
融合LSTM的深度强化学习视觉导航
2022-01-23 03:42刘紫燕梁水波孙昊堃
无线电工程 2022年1期
袁 浩,刘紫燕,梁 静,梁水波,孙昊堃
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
0 引言
视觉导航作为机器人和机器视觉的研究基础[1],已有诸多相关研究成果。传统的机器人导航需要事先完成环境建图,在对环境有了解的情况下才能较为精准地导航,大致需要经过3个步骤:同步定位和建图(SLAM)[2]、路径规划[3]和运动控制,但无法满足要求实时性或紧急状况下的机器人导航,这对无人机[4]和航天[5]的实时导航控制造成了诸多不便。
为了解决上述问题,即实现在无地图状况下的导航,Zhu等人[6]首次将深度强化学习(Deep Reinforcement Learning,DRL)应用到视觉导航领域,提出了一个完整的视觉导航架构,该框架使机器人仅仅依靠图像输入就可导航到目的地,极大地推动了机器人视觉导航研究的发展。该框架的局限在于当前观察的和目标必须处于同一个场景下,而且策略网络已经在此场景下得到了很好的训练。在跨场景的导航过程中,模型的性能有明显下降。文献[7]在Zhu等人工作的基础上将LSTM加在策略生成层之前,以保存最近所走的路径,但稳定性较差。文献[8]用可变通用后继特征逼近器(Variational Universal Successor Features Approximator,VUSFA)解决相当复杂的视觉导航,此框架很容易适应处理导航以外的其他任务。文献[9]提出了一种混合异步通用后继表示(Hybrid Asynchronous Universal Successor Representations,HAUSR)的方法,将它与异步优势演员-评论家算法(Asynchronous Advantage Actor-Critic,A3C)结合从而提升模型在新场景下的适应能力,但是对于长时间及跨场景的导航任务,导航的性能会有所下降。
本文在Zhu等人提出的目标驱动视觉导航框架上改进,提出了一种基于长短时记忆网络(Long Short-Term Memory,LSTM)和后继表征的视觉导航网络模型,使智能体可以跨场景导航(各个场景下的性能不会有较大差异)并具有一定轨迹意识,即结合已有的轨迹在选择动作时能够有意识地躲避场景中的障碍物,提升在多个场景下的导航性能。
1 相关原理
1.1 LSTM
循环神经网络(Recurrent Neural Network,RNN)是一种允许信息持续存在的神经网络[10],依靠已有的知识预测未知的信息,其结构如图1所示。
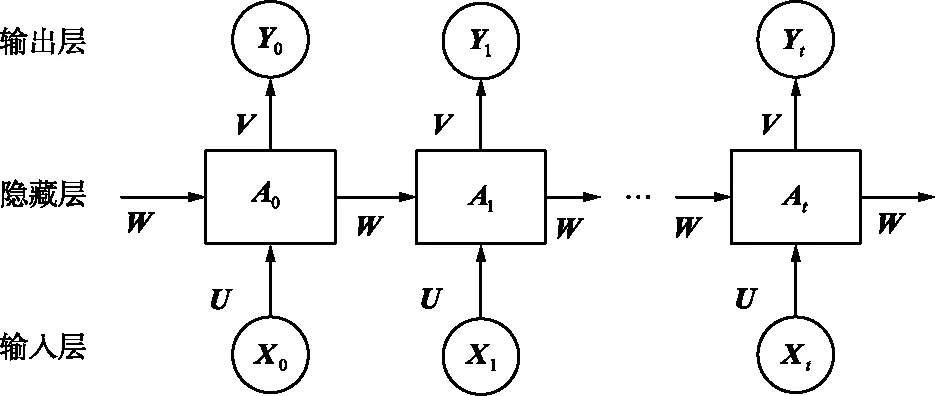
图1 RNN原理Fig.1 Schematic diagram of RNN
RNN主要分为输入层、隐藏层和输出层。图1中,输入Xt为字或词的特征向量,U为输入层到隐藏层的参数矩阵,At为隐藏层的向量,V为隐藏层到输出层的参数矩阵,Yt为输出向量,W为每个时间点的权重矩阵。RNN之所以可以解决序列问题,是因为它可以记住每一时刻的信息,每一时刻的隐藏层不仅由该时刻的输入层决定,还由上一时刻的隐藏层决定,输出Yt和隐藏层向量At的更新公式为:
Yt=g(V·At),
(1)
At=f(U·Xt+W·At-1),
(2)
式中,g和f为激活函数。
RNN中的一部分信息会被循环使用,但RNN的主要问题在于无法保存很多时间步之前的信息,当某个信息经历一定的时间后可能无法利用它进行预测或判断新的信息,这种问题称为“长依赖”。
LSTM是一种改进RNN[11],通过增加“遗忘门”以避免“长依赖”问题,方法是在产生当前时刻输出时,通过一个状态参量来实现遗忘功能。LSTM网络可以长时间记忆信息,不仅可以从单个数据点提取信息,还可以从整个数据系列中提取信息,主要分为遗忘门、输入门和输出门3种。其结构如图2所示。
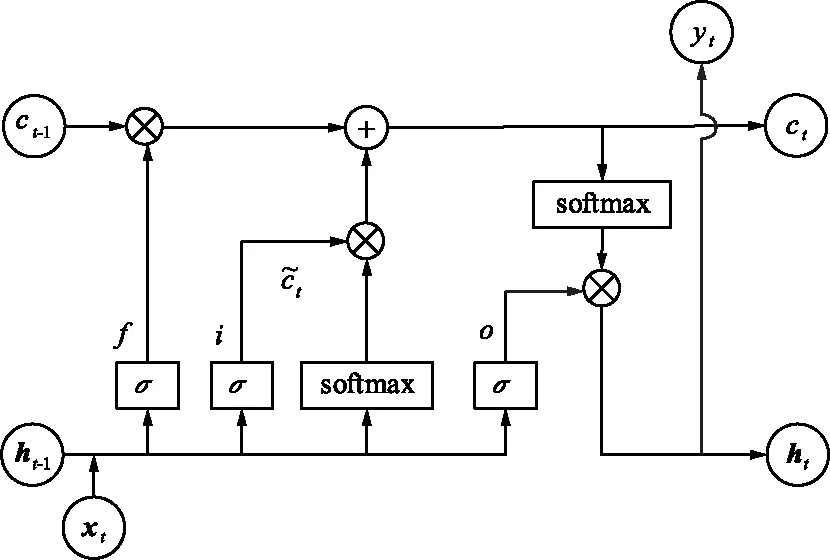
图2 LSTM原理Fig.2 Schematic diagram of LSTM
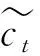
门控单元:
(3)
(4)
(5)
存储单元:
(6)
(7)
输出状态:
ht=ot·tanh(ct),
(8)
式中,W,U表示输入量Xt,ht-1的权值;b为偏置向量,用以调和门控激活函数的输入水平;ct和ht是2个记忆向量;Wf,bf,Wi,bi,Wo,bo可以通过训练获得。∑(·)一般取Sigmoid函数,激活函数Softmax取tanh(·),即:
(9)
(10)
1.2 深度强化学习
强化学习(Reinforcement Learning,RL)的基本原理是利用智能体(Agent)与环境交互以产生新的数据,再利用新的数据进行策略的迭代学习,从而改善自身的决策。通过迭代学习,智能体学到最优策略[12]。智能体根据每个时刻的环境状态信息来学习,可以用马尔科夫决策过程(Markov Decision Process,MDP)来表示。智能体基于当前状态s,选择以策略π为指导的行为,期望其未来折现奖励R最大:
(11)
式中,γ∈[0,1]为折扣因子。通过设置较大的γ值,鼓励模型更加关注未来的回报。如果γ下降,模型的训练将更关注当前行动。
DRL模型定义转换元组为
转移概率P(st+1|s,a)表示从状态s选择动作a转移到状态s′的转移概率,对于任何目标g,定义伪奖励函数rg(st,at,st+1)和伪折扣因子γg(s),对于任意的策略π(at|st),其通用值函数为:
(12)
通过让策略不断学习,使智能体在每集(Episode)中得到的未来折扣奖励最大化[13]。
2 视觉导航方法
目标驱动视觉导航智能体的目的是学习一个随机策略[14]π(st,gt),其中st是当前状态,gt是目标状态。策略的输出π是动作的概率分布。智能体的目标是通过最少的步数导航到目标位置。经过训练,智能体能够在新的场景下导航,从而验证模型的泛化能力[15]。
2.1 基于DRL的视觉导航模型
如前文所述,基于DRL的视觉导航框架最早由Zhu提出,该框架融合了DRL模型和Actor-Critic算法来解决以往DRL算法泛化性差的问题,智能体可以与环境交互,在此环境中收集更多有用的样本[16]。目标驱动的视觉导航网络模型如图3所示,采用4张连续历史帧描述智能体的动作,再用预训练的ResNet50网络分别进行特征提取,投影到特征空间后,把2个孪生层的输出特征串联起来得到融合特征,最后输入到特定的场景得到对应的策略和Q值。
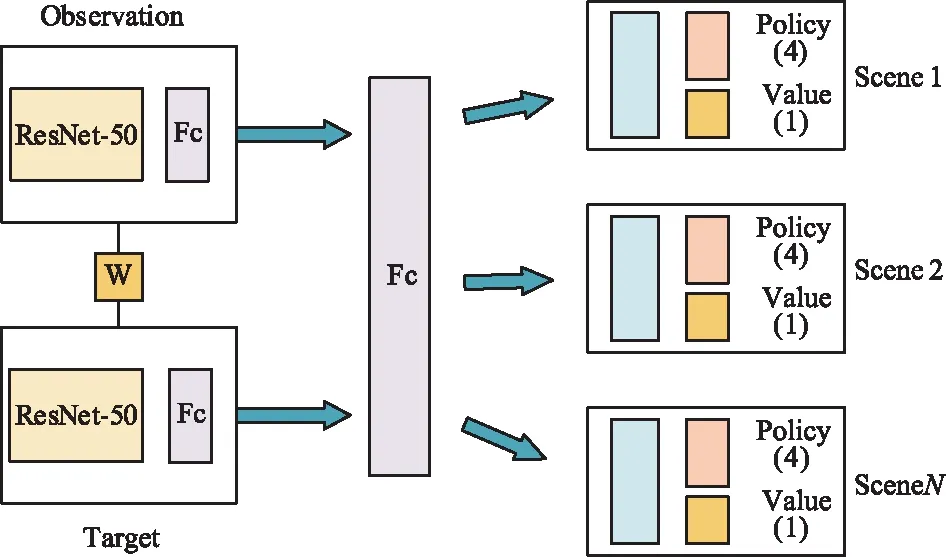
图3 目标驱动的视觉导航网络框架Fig.3 Target-driven visual navigation network framework
2.2 融合LSTM的视觉导航网络
在特定的当前场景中需要采取的动作不仅取决于当前状态,还取决于走过的路径。Zhu等人提出的目标驱动视觉导航模型未将之前的状态作为参考,故本文将状态表征与LSTM相结合实现长期路径感知目标驱动导航,融合LSTM的改进强化学习网络如图4所示。
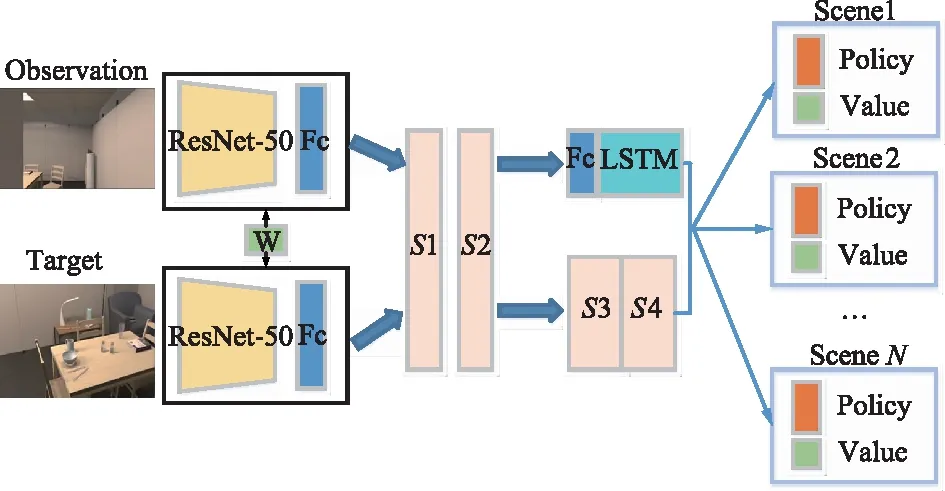
图4 改进的融合LSTM的视觉导航网络Fig.4 Improved visual navigation network with LSTM integrated
该网络由图像输入、共享孪生网络、策略生成网络以及状态表征与奖励预测网络4部分组成。图像输入是智能体当前观察到的及目标所在地的RGB图像,经由共享孪生网络提取特征并投影到特征空间判断2幅图像的空间位置关系后,输入有LSTM的策略生成网络,使用A3C算法,最终输出四维的策略分布和单一的值函数。
2.2.1 共享孪生网络
共享孪生网络由图4中ResNet50和全连接层构成[17],当前观察的图像和目标图像分别对应共享孪生网络的两端。首先将输入的RGB图像(84×84×3)投影到特征空间产生2 048维特征,经ResNet50和全连接层后产生512维特征。共享孪生网络的参数在所有场景中的目标之间共享以确保模型的泛化性。
2.2.2 策略生成网络
策略生成网络由特征融合层、全连接层和LSTM层组成,S1,S2,S3和S4分别为4个特征融合层,由S2引出一路经过全连接层和LSTM后与S4的结果融合,最终输出策略π和对应的Q值。由于使用了A3C算法,智能体可以在多个线程下同时训练,并将训练结果用于更新模型参数,输入的当前状态和目标状态的图像会被以融合特征的方式输入LSTM作为“记忆”来保存,在应对相似的场景或任务时能够更好地做出动作决策。
2.2.3 状态表征与奖励预测网络
对于视觉导航来说,当场景更换时,需要智能体基于对其他任务的经验来选择动作。通用后继表征(Universal Successor Representations,USR)用于表示可转移的知识[18],通过获得一个通用价值函数,并以此来获得最优的策略,其奖励函数rg近似表示为[19]:
rg≈φ(st,at,st+1;θφ)Τω(gt;θω)≈φ(st+1;θφ)Τω(gt;θω),
(13)
即将奖励函数rg近似地表示为状态st+1的编码和目标gt编码的乘积形式,其中,θφ和θω是网络训练的参数。于是,可以将通用价值函数改写为:
ω(gt;θω)=ψπ(st,gt;θψ)Τω(gt;θω)。
(14)
而状态st所对应的USR为ψπ(st,gt),这样对于任何目标gt,都可以根据式(14)计算它的值函数,从而为其设计最优策略,USR使得知识可以在目标之间转移,从而增强模型的泛化能力[9]。状态表征和奖励预测网络如图5所示。
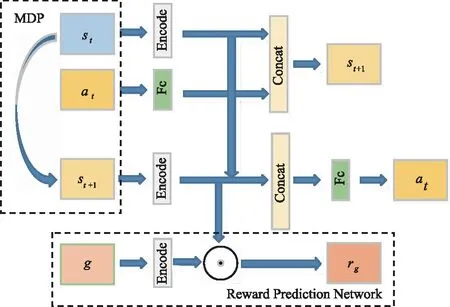
图5 奖励预测与状态表征网络Fig.5 Reward prediction and state representation network
2.2.4 动作空间
在3D环境AI2-THOR中,每个场景被划分为0.5 m×0.5 m的网格,类似于一个网格世界环境。智能体有4个离散的动作:向前移动0.5 m、向后移动0.5 m、左转和右转,采用恒定的步长(0.5 m)和转角(90°)。为了模拟现实世界系统动力学中的不确定性,在每个位置的步长和转弯上添加高斯噪声。
2.2.5 奖励设置
设置奖励函数如式(15)所示,如果智能体到达指定目标,则给予10的正奖励,如果智能体发生碰撞,则给予0.1的负奖励;如果在行进状态,则给予0.01的负奖励,以刺激智能体不断探索:

(15)
3 实验结果及分析
3.1 实验环境
实验环境为Ubuntu16.04,GPU为NVIDIA2080Ti,深度学习框架为TensorFlow,采用的DRL算法为A3C,学习过程中使用8线程A3C算法进行参数优化,采用Adam优化器,学习率从[10-4,5×10-3]区间内按对数均匀分布取样,折扣因子γ=0.99。仿真环境AI2-THOR由120张逼真的平面图组成,如图6所示,包含4种不同的房间布局:厨房、客厅、卧室和浴室,每种布局有30张平面图。将每个场景类型的前20个房间作为训练集,其余10个房间作为评估。在100个线程下同步训练,每个线程下都对不同的目标学习,训练一个模型需要100万个训练帧,从仿真环境中的20个室内场景随机抽取导航的起点和终点进行训练。

图6 AI2-THOR仿真环境Fig.6 AI2-THOR simulation environment
3.2 对比模型和评价指标
基线(Baseline):Zhu等人提出的视觉导航模型,这是目标驱动的视觉导航领域最早提出的模型。LSTM-Nav[7]:在Zhu等人基础上在特征融合层之后,最终的策略输出前添加LSTM网络。HAUSR:提出了一种通用异步后继特征表示方法,与A3C算法结合,使得模型有更好的泛化能力。
本文评价指标为平均轨迹长度(Average Trajectory Length,ATL)、平均奖励(Average Reward,AR)和平均碰撞率(Average Collision,AC)。在4种房间类型共20个场景中评估,每个场景下共100集(Episode),计算方法为:
(16)
(17)
(18)
式中,tli,ri,ci分别是每集(Episode)导航的路径长度、奖励和碰撞次数。
3.3 实验结果与分析
为了验证改进模型的正确性和有效性,在AI2-THOR的浴室_02、卧室_04、厨房_02和客厅_08的部分场景下训练,结果如图7~图9所示,平均轨迹长度单位为步数,训练帧数单位为百万。
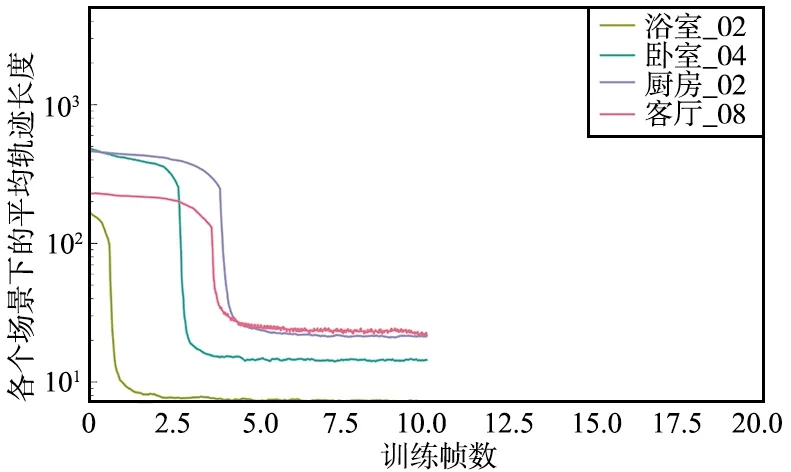
图7 Baseline在4个场景下的平均轨迹Fig.7 Average trajectory of baseline in four scenarios
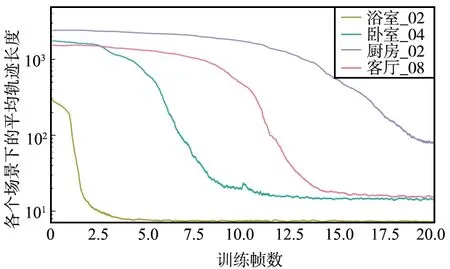
图8 LSTM-Nav在4个场景下的平均轨迹Fig.8 Average trajectory of LSTM-Nav in four scenarios
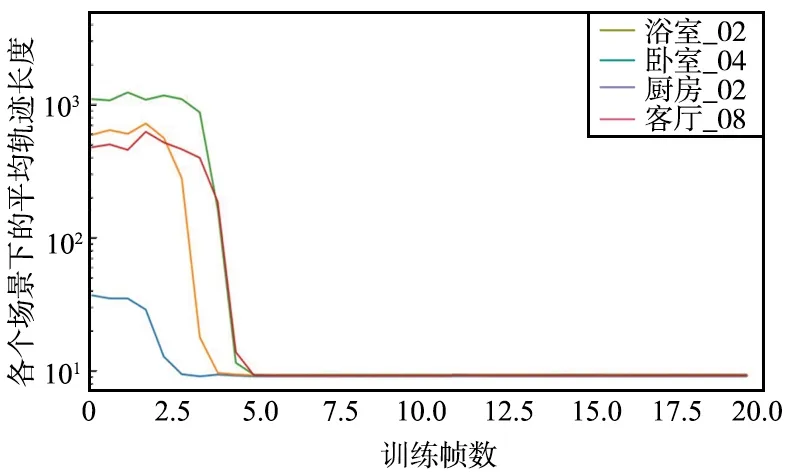
图9 本文模型在4个场景下的平均轨迹长度Fig.9 Average trajectory length of the proposed model in four scenarios
从模型训练的收敛速度来看,Baseline收敛速度最快,改进模型收敛速度介于Baseline和LSTM-Nav之间,LSTM-Nav的收敛速度最慢。
从平均轨迹长度来看,Baseline除了浴室_02场景以外,在其他3个场景下最终收敛到的平均轨迹长度效果较差,而LSTM-Nav除了厨房_02之外,其余3个场景下收敛的平均轨迹长度均好于Baseline,而本文提出的模型相较于Baseline和LSTM-Nav的指标都要更好一些,在4个场景下的平均轨迹长度均收敛到一个较好的水平。
相较于Baseline,在收敛速度慢两百万时间步的情况下,改进模型在所有场景下的平均轨迹长度能够收敛到一个很低的水平,尤其是在除了浴室_02外其余3个场景下,最终的平均轨迹长度远远小于Baseline的结果,平均轨迹长度减少约50%;对比LSTM-Nav,除了厨房_02场景外(LSTM-Nav在此场景下泛化能力较差),平均轨迹长度减少约30%。
除此之外,本文在测试集上进行了模型的泛化性测试,在其他20个场景下测试,将文献[7]中的HAUSR(Hybrid Asynchronous Universal Successor Representations)模型的方法加入作为对比,各模型的平均轨迹长度测试结果如表1所示。
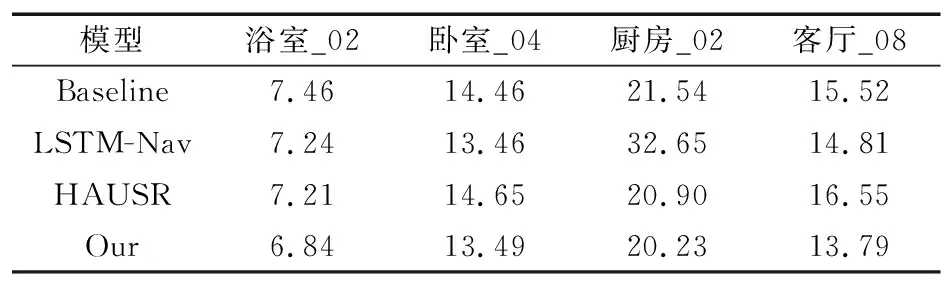
表1 不同模型的平均轨迹长度对比
表1中,除了在卧室_04下和LSTM-Nav效果接近以外,其余每个场景下改进模型都优于其他3个模型,相较于baseline提升约8%,相较于LSTM-Nav提升约5%,因为LSTM-Nav在厨房_02场景下泛化能力较差,所以不将其计算在内,相较于HAUSR提升约6%,可以看到改进模型和HAUSR在卧室_04和厨房_02场景下的性能较为接近,但在其他2个场景下的性能好于HAUSR,由此可以看出改进模型有较好的泛化能力。由于LSTM-Nav在某些场景下泛化能力较弱,所以在比较平均奖励和平均碰撞率时选择用性能更好的HAUSR代替。其次,在4个场景下对3个模型的平均奖励进行测试,结果如表2所示。
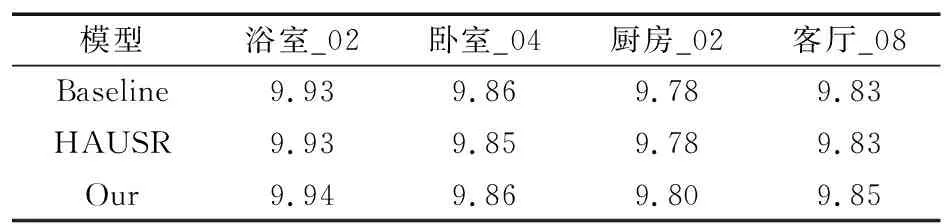
表2 不同模型的平均奖励对比
表2中,Baseline和HAUSR只有在卧室_04场景下相差0.01,模型比其他2个模型有较小提升,虽然这与奖励设置有关,但在一定程度上也能反映改进模型的性能。最后,对不同模型在多个场景下的碰撞率进行测试,结果如表3所示。
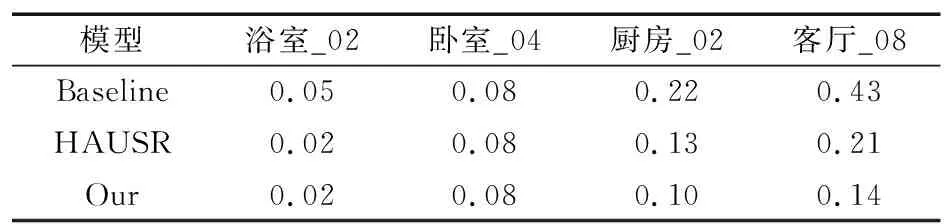
表3 不同模型的平均碰撞率对比
表3中,HAUSR相比Baseline在厨房_02和客厅_08场景下有较大提升,减少约为40%。同样,改进模型相比较HAUSR在厨房_02和客厅_08场景下也有较为明显的提升,证明改进模型良好的性能。
4 结束语
本文在已有的基于DRL视觉导航模型的基础上做出改进,提出了一种新的视觉导航模型,该模型结合了LSTM和USR,能够有效地利用智能体以往的路径信息并对接下来要采取的动作做出有效预测,在AI2-THOR仿真环境下的实验结果表明,本文的方法相较于其他方法具有一定提升,在仿真环境下有较好的导航效果。未来的工作将考虑将视觉信息和语义等信息融合后实施跨模态的导航,智能化的视觉导航要想真正应用到实际机器人上,需要进一步提升模型在实际场景中的泛化能力,人机交互也是未来研究的一个重要方向。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
小学生作文(低年级适用)(2019年5期)2019-07-26
文苑(2018年23期)2018-12-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
读友·少年文学(清雅版)(2018年12期)2018-04-04
山东青年(2016年3期)2016-02-28
