
一种基于LSTM模型的水库水位预测方法
2022-01-23 03:46刘威,尹飞
无线电工程 2022年1期
刘 威,尹 飞
(1.金陵科技学院 网络与通信工程学院,江苏 南京 211169;2.江苏省连云港市水利局,江苏 连云港 222006)
0 引言
水库通过改变水资源的时空分布来达到兴利除害的目的。水库的一个重要功能是蓄水防洪。在防洪工作中,可以通过对防洪风险的估测来辅助水库的调度决策。在这些风险估测中,水库水位是一个最为重要的参数。目前,随着人工智能、大数据等技术的不断发展,对于水库水位的长期估计,可以采用深度学习的方式进行预测[1-2]。
深度学习中有不同类型的神经网络,常用的有人工神经网络(Artificial Neural Networks,ANN)、卷积神经网络(Convolutional Neural Networks,CNN)和周期神经网络(Recurrent Neural Networks,RNN)。在深度学习的模型构建过程中,最重要的步骤是特征提取和特征选择。在特征提取中,一般提取待解决问题的重要特征。在特征选择中,一般要选择那些能够提高机器学习或深度学习模型性能的特征[3-5]。
ANN一般由输入层、隐藏层和输出层组成,每一层都包含多个感知器或神经元。ANN也被称为前馈神经网络,输入只在正向处理,可以用来解决表格数据、图像数据和文本数据等问题,优点是能够学习任何非线性函数。因此,这些网络通常被称为通用函数逼近器。ANN的缺点是容易失去空间特征。比如,在使用神经网络解决图像分类问题时,首先要将二维图像转换为一维向量,然后再对模型进行训练。这里有2个缺点:随着图像大小的增加,可训练参数的数量急剧增加;影像分类存在延时[6]。
CNN模型被用于不同的应用和领域,在图像和视频处理项目中尤其普遍,在处理序贯数据(Sequence Data)方面的表现也令人印象深刻。CNN的组成部分是过滤器,又称内核[7]。内核用于使用卷积运算从输入中提取相关特征。优点是可以自动学习过滤器,而不必显式地监控它。这些过滤器有助于从输入数据中提取正确的和相关的特征。
RNN在隐藏状态上有一个循环的连接。这个循环约束确保在输入数据中能捕获到含有顺序的信息。RNN特别适合解决以下问题:时间序列数据、文本数据和音频数据[8]。优点是可以利用输入数据之间的依赖关系(时间、空间上)。但是,RNN存在梯度消失和梯度爆炸问题。
长短期记忆(Long Short Term Memory,LSTM)网络是一种特殊的RNN[9-11]。本身有“门”(gate)这种设计,所以能够通过gate的值来决定信息的保留和丢失,这样就可以让长期依赖的信息沿着序列一直传递下去[12-14]。LSTM模型目前已被广泛地接受用于时间序列预测。最近,一些关于水位预测的研究使用了具有深度学习的LSTM模型,特别是在河流洪水事件期间。LSTM的内部结构适合于预测时间序列数据,因为它的记忆功能保留了过去的顺序模式。因此,本研究也采用LSTM模型来预测水位。该LSTM结构在传统LSTM隐含层结构的基础上扩展了多个隐含层[15]。
上述学者提出的数据驱动模型取得了预期效果,特别是基于RNN模型的洪水预测模型得到了很大的改进。但并非所有的输入数据都与水位预报具有正相关关系,比如,不相关的输入数据往往会带来大量噪声。综上所述,基于常用数据驱动模型的中型水库水位预测局限于以下两部分:① 水库水量受降雨、水流和上游土壤含水量等因素的影响。然而,一般的数据驱动模型很难保留上述物理量的长期历史信息,这使得预测难以达到预期的准确性。② 在进一步增加预测时间步长的情况下,数据驱动模型的预测精度易出现剧烈下降。
针对上述常见模型的局限性,提出了一种基于长期历史物理量和最优化预测时间步长的LSTM模型,该模型整合了降雨、水流和土壤含水量等历史信息,并通过实验获取最优预测步长。本文实验结果表明,与多层感知机(Multi-Layer Perceptrons,MLP)模型和CNN模型相比较,本文提出的LSTM模型性能优于MLP和CNN模型。在NSE评价指标中,LSTM模型的性能比MLP提升了12.2%,比CNN提升了5.1%。在R2评价指标中,LSTM模型的性能比MLP提升了5.9%,比CNN提升了1.4%。在RMSE评价指标中,LSTM模型的性能比MLP降低了34.7%,比CNN降低了25.8%。
本文的主要创新点如下:① 改进了基于LSTM模型的数据使用方式,建立了历史水量信息与水位之间的长期依赖关系;② 通过实验获得预测步长的最优值,确保模型的预测精度不会随着预测时间步长的增加而急剧下降。结果表明,本文建议的方法在一个真实的洪水事件上具有显著优势,雨量较小时不会引起预报线的波动,且预测洪峰时偏离较小,不会导致错过洪水警报。
1 LSTM模型介绍
在当前时刻t,输入数据包含多个节点。在前一时刻t-1,输出数据ht-1也包含多个节点。节点大致模拟了大脑中的一个神经元。输入数据依次经过3个门:遗忘门、输入门和输出门。式(1)定义了遗忘门ft的作用,它从记忆单元中移除一些信息:
ft=σ(wf,hht-1+wf,xxt+bf),
(1)
式中,wf,h和wf,x是和ht-1,xt相关的系数;bf为偏置量;σ(·)为S型函数,也称为S型生长曲线,这里被用作激活函数。输入门与输入数据的2类特征源混合。下式表示了2种来源:
it=σ(wi,hht-1+wi,xxt+bi),
(2)
zt=tanh(wz,hht-1+wz,xxt+bz),
(3)
式中,tanh(·)为双曲正切型的激活函数;wi,h,wi,x,wz,h和wz,x为矩阵形式的加权系数;变量ft,it和zt被组合成:
Ct=ft⊗Ct-1⊕it⊗zt,
(4)
式中,⊗表示矩阵的点积计算;⊕表示矩阵的点和计算。输出门ot的定义为:
ot=σ(wo,hht-1+wo,xxt+bo),
(5)
式中,wo,h和wo,x是和ht-1,xt相关的系数;bo为偏置量。最后,Ct与ot相乘,并且更新输出ht:
ht=ot⊗tanh(Ct)。
(6)
为了判断预测的准确性,通常使用以下几类评价指标:Nash-Sutcliffe效率(Nash-Sutcliffe Efficiency,NSE)、Pearson相关系数平方(Squared Pearson Correlation Coefficient,R2)、RMSE和相对均方根误差(Relative Root Mean Square Errors,rRMSE)、绝对偏差(Bias)和相对偏差(Relative Bias,rBias)以及持续性指数(Persistency Index,PI)。其中,评价指标NSE定义为:
(7)
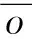
Pearson相关系数平方R2的定义为:
(8)
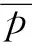
RMSE定义为:
(9)
RMSE的值对特别大的误差值敏感,因此可以反映模型的预测精度。RMSE的值越大,说明预测值与测量值之间的误差越大。
rRMSE定义为:
(10)
Bias定义为:
(11)
rBias定义为:
(12)
式中,omax为最大观测值;omin为最小观测值。
PI定义为:
(13)
式中,olast表示最后一个观测值。在以上各项指标中,RMSE和Bias指标虽然都可以用于比较不同模型之间特定时间序列的性能,但是rRMSE和rBias指标用于比较不同时间序列间的模型性能时更有效。PI基本上是将性能与朴素模型进行比较,后者使用预测开始时最后已知的水库水位。当使用过去的水库水位作为输入时,上述数据的选择对于判断性能尤其重要。此时,该模型的性能应该优于朴素预测(即PI>0)。
2 项目背景
沂沭泗水系是淮河流域内一个相对独立的水系,系沂、沭、泗(运)3条水系的总称,位于淮河流域东北部,北起沂蒙山,东临黄海,西至黄河右堤,南以废黄河与淮河水系为界。全流域介于114°45′E~120°20′E,33°30′N~36°20′N,流域面积7.96万平方千米,占淮河流域面积的29%。沂沭泗流域多年平均降水为830 mm,最大年为1 098 mm(1964年),最小年为562 mm(1966年)。多年平均年内分配:春季(3—5月)为131 mm,占15.8%;夏季汛期(6—9月)平均为592 mm,占71.3%;秋季(10—12月)平均为77 mm,占9.3%;冬季(次年1—2月)平均为30mm,占3.6%。全流域多年平均径流深为232 mm,年径流系数为0.28。年径流分布与降水分布相似,南大北小,山区大平原小。泰沂山丘区年径流深达348 mm,年径流系数为0.40;南四湖湖西年径流深达97.2 mm,年径流系数为0.14。
石梁河水库的位置如图1所示,地理坐标为34°44′33″N~35°49′46″N,118°44′11″E~118°52′31″E。其周围有蒋庄闸、南闸和北闸3个闸所,该水库是江苏省最大的人工水库,也是“导沭(河)经沙(河)”主要工程之一。
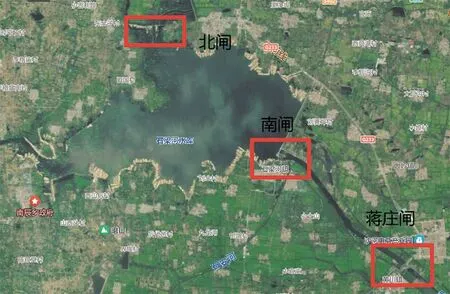
图1 石梁河水库及闸所示意Fig.1 Illustration of location of Shiliang River reservior and its three gates
本文获取了2011—2020年,在石梁河水库及其周边所有泵站、闸门的水位传感器观测数据。每个泵站收集的数据是泵流量(简称“流量”)、降雨量和水位。测量了每个闸门的上游和下游水位,在每个传感器位置测量水位。这些数据被用来训练LSTM模型并评估模型预测的误差。采用K-fold交叉验证进行验证比较。K设为10,将观测数据分为10组。9组对模型进行训练,1组对模型预测结果进行比较。模型预测组按顺序与其他组进行交换。第1步的观测数据来自实地测量。在第2步的学习过程中,部分观测数据被用于K-fold交叉验证。第3步利用剩余观测数据进行预测。LSTM模型的程序是使用Python(版本3.8.8)和Keras中Python深度学习库创建的。其中包含了Windows操作系统PC上的tensorflow模块,PC上的Intel Core i7-4770K CPU为3.50 GHz,GPU为Nvidia GeForce RTX 2070,所有情况下的平均计算时间约为1 h。
3 实验及仿真结果
在实验中,利用训练后的模型,输入代表水位信息的时间学历,并运行LSTM模型,可以得到如图2所示的预测结果。图2的上半部分,是全部15 000个观测值的预测情况。可以看出,LSTM预测结果与实际的观测结果基本吻合,在部分峰值处和谷值处,预测值误差稍大。但是,由于样本较多,无法看到某微观时间段的预测结果。鉴于此,在图2的下半部分,仅选取了其中500个观测值和预测值进行绘图,从中也可以看出,预测值与观测值的误差较小,2条曲线基本一致。
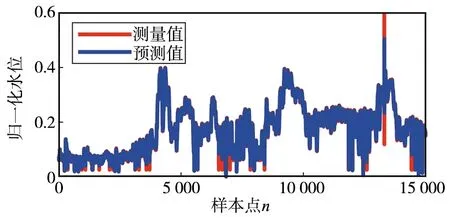
(a) 测量值与预测值比较(全部样本)
另外,为了评价本文模型的性能优劣,将LSTM模型的结果与MLP模型、CNN模型的结果进行了对比。性能评价指标选择了NSE,R2和RMSE三类。具体仿真结果如表1所示。从表1可以看出,在NSE评价指标中,LSTM模型的性能比MLP提升了12.2%,比CNN提升了5.1%。在R2评价指标中,LSTM模型的性能比MLP提升了5.9%,比CNN提升了1.4%。在RMSE评价指标中,LSTM模型的性能比MLP降低了34.7%,比CNN降低了25.8%。
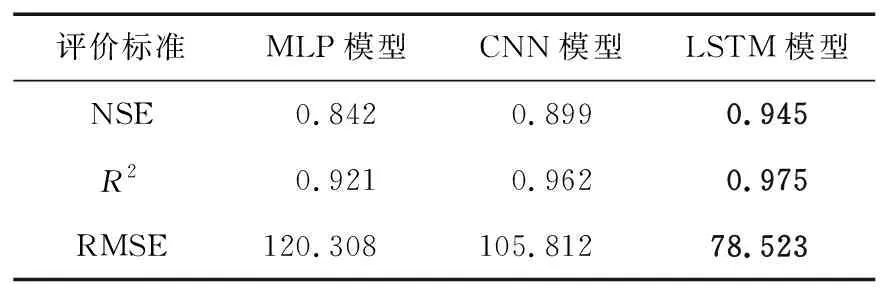
表1 MLP,CNN,LSTM三种模型预测结果比较
LSTM模型性能较好的主要原因是:与MLP和CNN模型相比较,LSTM模型的预测值不存在明显较小的波峰或波谷。该结果表明,LSTM的记忆遗忘能力有助于模型对非线性和时间序列数据的预测,对水库水位的预测有较好的效果。但是,LSTM在主峰值预测方面仍然有误差,大多数主要峰值预测超过实际值约10%。若想解决这类问题,需要调整训练过程,或者采用更大规模、更准确的可用数据库。
4 结束语
基于降雨量、流域水量、土壤水含量和中小河流洪水事件,提出了一种基于LSTM模型的水库水位预测方法。该模型能够学习空间(降水中心)和时间(短时间和长时间)的依赖关系,并且利用了最优步长来提高预测精度。本文采用NSE、R2和RMSE作为模型的性能评价标准,对LSTM模型进行评价。主要结论如下:首先,本文建议的LSTM模型性能明显优于MLP模型和CNN模型;其次,建议的LSTM模型比MLP模型和CNN模型更稳定;最后,通过历史上的实际洪水事件测试,LSTM模型的洪水预报结果更加精确,说明了该模型对洪水过程中的关键节点具备预报能力。
本文建议的模型主要应用于中小流域,在未来的工作中,将重点从以下3个方面进行算法改进和进一步研究:① 在大规模流域中应用该模型;② 对流域中的多个水库水位同时预测;③ 建立更多类型的时空相关性,对水库水位进行预测。
猜你喜欢
中国三峡(2022年6期)2022-11-30
建材发展导向(2021年10期)2021-07-16
知识就是力量(2019年9期)2019-09-09
军事文摘(2018年24期)2018-12-26
中国化妆品(2017年12期)2017-06-27
太空探索(2016年7期)2016-07-10
太空探索(2015年8期)2015-07-18
中国火炬(2013年8期)2013-07-25
中学生数理化·七年级数学人教版(2008年10期)2008-01-21
