
面向SSL VPN加密流量的识别方法
2022-01-22 07:46王宇航姜文刚翟江涛史正爽
计算机工程与应用 2022年1期
王宇航,姜文刚,翟江涛,史正爽
1.江苏科技大学电子信息学院,江苏 镇江 212003
2.南京信息工程大学智能网络与信息系统研究院,南京 210000
3.爱丁堡大学信息学研究院,爱丁堡 EH8 9YL
互联网技术的高速发展,在为人们生活带来便利的同时,也会被一些犯罪分子用于不法传输,这对网络空间的稳定性及安全性产生了极大的影响,使得网络安全问题越来越受到人们的关注,因此,全球加密网络流量不断飙升。虽然流量经过加密后再传输,使得传输数据的安全性得到保障,但也为流量的审计增加了难度。
常用的VPN 技术有MPLS VPN、IPSEC VPN、SSL VPN三种。MPLS VPN主要应用在路由器和交换机等设备上,IPSEC VPN 是IPSec 协议在VPN 上的一种应用,SSL VPN 属于应用层VPN 技术。相比于前两种在使用上更加便捷,这使得SSL VPN 在安全传输中得到了广泛使用,但这也使得一些恶意流量有了可乘之机。一些非法应用利用SSL VPN来绕过防火墙等安全设施的检测。因此,对SSL VPN 加密流量的有效识别对网络信息安全具有重要意义。
Shen等人[1]通过增加Markov链的状态多样性,来建立二阶Markov 链模型从而对HTTPS 应用进行识别。程光等人[2]采用相对熵区和蒙特卡洛仿真方法结合实现加密流量和非加密流量的识别,取得了不错的识别效果。Lotfollahi 等人[3]采用卷积神经网络模型对流量进行分类。赵博等人[4]利用加密数据的随机性特点,对网络报文逐一实施累积和检验,最终,实现了对加密流量的普适识别。目前,对加密流量分类的相关文献取得不错的成果。
针对SSL 流量的识别常采用机器学习的方法和指纹识别的方法,文献[5]对SSH 流量的识别问题展开研究,提出了一种SSH 流量识别方法。该方法基于SSH协议建立连接阶段的特征,对使用SSL 协议的流量进行识别。文献[6]采用签名和统计相结合的方法,选择了13 个特征字段和14 个流属性,通过C4.5,Naive Bayesian 和SVM 等多种机器学习算法,对SSL 协议流进行识别。
流量识别研究大多围绕对某种协议流量的识别展开,针对VPN 流量识别的研究尚不足。西佛罗里达大学[7]的研究人员对文献[8]发布的数据集开展深一步的研究,比较了Logistic回归、朴素贝叶斯、SVM、KNN、RF和GBT 方法的识别效果,并对算法参数进行了相应的优化,最终VPN 流量达到了90%以上识别率。王琳等人[9]提出一种将指纹识别与机器学习方法相结合识别SSL VPN流量,虽然取得了91%以上的识别率,但是该方法需要手工提取流的特征。
本文在现有研究基础上,提出一种基于Bit 级DPI和深度学习的检测方法,分两步实现SSL VPN 流量的识别。先使用本文提出的一种新的基于Bit级DPI的指纹生成技术——位编码,通过将流的少量初始位与生成的位指纹匹配,来判断当前数据包是否使用SSL 协议、当前数据流是否为SSL 流。对于第二阶段的SSL VPN 流量识别,本文提出了一种基于注意力机制的改进的CNN网络流量识别模型,并与一般的CNN模型进行比较。实验结果表明,本文提出的方法不仅有效解决了SSL 加密流量指纹识别方法存在的漏识别率较高的问题,同时改进后的深度学习模型,能提取网络流量中具有非常显著性的细粒度的特征,从而更加有效地捕捉网络流量中存在的依赖性,识别模型具有良好的实验效果。
1 相关工作
1.1 DPI识别技术
深度包检测技术(deep packet inspection,DPI)采用匹配特征字段对网络流量进行识别[10]。许多基于DPI的检测方法使用有效负载内容生成特定于应用程序的指纹。DPI可快速准确地识别指纹库存在的流量,但也存在着致命的缺陷,DPI 识别依赖于应用协议特征字段,无法识别协议交互阶段加密数据和私有协议[11]。但本文提出了一种基于Bit 级DPI 的指纹生成技术,用于快速筛选识别SSL协议流量,发挥了DPI识别速度快的优点,对识别模型预处理过程有很大的作用。
1.2 SSL协议
SSL(安全套接字协议)在传输层与应用层之间对网络连接进行加密,是一种为主机间通信提供安全的协议。SSL 协议由握手协议、记录协议、更改密文协议和警报协议组成,如图1所示。

图1 SSL协议位置与组成Fig.1 SSL protocol location and composition
握手协议是SSL协议中十分重要的协议,是在应用程序的数据传输之前使用的。该协议允许服务器和客户机通过握手相互验证,在这一过程中双方需要确认密钥和算法,同时还要协商信息摘要算法、数据压缩算法等。在握手协议结束后,双方开始加密数据的传输。握手协议的通信流程如图2所示。
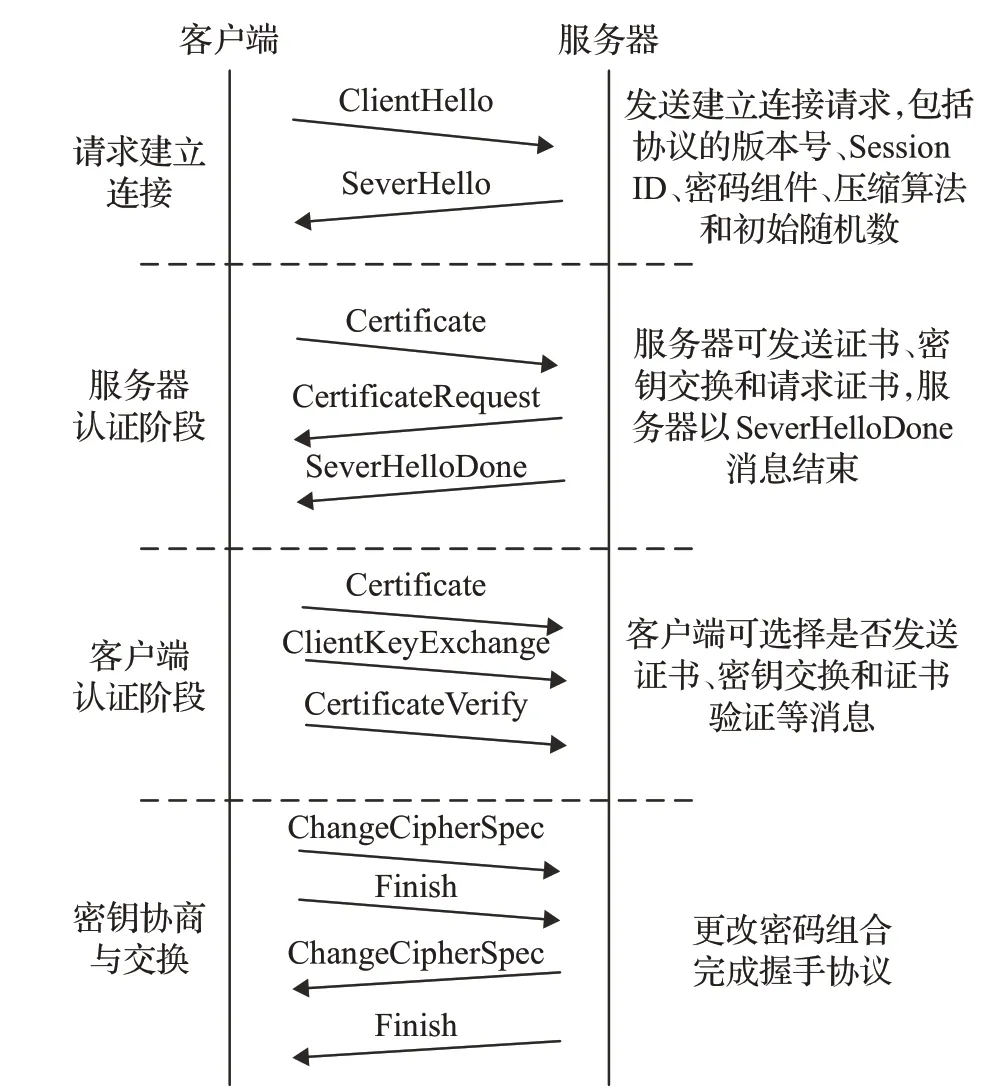
图2 握手协议的通信流程Fig2 Flow of handshake protocol communication
1.3 卷积神经网络
卷积神经网络(convolutional neural network,CNN),是深度学习的代表算法之一,提供了一种端到端的学习模型。这一深度学习网络模型相较于传统的其他模型存在以下优点:
网络中的神经元采用稀疏连接的方式,而非像一般神经网络的神经元采取全连接的方式。达到了降低参数的数量的目的,方便网络结构模型的扩展和模型的训练。
采用参数共享,其过程就是针对每个神经元与前面层次的所有连接都贡献权重值,这样也能够进一步的减少训练的参数数量[12]。
利用池化操作获取更具代表性的特征值,同时降低了参数的数据量信息。有利于后面模型的训练卷积神经网络能自动从学习样本中很好的学习原始数据中的特征,并完成对数据特征的提取与分类,无需像机器学习那样人工设计特征。
1.4 注意力机制
注意力模型最近几年在图像处理、语音识别、自然语言处理等领域得到广泛应用,其核心目标是从众多信息中选择出对当前任务目标更关键的信息,增加感兴趣区域,抑制无用信息。因此,本文将注意力机制引入到CNN 模型当中,用来提取序列中非常显著性的细粒度的特征,实现短期的有效提取。从而优化输入信息,达到提升模型分类能力的目的。
注意力机制可分为,硬注意力(hard attention)及软注意力(soft attention)。硬注意力核心的原理在于直接限制深度学习模型当中输入内容的这种处理方法,但是在时序预测的相关领域相对来说并不是完全适合[13]。同时硬注意力是一个随机的预测过程,更强调动态变化。其训练过程往往是通过增强学习来完成的,且后期模型训练难度较大,导致模型的通用性比较差。与硬注意力机制不同,软注意力是确定性的注意力。学习完成后,可以通过神经网络得到注意力的权重,直接加权全局上的信息作为输入特征。软注意力机制更关注区域或者通道,最关键的地方是软注意力是可微的,可以很好地与一种端到端的学习方式相结合。
基于以上分析,本文将软注意力机制引入到一维卷积神经网络当中。采取对输入特征逐个加权的方式,达到关注特定空间和通道目的。最终,对时间序列上细粒度的显著性特征进行提取,从而完成对网络流量中存在的依赖性的有效捕捉。
2 基于Bit级DPI的SSL加密流量识别
SSL握手协议采用明文传输的形式,因此可以利用解析PCAP文件得到的数据包的头部信息,判断出当前数据包为何种SSL 握手协议的消息类型。一个完整的握手协议,其通信过程一定包含ClientHello、SeverHello、SeverHelloDone、ClientKeyExchange、ChangeCipherSpec类型的消息。基于传统的DPI 检测技术若某数据流中未能全部包含以上5 种类型的消息,则判断为非SSL流。当数据流中只检测到部分类型信息时,可能是自身握手协议建立不成功,或者是抓取数据包时存在漏包的情况。然而在实际抓取数据包时,设置确定截断时间,会存在一个流虽然是SSL 流,但并不是从开始截取的,而是从其他传输阶段截取的。这时,基于传统的DPI检测技术会因为没有检测到SSL握手协议的消息,将其判定为非SSL 流,因此,会产生漏识别的情况。为了解决这一问题,本文提出一种基于Bit 级DPI 的SSL 加密流量识别。
SSL 加密的数据包根据其消息类型的不同,有不同的消息格式,但其前5 个字节的格式是固定的,分别表示通信的阶段(握手(Handshake)、开始加密传输(ChangeCipherSpec)还是正常通信(Application)等),SSL 协议版本号和剩余包长度[2],如表1 所示。基于位级DPI的SSL加密流量识别方法,仅使用来自TCP数据段的少量初始位,并将不变位标识为位指纹。随后,对这些指纹进行编码,将其转换为状态转换机,用来识别SSL流量。这种方法扩大了SSL流识别的范围,不仅能够识别SSL握手阶段的流,同时也能识别数据传输阶段的SSL流。

表1 协议前5个字节格式Table 1 First five bytes of protocol format
整个识别过程分为以下几个部分:
(1)重构流
网络流由两个主机之间交换的一系列数据包组成。这两个主机由两个唯一的IP 地址标识。共享相同5 元组的所有包都是流的一部分,依据相同的5元组信息对流进行重构,从而将所有数据包(流内)的有效载荷数据都被获取并连接起来,用作后续指纹生成阶段的输入。
(2)位指纹生成
位编码使用前一阶段选择的有效载荷的不变位集生成应用程序特定的位指纹。假设训练集中存在L(L∈I)个SSL流,它从SSL的L个流中各收集前n位,并为SSL流生成n位位指纹。第h个流(1 ≤h≤L)的前n位为f1h,f2h,…,fnh。L个流都被提取都用于生成如下位指纹。每个流提取的第k位[1,n]位置用来决定SSL流的第k个指纹位。指纹创建过程如下所示,其中每个Si是一个指纹位:

如果每个流的第k位(1 ≤k≤L)的值都为0,k指纹位设置为0,如果每个流的第k位(1 ≤k≤L)的值为1,k指纹位设置为1。如果这些位的位置中有0位和1位,则第k个指纹位设置为“^”。图3 显示了SSL 流的位指纹生成过程,在这个示例中,有3 个流,每个流有15 位,用于指纹生成。

图3 生成位指纹Fig.3 Generate bit signature
(3)运行长度编码
指纹位由1 位、0 位和^位组成,每个指纹为n位。为了有效地表示、存储和比较,对这n位进行了运行长度编码(RLE)。RLE 是一种用于无损数据压缩的技术。RLE 通过指定重复次数来减少重复字符串的大小。在RLE中,数据的运行是指在许多连续数据元素中具有相同数据值的序列存储为单个值,并存储该数据值重复的次数计数。例如,它的位值是1111111000000^^^^111,在使用RLE编码之后,它被转换为7O6Z4^3O显示状态。
(4)状态转换机器创建
经过第(3)步骤之后生成一个编码指纹,将经过编码的位指纹转换成状态转换机。然后与需要的网络流量流进行比较,以识别应用程序。状态转换机的定义如下:

用20 位指纹(11111111000000^^^111,编码指纹为8O6Z3^3O)生成的示例状态转换机如图4 所示。在状态转换机中有5种状态,从q0到q4,q0是开始状态,q4是结束状态。每个状态都有一个计数器(C0到C4),每次转换访问该状态时,该计数器都会被初始化为一个新值。机器在q0状态下启动,将q0的计数器设置为0,从测试流中读取比特,并进行允许的转换以达到最终状态。状态转换机的转换有一个输入符号(位值)和一个对计数器值的约束,计数器值充当保护,只有当约束被满足(评估为true)时,才允许转换。
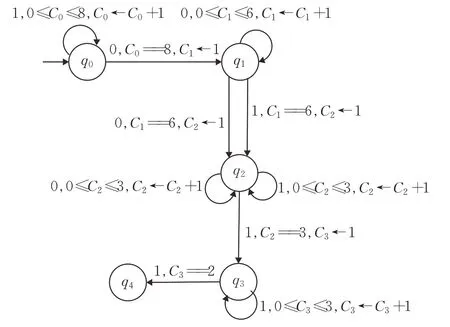
图4 生成状态转换机Fig.4 Transition machine of generating state
在图4中,状态q0在输入1上定义了一个到自身的转换。这个转换对C0的计数器值有一个约束,它在0到8之间。这个约束映射了在开始时在流中读取8个连续的1 要求。从q0到q1的转换是在输入0 上,只有当C0处的计数器值为8时才有效(已经读取了8个连续的1),并将q1处的计数器C1设置为1(在8 个连续的1 之后读取0)才有效。无论何时在指纹中有^,它将有两个转换,一个是输入0,另一个是输入1,这两个转换都将增加计数器值。
(5)识别SSL流
与状态转换机匹配的签名过程如图5 所示。与签名生成过程类似,在这个阶段也存在重构该流,数据流的前n位被提取出来作为输入(从第一个位到最后一个位,每次一个位),来自测试流的n位将提供给SSL状态转换机。SSL状态转换机进行了允许的转换,如果数据流能达到SSL 状态转换机最终状态,则流被标记SSL流;如果没有达到最终状态,则标记为非SSL流。

图5 匹配状态转换机Fig.5 Transition machine of matching state
以位序列11111111000000101111 和001111110000 00101111。第一个序列作为输入提供11111111000000 101111 给图4 状态转换机,很容易看到它到达最终状态,因为它以8个1开始,接下来是6个0,随后三位0或1都行,最后三位数是1。然而,第二个序列不被状态转换机接受,因为它从0开始,并且当计数器C0在状态q0下为0时,不存在与输入0的转换。
3 基于注意力机制的改进CNN 网络流量分类识别模型
3.1 基于注意力机制的CNN结构
在本文中注意力机制模块引入到一维CNN 中,包含特征的聚合和尺度恢复两个部分。特征聚合主要是采用多层次的卷积和池化层次的堆叠,从跨尺度的子序列中提取出细粒度的显著性的特征,最后一层上则用来挖掘其中的线性关系。尺度恢复指是将关键性的特征直接恢复到与网络模型中的CNN模块的输出保持一致。为将数值直接保持在0~1 之间,采用Sigmoid 函数。最后将获得的上下文特征,作为实际的基础性的显著性特征。
令xi∈Rk,也就是用k维向量表示数据流中的第i个流量字节,一个长度为n的数据流的定义如下:

xi:j为流量字节的连接结果,卷积操作由一个过滤器或卷积核构成,w∈Rhk,过滤器的窗口宽度为h,过滤器对一组流量字节操作一次,就输出一个新的特征CI。具体操作如下:

其中,Patt为注意力机制的权重,b为偏置项,f是ReLU的非线性函数。过滤器将在每个可能的流量字节窗口进行操作,产生一个特征映射。时序最大池化操作,在特征映射上找到最大值,最终输出对应输入在每一类输出上的概率分布。
基于注意力机制的CNN 结构,由于将原本的CNN的输入替换为注意力模块支路输入,并采用堆叠深层卷积和池化层的方式,所以扩大了特征对应的输入感受野。这样有利于捕捉网络流量中存在的依赖性,从而学习当前局部序列特征的重要程度。通过引入注意力模块,能够提高重要时序特征的影响权重,抑制非重要特征时序的干扰,因而有效解决了模型无法区分时间序列数据重要程度的差异性的问题。
3.2 基于注意力机制的改进CNN 网络流量分类识别模型
本文提出的基于注意力机制的改进CNN网络流量分类识别模型如图6所示。模型包含数据预处理、模型训练和模型测试3个阶段。
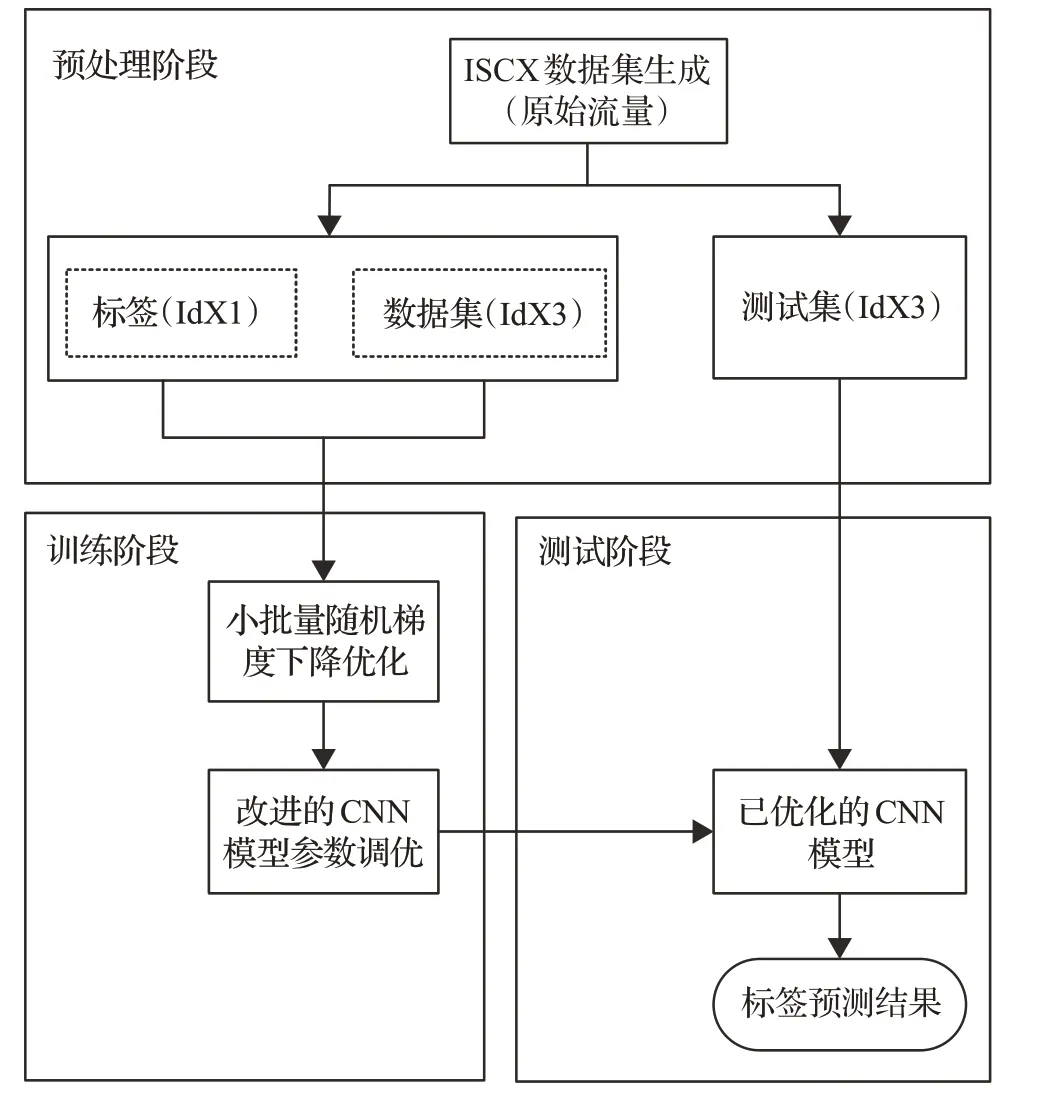
图6 改进的CNN网络流量分类识别模型Fig.6 Improved traffic classification and recognition model of CNN network
数据预处理阶段:将数据集中的原始流量进行预处理,得到CNN 模型输入所需的数据格式文件。这里使用的王伟博士开发的USTC-TK2016,包括流量切分、流量清理、图片生成、IDX转换4个步骤[13]。流程全过程如图7所示。

图7 网络流量数据预处理流程图Fig.7 Flow chart of network traffic data preprocessing
训练阶段:使用上一阶段处理得到的流量数据(IDX3 格式)和标签数据(IDX1 格式)训练改进的CNN模型,训练方法是最小批随机梯度下降技术。为使模型具有良好的泛化能力,训练采用10 折交叉验证技术。最终,得到的改进CNN 模型作为测试阶段使用的模型。
测试阶段:使用训练阶段得到改进的CNN模型数,对数据预处理阶段输出的IDX3格式的测试数据进行类别预测,得出最终分类结果。
其中,在数据预处理阶段的图片生成步骤,每个流量结果样本可以表示成28×28 像素的灰度图,结果如图8 所示。从流量可视化的结果看,大部分图片之间还是很容易区分的。SSL VPN 流量的黑色部分主要集中在底下部分,而非SSL VPN 流量的黑色部分主要集中在底部1/4 处。因此二者之间的区分度较为明显,可以推测,使用CNN 模型对其进行分类应该能够取得良好效果。

图8 可视化结果Fig8 Visualization results
4 实验结果及分析
4.1 实验数据集
本文采用的数据集是Lashkai等人[14]在2016年发布的VPN-nonVPN数据集,共包含28 GB数据。该实验室的官网对数据集进行了详细介绍,并提供下载,不同类别的流量生成方式如表2所示。

表2 实验数据集Table 2 Experimental data set
4.2 SSL流识别结果
SSL加密的数据包虽然有不同的消息格式,但其前5个字节的格式是固定的。分别表示通信的阶段(握手(Handshake)、开始加密传输(ChangeCipherSpec)还是正常通信(Application)等)、SSL 协议版本号和剩余包长度[9]。因此,本文选定SSL流数据包的前40位生成指纹将压缩后,生成状态转换机,用以识别SSL 流。由于传统的SSL 加密流量指纹识别方法在没有检测到完整的SSL 握手协议的消息,就会将其判定为非SSL 流。本文在此基础上提出了基于Bit级DPI的SSL加密流量识别技术,有效地解决了传统SSL 加密流量指纹识别方法存在的漏识别率较高的问题。除Vimeo 等少数流量识别率未到97%外,其余应用的SSL 流识别率均达到99%以上,与传统SSL 识别方法的实验结果对比如图9所示。

图9 SSL流识别结果对比Fig.9 Comparison of SSL stream identification results
4.3 改进CNN模型识别VPN流量实验结果
本文选择精准率P、召回率R和F1这3 项评分来评估基于注意力机制的改进CNN模型。其计算公式为:

式中,Tp真正表示加密流量的样本被正确识别的个数,Fp假正表示真实是加密流量但被错误的标识的个数,FN假负表示未加密流量的样本被正确识别的个数。
为了验证本文提出的算法模型的有效性及优越性,本文选择了KNN(K近邻)、PGA-RF(基于参数优化的改进RF 算法)和CGA-RF(基于子分类器优化的改进RF算法)进行比较。为验证一维CNN 模型相比于二维CNN 模型更适合于流量分类,本文还设计了二维CNN模型与之对比,结果如表3所示。
从表3 可以看出,相比较于传统的机器学习算法,本文提出的模型具有很好的识别效果,网络流量的服务识别性能都有了大幅度的提升。本文方法的准确率为97.6%,相比于文献[7]中KNN 的83.7%提升了13.9个百分点。与文献[9]中改进的方法PGA-RF 的91.6%相比,CGA-RF 的92.2%提升了0.6 个百分点。在精确率对比实验中,本文方法的精确率为98%,相比于文献[7]中KNN 的83.9%提升了14.1 个百分点,而参考文献[9]中PGA-RF、CGA-RF 的精确度分别为92.1%、92.6%,本文方法精确率明显高于参考文献[9]。同时本实验还对召回率进行了对比,召回率优于文献[7]中KNN的82.5%与文献[9]中91.1%和91.9%。最后,本文方法与各方法的F1-score 进行对比,本文方法的F1-score 为97.8%,文献[7]中KNN 为83%,参考文献[9]的F1-score 分别为92.3%、92.1%,本文方法F1-score 上也是高于参考文献[9],提升了5.7 个百分点。综合4 项指标对比实验可以看出,本文模型优于文献[7]中使用的KNN 与文献[9]中改进传统机器学习方法PGA-RF 与CGA-RF。

表3 SSL VPN 流量识别结果对比Table 3 Comparison of SSL VPN traffic identification results
通过四项指标对比实验可以看出,一维CNN 模型在准确率、精确率、和F1-score 上均优于二维CNN 模型。这是由于网络流量本质上是一种时序数据,是按照字节、帧、会话、整个流量层次化结构组织起来的一维字节流,因此选择一维CNN 网络模型识别加密流量更符合数据流的特征。
此外,相比于其他普通的深度神经网络模型,本文所提模型在准确率上提升了2.9 个百分点,精确率提升了2.9 个百分点,召回率提升了2.7 个百分点,F1-score则提升了3.2个百分点。这是由于注意力机制的引入能够对网络流量中存在的依赖性的进行有效捕捉,从而提高重要时序特征的影响,抑制非重要特征时序的干扰,因而有效解决了模型无法区分时间序列数据重要程度的差异性的问题。
因此,本文还将改进前后的一维CNN 网络模型进行了对比,分别选择前5 轮训练的准确率结果进行比较,如图10。可以看出引入注意力机制的改进CNN 模型比普通的CNN 模型收敛速度快,且平均准确率提升了0.3 个百分点以上。如图11 展示了基于注意力机制的改进的CNN识别模型在实际训练过程中准确率的变化趋势;图12 展示了是基于注意力机制的改进CNN 识别模型训练过程中的损失率变化的情况。
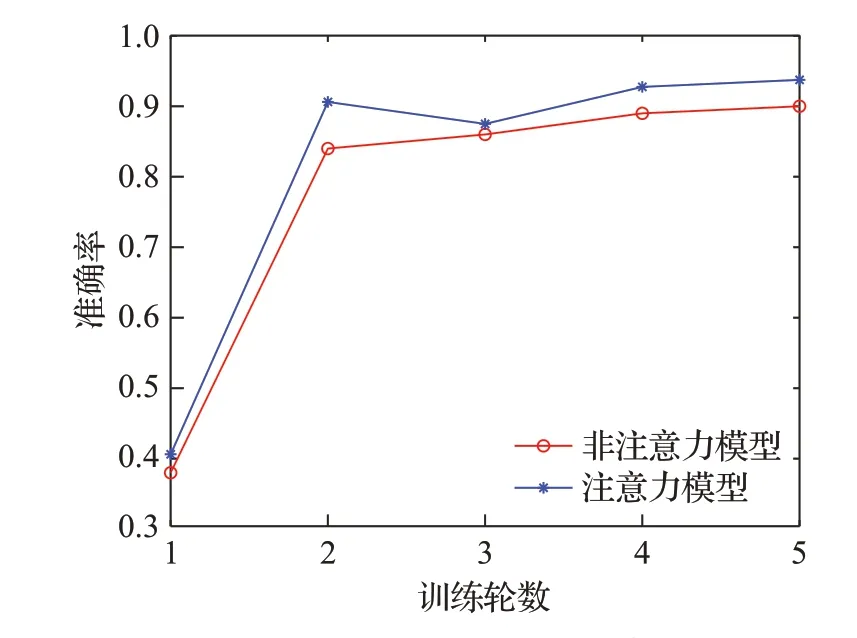
图10 改进前后的一维CNN网络实验对比图Fig.10 One-dimensional CNN network experimental comparison diagram of before and after improvement
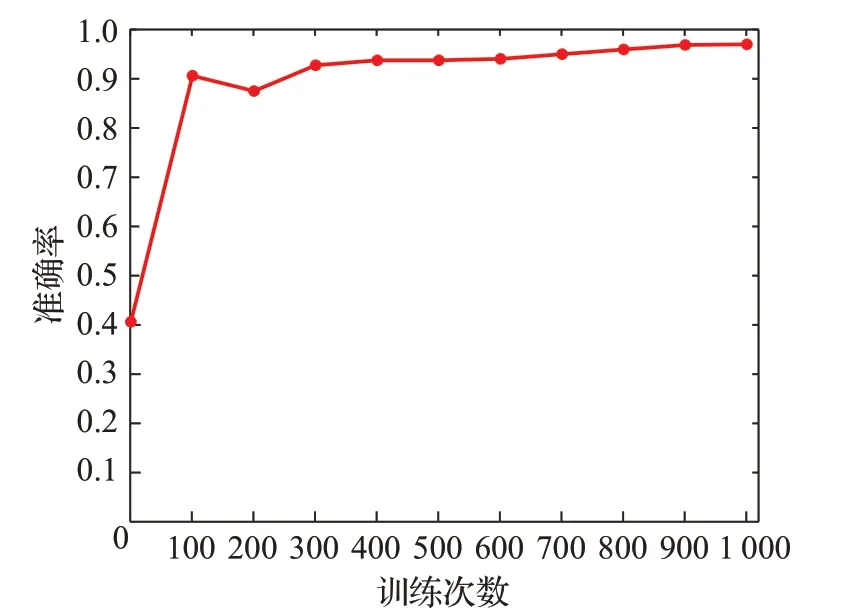
图11 模型训练过程中准确率的变化Fig.11 Change of accuracy during model training
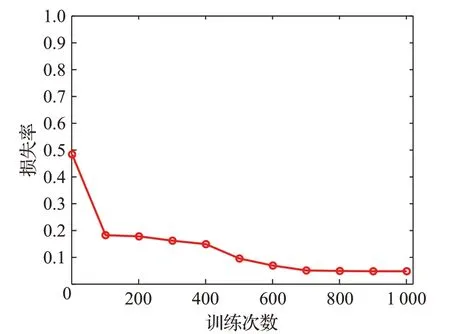
图12 模型训练过程中损失率的变化Fig.12 Change of loss during model training
5 结语
本文提出了一种基于混合方法的SSL VPN 加密流量识别方法。本文的Bit 级DPI 技术识别SSL 流具有快速、准确的优点,极大地改善了流的漏识别问题,最大程度上发挥了DPI 的优势。所提基于注意力机制的改进CNN 网络流量识别模型对SSL VPN 流量识别,其平均的精准率、召回率和F1-score 分别达到了98.0%、96.9%和97.8%,与传统的流量识别模型相比具有优良的识别性能,实现了SSL VPN 加密流量的有效识别。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
小哥白尼(趣味科学)(2021年11期)2021-02-28
小天使·一年级语数英综合(2020年10期)2020-12-16
微型电脑应用(2019年8期)2019-08-22
太原科技大学学报(2019年3期)2019-08-05
北京航空航天大学学报(2017年7期)2017-11-24
课堂内外(小学版)(2017年5期)2017-06-07
儿童时代·快乐苗苗(2016年2期)2016-10-22
