
遗传算法优化的BP神经网络拷贝数变异检测
2022-01-22 07:47黄体浩李俊青赵海勇
计算机工程与应用 2022年1期
黄体浩,李俊青,赵海勇
聊城大学计算机学院,山东 聊城 252000
拷贝数变异(copy number variation,CNV)是指DNA拷贝数偏离正常拷贝数时基因组序列发生扩增或缺失,是基因组结构变异的一种重要形式。生物医学研究估计,人类基因组中包含1 000 多个CNV 区域,约占基因序列的1%。CNV 与肿瘤疾病的产生和发展有着极其重要的联系,也是引发众多复杂肿瘤疾病的主要原因之一,因此发现原癌基因和抑癌基因尤为关键的一步就是准确检测目标基因组的拷贝数变异。
利用下一代测序(next-generation sequencing,NGS)技术检测拷贝数变异的策略主要分为四种:基于读深(read depth,RD)、基于双端比对、基于分裂读段、基于序列组装。其中最常用的拷贝数检测方法是基于RD的方法,Xie等[1]通过利用病例样本与对照样本之间的读段数目(read count,RC)比例建立统计模型,并根据比例差异识别CNV;Yoon等[2]采用基于事件测试的方法在个体基因组中检测到的缺失和扩增跨多个基因组进行检查,以确定个体之间的多态性;Ivakhno 等[3]采用离散小波变换对QC 过滤的RC 进行去噪,并使用隐马尔可夫模型(hidden markov model,HMM)进行分段。早期基于RD的拷贝数检测方法过度依赖RD信号,Abyzov等[4]采用均值漂移算法对单个样本的RD信号进行处理,并以此统计模型建立检测CNV;Xi等[5]将最小化贝叶斯信息准则算法扩展应用到多个样本中,以检测重复出现的CNV;Miller等[6]建立服从负二项分布的RC统计模型以减少均方根误差;Boeva 等[7]对GC 含量进行建模,并将模型用于归一化RD 信号;Gusnanto 等[8]通过损失函数纠正RC比例以消除GC含量偏差的影响。然而上述方法只能检测出显著性的CNV,且不能准确定位CNV 的断点位置。反向传播(back propagation,BP)神经网络拥有强大的非线性映射能力,可用来解决拷贝数变异检测中多个特征的联合作用,然而BP 神经网络在实际应用中仍存在诸多缺点,如局部最优、收敛速度慢、过拟合等。
基于上述研究,本文提出CNV-GABP(copy number variation detection of BP neural network based on genetic algorithm)检测方法。方法分为四个部分:特征值计算与归一化、BP神经网络结构确定、遗传算法优化和BP神经网络预测。该方法的优点在于:(1)充分考虑了多个特征之间的联合作用;(2)在BP 神经网络基础上,使用遗传算法(genetic algorithm,GA)优化BP 神经网络模型,提高模型的泛化能力;(3)优化后的BP 神经网络用以解决多个特征之间的联合作用,进一步提高了检测准确率和精度,可有效识别特征不明显的CNV。
1 相关工作
近年来,研究者综合考虑RD信号和其他因素,提出了很多CNV检测算法,Wang等[9-11]采用基于HMM的方法,分别利用期望最大化(expectation-maximization,EM)算法和置信传播算法估计模型的最优参数;Onsongo等[12]采用随机森林算法结合机器学习识别CNV;Johansson 等[13]选择与分析样本最具相似度的对照样本,归一化后分析两个样本间的平均覆盖率差异;Dharanipragada等[14]使用覆盖深度方法检测CNV;Chen等[15]采用最大惩罚似然估计的方法识别CNV和检测CNV边界;Melcher等[16]和Jugas 等[17]分别采用局部多项式回归拟合算法和中位数方法进行GC偏差矫正,然后利用全变分模型和循环二元分割算法进行分割读取;Yuan等[18]采用基于统计混合模型的贝叶斯方法来推断拷贝数的扩增和缺失;Xiao 等[19]采用基于高斯混合模型的聚类策略消除假阳性,并在聚类步骤中引入EM算法优化模型参数;Li等[20]建立高斯混合模型,并用先大窗后小窗的分割方式进行分割;Yuan等[21]采用孤立森林算法将RD信号生成孤立树集合,并使用全变分模型进行去噪;Li等[22]在RD信号的基础上引入了连续位置的相关性作为统计量以提高对CNV 的识别能力;Yuan 等[23]为每个分段分配一个离群点因子,采用局部异常因子算法识别CNV;Yuan等[24]利用肿瘤纯度和RD信号建立非线性模型,采用穷举搜索策略计算最优解;Zhao 等[25]利用BP 神经网络构建多特征训练算法以预测CNV;Yuan 等[26]利用潜变量模型重建观察到的信号,并对其进行分层处理。上述方法不仅仅依赖RD信号,减少了由于读段数目分布不均和定位模糊产生的影响,提高了灵敏度和特异性,但是仍然忽略了多个特征之间联合作用的影响,并且由于测序误差、GC 含量偏差等影响,一些特征较不明显的CNV 无法被识别。
2 CNV-GABP检测方法
本文提出的CNV-GABP方法是一种基于多个特征的检测方法,用于从NGS 数据中准确检测CNV。目前很多方法也逐渐考虑基因组位置之间的相关性,例如文献[4]和文献[18]都将基因组位置之间的相关性综合到统计量中来提高RD信号的检测效率,但是这些方法忽略了特征值之间的相互作用。CNV-GABP将GC含量、RD 信号、基因组相邻位置之间的相关性以及比对质量这四个特征融入到基因组序列的分析中,并通过训练BP 神经网络使四个特征相互作用。为了克服BP 神经网络全局搜索能力差、易陷入局部最优等缺点,本文使用遗传算法优化BP 神经网络模型,增强模型的泛化能力,提高方法的检测性能。
2.1 算法流程
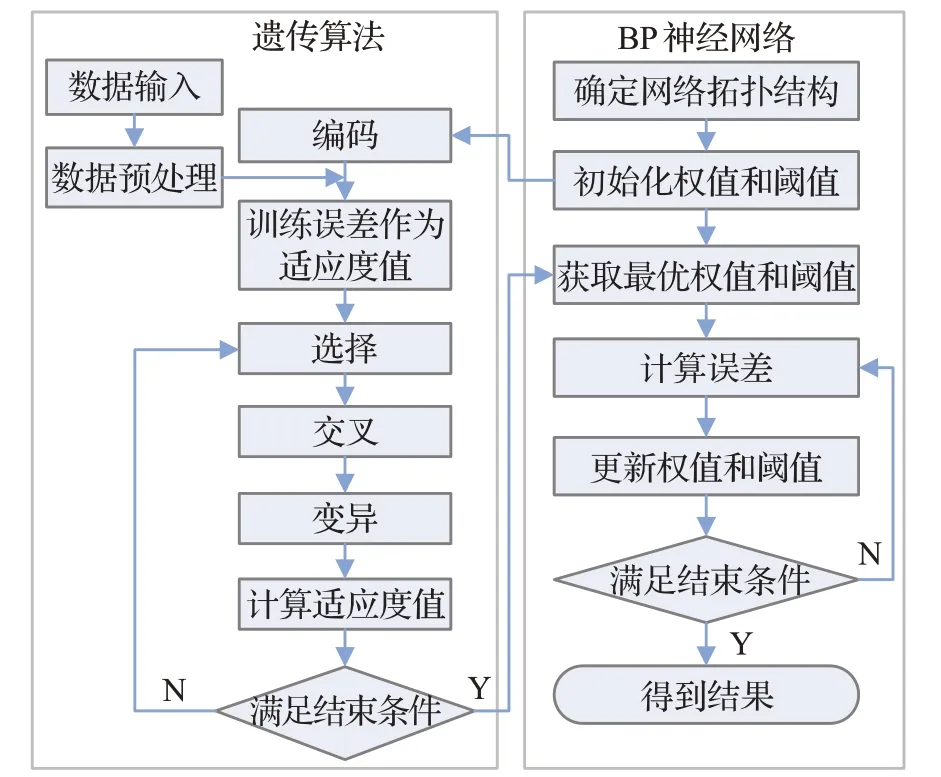
CNV-GABP 方法工作流程如图1 所示。首先输入一个参考基因组和一个测序样本,然后对输入数据进行预处理,最后经过四个步骤实现CNV 的预测:(1)定义与CNV相关的四个特征值,计算四个特征值并归一化;(2)利用四个特征值构建基于遗传算法优化的BP 神经网络;(3)训练BP神经网络,其中标记为CNV的数据从仿真数据和真实数据中采样获取;(4)根据训练完成的BP 神经网络模型预测每个窗的CNV 状态(正常、扩增或缺失)。
2.2 数据预处理与特征值量化
CNV-GABP使用比对算法BWA来处理格式为fasta的参考文件和格式为fastq 的序列样本文件,以生成格式为bam 的比对文件。使用samtools 软件从bam 文件中获取RC 文件,RD 信号是根据RC 文件计算得来的,为方便计算RD 信号,CNV-GABP 将提取的RC 文件分成连续非重叠且大小相等的窗,可根据需求自由设置窗的大小,本文中窗的大小为1 000 bp,取每个窗内的平均RC值作为该窗的RD值。由于GC含量偏差对RD信号产生噪声,通常如文献[21]中的方法会预先对GC 含量偏差进行校正,以期降低GC含量偏差的影响,这种方法适用于一些特定的情况,但在大多数应用场景下并未取得十分显著的效果。因此CNV-GABP并未同常规方法般预先对每个窗的GC 含量偏差进行校正,而是将GC含量作为该窗的特征值之一。基因组相邻位置之间的相关性和比对质量在一定程度上反应出该区域的CNV状态,因此CNV-GABP 也将这两个因素作为特征值。其中基因组相邻位置之间的相关性值参考文献[25],计算方式如式(1):

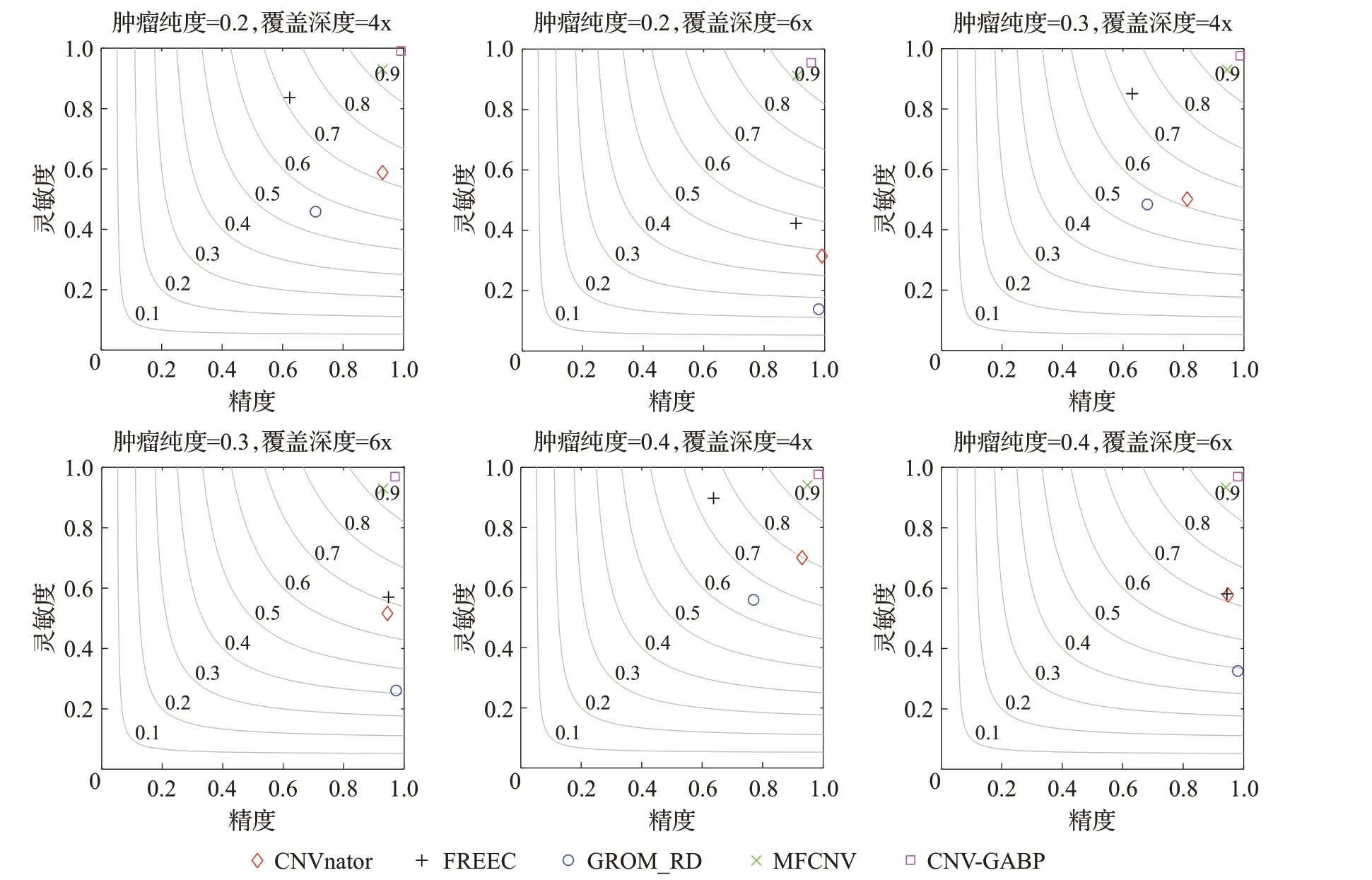
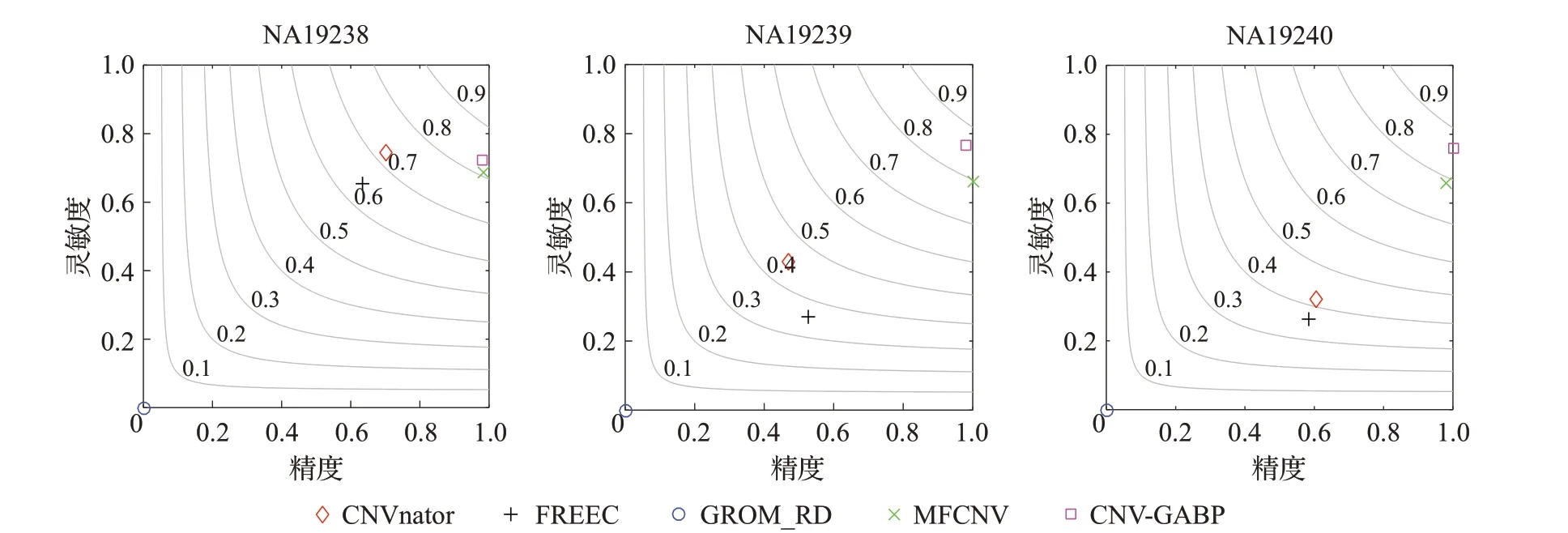
其中Ci表示基因组第i个位置与相邻位置的相关性值,Ri表示表示第i个窗的RD 值,n表示窗的总数,且j 每个窗的量化方式如式(2): 其中,Gi表示GC 含量,Qi表示比对质量,Ci和Ri的定义由式(1)给出。 由于四个特征值的表示标准不同,为消除特征值之间的量纲影响,CNV-GABP 对特征值进行归一化处理。以比对质量为例,归一化方式如式(3): BP神经网络是一种按照误差逆向传播算法训练的多层前馈式神经网络,以其优越的非线性映射能力和柔性的网络结构被广泛应用于分类问题,BP 神经网络算法的学习过程包括信号的正向传播与误差的反向回传。正向传播时,数据从输入层传入,经隐含层处理,传向输出层,若输出层输出与期望输出不一致,则将误差作为调整信号反向回传,调整神经元之间的权值矩阵,减小误差。本文用归一化之后的特征值组成的四元组Xi=(Ri,Gi,Qi,Ci)作为输入构建BP 神经网络。如图2表示该网络的拓扑结构。 图2 BP神经网络拓扑结构Fig.2 Topology of BP neural network 其中ω表示输入层与隐含层、隐含层与输出层之间的权重,θ表示偏差,X表示神经元输入向量,即归一化之后的特征值组成的四元组。除此之外,学习速率与收敛性密切相关,是神经网络的重要参数之一,本文使用BP神经网络的默认值0.1作为该网络的学习速率。 遗传算法是一种启发式随机搜索算法,能够在不需要误差函数梯度信息的情况下学习近似最优解,具有良好的全局搜索能力和隐并行性,适合复杂的非线性问题求解。遗传算法的主要步骤包括编码、种群初始化、选择、交叉和变异。使用遗传算法优化BP 神经网络主要是对神经网络各项参数的调整,本文使用遗传算法优化BP神经网络的权值和阈值。 基于遗传算法优化BP神经网络算法的基本思想是将BP神经网络算法与遗传算法相结合,当BP算法训练网络的收敛速度较慢时,将BP 神经网络每个隐含层节点的阈值和权重作为遗传算法的输入信息,并对它们进行编码以生成染色体,然后使用遗传算法的选择算子、交叉算子和变异算子来生成新的后代作为BP算法的初始值,最后继续使用BP 算法训练网络。基于遗传算法优化的BP神经网络算法流程如图3所示。 图3 基于遗传算法的BP神经网络程序流程图Fig.3 Flow chart of BP neural network based on genetic algorithm 算法分为两个部分:遗传算法优化部分和BP 神经网络部分。 (1)遗传算法优化部分。首先对种群进行初始化,初始化种群由BP 神经网络的初始权值和阈值组成,随后执行选择、交叉和变异操作,将种群中执行完操作的个体代入BP神经网络进行迭代以寻找最优个体。具体内容如下: 步骤1 初始化种群。本文采用实数编码,种群中的每个个体都是由输入层与隐含层之间的权值、隐含层阈值、隐含层与输出层之间的权值、输出层阈值组成的实数串。 步骤2 计算适应度函数。本文将期望输出与预测输出之间的误差绝对值作为个体的适应度值F,计算方式如下: 其中m表示神经网络输出节点总数,di表示神经网络第i个节点的期望输出,pi表示神经网络第i个节点的预测输出。 步骤3 选择操作。本文采用轮盘赌法作为选择策略,选择适应度好的个体组成新的种群,选择算子的计算方式如下: 其中Fi表示个体i的适应度值,N为种群中个体的总数。 步骤4 交叉操作。在种群中随机选择两个个体按照一定概率进行交叉操作,两个父代个体Pk和Pl在第j个点位的实数交叉方式如下: 其中α是介于(0,1)之间得随机数。 步骤5 变异操作。在种群中随机选择一个个体按照一定概率进行变异操作,个体Pi在第j个点位变异方式如下: 其中Pmax表示个体的上界,Pmin表示个体的下界,v 表示当前迭代次数,Vmax表示最大进化次数,μ是介于(0,1)之间的随机数。 步骤6 检查新的个体是否符合最优个体标准,若不符合,则返回步骤2;若符合,则将最优个体分割为BP神经网络的权值和阈值,调整网络参数,重复学习训练,直至达到所需精度或学习次数的上限为止。 (2)BP 神经网络部分。将经过遗传算法优化得到的初始权值和阈值等个体,代入BP神经网络,输入训练数据,进行BP 神经网络训练。利用遗传算法检验个体的适应度,无法达到适应度标准的个体进行选择、交叉和变异操作,重新进行BP神经网络训练,直至个体满足适应度标准或满足精度要求为止。具体内容如下: 步骤1 初始化网络。X为神经元输入向量,n为输入层节点数;Y为神经元输出向量,m为输出层节点数。 其中输入向量根据式(1)进行量化,输出向量分别代表拷贝数变异的3种状态。 步骤2 计算隐含层输出。隐含层节点数为p,输入层与隐含层之间的权值为ωij,阈值为λa,隐含层输出值Ha的计算方式如下: 其中f为激励函数,计算方式如式(4)所示。 步骤3 计算输出层输出。隐含层与输出层之间的权值为ωjk,阈值为λb,输出层输出值Hb的计算方式如下: 步骤4 计算误差并验证。误差e表示为预测输出Hb与期望输出Y之差,计算方式如下: 假定e0为允许的误差最大值,若max(em)>e0,则调整BP神经网络参数,重新进行学习训练,直至全部训练数据满足误差标准。 步骤5 更新权值和阈值。根据上述步骤计算出的误差e更新ωij和ωjk,计算方式如下: 其中η为学习速率,介于(0,1)之间。阈值修正如下: BP 神经网络算法的结果还取决于网络的原始状态,在局部搜索中使用BP 算法更为有效,GA 则擅长全局搜索。因此,本文使用GA 优化初始权值和阈值,并在解空间中找到一些更好的搜索空间,然后使用BP 算法在这些小的解空间中搜索最优解。通常使用混合算法的效果要优于仅使用BP神经网络算法的效果。 为防止细胞污染等外部因素造成的误差,本文在不同的肿瘤纯度和覆盖深度中选择样本作为训练数据。利用经过上述步骤训练完成的BP 神经网络模型,对测试数据集进行预测。对于每个窗,算法输出3个从tansig函数映射的0 到1 之间的值,分别表示CNV 这3 种状态的概率,并根据最大的概率确定该窗的CNV 状态。例如,代表扩增的概率大于代表其他两种CNV 状态的概率,则该窗的CNV状态为扩增。 本文中BP神经网络结构为3层,利用式(4)给出的激活函数,输入层节点数为4,隐含层节点数为5,输出层节点数为3,共4×5+5×3=35个权值,5+3=8个阈值,因此需要优化43 个参数。交叉概率pc=0.2,变异概率pm=0.1,初始种群规模S=10。 为了验证CNV-GABP 方法的合理性和可靠性,首先使用模拟数据进行实验。本文从基因组变异模拟方法中选择了一种综合模拟方法IntSIM[27]来生成测序数据。肿瘤纯度设置为0.2、0.3和0.4,覆盖深度设置为4x和6x,以生成不同配置的数据集。从标准参考基因组中选择一条染色体Chr21作为IntSIM输入序列,并针对每种配置模拟50个样本,共计300个样本。将CNV-GABP与4 种现有方法(CNAnator[4]、FREEC[7]、MFCNV[25]、GROM_RD[28])在灵敏度、精度和F1评分上进行比较,指标的计算方式参考文献[16]。每个指标均取50 个样本的测量均值,5种方法的性能比较结果如图4所示。 图4 仿真数据中5种方法的性能比较Fig.4 Performance comparison of five methods in simulation data 由图4可以看出,肿瘤纯度增加的同时,5种方法的检测性能都在提高。例如肿瘤纯度0.2、覆盖深度均为4x 时GROM_RD 的灵敏度约为0.45,而肿瘤纯度0.4 时约为0.56;5种方法F1 评分均值在肿瘤纯度0.2、覆盖深度均为4x 时约为0.59,而在肿瘤纯度0.4 时约为0.71。就精度而言,在6类样本中GROM_RD获得2个最高值,CNVnator 获得1 个最高值,CNV-GABP 获得3 个最高值;就灵敏度和F1 评分而言,在6类样本中CNV-GABP均获得最高值。 检测CNV边界的准确性同样是衡量算法可靠性的指标之一,边界偏差越小,CNV 检测方法性能越高。MFCNV在边界偏差上取得了良好的效果,本文将CNVGABP与之比较,结果如图5所示。 图5 两种方法的边界偏差比较Fig.5 Boundary bias comparison of two methods 由图5 可以看出,随着肿瘤纯度的增加,两种方法的边界偏差都随之减小。实验结果表明,CNV-GABP在六类样本中的边界偏差均小于MFCNV。因此,CNVGABP在模拟数据中的性能表现优于其他4种算法。 CNV-GABP 的性能优势主要由三方面原因导致:一方面,CNV-GABP在不同的肿瘤纯度和测序深度中选择大量训练数据进行训练,提高了容错率;另一方面,其他方法只考虑到多个特征的边际效应,而CNV-GABP通过BP神经网络解决多个特征之间的联合作用;最后,CNV-GABP 使用遗传算法优化BP 神经网络模型,增强了模型的鲁棒性。 为验证CNV-GABP 的有效性,应用该算法分析3个实际测序样本:NA19238、NA19239 和NA19240,数据可以在1 000 基因组项目网站http://www.internationalgome.org/上获取。本文将5 种检测方法分别用于这3个样本,检测结果如表1 所示。基因组变异数据库(http://DGV.tcag.ca/)提供已确认的CNV,可量化这5种方法的性能。 表1 5种方法检测的CNV个数比较Table 1 Number comparison of detected copy number variations by 5 methods 由表1 展示的结果可以看出,在NA19238 样本中,CNV-GABP 检测的CNV 个数少于CNAnator,剩余的两个样本中,CNV-GABP 检测的CNV 个数均多于其他方法。这表明针对特征不明显的CNV 时,该算法具备较强的检测能力。5种方法在真实数据上的性能比较结果如图6所示。 由图6 可以看出,3 个样本中CNV-GABP 的F1 评分值均最高,平均值为0.85;就精度而言,MFCNV 表现优于CNV-GABP,其次是CNVnator;就灵敏度而言,CNV-GABP 获得两个最高值,其次是MFCNV。因此,CNV-GABP 在实际测序样本数据中的整体性能表现优于其他4种算法,这说明该算法在实际应用中是有效且可靠的。 图6 真实数据中5种方法的性能比较Fig.6 Performance comparison of five methods in real data 针对GC 含量偏差校正过程产生的误差对现有CNV 检测方法造成影响的问题,本文提出了一种遗传算法优化的BP神经网络拷贝数变异检测算法。该算法无需进行GC含量偏差校正,采用BP神经网络解决不同特征之间的联合作用,然后使用遗传算法优化BP 神经网络模型获取最优参数,最后使用优化的BP 神经网络进行CNV 预测。本文基于仿真数据和1 000 基因组计划的真实数据,将CNV-GABP与其他4种现有算法进行比较。实验结果表明,CNV-GABP算法在灵敏度、精度、F1 评分和边界偏差上均获得了明显的优势,尤其提高了对特征不明显的CNV的检测能力。 对于将来的工作,将从以下几方面着手对CNVGABP 方法进行改进和扩展:(1)将算法扩展至肿瘤-正常配对样本的研究,对肿瘤样本和正常样本分别提取特征,并将提取后的特征作为CNV-GABP算法的输入,以进行差异基因分析;(2)单细胞测序技术蓬勃发展,下一步可收集此类测序数据的基因组特征,将该算法扩展至单细胞测序数据中,以分析单个细胞的基因组突变;(3)同时可根据混合优化算法[29-31]优化BP神经网络的结构,提高算法运行效率。

2.3 BP神经网络构建


2.4 基于遗传算法的BP神经网络






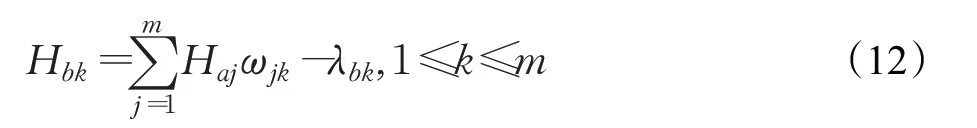

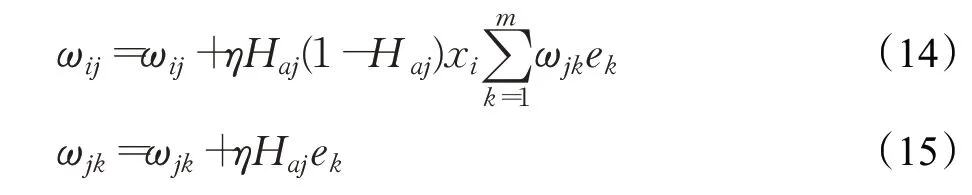

3 实验结果与分析
3.1 仿真数据研究

3.2 真实数据研究

4 结束语
猜你喜欢
军事文摘(2022年16期)2022-08-24
右江民族医学院学报(2022年2期)2022-05-19
河北医学(2021年10期)2021-10-27
今日农业(2021年11期)2021-08-13
中国农业科学(2021年6期)2021-03-25
汽车工程(2021年12期)2021-03-08
中国生殖健康(2020年4期)2020-12-09
中西医结合肝病杂志(2020年2期)2020-10-27
中国临床医学影像杂志(2019年6期)2019-08-27
电子制作(2019年24期)2019-02-23
