
Scribble-Supervised Video Object Segmentation
2022-01-25 12:51PeiliangHuangJunweiHanNianLiuJunRenandDingwenZhang
Peiliang Huang,Junwei Han,,Nian Liu,Jun Ren,and Dingwen Zhang,
Abstract—Recently,video object segmentation has received great attention in the computer vision community.Most of the existing methods heavily rely on the pixel-wise human annotations,which are expensive and time-consuming to obtain.To tackle this problem,we make an early attempt to achieve video object segmentation with scribble-level supervision,which can alleviate large amounts of human labor for collecting the manual annotation.However,using conventional network architectures and learning objective functions under this scenario cannot work well as the supervision information is highly sparse and incomplete.To address this issue,this paper introduces two novel elements to learn the video object segmentation model.The first one is the scribble attention module,which captures more accurate context information and learns an effective attention map to enhance the contrast between foreground and background.The other one is the scribble-supervised loss,which can optimize the unlabeled pixels and dynamically correct inaccurate segmented areas during the training stage.To evaluate the proposed method,we implement experiments on two video object segmentation benchmark datasets,YouTube-video object segmentation (VOS),and densely annotated video segmentation(DAVIS)-2017.We first generate the scribble annotations from the original per-pixel annotations.Then,we train our model and compare its test performance with the baseline models and other existing works.Extensive experiments demonstrate that the proposed method can work effectively and approach to the methods requiring the dense per-pixel annotations.
I.INTRODUCTION
VIDEO object segmentation (VOS) aims at segmenting one or multiple foreground objects from a video sequence,which has been actively studied in computer vision applications,such as object tracking [1],video summarization[2],and action recognition [3].Segmenting objects on videos are partially inspired by researches about semantic segmentation,e.g.,semantic segmentation in the urban scene[4],[5].However,VOS needs to simultaneously explore both the spatial and temporal information.
Based on the levels of human intervention in test scenarios,existing VOS approaches can be divided into two main categories,which are the semi-supervised approaches [6]–[10]and unsupervised approaches [11]–[15],respectively.The semi-supervised VOS approaches need the ground-truth annotations of the objects for the first frame for each test video sequence,while the unsupervised approaches do not need such annotation.However,both the semi-supervised and unsupervised approaches need the per-pixel annotations of each video frame in the training stage,and the per-pixel annotation on large-scale video data is prohibitively expensive and hard to obtain.Due to the lack of prior knowledge of the primary objects in the first frame,the unsupervised approaches cannot select the objects of interest flexibly.
In this paper,to achieve the trade-off between annotating efficiency and model performance,we propose a novel method to achieve video object segmentation that needs only the scribble-level supervision.Specifically,our method requires the scribble annotation on each video frame in training while only requires the scribble annotation on the first video frame in testing.Consequently,compared to the conventional semi-supervised VOS and unsupervised VOS methods,our scribble-supervised VOS method has two advantages.Firstly,as shown in Fig.1 (a) and 1(b),unlike the per-pixel annotations,drawing a scribble greatly reduces the cost of labeling.Secondly,the annotated scribble on the first frame of each test video can provide informative guidance for segmenting the desired objects,which is beyond the capacity of the unsupervised VOS approaches.
Implementing the scribble-supervised VOS process is very challenging.As shown in Fig.1 (a),per-pixel annotations allow fully supervised VOS methods to achieve reliable segmentation results since they provide supervision on all aspects of the targeted objects,including structure,position,boundary detail,etc.However,scribble-level annotations (see Fig.1 (b)) only provide a limited number of labeled pixels inside the objects which are highly sparse and most of the pixel information is missing.In this case,missing the supervision information would limit the performance of the deep model trained on scribble-level annotations.Directly using conventional network architectures and object functions to learn video object segmentation models with these sparse scribbles may lead to segmentation results that have poor boundary and details,as shown in Fig.1 (c).
To achieve high-quality video object segmentation results,we introduce a novel scribble attention module and a scribblesupervised loss to build the video object segmentation model.

Fig.1.The illustration of different annotations and the results of different methods supervised by scribbles.(a) Manually annotating cost with the perpixel annotations.(b) Manually annotating cost with the scribble-level annotations.(c) Baseline model:trained only on scribbles with partial crossentropy loss [16].(d) Ours.
First,we design a novel scribble attention module that learns an effective attention map to enhance the contrast between the foreground and background.Most existing selfattention models utilize global context regions to construct contextual features,where the information at each location is aggregated.However,not all contextual information is reliable for the final decision.Instead of learning dense pairwise relationships globally,the scribble attention module is able to selectively learn the relationship between reliable foreground positions and the query position with the help of the foreground scribble annotation information.Specifically,the scribble attention module computes the response at a query position as a weighted sum of the features at the scribble positions in the input feature maps.Intuitively,if the query position belongs to the background region,the pairwise affinities between it and all scribble positions are relatively low,so is the aggregated response of this query position.On the contrary,if the query position belongs to the foreground region,the pairwise affinities between it and all scribble positions are relatively high,so is the aggregated response of this query position.Therefore,the scribble attention module can capture more accurate context information and learn an effective attention map to enhance the contrast between the foreground and background.
Second,we propose a novel scribble-supervised loss which optimizes both the labeled and unlabeled pixels by making full use of pixel positions and red-green-blue (RGB) color.This scribbled-supervised loss can be seen as a regularized loss and cooperated with the partial cross-entropy loss [16] to optimize the training process.Specifically,we leverage the partial cross-entropy (pCE) loss [16] on the scribble labeled pixels and scribble-supervised loss on both the labeled and unlabeled pixels in “shallow” segmentation [16],[17].Our scribble-supervised loss penalizes disagreements between the pairs of pixel points and softly enforces output consistency among all pixels points based on predefined pairwise affinities.These pairwise affinities are based on dense conditional random field (CRF) [18] which makes full use of pixels position and RGB color.By adding this regularization term,all pixel information is used throughout the training process,which compensates for missing information in scribble-level annotations.Furthermore,we dynamically divide the predicted mask into three different confidence regions and assign different scribble-supervised loss weights to these three regions at the same time.Thus,we can achieve better segmentation of the object’s boundary by dynamically correcting the inaccurate segmentation area throughout the training process.
The contributions of this paper can be summarized as follows:
1) We propose a novel weakly-supervised VOS method which trains the model with only scribble-level annotations.To the best of our knowledge,this is one of the earliest VOS frameworks working under the scribble-level supervision.
2) We design a novel scribble attention module which can capture more accurate context information and learn an effective attention map to enhance the contrast between foreground and background.
3) We propose the scribble-supervised loss and integrate it into the training process to compensate for the missing information of scribble-level annotations and dynamically to correct the inaccurate segmentation area.
4) We evaluate the proposed algorithm on two benchmark datasets quantitatively and qualitatively.The extensive experiments show that the proposed algorithm effectively reduces the gap to approaches trained with the per-pixel annotations.
The remainder of this paper is organized as follows.A brief review of the related works on video object segmentation,scribble-supervised semantic segmentation,and self-attention module is presented in Section II.Then,the problem formulation and detailed explanations of the proposed method are presented in Section III,followed by the experimental results in Section IV.Finally,the conclusions are drawn in Section V.
II.RELATED WORKS
We start with providing an overview of related works on video object segmentation,followed by an overview of scribble-supervised semantic segmentation,and finally review several related works for self-attention models.
A.Video Object Segmentation
Semi-Supervised Methods:In the semi-supervised setting,the ground truth masks of the foreground objects are given for the first frame in the video sequence,the goal is to propagate the object masks of the given objects for the rest of the video sequence.Perazziet al.[6] combined offline and online learning strategies,where the former produces a refined mask from the estimation on previous frames,and the latter captures the appearance of the specific object instance.Caelleset al.[7] proposed a one-shot video object segmentation (OSVOS)method,which pre-trains a convolutional network for foreground-background segmentation and fine-tunes it on the first-frame ground truth of the video sequence at test time.After that,Maniniset al.[19] improved the OSVOS by semantic information from an instance segmentation network.Voigtlaender and Leibe [20] extended the OSVOS by updating the network online using training examples selected based on the confidence of the network and the spatial configuration.
These online methods greatly improve segmentation results but sacrifice running efficiency.To address the time cost in the fine-tuning stage,some recent works achieved a better runtime and a satisfactory segmentation performance without fine-tuning.Chenet al.[21] proposed a blazingly fast video object segmentation method with pixel-wise metric learning(PML),which uses a pixel-wise embedding space learned with a triplet loss together with the nearest neighbor classifier.Inspired by PML,Voigtlaenderet al.[10] proposed a fast endto-end embedding learning method for video object segmentation,which uses a semantic pixel-wise embedding mechanism together with a global and a local matching mechanisms to transfer information from the first frame and the previous frame of the video to the current frame.Johnanderet al.[9] proposed a generative appearance model(A-GAME) which learns a powerful representation of the target and background appearance in a single forward pass.Although semi-supervised VOS methods have achieved tremendous progress,they rely on the high cost of per-pixel annotation.
Unsupervised Methods:In the unsupervised setting,the ground truth masks of the foreground objects are not given at all.Early unsupervised VOS approaches mainly leveraged object proposals [11],[21]–[25],analyzed long-term motion information (trajectories) [12],[26]–[29] or utilized saliency information [30]–[33],to infer the target.Recently,with the success of deep learning,many convolutional neural network(CNN)-based models were proposed.For example,Jainet al.[34] proposed a two-stream architecture which fuses motion and appearance in a unified framework for segmenting generic objects in videos.Chenget al.[35] proposed an end-to-end trainable SegFlow network which simultaneously predicts optical flow and object segmentation in video sequences.The information of optical flow and object segmentation are propagated bidirectionally in this unified framework.This method needs to fine-tune the pre-trained segmentation network for specific objects.Liet al.[36] proposed an instance embedding network to produce an embedding vector for each pixel.This embedding vector can identify all pixels belonging to the same foreground.Then,they combined motion-based bilateral networks for identifying the background.Songet al.[13] used a video salient object detection method to segment objects,which fine-tunes the pre-trained segmentation network for extracting spatial saliency features and trains ConvLSTM to capture temporal dynamics.Luet al.[14] proposed a novel co-attention siamese network to address the unsupervised video object segmentation task from a holistic view.This method emphasizes the importance of inherent correlation among video frames and incorporates a global co-attention mechanism.Wanget al.[37] conducted a systematic study on the role of visual attention in the unsupervised VOS task,which decouples unsupervised VOS into two sub-tasks:Attention-guided object segmentation in the spatial domain and unsupervised VOS-driven dynamic visual attention prediction in spatiotemporal domain.However,due to the lack of prior knowledge about the primary objects,these unsupervised VOS methods are difficult to correctly distinguish the primary objects from the complex background in real-world scenarios.Additionally,they also need fully annotated masks in the training stage like the semi-supervised method,which is expensive and time-consuming.
Our method uses scribble-level annotations as the supervision of each video frame in the training stage.We also use scribble-level annotations as the object’s inference mask of the first frame in the testing stage.This greatly reduces the cost of labeling during both the training and testing phases.Furthermore,it avoids the lack of prior knowledge about the primary objects.
B.Scribble-Supervised Semantic Segmentation
To avoid requiring expensive pixel-wise labels,semantic segmentation methods attempt to learn segmentation from low-cost scribble-level annotations [16],[17],[38],[39].Linet al.[38] first proposed scribble-supervised convolutional networks for semantic segmentation.Tanget al.[16]combined partial cross-entropy loss on labeled pixels and normalized cut loss for unlabeled pixels.After that,Tanget al.[17] further explored the role of different regularized losses for scribble-supervised segmentation tasks.Wanget al.[39] proposed a boundary perception guided method,which employs class-agnostic edge maps for supervision to guide the segmentation network.To the best of our knowledge,there is no published work for scribble-supervised VOS.Comparing with the scribble-supervised semantic segmentation,the scribble-supervised VOS task is more complex since it is still costly to manually draw scribble-level labels for each object in a large-scale video dataset.Further,the model has to detect and segment the objects along the video sequence depending on the scribble-level label only in the first frame.In this paper,we simulate the human annotations on the original per-pixel annotated datasets.Therefore,the time cost of manual labeling is further reduced.Furthermore,we propose a novel scribble attention module and a scribble-supervised loss to build our video object segmentation model.
C.Self-Attention Mechanisms in Neural Networks
A self-attention module computes the response at a position by using the weighted sum of all the features in an embedding space,which can capture the long-range information.Vaswaniet al.[40] first proposed the self-attention mechanism to draw global dependencies between input and output and applied it in the task of machine translation.This attention mechanism has been attended in the computer vision field.Wanget al.[41] proposed a non-local network for capturing long-range dependencies,which computed the response at a position as a weighted sum of the features at all positions.Inspired from[41],Yiet al.[42] proposed an improved non-local operation to fuse temporal information from consecutive frames for video super-resolution,which was designed to avoid the complex motion estimation and motion compensation and make better use of spatiotemporal information.Fuet al.[43]proposed a dual attention network to model the semantic interdependencies in spatial and channel dimensions respectively.Zhanget al.[44] proposed an aggregated cooccurrent feature module for semantic segmentation,which learned a fine-grained spatial invariant representation to capture co-occurrent context information across the scene.The difference between the co-occurrent feature module and non-local network is that the co-occurrent feature model learns a prior distribution conditioned on the semantic context[44].
Our scribble attention module is inspired by the success of above attention modules.The key difference between our scribble attention module and them is that the scribble attention module computes the response at a position as a weighted sum of the features at the scribble positions labeled in objects by multiplying scribble-level ground truth and feature maps.
III.METHOD
This work aims to design an algorithm for weakly supervised video object segmentation with scribbles as supervision.We introduce the mask-propagation module [9]to propagate the object appearance and introduce the appearance module [9] to provide discriminative posterior class probabilities.To achieve high-quality segmental results with sparsely annotated scribbles,we add a scribble attention module in the two backbones to enhance the contrast between the foreground and background and propose a scribblesupervised loss to take both the labeled and unlabeled pixels into account.In this section,we first present an overview of our proposed VOS method in Subsection A.Then,we discuss the mask-propagation module and the appearance module in Subsection B.In Subsections C and D,we introduce in detail the scribble attention module and the scribble-supervised loss,respectively.Finally,we elaborate on the generation process of scribble annotation in Subsection E.For easy retrieval,we summarize the used symbols of this paper in Table I.
A.Overview
The flowchart of complete VOS in this work is shown in Fig.2,which can be divided into two stages:training stage and test stage.In the training stage,we generate the scribble annotations for all the frames and the detailed generation process is described in Subsection E.The scribble annotations of each frame are used to train our scribble-supervised video object segmentation (SSVOS) model.In the test stage,we only generate the scribble annotation for the first video frame and predict the segmentation mask for each frame.The proposed SSVOS model is illustrated in Fig.3.Given a video frame It,the features are first extracted with a backbone network.Then,they are input to the mask-propagation module and the appearance module.The features and the scribble annotation of the initial frame I0are input to the maskpropagation module to provide a rough prior.The coarse segmentation mask of frame It−1is input to the maskpropagation module to propagate the object’s appearanceinformation from frame It−1to frame It.The coarse segmentation mask and the mean and covariance of frameIt−1are used to update the appearance module.The two features from the mask-propagation module and the appearance module are combined in the fusion module,which comprises two convolutional layers.We first concatenate these two features along the channel dimension and obtain aggregated feature maps.Then,we fuse the aggregated features to generate a coarse mask encoding by using two convolution layers with 3×3 and 1×1 convolutional kernels,respectively.The coarse mask encoding is input to a convolution layer with 3×3 convolutional kernels to generate a coarse segmentation mask.This mask is further used to update the maskpropagation module to propagate the object’s appearance information from frame Itto frame It+1.The coarse segmentation mask is also used to update the appearance module to provide posterior possibilities for frame It+1.Finally,the coarse mask encoding from the fusion module is passed through the upsampling module and a convolution layer with 3×3 convolutional kernels to produce the final segmentation mask.

TABLE IA SUMMARY OF SYMBOLS USED IN THIS PAPER
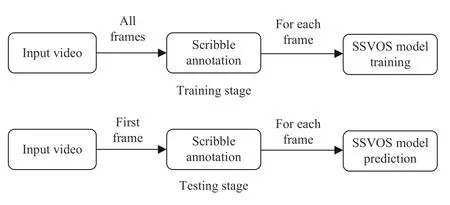
Fig.2.Flowchart of complete video object segmentation in this work.
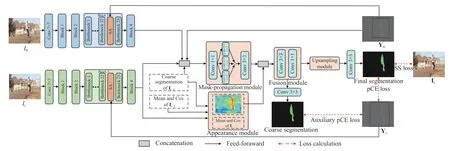
Fig.3.The architecture of the proposed scribble-supervised video object segmentation model (SSVOS).The scribble attention (SA) module is only embedded into the third block of the backbone network.The features and the scribble annotation of the initial frame I0 are first concatenated with the features of the current frame It and the coarse segmentation mask of the previous frame It−1.Then,the concatenated features are input to the mask propagation module.The features of It and the coarse segmentation mask of I t−1 are input to the appearance module.Furthermore,the mean and covariance of I t−1 are also input to the appearance module.The two features from the mask propagation module and the appearance module are fused in the fusion module and generate a coarse mask encoding.This coarse mask encoding is input to a convolution layer to generate a coarse segmentation mask which is then used to update the maskpropagation module and the appearance module for the next frame I t+1.The coarse mask encoding is then refined by the upsampling module and a convolution layer to generate the final segmentation.The pCE loss and the auxiliary pCE loss only consider the labeled pixels and scribble-supervised (SS) loss considers both the labeled and unlabeled pixels.“Conv” indicates “convolution”.“r” indicates dilation rate [45].“Cov” indicates covariance.
B.Mask-Propagation and Appearance Modules
Inspired by A-GAME [9],we use a mask-propagation module to propagate the object’s appearance and keep the temporal-spatial consistency.As shown in Fig.3,the maskpropagation module consists of three convolutional layers,where the first and third layers are two convolution layers with 1×1 and 3×3 convolutional kernels,respectively.The middle layer is a dilation pyramid [45],which has three 3×3 convolution branches with dilation rates of 1,3,and 6,respectively.In the first frame I1,the scribble annotation of initial frame I0is used as input to the mask-propagation module to propagate the object’s appearance from frame I0to frame I1.In the subsequent frames,where the scribble annotations are not available,the coarse segmentation mask from It−1is used as the input to update the mask-propagation module.Thus,the mask-propagation can propagate the object’s appearance from frame It−1to frame It.As the displacements between adjacent frames are very small,temporal-spatial consistency can be kept,and the mask-propagation module can provide the accurate foreground prior estimation to frame It.
Furthermore,we also use an appearance module [9] to return the posterior class probabilities at each image location.These posterior class probabilities form an extremely strong cue for foreground/background discrimination.Like [9],let us denote the of features extracted from the video frames as{Mp}.The feature Mpat each pixel locationpis aDdimensional vector.We model these feature vectors as i.i.d samples drawn from the underlying distribution:
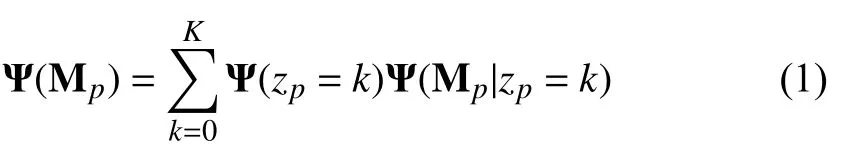
wherezpis a discrete random variable which assigns the observation Mpto a specific componentzp=k.We use a uniform prior Ψ(zp=k)=1/Kforzp.Kis the number of components and each component exclusively models the feature vectors of either the foreground or the background.In(1),each class-conditional density is a multi-variate Gaussian with mean µkand covariance matrix Σk:
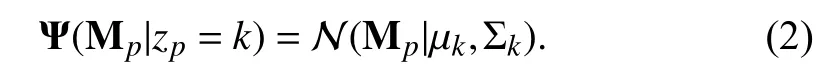
In the first frame,our module parameter is inferred from the extracted features and the scribble annotation of initial frame I0.In subsequent frames,we update the module using the network coarse segmentation predictions as soft class labels.We compute the appearance module parameter of frame Itas follows:


Given the module parameters computed in the previous frame It−1,τt−1,our appearance module can predict the posterior map of frame Itas follows:
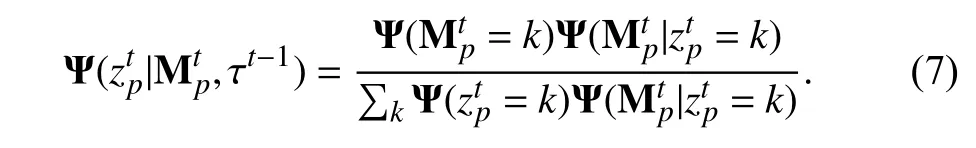
C.Scribble Attention Module
As illustrated in Fig.4,given an input feature X ∈RC×H×W,we first transform it into three new feature maps Φ(X),Θ(X)and Ω(X),respectively,where {Φ(X),Θ(X),Ω(X)}∈RC/2×H×W.We resize the scribble-level ground truth to R1×H×W.Then,we perform an element-wise multiplication between the Φ(X) and the scribble-level ground truth.Here,the foreground scribble pixels are set to 1 and the rest are set to 0.After that,we calculate the attention as
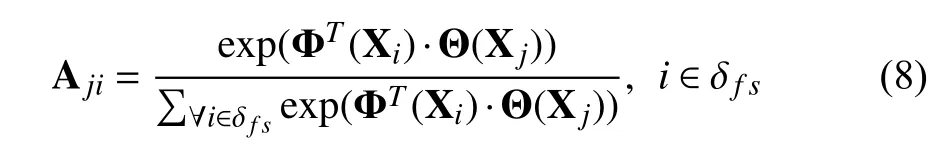
where Ajiindicates the extent to which the model attends to theith position when synthesizing thejth position.δf sindicates the foreground scribble pixels position.Tindicates the transpose operation.Φ(Xi)=WφXi,Θ (Xj)=WθXj,where Wφand Wθare two weight matrices which are learned via 1×1 convolution.Then,the output of the attention layer in thejth position can be represented:
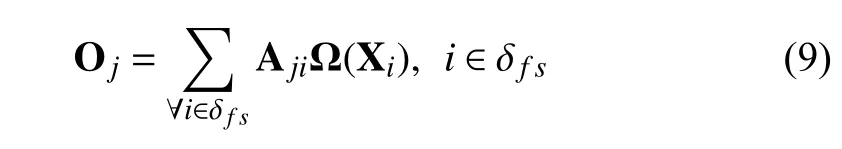
where Ω(Xi)=WωXiand Wωis a weight matrix which is learned via 1×1 convolution.Finally,we further multiplyOjby a scale parameter γ and perform an element-wise sum operation with the input feature X to obtain the final output Z ∈RH×W×Cas follows:

where γ is initialized as 0 and gradually learned to assign more weight [43],[46].The output feature Zjof the scribble attention module at each position is a weighted sum of the features at the positions of the foreground scribbles and original features.
The scribble attention module computes the response at a position as a weighted sum of the features at the scribble positions labeled in objects.Each pixel in the scribble belongs to the foreground object.Thus,the module can capture more accurate context information and learn an effective attention map to enhance the contrast between foreground and background,which plays an important role in the segmentation task.
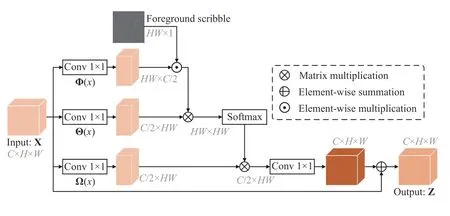
Fig.4.Illustration of the proposed scribble attention module.
D.Scribble-Supervised Loss
As shown in Fig.3,the annotated scribbles are sparsely provided,and the pixels that are not annotated are considered as unknown.We use the (auxiliary) partial cross-entropy loss[16] to consider the partially labeled pixels which can effectively ignore unknown regions.This partial cross-entropy loss can be seen as a sampling of cross-entropy loss with perpixel masks by rewriting it as follows:
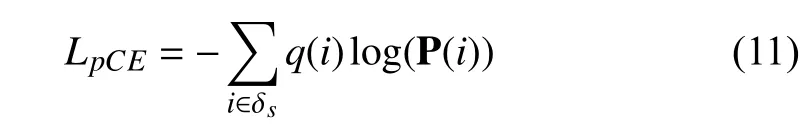
whereq(i) is a binary indicator,which equals 1 if pixeliis labeled on the foreground scribble and 0 otherwise;P (i) is the softmax output probability of the network;δf sindicates that the scribble labeled pixels.
So far,all scribble labeled pixels have been used for training with partial cross-entropy loss.However,comparing with perpixel annotations,scribbles are often labeled on the internal the objects which are lack of determinate boundary information of objects and confident background regions.Therefore,with limited pixels as supervision,object structure,and boundary details cannot be easily inferred.Furthermore,since the scribble-level annotations only label extremely fewer pixels,training the CNN networks on scribbles would lead to overfitting.The proposed scribble-supervised loss optimizes the training process on both the scribble-labeled and unlabeled pixels,which compensates for missing pixel information in unlabeled pixels.Thus,the scribble-supervised loss can be seen as a regularized loss and can prevent overfitting.Our scribble-supervised loss penalizes disagreements between the pairs of pixel points and softly enforces output consistency among all pixel points based on predefined pairwise affinities.These pairwise affinities are based on dense CRF [18] which makes full use of pixels position and RGB color.To this end,we first define the energy formulation between pixeliand pixeljbased on [47],[48] as follows:
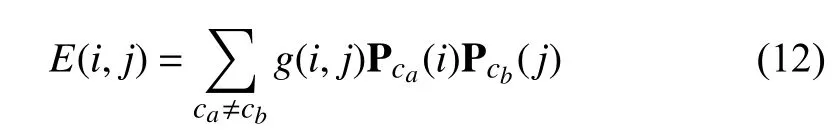
wherecaandcbare the class labels.(i) and(j) are the soft-max outputs of network at pixeliand pixelj,respectively.g(i,j) is a Gaussian kernel bandwidth filter which considers both pixel spatial positions and RGB colors and can be represented as follows:
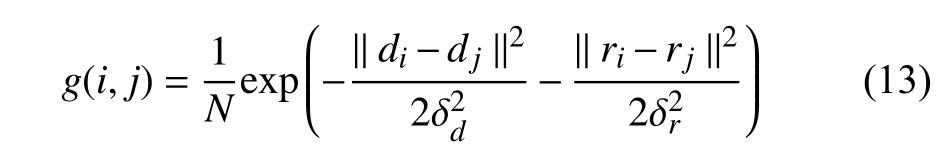
whereNis the normalized factor,dandrare the pixel spatial position and RGB color,respectively.δdand δrare the hyper parameters that control the bandwidths of Gaussian kernels.We use the Potts model [49] as a discontinuity preserving function to penalty disagreements between the pairs of pixels and encourage the pixels in the same region to have equal labels.Assuming that the segmentation results P are restricted to binary class indicators P ∈{0,1},the standard Potts model[49] could be represented via Iverson brackets [·],as on the left-hand side below:
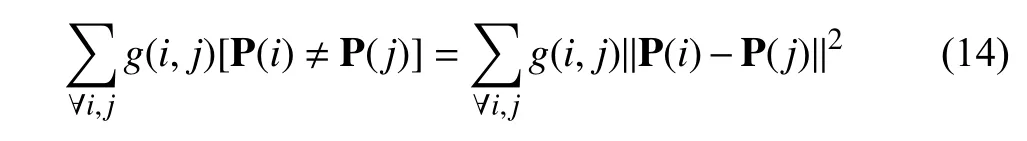
whereg(i,j) is a matrix of pairwise discontinuity costs or an affinity matrix.The right-hand side above is a particularly straightforward quadratic relaxation of the Potts model [49]that works for relaxed P ∈[0,1] corresponding to a typical soft-max output of CNNs [17].
Inspired by [48],we use a modified quadratic relaxation of the Potts model [49] to simplify the energy formulation:
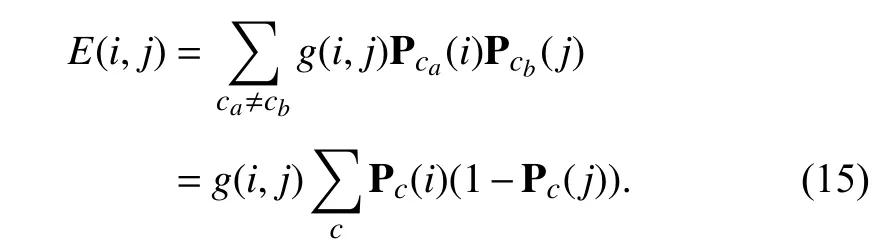
The affinity matrixg(i,j) is based on a dense Gaussian kernel which makes full use of pixels position and RGB color.We can see that the Potts model [49] penalizes disagreements between the pairs of pixels only based on the spatial and appearance information of the pixels,and there is no need for any supervision information of groundtruth.
The dense CRF loss [17],[47],[48] can be represented as follows:
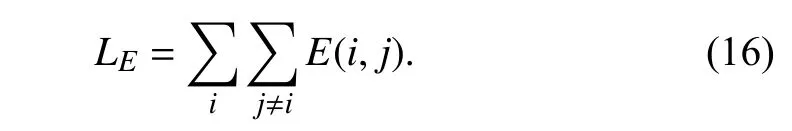
As we all know,the difficulty for the segmentation task is the segmentation of the object’s boundary.In this task,since scribbles have only limited pixels as supervision,it is more difficult to obtain accurate boundary segmentation masks.In order to better segment the boundary regions,we divide the predicted mask into three subregions by predicted mask scores.Specially,we identify pixels with scores larger than 0.3 as reliable foreground pixels,and smaller than 0.05 as reliable background pixels.The remaining pixels are classified as unreliable areas.Then,we assign different loss weights to these areas.Based on this idea,we design a scribblesupervised (SS) loss:
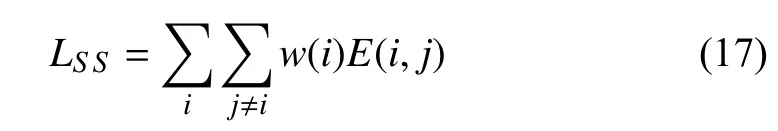
wherew(i) is an adaptive region weight and can be represented as follows:

where β controls the weight of the scribble-supervised loss on unreliable regions.
For each prediction branch,we deploy a new joint loss function combining the partial cross-entropy loss with the designed scribble-supervised loss function:
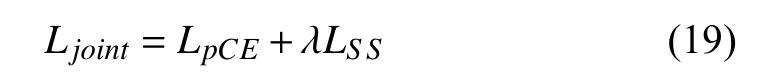
where λ controls the weight of the scribble-supervised loss.
E.Scribble Simulation Generation
Compared with per-pixel labels,scribbles greatly reduce the expensive cost of annotation.However,it is still costly to manually draw scribble-level labels for each object in a largescale video dataset.In order to reduce the annotation cost of video tasks,Liuet al.[50] designed an interactive computer vision system to allow a user to efficiently annotate motion.Karasevet al.[51] proposed a frame selection method for video annotation,which naturally allows for uncertainty in the measurements,and thus is applicable to both an automated annotation,as well as a manual annotation.Luoet al.[52]used an active learning framework to obtain higher segmentation accuracy with less user annotation.Differently from the above methods,we are inspired by [53] to simulate scribble-level annotations on each video frame from two available per-pixel annotated datasets,YouTube-VOS [54],and densely annotated video segmentation (DAVIS)-2017[55].In these two datasets,as all video frames are provided with per-pixel annotations,we can obtain the scribbles of all video frames by leveraging the proposed scribble simulation generation process.For each video frame,we use morphological skeletonization [56] to automatically generate realistic foreground object scribbles and randomly generate a rectangular box as the background scribbles.As shown in Fig.5,the whole process consists of four steps:1) Foreground skeletonization:we achieve the skeletonization of the perpixel annotated masks to get foreground scribbles by using a fast implementation of the thinning algorithm [56].2)Morphological dilation:these scribbles directly obtained through the thinning algorithm in Step 1 are a single-pixel width.These single-pixel width scribbles have a gap to the manually annotated scribbles.Therefore,we use a morphological dilation algorithm to obtain the five-pixel width scribbles.Then,we use the original per-pixel annotated mask and the obtained scribble-level mask to conduct dot multiplication to eliminate the pixels which are extended to the background due to morphological expansion.We use these scribbles as the final foreground object scribbles.3)Background generation:We randomly generate a five-pixel width rectangular box as the background scribble in the background area around the foreground scribbles.When the foreground object touches an edge of the image,the rectangular edge corresponding to the edge of the image will not be needed,e.g.,the background scribble in Fig.3.4) We label the areas outside of the foreground and background scribble regions as unknown areas.
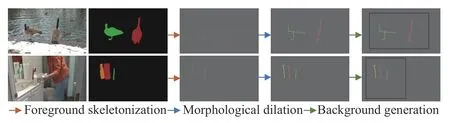
Fig.5.Illustration of scribble simulation generation.From left to right:RGB images,per-pixel ground-truth annotations,foreground scribbles,dilated foreground scribbles,final scribbles annotations (best viewed in amplification).
IV.ExPERIMENTS
The proposed algorithm is evaluated on two most recent VOS benchmark:YouTube-VOS [54] and DAVIS-2017 [55]dataset.We first conduct ablation studies on YouTube-VOS[54].Then,we compare it with the state-of-the-art VOS methods on both YouTube-VOS [54] and DAVIS-2017 [55]datasets.
A.Datasets
YouTube-VOS:The YouTube-VOS consists of 3 471 and 474 videos in the training and validation sets,respectively,being the largest video object segmentation benchmark.Each video sequence is 20 to 180 frames long and every fifth frame is annotated.In the training set,there are 65 unique object categories which are regarded as seen categories.The validation set contains 91 unique object categories,which contain all the seen categories and 26 unseen categories.
DAVIS2017:The DAVIS2017 is a popular benchmark dataset for VOS tasks which is a multi-object extension of DAVIS2016 [57].In the training set,there are 60 video sequences with multiple annotated instances.The validation and test-dev sets include 30 video sequences with multiple annotated instances,respectively.
B.Evaluation Metrics
We evaluate experiment results using three usual evaluation measures suggested by [58]:1) Region similarityJ:The mean intersection-over-union (mIoU) between the ground truth and the predicted segmentation masks.2) Contour accuracyF:TheF-measures of the contour-based precision and recall between the contour points of the ground truth and the predicted masks.3) Overall score G:The average score ofJandF.For the YouTube-VOS dataset,bothJandFare divided into two different measures,depending on whether the categories of the validation are included in the training set(JseenandFseen),or these categories are not included in the training set (JunseenandFunseen.
C.Implementation Details
Our framework is based on the A-GAME [9],which is the state-of-the-art in semi-supervised VOS.Our network is implemented based on PyTorch [59].We choose Adam [60]as the optimizer to minimize the joint loss.Adam is an algorithm for first-order gradient-based optimization of stochastic objective functions which is based on adaptive estimates of lower-order moments.Following [9],we divide network training into two stages.In the first stage,we train for 80 epochs on half resolution images (240×480).We set batch size to 4 video snippets and set 8 frames in each snippet.We set a learning rate of 1 0−4,exponential learning rate decay of 0.95 each epoch,and a weight decay of 10−5.In the second stage,we train 100 epochs on full image resolution.The batch size is set to 2 snippets,to accommodate longer sequences of 14 frames.We set a learning rate of 1 0−5,exponential learning rate decay of 0.985 each epoch,and a weight decay of 1 0−6.In both stages,we set the hyper parameters γdand γrof the Gaussian kernels bandwidths to 100 and 15,respectively.We set the scribble-supervised loss weight λ to 2× 10−15and set the unreliable region weight β to 0.1.We determine all hyperparameters via experience and grid search method.To show that they are the best settings,we vary these hyper-parameters in different ways,measuring the change in performance on the YouTube-VOS dataset [54].In Table II rows A and B,we vary the learning rateslr1andlr2in the two training stages,respectively.Each overall score decreases to varying degrees.In rows C and D,we observe that the overall score decreases to varying degrees when varying the hyper-parameters γdand γrof the Gaussian kernels bandwidths.In rows E and F,we vary the loss weight λ and region weight β.Each overall score decreases to varying degrees.These ablation experimental results prove that we can choose the best settings of the hyperparameters via experience and grid search method.
D.Ablation Studies
We conduct ablation studies on YouTube-VOS to verify the effectiveness of the scribble attention module and scribblesupervised loss.We compare our baseline with different variant models and the quantitative results for different models are shown in Table III.We also show qualitative comparison results in Fig.6.“pCE” denotes our model training on the scribble labels with the partial cross-entropy loss which can be seen as our baseline.“SA” denotes the proposed scribble attention module.“PSA” denotes the pointwise spatial attention module [61].“NL” denotes the nonlocal module [41].“CCA” denotes the criss-cross attention module [62].“SS” denotes the proposed scribble-supervised loss.“DCRF" denotes the dense CRF loss [17],[47],[48].“ ✓” denotes the model with the corresponding module.
Analysis on Scribble Attention Module:We first analyze the impact of the proposed scribble attention module.To confirm its effectiveness,we compare the performances of the baseline and its variant by adding the proposed scribble attention module.The second row of Table III shows the result of adding the scribble attention module to our baseline model.The overall score increases by more than 3.5% compared with our baseline model (first row of Table III).Fig.6 shows some qualitative results and the segmentation results (second column of Fig.6) with our scribble attention module are greatly improved compared to the baseline model.These quantitative and qualitative comparison results demonstrate usefulness of the proposed scribble attention module for this scribble-supervised video object segmentation.To further demonstrate the effectiveness of the proposed scribbleattention module in this special scribble-supervised task,we replace our scribble attention module with three recent attention modules,“PSA” [61],“NL” [41] and “CCA” [62].As shown in Table III,“PSA”,“NL” and “CCA” all achieve better performance compared with our baseline model,which demonstrates that the self-attention mechanism is able to capture contextual dependencies and is helpful for the VOS task.Compared with the proposed scribble attention module,the overall scores of “PSA”,“NL” and “CCA” drop from 47.8 to 46.5,46.6,and 46.9,respectively.The second and third columns of Fig.6 show the quality results of “SA” and“CCA”,respectively.We can see that the segmentation results of “SA” are better than those of “CCA”,such as human leg area.These quantitative and qualitative comparison results further demonstrate the superior performance of our scribble attention module.

TABLE IIG OVERALL SCORE UNDER DIFFERENT HYPER-PARAMETERS SETTINGS.“BASE” INDICATES THE BASE HYPER-PARAMETERS SETTINGS WHICH ARE USED IN THIS PAPER.UNLISTED VALUES ARE IDENTICAL TO THOSE OF THE BASE HYPER-PARAMETERS SETTINGS
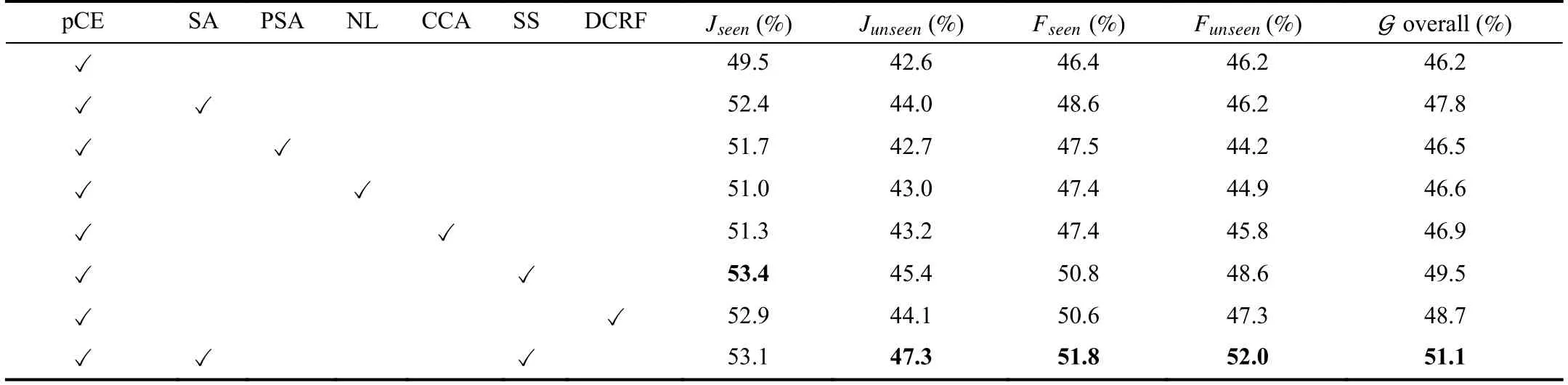
TABLE IIIABLATION STUDIES ON YOUTUBE-VOS DATASET
Scribble-Supervised Loss:Another ablation study is carried out on the use of the proposed scribble-supervised loss by adding it to the baseline model.The sixth row of Table III shows the quantitative result of our baseline with the proposed scribble-supervised loss.Experimental results show that the overall score increases by more than 7.1% compared with the baseline model (first row of Table III).In addition,the other four indicators have also been greatly improved with proposed scribble-supervised loss.As shown in Fig.6,compared with the baseline model (first column of Fig.6),the segmentation quality (fourth column of Fig.6) becomes much better with using the scribble-supervised loss.The baseline model can only segment out the general shape of the objects and the model with scribble-supervised loss can segment out the boundaries and details of the objects.For example,the boundary segmentation results of the man and the tennis racket are rough by the baseline model.Our scribblesupervised loss greatly improves the segmentation results.These quantitative and qualitative comparison results demonstrate that the proposed scribble-supervised loss can indirectly compensate for missing information in weak scribble-level labels.In order to further show the segmentation effects of our scribble-supervised loss on the boundary area,we replace our scribble-supervised loss with dense CRF loss.The overall score decreased from 49.5 to 48.7.As shown in Fig.6,the boundary segmentation results of the man with dense CRF loss (fifth column of Fig.6) are worse than those with scribble-supervised loss (fourth column of Fig.6).These quantitative and qualitative comparison results demonstrate that our scribble-supervised loss can dynamically correct inaccurately segmented areas.

Fig.6.Quality comparison of different variant modules on Youtube-VOS.The first column to the sixth column are “pCE”,“pCE” with “SA”,“pCE” with“CCA”,“pCE” with “SS”,“pCE” with “DCRF”,and our complete model,respectively.
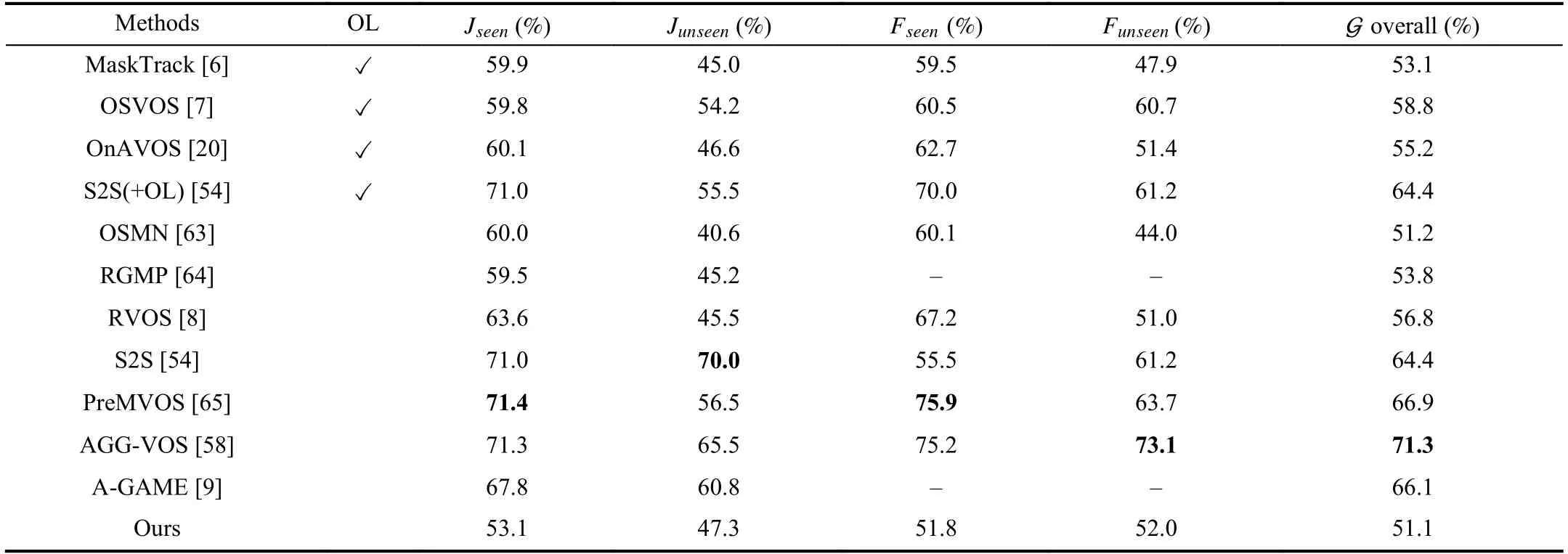
TABLE IVQUANTITATIVE RESULTS ON THE YOUTUBE-VOS VALIDATION SET.“OL” DENOTES ONLINE LEARNING
We also show the quantitative (eighth row of Table III) and qualitative (sixth column of Fig.6) results of our complete model which demonstrate that combining scribble attention module and scribble-supervised loss is able to further improve the segmentation results.
E.Comparison With State-of-the-Art
To our best knowledge,there are no published results for weakly-supervised VOS tasks to be compared on YouTube-VOS [54] and DAVIS-2017 [55].We first compare our approach with the state-of-the-art semi-supervised methods on YouTube-VOS [54].Then,we compare our approach with the state-of-the-art unsupervised methods and semi-supervised on DAVIS-2017 [55].
YouTube-VOS:The validation set of this large-scale dataset contains 474 sequences with 91 categories,26 of which are not included in the training set.We evaluate our method on this validation set and evaluate the results on the open evaluation server [54].Table IV shows the comparison with previous start-of-the-art semi-supervised methods on YouTube-VOS [54].“OL” denotes online learning in the inference stage.Our method achieves 51.1 % of overall scores using scribbles as supervision and without online learning.We obtain almost the same overall scores like [63].Our method reaches comparable results to [6],[20],[64].The gap between our method and [20],[8] is very small.Compared with [7],[9],[54],[58],[65],although there is a certain gap in overall scores,this result is acceptable in view of the huge gap in supervision information.Our method closes the gap to approaches trained on per-pixel annotation.
Besides,to our best knowledge,end-to-end recurrent network for video object segmentation (RVOS) [8] is the only one that published the results for zero-shot (unsupervised)VOS tasks in YouTube-VOS.Table V shows the quantitative comparison results of our scribble-supervised method with RVOS.We can see that although RVOS uses the per-pixel annotations as supervision during the training phase,our results are still far better than those of RVOS.One of the possible reasons for this is that our method provides the scribble annotation of the first frame in the testing phase,which is able to provide a certain prior knowledge of the objects.
DAVIS2017:The dataset comprises 60 videos for training,30 videos for validation,and 30 videos for testing.Following[9],we first train on the Youtube-VOS and DAVIS2017 training sets and then evaluate to boost the performance.We evaluate our method on both the validation and test-dev setsand evaluate the results of the test-dev set on the open evaluation server [55].Table VI shows the quantitative comparison results on the DAVIS-2017 validation set of our method to the recent start-of-the-art unsupervised and semisupervised methods.We can see that our method achieves 55.7% ofJ&FMean using scribbles as supervision.Compared with unsupervised methods,our method exceeds [8] largely,and exceeds [13] to some extent.The gap between ours and[37] is very small.Compared with semi-supervised methods with per-pixel annotations as supervision,our method exceeds [63].Our method reaches comparable results to [15],[66].The gap between our method and [7],[8] is very small.Table VII shows the quantitative comparison results on the DAVIS-2017 test-dev set.Our method achieves 41.7 % ofJ&FMean and exceeds the most unsupervised methods [8],[13],[15].The large performance gap is due to the difference of the supervised information,which is acceptable.Compared with semi-supervised methods with per-pixel annotations as supervision,our method exceeds the semi-supervised method[63].The gap between our method and [67],[66] is very small.

TABLE VQUANTITATIVE RESULTS FOR ZERO-SHOT METHODS IN THE YOUTUBE-VOS DATASET
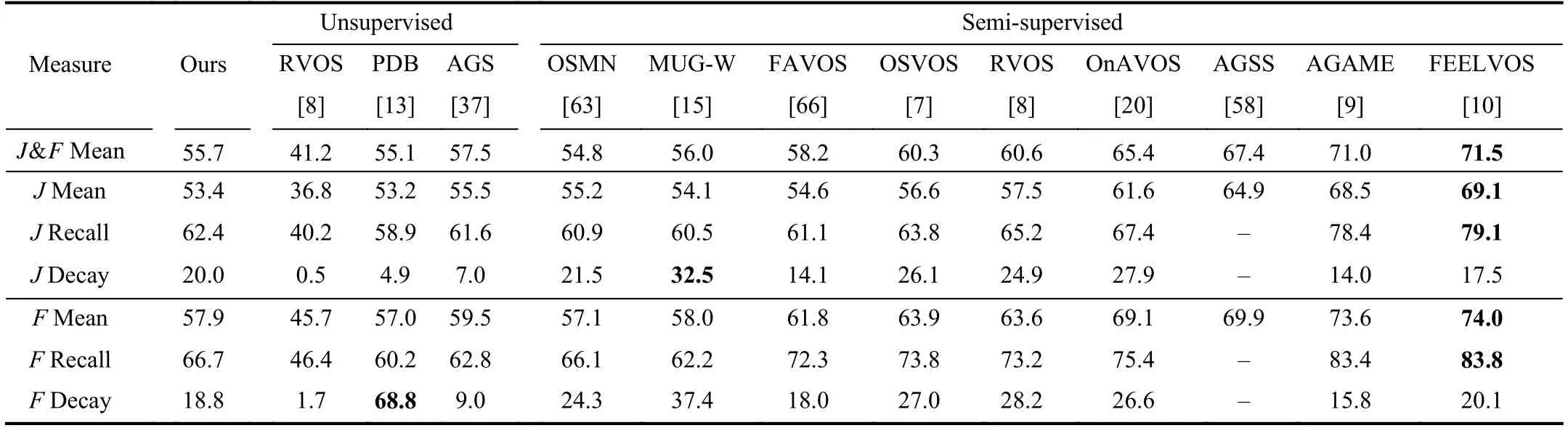
TABLE VIQUANTITATIVE RESULTS ON THE DAVIS2017 VALIDATION SET
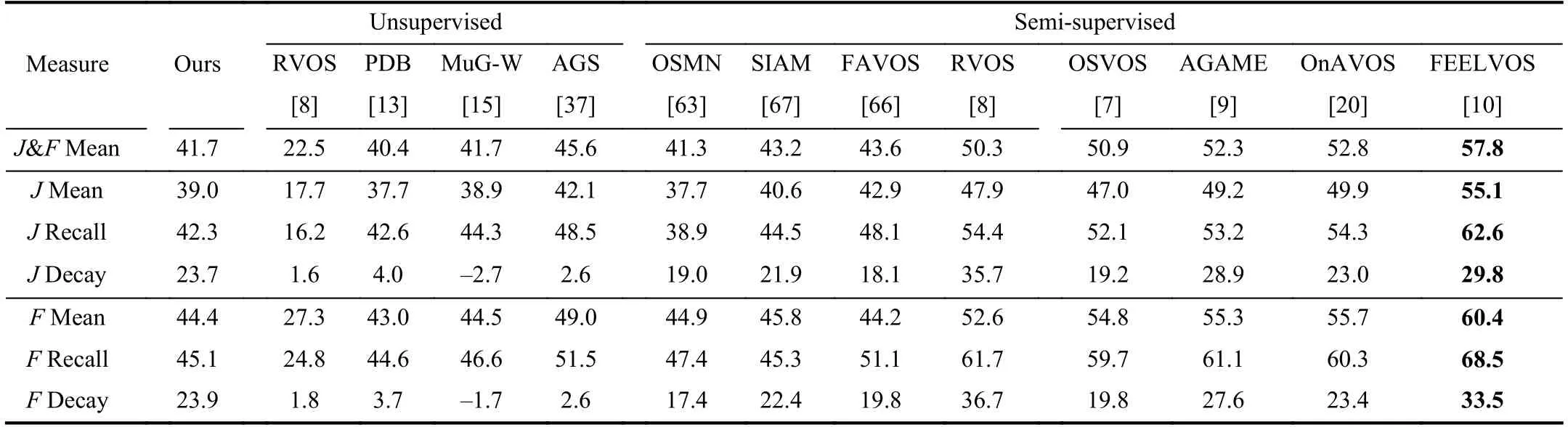
TABLE VIIQUANTITATIVE RESULTS ON THE DAVIS2017 TEST-DEV SET
F.Qualitative Results
Fig.7 shows the qualitative results of our methods on YouTube-VOS [54] and DAVIS-2017 [55].These videos all contain at least one object with diverse size,shape,motion,and occlusion,etc.It can be seen that in many cases our method can produce high-quality segmentation results.For example,our method is able to successfully segment the challenging motorcycle sequence (first row) in which objects move very fast.In the bmx-trees sequence (fourth row),the objects move fast and parts of objects are occlusion by the tree in some frames.Our method can successfully segment out people and the bike from these occlusion areas.In the last row,our method fails to segment some bottom edges of the car in the start frame.However,afterward,our method is able to recover from that error.
G.Failure Case

Fig.7.Qualitative results showing objects on videos from the Youtube-VOS and DAVIS2017.The first second rows are from Youtube-VOS validation set;the latter two are from DAVIS2017 validation set and test-dev set,respectively.

Fig.8.Illustration of two failure cases on DAVIS-2017.The first row is the paragliding-launch video sequence,where the paragliders ropes are not segmented out properly.The second row is the pigs video sequence,where the segmentation results of the later frames are worse.
While our approach verifies satisfactory results on both the quantitative and the qualitative evaluations in YouTube-VOS[54] and DAVIS-2017 [55],we find a few failure cases as shown in Fig.8.In the first row,our method fails to segment out paragliders’ ropes.It is because we fail to simulate generating scribbles of very small objects and thus scribbles of paragliders ropes are not well provided in the first frame during the inference stage.We believe that a good future direction is to generate more reliable scribbles with a better simulation generation algorithm.We can also use other data processing methods to handle the problems of the scribbles,such as [68]–[71].In the second row,we found that our method may be less stable to segment these frames which are far from the first frame.Since we take the scribbles as the guidance information in the first frame,these scribbles only occupy the limited pixels information of the objects.It is mostly because the model is difficult to propagate the limited guidance information from the first frame to the too far frames on very challenging scenes.The challenging scenarios can be resolved by incorporating the spatiotemporal information encoding module [72],which will be our future direction.In addition,we can also use other advanced technologies of image segmentation and deep learning [73]–[76] to further improve the performance of the failure cases.
V.CONCLUSIONS AND FUTURE WORK
In this paper,we propose a scribble-supervised method for video object segmentation.The first contribution of our method is the scribble attention module,which is designed to selectively learn the relationship between the context regions and the query position.Unlike conventional self-attention modules which consider all the context information,with this selective strategy,our attention module can capture more accurate context information and learn an effective attention map to enhance the contrast between the foreground and the background.Furthermore,to resolve the missing information of scribble-level annotations,we propose a novel scribblesupervised loss that can compensate for the missing information and dynamically correct inaccurate prediction regions.The proposed method alleviates a huge amount of human labor than that of the per-pixel annotation and closes the performance gap to approaches trained on per-pixel annotation,which achieves the trade-off between annotating efficiency and model performance.Therefore,it is of great significance to further exploit weakly supervised method[77]–[80] to learn video object segmentation.In future,we plan to explore the potential of using a new simulation method to generate more reliable scribbles and incorporating the spatiotemporal information encoding module [72],[81] to better propagate guidance information throughout the video sequence.
 IEEE/CAA Journal of Automatica Sinica2022年2期
IEEE/CAA Journal of Automatica Sinica2022年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Sampling Methods for Efficient Training of Graph Convolutional Networks:A Survey
- Fault Accommodation for a Class of Nonlinear Uncertain Systems With Event-Triggered Input
- Precise Agriculture:Effective Deep Learning Strategies to Detect Pest Insects
- Maximizing Convergence Speed for Second Order Consensus in Leaderless Multi-Agent Systems
- Exponential Set-Point Stabilization of Underactuated Vehicles Moving in Three-Dimensional Space
- An Adaptive Rapidly-Exploring Random Tree