
Sampling Methods for Efficient Training of Graph Convolutional Networks:A Survey
2022-01-25 12:50XinLiuMingyuYanLeiDengGuoqiLiXiaochunYeandDongruiFanSenior
Xin Liu,Mingyu Yan,Lei Deng,,Guoqi Li,,Xiaochun Ye,and Dongrui Fan, Senior
Abstract—Graph convolutional networks (GCNs) have received significant attention from various research fields due to the excellent performance in learning graph representations.Although GCN performs well compared with other methods,it still faces challenges.Training a GCN model for large-scale graphs in a conventional way requires high computation and storage costs.Therefore,motivated by an urgent need in terms of efficiency and scalability in training GCN,sampling methods have been proposed and achieved a significant effect.In this paper,we categorize sampling methods based on the sampling mechanisms and provide a comprehensive survey of sampling methods for efficient training of GCN.To highlight the characteristics and differences of sampling methods,we present a detailed comparison within each category and further give an overall comparative analysis for the sampling methods in all categories.Finally,we discuss some challenges and future research directions of the sampling methods.
I.INTRODUCTION
A fairly large number of data in the real world contain complex information representations and exhibit a natural graphical structure,for example,the structure of proteins [1],traffic networks [2],[3],and knowledge graphs[4],[5].Analyzing the graph data has frequently appeared in various research fields in recent years and gradually becomes a critical task of deep learning.Typically,the types of data that deep learning models process mainly include image,text,voice,and video.These data are Euclidean structures,and can be regarded as many regular sample points in the Euclidean space [6].However,graph data are typical non-Euclidean data and are difficult to process using general deep learning models.Therefore,motivated by some conventional deep learning methods,many modified models are proposed to process graph data.Graph neural network (GNN) [7] is one of the most influential models.Distinctly,besides the natural advantage of processing graph data,GNN is explainable and can be efficiently used in various reasoning tasks [8]–[14],which makes GNN a highly available model in a practical and theoretical manner.Herein,despite several variants of GNN models [15]–[23],we pay intensive attention to graph convolutional networks (GCNs) [21],which outperform many graph deep learning models in various graph-based tasks.
GCN shows excellent efficiency in learning graph representations and has become a research hotspot in both industry and academia.However,training GCN is a no picnic task and generally requires non-trivial cost in terms of computation and storage.Some previous works have explored improving GCN training by leveraging model-based optimizations,e.g.,model simplification [24]–[26] and knowledge distillation [27],[28],to reduce the training cost,which provides a great leap for efficient GCN training.From another perspective,it is also observed that the original training approach used in GCN [21]generally uses a full-batch approach that has two main limitations.
Inefficiency:The full-batch training approach causes a slow convergence of gradient descent since parameters of the model are updated only once in every epoch.The full-batch parameter update in training slows down the convergence of training and leads to lower training efficiency.
Poor-Scalability:The full-batch gradient is computed according to all intermediate embeddings from the entire graph,making it difficult to scale the training to large graph data.In consequence,training GCN with the original fullbatch approach generally requires considerable cost in time and high requirement in storage,which is not efficient and scalable for large graph data.
To overcome the limitations of the conventional training approach,sampling methods are proposed and have achieved considerable performance.In statistics,the sampling method refers to taking a part of individuals from the target population as a sample.Then,a reliable estimation or judgment is obtained by observing the interested attributes of the sample.Similarly,sampling methods used in training GCN are performed by selecting partial nodes in a graph as a sample based on the specific rule.After sampling,the embedding of one node can be aggregated based on the sampled neighbors’embeddings.Instead of using all neighbors in the conventional training approach,sampling methods construct mini-batches and assuredly reduce the computation and storage cost for GCN training with acceptable accuracy loss,simultaneously ensuring the efficiency and scalability in training GCN.
Sampling methods benefit GCN training in terms of efficiency and scalability,and a well-designed sampling method definitely makes the training process more efficient.Recently,vast data are sampled and fed into graphics processing unit (GPU) for shallow neural network training.Instead of computation in neural networks,the research focus has gradually switched to graph data sampling and aggregation.Distinctly,the aggregation phase is a computeintensive process,where the embedding of one node is aggregated recursively based on all sampled neighbors’embeddings.However,with the dramatic growth of graph data,the sampling phase is becoming a time-consuming process,which affects the efficiency of the aggregation phase,and even the entire training,to a large extent.Therefore,sampling is a critical phase in GCN training and needs to be well considered,especially in learning large-scale graphs.Some existing surveys of graph neural network models [6],[29]–[31] mainly focus on model variants and applications,lacking a detailed review in terms of sampling methods.
In this paper,we provide a thorough survey on sampling methods in different categories.To summarize,we highlight our contributions as follows:
1) We systematically categorize sampling methods in the existing works based on the sampling mechanisms and provide a thorough survey on sampling methods in all categories.
2) We compare sampling methods from multiple aspects and highlight their characteristics.For summarization and analysis,we put forward comparisons for sampling methods within each category and further give an overall comparative analysis for sampling methods in all categories.
3) We propose some challenges based on the overall analysis and discuss some potential directions of sampling methods in the future.
The rest of this paper is organized as follows.In Section II,we first introduce the background of the GCN model and sampling methods,then we present a taxonomy for sampling methods.Based on the taxonomy,we divide sampling methods into four categories and further introduce different categories of sampling methods in Section III.Besides,for sampling methods in each category,we highlight the characteristics of each method and give a detailed comparison within each category from multiple aspects.In Section IV,we present comprehensive comparison and analysis for sampling methods in all categories.In Section V,we first put forward various challenges faced by the existing sampling methods based on the overall analysis and then discuss some potential directions in the future.Finally,we conclude this paper in Section VI.
II.BACKGROUND AND CATEGORIZATION
In this section,we first outline the background of GCN.To introduce the important concept of sampling,we highlight the training process of GCN.Moreover,we present our taxonomy for sampling methods and divide sampling methods into four categories.
A.Background of GCN
1) Model:Recently,there is an increasing interest in applying convolutions to graph tasks.Inspired by the wide use and the remarkable success of convolutional neural networks(CNNs) [32] in deep learning,the spectral CNN is proposed by Brunaet al.[23].Given a weighted graphG,the index set ofGis defined asI,and the eigenvector of the graph LaplacianLis defined asV.The proposed model extends convolution via the Laplacian spectrum.It takes a vectorxkof size |I| ×fk−1as the input of thek-th layer and outputs a vectorxk+1of size |I| ×fk.The aforementioned graph convolution layer is defined as
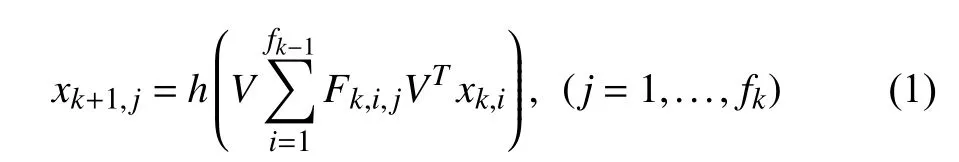
wherehis an activation function andFk,i,jis a diagonal matrix of learnable parameters of the filter at thek-th layer.However,the aforementioned graph convolution operation results in potential high computation cost and bad spatial localization.For every forward propagation,the multiplications betweenV,Fk,i,j,andVTlead tocomputation complexity.Besides,the non-parametric filters also have several limitations:They are not localized in the vertex domain and their learning complexity of the parameters in each layer isO(n).
To overcome these drawbacks,ChebNet [19] uses the Chebyshev polynomial of the diagonal matrix of eigenvalues to approximate the filtergθ.That is

Based on the special variant of the ChebNet [19],GCN [21]is proposed by Kipf and Welling for semi-supervised classification of nodes in a graph.Specifically,GCN introduces a first-order approximation of the ChebNet,that is,Kis fixed as 1 and λmaxis fixed as 2 in (3).Under this special condition,(3) is simplified as
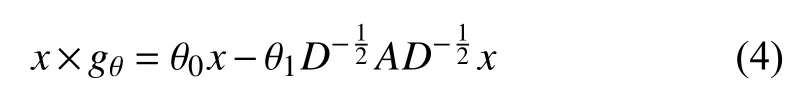
whereAis an adjacency matrix andDis a degree matrix.To constrain the number of parameters,under the assumption that θ=θ0=−θ1,the graph convolution can be rewritten as

Herein,Hkis the hidden representation matrix in thek-th layer of GCN,and Wk is the trainable matrix that corresponds to the weights ink-th layer of GCN.σ(·) denotes a specific activation function,such as ReLU and Softmax activation function.
So far,we have introduced the GCN model [21] and some basic models [19],[23] for inspiration.Typically,the common ground between these models is that the construction of graph convolutions is based on filters from the aspect of the signal processing field [33].Thereby,these models are categorized as spectral-based models in the existing surveys [6],[29]–[31].In contrast,another perspective that defines the graph convolutional operation on a spatial dimension is devoted to capturing the relationship between the target node and its neighbors,which is inspired by the application of performing CNNs on images.Such models generally apply graph convolutional layers to a neighboring node region and compute the representation of a target node from its neighbors in diverse approaches,e.g.,diffusion-convolutional neural networks (DCNNs) [17],message passing neural networks(MPNNs) [34],GraphSAGE [35].And these models are categorized as spatial-based (non-spectral) models in the existing surveys [6],[29]–[31].As a bridge,GCN [21] fills the gap between spectral-based models and spectral-based models and provides both practical and theoretical supports for building novel graph convolutional networks.
2) Limitations:Due to the attractive universality and efficiency of GCN,innovative applications using GCN to process multiple types of data have appeared in various fields[1],[4],[36]–[41].However,there are some limitations in GCN.The conventional training approach used in GCN is inefficient.Distinctly,by observing (6),GCN uses a graph convolution operation to learn the embeddings of nodes in each layer under a top-down order.In this process,one node’s embedding is computed by aggregating the embeddings of the neighboring nodes in a recursive manner.As the model goes deeper,the computation cost of the nodes’ embeddings will become unacceptable.Besides,since the model’s weight matrices are trained using a full-batch gradient descent approach,the model parameters are updated only once in every epoch,which slows down the convergence and ultimately affects the model’s training efficiency.
On the other hand,the conventional training approach used in GCN is also poor in scalability.Since nodes’ embeddings are aggregated recursively from the neighbors’ embeddings layer by layer,the embeddings in the final layer therefore require all embeddings of nodes in the upper layers,bringing about high storage cost.Moreover,the model’s gradient update in the full-batch training approach requires storing all intermediate embeddings,which makes the training unable to extend to large-scale graphs.In original GCN [21],Kipf and Welling built the GCN model using quite shallow neural networks.Recently,with the dramatic expansion of graph data,there is an urgent need to build more complex GCN models for learning large-scale graphs.Thereby,the conventional training approach still requires continuous improvement.
3) Sampling in the Training of GCN:To overcome the limitations of the conventional training approach,sampling methods have been proposed and achieved a significant effect.Fig.1 illustrates a variant of graph convolutional networks with two GCN layers.Like general neural networks,the training process of GCN can be divided into forward propagation and backward propagation.In the forward propagation,a graph and the corresponding features are fed into the model.Then,a graph convolutional layer gets embeddings of nodes after several phases.The final output that includes graph embeddings is obtained by stacking multiple layers.In the backward propagation,the loss between labels and predictions generated in the forward propagation is computed to update the model parameters.Finally,a welltrained model is obtained by repeating the above two processes.To analyze the time-consuming phases,we formally dissect the computation process in one graph convolutional layer and divide the process into three phases[42],[43],namely,sampling,aggregation and combination.As mentioned above,the partial nodes of an entire graph are selected based on a certain standard in the sampling phase.For the aggregation phase,many works [18],[21],[35],[44]recursively aggregate the features from the sampled neighbors of one node.After aggregation,the combination phase updates the node’s feature in the current layer by combining the neighborhood features generated in aggregation with the node’s feature in the upper layer [45],[46].Formally,the typical definition of the above phases is
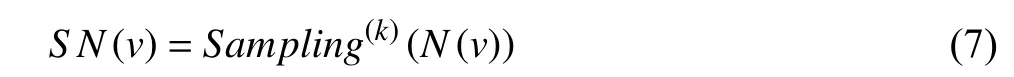
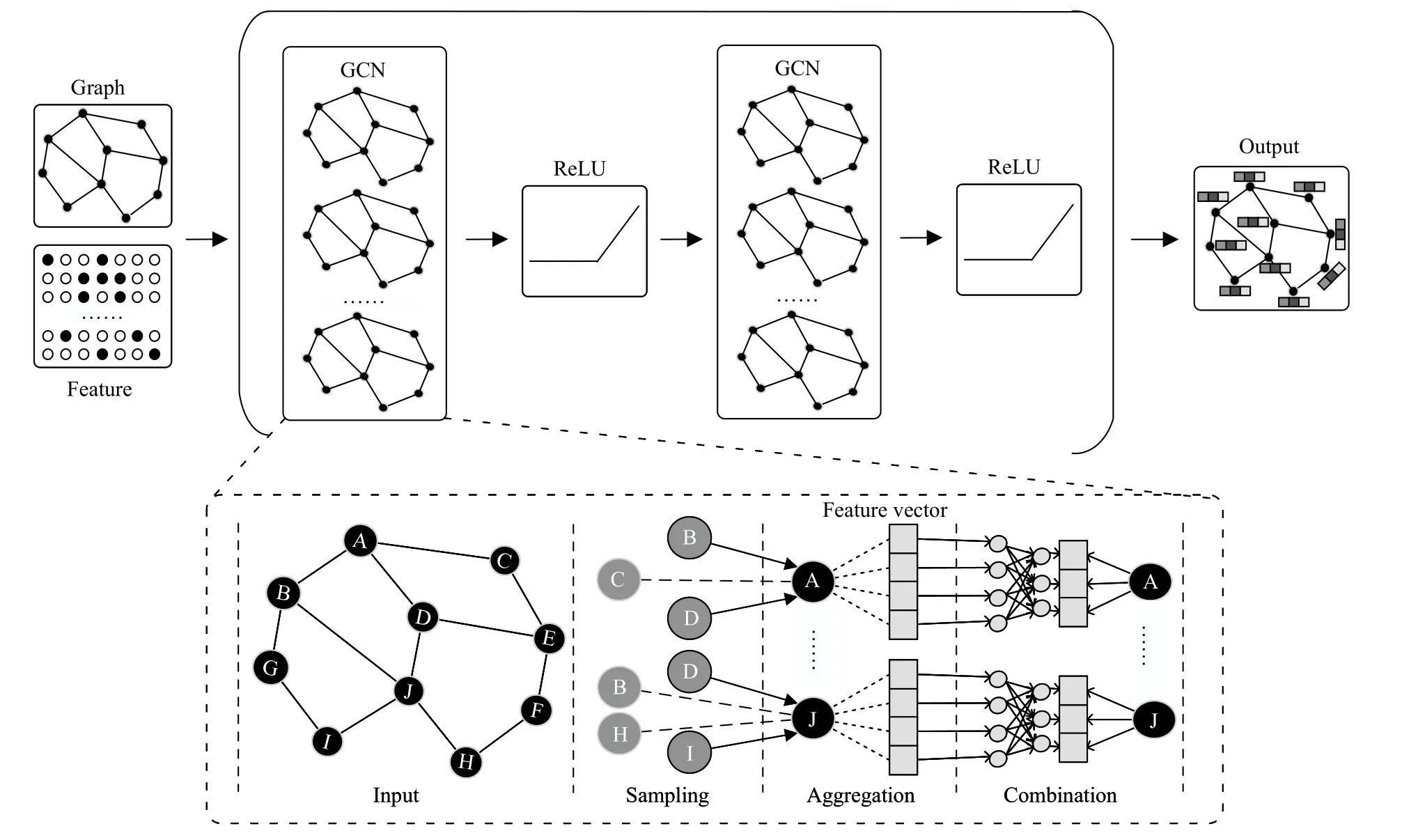
Fig.1.A variant of graph convolutional networks with two GCN layers.Note that in many variants of GCNs,one GCN layer is generally followed by an ReLU activation function or a pooling layer,or a CNN layer,which depends on the model and the graph task.
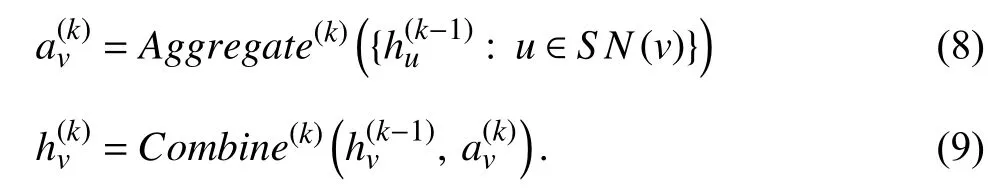
In (7),N(v) is the neighboring nodes of nodev,andS N(v)is the sampled neighbors fromN(v) based on a certain standard.Since all these phases are executed in thek-th layer(iteration),we define thatis the aggregation feature vector of nodevin thek-th layer,andis the representation feature of nodevin thek-th layer.As illustrated in the lower part in Fig.1,the sampling phase selects a part of the neighbors of each node in a graph,for example,nodes B and D are selected for aggregating the representation feature of node A.As the previous step of the aggregation,the function of sampling is to reduce the computation cost for aggregation while maintaining comparable model accuracy.Distinctly,an efficient sampling method can accelerate the aggregation phase greatly and ultimately speed up the training.Considering that sampling methods are different in their mechanisms,we present a taxonomy of sampling methods in Section II-B.
B.Categorization of Sampling Methods
To systematically introduce sampling methods,we divide them into four categories,namely node-wise sampling,layerwise sampling,subgraph-based sampling,and heterogeneous sampling.The taxonomy is based on a special standard that depends on the granularity of the sampling operation in one sampling batch.For sampling methods proposed in the works[35],[44],[47],[48],the sampling operation is applied to each node’s neighbors.A part of neighbors of a single node are sampled in one sampling batch,so we define this kind of sampling methods as the node-wise sampling method;for sampling methods proposed in the works [49]–[51],multiple nodes are sampled simultaneously in the sampling operation in each layer,so we define this kind of sampling methods as the layer-wise sampling method;for sampling methods proposed in the works [52]–[55],a subgraph that is induced from specially chosen nodes (and edges) is sampled in one sampling batch for further computation,so we define this kind of sampling methods as the subgraph-based sampling method;for sampling methods proposed in the works [56]–[59],different types of nodes and edges are sampled in a heterogeneous graph.This kind of sampling methods generally vary with different structures of heterogeneous graphs,and we therefore define this kind of sampling methods as the heterogeneous sampling method.
An illustration of the typical process of sampling methods in the first three categories is shown in Fig.2 (We did not show the process of heterogeneous sampling methods since the heterogeneous sampling is generally fickle).Based on our taxonomy,we systematically introduce the characteristics of sampling methods in each category and put forward detailed comparisons in Section III.The correlative works are given in Table I by category.
III.SAMPLING METHODS
In this section,we introduce sampling methods by category.In each category,we highlight the characteristics for each sampling method and compare them from multiple aspects.It is important to note that most of the sampling methods we introduce in this section are applied to spatial-based GCN models for capturing the relationship between nodes in a neighboring node region.Besides,since most of the sampling methods use common benchmark datasets,we give summary information of these datasets in Table II.
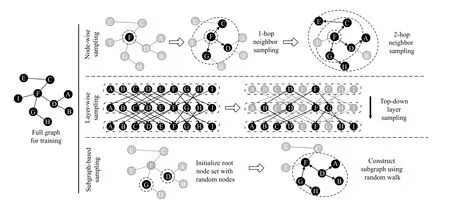
Fig.2.Illustration on the typical sampling process of the sampling method in each category.

TABLE ICATEGORIES AND CORRELATIVE WORKS OF THE SAMPLING METHODS
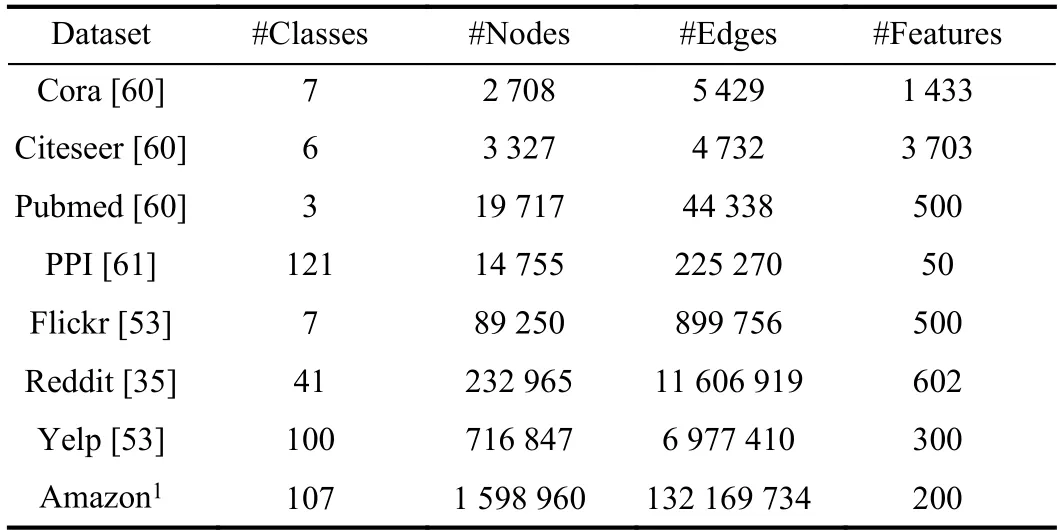
TABLE IISUMMARY INFORMATION OF THE DATASETS
A.Node-Wise Sampling Method
Node-wise sampling method is the fundamental sampling method and is first proposed by some inspiring works.Generally,the common ground between node-wise sampling methods is that they perform the sampling process on each node and sample neighbors based on specific probability.Simply taking the form of the formula in (7),we modify it to be the following form:
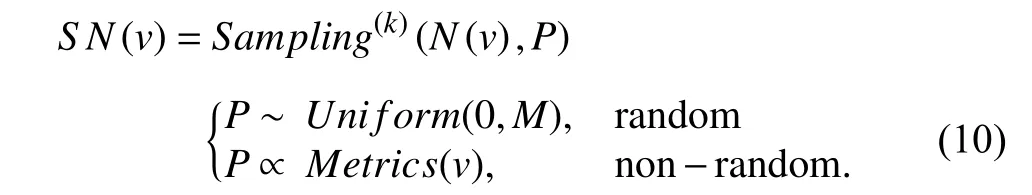
Here,for random sampling,the probabilityPobeys uniform distribution,andMdenotes the maximum number of neighbors to be sampled of nodev.Sampling methods used in works [35],[47],[48] distinctly satisfy the characteristics of random sampling.For non-random sampling,the probabilityPis non-uniform and is proportional to particular metrics of nodev,e.g.,PinSage [44] computes the L1-normalized visit counts to define the topTneighbors and affect the sampling probability,where neighbors with higher L1-normalized visit counts are easier to be sampled.In this case,the metrics-based probability requires the pre-computed metrics before performing the sampling process.
In most instances,it is inflexible and inefficient to sample all neighbors of each node in the training process,and we prefer to add a restricted value to the sampling process for flexibly controlling.Since the sampling size of neighbors cannot be arbitrarily large,we restrict the original sampling size to be an appropriate value and redefine the sampling form as
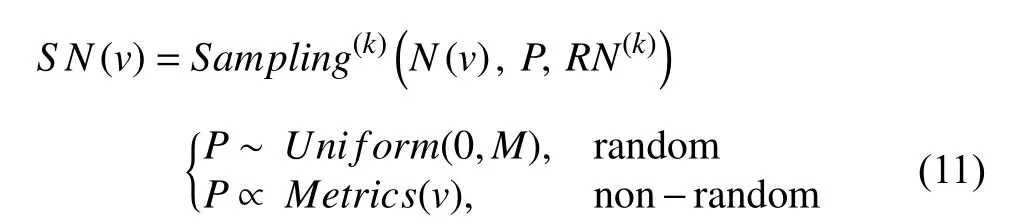
whereRN(k) denotes the restricted number of neighbors to be sampled in one sampling batch in thek-th layer.To a certain extent,most node-wise sampling methods can be abstracted in the form of (11),and the main difference between these methods lies in the unique mechanism added to the original neighbor sampling process.We compare these differences in the last part of this section.Next up,we will introduce some typical works leveraging the node-wise sampling method in detail and highlight each method’s characteristics in the following subsections.
1) GraphSAGE:GraphSAGE [35] is a general framework for learning node embeddings.To train the model efficiently,an inductive process is learned to generate node embeddings using neighborhood sampling and aggregation.Specifically,the sampling operation randomly selects neighbors for each node in the graph,which is closely followed by the aggregation.The aggregation leverages the sampled neighbors’ features and generates the embedding of each node from the top layer to the final layer.Then,the output embedding is used for the model’s weight update and some specific applications.The authors also propose three alternative aggregators,which can be learned in a supervised or unsupervised approach.Detailed pseudocode of the forward propagation algorithm is given in Algorithm 1,which covers the sampling (Lines 2–7 of the algorithm) and aggregation process.

The node-wise sampling method proposed in GraphSAGE corresponds to the typical node-wise sampling process in Fig.2.For each node in the training graph,the sampling method samplesk-hop neighbors by search depth.Then,the sampled neighbors are added to the minibatch node set Bkfor storage.Besides,the authors choose the corresponding sampling size for each depth (layer) in the model by demonstrating the different neighborhood sampling sizes with the impact on the model performance.Distinctly,the node-wise sampling method proposed in GraphSAGE satisfies the form of (11),where the sampling probabilityPobeys uniform distribution,andkis set to 2.Restricted numbers of neighbors to be sampled in the first and second layers are set to 25 and 10,respectively.Then,the sampling process can be specified in a detailed format:
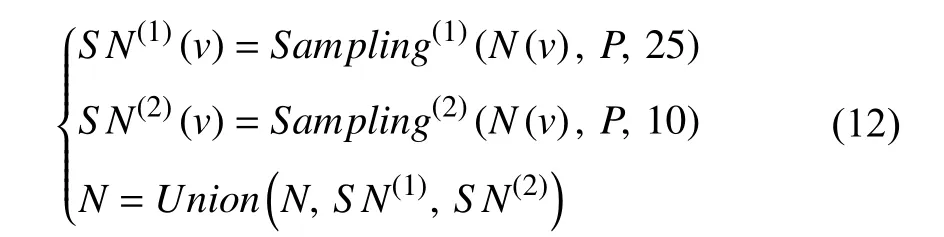
whereNdenotes the node set used for the aggregation process.In this way,2-hop neighbors for aggregation are randomly sampled.And the complexity in time and space per batch is controlled asguaranteeing acceptable and predictable runtime in mini-batch GCN training.
The proposed node-wise sampling method in GraphSAGE has the following characteristics.
a) Heuristic:GraphSAGE first introduces the mini-batch method into GCN training.Instead of using all nodes in the graph,the sampling method randomly selects a fixed number of neighbors of each node to reduce the computation cost.Compared with aggregating all node features for embedding generation,partial neighbors are sampled in a mini-batch that may cause loss of information.Still,GraphSAGE achieves a good trade-off between performance and runtime leveraging the neighborhood sampling.
b) Storage-friendly:The original training approach uses a full-batch approach to compute the gradient.For each training epoch,the whole graph and all intermediate embeddings are required to update the full gradient,leading to high storage cost.The sampling method proposed in GraphSAGE reduces the number of features being aggregated in one batch by restricting the sampling size,which helps to lower the storage requirement in GCN training.
c) Stochastic:The number of neighbors per node (defined asM) is unknowable and stochastic in a training graph.Since the sampling method proposed in GraphSAGE samples a fixed number (defined asN) of neighbors of each node,whenNis larger thanM,the same neighbors will inevitably be sampled multiple times,leading to lots of redundant computation.Therefore,the randomness in the sampling method may cause indeterminacy and thus lower efficiency of training.
2) PinSage:PinSage [44] is a highly scalable framework that designs for the industrial recommender system.Since the user-item network’s transformed graph includes countless nodes and edges,the authors use multiple localized convolutional modules to aggregate the neighborhood representations and generate embedding for nodes.Each convolutional module learns to represent the partial neighborhood information of one node,so that the embedding can be obtained by stacking multiple convolutional modules.The computation of neighborhood representations between nodes uses the hierarchical shared parameters to ensure that the computation complexity has no concern with the size of the input graph.The authors also leverage some tricks,such as negative sampling [63],to optimize the PinSage-based training process and further design a curriculum training approach [64] for faster convergence.The embeddings output by PinSage are used for the candidate generation in the recommender system.
The node-wise sampling method proposed in PinSage is greatly similar to the method in GraphSage [35] at the pseudocode level.Differently,PinSage leverages an importance-based measuring standard to define the neighborhood of one node.The authors perform a random walk simulation that begins with an initial nodevand then compute the nodes’ L1-normalized visit counts [65].One node’s neighborhood is defined as the topTneighbors with the largest normalized visit counts,that is,Tneighbors with the largest L1-normalized visit counts are sampled for one node.The larger normalized visit count a neighbor has,the greater its importance and influence onv.Distinctly,the nodewise sampling method proposed in PinSage satisfies the form of (11),where the sampling probabilityPis non-uniform and proportional to the L1-normalized visit counts.Through experiments and observations,the authors find that a 2-layer GCN with neighbors sizeTset to 50 achieves an optimal trade-off in capturing neighborhood representation and training the model.The sampling process can be specified in a detailed format:
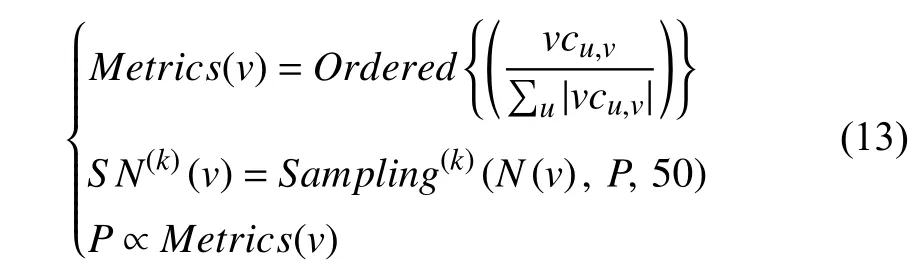
whereuis a neighbor ofv,andvcu,vdenotes the visit counts recorded in the random walk simulation.Sampling probabilityPis proportional toMetrics(v) that includes L1-normalized visit counts in descending order.In this way,PinSage can sample the most influential neighbors for each node in the training graph.
The proposed node-wise sampling method in PinSage has the following characteristics.
a) Storage-friendly:Only the sampled neighbors are used to aggregate the neighborhood vector,which reduces the storage requirement of training the large-scale GCN.Additionally,the node-wise sampling method helps the execution of the localized convolution.PinSage leverages the localized convolution to generate the node embedding in an efficient way,where the dense neural networks that transform neighbors’ representations all share the same parameters.
b) Conditional:The node-wise sampling method benefits sampling and aggregation in a similar manner.Compared with the random neighbor sampling,the conditional neighbor sampling selects the neighbors with the largest normalized visit counts,which makes it possible that the aggregation of the neighborhood vector can be executed using different weight parameters according to the normalized visit counts.
3) SSE:As many graph analytical tasks can be solved using various iterative algorithms,solutions of these algorithms require extensive iterations.These solutions are usually represented by a combination of multiple steady-state conditions,making it inefficient to achieve steady-state solutions.Therefore,the authors design a stochastic learning framework for learning the steady states and design fastlearning algorithms for various graph analysis scenarios.Stochastic steady-state embedding (SSE) [47] is an alternating algorithm proposed to tackle the optimization problem in the stochastic learning framework.


The proposed node-wise sampling method in SSE has the following characteristics.
a) Asynchronous:The update of embeddingis executed asynchronously between the sampled nodes.The reason is that the computation complexity of synchronous updates is costly,especially when handling large-scale graphs.Besides,the authors [47] only use 1-hop neighbors to update the embedding,which avoids the exponential growth of neighbors and makes asynchronous updates feasible.
b) Alternating:The algorithm alternates between leveraging the operator TΘand 1-order neighborhood representations to update the embedding of the sampled nodes,and leveraging the computed loss via stochastic gradient descent to update the parameters of the operator TΘand the functiong.The authors also find that the model will gain a faster convergence rate and better generalization when the number of inner loops inembedding update is larger than that in parameter updates.

TABLE IIISUMMARY OF THE COMPARISONS AMONG NODE-WISE SAMPLING METHODS
4) VR-GCN:VR-GCN [48] is a stochastic approximation algorithm for efficient GCN training.To alleviate the exponential growth of the receptive field caused by the recursive computation of neighborhood representations,VRGCN leverages a variance reduction technique to restrict the size of sampled neighbors to an arbitrarily small number.Empirically,VR-GCN only Samples 2 neighbors per node,which still achieves a comparable predictive performance compared with some existing methods.

The basic sampling process in VR-GCN is to randomly sampleD(l) neighbors for each nodeuin the set of receptive field in the (l+1) layer,which is shown in the inner loop of Algorithm 3.The node-wise sampling method used in VRGCN can be regarded as a variant of GraphSAGE [35] with a particular restriction that only two neighbors are sampled per node for updating the receptive fieldrand the propagation matrices.The above process can be formally specified as the following form:


The proposed node-wise sampling method in VR-GCN has the following characteristics.
a) Time-saving:Based on the stochastic approximation algorithm,only two neighbors are empirically sampled for each node in one mini-batch.Compared with the original GCN [21] and GraphSAGE [35],the sampled size is arbitrary small,which makes it possible that the time cost of training GCN is relatively small.Besides,the historical activationdoes not need to be computed recursively.
b) Approximated:Neighborhood representation of each node is approximated by the restricted neighbor sampling.Based on the sampled nodes,the embedding is approximated by the historical activation.Further,the approximated gradient is computed for model update leveraging the CV estimator.The approximate method makes the model theoretically converge to a local optimum.
5) Comparisons Within the Category:In the preceding subsections,we have introduced typical node-wise sampling methods.Distinctly,it is common ground that all these methods sample neighbors for each node in a training graph.However,some differences lie in several aspects,e.g.,sampling depth and sampling condition,since not all nodewise sampling methods sample neighbors in a random manner.For summarization and analysis,we put forward some considerable questions and compare these sampling methods from multiple aspects.A summary of the comparisons is given in Table III.
a)How they work?
To analyze the availability of a sampling method,we explain the workflow of these methods based on their sampling conditions in the form of illustration.As illustrated in Fig.3,GraphSAGE randomly samplesk-hop (herein,k=2)neighbors for each node in a recursive manner.As an improvement,VR-GCN optimizes the random sampling strategy by restricting the sampling size,which reduces the receptive field size and guarantees the training convergence.SSE uses a random sampling strategy to sample 1-hop neighbors for updating the embedding and functions(operator).The random sampling strategy used in these methods is simple yet efficient,reducing the training cost in computation and storage compared with the original GCN.Differently,PinSage uses conditional sampling to select neighbors according to normalized visit counts,which guarantees the correlation between the sampled neighbors.
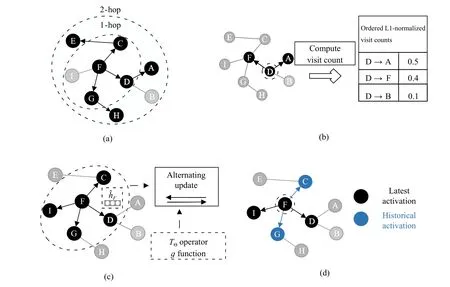
Fig.3.Illustration on the introduced node-wise sampling methods in existing works.(a) 2-hop neighbor sampling in GraphSAGE.(b) Importance-based neighbor sampling in PinSage.(c) Alternating sampling for embedding and function (operator) update in SSE.(d) Neighbor sampling leveraging historical activation in VR-GCN.
b) What is the difference?
Excluding the sampling condition,the differences among these methods are also reflected in some details of neighbor sampling.In the aspect of sampling depth and neighbor extension,GraphSAGE and VR-GCN similarly sampleK-hop neighbors for each node recursively,which leads to the exponential neighborhood extension.PinSage samples neighbors based on the normalized visit counts in a random walk process,but it still cannot avoid the exponential extension of the neighborhood.SSE only samples 1-hop neighbors to maintain neighbors’ linear extension,ensuring efficiency and effectiveness in training.Distinctly,the exponential extension of the neighborhood will bring up significant computation and storage costs,which may deteriorate the efficiency of the method.
c) What is the special?
Typically,GraphSAGE first introduces the sampling strategy into GCN training,bringing inspiration to some works.Some methods modify the original random sampling proposed in GraphSAGE to achieve better performance by adding unique mechanisms.For example,PinSage traverses nodes by simulating a random walk process to compute the visit counts,which helps to sample the most influential neighbors for each node.SSE uses the alternating sampling strategy to sample 1-hop neighbors for embedding computation and labeled nodes for functions update.VR-GCN leverages the historical activation to approximate the embedding,avoiding the recursive computation,which makes it possible that comparable predictive performance is achieved with an arbitrarily small sampling size.
B.Layer-Wise Sampling Method
Layer-wise sampling method is the improvement of nodewise sampling method and generally samples a certain number of nodes together in one sampling step.In this category of sampling methods,since multiple nodes are jointly sampled in each layer,time cost of the sampling process is significantly reduced by avoiding the exponential extension of neighbors.More importantly,a novel view that one can interpret loss and graph convolutions as integral transformations of embedding computation to reduce sampling variance leveraging importance sampling technique,is first introduced in the work[49],which is widely used in later works [50],[51].
To introduce importance sampling and Monte-Carlo approximation,we begin with recalling the forward propagation of GCN [21] in (6) and rewrite the formula as an integral format:
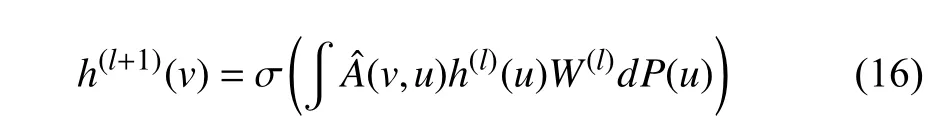
where σ(·) denotes a specific activation function,andis a renormalized adjacency matrix.h(l)(u) andW(l) denote the hidden feature vector ofuand weight matrix in thel-th layer,respectively.And probabilityPis introduced as the sampling distribution to represent various sampling,e.g.,uniform probability for independent sampling and conditional probability for node/layer-dependent sampling.Specifically,in some layer-wise sampling methods,one node is sampled under the influence of other nodes in the current layer,we thereby introduce the impact of other nodes in the form of importance sampling as
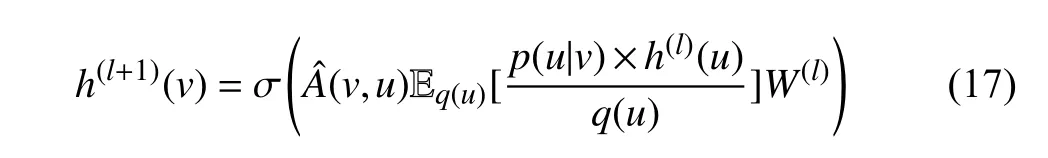
whereq(u) denotes the probability of sampling nodeuunder the condition that all nodes in the current layer are given.In this situation,to accelerate the forward propagation in (17),we specify a concrete instance and apply Monte-Carlo approximation to the expectationµq(v)=Eq(u)[p(u|v)·h(l)(u)/q(u)]:

Practically,there is a distinction between the optimal sampling probabilitiesq∗(u) used in the sampling process among these layer-wise sampling methods.We will show the differences of sampling probability in each work subsequently and compare these methods in the last part of the section to clarify how to reduce the sampling variance.Next up,we will introduce some typical works leveraging the layer-wise sampling method in detail and highlight each method’s characteristics in the following subsections.
1) FastGCN:FastGCN [49] is a fast learning method for training GCN.To alleviate the expensive computation caused by the exponential neighborhood expansion,FastGCN samples a certain number of nodes in each layer independently based on the pre-set probability distribution.Formally,the authors use an integral transformation of the embedding function to interpret the convolution operation in GCN.Further,under the condition that the training graph is an induced subgraph of an infinite graph,the node embedding which is in the form of integrals,can be estimated using the Monte Carlo approach.In this way,the embedding is approximatively evaluated by samplingtlnodes in each layer.Thereby,GCN training can be represented as an inductive learning process and achieve a considerable speedup.
The layer-wise sampling method proposed in FastGCN corresponds to the typical layer-wise sampling process in Fig.2,it samples a certain number of nodes in each layer in a batched manner.Since the main challenge in node-wise sampling methods is the massive neighbors that expand exponentially with the number of layers,the layer-wise sampling method alleviates this heavy overhead by restricting the sampling size in each layer.To reduce the variance,the authors use importance sampling technique to alter the probability distribution.As introduced by us in the previous chapter,to compute the optimal sampling probability that can minimizeas far as possible,FastGCN defines the optimal probability that is proportional to,that is
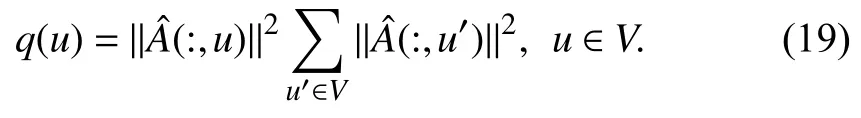
Based on theq(u),tlnodes are sampled in each layer independently,and the inter-layer connections (edges) are reconstructed after the sampling process to link the sampled nodes.Besides,the authors also define vanilla FastGCN which samplestlnodes in each layer uniformly as contrast and has experimentally demonstrated the advantage of importance sampling technique in predicting accuracy used in FastGCN,compared with the uniform sampling used in vanilla FastGCN.Detailed pseudocode of the training process is given in Algorithm 4,which includes the sampling and forward propagation.
The proposed layer-wise sampling method in FastGCN has the following characteristics.
a) Fast:Compared with thek-hop neighbor sampling,the layer-wise sampling method restricts the size of the sampled neighbors in each layer.Since the layer-wise sampling process is independent between layers,the sampled neighbors maintain a linear-growth trend,which avoids the recursive sampling of the multi-hop neighbors.
b) Possibly-sparse:The layer-wise sampling method proposed in FastGCN samples a certain number of nodes in each layer independently,which may cause the situation that the sampled nodes are not connected in two consecutive layers.Thereby,the generated adjacency matrices of the sampled nodes are possibly sparse,which may deteriorate the training and model accuracy.

2) AS-GCN:AS-GCN [50] introduces an adaptive sampling approach into GCN training.It builds a sequential model from the top layer to the bottom layer.The importance of sequentiality lies in that the lower layer’s nodes are sampled according to the upper layer’s nodes conditionally.In this way,the sampled nodes in the lower layer can be efficiently reused in the upper layer since they are shared by their parent nodes.Besides,AS-GCN adds the variance generated by sampling into the loss function and reduces the variance through model training.To efficiently use the remote nodes’information,AS-GCN designs a skip connection to maintain the second-order proximity,which makes it possible that the 2-hop neighbors are directly used without sampling recursively.
The layer-wise sampling method proposed in AS-GCN samples a fixed number of nodes in each layer under a topdown manner.Especially,the lower layer’s nodes are sampled conditionally according to the nodes in the upper layer instead of independent sampling in each layer.The conditional sampling approach ensures the efficient reuse of the sampled nodes.Similarly to FastGCN [49],the authors transform the embedding function to a probability-based form by using importance sampling and accelerate the computation by approximating the expectation in the Monte Carlo manner.They specify the form of the variance of the approximate expectation to be
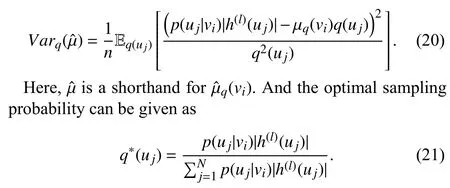
Since the optimal sampling probability is unable to compute due to the chicken-and-egg dilemma that the hidden feature can not be gained until the model is fully built through sampling,AS-GCN approximately replaces the uncomputable part with a linear functiong(x(uj)),that is
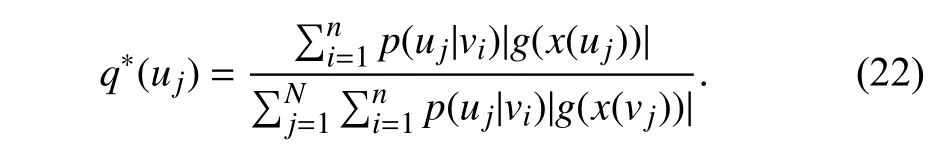
Therefore,the optimal sampling probability can be computed by definingg(x(uj))=Wgx(uj).Besides,the variance caused by the sampler is added to the loss function for minimization during the training.
The proposed layer-wise sampling method in AS-GCN has the following characteristics.
a) Adaptive:The adaptivity of the sampling method lies in two aspects.On the one hand,the training frameworks used in GraphSAGE [35] and FastGCN [49] are compatible with ASGCN by modifying the conditional sampling probability.On the other hand,the sampler used in AS-GCN is parameterized and can be adaptively trained to reduce the variance.
b) Empirical:To obtain the optimal sampler,the authors design a self-dependent functiong(x(uj)) of each node and replace the embedding function withg(x(uj)) to compute the optimal sampling probability.The self-dependent function is empirically defined to be a linear form and assigned asg(x(uj))=Wgx(uj).
c) Efficient:A skip connection is added across the two layers to pass the information across layers over remote nodes efficiently.Since the skip connection mechanism preserves the second-order proximity,the nodes in the (l+1) layer can aggregate the information from the (l) layer and (l−1) layer without extra 2-hop sampling and parameter computation.In this way,the information pass between two layers with large spacing is allowed,and the training is therefore becoming more efficient.
3) LADIES:LADIES [51] is a layer-dependent importance sampling algorithm for training deep GCN models efficiently.Especially,LADIES is designed to solve the challenges of the high overhead in training and sparsity in sampling.On the one hand,the typical neighbor sampling method samples a subset of neighbors of each node in a recursive manner,but it leads to high computation cost which grows exponentially as the neighborhood expands.On the other hand,in some layer-wise sampling methods,many nodes are jointly sampled in each layer independently,which may cause a sparse situation in terms of node connection.
To solve the above two challenges,LADIES performs layer-dependent sampling in a top-down manner.A detailed sampling procedure is given in Algorithm 5.Firstly,LADIES computes the sampling probabilityof each node in thel−1layer according to the layer-dependent Laplacian matrices:
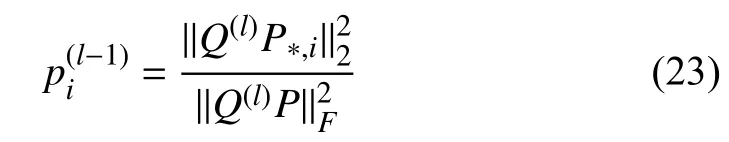
wherePdenotes the modified Laplacian matrix,andQdenotes the row selection matrix.Notably,the computed probabilities are organized into a random diagonal matrix for the subsequent step.Next,a fixed number of nodes are sampled in the (l−1) layer based on thep(l−1).Note that nodes are not independently sampled in each layer.They are generated from the union set of neighbors which are sampled in the upper layer.The sampled adjacency matrix is then reconstructed between two consecutive layers since the sampling process is based on the layer-dependent matrices in the current and upper layers.Finally,the sampled adjacency matrix is further modified by row-wise normalization for stabilizing training.

LADIES has the following characteristics.
a) Layer-dependent:The neighbor dependence of each node is leveraged in LADIES,where nodes are conditionally sampled in the (l−1) layer according to the sampled nodes in the (l) layer.The characteristic of layer-dependent sampling ensures that the adjacency matrices generated by the sampled nodes are dense,which maintains sufficient information for training GCN.
b) Importance-based:LADIES uses an importance sampling approach to reduce the variance,where the importance probability for sampling only depends on the layer-dependent Laplacian matrix.Besides,importance sampling approach isalso beneficial to the convergence of training.

TABLE IVSUMMARY OF THE COMPARISONS BETWEEN LAYER-WISE SAMPLING METHODS

TABLE VCOMPARISON OF TESTING MICRO F1 SCORES BETWEEN LAYER-WISE SAMPLING METHODS
4) Comparisons Within the Category:In the preceding subsections,we have introduced some typical layer-wise sampling methods.Similarly,these methods sample a fixed number of nodes according to the particular probability in a layer-by-layer manner and reduce the variance caused by sampling with some techniques or tricks.Although they perform the sampling based on some common ground,there are still some distinct differences among these methods.We thereby analyze the discrepancies from multiple aspects and explain them in a Q&A manner.A summary of the comparisons is given in Tables IV.
a)What is the difference?
All these methods sample nodes per layer in a mini-batch manner to guarantee the scalability of training for large-scale graphs.FastGCN samplestlnodes in the (l) layer according to the pre-computed probability independently.AS-GCN samplesnnodes based on the parent nodes sampled in the upper layer,where the sampling process is probability-based and dependent between layers.LADIES samplesnnodes per layer with the restriction that nodes being sampled are from the union of neighbors of the already sampled nodes,which preserves the inter-layer dependence.Obviously,although all these methods sample a fixed number of nodes together in one sampling batch,FastGCN samples nodes regardless of dependency,while AS-GCN and LADIES perform sampling in a layer-dependent manner.There are both pros and cons.In FastGCN,the computation of sampling probability can be finished in the pre-processing,which reduces the time cost of sampling.However,FastGCN faces a possibly-sparse issue in the sampled result due to ignoring the dependency.AS-GCN and LADIES compute the probability in the sampling process iteratively to preserve the inter-layer dependency,which increases the computation cost.But AS-GCN and LADIES obtain denser neighborhoods in the sampled result.
b)How to reduce variance?
Reducing the variance caused by sampling is the critical work to optimize the sampling,which directly affects the accuracy of the model.Table V [66] shows a comparison of testing Micro F1 scores among these methods.All these methods reduce variance through the approach of changing the sampling distribution by importance sampling.Besides,AS-GCN uses an explicit variance reduction technique,where the variance is added into the loss function for explicit minimization during the training.It is reported in AS-GCN that compared with directly using AS-GCN,AS-GCN with variance reduction achieves better performance,especially on the Cora dataset and the Reddit dataset.Nevertheless,GraphSAINT [53] finds that AS-GCN requires more storage than FastGCN when training on some large datasets since only AS-GCN throws a runtime error on the Yelp and Amazon datasets under the same experimental environment.
c) What is the special?
All these methods achieve considerable efficiency compared with the original GCN in terms of training cost and speed.Besides,some extra tricks are used in these methods to provide further optimization:AS-GCN uses a skip connection technique to preserve the second-order proximity across two layers,making it possible that remote nodes’ information can pass efficiently across layers without extra computation.LADIES applies the normalization to Laplacian matrix in each layer,which stabilizes the training.
C.Subgraph-Based Sampling Method
Formally,in this category of sampling methods,one or more subgraphs are sampled for each mini-batch in GCN training.
Generally,a subgraph is directly formed by the graph partition algorithm,or induced from the specifically sampled nodes (edges) set.As illustrated in Fig.4,for the former case,a training graph is partitioned using special methods,e.g.,graph partition algorithms and graph clustering algorithms.Thereby,the original graph is divided into multiple subgraphs,and we can sample one or a certain number of subgraphs in each sampling batch.The sampling method used in work [52]distinctly satisfies the characteristics of the above process.
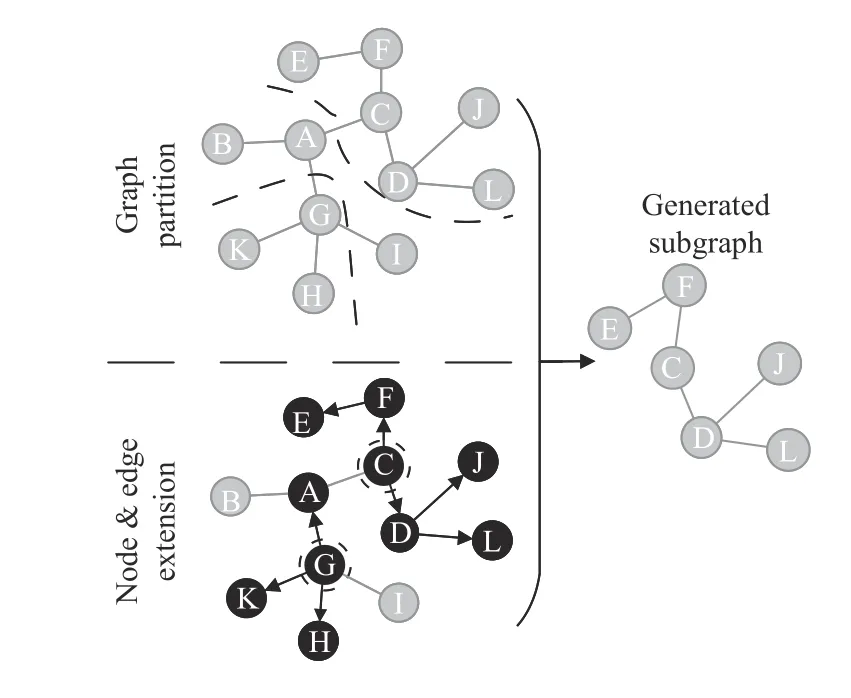
Fig.4.Illustration on typical process of subgraph-based sampling.
For the latter case,a subgraph is progressively generated from a specifically sampled nodes (edges) set.In this situation,one or several nodes are chosen as initial nodes.Based on the initial nodes,more nodes or edges are sampled by specific expansion and added to a candidate sampling set.Neighbors expansion can be achieved using a random walk process or probabilistic sampling.Thereby,a subgraph can be induced from the candidate sampling set.The sampling methods used in works [53]–[55] all satisfy the mechanism that subgraphs are induced from nodes (edges) extension.
However,due to the diversity in subgraph generation and execution flow,subgraph-based sampling methods have many differences in various aspects.We compare these differences in the last part of this section.Next up,we will introduce some typical works leveraging the subgraph-based sampling method in detail and highlight each method’s characteristics in the following subsections.
1) Cluster-GCN:As the name suggests,Cluster-GCN [52]extends the sampling operation to clusters and subgraphs.Cluster-GCN first partitions the original graph into multiple clusters by using graph clustering algorithms (e.g.,Metis [67]and Graclus [68]).Then,Cluster-GCN randomly samples a fixed number of clusters as a batch and forms a subgraph by combining the chosen clusters.Finally,the batch training of GCN is executed based on a subgraph in each iteration.Detailed pseudocode of the training algorithm is given in Algorithm 6,where the sampling process corresponds to Lines 3–4 of the algorithm.

The subgraph-based sampling method proposed in Cluster-GCN is inspired by the efficient use of stochastic gradient descent (SGD).To characterize the computation efficiency of the SGD,Cluster-GCN puts forward a concept of embedding utilization and considers that the embedding utilization is proportional to the number of edges within a subgraph in each batch.Therefore,to maximize the embedding utilization,a definite idea is to maximize the number of edges in each batch.Firstly,Cluster-GCN applies a graph clustering algorithm to partition the original graph and forms dense subgraphs.Given a graphG,Cluster-GCN partitions all nodes intocclusters:V=[V1,V2,...,Vc].Based on the clustering result,the graphGis divided intocsubgraphs:=[G1,G2,...,Gc],whereGt={Vt,Et},Vtand Etdefine all nodes in thet-th cluster and all links between nodes in thet-th cluster respectively.Thereby,the adjacency matrix of graphGis divided intoc2submatrices:

The graph clustering algorithms guarantee the density of the subgraph in each batch,and the decomposition of the loss enables the forward and backward propagations on subgraphs in the mini-batch training.Based on the above ideas,Cluster-GCN randomly samplesqclusters without replacement to form a subgraphThe subgraphnot only includes all nodes and edges within the chosen clusters,but also includes the edges between these clusters.The generation process of a subgraph in Cluster-GCN typically corresponds to the graph partition that is shown in Fig.4.Specially,instead of directly sampling a subgraph in each batch,a fixed number of subgraphs are randomly chosen to construct a larger subgraph to maintain the randomness,which also reduces information(inter-cluster edges) loss.
The proposed subgraph-based sampling method in Cluster-GCN has the following characteristics.
a) Scalable:In each batch,only a subgraph is loaded into GPU memory instead of the original graph,which is friendly to learning large-scale graphs.In vanilla Cluster-GCN,the mini-batch stochastic gradient descent is executed on a subgraph (cluster),which avoids the neighborhood searching outside the subgraph and ultimately reduces the training cost.
b) Heuristic:Cluster-GCN leverages a stochastic multiple clustering approach to address the imbalanced distribution of nodes’ labels caused by the clustering algorithm (Metis)instead of analyzing the variance in a theoretical manner.Although Cluster-GCN outperforms the previous works,it does not explicitly account for or solve the bias caused by the graph sampling.Nonetheless,Cluster-GCN provides a heuristic way to perform sampling in large-scale graphs.
2) Parallelized Graph Sampling:A novel GCN model based on parallelized graph sampling [55] technique is proposed in this work to train large-scale graphs accurately and efficiently.Since subgraphs are sampled independently in the training approach,the authors design a unique data structure to enable the thread-safe parallelization of the sampler and parallelize the sampling step on multiple processing units.Besides,to scale the sampling across samplers,a training scheduler is proposed to manage subgraphs pool and samplers.In each iteration,a complete GCN model is built on a sampled subgraph Gsubfor the forward and backward propagations.Detailed pseudocode of the GCN training with the parallel method is given in Algorithm 7.

The parallelized graph sampling method proposed in this work is built based on the frontier sampling method [69].Subgraphs generated by the frontier sampling method approximate the original graph in respect of numerous connectivity measures,which makes it possible that the graph sampling based model can learn accurate embeddings from a graph.To accelerate the sampling and reduce the time cost of training,the authors parallelize the frontier sampling under the condition that the subgraph’s quality is well guaranteed.Besides,the authors design a novel data structure,namely,“Dashboard” table,to guarantee thread-safe parallelization of the sampling step with low complexity.Since the sampler randomly pops out a nodevleveraging a probability distribution which is based on the degree of nodes and replacesvwith a random neighboruofvin each iteration,we define the current nodevas a historical one whenvis popped out.A detailed algorithm of parallel dashboard based sampling is given in Algorithm 8,where FS denotes the frontier set,and DB is a dashboard table to store information(e.g.,probabilities and status) for current and historical vertices in FS.IA is an auxiliary index array used to clean up the DB to avoid overflow.

To begin with,DB and IA are initialized by FS.A parallel scheme is applied to DB to speed up the process of initialization.Next,for each iteration in the main loop of the sampling step,a vertex to be popped out next is obtained from the function “pardo_POP_FRONTIER”.After the vertexvpopis popped out,a vertexvnewis randomly sampled fromvpop’s neighbors.If the degree of the latest sampled vertexvnewimplies that DB needs to be cleaned,the function“pardo_CLEANUP” is executed and reconstitutes DB leveraging the information in IA.Then,DB is updated by the function “pardo_ADD_TO_FRONTIER”,and the vertexvnewis added into the Vsub.Finally,a subgraph Gsubis induced by the Vsubafter multiple iterations.Distinctly,multiple subgraphs are sampled in parallel in one sampling batch.The generation mechanism of a subgraph satisfies the process that nodes extension from the randomly selected node set FS that is shown in Fig.4.Note that the abovementioned functions can be executed in parallel on multiple processors to accelerate the sampling because the subgraphs in this training approach are sampled independently.Moreover,the authors give the overall cost of sampling a subgraph withpprocessors,that is
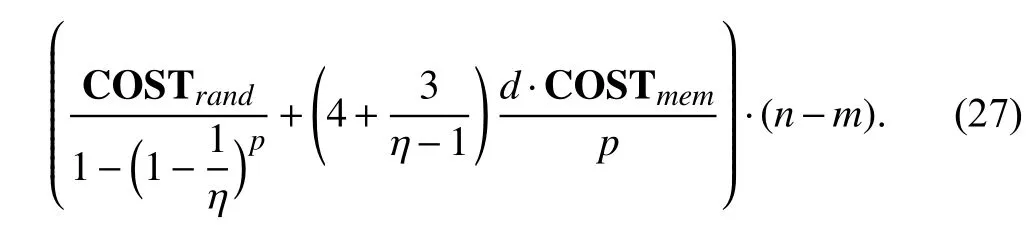
Based on the assumption that COSTrand=COSTmemin(27),the authors have proven that for any given ϵ >0,a lower bound of speedup of the sampling algorithm isp/(1+ϵ),∀p≤ϵd(4+3/(η−1))−η.
The proposed subgraph-based sampling method in this parallelized training approach has the following characteristics.
a) Parallelizable:Both inter-subgraph and intra-subgraph parallelization methods are used in GCN training.For intersubgraph parallelization,subgraphs are sampled independently on multiple processors in parallel with the help of the scheduler.For intra-subgraph parallelization,each sampler (an instance of sampling) can be parallelized by exploiting the parallelism of the proposed functions in the main loop of sampling in Algorithm 8.
b) Scalable:The cost of sampling a subgraph achieves a near-linear speedup with the number of processing units in terms of scalability.Furthermore,the speedup of sampling is scalable with the number of samplers under the condition that the number of processors is fixed in the experimental platform.The authors also experimentally demonstrate the scalability in respect of the depth of GCN model,which achieves a significant training speedup relevant to the number of cores.
3) GraphSAINT:Motivated by training GCN models on large-scale graphs,GraphSAINT [53] proposes a graph sampling based inductive method for efficient training of GCN.GraphSAINT first uses a proper-designed sampler to estimate the probability of nodes and edges being sampled,respectively.In each batch,an appropriately connected subgraph is sampled according to the sampler.Then,GraphSAINT builds a full GCN on the sampled subgraph and executes the training process.Finally,the weights of the model are updated after the forward and backward propagations.Especially,GraphSAINT leverages normalization techniques to address the bias issue introduced by the graph sampling method.Detailed pseudocode of the training algorithm is given in Algorithm 9,here we mainly focus on the sampling method and the normalization techniques.

The subgraph-based sampling methods proposed in GraphSAINT are alternative in training.The authors put forward two intuitions:1) Nodes influential to each other should be sampled in the same subgraph.2) The probability of each edge being sampled cannot be neglected.The above two intuitions will undoubtedly introduce bias into training.GraphSAINT therefore optimizes sampling by considering the bias explicitly.
Firstly,GraphSAINT proposes an unbiased estimatorof the aggregated embedding in (l+1) layer under the condition that the embedding is learned independently in each layer.To accurately perform sampling,GraphSAINT leverages an optimal edge sampler to reduce the variance of the unbiased estimator.Assuming thatmedges are independently sampled,the optimal probabilitypefor edges that are sampled to minimize the sum of variances of ζ in all dimensions is

GraphSAINT also proposes two random walk based samplers for multi-layer GCN by representing L-layer GCN as one-layer GCN with edge weights.Detailed pseudocode of the samplers integrated in GraphSAINT is given Algorithm 10.Obviously,the generation mechanism of a subgraph in the random walk based samplers satisfies the process of nodes extension from the randomly selected root nodes,while as for edge samplers,it samples edges based on pre-computed probability and adds them to Es.And a subgraph is generated by a set of nodes Vsthat are end-points of edges in the sampled edge set Es.

The probability-based edges sampling method is similar to layer-wise sampling methods [49]–[51].The common ground between them is that a fixed number of nodes (edges) are sampled according to the pre-computed probability.Differently,the edge sampler in GraphSAINT forms a subgraph from the node set relevant to the sampled edges,while layer-wise sampling methods directly construct GCN training on multi-layer sampled nodes.
The proposed subgraph-based sampling method in GraphSAINT has the following characteristics.
a) Precise:In GraphSAINT,nodes that appear with a higher effect on each other are more likely to be sampled to form a subgraph,ensuring better connectivity between layers.Besides,GraphSAINT proposes normalization techniques to eliminate the bias introduced by graph sampling explicitly.
b) Conditional:The analysis of the normalization technique and sampling probability is under the condition that the embedding of each layer is learned independently,which is similar to the treatment of layers in some layer-wise sampling methods [49],[50].
c) Flexible:As shown in Algorithm 10,GraphSAINT can integrate many other graph sampling methods.On the other hand,the graph sampling based training framework used in GraphSAINT is also applicable to many other popular variants of GCN.
4) RWT:Ripple walk training (RWT) [54] is a subgraphbased training framework for large and deep GNNs (GCN &GAT).In this framework,a ripple walk sampler is integrated in RWT to sample high-quality subgraphs for computation of mini-batch gradient.In each iteration,the model’s weight is updated according to the gradient.RWT is designed to simultaneously solve some critical problems in many current GNNs,namely,neighbor explosion,node dependence,and over-smoothing.The first two problems can be well solved by the subgraph-based sampling method,and the over-smoothing problem in deep GNNs can be handled by applying RWT.
The subgraph-based sampling method integrated in RWT is designed to sample particular subgraphs with two characteristics:randomness and connectivity.For randomness,each node in a graph is sampled with the same probability,and each node’s neighbors are chosen with the same probability.For connectivity,each subgraph is required to have high connectivity to maintain the connectivity in the original graph.
To begin with,a random nodevsis chosen to initialize the subgraph Gkand added into the node set Vkof Gk.Then,Vk’s neighbor node setNSis required for further selection.For each node in Vk,a certain percentage of its neighbors are randomly sampled according to the ratior(herein,ris set to 0.5 by the authors to denote 50%) and added into Vkin every expansion of the subgraph.Finally,a subgraph that includesSnodes is returned after multiple expansions.Detailed pseudocode of the ripple walk sampler is given in Algorithm 11.A subgraph sampled in each batch is generated by an increasingly expanding node set.The generation process of a subgraph is similar to the neighbor sampling process in GraphSAGE [35].Differently,GraphSAGE samples a fixed number of neighbors for each node in the training graph,while RWT simultaneously extendsrof neighbors for multiple nodes in Vsand gradually expands the scope of sampled neighbor set for subgraph generation.Taking the form of the formula in (11),we argue that the subgraph sampling process in RWT can be given by modifying the typical form of node-wise sampling:

TABLE VISUMMARY OF THE COMPARISONS BETWEEN SUBGRAPH-BASED SAMPLING METHODS
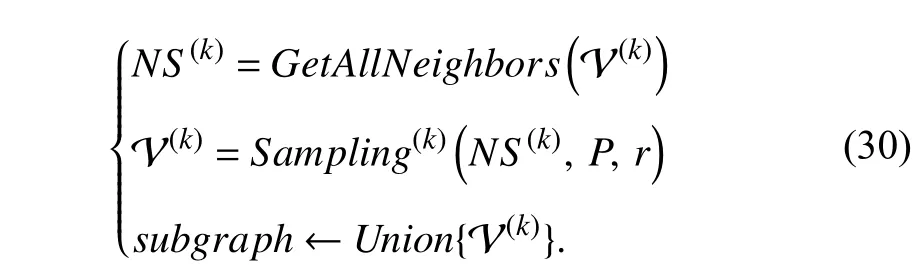
Here,the probabilityPobeys uniform distribution,andris set to 0.5 to ensure half percent of neighbors of each node are sampled for extension.The neighbor extension stops when the size of Vsis not less than the preset size of the target subgraph.By repeating the above process,multiple subgraphs are sampled for training GCN.

The proposed subgraph-based sampling method in RWT has the following characteristics.
a) Elastic:Both the sizeMof a mini-batch and the sizeSof a sampled subgraph can be preset before training.Therefore,the mini-batch training using subgraphs is well controlled and can be designed elastically.
b) Alternative:Ripple walk sampler shows advantages in maintaining the connectivity and randomness of the subgraph.The ripple walk sampler is equivalent to breadth first search(BFS) whenris close to 0.Differently,the ripple walk sampler randomly selects the neighbors of nodes in Vsto guarantee the randomness.Meanwhile,each expansion of the subgraph in ripple walk sampler is based on the neighbors of nodes in Vk,which guarantees the connectivity.
5) Comparisons Within the Category:In the preceding subsections,we have introduced typical subgraph-based sampling methods.Distinctly,all these methods sample one or more subgraphs in each sampling batch based on different mechanisms.To summarization and analysis,we compare these methods from multiple perspectives and explain the differences between these methods in a Q&A manner.A summary of the comparisons is given in Table VI.
a) How do they work?
An understanding of the mechanism is the primary work for analyzing the availability.Based on the common ground that all these methods output subgraphs leveraging the given input,we therefore focus on how a subgraph is generated.Cluster-GCN uses a graph clustering algorithm to partition the full graph into multiple clusters and forms a subgraph with some randomly chosen clusters.Parallelized graph sampling modifies the frontier sampling algorithm to an approach that is executed in parallel.In RWT,a subgraph is generated by neighbor searching and sampling under the condition that an initial node is randomly chosen as a root node.Similarly,GraphSAINT-RW uses a random walk strategy to sample neighbors of a node in the root node set and generates subgraphs leveraging the selected neighbors and the root node set.The differences in sampling between RWT and GraphSAINT-RW are the root node set’s initial capacity and neighbor sampling strategy.GraphSAINT-EDGE samples edges based on a pre-computed probability.In sum,subgraphs generated in all these above works are commonly induced from the nodes and edges which are selected in a random or probability-based manner.
b) Can they be faster?
Efficiency is a crucial metric to quantize the execution of a method.Although all methods have been proven to be available in their papers,we hope that the sampling process in these methods can be further accelerated by reducing computation cost.Intuitively,we focus on the most timeconsuming part of these methods.In Cluster-GCN,graph clustering consumes a lot of time due to the complexity of the original graph.In parallelized graph sampling,the dashboard’s cleanup is proven to be the most time-consuming process by the authors.In RWT and GraphSAINT-RW,the sampling process is based on neighbor searching and selecting.Therefore,neighbor traversal causes non-trivial computation overhead.In GraphSAINT-EDGE,edge sampling is the heaviest part.In this way,a potential idea for accelerating sampling is to reduce the cost of the most time-consuming operation.For some operations which are only executed once,such as graph clustering and probability computation,we consider performing them in the pre-processing and leave the resource to frequently executed operations.For some operations which are time-consuming and unavoidable,such as dashboard cleanup,we can add some unique mechanisms to reduce the number of occurrences of these operations.Herein,since we only focus on the impact on the sampling process,the impact on the entire training should also be taken into consideration when adding new mechanisms to a sampling method.

TABLE VIICOMPARISON OF TESTING MICRO F1 SCORE BETWEEN SUBGRAPH-BASED SAMPLING METHODS
c) How to evaluate?
Evaluation of the sampling method depends on multiple metrics.Accuracy is a fundamental metric for evaluation.Since all these works have experimentally demonstrated their methods to be accurate,we summarize the reported results in Table VII.Moreover,scalability is a non-negligible metric to evaluate a method’s performance,especially when adopting the model on large datasets.It has been proven that the minibatch training approach is more flexible and scalable than the full-batch approach.And sampling methods are also supposed to follow a mini-batch manner to maintain this characteristic of training.Last but not least,we evaluate a method based on its unique points.For example,Cluster-GCN uses a heuristic method to perform the sampling in large-scale graphs.We highlight these unique points so that readers can quickly get through to the mechanism of a method.
D.Heterogeneous Sampling Method
Heterogeneous sampling method is a novel strategy to handle the heterogeneity in graphs and accelerate the training.In this category of sampling methods,the main target is to perform sampling among various types of nodes reasonably and efficiently.Typically,a heterogeneous graph includes nodes and edges in different types.For example,we take the form of the definition of the heterogeneous graph given in work [57],that is,G=(V,E,OV,RE).V and E denote sets that consist of various types of nodes and edges,respectively.OVrepresents node types that correspond to nodes in V,and RErepresents edge types that correspond to edges in E.Generally,relations between nodes in G are complex and imbalanced,which is reflected in that the number of neighbors of each node is different,and one single node can have different types of neighbors with an unbalanced number.In this situation,imbalanced neighbors’ numbers in different types bring about a significant challenge in sampling neighbors and capturing neighborhood representation.
Therefore,it is critical for a sampling method to distinguish different types of nodes and compute the effect.We formally divide the sampling process for heterogeneous graphs into two phases.In phase one,the effect of different types of neighbors on the target node is computed to capture the importance and influence in neighborhood.We modify the typical format of sampling in (7) and propose a general form of heterogeneous sampling methods:
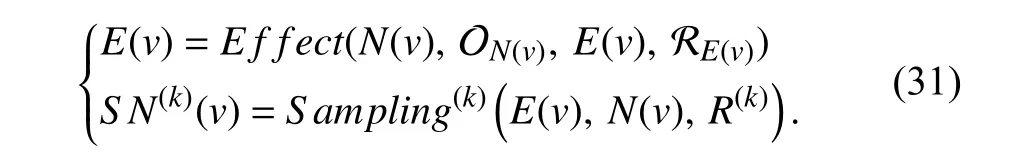
Here,N(v) andE(v) denote neighbor set and edge set of nodev,respectively.ON(v)and RE(v)denote sets that consist of node types and edge types,respectively.E(v) is a set that stores the effect of different types of neighbors on nodev.Based on the pre-computedE(v),sampling is performed for each nodevto select different types of neighbors orderly.AndRis a restrict factor in guaranteeing a balanced distribution of different types of neighbors in terms of number.
Since heterogeneous sampling methods generally vary in mechanism especially in capturing neighborhood representation,we thereby compare these methods in the last part of this section to emphasize the differences and commonness between the heterogeneous sampling methods.Next up,we will introduce some typical works leveraging the heterogeneous sampling method in detail and highlight each method’s characteristics in the following subsections.
1) Time-Related Sampling:Time-related sampling [56] is a heterogeneous sampling method proposed in a GCN-based anti-spam (GAS) model for sampling comments in a timerelated manner.Since the spam comment on the online shopping website will badly affect consumers’ buying decisions,the GAS model is proposed to identify adversarial actions and filter spam comments.The execution of the GAS model is based on two graphs,that is,a heterogeneous graph and a homogeneous graph.The heterogeneous graph is a directed bipartite graph,namely Xianyu Graph,where users and items are abstracted as nodes while comments are abstracted as edges between a user and a commented item.The homogeneous graph includes nodes abstracted by comments.The two graphs capture the local context and global context of a comment,respectively.And the GAS model can therefore identify spam comments and alleviate the impact of adversarial actions by mixing the local and global context of comments.
To identify the validity of a comment,the authors sample neighbors of the associated nodes (user and item) on both sides of the edge (comment),leveraging the time-related sampling method.As illustrated in Fig.5,several comments form a batch for identification.To obtain the embedding of the commente0,the embeddings of useru0and itemi0are primarily required.Specifically,the time-related sampling method samplesMcomments whose published times are closest to thee0to compute the embedding ofi0,for example,e3ande5.In this way,the embedding ofi0is computed by aggregating the embedding from {e3,u1} and {e5,u3}.The computation of the embedding ofu0is similar.Note that the authors use placeholders to pad the samples when the number of alternative comments is less thanM.The computation of the padded placeholders is ignored in training.Typically,time-related sampling similarly corresponds to the two-phase general sampling process defined in (31),but is simplified in distinguishing neighbors since they only sample edges(comments) in the Xianyu Graph.
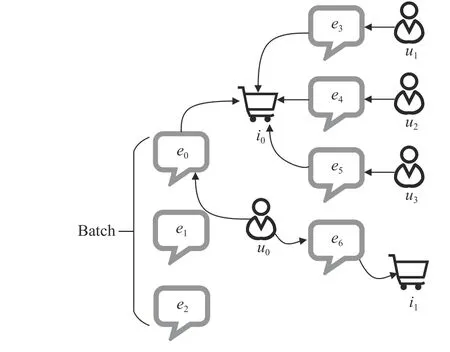
Fig.5.Illustration on a case of time-related sampling.
The proposed heterogeneous sampling method in GAS has the following characteristics.
a) Time-related:The time-related sampling method samples edges abstracted from comments based on the published time.In this way,the closestMcomments in the aspect of time are sampled for aggregating embeddings of users or items.
b) Reasonable:Compared with randomly sampling neighbors,the time-related sampling method samples the most related comments in terms of the publish time instead of random neighbors since the published comments have a more significant impact on the comment to be identified in a short time.Generally,comments on an item may be sparse.Therefore,when the sampling sizeMis greater than the number of alternative comments,the time-related sampling method uses placeholders to pad the samples instead of sampling with replacement.And the padded placeholders’computation is ignored to maintain the neighborhood distribution,which also reduces the cost in terms of training time and storage.
2) HetGNN:HetGNN [57] is a heterogeneous graph neural network model to handle the issue of the structural information in heterogeneous graphs and attributes or contents correlated to each node.The authors propose three critical challenges faced with heterogeneous graphs:the strategy to sample highly related neighbors in a heterogeneous distribution,the method to design an encoder for all types of nodes with heterogeneous contents,and the approach to aggregate information of heterogeneous nodes with considering the influence of the node type.Herein,we mainly focus on the heterogeneous sampling method used in HetGNN.
To solve the issue of heterogeneous neighbor sampling,HetGNN proposes a heterogeneous sampling method based on random walk with restart (RWR).Specifically,the heterogeneous sampling method starts traversal among nodes in a random walk manner.Assuming thatuis an arbitrary intermediate node in the traversal whilevis the start point,and the target is to get a set of nodesRWR(v) with a fixed lengthN.For each walking step,the heterogeneous sampling method performs one of the following operations with probabilityp:samples the neighbors ofuand adds them intoRWR(v);directly returns to the start point.The random walk process ends up with returning theRWR(v) with lengthN,and it is ensured that all types of nodes can be sampled in the random walk process.Next,the second sampling phase based on the sampled nodes inRWR(v) groups the most related neighbors ofvby the node type.The authors samplektneighbors in typetaccording to the visit frequency and take them as the most related neighbors ofvin typet.
Especially,the heterogeneous sampling method performs a neighbor traversal and sifting based on a restartable random walk before sampling neighbors.Since neighbors inRWR(v)are sampled according to the visit frequency,we suppose thatRWR(v) includes multiple identical neighbors for recording the visit frequency.We abstract the sampling process as
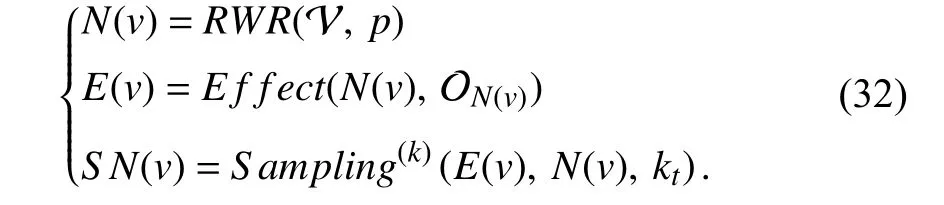
The proposed heterogeneous sampling method in HetGNN has the following characteristics.
a)Restricted:Two principles restrict the process of random walk in the heterogeneous sampling method.Firstly,the sampling size of neighbors is restricted to a fixed number.Secondly,the number of neighbors in each type is restricted to be reasonable,ensuring all types of nodes are sampled ultimately.
b)Frequency-based:The second phase of the heterogeneous sampling method samples the topktneighbors in typetthat are most frequently visited inRWR(v).After this,the selected neighbors are grouped by the type of nodes to make the aggregate efficient since nodes in the same type include the same content features.
3) HGSampling:Heterogeneous mini-batch graph sampling(HGSampling) is a heterogeneous sampling method proposed in heterogeneous graph transformer (HGT) [58] to train webscale heterogeneous graphs efficiently.Specifically,HGT leverages heterogeneous graphs’ meta-relations to parameterize weight matrices for several critical steps:heterogeneous mutual attention,heterogeneous message passing,and targetspecific aggregation.To further handle the graph dynamics,a relative temporal encoding technique is designed to simulate dynamic dependencies for assisting HGT.Last but not the least,the authors use HGSampling to optimize the training in terms of scalability,which makes it possible that all the proposed GNN models,including HGT,can train heterogeneous graphs in an arbitrary size by using HGSampling.
Based on the fact that the number of each type of nodes and the degree distribution are dramatically different in heterogeneous graphs,HGSampling solves the issue in a balanced approach.A detailed procedure of HGSampling is given in Algorithm 12.Firstly,HGSampling initializes the sampled node setNSand a node budgetBthat is used to store different types of nodes separately.Next,for each nodetinNS,HGSampling adds all direct neighbors ofttoBand updates corresponding budgets inB(that has stored these neighbors) with the normalized degree oft.Then,HGSampling computes the sampling probabilityprob[τ] for each node of each type using the budget.Based onprob[τ],HGSampling samplesnnodes in type τ and updatesBby swapping out the already sampled nodes.Finally,after the output node setOSis padded by sampled nodes,HGSampling reconstructs the adjacency matrix with the sampled nodes.The abovementioned sampling process repeatsLtimes to obtain a sampled subgraph that is dense and includes a similar number of nodes in different types.Compared with the general heterogeneous sampling process in (31),HGSampling uses the budgetBto store all direct neighbors ofOSand dynamically updatesBand the sampled neighbor setOSin each sampling batch.The effect on a node is quantized in the form of the sampling probability.We thereby abstract the execution process of HGSampling as

The proposed heterogeneous sampling method in HGT has the following characteristics.
a)Balanced:The heterogeneity of graphs is distinctly reflected in the number and degree distribution among all types of nodes.HGSampling samples a similar number of nodes for each type to maintain a balanced sampling result.
b) Probability-based:In the prior update of the budgetB,HGSampling adds the normalized degree of a node to its neighbors stored in corresponding budgets,which alleviates the impact by some high degree nodes.In this way,nodes with higher value in the corresponding budgets are given a higher probability of being sampled.
c) Subgraph-induced:In HGSampling,a subgraph is generated by repeating the main procedure of sampling forLtimes.The induced subgraph withLdepth is adequately dense due to importance sampling and normalization technique,which is beneficial to variance reduction.
4) Text Graph Sampling:Text graph sampling is a heterogeneous sampling method proposed in text graph transformer (TG-Transformer) [59] to construct the minibatch for learning node representations.Since some GCNbased models for classifying texts and training heterogeneous text graphs have trouble preserving scalability and heterogeneity,the authors propose the TG-Transformer to address these issues.Specifically,TG-Transformer uses the text graph sampling to reduce the computation cost and make the model scalable for a large-size corpus.The authors then leverage two structural encodings to capture the nodes’ types and structure of the text graph and jointly add the information as the model’s input.The transformer can thereby learn the target node embedding by aggregating the information from mini-batches generated by sampling.

Text graph sampling constructs mini-batches on a heterogeneous text graph G=(U,V,E,F),where nodesU and V denote words and documents,respectively,while edges E and F represent word-document edges and wordword edges,respectively.Firstly,the intimacy matrixSof G is computed by using the PageRank algorithm [70] in the following form:
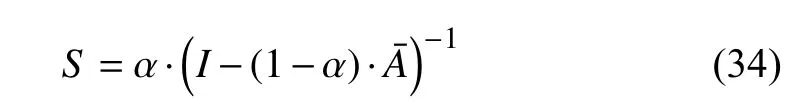
where parameter α is set as 0.15,and the normalized matrixFor each document node in V,text graph sampling forms its context graph by sampling the most intimatekword nodes as neighbors.For each word node U,text graph sampling forms its context graph by sampling totally the most intimatekneighbors,where the document node and word node each occupy a certain proportion.Detailedly,for each word nodeui∈U,most intimatek·rw(ui)andk·rd(ui) neighbors in the type of word and document are respectively sampled.The proportionality coefficientsrw(ui)andrd(ui) can be computed as
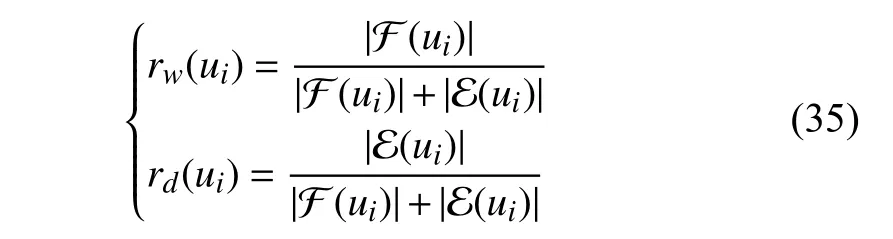
where F(ui) and E(ui) denote different types of edge sets that associated with nodeuiwith especial intimacy score requirement.Obviously,text graph sampling satisfies the formof general heterogeneous sampling in (31).Besides,it explicitly considers the sampling mechanism among word nodes and document nodes by applying proportional division.

TABLE VIIISUMMARY OF THE COMPARISONS BETWEEN HETEROGENEOUS SAMPLING METHODS
The proposed heterogeneous sampling method in TGTransformer has the following characteristics.
a) Intimacy-based:Text graph sampling samples the most intimatekneighbors to form the context graph for each document node and word node.And each mini-batch is constructed based on sampled subgraphs (context graphs),which improves the scalability of the model when learning a large-size corpus.
b) Categorized:Since nodes in the heterogeneous text graph are categorized into two types,text graph sampling performs different flows according to the node type.For document nodes,the most intimate word nodes are directly sampled to form the context graph.For word nodes,the most intimate neighbors that include a mixture of word and document nodes are proportionally sampled to form the context graph.
5) Comparisons Within the Category:In the preceding subsections,we have introduced some typical heterogeneous sampling methods.It is explicit that the common ground of these methods is to handle the heterogeneity in graphs,especially heterogeneous neighbor connection and distribution.Since most heterogeneous sampling methods are used in application-driven scenarios,the experiments and evaluations can be quite diverse.Herein,we focus on the differences in these methods’ mechanisms instead of directly comparing the evaluation results.And we explain the differences among these methods in a Q&A manner.A summary of the comparisons is given in Table VIII.
a) How do they work?
To analyze the availability of a sampling method,we pay special attention to some aspects in the sampling process,that is,the sampling target and the sampling condition.Timerelated sampling method samples edges from the heterogeneous graph,where edges in the graph are abstracted by comments between users and items.The sampling method proposed in HetGNN samples nodes in all types randomly as the neighbors ofvand stores them inRWR(v),while HGSampling samples nodes in each type orderly with the help of the budgetB.Text graph sampling samples document nodes and word nodes as neighbors to form a context graph.
As for the efficiency,it is unreasonable to sample neighbors randomly from a graph due to its heterogeneity.Therefore,the sampling condition then highlights its role in the sampling process.In time-related sampling,the closest comments in terms of the publish time are sampled as neighbors of the target one.In HetGNN,the most frequently visited nodes are sampled as neighbors of the nodev.In HGSampling,the sampling probability is pre-computed according to corresponding budgets inB,which are based on the neighbors and the normalized degree.In text graph sampling,the most intimate nodes are sampled as neighbors for a document or word node.Distinctly,all these heterogeneous sampling methods follow a common idea:the most related neighbors are sampled with a higher probability.
b) What is the special?
The scalability is a critical indicator to estimate the model performance.All of these sampling methods execute in a mini-batch manner,which benefits the execution of subsequent steps,e.g.,aggregation and gradient update,in the training process.Besides,there are some extra tricks:timerelated sampling uses placeholders to pad the samples when the number of alternative comments is less than the required sampling size.This trick helps to maintain the neighborhood distribution and lower the computation cost.HetGNN leverages a restartable random walk strategy to select the initial neighbor set for further sampling.And the grouping trick also helps the aggregation.HGSampling designs an efficient budgetB,andBcan not only store the neighbors by type but also be used in computing the sampling probability.Text graph sampling computes the intimacy matrix leveraging the PageRank algorithm novelly.Obviously,all these methods have some special points to assist the original sampling.
IV.COMPARISON AND ANALYSIS
The previous section has clearly explained the mechanisms of sampling methods and put forward detailed comparisons within each category for highlighting the similarities and differences.In this section,we adequately compare the introduced sampling methods together for summary and analysis.
A.Comparison in Characteristics
In the previous section,we have highlighted the characteristics of each sampling method for emphasizing similarities and differences between diverse sampling methods.Herein,we provide a summary in Table IX for characteristics of the introduced sampling methods.Most of the characteristics are unique to each sampling method and reflect the pros and cons of a sampling method from the computation or storage aspect.Thereby,we summarize in Table X for descriptions about how the characteristics affect a method from the perspective of computation or storage.
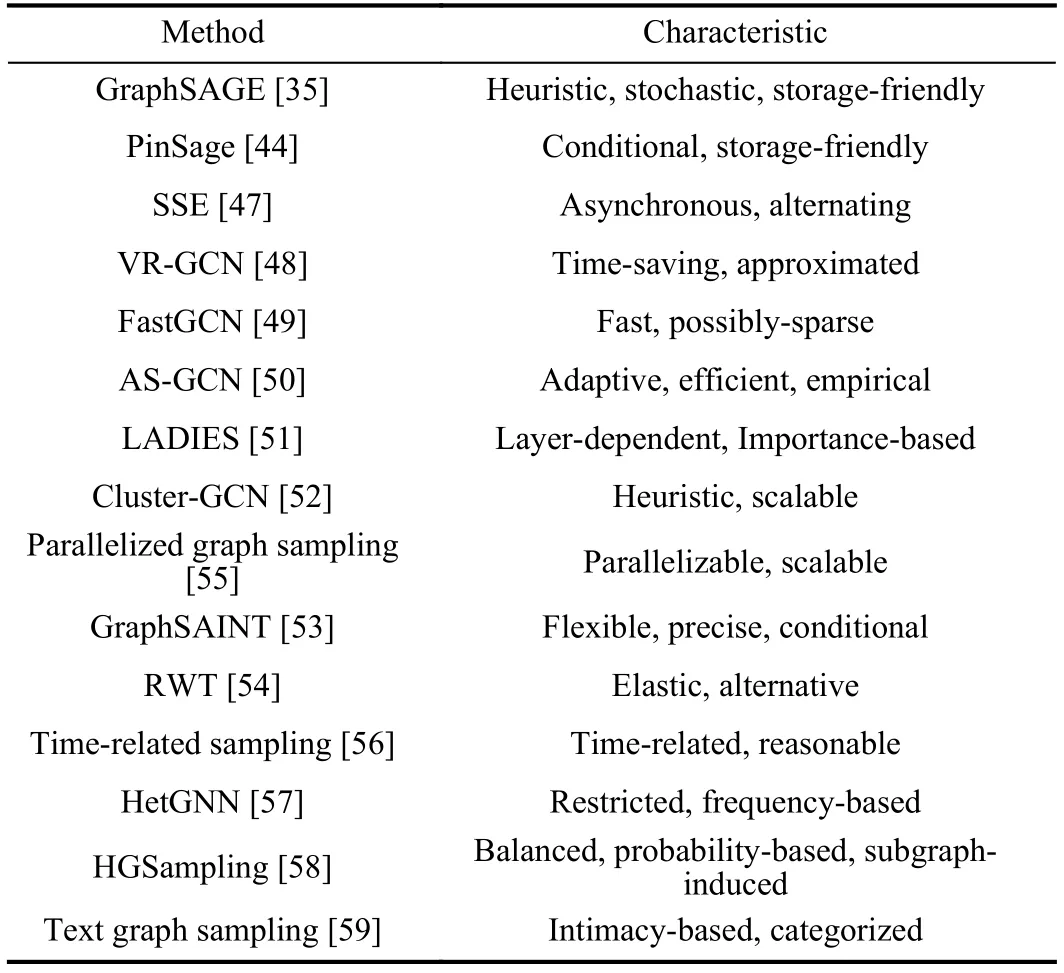
TABLE IXSUMMARY OF THE CHARACTERISTICS OF SAMPLING METHODS
B.Comparison in Applications
We divide the applications into two categories,that is,general applications and specific applications.The general application is the basic usage of a method,where the trained model can be directly used in node classification and prediction.The specific application is the particular usage or scenario,which varies with different methods.Besides,in most works,the specific application usually corresponds to the target problem of a method.For instance,time-related sampling is designed to alleviate adversarial actions and can be applied to an industrial-level anti-spam system.A summary of these applications is shown in Table XI.
C.Comparison in Experiments
We conduct extensive experiments of vanilla GCN and various sampling methods on common benchmark datasets(which are introduced in Table II) and exhibit the timeaccuracy plots for comparison and analysis.As HetGNN [57]and HGSampling [58] place emphasis on different applications of the heterogeneous graph respectively and have not conducted experiments on common benchmark datasets,we do not consider conducting experiments for the two methods separately for lacking the control group.Besides,we record some significant factors in GCN training to provide a detailed performance comparison,including validation accuracy,total epoch number and time cost before convergence,the proportion of sampling in the total time cost(excluding the time of loading data),and the proportion of model training (without regard to model evaluation) time in the total time cost.To impartially exhibit the impact of sampling methods in GCN training,we conduct all experiments on a two-layer GCN model and mainly use their official configurations in model training.We evaluate all the models with available code in GitHub on a Linux server equipped with dual 14-core Intel Xeon E5-2 683 v3 CPUs(2.00 GHz) and an NVIDIA Tesla V100 GPU (16 GB memory).Available links and the corresponding sampling methods are listed in Table XII.
1) Time-Accuracy Comparison
We exhibit the time (sequential training time) and accuracy(validation accuracy) comparison of various methods on benchmark datasets in Fig.6,where GraphSAGE1and GraphSAGE2are different implementations proposed by their authors [35],and PGSampling1is short for parallelized graph sampling [55].Note that the sequential training time we recorded includes the time of data loading and processing,the computation of critical factors (used for sampling or training),sampling,model training and evaluating.To make GCN training efficient,sampling methods improve the training by reducing computation cost and accelerating the convergence.Firstly,most sampling methods optimize the training mechanism and select part of neighbors for neighborhood representation aggregation reasonably,which reduces computation cost compared to training with entire nodes.Secondly,sampling methods use a mini-batch strategy to allow the model to be updated once per batch,which accelerates the convergence of model compared to the fullbatch training.
Distinctly,most sampling methods converge faster than vanilla GCN in training.Still,some of them may require a longer time than vanilla GCN in terms of the total training cost,which can be suggested from comparisons in sequential training time on each benchmark dataset.For instance,ASGCN [50] achieves the top accuracy but requires maximum sequential training time since the time of computing sampling probability and capturing layer-dependent neighboring relationships is non-negligible,which is a trade-off between time and accuracy.On the other hand,it is quite appropriate for sampling methods to handle large datasets which includes tens of thousands of nodes and millions of edges,e.g.,Reddit[35] and Yelp [53].The sampling process helps to explore the neighboring relationship and accelerate the convergence of training in a batched manner.
2) Detailed Performance Comparison
Previously,we have exhibited the time-accuracy comparison on benchmark datasets,and we further compare each method on various benchmark datasets and record significant factors in model training.Detailed performance comparison is given in Table XIII.Specifically,we pay more attention to the following factors:validation accuracy(abbreviated as Accuracy),the number of training epoch before convergence (abbreviated as Epoch),the total time cost before convergence (abbreviated as Total time),the proportion of sampling time in the total time cost (abbreviated as Sampling %),and the proportion of time of model training without regard to model evaluation,i.e.,pure training time,in the total time cost (abbreviated as Training %).
Instead of simply recording the training time that includes the forward and backward propagations,we focus on the total time cost from model initialization to convergence,which is advantageous for discovering the bottleneck in terms of time during training.Formally,the sampling process mainlyincludes computing necessary factors for sampling,selecting nodes,and constructing the adjacency matrix for training.As a result,the sampling process is usually mixed with the process of pre-processing,which makes it hard to filter the time of sampling out separately at the code level in most instances.Thus,the Sampling % can be regarded as a maximum value of sampling cost in training in this sense.

TABLE XSUMMARY AND CLASSIFICATION OF DESCRIPTIONS OF THE CHARACTERISTICS

TABLE XISUMMARY AND CLASSIFICATION OF THE APPLICATIONS OF SAMPLING METHODS

TABLE XIIAVAILABLE LINKS AND THE CORRESPONDING MODELS
Sampling methods improve GCN training by reducing the cost in terms of computation and storage,which makes it possible to extend the training to larger datasets.However,it comes from the Table XIII that sampling % is becoming a considerable value as the graph data become larger,and can reach a comparable cost to the model training in some cases.Consequently,it is suggested that the sampling process has gradually become a non-trivial part of the training that can not be ignored.
D.Comparison in Deep Models
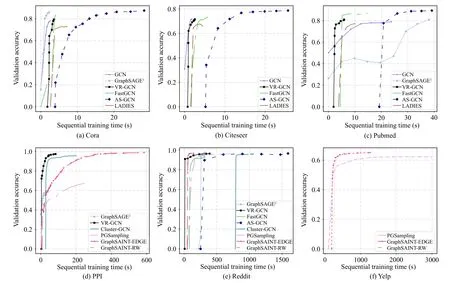
Fig.6.Time-accuracy comparison on benchmark datasets.
In the previous section,extensive experiments of various sampling methods have been conducted on the two-layer model for comparison.Further,we consider the performance of sampling-based methods in converged sequential training time and validation accuracy on deep models.We thereby conduct experiments of node-wise sampling methods and subgraph-based sampling methods on deep models,i.e.,VRGCN [48] and Cluster-GCN [52],since the current layer-wise sampling methods do not support the modification of the model depth.Time (sequential training time) and accuracy(validation accuracy) comparisons of node-wise and subgraph-based sampling methods on the deep model (model depth varies from 2 to 5) are illustrated in Fig.7.Note that the configurations for sampling and training of VR-GCN and Cluster-GCN are given in the “Hyperparameters” column in Table XIII.
Generally,for VR-GCN (node-wise sampling),the sequential training time increases as the model becomes deeper,and the validation accuracy decreases as the number of the model depth increases.Distinctively,on the PPI [61]dataset,VR-GCN converges fast on the five-layer model since the validation accuracy converges to a relatively low value(0.725) and will not be increased further.For Cluster-GCN(subgraph-based sampling),the sequential training time increases as the model depth increases,while the validation accuracy is slightly improved or remains stable.
Practically,constructing a deep GCN model by simply adding more layers will suffer from the problem of vanishing gradient,which is also known as the phenomenon of oversmoothing.In this case,the converged features of nodes in a graph eventually become the same value,which deteriorates the model ability in various graph-based tasks [71],[72].Therefore,the validation accuracy of VR-GCN is generally declining as the model becomes deeper.However,Cluster-GCN preserves a relatively stable validation accuracy since it additionally uses a diagonal enhancement technique to improve the training in the deep model.
In summary,the sequential training time on the deep model is generally increasing,and the validation accuracy is generally declining unless the additional technique on overcoming the phenomenon of over-smoothing is added.
E.Comparison in Overall
A comprehensive summary of overall comparison on sampling methods in all categories is given in Table XIV,and we pay special attention to the following aspects.
1) Random Sampling
It denotes whether a sampling method samples nodes in a random manner.Random neighbor sampling is widely used in node-wise sampling methods to guarantee randomness and uniformity since every node of the same type can be considered with equal probability.Besides,subgraph-based sampling methods likewise randomly sample nodes to generate subgraphs.In some situations,we can not directly perform random sampling.For example,when handling heterogeneous graphs,the heterogeneity of nodes and edges should be well considered.On the other hand,sampling with probability is adequately used in layer-wise sampling methods for reducing variance.Moreover,some methods sample nodes in an ordered pattern,where the sampling standard is defined by some metrics,such as visit frequency and publish time.
2) Sampling Condition
It denotes the specific sampling condition of each samplingmethod.To show the similarities between different methods,we simply highlight the characteristics of the sampling operation,for example,we define both the sampling conditions of AS-GCN and LADIES as layer-dependent sampling though the two are slightly different throughout the sampling process.This unified definition is conducive to classifying and analyzing methods based on similarities and differences.
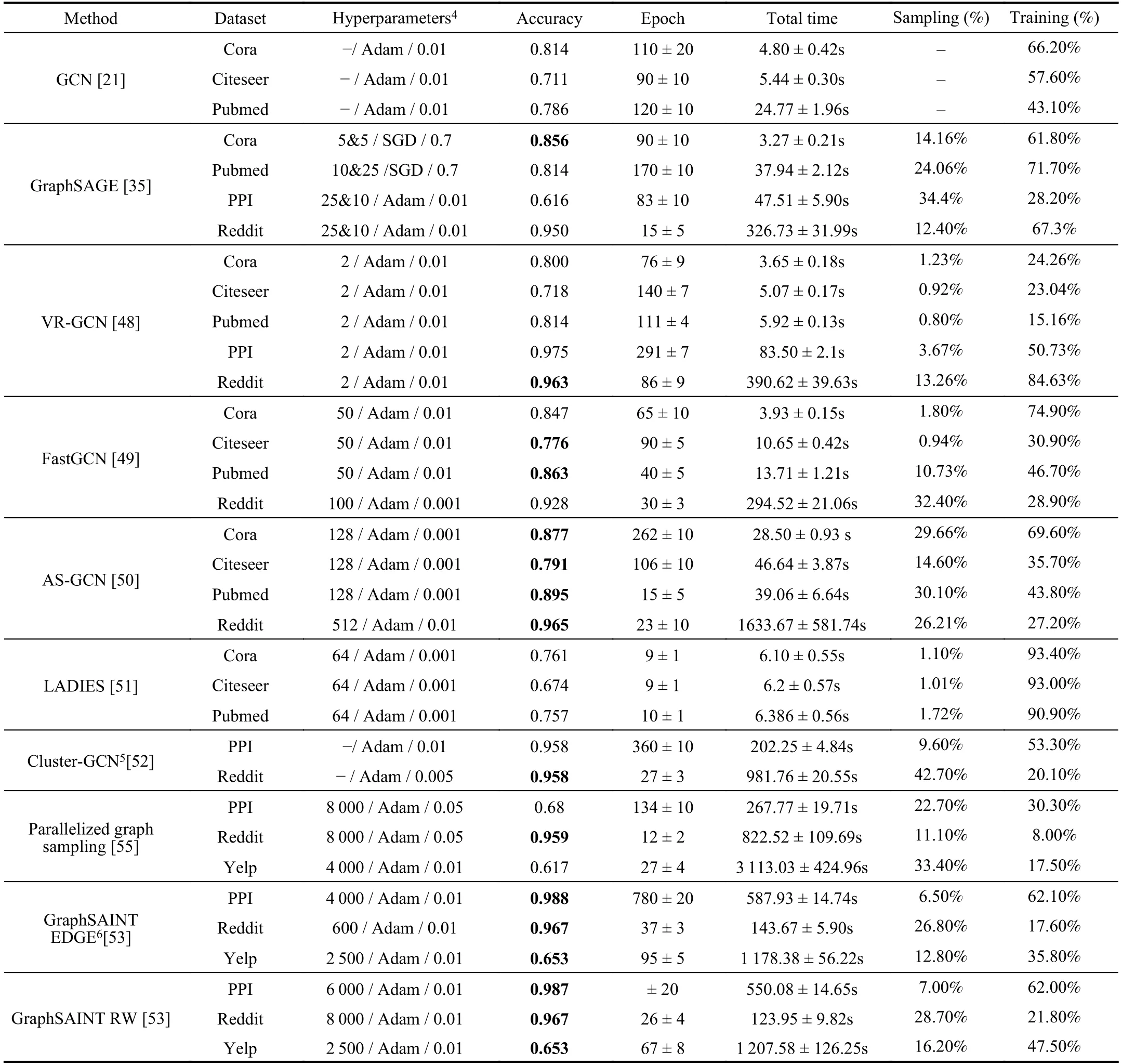
TABLE XIIIDETAILED PERFORMANCE COMPARISON ON SAMPLING METHODS
3) Target Problem
It denotes the target problem being solved in each work.To analyze a work comprehensively,we should focus on not only the sampling algorithm,but also the difficulty to be solved by sampling and the target problem of the work.Besides,the target problem is closely related to the motivation of a work.For example,most layer-wise sampling methods are proposed to alleviate neighbor explosion caused by recursive neighbor sampling.And most heterogeneous sampling methods are devoted to learning representation in heterogeneous graphs.In this way,the key idea of a work can therefore be comprehended by jointly considering the sampling condition and the target problem.
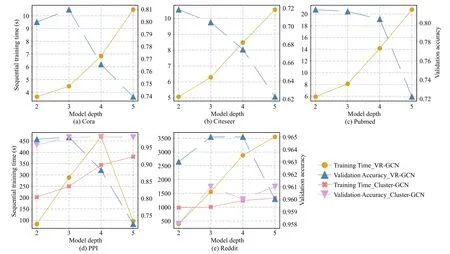
Fig.7.Time-accuracy comparison of node-wise and subgraph-based sampling methods on deep models.
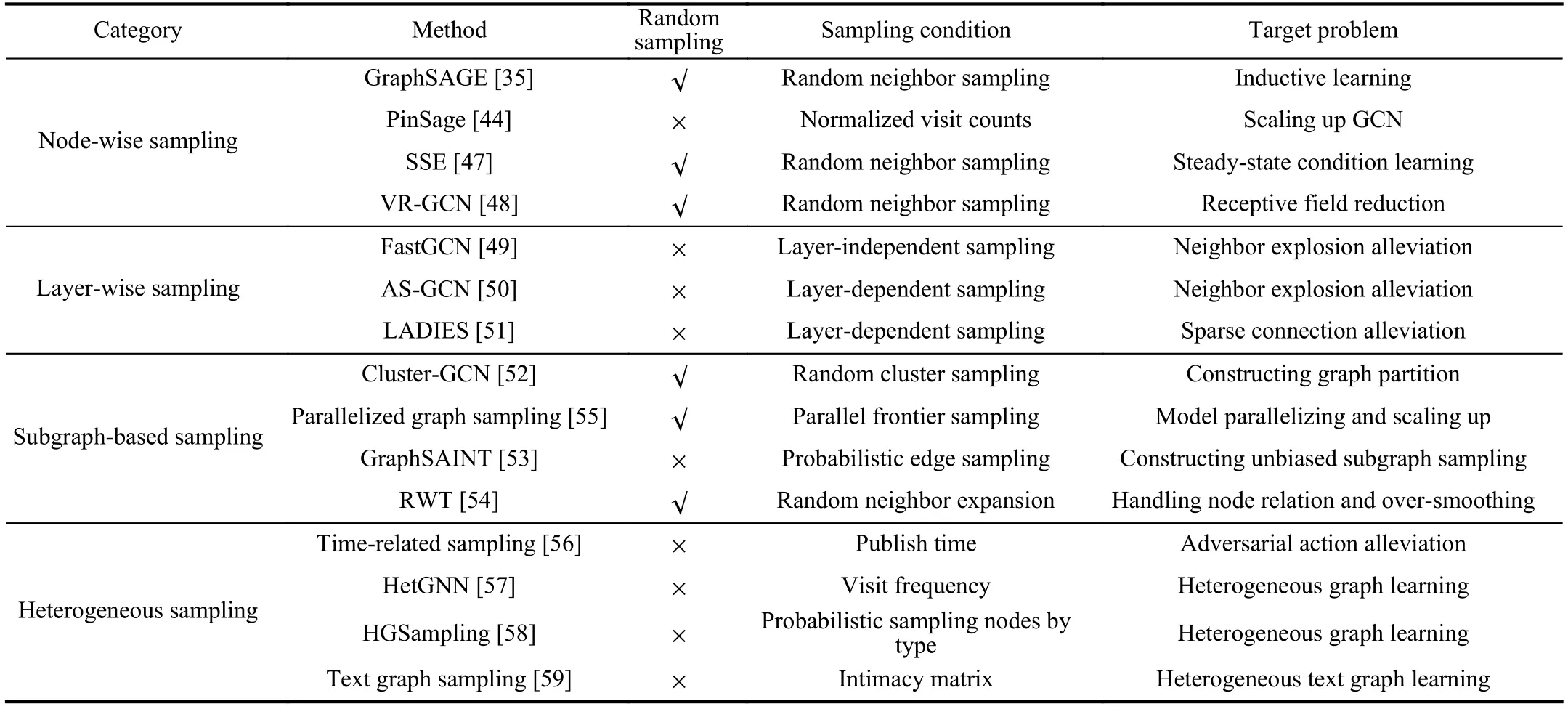
TABLE XIVCOMPREHENSIVE SUMMARY OF SAMPLING METHODS IN ALL CATEGORIES
V.CHALLENGES AND FUTURE DIRECTIONS
In this section,we discuss some challenges and future research directions of sampling methods.Although sampling methods accelerate the training of GCN efficiently and reduce the cost of training in terms of computation and storage,there are still challenges due to some factors in graphs’characteristics and training.
Firstly,sampling methods inevitably introduce variance and bias into the training compared with the exact training approach.In most instances,it is challenging to achieve an appropriate trade-off between accuracy and runtime.Secondly,as graphs grow large and complex,sampling methods are enhancing the requirements in computation and storage for experimental platforms.Thirdly,it is significant to take the hardware into consideration when performing sampling methods to GCN since the hardware is getting increasingly important in GCN training.Fourthly,some sampling methods designed for homogeneous graphs can hardly be directly applied to heterogeneous graphs.Moreover,stacking more layers to form a deeper GCN model is an emerging trend for improving performance.Performing sampling on deep models is a challenging task.Therefore,there is still room for improvement of sampling methods.Next,we suggest some potential directions of sampling methods in the future.
1)Variance Reduction and Elimination
Instead of training GCN with all nodes in a graph,sampling methods accelerate the training by conditionally selecting partial nodes and bring about,which is unavoidable,a slight accuracy loss.To solve the problem,some existing sampling methods leverage importance sampling technique to reduce variance [49]–[51],while others reduce variance by adding special mechanisms [48],[52],[53],[58],[73].Besides,it is promising to execute variance reduction in an explicit manner.For instance,AS-GCN [50] and MVS-GNN [73] adaptively sample nodes and explicitly reduce variance in the training of GCN.Therefore,we suggest optimizing sampling methods with variance reduction and elimination techniques.Through this way,it is feasible to build time-saving sampling methods with better accuracy than exact training approachs.
2)Co-Ordination With Experimental Platforms
Taking full advantage of experimental platforms benefits the training and inference of GCN significantly.Recently,instead of merely performing GCN on GPU (CPU),various experimental platforms are used for accelerating training and inference of GCN,for instance,paralleled platform [55],(multi-) FPGA platform [74]–[76],and heterogeneous platform [77],[78].On the other hand,the costs in terms of computation and storage of sampling methods are growing large as the explosion of the graph size,putting pressure on existing experimental platforms.All these put forward a higher demand to enhance co-ordination with experimental platforms.Therefore,we suggest optimizing sampling methods by leveraging characteristics and advantages of experimental platforms.It is also useful to design a fitting sampling method for a specified experimental platform.
3)Hardware-Friendly Sampling
In recent years,a few works have been proposed to optimize GCN based on the specific hardware design.Most of these works accelerate the inference process or a certain phase in the training of GCN leveraging hardware characteristics and specially designed tools [43],[74],[78]–[82].For instance,Hygcn [43] accelerates the inference process by optimizing two processing engines in inference with the help of an interengine pipeline and a priority-based memory access coordination.However,the sampling phase is gradually becoming a time-consuming process with the drastic extension of graph data,which affects the execution efficiency of the training to a large extent.Just as these accelerators use hardware characteristics to speed up the inference process,we suggest accelerating the sampling process using hardware characteristics.And this raises the question of what characteristics should be carefully considered to design a hardware-friendly sampling method.
4) Heterogeneous Graph Sampling
Recently,there has been a growing trend in the study of heterogeneity of graphs.Compared with homogeneous graphs,heterogeneous graphs are superior to model complex structures of graphs in the real world,e.g.,Xianyu Graph [56] and open academic graph (OAG) [83].However,heterogeneous graphs typically include edges and nodes in different types[57],[84],and most existing sampling methods designed for homogeneous graphs cannot be directly used since applying these sampling methods to heterogeneous graphs may lead to an imbalanced sampling result in terms of different types of nodes and edges [58].As a result,there is an urgent need to extend original sampling methods to heterogeneous graphs.We suggest improving the original sampling method by merging the characteristics of several sampling methods in different categories.It is also useful to design a novel sampling method for a specific heterogeneous graph.
5)Sampling in Deep Models
Deep GCNs are attracting more attention and are intuitively regarded as a potentiality for improving model capability since constructing a deep structure helps CNNs achieve outstanding performance in tasks of diverse fields [85]–[87].However,it has been theoretically demonstrated that GCN[21] is not applicable to scale a deep model due to the phenomenon of over-smoothing [88],[89].Thereby,various approaches are proposed to overcome the phenomenon of over-smoothing for enabling deep GCNs training,e.g.,adding skip connections [46],[50],[71],using regularization techniques [88],[90],and concatenating multi-scale information [91]–[93].Most of these approaches target alleviating destructive impact from over-smoothing by modifying models or leveraging extra techniques.We argue that sampling methods could also benefit the address of oversmoothing.For instance,SHADOW-GNN [94] applies shallow subgraph-based sampling methods to deep GCNs to guarantee the unique aggregation of any two nodes and preserve node feature information,which helps avoid the damage to the diversity of the converged aggregation features.Thereby,we suggest designing suitable sampling methods according to the model depth and aggregation mechanism for overcoming the phenomenon of over-smoothing synergistically.
VI.CONCLUSIONS
In this paper,we conduct a thorough survey on sampling methods for efficient training of GCN.Specifically,we provide a taxonomy that categorizes sampling methods into four categories,i.e.,node-wise sampling,layer-wise sampling,subgraph-based sampling,and heterogeneous sampling.Based on the taxonomy,we compare sampling methods from multiple aspects and highlight their characteristics for each category.Finally,we discuss challenges faced by the existing sampling methods and suggest five potential directions of research.
 IEEE/CAA Journal of Automatica Sinica2022年2期
IEEE/CAA Journal of Automatica Sinica2022年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Fault Accommodation for a Class of Nonlinear Uncertain Systems With Event-Triggered Input
- Precise Agriculture:Effective Deep Learning Strategies to Detect Pest Insects
- Maximizing Convergence Speed for Second Order Consensus in Leaderless Multi-Agent Systems
- Exponential Set-Point Stabilization of Underactuated Vehicles Moving in Three-Dimensional Space
- An Adaptive Rapidly-Exploring Random Tree
- Aerodynamic Effects Compensation on Multi-Rotor UAVs Based on a Neural Network Control Allocation Approach