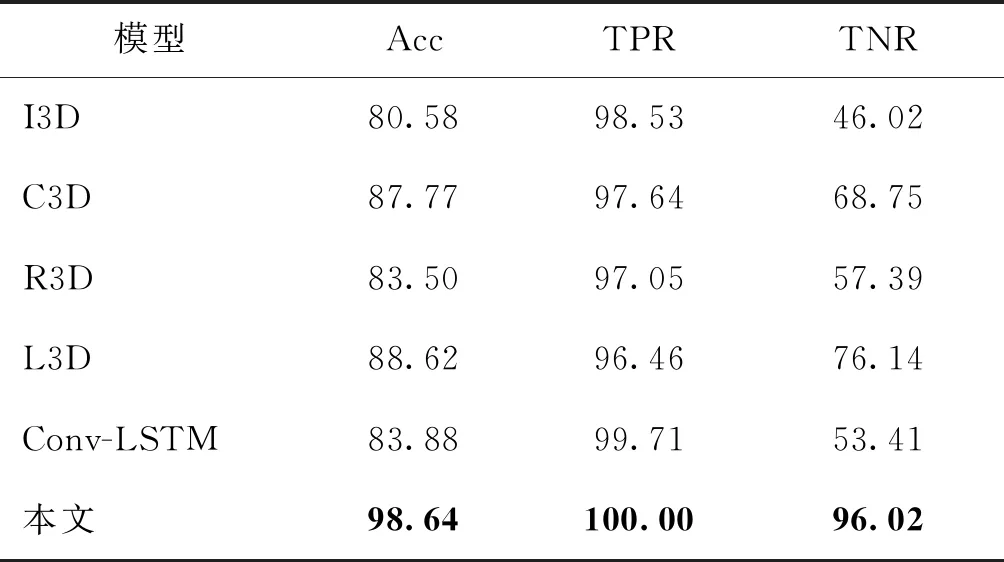
表3 不同模型在Celeb-DF上的检测结果(连续帧)Table 3 Result of detection on Celeb-DF with different models using consecutive frames /%
从以上实验可以发现,本文检测模型在连续帧和关键帧两种不同输入的情况下均能很好地识别人脸交换视频,TPR都能达到100%,同时TNR在连续帧的输入下达到了96.02%,比C3D高出了27.27%,比L3D高出了19.88%,比Conv-LSTM高出了42.61%;在关键帧的输入下TNR则达到了98.86%,比R3D高出了48.29%,比L3D高出了30.68%,比Conv-LSTM高出了1.73%;均是几个模型中的最优值,这说明模型很好地提取了交换篡改的人脸图像相较于真实人脸在嵌入空间中的异常特征信息,自注意力机制也很好地聚合了视频的多个帧间的区分性信息。
Conv-LSTM和本文所提模型同样是层级模型,其通过门控机制进行序列化的信息流动,每一帧的特征只能学习到上一帧或下一帧的信息,判决依赖于最后一帧的信息;而本文模型通过自注意力的机制使得每一帧都可以和其他所有帧进行交互关注,从而学习到更丰富的信息,另有指示向量关注全局信息进行判决,最终使得模型对真实图像有着更好的识别能力。
基于3D卷积的模型均显示出较弱的检测能力,且受样本不均衡的影响更大。在一般使用3D卷积的工作中,一个视频会提取多个样本从而增加训练集的大小,而在本实验中训练样本相对其训练需要而言是不足的。对于3D卷积的模型而言,其原为连续帧的任务所设计,因而更倾向于从相邻相似的帧中捕捉类间不同的信息,相邻帧的一致性信息对其在真实视频的识别的影响较大,因而其在关键帧为输入的情形下的检测能力会被削弱。
另外,实验发现,对于层级模型而言,具有较大间隔的关键帧能够提供模型更丰富的信息,从而提升模型的检测性能,这对于识别真实视频更为重要,与前文的假设一致。除较大间隔帧上人脸姿态等更多变,使得差异化信息较多外,对于真实视频,无论连续帧还是关键帧,其图像内部存在着相对稳定的特征;而对篡改视频而言,篡改中的一些优化方法可导致相邻帧之间的一致性有所增强,因而使用连续帧进行检测时,篡改样本与真实样本之间的区分度减弱,对真实视频的检测带来了不利的影响。然而,篡改手段无法保持较大间隔的帧之间的一致性,使得在关键帧上进行特征提取,篡改样本和真实样本有较大的区分度。此外,与基于循环神经网络的模型相比,自注意力机制很好地保留了长期的信息,更有利于长序列下的篡改检测。
表2和表3的实验表明了本文所提检测框架——以关键帧为输入,使用帧上特征提取与基于自注意力机制进行帧间交互的模型能在人脸篡改视频检测的任务中能达到优越的性能。
在表4中,比较了不同模型在两种输入情形下对人脸交换篡改视频上进行完整的检测流程所需要的平均时间消耗。需要注意的是,为得到可靠的检测结果,在使用连续帧的实验中(除所提模型),需要将视频帧序列划分成不重叠的片段作为样本,并对每个片段的检测结果进行平均,得到最终视频的检测结果;在使用关键帧的实验中,层级模型使用所有可提取的关键帧,直接得到视频的检测结果,对于其他模型依然需要划分片段。输入结构和网络设置与前面相同,整体检测流程包括加载模型和解码视频流等环节,使用1个GPU加速测试。与现实场景类似,测试环境存在干扰,同时考虑视频长度等因素,使用平均消耗时间(s)作为评价指标。

表4 使用不同模型与输入对待测视频检测的时间消耗Table 4 Average time consumption of detecting deepfake videos with different models and inputs /s
从表4的实验中可以发现,对所有模型,使用连续帧为输入的耗时远多于使用关键帧为输入的耗时。网络规模和构造也会对耗时产生影响,使用基于自注意力机制的并行计算方式可以大幅减少测试的耗时。本文检测框架在保持优越的检测性能的同时,耗时较少,证实了检测框架的高效性。
3.3 消融实验及分析
从本文模型的设计上可以看出,该模型可以对拥有任意数目关键帧的视频进行检测。在表5中,在Celeb-DF数据集上测试了使用不同数目关键帧对检测效果的影响,可以发现随着使用帧数的增加,模型的检测性能是在逐渐提升的。
面对一个较大的数据库,使用2帧显然是不能完全捕捉两类视频间的有区分度的信息,检测结果受数据集样本不平衡的影响更大,导致对真实视频的判别能力不足;到达10帧时,视频提供的信息较为丰富,模型对真假视频都有足够的判别能力;使用16帧以上,模型对篡改视频能够基本完美识别,TPR达到了100%;在24帧的时候,模型对真实视频的判别能力达到了最佳,TNR为99.43%,准确率达到99.81%;而当32帧的时候,存在信息冗余的情况,干扰了模型对真实视频的帧间信息的学习与提取,性能有所下降。
由于现实情况中,待测视频所拥有的关键帧的数目不一定能达模型训练时的要求,因此在表6中进行了跨关键帧数目的实验,在使用一定数目的关键帧的训练集上进行训练,并在使用2、4、8、10、16、24、32个关键帧的测试集上分别进行测试。

表5 在Celeb-DF上使用不同数目关键帧的检测结果Table 5 Result of detection on Celeb-DF with different number of key frames using proposed framework /%
从表6中可以发现,当使用相对不足的帧数(2、4)进行训练时,使用稍多的关键帧数(4、8)进行测试反而能得到更好的结果,说明模型在帧数较少的情况下依然良好地捕捉了帧间的关联性,但当继续增加关键帧的数目时,所提供的信息量超出了模型的处理能力,因而性能有着较大的下降;在使用8帧以上进行训练时,模型基本学到了帧间的关系,在待测样本拥有更多的关键帧的情况下能充分利用关键帧所提供的丰富信息,达到更高的准确率,尤其在训练集使用16帧的时候,模型在不同测试帧数的情况下均达到了良好的检测结果,且性能更稳定,测试帧数为8帧以上的准确率为99.61%。值得注意的是,对于待测视频关键帧数比训练帧数更少的情况,模型会认为信息量相对不足而导致性能不佳,测试时相较于训练时使用的帧数越少,其性能下降越大。总体而言,使用16帧训练的模型能够较为稳定地发挥模型对视频篡改的检测能力。

表6 在Celeb-DF上跨关键帧数的检测结果Table 6 Detection results of cross key frames number on Celeb-DF /%
在实验中,检测模型中的单帧特征提取网络使用了其在人脸识别领域预训练的参数进行初始化,后续多帧交互模块使用了两层各16个注意力机制的编码单元,整体模型进行端到端的更新。在表7中对本文模型结构进行消融实验。首先在保持其他结构不变的情况下,对单帧特征提取网络不使用预训练参数初始化和初始化后不进行更新两种情况进行实验。不更新参数的做法显然对检测性能有很大削弱,只能达到83.30%的准确率,对真实视频更容易误判;无预训练参数则在梯度下降的过程引入过多的随机性使得更容易陷入局部最优值,但二者依然优于基于3D卷积的模型,说明人脸识别领域的先验知识对人脸篡改检测有着很好的指导作用,单帧提取特征所在的嵌入空间与人脸识别的聚类空间有相关性。
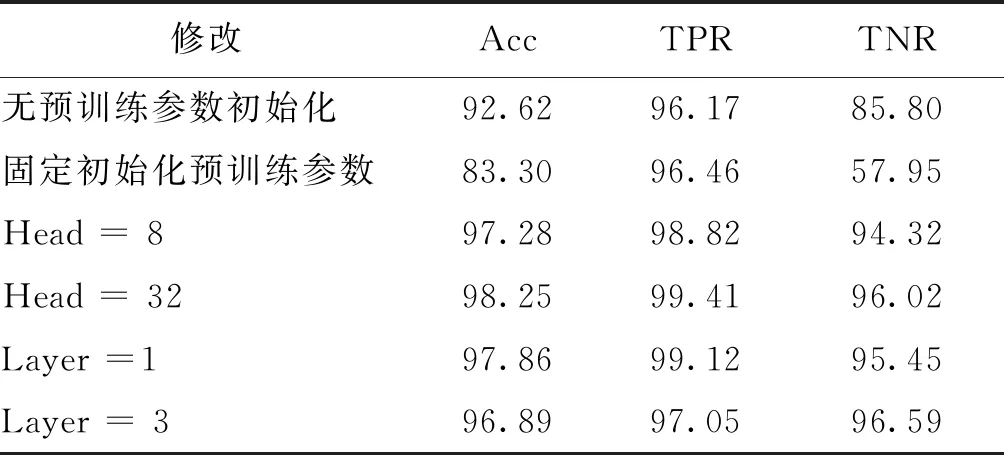
表7 结构消融实验结果Table 7 Result of structure ablation experiment /%
后续对帧间交互所使用编码单元层数与注意力机制的个数也进行了验证。实验发现,层数与注意力机制数目过少都会使检测模型缺乏学习能力,而过多则容易产生过拟合。选择合适的结构设置对模型关于人脸交换篡改视频的检测性能十分重要。
4 结 论
为了应对深度伪造技术对网络安全和个人权利带来的威胁与挑战,提出一种针对人脸交换篡改视频的检测框架:首先,对待测视频流直接提取编码关键帧,并使用两步的人脸检测在关键帧上提取有效的紧密人脸区域集合作为后续模型输入;然后使用卷积神经网络将每个人脸图像映射到统一的高维特征空间中;最后使用基于注意力机制的编码单元在多帧之间进行信息交互,使得每帧的特征能学习到有意义的信息,并且获取全局信息进行检测。
通过仅提取关键帧作为样本的方式,避免了帧间解码的过程,减少了视频流预处理中的时间消耗;通过使用在人脸识别系统中预训练的参数对卷积神经网络进行初始化,引入了人脸空间的先验性信息;通过使用自注意力机制的并行化计算方式,进一步减小了检测过程中的时间消耗。本文框架在几个主流的人脸交换数据集FaceForensics++、DeepFakseDetection和Celeb-DF上均展现出了优良的检测性能——达到了96.96%以上的检测准确率。本文在Celeb-DF上还进行了对比实验与结构消融实验。在对比实验中,本文模型与经典时序模型C3D、R3D、I3D、CNN结合LSTM的模型以及为深度伪造检测所设计的轻量化3D卷积模型L3D进行了比较。实验表明,相较于使用连续帧作为样本,以关键帧为样本能使得层级模型达到更高的准确率,同时,本文模型的检测性能在两种情形下均优于其他模型,尤其在关键帧数目为16时,已经达到99.61%的检测准确率。此外,在时间消耗上的实验也证明了使用关键帧为输入能大幅减少检测时间,同时无论使用关键帧还是连续帧为输入,本文模型的平均检测时间均小于其他模型。综上,本文框架能够实现对人脸交换篡改视频的高效检测。
虽然实验上显示本文框架对拥有不同数目关键帧的视频均适用,但在消融实验上可以发现当帧数变化时所提模型的性能存在一定的不稳定。一方面,在数据集视频数较多而可提取关键帧数较少时,关键帧不足以完全捕捉类别间的差异性特征,无法为模型提供足够的信息,会导致检测能力下降;另一方面,当模型适应了从较多的关键帧中捕捉信息时,当实际情况下待测视频能提供的关键数目较少时模型会认为输入信息不足而产生误判。一个常规的解决方法是,使用多个不同帧数下训练的模型进行投票决策。后续的研究工作包括:进一步探究在单帧里提取更稳定更深层的区分性特征的方法;再在此基础上设计更稳定的帧间特征交互融合方法;设计性能更好,对输入帧数更稳定,对后续处理更鲁棒的检测模型。此外,为使在移动终端设备中部署检测模型成为可能,将进一步探究更轻量化的高效检测模型。
猜你喜欢
现代计算机(2022年4期)2022-04-24
奥秘(2021年5期)2021-06-15
小雪花·初中高分作文(2017年9期)2018-05-21
软件导刊(2018年4期)2018-05-15
中学生数理化·高一版(2017年2期)2017-04-25
电脑知识与技术(2017年3期)2017-03-27
数学学习与研究(2017年3期)2017-03-09
现代电子技术(2016年24期)2017-01-19
米娜·女性大世界(2016年8期)2016-08-17
计算技术与自动化(2014年1期)2014-12-12
