
多云协同构架云数据分区并行挖掘算法研究
2022-01-25 02:54尚影,牛磊
安徽职业技术学院学报 2021年4期
尚 影,牛 磊
(1.阜阳幼儿师范高等专科学校 小学教育学院,安徽 阜阳 236015;2.阜阳师范大学 计算机学院,安徽 阜阳 236037)
云计算和大数据挖掘技术的高速发展,多云协同构架云数据的挖掘逐渐受到人们的关注。人们通常根据数据特征,采用分布式的实体融合性聚类分析方法,建立多云协同构架云数据并行挖掘模型,提高多云协同构架云数据的管理和特征分析能力,从而提高多云协同构架云数据的特征聚类性,相关的多云协同构架云数据挖掘和并行调度研究在云数据管理和协同调度领域具有很好的应用价值[1-2]。
多云协同构架云数据挖掘是建立在数据的特征分析和属性筛选基础上,构建多云协同构架云数据关联规则聚类分布集,通过特征子集的筛选和融合聚类分析,实现多云协同构架云数据挖掘和并行特征提取[3-4]。当前,多云协同构架云数据挖掘方法主要有模糊子空间聚类分析方法、关键特征子集选择方法、属性融合分析方法等。传统方法一般会采用适应度分析和数据集度量方法,进行多云协同构架云数据挖掘和特征提取[5-6],但存在挖掘结果模糊度较大以及计算开销较大的问题。
为此,本文提出一种新的多云协同构架云数据关联规则分区挖掘算法。首先构建多云协同构架云数据的分布式存储结构模型,采用约束性连续值属性特征分解方法,建立多云协同构架云数据的特征数据聚类模型,然后采用边界特征点融合和阈值分割方法,实现多云协同构架云数据的信息融合和聚类处理,结合决策树聚类分析模型,完成对多云协同构架云数据并行挖掘过程中的数据分类,采用关联规则分区调度和融合方法,实现多云协同构架云数据的并行挖掘和离散化融合聚类处理,提高多云协同构架云数据的协同并行挖掘能力。最后进行仿真测试分析,测试结果显示本文方法在提高数据关联规则分区并行挖掘能力方面具有优越性能。
1 多云协同构架云数据存储和融合
1.1 云数据存储结构
为实现数据关联规则分区并行挖掘,首先构建多云协同构架云数据的分布式存储结构模型,采用约束性连续值属性特征分解方法,对特征量进行分解,实现对多云协同构架云数据的融合处理[7-8],得到多云协同构架云数据存储结构模型如图1所示。

图1 多云协同构架云数据存储结构模型
采用决策树模型和量化回归分析方法,依据特征向量来决定对应的输出值,将特征空间划分成若干单元,按照特征将其归到某个单元,得到云数据额分组传输控制协议[9-10],由控制协议得到多云协同构架云数据传输的标准差σj,分析多云协同构架云数据的第i条记录第j个属性值的样本聚类特征量,采用相似性融合方法,得到多云协同构架云数据的相异度特征分量ri()
j,计算关系为:

其中,μ 为每一个属性的信息增益,i=1,2,…,n,j=1,2,…,m。根据已有算术平均值和中值计算的方法,得到多云协同构架云数据存储线性结构分布为:

其中,Ai(j)为多云协同构架云数据的变异度。计算第i 条记录第j 个属性多云协同构架云数据分布差异性特征量,表示为:

考虑云数据特征属性 X、Y 的相关系数,得到多云协同构架云数据的属性集相异性特征分量为me,依据现有的多云协同构架云数据的属性相异度[11],可知多云协同构架云数据的模糊相关性属性值为:

其中,sh为循环执行直至产生多云协同构架云数据的特征参数,得到多云协同构架云数据的模糊信息融合构造随机函数为b(u)。
根据上述分析,将数据集中的属性作为一个聚类特征,得到第j个Tausworthe 随机数生成的多云协同构架云数据的模糊度特征量为K(w),结合交互式融合的方法,得到多云协同构架云数据的输出稳态特征值为:

计算多云协同构架云数据的数据包的特征子集,得到多云协同构架云数据挖掘的时延控制参数模型[12-13]。
1.2 多云协同构架云数据特征分析
采用边界特征点融合和阈值分割方法,集合模糊度特征量周边的特征点,设定不同的特征阈值,将云数据分成若干类,实现多云协同构架云数据的信息融合和聚类处理[14-15],结合决策树聚类分析模型,得到多云协同构架云数据的关联分布函数为:

其中,Γv,Γr为自适应寻优实现对多云协同构架云数据的特征寻优和解析控制参数,l为关联特征函数。
采用融合和时延控制的方法,得到多云协同构架云数据的模糊关联规则分布函数为UT=U-1,D∈Rm×M,且D=[∑ 0],结合语义分析,得到多云协同构架云数据挖掘的语义特征分量:

根据多云协同构架云数据挖掘的特征属性子集,可知多云协同构架云数据挖掘的阈值函数满足:
X(2)={x2(1),x2(2),...,x2(9)}={2,1,4,8,6,3,9,5,7},输出多云协同构架云数据挖掘的模糊信息融合结果多云协同构架云数据的关联规则集X(3)={x3(1),x3(2),...,x3(8)}={4,1,3,8,7,6,2,9},得出多云协同构架云数据的样本子集分布结果采用优先级聚类和关联规则排序方法,实现多云协同构架云数据挖掘的优先级融合排序,记L1,...,Ln和为数据样本子集,根据多云协同构架云数据挖掘的分布式特征融合结果,考虑多云协同构架云数据挖掘的数据包的排列分布概率。选择Qn作为多云协同构架云数据的模糊度特征量,得到分别表示多云协同构架云数据概念集和测试集,记多云协同构架云数据的测试集为I,概念集为J,得到多云协同构架云数据的并行挖掘的均值函数为:

结合离散化调度,构建多云协同构架云数据挖掘的寻优函数:

根据多云协同构架云数据的交互误差进行大数据挖掘和过程采样,f(u)为多云协同构架云数据的分割函数,DS为多云协同构架云数据挖掘的优先级系数。根据上述分析,采用边界特征点融合和阈值分割方法,实现多云协同构架云数据的信息融合和聚类处理[16-17]。
2 数据关联规则分区并行挖掘优化
2.1 云协同构架云数据融合聚类
采用边界特征点融合和阈值分割方法,实现多云协同构架云数据的信息融合和聚类处理,结合决策树聚类分析模型,建立数据包排队序列分布融合模型,得到云协同构架云数据的自相关特征量:

采用决策树和模糊C 均值聚类,得到云协同构架云数据的特征参数为Cw,通过聚类中心的输出增益控制,得到云协同构架云数据的并行挖掘的可靠性融合函数为a,多云协同构架云数据的权重特征分布为E(s)。
利用候选阈值分割的方法,得到多云协同构架云数据的离散化阈值分割函数为:

其中,θ0和Δ表示多云协同构架云数据挖掘的时延和偏移系数。
采用梯度信息融合,得到多云协同构架云数据交互的均衡控制模型,得到模糊信息调度矩阵:

其中,ru为数据交互的均衡控制特征参数,将多云协同构架云数据连续字段属性值按照从小到大排序[18-20],得到多云协同构架云数据的扩展能量开销为g(i)。考虑数据包的大小和能量开销,得到多云协同构架云数据融合聚类输出为:

其中,ω(t)为当前多云协同构架云数据传输的聚类系数,综上分析,实现对多云协同构架云数据的融合聚类处理。
2.2 数据挖掘输出
关联规则主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(Fre⁃quent Itemsets),第二阶段再由这些高频项目组中产生关联规则(Association Rules)。采用关联规则分区调度和融合方法,将挖掘后的数据进行分区管理,实现多云协同构架云数据的并行挖掘和离散化融合聚类处理,提高多云协同构架云数据的协同并行挖掘能力,得到多云协同构架云数据挖掘的时延为:
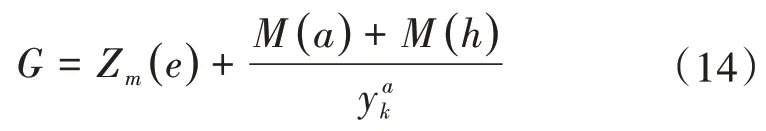
在信息增益最大点时,得到多云协同构架云数据挖掘的关联规则分区聚类约束规划模型为:

采用连续值属性分析方法,进行多云协同构架云数据挖掘的关联规则分析,得到有限数据集Y={y1,y2,...,yn} ,n 是多云协同构架云数据集 Y 的分区块数,得到最佳阈值分割的属性分布为c(A)。基于边界点判定的方法,得到多云协同构架云数据的联合关联规则挖掘分布为:
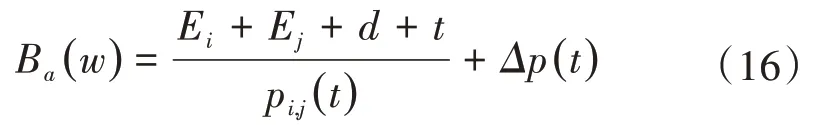
其中:pi,j(t)为多云协同构架云数据的边界点的信息增益,Δp(t)为梯度输出增益。用4 元组(Ei,Ej,d,t)来表示多云协同构架云数据的优先级数据包排序集,由此构建多云协同构架云数据关联规则分区并行挖掘模型,实现步骤示意图如图2所示。

图2 算法实现步骤示意图
图2 中,稀有类拓展实例选择算法(MEIS)对训练集中数据进行选择,选择后的特征再经由特征选择(PCA)选择已有的有限数据集,使系统的具体指标最优化,从现有数据集中选出一些最有效的特征,从而减少数据集的维度。
3 仿真测试分析
为验证本文方法在实现多云协同构架云数据并行挖掘中的应用性能,采用Matlab 进行仿真测试分析待挖掘的数据如图3 所示(数据形状不同说明其种类不同)。

图3 待挖掘的多云协同构架云数据
由图3 可知,采用边界特征点融合和阈值分割方法,使得原有测试集中的数据可以按照种类进行分布,分区效果明显,且同一种类的数据聚集紧密,由于训练集中的数据边界特征点无法得以融合,训练集中的同一种类数据分布较为分散。以图3 的数据为研究对象,进行多云协同构架云数据的分区并行挖掘,得到挖掘结果如图4所示。

图4 多云协同构架云数据分区并行挖掘输出
分析图4 得知,由于采用关联规则分区调度和融合方法,使得不同种类的数据分区效果明显,且数据聚集紧密,证明本文方法进行多云协同构架云数据分区并行挖掘的输出特征聚类性较好,提高了数据挖掘的分区聚类性能,测试不同方法进行多云协同构架云数据分区并行挖掘的精度,得到对比结果如图5所示。

图5 数据挖掘精度对比
分析图5 得知,随着迭代次数的不断增加,本文方法的挖掘精度不断提高,增长速度较快,在迭代次数4-12 时挖掘精度增长速度缓慢,收敛性差、精度偏低,与之相比,本文方法基于并行挖掘算法进行多云协同构架云数据分区并行挖掘的精度较高,可应用性更强。
4 结语
本文提出基于并行挖掘算法的多云协同构架云数据关联规则分区挖掘算法。采用边界特征点融合和阈值分割方法,实现多云协同构架云数据的信息融合和聚类处理,通过聚类中心的输出增益控制,得到云协同构架云数据的并行挖掘的可靠性融合函数,采用关联规则分区调度和融合方法,实现多云协同构架云数据的并行挖掘和离散化融合聚类处理。研究得知,本文方法对多云协同构架云数据挖掘的并行效率较高,挖掘精度较高。
猜你喜欢
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
建材发展导向(2021年7期)2021-07-16
中华养生保健(2020年3期)2020-11-16
作文周刊·小学一年级版(2020年20期)2020-09-02
电子制作(2018年17期)2018-09-28
知识经济·中国直销(2018年7期)2018-07-27
中华诗词(2018年1期)2018-06-26
小学生作文·小学低年级适用(2016年4期)2017-01-16
人间(2015年11期)2016-01-09
