
考虑高频数据V-I特性的电力负荷异常值自动识别系统
2022-01-20 04:06:38冯建宇
机械设计与制造工程 2021年12期
冯建宇
(陕西省地方电力(集团)有限公司,陕西 西安 710061)
我国智能电网发展迅速,接入用户数量庞大,电力系统中的电力负荷数据的特点由最初的量少、结构单一变为数量庞大、结构复杂。在智能配电网的日常运行中,电力调度会通过数据采集和分析对配电网历史数据进行处理,但是由于我国智能配电网结构错综复杂,会出现一些意外故障导致电力负荷异常,这些异常数据会降低调度决策的精准度,影响智能配线网的安全稳定运行,因此对电力负荷异常值进行筛选、剔除是配电网安全运行的重要保障。
对电力系统中的负荷异常值进行识别与筛选已经引起了相关领域学者的重视,很多专家也在这方面做出了很多成绩。文献[1]中主要利用改进K-means方法对电网中的负荷进行预测。该方法存在固有电能消耗规律,可以得到不同类型的曲线,但是在特定的环境和约束条件下是有效的,识别错误率和识别相似率较低。文献[2]中利用关联矩阵筛选负荷变化的影响因素,建立X-12-ARIMA模型,该方法可以得到特征分解部分后确定滞后期数,去除噪声提纯数据,但是没有考虑区域、使用者的差异,缺乏对具体数据的负荷预测,一般只对具体的负荷值进行预测,很少开展负荷分布预测,识别准确率较低。因此本文设计了一种考虑高频数据V-I特性的电力负荷异常值自动识别系统。
1 电力负荷异常值自动识别系统
1.1 系统硬件设计
在电力系统出现异常负荷时,需要及时对异常情况进行识别,因此有必要对电力系统中的高频数据V-I进行数字采样,也就是对负载启动前后的电压与电流进行数/模变换[3-4]。在本文设计的异常负荷自动识别系统中,需要考虑高频数据V-I的特性,因此在硬件结构中设计了电压采集器和电流采集器。由于V-I的数据波形图具有正弦性质,因此在信号数据处理的过程中,需要使用过零检测器,将采集到的电流/电压数值经过放大电路后,完成过零检测,再通过波形整形电路后,传输到单片机中[5-6]。
由于高频数据V-I具有信息量丰富、负荷设备保留完整的特性,因此将采集到的电压和电流经过电路处理后,能够得到系统能够识别的方波信号,但此时的方波信号与实际数值相比还存在一定误差[7-8],需要输入到单片机中进行脉宽的计算,至此完成系统的硬件设计。
1.2 系统软件设计
1.2.1数据预处理
由于在系统采集的数据中很多数据都是杂乱、冗余或不完整的,因此需要对高频数据V-I进行预处理,即对所得数据进行清理和标准归一化处理,从而为后期的识别工作提供处理依据[9-10]。首先需要对数据进行聚类分析,当负荷数据的总数为n时,其属性个数为p,采集数据之间的聚类方式可以用以下矩阵来表示:
(1)
完成数据聚类后,需要对数据进行清理。将经过聚类后的数据拟合成电力用户负荷曲线,观察曲线与正常负荷曲线的走势是否一致,读取电力用户负荷曲线的数据,如果与正常负荷曲线相比出现大段的曲线偏离、归零,则说明出现了电力负荷异常值。当上述情况出现时,若一条短时负荷资料中3条数据中的点是相似的,则识别并标记待测曲线中间位置的间断点,同一类曲线的横向趋势也是相似的,然后判断待测曲线的首位负荷点是否中断,若存在中断现象,则需标记负荷点,将中断点自动归并为突降点异常负荷类别,从而判断数据中的噪点。
1.2.2电力负荷异常值的识别
若想对异常负荷进行自动识别,需要对负荷数据进行聚类和预处理。负荷数据经过聚类后,能够生成负荷特征曲线,然后根据该负荷特征曲线得到带通矩阵和上下阈值。对于带通矩阵,首先整理智能配电网中负荷历史样本数据集,在聚类后,将数据集中的数据划分为几类,其中第i类样本的数据矩阵在识别时间段内的极值如式(2)所示:
(2)
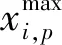
由于本文设计的系统考虑到了高频数据V-I特性,在负荷发生异常前的变换会存在一个时间滞后阶段,因此得到的稳态电流能够准确描述单一用电器的运行电流波形。在用本文设计系统进行训练时,需要设置提取波识别的种群规模,建立异常负荷数据识别决策树。该决策树是一种统计学习方法,其本质是通过建立初始决策树,计算其相应识别函数的损失函数,然后采用梯度下降法在其负梯度方向上依次建立一系列弱树,逐步优化预测函数,优化后称为强决策树。根据训练数据的相似度和加权组织,进一步引入基于综合相似度加权的综合损失函数,由此拟合单一用电器的V-I曲线,保证能够准确识别异常数据,至此完成考虑高频数据V-I特性的电力负荷异常值自动识别系统的设计。

图1 异常负荷识别流程
2 系统仿真实验
为了验证本文设计系统的有效性,在性能测试中针对系统的特点搭建系统测试环境,并在相同实验条件下利用现存的系统进行相同的测试,对测试结果进行分析与对比。
2.1 搭建系统测试环境
本文搭建的系统测试环境中,采用安装32位Windows10的PC,利用MATLAB软件进行仿真。在训练集数据选取中,选择某供电站在机械加工、餐饮行业、写字楼、冶金、商场等不同行业所统计的实际电能消耗数据,数据来源于每间隔30 min记录一次的自动抄表系统。将采集到的数据进行统一预处理,首先要去除数据中的噪声,并对缺失数据进行人工填补。由于本文测试中得到的负荷数据在拟合成曲线后,具有相似连续的特点,因此可以利用平均插值填补数据。
在实验搭建的电力负荷异常值自动识别系统内输入包括电力负荷状态和动作的数据特征,在电力负荷异常值自动识别系统中,对传输数据状态的识别主要基于传输数据循环平稳特征实现,输入数据产生的特征会表现出一定的周期性。当某一电力负荷异常值节点做出传输数据相应的动作后,考虑高频数据V-I特性,识别系统需要给出相应的反应,执行相应的感知识别动作。在本文设计的系统性能测试实验中,由于异常负荷数据在系统中的修正误差较大,为降低这种误差,需要将采集到的用电负荷数据进行归一化:
(3)
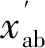

表1 负荷指标区间
在本文开发的系统中,调试的结果如图2所示。

图2 开发调试的结果截屏示意图
根据图2开发调试的结果截屏,建立的异常负荷数据识别决策树如图3所示。
在图3的决策树中,每一层节点中所包含的Ⅰ、Ⅱ、Ⅲ、Ⅳ表示样本分类的4个类别,其中的每一个类别分别对应系统中的一个异常数据检测模型。本文在系统测试中,主要选取误识别、漏识别的数据进行对比,并分别计算出不同系统的识别错误率,对结果进行对比。
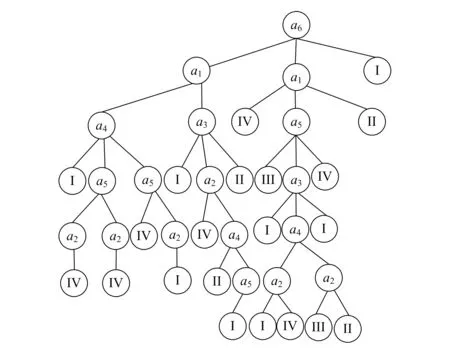
图3 本文开发系统的决策树示意图
2.2 测试结果与分析
在上述实验环境下得到的3种系统的检测结果见表2。

表2 实验结果对比与分析
在表2的3个系统的检测结果中,漏识别数量表示数据集中存在的异常负荷未被检测到的数量,误识别数量表示将正常负荷识别为异常负荷的数量。通过表2的对比结果可以看出,本文设计的考虑高频数据V-I特性的电力负荷异常值自动识别系统发生异常数据漏识别数量和误识别数量较少,识别错误率更低,说明其识别准确率与原系统相比得到了提升。
为了进一步验证考虑高频数据V-I特性的电力负荷异常值自动识别系统的效果和可行性,需要对识别系统的相似度这一指标进行分析,相似度Uh的计算公式为:
(4)
式中:Ag为识别列表;Hh为识别数量集合;Sz为识别项目集合。相似度越低,表明性能越好,利用式(4),对所提出的考虑高频数据V-I特性的电力负荷异常值自动识别系统识别相似度进行分析,结果如图4所示。
根据图4可知,本文所设计的电力负荷异常值自动识别系统识别相似率较低,均低于20%,而文献[1]系统和文献[2]系统的识别相似率较高,均高于60%,表明本文所设计系统具有更好的性能。

图4 不同方法识别相似度计算测试结果
3 结束语
本文针对现有电力负荷异常值自动识别系统中所存在的缺陷,设计了一种考虑高频数据V-I特性的电力负荷异常值自动识别系统,该系统的创新点是考虑高频数据V-I特性设置电力负荷异常值的识别,其中数据的聚类和预处理是异常负荷自动识别的基础,经过聚类后的负荷数据能够生成负荷特征曲线,根据不同的曲线则能够得到带通矩阵和上下阈值。由于本文所设计的系统主要是基于高频数据V-I特性来对电力负荷异常值进行识别,因此数据中所包含的信息量巨大,在下一步的工作中,需要结合一些机器学习等应用,在实际电网运行过程中优化识别过程,减少识别耗时。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
特别健康(2018年3期)2018-07-04 00:40:18
电子测试(2017年15期)2017-12-18 07:19:27
发明与创新(2016年26期)2016-08-22 03:23:28
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
电测与仪表(2016年6期)2016-04-11 12:06:38
智能系统学报(2015年4期)2015-12-27 09:38:39
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
