
海量地名地址点高效抽稀方法的研究
2022-01-25 06:58王朝辉
现代测绘 2021年5期
王朝辉,杨 洁
(江苏省测绘工程院,江苏 南京 210013)
0 引 言
随着国家智慧城市建设的快速发展,电子地图建设已成为各行各业信息化建设不可缺少的重要基础支撑。城市规模日益扩大,经济技术的快速发展,决定着电子地图中各要素信息的数据量不断增加,更新频率也在不断加速。这对智慧城市建设的信息化和数字化提出了更高要求,所以如何进行空间数据收集和整理工作也变得越来越重要。
POI点(地名地址点)作为电子地图的重要要素,其重要性日益明显。其数据量大、地理位置分布密级稀疏不规则性,决定着其无法全局显示,需要根据其空间和属性特征进行相应提取处理,即为点的抽稀处理。如何更高效更合理的分析和挖掘POI数据,合理地将其在电子地图中,按各显示比例和抽稀距离正确均匀标注,并且顾及其相应的要素属性,是POI点数据整理过程的重要工作环节,也是POI点抽稀工作的最终目标。
结合目前常规点抽稀方法的局限性,设法研究高效的抽稀方法也是当前数据处理技术的发展趋势。本文主要介绍在传统方法进行点抽稀的基础上,基于Python的Arcpy编程语言,编制的POI数据的一键式自动抽稀工具,从而做到运用编程手段实现数据处理过程的作业流程优化,为海量数据点的多比例尺抽稀工作带来了便利。
1 传统点抽稀方法研究
1.1 研究现状
POI点数据通常数据量大、分布不均匀、地理位置叠加复杂,在制作电子地图过程中,为了注记标注均匀、取舍有度、直观有效,达到制图美观的效果,经常需要对POI点进行抽稀处理。目前ArcGIS的3种最常用点抽稀的方法[1],分别为:Maplex自动点抽稀,Subset点抽稀和SubPoint点抽稀[2]。3种方法进行的优缺点对比和适用范围如表1所示。

表1 3种点抽稀方法优缺点对比表
(1)Maplex牵引线抽稀法:牵引线抽稀是利用ArcGIS的高级智能标注引擎Maplex的牵引线进行标注,将符号作为注记显示,把符号和注记绑定在一起,通过阈值自动进行标注间避让,计算出地图上所有标注的最佳放置位置,达到抽稀的目的。
(2)Subset随机抽稀法:其核心工具是ArcGIS地统计分析模块的“子集要素”工具,该工具对所有POI数据按百分比进行随机抽稀,抽稀后的兴趣点密集度与抽稀前的数据密集程度一致,稀疏的地方更稀疏,密集的地方依旧密集,未考虑均匀。
(3)SubPoints插件抽稀法:是Esri中国自主开发的一个插件,该工具优先考虑点在空间分布上的均匀合理性,并结合点数据中包含的“优先级”属性进行筛选。
1.2 常用SubPoints点抽稀研究
参照以上3种点抽稀优缺点分析,在天地图项目中,由于其数据量大、精度要求高、有权重要求,所以在进行POI点抽稀工作时,通常采用SubPoints点抽稀方法。
SubPoints点抽稀方法是Esri中国自主开发的一个插件,该工具优先考虑点在空间分布上的均匀合理性[3],并结合点数据中包含“优先级”属性进行筛选。通过获取每个点在一定范围内具有的相邻点的数目信息,得到地图中点密度的分布状况,具体操作流程如图1所示。

图1 SubPoints点抽稀方法流程图
电子地图在不同比例尺下,POI点群数量有很大差别,根据每个级别的点距离设置大小不同,各级别抽稀参数需要特别定制[4],同时每一级别都需要根据上一级别的抽稀成果进行抽稀处理,从而保证上一级别显示的注记在当前级别都能出现。即从L20-L19-L18……,数据提取顺序如图2所示。

图2 L10-L20级数据抽稀提取顺序图
所以,在进行海量地名地址点从第10级至第20级多比例尺级别抽稀过程中,需要人工进行多次交互,多次处理才能完成。
2 基于Python和Arcpy的抽稀算法研究
随着社会经济的快速发展,测绘成果的需求也在不断的提高,随之而来的对电子地图数据需求和现势性要求也越来越高。面对海量的地名地址点,如何更高效的研究新技术和新方法,完成电子地图制作的各项数据处理工作,变得越来越重视。
基于Python和ArcPy编辑处理工具是目前比较常用的开发方式,此方法可以实现自动化处理重复的、多步骤的数据处理工作,减少人工参与度,提高工作效率,做到工作流程的优化,为数据快速更新提供有效的技术支持。
2.1 常规抽稀方法
现阶段,点抽稀工作一直是我们在进行电子地图配图过程中,非常重要的一项工作。也是一个必不可少的环节,我们在进行点抽稀工作前,需要进行一系列的数据预处理,比如数据的优先级设置、点距离设定等工作,然后再运用抽稀方法进行抽稀处理,实现地名地址点的有效及合理应用。
常规的SubPoints点抽稀方法,是人工加程序交互的处理方式,存在较多弊端:① 人工参与度高,容易出现误操作;② 工具运行错误时不能及时修复;③ 工作效率较低、处理时间长;④ 抽稀步骤太多,不容易掌握。
所以,常规点抽稀方法已经越来越不能适应目前测绘市场的应用需求,研究如何能更简单快捷的完成抽稀工作已经成为当前非常必要的研究内容。
2.2 Python和Arcpy简介
Python是一种开源的面向对象的解释型计算脚本语言,有丰富的资源库。由于Python 处理速度快、功能强大且具有广泛的认可度,ESRI 选择它作为脚本语言嵌入ArcGIS 中。
ArcPy是一个原生的Python站点包,它涵盖并进一步加强了ArcGIS的arcgisscripting模块的功能。基于Python和ArcPy方法进行GIS数据处理方法开发,既可以运用Python语言的简单性和高效性,又可以直接调用ArcGIS已有的成熟的GIS处理工具,做到自由组合、相辅相成、高效专业,是当前比较成熟有效的开发方式[5]。
所以,基于Python和ArcPy实现数据自动化处理的方法可行并且有效。运用该方法可以编写代码实现GIS数据处理的多个环节、多个循环的自动读取、遍历、更新、转换、融合等处理,实现自动化完成多个工序的功能[6]。
2.3 POI点抽稀的要求
本文运用Python方法实现点抽稀功能[7],是在结合SubPoints方法基础上,进行了一系列的优化处理,同时考虑各级别显示内容一致性限制的情况下完成。具体点抽稀要求为:① 上下级显示的地名地址点内容要一致(本级显示的点,在下一级必须显示);② 优先选择优先级高的点;③ 优先级一样时,优先选择NAME内容短的点;④ 优先级和NAME长度一样时,任意选一个点;⑤ 保证抽稀成果的均匀性,并满足各级别抽稀间距符合各级抽稀距离限制。
2.4 Arcpy编辑抽稀的流程设计
结合点抽稀的具体要求,进行编程方法的抽稀数据的处理流程设计,构建数据提取、筛选和Update数据处理流程。本方法的抽稀顺序是从10级到20级,即从小比例尺到大比例尺顺序进行抽稀,具体流程图如图3所示。
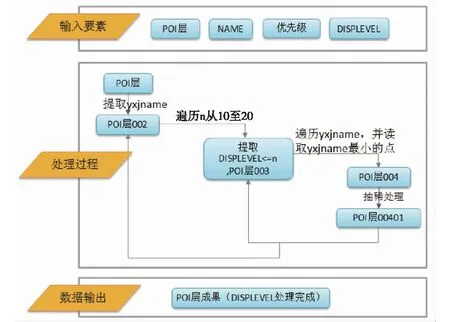
图3 抽稀方法流程图
流程说明:
(1)本方法需要的输入参数分别是:优先级、NAME、DISPLEVEL字段(数据显示级别字段参数)。DISPLEVEL(用于标记各级别显示级别数):根据各比例级别显示要素要求,填写相应数字,如火车站、公园可以从13级显示的,即填写13;公司企业、工厂等只能在16级开始显示的,填写16。
(2)首先根据各字段的“优先级”和“NAME”字段长度,编辑填写yxjname字段。
(3)遍历选择每一级中DISPLEVEL<=n的点,设置为lyrpoi_n。
(4)用DISPLEVEL<=n-1的点,对lyrpoi_n按当前级别抽稀距离选择,将选中的点设置DISPLEVEL=n+1(用上一级筛除部分点)。
(5)对剩下的lyrpoi_n点,提取其yxjname,得到无重复元素的List_yxjname列表。
(6)按从小到大顺序读取List_yxjname列表,遍历各yxjname的要素点,对该要素点进行抽稀处理。
(7)n级处理完成后,再进行n+1级处理。
2.5 ArcPy编辑抽稀算法的研究
点抽稀的对象通常是数以万计的POI点大数据处理,所以计算方法的模型设计非常关键。本方法研究过程中,为提高抽稀方法的可行性和有效性,进行了多种算法对比和编码模型优化,目前抽稀结果在满足项目抽稀要求的前提下,提取效率显著提高。
2.5.1 按距离抽稀
抽稀条件只有距离时,只要将遍历点范围内按距离均匀提取中心点,其他点设置下一级显示,然后遍历下一个循环处理即可。图4(a)按距离抽稀展示图中红色POI点为抽稀结果,其分布均匀,简单有效,但其抽稀方式不满足出图要求,不可取。
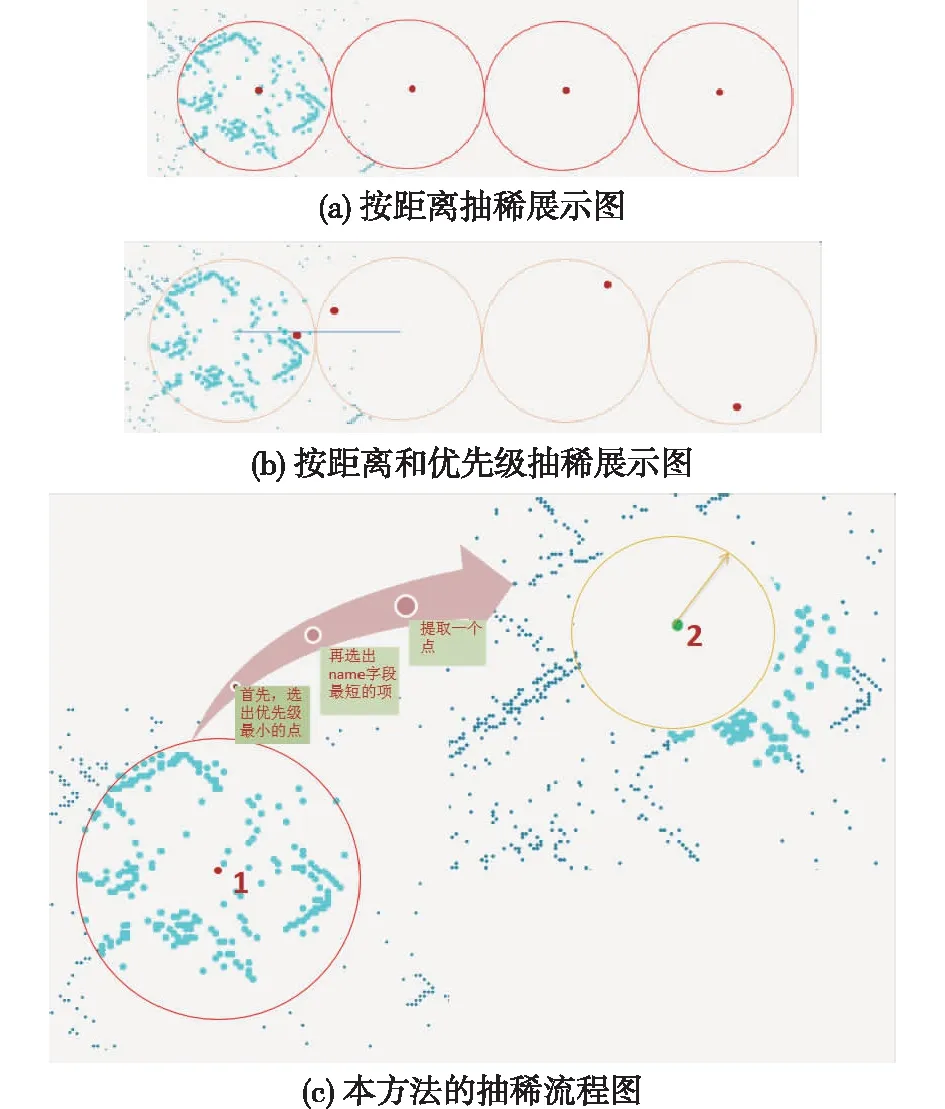
图4 点抽稀展示图
2.5.2 按距离和优先级抽稀
按距离和优先级两个条件抽稀时,如果先按距离选择出分组点,然后再从该分组点中找到优先级最高点提取,其他设置下一级显示,这样抽稀结果即为图4(b)按距离和优先级抽稀展示图中红色POI点所示,其抽稀结果分布不均匀,抽稀不正确。
2.5.3 本方法的抽稀
本方法的抽稀流程图,能有效实现按距离、优先级以及NAME名称长度进行逐级分布式提取,并能实现成果点均匀分布,做到周密有效。
算法说明(如抽稀K级):
(1)设置抽稀对象为DISPLEVEL <=K(从高级往低级抽稀)。
(2)用DISPLEVEL <=K-1的点选择DISPLEVEL=K,并将选中的点设置DISPLEVEL <=K+1(将上一级的点周围距离的点设置下一级显示)。
(3)遍历DISPLEVEL <=K的所有点(遍历逐个处理)。
(4)如图4(c)左侧,遍历到点1,按位置选择周围抽稀距离范围内的点,设为:组i。
(5)从组i中,选择优先级最高的点,设为:点2,如图4(c)右侧。
(6)用点2按位置选择周围抽稀距离范围内的点,令其DISPLEVEL <=K+1。
(7)继续在剩下的组i中,选择优先级最高的点,同点2进行处理。
(8)重复(7)步骤,直到组i中的点全部筛查完毕。
(9)遍历到下一个处理点,重复到(4)步骤,直到K级别中的点全部筛查完毕。
(10)进行K+1级抽稀处理,重复(1)步骤。
以上方法,运用编码进行分级分批遍历处理,并结合按位置选择、按属性选择、属性计算、点距离分析等计算方法,搭建多循环多遍历模型,这种层层套叠的计算流程,有效满足抽稀要求,最终实现抽稀工作的全自动处理,进一步提高数据处理的工作效率,有效可取。
2.6 关键技术
2.6.1 筛选次数的简化
抽稀条件中说明数据提取方式为:优先根据优先级进行提取,若提取数量大于1,则再根据NAME长短进行提取,若提取结果仍然大于1,则随机提取。本方法通过代码优化处理,将优先级和NAME两个字段的内容融合成yxjname字段,成功地将优先级和NAME字段长度两次筛查合并成一次筛查,达到简化筛选步骤,优化处理方法的效果。
2.6.2 优化遍历对象
本次抽稀的遍历对象是yxjname列表,通过逐个读取该列表中从小到大顺序的值,实现yxjname权重从高到低提取,逐个遍历yxjname列表,设置POI点进行抽稀处理。将计算对象从每个点,转换成yxjname列表元素,大幅度地减少了遍历海量对象次数,减少抽稀循环计算量,达到优化计算方式,进一步提高抽稀速度。
2.6.3 先用上一级提取点过滤掉部分点
由抽稀处理的第一个条件可知,上一级的点在本级必须显示。本方法在抽稀各级别前,首先进行叠加分析处理:运用Arcpy的SelectLayerByLocation_management工具,在当前级抽稀处理前,先用上一级抽稀成果点,按位置选择本级抽稀距离范围内的点,设置其在下一级显示。这样就能避免后期计算时,不会将上级的点抽稀过滤掉,实现上级点在本级一定显示的要求。
通过这项处理,实现上级提取点在本级一定显示的目的,同时提前过滤部分点,减少抽稀计算对象,优化抽稀算法。
2.6.4 优先处理频率高的点
POI点数据量大且分布不均,地理位置的稀疏和稠密程度没有规律。优先计算点密度高的区域,不但可以快速地过滤掉较多点,而且可以更精确地提取出优先级高的点,做到提高处理速度,优化计算方法。
本方法在代码编辑过程中,调用了Arcpy的Frequency_analysis方法,计算出点距离表中各点的叠加频数,通过读取频数高的点进行计算,达到了优化此类计算方法的效果。
3 应用实例
以数字太仓项目POI数据为例,运用此方法进行十个级别的抽稀处理。
脚本工具界面及参数设置如图5所示。
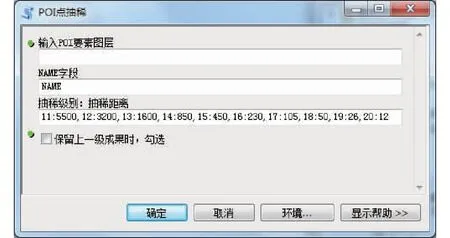
图5 抽稀工具
抽稀处理后,POI点属性项DISPLEVEL的内容即为抽稀结果,如L级别设置的显示内容为:DISPLEVEL<=L,如图6展示内容,每种符号代表一个级别。由图6可知,显示的每个符号之间没有压盖,每种符号都是按相应距离均匀分布,能够符合抽稀要求。

图6 太仓市POI点抽稀前后对比展示图
研究表明:本文提出的基于Python和Arcpy的抽稀算法,与其他常规使用的抽稀方法相比,既保证了重要地物的保留,又有效地实现了图面效果均匀、整洁,同时很好地完成各级别抽稀成果点之间的继承和衔接,做到一键式全自动处理。
4 结 语
随着国家经济社会的高速发展,人们对新型智慧城市服务需求不断增加,如何更高效的分析和挖掘海量POI点的工作变得越来越关键。本文以海量地名地址点抽稀工作的流程优化为目标,运用Python和ArcPy相结合的方法搭建抽稀模型,制作批处理工具,并在数字太仓项目的电子地图配图中得到广泛应用。其抽稀结果整洁清晰、分布均匀,符合电子地图配图要求,并且抽稀效率得到大幅提升,有效提高工作效率,实现工作流程优化目标。希望通过该方法的进一步推进,为今后开展类似海量数据分析和挖掘工作提供新方法和新思路。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
基层中医药(2021年8期)2021-11-02
铁道通信信号(2020年10期)2020-02-07
当代陕西(2019年14期)2019-08-26
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
中学生(2017年13期)2017-06-15
测绘科学与工程(2017年5期)2017-05-07
中学数学杂志(初中版)(2016年5期)2016-11-01
中国教育技术装备(2015年21期)2015-03-11
