
基于改进的YOLOv4安全帽佩戴检测研究
2022-01-21 06:35:02郭师虹井锦瑞张潇丹秦晓晖
中国安全生产科学技术 2021年12期
郭师虹,井锦瑞,张潇丹,秦晓晖
(西安建筑科技大学 土木工程学院,陕西 西安 710055)
0 引言
建筑施工中,往往存在不同类型的施工和作业风险,时刻威胁着施工人员的人身安全。例如,高处坠落、物体打击、坍塌、起重伤害、其他伤害等。其中,2014—2018年间,高处坠落事故占建筑施工事故总数的51.52%;物体打击事故占建筑施工事故总数的13.89%[1]。因此,建筑施工人员必须正确使用个人防护用品,尤其是佩戴安全帽。安全帽可以保护头部免受高处坠物对头部的冲击力,减轻头部在重压下受到的损伤,从而保护工作人员在危机时刻的生命安全[2]。目前对安全帽佩戴的检测仍然主要依靠施工现场管理人员的检查,繁琐且耗时。针对这一情况,迫切需要更加经济有效的方式使该过程自动化,进一步减轻施工受伤和死亡的风险,进而提供一个更安全的工作环境。
在建筑领域,利用机器学习和多信息融合技术可以实现施工过程的自动化[3]。其中,机器视觉技术被证明可以快速、方便地从建筑工地采集相关数据,如检测、定位和跟踪施工人员和设备,但相关研究仍处于起步阶段。在现有的施工安全检测系统中,仍存在较多不足,可分为2类,一类是识别速度慢且错误率偏高;另一类则是没有考虑到不同外界因素对系统造成的影响,例如方向、颜色、背景对比度、图像分辨率和现场照明强度等因素[4]。
为了解决上述问题,本文提出1种轻量化的安全帽佩戴检测系统,该系统可以在移动设备端进行部署,如笔记本电脑,可大大降低系统实现条件,有利于现场的实时监控,既可节省人工成本,又可提高现场安全性。
1 安全帽佩戴检测方法研究现状
目前对于安全帽佩戴检测的研究可分为基于传感器的检测方法、基于传统图像处理的识别方法和基于计算机视觉的检测方法。
1.1 基于传感器的检测方法
基于传感器的检测方法主要依靠定位技术来定位工人和安全帽。Kelm等[5]设计了1种移动射频识别门户,安装于建筑工地入口,用于检查施工人员的个人防护用品(PEE)是否符合规定。Barro-Torres等[6]介绍了1种信息物理系统(CPS),用来实时监控施工人员是否穿戴个人防护用品,施工人员佩戴的传感器不是位于施工现场的入口,而是集成在工人的衣服中进行持续监控。Dong等[7]使用具有虚拟建筑技术的定位系统来跟踪工人,判断工人的当前状态是否应该佩戴安全帽并发送警告。压力传感器放置在安全帽中,通过收集和存储压力信息来判断安全帽是否佩戴,然后通过蓝牙传输进行监视和响应。此外,蓝牙设备使用一段时间后需要充电,这增加了大量的后期工作,不利于该技术的长期使用。
通常,现有的基于传感器的检测和跟踪技术受限于每个建筑工人,工人必须穿着物理标签或传感器,并且需要对硬件设备进行大量的前期投资,包括物理标签或传感器。同时,许多工人出于健康和隐私方面的考虑,不愿佩戴此类跟踪设备。
1.2 基于传统图像处理的识别方法
蔡利梅等利用安全帽的外部形象特性信息建立安全帽模型,用于解决复杂环境下矿井视频的安全帽识别[8],但需要采集具有准确外部特征才能匹配。刘晓慧、叶西宁采用肤色检测的方法定位到人脸区域,并以此获得脸部以上的区域图像,并将神经网络和支持向量机(SVM)2种分类模型进行比较,证明SVM对安全帽的识别效果更好[9]。冯国臣等提出利用混合高斯模型进行前景检测,通过对连通域的处理判断其是否属于人体,最后定位人体头部区域实现安全帽的自动识别[10],但是其方法对不同工人姿态的鲁棒性较差。上述的这些方法需要施工工人在工作过程中面对监控摄像头采集正脸区域时才能识别面部特征。而在建筑施工过程中,工人因工种不同,姿态也有所不同,不能时刻保证正脸朝向监控摄像头。
通过对国内外基于传统图像处理的安全帽识别研究进行总结概括,目前已有研究的识别方法不适用于具有独特性、动态性、杂乱的建筑施工现场环境,在实际施工现场表现较差。此外,需构建大量的样本特征库,耗时长且效率低。
1.3 基于计算机视觉的检测方法
近几年,将计算机视觉方法应用于施工安全检测已成为趋势。杨莉琼等利用YOLOv3算法对图像中人脸的区域进行定位,然后根据人脸与安全帽的关系估算出安全帽的潜在区域,再利用HOG进行特征提取,利用SVM分类器来判断是否佩戴安全帽[11]。赵平等提出1种基于YOLO-BP神经网络的古建筑修缮阶段火灾监测方法[12],使用YOLO算法检测火源和可燃物,BP神经网络的应用增强了系统的自学习能力,提高了系统的检测精度。李华等使用Faster RCNN算法进行改进,增加锚点来改善系统对于小目标的检测能力[13],使系统在远距离检测场景下对小目标的检测能力拥有更好的表现。
与其他算法相比,YOLOv4[14]在检测速度和精度上的表现更适合在实际部署中使用。谷歌提出的MobileNet轻量化网络结构,推动系统向移动端部署,如手机或笔记本电脑。因此,本文将MobileNetV3网络与YOLOv4网络进行结合,提出改进的YOLOv4轻量级模型用于建筑工人安全帽佩戴的检测,使没有很好计算能力的设备也可以拥有较高的检测速度和识别精度,进而满足施工现场的要求。
2 改进的YOLOv4安全帽佩戴检测模型
2020年Rachel Huang等提出了YOLO-LITE模型[15],这是1个实时的物体检测模型,旨在创建1个更小、更快、更高效的模型,可以在便携式设备上(笔记本电脑或手机)拥有更好的性能。
本文基于这一思想,采用谷歌提出的MobileNet模型来代替YOLOv4的主干特征提取网络,并且为了进一步减少模型的参数量提高检测速度,使用深度可分离卷积代替YOLOv4中用的普通卷积。
2.1 模型训练及检测流程
本文基于Tensorflow框架对施工人员佩戴安全帽行为进行检测,采集的8 000张图像的数据集可以使模型在训练时避免过拟合情况发生,并且提高模型的识别精度。对于采集到的数据集,使用LabelImg软件对图片进行标注,标注出目标在图片中所在位置及类别。
在模型训练时,首先需要将图片进行预处理,并且提取预处理后图片中标记目标的所在区域,输入到改进的YOLOv4网络中进行特征提取,最后输出模型权重文件用于佩戴安全帽的实时检测。
在进行实时检测时,首先调用监控摄像头视频,将视频流以截取图像帧的形式输入到构建好的网络中进行识别,识别具有特定特征值的区域,并用方框标记出识别到的特征值区域,最后将输出的图像帧转化为视频流,达到实时检测的效果。模型训练及检测流程见图1。

图1 佩戴安全帽行为检测流程Fig.1 Detection procedure for behavior of wearing safety helmet
2.2 改进的YOLOv4模型构建
若想提高模型的识别精度,需加深模型网络的结构深度,采集更为精确的特征图谱,但这样会对模型的识别速度产生影响;反之,若提高模型的识别速度,需简化模型的结构,提高速度,但会对识别精度产生影响。为找到这一矛盾的折中点,本文借鉴YOLO-LITE中提出的思想,将YOLOv4的主干特征提取部分的CSPdarknet53网络替换为MobileNetV3网络,在简化网络模型结构、降低参数量的同时,也保证一定的识别精度,使模型又快又准。
MobileNetV3结合了前2代V1和V2的优点,将MobileNetV1的深度可分离卷积层和MobileNetV2的线性瓶颈逆残差结构(the inverted residual with linear bottleneck)进行结合,并且加入了轻量级的注意力模型,调整每个通道的权重。将深度可分离卷积层作为传统卷积层的有效替代,可以把空间滤波与特征生成机制分离开来,有效地分解传统卷积,降低计算量。
在简化模型结构的同时,为了更进一步提升模型的识别精度,在训练模型时依然选择YOLOv4提出的Mosaic数据增强方法,每次提取4张图片,分别对4张图片进行翻转、缩放、色域变化等,并且按照4个方向位置进行组合生成新的训练图片。这种数据增强方法的一个巨大优点是丰富检测物体的背景,提高模型的鲁棒性。Mosaic数据增强后的图片如图2所示。

图2 Mosaic数据增强后的图片Fig.2 Images after Mosaic data enhancement
采用CIoU损失函数。CIoU考虑到了3个几何因素:1)重叠面积;2)中心点距离;3)长宽比。CIoU损失函数公式定义如式(1)所示:
(1)
式中:IoU为交并比,用来反映预测检测框与真实检测框的检测效果;b,bgt分别代表了预测框和真实框的中心点;ρ代表计算2个中心点间的欧式距离;c代表能够同时包含预测框和真实框的最小闭包区域的对角线距离;α为权重参数;v是用来衡量长宽比的相似性的参数。α和v表达式如式(2)~(3)所示:
(2)
(3)
式中:ωgt和hgt分别表示真实框的宽和高;ω和h分别表示预测框的宽和高。
本文构建的改进的YOLOv4整体结构如图3所示。
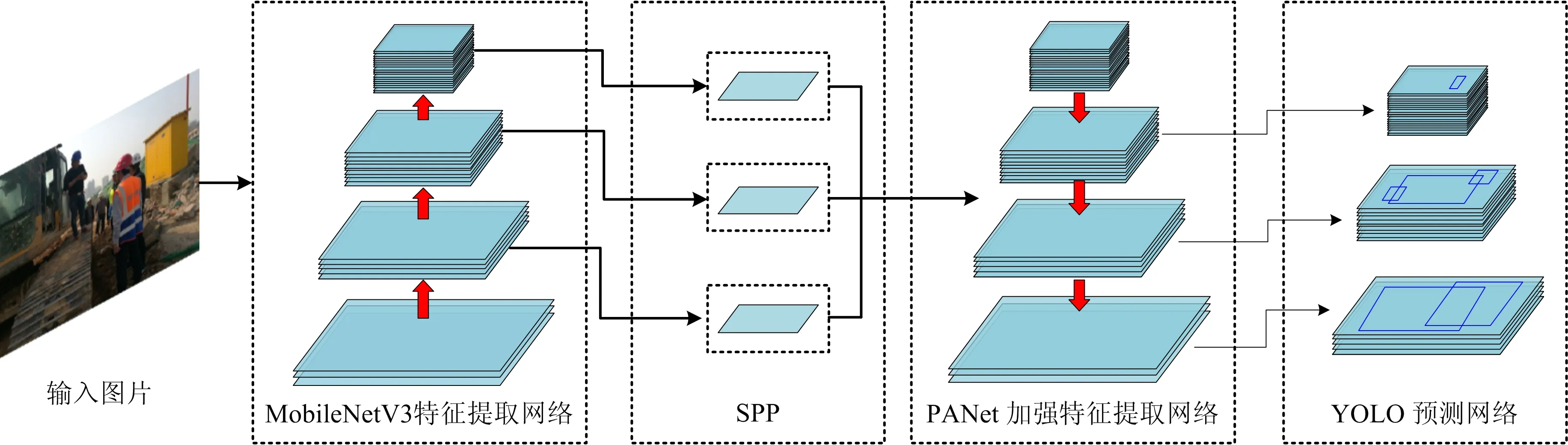
图3 YOLOv4—MobileNetV3网络结构Fig.3 YOLOv4-MobileNetV3 network structure
2.3 评估模型性能指标分析
为了评估模型的性能,本文从准确性、速度和鲁棒性3个方面进行评估。
1)准确性:模型的准确性也可称为识别精度,主要对输入图像中施工工人是否佩戴安全帽进行准确的判定。这里我们采用精确度(Precision)和召回率(Recall)来对模型的识别精度进行评估。为了阐明精确度的含义,首先介绍TP(True Positive)、FP(False Positive)和FN(False Negative)的定义。TP代表预测结果正确;FP代表错将其他类分为本类;FN代表将本类错分为其他类。
精确度可以理解为在所有预测结果是正样本中,实际也是正样本的比例,如式(4)所示:
(4)
召回率可以理解为在所有实际是正样本结果中,预测也是正样本结果的比例,如式(5)所示:
(5)
由于精确度未考虑分类器将正样本分为负样本的情况,召回率未考虑分类器将负样本分为正样本的情况,考虑到这个局限性。在得到其中1个标签的Precision-Recall曲线的基础上,计算每个Recall值相对应的Precision值的平均,得到该标签的AP(Average Precision)值。
获取全部标签的AP值后,计算全部标签的平均AP值,得到mAP(Mean Average Precision)。如式(6)所示:
(6)
式中:k为标签的总数。
2)速度:速度是指将1幅图片输入到网络中进行运算,得到预测结果所用的时间。在进行视频验证时,用每秒传输帧数(FPS)来体现模型的速度。
3)鲁棒性:对于本文提出模型的鲁棒性研究,主要考虑模型对于外界干扰因素的容忍度。在验证时,将采集到的验证集分为室内和室外2类情况,其次在验证室外情况时,又根据不同的环境、光照条件将室外验证集按不同天气、不同光照程度进行详细的划分,分别进行验证。
3 实验与测试结果
为验证本文提出的轻量级YOLOv4模型可在移动端设备拥有较好的性能表现,训练模型和模型测试阶段均在笔记本电脑上进行,硬件条件为:Intel(R)Core(TM) i5-8300 @2.30GHz,8G运行内存,NVIDIAGeForce GTX 1050。
通过网络下载和现场拍摄,采集8 000张图片作为模型训练的数据集,使用LabelImg对图片进行标注,标注出目标在图片中所在位置及类别。对于佩戴安全帽的正样本标记为:helmet,对于未佩戴安全帽的负样本标记为:person。标记结果如表1所示。在训练时,将数据集90%用于训练,10%用作验证。

表1 模型训练数据集标记结果Table 1 The label results of the training data set
3.1 工程背景
为了评价该安全帽佩戴识别系统性能,选取洛阳市地铁系统建设项目的某段实际施工现场作为案例研究,该项目的现场人员构成复杂且数量较多,分别归属于不同的参与方,管理难度较大。本文从5个不同建筑工地采集到600张施工人员图像和60条施工视频作为验证集,对改进的YOLOv4的性能进行评估。根据建筑工地不同的视觉条件对图像进行分类,验证该算法在不同外界环境下的性能。
3.2 实验结果及模型对比
模型在数据集上进行训练时,将数据集的90%用于模型训练,10%用于模型验证。经过验证,该模型的mAP达到83.96%,如表2所示。
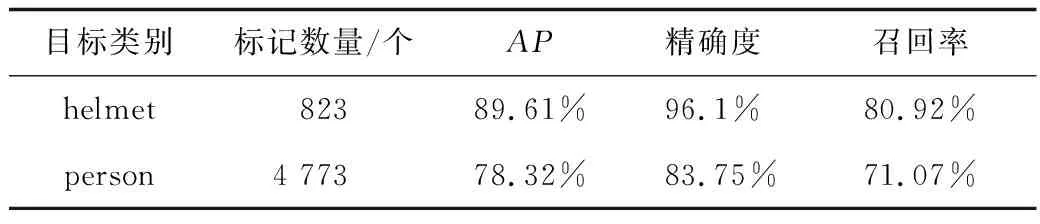
表2 改进的YOLOv4模型验证结果Table 2 Verification results of improved YOLOv4 model
为了体现该模型在识别速度和识别精度上的提升,本文还采用目前主流的算法框架,如:YOLOv4、YOLOv4-tiny和Faster RCNN,分别在制作的数据集上进行训练,然后从FPS、mAP值、精确度和召回率进行对比,如表3所示。改进的YOLOv4模型与原YOLOv4模型相比,速度提高了3.4倍,mAP值仅降低了5.38%,符合提高模型识别速度的同时保证良好的识别精度的条件。与同为轻量级网络的YOLOv4-tiny相比,FPS虽然不及,但mAP值提高了28%。Faster RCNN在移动设备端的FPS仅为2帧/s,不具备实时监控的条件,因此不再进行模型性能验证。
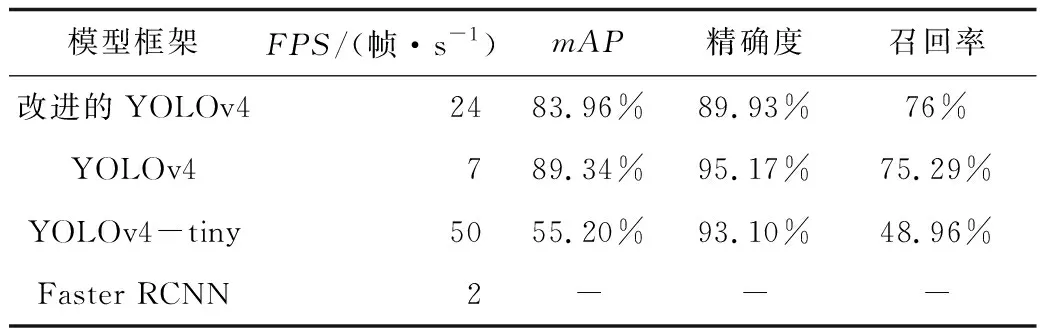
表3 不同模型的对比Table 3 Comparison of different models
根据模型对比结果可以看出,改进后的YOLOv4同时拥有较好的识别精度和速度,满足本文提出的又快又准的想法。与其他识别精度相近的模型相比,速度有很大的优势;与速度相近的模型相比,识别精度有很大的优势。
3.3 现场验证
在验证时,从施工现场通过现场采集的方式,采集图片和现场视频来对模型进行评估。考虑到不同的外界因素会对模型的识别结果产生不同程度的影响,按室内和室外将采集到的图片和视频进行分类,并将室外的验证集按不同时间段和不同天气进行分类,分别进行评估验证。
3.3.1 室内验证
室内通常拥有较好的视觉条件,照明强度也能够保持一个比较平稳的水平,这为目标识别创造了比较理想的环境。本文在洛阳地铁站内进行现场图像采集,地铁站内照明强度适中,外界干扰因素少,有助于该模型的运行。经过验证,该模型的识别正确率高达98.69%,错误率为1.32%,漏检率为11.63%,检测结果如图4所示。

图4 室内图像帧识别示例Fig.4 Example of indoor image frame recognition
3.3.2 室外验证
对室外施工环境的适用程度是验证该模型的主要因素,在现场验证时,需着重考虑不同室外环境对该模型产生的影响。根据不同的施工视觉条件,在验证时,将验证集根据不同的时间段和不同的天气进行划分,进行分别验证,实验结果如表4所示。
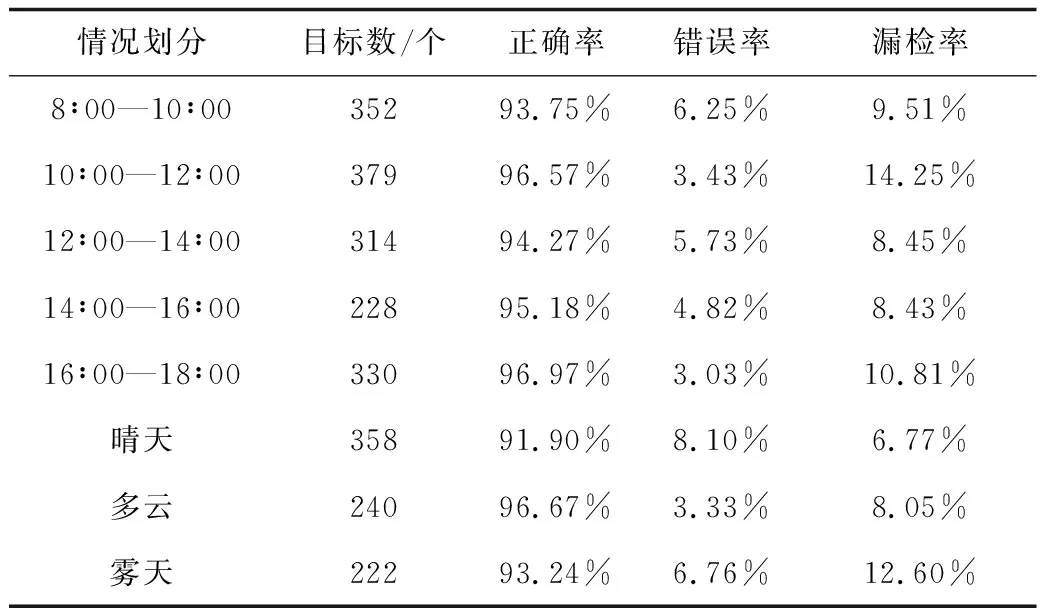
表4 不同情况下的检测结果Table 4 Detection results under different conditions
1)时间段的影响
施工现场的工作时间为早上8点到下午6点。由图5可以看出,下午4点到下午6点的光照强度较弱,白天光照强度最强,上午10点下午4点为峰值,下午4点以后光照逐渐减弱。将图像帧分为5类,如图5,以2 h为1个时间段,共5个时间段进行验证,以测试光照对识别正确率、错误率以及漏检率的影响,检测结果如表4所示。由表4可知,本文模型对于不同时间段的检测均保持在很高的正确率,能够在不同的时间段拥有较高的检测性能。

图5 不同时间段下图像帧识别示例Fig.5 Examples of image frame recognition in different time periods
2)天气的影响
建筑工地主要暴露在室外环境中,受到自然条件的影响显著。因此,天气的变化会影响监控视频的质量。如图6所示,本文考虑3种常见的天气类型,图6(a)为晴天;图6(b)为雾天;图6(c)为多云,验证结果如表4所示。下雨和严重的雾霾不包括在内,因为此类天气往往会导致工作暂停。根据验证结果,本文模型对于不同天气的识别正确率均在91%以上,识别错误率保持在很低的数值,可以应用在常见的天气环境中。

图6 不同天气下图像帧识别示例Fig.6 Examples of image frame recognition in different weather conditions
4 结论
1)将改进的YOLOv4与YOLOv4、YOLOv4-tiny和Faster RCNN相比,改进的YOLOv4的mAP较YOLOv4降低了5%,但是识别速度提高了3.4倍。与同为轻量级模型的YOLOv4-tiny相比,mAP提高了28%。这一改进在提高检测速度的同时,也保证了较好的识别精度,且可以在移动设备端拥有良好的性能,大大降低现场部署的条件,降低计算成本,有利于现场实时监控,改善现场施工人员的安全管理环境,促进自动检测系统的推广应用。
2)从室内和室外分别对检测效果进行验证,又进一步将室外环境按照不同光照条件因素分为不同时间段和不同天气分别进行验证。结果表明,本文模型对于不同的施工环境均拥有很高的识别正确率,对施工人员是否佩戴安全帽取得良好的识别效果,且可以保持较高的运行速度。
3)下一步研究将致力于将本文提出的安全帽检测过程集成到一个完整的安全检查框架中,使该框架能够在检测到危险行为时,迅速、有效且合理地向监控端发出安全警告,提高现场施工安全。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
中学生数理化·七年级数学人教版(2021年6期)2021-11-22 07:50:58
中学生数理化·七年级数学人教版(2021年6期)2021-11-22 07:50:58
中学生数理化·七年级数学人教版(2021年6期)2021-11-22 07:50:58
电子制作(2018年11期)2018-08-04 03:25:38
海峡科技与产业(2016年3期)2016-05-17 04:32:12
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
河南科技(2014年14期)2014-02-27 14:11:53
