
基于多特征融合与CELM的场景分类算法
2022-01-22 07:48沈慧芳周树东
计算机工程与应用 2022年1期
王 光,陶 燕,沈慧芳,周树东
1.辽宁工程技术大学软件学院,辽宁 葫芦岛 125000
2.中国科学院海西研究院泉州装备制造研究所遥感信息工程实验室,福建 泉州 362000
近几十年来,随着遥感技术的快速发展以及数据获取的成本降低,对遥感图像的研究逐渐成为遥感领域的热点之一。遥感图像的语义解译在多种应用中扮演着重要角色,如城市规划、交通控制、土地利用制图以及灾害监测等[1-4]。场景分类的目的是给当前图像分配对应的语义标签,是遥感图像语义解译的重要手段。因此,如何在图像中捕捉具有鉴别性的特征并取得精确的图像分类结果是遥感场景图像分类亟待解决的难题。
现有的场景分类方法,大多数主要依赖于传统手工设计的局部特征描述子。其中,基于视觉的词袋模型(bag-of-visual-words,BoVW)首先提取像素点局部不变特征作为视觉单词,然后根据视觉单词出现频率构建直方图表示整张图像[4-5]。虽然该方法在场景分类中取得了一定的效果,但是BoVW模型完全忽略了产生的视觉单词的位置信息,无法得到图像之间的相互联系。因此Lazebnik 等人[6]提出了空间金字塔匹配核(spatial pyramid matching kernel,SPMK),首先将图像划分为不同尺度的网格,计算每个尺度上单元格中各个视觉单词的频率,以此估计两幅图像的相似度。然而,SPMK 模型只能计算两幅图像中固定位置之间的联系,无法体现邻接单元之间的相关性。Yang 等人[4]提出的空间共现核(spatial co-occurrence kernel,SCK)能够同时捕捉固定位置和相邻单元之间的相互联系。虽然局部特征描述子在场景分类中取得了较好的成果,但由于遥感图像自身存在的一些特性,如不同语义图像通常包含相同的对象或者同一语义图像尺度差异大,传统的手工设计方法难以获得鲁棒的特征,因此限制了图像分类的性能。
为了弥补手工制作特征的局限,提出了无监督特征学习的方法,通过模拟图像中的差异对图像进行分类。Hu 等人[7]采用线性流形分析技术将原始图像块从高维空间映射到低维空间中,然后在流形空间中使用K均值聚类对图像块进行编码。Risojevic等人[8]首先采用四元数特征过滤器进行无监督特征学习,然后基于四元数正交匹配追踪进行稀疏编码,该方法能够捕捉像素颜色与强度之间的内部联系。Othmana等人[9]采用无监督的方式将初始的卷积特征送入稀疏编码器对土地利用场景进行分类。无监督的特征学习方法虽然具备捕捉差异信息的能力,但由于缺乏图像的语义标签,无法根据识别结果对聚类过程进行改善,因此对图像分类性能的提升能力有限。
近来,卷积神经网络以其自主的特征学习能力和强大的特征表示能力在多种任务上取得了重要进展,不仅克服了手工制作特征表达能力单一等缺陷,而且能够通过训练过程中的损失函数对模型参数进行优化。Chen等人[10]基于单层的玻尔兹曼机和多层的深度置信网络分别学习低水平特征和高水平特征,然后使用逻辑回归分类器对高光谱图像进行分类。张康等人[11]利用8层深度的网络结构结合softmax和支持向量机对遥感图像复杂场景进行分类。Flores 等人[12]采用预训练的ResNet-50 DCNN模型对特定遥感场景数据中的训练集进行特征提取,以此得到高斯混合模型的先验知识,然后用得到的模型对测试集进行分类。虽然深度卷积神经网络在众多分类任务中取得了良好的表现,但是大多数网络精度依赖于网络的深度或者大量的标签数据。然而,大量标签数据集意味着需要耗费更多的人力物力,而且网络越深,训练复杂度越高。因此,本文基于迁移学习的思想,选取具备一定图像理解能力的预训练卷积神经网络,采用实验数据集对其进行特定领域图像分类的参数微调,实现运用浅层的卷积神经网络、有限数据集进行准确场景分类的目的。针对单一的预训练卷积神经网络提取特征的能力有限,本文融合三种不同结构的预训练卷积神经网络实现全方位多尺度的特征提取。
针对直接使用卷积神经网络架构作为最终的分类器训练时间长、难度大等问题,研究学者们提出了采用预训练卷积神经网络作为特征提取器结合简单高效的线性分类器的解决方案。其中,支持向量机(support vector machine,SVM)[13]是目前使用最为广泛的分类器,但其表现能力对参数的选择比较敏感,而且需要足够的训练数据,分类结果无法在两者之间取得平衡。Huang等人[14]提出了一种基于单隐藏层前馈神经网络的极限学习机(extreme learning machine,ELM),该方法通过随机初始化隐藏节点的参数,然后通过计算Moore-Penrose 广义逆矩阵求解输出权重,能够避免一般方法通过反向传播的迭代求解最优参数的缓慢过程,在一定程度上提高了网络的训练速度。基于此类方法,Kannojia等人[15]设计了一种三个并行的卷积神经网络,分别结合ELM对MNIST数据集进行分类,达到了超高的分类精度。但是ELM 中隐藏节点的参数是随机初始化的,并且卷积层得到的特征送入隐藏层之前没有进行任何的正则化操作,因而会导致节点利用率低以及过拟合等问题。为了解决此问题,Zhu等人[16]提出了ELM的改进版本CELM。该方法能够根据样本分布初始化隐藏节点的参数,并且对深度卷积特征进行L2 正则化之后送入分类器,不仅保证了模型的训练速度,而且提升了网络的泛化能力。本文将在特定数据集上进行精调的CaffeNet、VGG-F、VGG-M 三种预训练卷积神经网络作为特征提取器,将提取的三种特征融合后送入CELM分类器,得到最终的遥感图像语义分类结果。
综上所述,本文的主要贡献如下:
(1)利用有限的实验数据集对在强大的ImageNet数据集上预训练的卷积神经网络进行微调,实现了少量数据集的高分类性能;
(2)融合CaffeNet、VGG-F、VGG-M 三种不同的网络框架提取到的全方位多尺度特征,加强了图像的特征理解能力;
(3)引入了具有良好泛化能力的CELM 分类器,实现了高效的分类性能和快速的训练速度。
1 实验数据与预处理
本文采用由武汉大学发布的SIRI-WHU 和WHURS19 RGB3 通道遥感影像数据集以及由UC-Merced计算机视觉实验室发布的UC-Merced高分辨率遥感影像数据集作为实验数据集。其中,SIRI-WHU 数据集含有12 类土地场景,每类场景含有200 张图像,总计2 400 张图像,图像像素大小为200×200,空间分辨率为2 m;WHU-RS19数据集涵盖19类土地场景,每类场景中包含50~61 张图像,每类图像的具体数据如表1所示,共计1 005 张图像,图像像素大小为600×600;UC-Merced 数据集包含21 类土地场景,每类场景包含100 张图像,共计2 100 张图像,图像像素大小为256×256,空间分辨率为1 英尺。图1~图3 分别显示了UCMerced、SIRI-WHU 与WHU-RS19 数据集中不同类别的图像样本。

图1 UC-Merced样本Fig.1 Samples of UC-Merced

图2 SIRI-WHU样本Fig.2 Samples of SIRI-WHU

图3 WHU-RS19样本Fig.3 Samples of WHU-RS19
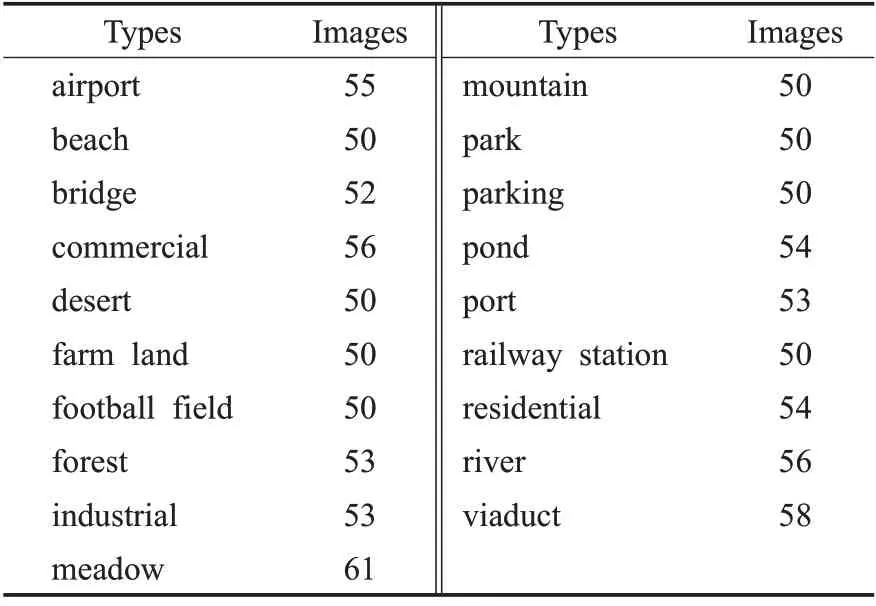
表1 WHU-RS19数据集样本分布Table 1 Sample distribution of WHU-RS19 dataset
CaffeNet、VGG-F 与VGG-M 三种卷积神经网络接收的是固定像素大小的图像输入,因此实验数据集的图像在进入网络之前,需要将对应的图像规则化为统一规格。对于CaffeNet 网络,输入像素大小为227×227;VGG-F 与VGG-M 网络的输入像素大小为224×224。文章采用缩放的方式对图像进行预处理,规则化输入图像。
2 研究方法
本文提出了一种结合多特征融合与CELM 的方法对遥感图像进行场景分类。网络的输入为3 通道RGB图像,首先利用SIRI-WHU 数据集对3 种不同的预训练卷积神经网络进行参数微调;接着将图像送入微调后的网络并对提取到的3种特征进行融合;最终送入CELM分类器,网络的输出为对应图像在不同语义标签上的类别分数。网络的总体结构设计如图4所示。

图4 网络的总体结构模型Fig.4 Structure model of proposed network
2.1 预训练CNN参数微调
场景图像不同于单一的对象图像,通常具有类间差异小、类内差异大等特征,分类难度较高。在ImageNet数据集上进行预训练的CaffeNet、VGG-F 与VGG-M 模型虽然已经具备强大的图像理解能力,但是针对于更加复杂的场景分类,仍有提升的空间。因此,采用一定的遥感场景训练样本对3种网络进行参数微调,优化特征提取性能。因为3种网络均由5个卷积模块和3个全连接层组成,最后采用softmax 分类器得到最终类别概率。3 种网络参数的调整方法基本相同,此处仅对VGG-F模型的参数调整过程进行阐述。

最后采用交叉熵的方式计算网络的损失函数,并根据随机梯度下降的方法最小化损失函数对预训练网络进行微调,求解最优的网络参数θ*。
2.2 多特征融合
预训练的CaffeNet、VGG-F与VGG-M模型中分别有5个卷积模块,每个模块中卷积层的核大小与核数量不同,具体参数如表2所示。可以得出,CaffeNet与VGG-F的每层卷积核的大小相同,因此感受野相同,但由于卷积核内参数以及卷积核的数量不同,因此能够捕捉到图像中相同尺度下的不同特征;VGG-M 的卷积核大小略小于其他两个网络,因此对图像中的细节信息的鉴别能力更强;并且由于模型的输入图像规格不同,因此相同大小的卷积核捕捉到的图像感受野也有所不同。对3种网络的特征进行融合,最终实现全方位多尺度的特征提取。

表2 模型的卷积核概况Table 2 Convolution kernel overview of model
预训练的CaffeNet、VGG-F 与VGG-M 模型在经过特定领域数据集的参数调优之后,舍弃最后一层全连接层与softmax层以及对应的参数。gC(Xi;θC)、gF(Xi;θF)和gM(Xi;θM)分别表示样本Xi在CaffeNet、VGG-F 与VGG-M 最后一层提取到的特征表示。随后,将3 个特征向量以元素相加的方式送入融合层,得到全方位多尺度的融合特征:f([gC(Xi;θC),gF(Xi;θF),gM(Xi;θM)])。
2.3 CELM分类器
将提取到的融合特征送入CELM 分类器得到最终样本标签。CELM 是一种基于单隐藏层的前馈神经网络的学习分类器,能够通过学习不同类别样本间的差异来初始化输入权重和偏置,根据最小二乘法求解分类器的输出权重。分类器模型的结构如图5所示,其中f为样本的融合特征,m为类别个数。

图5 约束极限学习分类器Fig.5 Classifier of CELM
CELM模型输入N个样本的融合特征{f1,f2,…,fN}、隐藏节点的个数L以及激活函数g(⋅);模型输出为输入层到隐藏层的权重矩阵WN×L和偏置向量b1×L,以及隐藏层到输出层的权重矩阵βL×m。模型的详细过程阐述如下:
(1)判断差异特征的个数是否小于L,若小于L,进行第(2)步,否则结束运算。
(2)从任意两个类别中随机选取两个样本Xc1和Xc2,并计算差异特征fc1-fc2。
(3)对差异特征进行标准化并计算对应的偏置:

(4)采用w和b构建输入权重矩阵WN×L和偏置向量b。
(5)计算输出矩阵:

(6)通过求解最小二乘问题计算输出层的权重矩阵:

3 实验结果与分析
本文提出的基于多特征融合与CELM 的场景分类算法实验过程中,每种类别中包含的训练样本与测试样本的比例为7∶3,CELM 的隐藏节点数为3 000,采用sigmiod 激活函数。UC-Merced、SIRI-WHU 数据集与WHU-RS19 数据集的总分类准确率分别为97.70%、99.25%与98.26%。图6~图8 分别显示了3 种数据集中测试集对应的混淆矩阵。
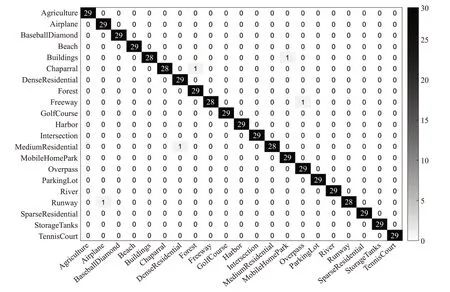
图6 UC-Merced数据集混淆矩阵Fig.6 Confusion matrix of UC-Merced dataset

图7 WHU-RS19数据集混淆矩阵Fig.7 Confusion matrix of WHU-RS19 dataset

图8 SIRI-WHU数据集混淆矩阵Fig.8 Confusion matrix of SIRI-WHU dataset
由图中可以得出,在每种数据集中,大多数场景类能够被正确分类。且每个场景中,至多有两张图像分类错误。因此,提出的基于多特征融合与CELM 的场景分类算法在遥感场景数据集中能够取得比较普遍的适用性。
为了验证提出的基于多特征融合与CELM 的场景分类算法的有效性,针对微调效应、特征融合效应以及分类器的选择设计了3组对比实验。
3.1 预训练CNN微调
本组实验采用SIRI-WHU 数据集分别对预训练CaffeNet、VGG-F 与VGG-M 模型进行参数调优。每个网络的迭代训练次数为20,图9显示了迭代过程中的训练集与验证集的top1错误率,实验选取验证集错误率最低的模型作为最终的微调模型。表3显示了3种预训练卷积神经网络与微调网络在UC-Merced、WHU-RS19和SIRI-WHU数据集上的分类准确率。

表3 数据集的微调效应比较Table 3 Comparison of fine-tuned effects in datasets%

图9 预训练网络微调过程Fig.9 Fine-tuned process of pre-trained CNN
由表3 可见,3 种网络在经过参数调优后的分类效果均有不同程度的提高。因此可以得出,微调后的卷积神经网络更有利于场景分类。
3.2 多特征融合
本组实验是为了验证不同网络中卷积结构相对于单独的网络卷积结构,能够捕捉多尺度互补特征。针对单特征、双特征融合以及多特征融合进行了7组对比实验。此外,对预训练卷积神经网络与精调的卷积神经网络上的特征融合结果也进行了实验对比。表4 显示了每组对比实验的分类精度。

表4 数据集特征融合效应对比Table 4 Comparison of feature fusion effects in datasets%
可以看出,单特征的分类性能有限,双特征融合的分类精度比单特征高,多特征融合的分类精度比双特征融合高,并且精调后融合的分类精度比预训练融合的分类精度高。此外,多特征融合在3 种种数据集上产生的99.25%、98.26%以及97.70%的分类精度表明,采用CaffeNet、VGG-F 与VGG-M 网络结构融合结合约束极限学习分类器捕捉的特征几乎涵盖图像的全部信息。
3.3 CELM分类器性能
为了验证不同分类器的分类性能,分别采用SVM、ELM与CELM分类器对UC-Merced、SIRI-WHU与WHURS19 数据集进行分类。其中,ELM 分类器的隐藏节点设为10 000。表5、6 和表7 分别显示了3 种分类器在每种数据集的单个类别上的分类结果,可以看出,与其他分类器相比,CELM分类器取得了相对较好的性能。
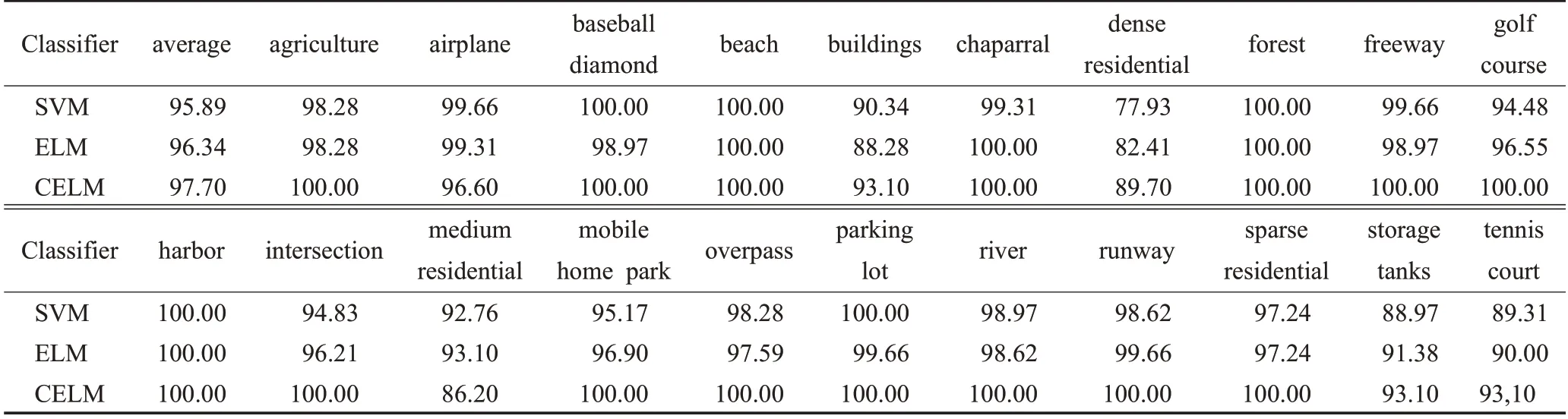
表5 UC-Merced数据集分类器性能Table 5 Classifier performance of UC-Merced dataset%

表6 SIRI-WHU数据集分类器性能Table 6 Classifier performance of SIRI-WHU dataset%

表7 WHU-RS19数据集分类器性能Table 7 Classifier performance of WHU-RS19 dataset%
4 结束语
本文提出了一种基于多特征融合与CELM 分类器相结合的卷积神经网络模型用于场景图像分类。方法首先选用3种不同的卷积神经网络训练模型,采用特定数据集对其进行参数微调;微调后的网络对图像进行特征提取,采用元素相加的方式对提取的3种互补特征进行融合;将融合后的特征送入CELM 分类器,得到每个类别的概率分数,并将概率最大的类别作为图像的语义标签。在UC-Merced、SIRI-WHU 与WHU-RS19 数据集上的分类结果表明,本文提出的场景分类模型采用深度较浅的卷积神经网络,在特定的数据集上实现了较高的分类效果。下一步工作将采用无监督学习的方法获取低水平的卷积核参数,使融合网络能够捕捉更具针对性的特征。
猜你喜欢
现代电力(2022年2期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年2期)2021-02-23
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子技术与软件工程(2019年18期)2019-11-18
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
电子技术与软件工程(2017年14期)2017-09-08
