
基于无监督学习的视频中人体动作识别综述
2022-01-22 07:23高文静琚行松
唐山师范学院学报 2021年6期
高文静,琚行松
基于无监督学习的视频中人体动作识别综述
高文静,琚行松
(唐山师范学院 信息技术中心,河北 唐山 063000)
对视频中无监督的人体动作识别方法进行了综述。基于聚类和基于降维的传统无监督学习识别算法,对前期动作特征的设计和提取有较高的依赖及敏感性;基于卷积神经网络和基于递归神经网络的深度学习无监督识别方法能够自动提取动作特征,因而弥补了传统方法手工提取特征的不足,但也带来了新挑战。
动作识别;无监督学习;聚类;降维;深度学习;卷积神经网络;递归神经网络
视频中的人体动作识别已经成为计算机视觉领域研究的热点并广泛应用于视频监控、人机交互、自动标签、赛事分析等多个领域[1,2]。然而,通过对视频帧的处理,检测跟踪人体肢体动作,建立视频数据与实际动作间的联系,从而使得机器像人类一样理解视频并给出分类结果,仍然是一项重大的挑战。
根据识别过程中是否对样本加注标签可将人体动作识别方法主要分为有监督的(supervised)和无监督的(unsupervised)动作识别方法,如图1所示。有监督的动作识别方法首先需要将样本集中所有样本加注分类标签。将样本集分为训练样本子集1(对应标签集(1))与测试样本子集2(对应标签集(2))。()为分类算法对应的输出。分类过程分为训练过程和测试过程。训练过程的目标是找到使得(1)与(1)不同的次数最少的损失函数。然后,在测试过程中利用训练过程找到的损失函数,测试(2)与(2)间的差距[4-7]。
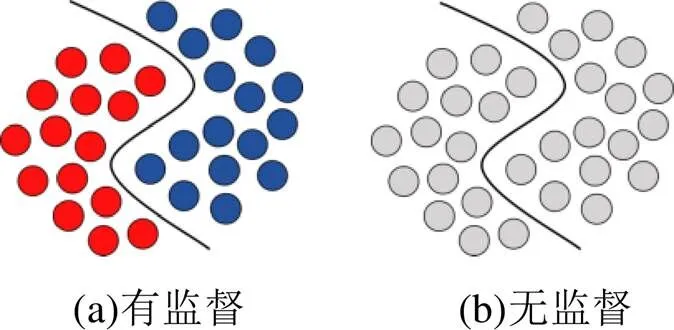
图1 有监督与无监督图示[3]
有监督的动作识别方法需要在早期对训练集创建标签进行预训练,需要消耗大量的人力进行手工标签。但是,在现实的分类问题中,创建带标签的训练数据集并不可行,而且对特定样本的训练过程难以推广到实际通用的环境中,因此,越来越多的研究转向不加标签的样本数据识别,称为无监督的动作识别方法[8-12]。
1 无监督学习的过程
无监督学习是以无标签的样本数据集
={1,2,3, …,n}
为研究对象,学习样本数据内部的潜在规律和结构信息,比如人体动作,并获得相应的输出
()=[(1),(X),(3), …,(n)],
进而依据输出信息把无标签样本数据信息划分到不同类别的簇、生成输入数据的高维样本数据的低维结构,或者直接输出分类结果。最后,将输出结果与真实情况比较得到算法的精确度。
2 基于无监督学习的动作识别算法
动作特征是视频中描述人体动作、反映运动信息的重要部分[13]。根据是否手工设计动作特征可将无监督的动作识别算法分为传统的动作识别方法与基于深度学习的动作识别方法。如图2所示。

图2 无监督动作识别方法分类
2.1 传统无监督动作识别方法
传统的人体动作识别方法首先需要手工设计并提取动作特征,之后基于提取的动作特征进行动作识别或分类[14]。广泛采用的动作特征主要分为全局特征和局部特征。全局特征主要通过计算视频帧的运动能量图(motion energy image,MEI)、运动历史图(motion history image,MHI)提取动作模板特征;局部特征是通过对人体发生运动的部位进行跟踪,计算局部区域的亮度梯度(gradient of brightness)、梯度直方图(histogram of gradient,HOG)、光流直方图(histogram of optical flow,HOF)、运动边界直方图(motion boundary histo- gram,MBH)等,提取时空关键点特征、运动部位的轨迹特征。还有一些算法通过计算视频帧的局部二值模式(local binary pattern,LBP)提取图像纹理等外观特征[15]。在得到相应动作特征后主要采用聚类或降维的方法对特征进行处理或建模,进而得到分类结果。
2.1.1 基于聚类
聚类算法是在提取到样本的动作特征后,计算样本特征的距离(通常计算欧氏距离)。将距离最近的样本特征划分到相同的类别中,从而得到分类结果[16]。

图3 聚类算法一般流程[16]
Lui[17]和Niebles[18]在提取到时空关键点组成的时空立方体的亮度梯度特征后,将视频表示成张量,再把张量映射成Grassmann乘积流形上的一点,如图4中的圆点。然后通过计算流形上两个点之间的测地距离进行聚类从而实现动作分类。

图4 乘积流形距离[17]
Nater[19]通过采用自顶向下的层次聚类(hier- archical cluster,HC)对人体动作进行分类识别。首先提取到样本局部时空特征后,将所有的样本都置于同一个动作类中,然后不断迭代计算不同样本特征的距离。在每次迭代中,一个动作类被分裂为更小的动作类,直到每个视频样本被归入相应的某种单独类中,最终得到分类结果。如图5所示。
在一个完全无监督学习的环境中,动作的类别数是未知的,层次聚类不需要在开始设定类别的个数,因而更符合实际情况。

图5 在不同层C(i)上的聚类结果[19]
2.1.2 基于降维
广泛使用的基于降维思想的动作识别方法主要有主成分分析法(principal component analysis,PCA)。PCA方法首先将样本的特征矩阵投影到一个超平面;然后选取方差尽可能大的、相互正交的、互不相关的特征作为样本的主成分,使样本的特征矩阵在超平面上的投影尽可能分散,从而实现分类。通过映射得到样本主成分特征,既消除了冗余的样本特征数据,又尽可能多地保留了样本原始特征数据。
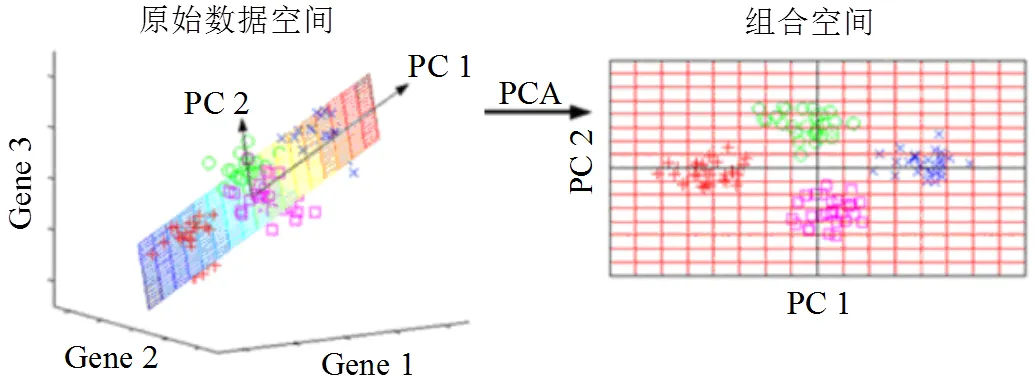
图6 PCA降维[20]
刘志强等人[21]借助kinect传感器提取到人体骨骼关键点的动作特征后,采用PCA对特征进行过滤重组,并采用了两种协方差矩阵构造方法进行主成分分析。吕想[22]跟踪人体运动曲线,提取手、脚、躯体轮廓的光流特征,然后将收集到的特征通过PCA进行降维得到特征矩阵。
2.2 基于深度学习
传统的无监督动作识别方法,在手工提取特征阶段存在设计失误和严重耗时等现象,降低了动作识别的准确率和时效性。基于深度学习的动作识别使用深度网络从原始视频中自动学习特征并输出分类结果,是一种端到端的方法,具有更强的鲁棒性。根据学习网络结构的不同,无监督的深度学习动作识别方法主要分为基于卷积神经网络(convolutional neural networks, CNN)的动作识别和基于递归神经网络(recurrent neural networks,RNN)的动作识别。
2.2.1 基于卷积神经网络
卷积神经网络是一种前馈人工神经网络。卷积神经网络对特征学习的过程是从数据的底层开始,向顶层逐层训练参数,整个过程是无监督的[8-12]。在学习过程中,首先以无标记的数据训练第一层的参数。根据模型的容量限制和稀疏性约束条件,模型学习到数据的自身结构,得到数据更具表征的特征。然后,将下一层的输出作为上一层的输入,再进行训练得到每层参数。在第层的第个特征的映射(,)的计算如式(1)[23]:

式中,是一个非线性的激活函数,是权重矩阵,和是卷积核的高和宽。
以上工作没有利用视频中的时间信息,而一些动作是能够通过时间信息来重点区分的,例如行走和跑步。现有两种方式可以引入时间信息。
2.2.1.1 3D CNN
Kim等人[24-26]通过3D CNN引入时间信息:
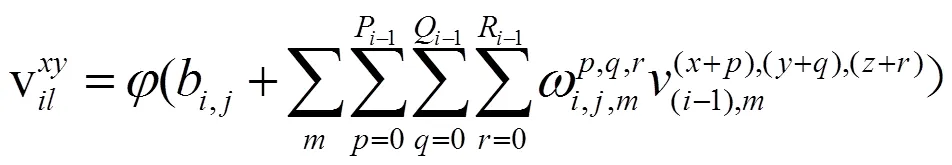
式中,、、和与式(1)相同,是卷积核内核的时间长度。
Tran等人[27]在前者的基础上提出了一种基于线性分类器的C3D方法(convolutional 3D),其网络由5个卷积层、5个最大池化层、2个全连接层和1个softmax损失层组成。为了进一步提高三维卷积网络的泛化能力,Qiu 等人[28]提出了另一种构建深度三维卷积网络的方法——伪三维残差网(pseudo-3D residual net,P3D ResNet),使用一个1×3×3卷积层和一个3×1×1卷积层的组合来代替标准的3D 卷积。
3D CNN通常考虑比较短的时间间隔,因此无法捕获长期的时间信息。
2.2.1.2 基于双流CNN
Simonyan[29]等人为引入时间信息,提出了基于CNN的空间流与时间流的双流模型进行动作识别,如图7所示。空间流采用CNN获取视频中所描述的场景和对象的信息,时间流以跨帧的运动形式获取观察者(相机)和物体运动的时间信息。得到两种特征后,将两种流的softmax得分进行融合,得到最终识别结果。
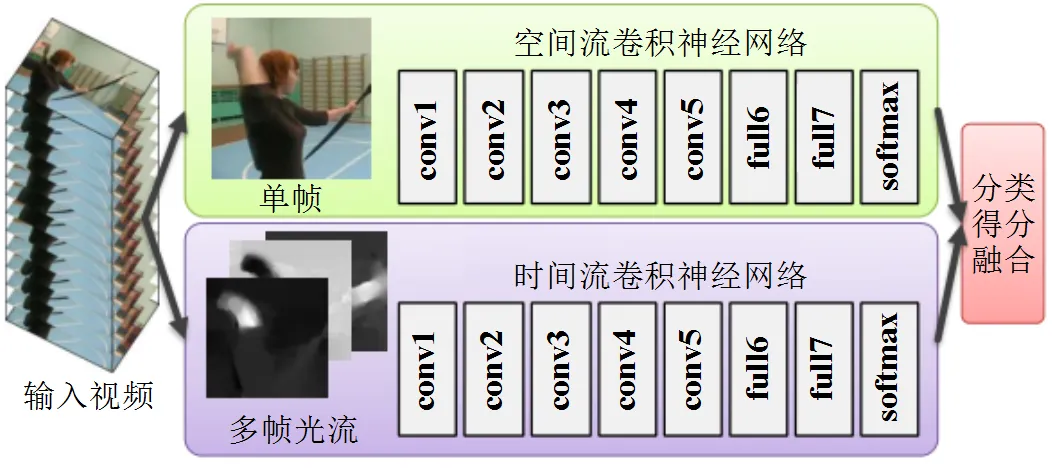
图7 动作识别的双流结构[29]
Wang[30]在此基础上采用GoogleNet和VGG- 16深度CNN 结构,设计了一个非常深的双流模型,同时在训练时做了一些改进,包括对两个流都进行预训练,使用更小的学习率,更多数据增强和高的丢弃(dropout)率。为了最大化利用双流模型中的时空信息,Feichtenhofer[31]等人在研究了多种时空流的融合方法后,提出了一种改进的双流模型。该模型在两个流之间引入了一种新的卷积融合层和一个包含了3D 卷积和3D池化的新型时间融合层,得到了更好的识别效果。
2.2.2 基于递归神经网络
视频样本包含很多帧,并不是所有帧对动作识别都能起到正向激励作用。如果将视频中的所有帧加入计算会增加成本,而且可能降低识别的性能。RNN选择性地关注每一帧的输入动作,并对不同帧的输出给予不同程度的关注,同时提取视频帧序列的上下文语义信息。因此RNN对高层时空特征序列的建模效果更好[32,33]。
Du[34]等人将人体分为左右上肢、躯干、左右下肢5个部分,并分别将此5个部分输入到5个RNN子网中。在第一层中提取到5种动作特征后,将驱干子网的动作特征与其他4种子网进行融合变成4种特征,然后将此4种特征输入到4个RNN子网中进行第二次特征提取。一直到子网提取的特征融合了全部人体的5个部分,最后输入一个RNN网络中,得到识别结果,如图8所示。该方法克服了背景、遮挡等干扰,将注意力集中于发生动作的人体,并分别从人体局部到人体整体的动作特征分别给予关注,从而有效减少了对分类结果的干扰。
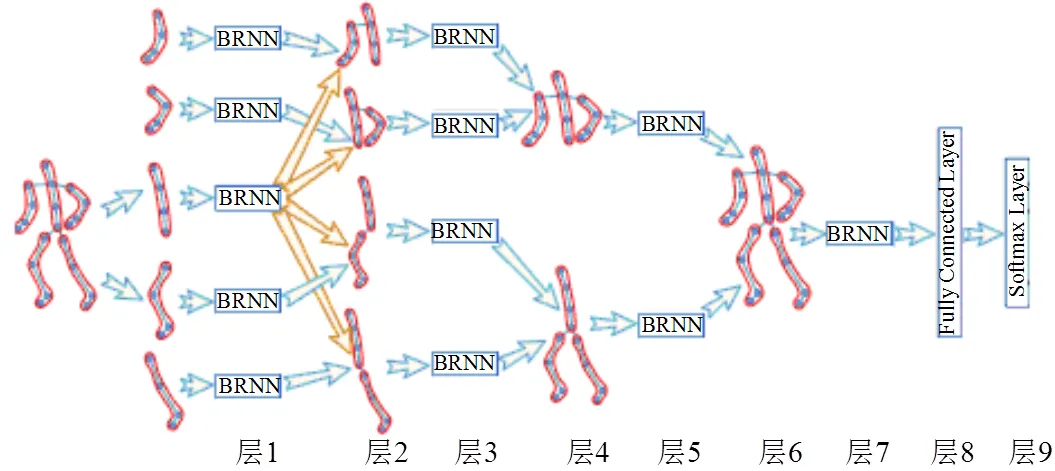
图8 分层子网融合递归神经网络识别[34]
Sharma等人[35]将注意力机制融合到RNN,提出了长短期记忆单元(long short term memory,LSTM)。LSTM具有较深的空间和时间架构。Sharma创建的模型有选择地聚焦于视频帧中存在运动的部分,学习与当前任务相关的视频帧,并对这些帧给予更高的重视,在注意几次后对视频进行分类。李等人[36]引入VideoLSTM,将注意力机制应用于卷积模型以发现相关的时空体。除此之外,VideoLSTM还采用了从光流图像中获得基于运动的注意力,以更好地定位动作。
3 总结
视频中的人体动作识别是计算机视觉中十分重要的研究领域,具有广泛的应用前景。本文通过是否手工设计特征对无监督的视频中人体动作识别的传统方法和基于深度学习的方法进行了讨论。最新的发展已经证明深度学习对于无监督的视频中人体动作识别的有效性。现有的深度模型方法然虽然取得了很好的成果,但依然面临诸多挑战,仍有很多技术难关需要攻克。例如,视频数据包含丰富的空间、时间和声音信息,深度模型的进一步发展需要充分利用这些不同维度的信息,以更好地完成视频识别的任务。
[1] Wang Z, She Q, Smolic A. ACTION-Net: Multipath Excita- tion for Action Recognition[EB/OL]. [2021-06-05]. https:// arxiv.org/abs/2103.07372, 2021: 13209- 13218.
[2] Nagrani A, Chen S, Ross D, et al. Speech2Action: Cross- modal Supervision for Action Recognition[C]// Pro- ceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, IEEE, 2020: 10314-10323.
[3] Schmarje L, Santarossa M, Schrder S M, et al. A survey on Semi-, Self- and Unsupervised Learning in Image Classifi- cation[J]. IEEE Access, 2021, 9: 82146- 82168.
[4] Bobick A, Davis J. An appearance-based representation of action[C]// Intl. Conf. on Pattern Recognition, 1996: 307- 312.
[5] C Yu, H Cheng, C Cheng, et al. Efficient Human Action and Gait Analysis Using Multiresolution Motion Energy Histo- gram[J]. EURASIP Journal on Advances in Signal Process- ing, 2010.
[6] Marszalek M, Laptev I, Schmid C. Actions in context[C] // IEEE Conference on Computer Vision and Pattern Reco- gnition, IEEE, 2009.
[7] Wang H, Yuan C, Hu W, et al. Supervised class-specific dictionary learning for sparse modeling in action recog- nition[J]. Pattern Recognition, 2012, 45(11): 3902-3911.
[8] Jain M, van Gemert J, Snoek C G M. University of Amsterdam at THUMOS challenge 2014[C]// THUMOS Challenge: Notebook Papers, 2014.
[9] Oneata D, Verbeek J, Schmid C. The LEAR submission at Thumos 2014[C]// Proc. ECCV THUMOS Challenge Workshop, 2014: 4-10.
[10] Wang L, Yu Q, Tang X. Action Recognition and Detection by Combining Motion and Appearance Features[C]// THUMOS’14 Action Recognition Challenge, 2014: 1-6.
[11] S Karaman, L Seidenari, A Bimbo. Fast saliency based pooling of Fisher encoded dense trajectories[C]// THUMOS’14 Action Recognition Challenge, 2014.
[12] Jain M, Gemert J, Snoek C. What do 15, 000 object categories tell us about classifying and localizing actions? [C]// IEEE Conference on Computer Vision and Pattern Recognition, 2015: 46-55.
[13] 李亚玮.视频动作识别中关于运动特征的研究[D].南京:东南大学,2018:8.
[14] 黄位.基于多特征融合的人体动作识别[D].西安:西北大学,2021:15.
[15] Zhu Fan, Ling Shao, Jin Xie, et al. From handcrafted to learned representations for human action recognition: A survey. [J]. Image and Visionuting, 2016, 55(2): 42-52.
[16] Xu R, Wunsch Donald. Survey of Clustering Algori- thms[J]. IEEE Transactions on Neural Networks, 2005, 16(3): 645-678.
[17] Lui Y M, Beveridge J R, Kirby M. Action classification on product manifolds[C]// 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CA: IEEE, 2010.
[18] Niebles J C, Wang H, Fei-Fei L. Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words [J]. International Journal of Computer Vision, 2008, 79(3): 299-318.
[19] Nater F, Gr Ab Ner H, Gool L V. Exploiting simple hierarchies for unsupervised human behavior analysis [C] // 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CA: IEEE, 2010.
[20] Muktabh Mayank. Ten Machine Learning Algorithms, You Should Know to Become a Data Scientis[EB/OL]. [2021- 06-05]. https://www.kdnuggets.com/2018/04/10-machine- learning-algorithms-data-scientist.html.
[21] 刘志强,尹建芹,张玲,等.基于Kinect数据主成分分析的人体动作识别[C]//2015光学精密工程论坛论文集, 长春:中科院长春光机所,2015.
[22] 吕想.基于运动曲线的主成分分析方法的人类行为识别研究[D].长春:吉林大学,2013.
[23] Yao G, Lei T, Zhong J. A Review of Convolutional Neural Network Based Action Recognition[J]. Pattern Recog- nition Letters, 2018, 118(FEB.): 14-22.
[24] H Kim, J Lee, H Yang. Human action recognition using a modified convolutional neural network[C]// International Symposium on Advances in Neural Networks, Berlin: Springer-Verlag, 2007: 715-723.
[25] M Baccouche, F Mamalet, C Wolf, et al. Sequential deep learning for human action recognition[C]// Inter- national Conference on Human Behavior Under- standing, 2011: 29-39.
[26] S Ji, W Xu, M Yang, et al. 3D convolutional neural networks for human action recognition[C]// Interna- tional Conference on Machine Learing, 2010: 495-502.
[27] Tran D, Bourdev L, Fergus R, et al. Learning spatio- temporal features with 3D convolutional networks[C]// 15th IEEE International Conference on Computer Vision, 2015: 4489-4497.
[28] Qiu Z, Yao T, Mei T. Learning spatio-temporal represen- tation with pseudo-3d residual networks[C]// 17th IEEE International Conference on Computer Vision, 2017: 5534-5542.
[29] Simonyan K, Zisserman A. Two-Stream Convolutional Networks for Action Recognition in Videos[C]// Advan- ces in neural information processing systems, 2014: 568- 576.
[30] Wang L, Qiao Y, Tang X. Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors [C]// Proceedings of the IEEE Computer Society Con- ference on Computer Vision and Pattern Recognition, 2015: 4305-4314.
[31] Feichtenhofer C, Pinz A, Zisserman A. Convolutional Two-Stream Network Fusion for Video Action Recog- nition[C]// Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recog- nition, 2016: 1933-1941.
[32] Wang X, Miao Z, Zhang R, et al. I3D-LSTM: A New Model for Human Action Recognition[C]// IOP Con- ference Series: Materials Science and Engineering, 2019: 569-571.
[33] Song S, Lan C, Xing J, et al. An End-to-End Spatio- Temporal Attention Model for Human Action Recog- nition from Skeleton Data[C]// 31st AAAI Conference on Artificial Intelligence, AAAI, 2017: 4263-4270.
[34] Du Y, Wang W, Wang L. Hierarchical recurrent neural net- work for skeleton based action recognition[C]// Proceed- ings of the IEEE Computer Society Conference on Com- puter Vision and Pattern Recognition, 2015: 1110- 1118.
[35] Sharma S, Kiros R, Salakhutdinov R. Action Recog- nition using Visual Attention[C]// Neural Information Process- ing Systems: Time Series Workshop, 2015.
[36] Li Z, Gavrilyuk K, Gavves E, et al. Video LSTM convolves, attends and flows for action recognition[J]. Computer Vision and Image Understanding, 2018, 166: 41-50.
[37] Hassner Tal. A Critical Review of Action Recognition Benchmarks[C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2013: 245-250.
A Summary of Human Action Recognition in Video Based on Unsupervised Learning
GAO Wen-jing, JU Xing-song
(Information and Technique Center, Tangshan Normal University, Tangshan 063000, China)
The unsupervised recognition algorithms of human actions in video were summarized. The traditional unsupervised action recognition algorithms including clustering algorithm and dimension reduction algorithm have high dependence and sensitivity on the design and extraction of early action features. The unsupervised deep learning action recognition algorithms including the ones based on convolution neural network and the ones based on recurrent neural network can automatically extract action features, which makes up for the deficiency of manual feature extraction in traditional algorithms, but new challenges are brought about.
action recognition; unsupervised learning; clustering; deep learning; demonsion reduction; convolution neural network; recurrent neural network
TP391
A
1009-9115(2021)06-0057-06
10.3969/j.issn.1009-9115.2021.06.015
唐山师范学院科学研究基金项目(2021B36)
2021-07-29
2021-10-25
高文静(1988-),女,河北唐山人,硕士,讲师,研究方向为人工智能、网络。
(责任编辑、校对:田敬军)
猜你喜欢
现代电力(2022年2期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
