
配电网信息智能分析与自适应控制策略研究
2022-01-25 10:25朱军飞
电子设计工程 2022年2期
朱军飞,徐 民,李 京
(国网湖南省电力有限公司,湖南长沙 410004)
随着传统化石能源的日益枯竭,具有可持续发展特性的清洁能源已被广泛应用[1]。具有代表性的为光伏和风电等清洁能源,以分布式发电(Distributed Generation,DG)形式接入电网,实现能源结构调整和环境保护[2]。然而大量的DG 并网后,将影响电网的规划、运行和控制,尤其对于含DG 的配网负荷预测与自适应控制会带来新的挑战。针对上述情况,国际上提出了主动配电网(Active Distribution,ADN)的概念。ADN 是智能电网的高级发展阶段,与传统配电网相比,强调电网中的资源应积极参与电网的运行和控制[3]。即在除了传统的网侧设备外,电网中的分布式发电与用户侧资源也应参与电网的运行和控制。其中无功电压优化控制是电力系统的一个重要研究课题,国内外学者对此做出了大量的研究,主要集中在目标函数的构造和算法的改进上[4]。文献[5]提出了一种基于非参数估计的无功电压控制方法,通过建立分布式发电模型来分析控制效果。文献[6]以配电网购电费用、DG 运维费用和DG 补贴费用之和最小为经济性目标,同时以节点电压的稳定性指标为优化目标,采用归一化权重方法进行多目标优化。文献[7]采用遗传算法,求解带分布式电源的配电网无功优化。虽上述文献的研究对象是具有分布式电源的配电网,但并未考虑DG 在无功和电压优化等自适应控制策略中的作用。
因此,对于配电网缺乏负荷信息综合分析能力以及自适应调控能力的缺点,对配电网进行控制策略研究,提出了一种能够综合考虑负荷信息,实现配网自适应控制的综合分析系统。
1 系统设计
配电网信息智能分析与控制系统主要包括3 个部分:基础层、支撑层和应用层,如图1 所示。
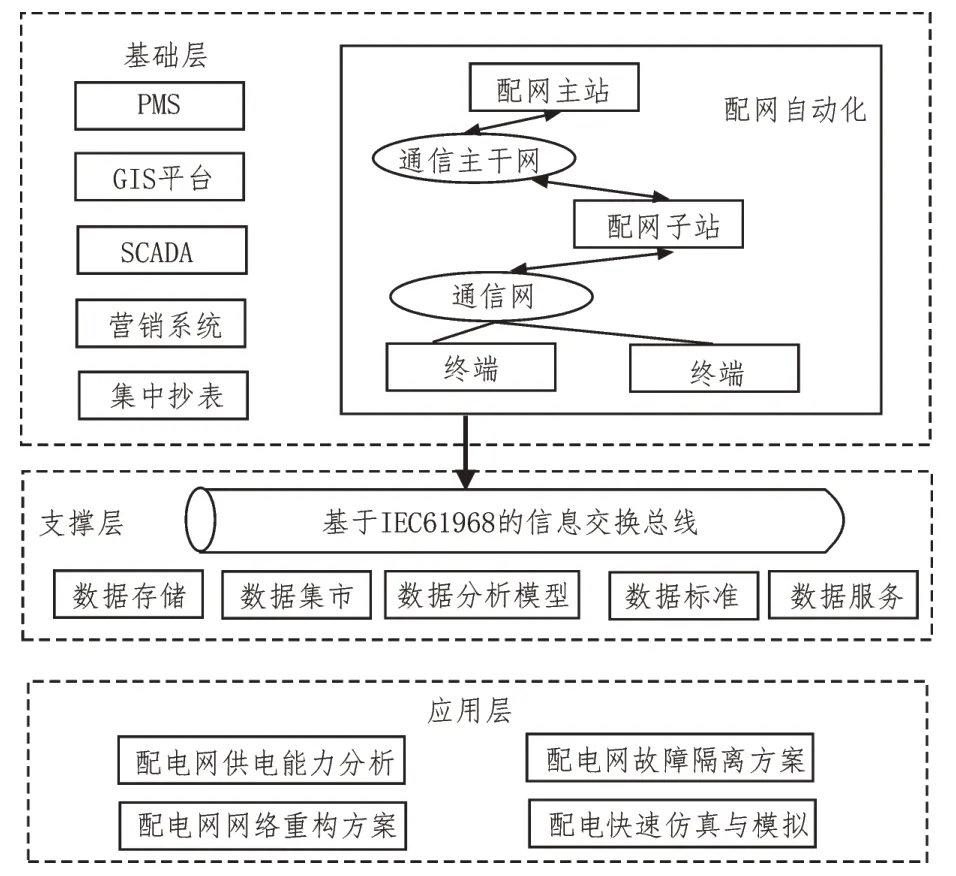
图1 系统中各模块功能及关系
基础层的功能是收集配电网的相关数据信息,如PMS 系统、SCADA 系统、电能量采集系统等。上述信息大致涵盖了配电网的所有数据,这也是智能分析与实施自适应控制策略的基础[8]。
支撑层利用通信体系,将基础层收集的数据进行融合,完成数据的初步分析、存储,并建立相关的理论模型,如配电网供电能力等[9]。
应用层的功能为深入剖析配电网的数据信息,完成其供电能力分析、配电网网络重构方案辅助分析、配网快速仿真与模拟等功能。
2 配电网智能分析
配电网智能分析过程主要包括数据采集、数据预处理和大数据分析与应用3个大的过程框架,具体的处理细节如图2所示。
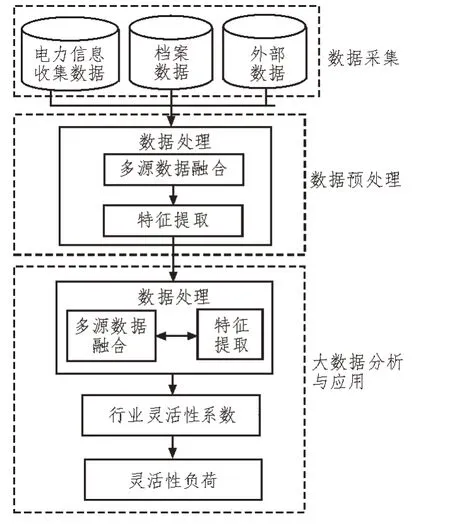
图2 智能分析过程
数据采集来自电力信息采集数据、外部数据等[10]。面对海量的配电网数据,在导入大数据平台数据库实现多源数据融合前,根据不同的融合需求进行关联和分类是不可缺少的数据预处理程序[11]。然后在数据融合的基础上,提取反映负荷特性的特征向量,完成信息的智能分析。
2.1 多源数据融合
数据融合可以看作是从原始数据到成熟数据的映射过程。定义映射F∶X to Y,X 为原始数据集,Y为数据融合集,映射F 为数据融合过程。对于原始数据,根据规划数据模型和数据融合维数提取特征向量。特征向量由数据的各个方面组成,代表融合维下数据的属性。然后将特征向量与数据流标准等数据处理规则融合,得到标准特征向量。标准特征向量的内容与成熟数据的相关属性相对应,可以从标准特征向量中恢复成熟数据。
2.2 特征提取
经过数据预处理,从规划需求中提取特征向量。这一向量是一个广义向量,可以是一维向量,也可以是多维向量。特征提取对象主要是反映负荷特征的指标,例如节点压降、线路损耗等[12]。为此,选取用电信息采集系统数据、气象信息系统数据、PMS 系统数据、海量历史/准实时数据平台数据和电网规划数据五类数据融合特征。另外,在特征提取后,为了便于数据聚类分析,数据预处理还应完成矢量单位、格式、精度的标准化,实现描述字段的统一。
2.3 智能分析
配电网的智能分析侧重于负荷,以提升系统的供电能力[13]。考虑一个12.66 kV、33 节点的配电网,实际与无功总需求分别为3.715 MW 和2.3 MVA,系统基本无功功率为100 MVA。采用一个与时间相关的时变负荷模型,可以表示为:
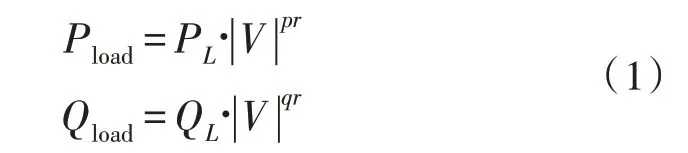
式中,Pload、Qload分别为实际有功和无功功率,PL、QL为额定电压下的有功和无功功率。V为电压幅值,pr、qr为有功和无功负荷系数。
3 自适应控制策略
结合配电网当前的负荷状态以及节点电压降、线路损耗、各个电源点的供电能力等具体情况,当配电网的供电能力无法满足所有负荷需求时,利用自适应遗传算法获得最佳的开关投切次序,以实现负荷调整,保证系统内最大的负荷供电能力[14]。
3.1 优化目标
为了最大限度地减少网络内的功率损耗、改善电压分布、提高供电能力,目标函数如下:
1)损耗最小化:
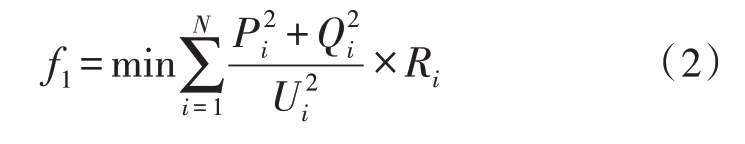
式中,N为支路数,Ri为支路电阻,Pi、Qi分别为支路有功功率和无功功率,Ui为节点i处的电压。
2)系统电压偏移最小化:
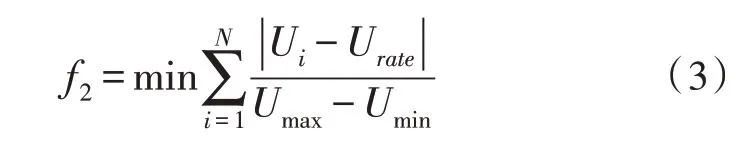
式中,i为系统节点数;Ui为节点i处的电压;Umax、Umin分别为节点电压的上限和下限。
同时,适应度函数为:
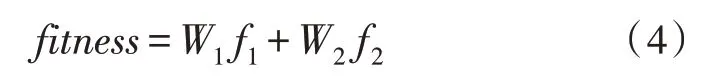
式中,W1、W2为权重,两者之和为1。
3.2 约束条件
在优化功率损耗和降低压降的同时,需要考虑其他约束:
1)配电线路容量Si的限制:

式中,Sk,max为线路容量的最大值。
2)电压限制:
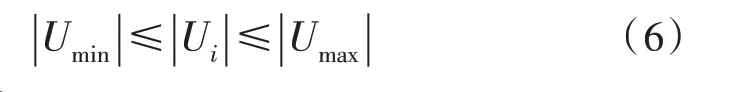
3)潮流约束:

式中,Sij是各馈线潮流,Lj为总的负荷需求。
3.3 基于自适应遗传算法的控制策略
利用自适应遗传算法求解上述优化问题,其中遗传算法是一种由自然选择过程产生的元启发式算法,属于一类进化算法。在此进化算法中,优化问题的候选解(染色体)群体可进化为更优或更适合的解[15-16]。而在配电网负荷转供需求的问题中,种群染色体可以用来表示问题的候选解,若一个解满足问题的约束条件,则其是可行的;否则,不可行。根据得到的最优解控制开关的状态,从而实现配网重构,提升网络的整体供电能力。
基于自适应遗传算法的控制策略流程如图3所示。
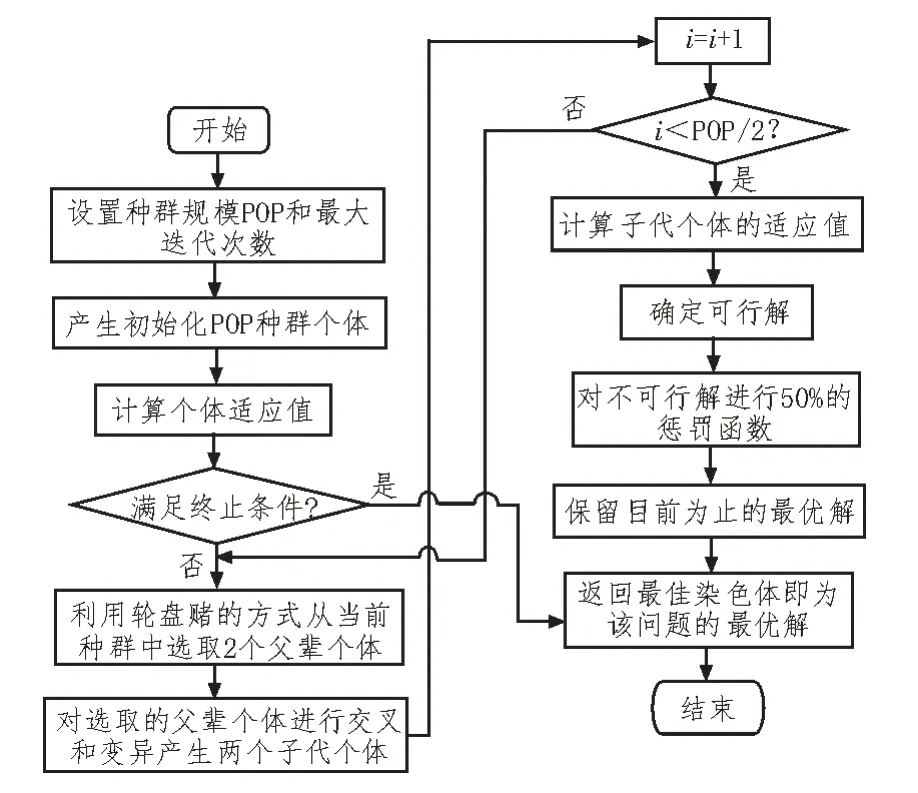
图3 自适应遗传算法控制流程
首先定义问题的规模,并生成种群数量的候选解(染色体或个体),以初始化群体。然后评估每个染色体的适应度fitness,并选择即将进行交叉和突变的配偶或亲本个体(染色体),从当前种群中创建新的后代种群。在完成交叉和变异后,该算法根据适应度函数fitness来评价每个产生的子代染色体的适应度值。最终使用一个程序确定不可行的染色体,以及使用另一个程序惩罚其中的一些染色体。此外,该算法保留了所有产生种群中的最优染色体,即适应值最小的染色体。遗传算法会不断重复上述步骤,直到满足一些终止的条件。当迭代终止时,遗传算法会返回代表优化问题解决方案的最佳染色体。
4 实验结果与分析
为验证所提配电网信息智能分析与自适应控制策略的有效性,在Matlab/Simulink 环境下建立了相应的配电网信息智能分析与自适应控制系统,对控制策略使用前后的供电能力进行对比。
4.1 有功功率损耗
提升配电网供电能力的一个关键指标就是实际的有功功率损耗,功率损耗降低意味着有更多的电能被有效使用。优化控制前后配电网的有功损耗如图4 所示。
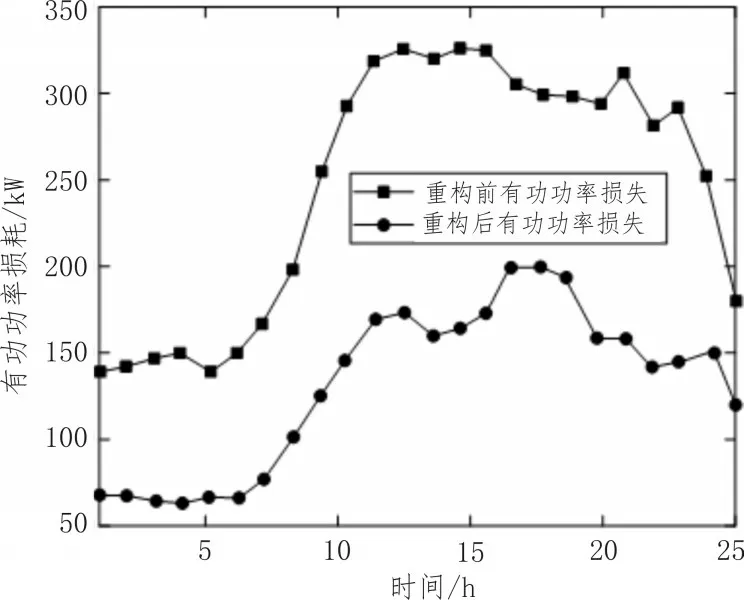
图4 配电网的有功损耗
从图4 中可以看出,经过自适应控制后,配电网的有功功率损耗有了明显的降低。经过每小时一次的信息分析和网络重构,网络的实际功率损耗显著下降。在14 小时,实际功率损失达到最大值344.986 4 kW。经过24 小时的系统运行,相比于优化控制前,配电网的功耗下降了53.87%,降至159.121 3 kW。
4.2 无功功率损耗
经过自适应控制,配电网的实际有功功率损耗明显降低。同样,无功损耗分量明显减小。优化控制前后配电网的无功损耗如图5 所示。
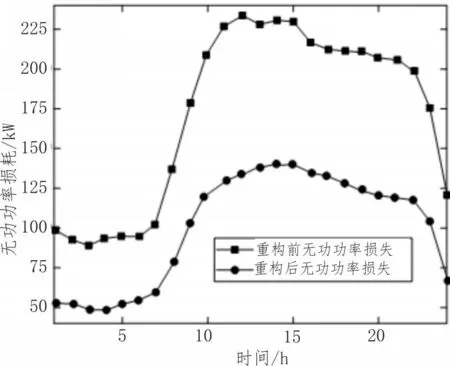
图5 配电网的无功损耗
从图5 中可以看出,优化控制前后,无功功率损失变化较为明显。因此在对配电网信息智能分析的基础上,实现自适应遗传控制有着较好的优化作用,且在特定季节,无功损耗每小时下降一次。
4.3 最小电压幅值
除了功率损耗外,提高电压幅值也是所提出系统的另一个目标。优化控制前后配电网的最小电压幅值如图6 所示。
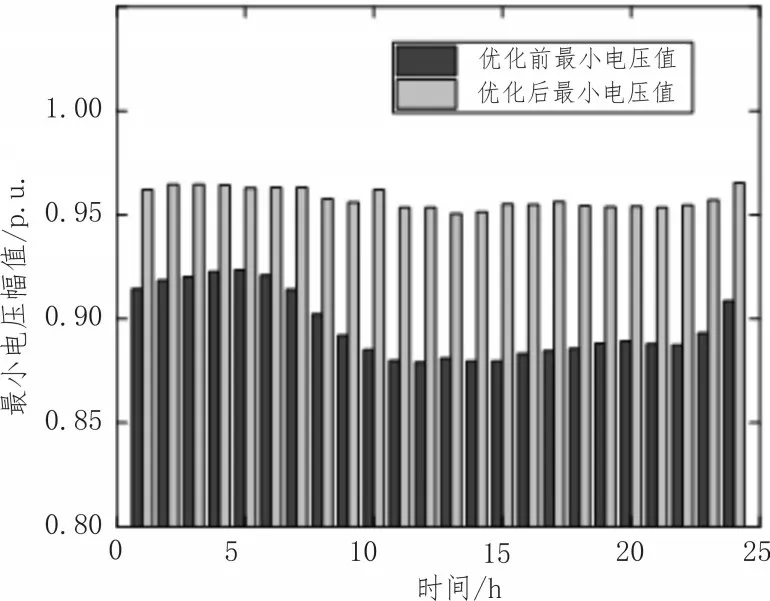
图6 配电网的最小电压幅值
从图6 中可以看出,在优化控制后,系统的每小时最小流量均超过0.95 p.u.,且较为稳定。尤其是在第14、15小时,优化前的最小电压幅值低于0.90 p.u.,且变化较大,不利于系统的稳定运行。经过配网重构,提高到0.96 p.u.,因此所提控制策略能够较好地提高系统的供电能力。
5 结束语
该文提出了一种配电网信息智能分析与自适应控制策略。在构建的配电网信息智能分析与自适应控制系统的基础上,对基础层获得的各种信息进行融合及特征提取,以完成信息的智能分析。同时在应用层根据智能分析的结果,利用自适应遗传算法完成系统的优化控制,实现损耗最小化,改善电压分布。通过Matlab 对所提优化控制策略进行仿真论证,仿真结果表明,优化控制后系统的有功和无功功耗均明显下降,且最小电压幅值趋于稳定。由于文中仅在24 小时内进行实验论证,对长时间的系统运行效果是未知的,接下来的研究中将侧重于所提策略在长时间系统运行中的有效性。
猜你喜欢
机械工业标准化与质量(2022年3期)2022-08-12
舰船科学技术(2022年11期)2022-07-15
防爆电机(2021年5期)2021-11-04
廊坊师范学院学报(自然科学版)(2021年2期)2021-09-10
黑龙江科学(2021年16期)2021-09-09
汽车工程(2021年12期)2021-03-08
电子制作(2019年24期)2019-02-23
汽车文摘(2018年4期)2018-11-27
家庭影院技术(2018年9期)2018-11-02
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
