
基于STN-CRNN的自然场景英文文本识别研究
2022-01-20 03:45汪洪涛
武汉理工大学学报(信息与管理工程版) 2021年6期
汪洪涛,李 魁,潘 昊,丁 力
(1.武汉理工大学 网络信息中心,湖北 武汉 430070;2.武汉理工大学 计算机学院,湖北 武汉 430070;3.武汉尚赛光电科技有限公司,湖北 武汉 430206)
对自然场景下图片中包含的文本识别,可以广泛应用于无人驾驶中路牌信息的理解、车牌的检测识别、图片广告过滤、场景理解、商品识别、票据识别等领域。与传统的高质量文档图像(optical character recognition,OCR)[1]相比,自然场景下的图片脱离了图片场景和质量的束缚,面临着复杂背景的干扰、文字的倾斜与形变、字体大小不一、字体格式多样、多方向文本等众多挑战。从传统的OCR文本识别到智能驾驶中街道交通标志识别,两者具有一定的相似性,但自然场景下的文本检测与识别面临着更大的困难。虽然传统OCR输入的图片具有清晰度高、文本区域位置明显、文字风格尺寸一致等特点,但是在自然场景下图片的文字检测和识别依旧面临着较大的可变形与差异性,而且图片拍摄的角度变化大、不具有可控性,导致文字产生长宽比不一、大小差异大的形变。正是由于不可控的、复杂多变的影响因素,处理自然场景下的图片文字信息时,需要先检测文本区域位置,再对文本区域内容进行识别。作为识别过程中的第一步,文本检测的效果对文本识别的最终结果起到了至关重要的影响。
传统文本检测方法是通过手工设计的特征进行分类,该方法受限于人工设计的特征分类能力,因此文本检测效果在相当长的一段时间内没有取得重要突破。近年来,随着深度学习理论的不断发展,神经网络在各种计算机视觉任务中得到了广泛应用,利用深度神经网络来进行文本检测与识别成为主流方向。与传统手工设计特征提取然后分类的框架不同,深度学习通过中间隐藏层自动学习特征,随着卷积层的叠加,低层特征组合形成更加抽象的高层特征来进行分类,进而使计算机自动地学习相关特征,避免了繁琐且低效的手工特征选择。此外,深度学习的自动学习算法是多层表达的复杂算法,其自动提取的分类特征是由低层次特征组合而来的高层次特征。在自然场景文本检测领域,也相继出现许多基于深度学习的方法[2],这些方法通过深度学习网络模型自动获取文本特征,并依据这些特征对自然场景文本进行检测,与传统方法手工设计特征进行检测相比,基于深度学习的方法取得了令人瞩目的成绩。
1 文本识别方法
随着深度学习和卷积神经网络在文本检测领域取得的成绩愈加显著,基于深度卷积神经网络的文本检测方法在实际应用中越来越普遍[3]。目前,在自然场景下有多种文本识别方法。
1.1 基于候选框的文本识别方法
基于候选框的文本识别方法一般从Faster-RCNN[4](faster-recurrent convolutional neural networks)等目标检测方法出发,通过anchor的密集采样实现对目标位置的检测。如ZHONG等[5]提出了DeepText算法,对Faster-RCNN进行改进并用于文字检测,先用Inception-RPN提取候选的单词区域,再利用文本检测网络过滤候选区域中的噪声区域,最后对重叠区域进行投票和非极大值抑制;LIU等[6]提出了DMPNet(deep matching prior network,),该方法为应对自然场景文本多方位、透视失真,以及文本大小、颜色和尺度的变化,提出了改用紧凑的四边形而非矩形的方法对文本区域进行检测,同时提出一个光滑的损失函数对文本位置进行回归,比L1和L2损失函数具有更好的鲁棒性和稳定性。DENG等[7]提出了基于CRPN (cascade region proposal network)的多方向文本检测方法,该方法不需要预先了解文本的形状,而是通过基于顶点的CRPN来预测文本区域的位置。CRPN生成的候选框有几何适应性,因此对任意方向和各种长宽比的文本区域具有较好的鲁棒性。
1.2 基于图像语义分割的文本识别方法
基于图像语义分割的识别方法是从全卷积神经网络的思想出发,将文本区域视为一种类别进行像素级别的分类。本质上,它将文本检测看作一种广义上的图像语义分割。此类方法一般利用图像语义分割中常用的全卷积网络作为基本骨架,从而进行像素级别的文本区域与分文本区域的标注,同时对文本区域边界框进行回归。HE等[8]提出了一种高性能的直接回归文本区域位置的检测算法DDRN,该算法通过回归预测偏移量得到文本位置的边界框。LYU等[9]提出了角点定位的文本检测算法,该方法结合了物体检测和语义分割这两种方法的思想,针对文本排列方向不确定和文本区域长宽比变化大的问题,先检测文本区域的角点位置,接着对角点位置进行采样和分组,进而得到文本候选区域的边框位置,然后利用全卷积神经网络对文本候选区域边框按得分进行排序,最终通过非极大值抑制处理得到检测结果。
1.3 基于CRNN的文本识别方法
在传统的深度卷积神经网络(deep convolutional neural networks, DCNN)[10]模型进行文本识别时,通常是使用标记的字符图像进行训练,对于每一个字符有一个对应的预测输出,字符与字符之间没有任何上下文关系,这种方法需要训练出一个强健的字符检测器来识别每张图片中出现的字符。还有一些方法是将字符图像识别视作图片分类问题,对于每一个图片中出现的单词,为其分配一个标签与之对应,会有超过9万个单词的情况出现。这些方法对于序列对象的识别较难,如生活中常见的乐谱、文字、笔迹等,它们之间的组合方式复杂多变,数量庞大,基于DCNN的系统很难应用在序列识别任务中。因此,SHI等[11]提出了CRNN(convolutional recurrent neural network,)模型,解决了可变长度序列下的识别问题,不仅适用于文本识别领域,还适用于其他的序列数据识别。
CRNN算法网络结构可以分解为卷积层、递归层和转录层3个部分,通过最底层的卷积神经网络(convolutional neural networks, CNN)直接读取输入图像,自动从里面提取文本特征,在递归层主要是利用到了循环神经网络(reursive neural network, RNN)的“记忆”性,建立一个序列到序列的模型,对卷积层提取到的特征进行预测,之后输出到顶部的转录层,转录层再将前面预测到的特征分布转换为序列标签,通过连接时序分类(connectionist temporal classification, CTC)解码找出对应标签概率最大的字符,然后进行输出[12]。通过CRNN网络架构进行文本识别有以下优点:①可以不用逐个对字符进行标注,完全可以对整个序列文本进行识别;②没有序列长度的限制,只需要输入文本图片和与之对应的序列标签即可;③通过CNN和RNN可以直接由输入图片得到序列标签,无需进行字符分割、尺度归一化等数据预处理操作;④相比于其他文本识别模型,参数更少且有效。
2 优化的CRNN自然场景文本识别方法
由于传统的DCNN模型只对固定维数的输入和输出进行操作,无法应用于可变长度标签序列的文本识别问题。笔者采用优化的CRNN模型,对修正后的图像进行文本识别,同时对其中编码器网络架构进行优化,替换了文本序列特征提取网络,将空间转换网络(spatial transformer network, STN)[13]与CRNN整合起来,设计新的损失函数,并对实验细节进行了优化。
2.1 编码器网络优化
在CRNN中,主要的网络架构是由编码器网络中CNN+RNN组成的,CNN网络配置是基于VGG-VeryDeep体系结构的,RNN使用的是双向长短时记忆循环神经网络(Bi-directional LSTM,BiLSTM),为了能够适用于英文文本的识别,在第三层和第四层的最大池化层采用的是1×2的矩形窗口代替传统的2×2池化,这能产生更长的特征序列以便识别更狭小的字符,如“L”和“l”这种字符。此外,第5层和第6层使用了批尺度归一化层,用于缓解因CNN和RNN结合起来导致难以训练的问题。在输入网络前,对图像进行预处理操作,将其缩放到相同的高度,输入到CNN中提取特征序列,然后从中提取特征向量,根据CNN的平移不变性,特征向量的生成也是从左往右的,最后将生成的特征向输入到RNN中进行序列建模,继续提取文本的序列特征,输出特征分布,给后面的CTC进行解码。
编码器接受输入的图片,通过CNN将之转化为特征向量W×H×D的形式,在CNN中经过卷积、池化和激活函数作用于图像中某一区域,最后提取出来的特征图在空间相对位置上是不变的,特征图的每个列向量都对应原图像中的一块矩形区域。
CRNN中CNN是基于VGG16结构的,为了更好地提取文本特征,将CNN中基于VGG特征提取网络替换为Resnet50,与STN中不同的是,这里对残差块进行了优化处理。在接近输入和输出之间有着更短的连接,可以使得CNN更为深入,且准确有效,故在每个残差单元引入了一个1×1的卷积,在它之后才是一个3×3的卷积,每个残差块中包含的残差单元个数分别为3、4、6、6、3。Res_unit_0是对输入图像进行处理的模块,在之后两个残差块中,采取步长为2、padding为2对特征图进行采样提取特征,最后3个残差块padding改为1,使得在水平上不降低分辨率,区分相邻图像之间的特征,具体配置如图1所示。
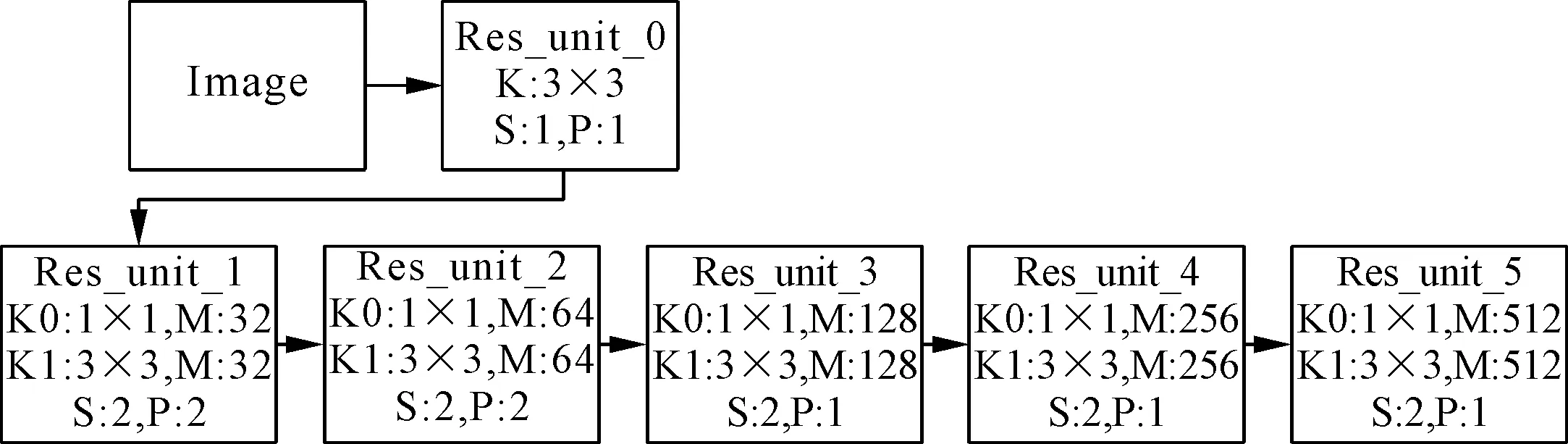
图1 残差块单元配置
训练过程中,引入STN后的模型基于Resnet50和VGG16的特征提取网络上单词识别精度变化,具体如图2所示。由图2可知,随着训练次数的增加,二者识别精度上升趋势基本一致,最后稳定不变,Resnet50相对于VGG16单词识别精度更高,故笔者选用Resnet50作为特征提取网络。
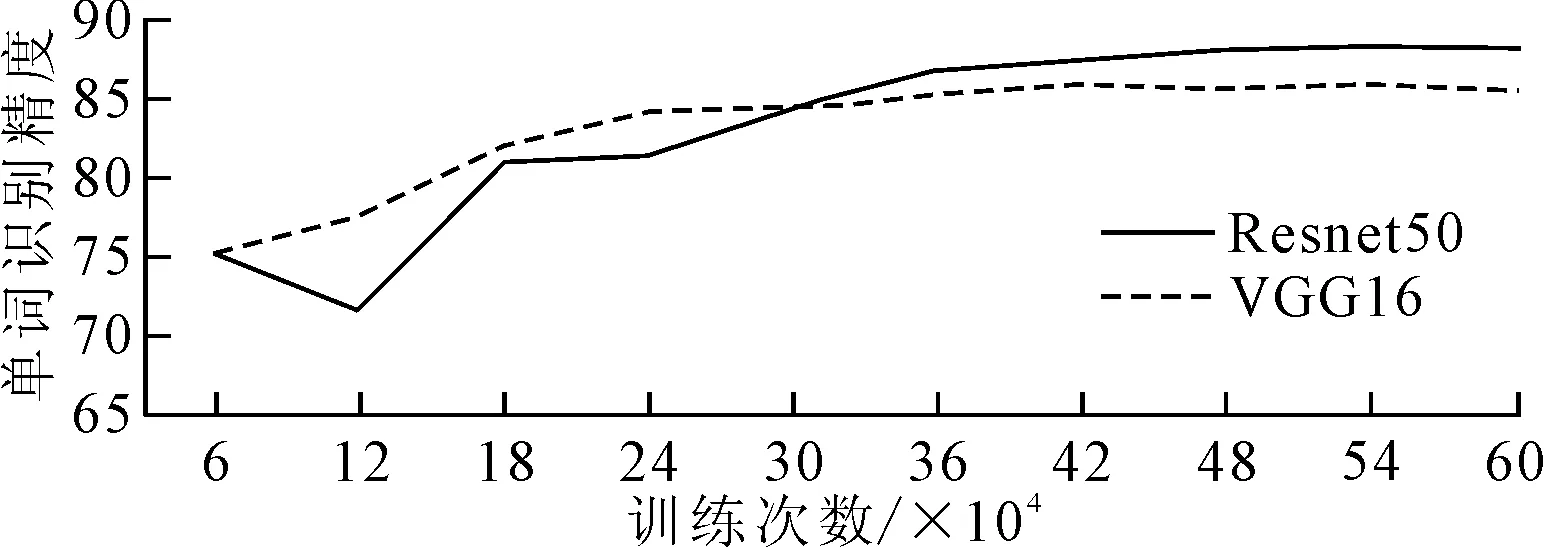
图2 Resnet50和VGG16单词识别精度变化
2.2 CTC损失函数设计与融合
CRNN中对于RNN的使用采取的是BiLSTM结构,并引入残差连接的方式,可以让上下文的信息传递到深层,通过将LSTM的起始输入信息和输出信息相加,构成了双向残差长短时记忆网络(residual Bi-directional LSTM, resBiLSTM),使得在CNN中提取出来的特征能够更好地和BiLSTM层结合,同时也能学习到复杂序列数据中的上下文信息。将CRNN网络架构(VGG16+BiLSTM)和改进后的网络架构(Resnet50+resBiLSTM)在Synth90k和SynthText进行训练。
利用CNN-resBiLSTM得到预测标签序列yt后,需要通过yt找到它所对应的概率最高的输出标签序列。一般在使用Softmax计算损失值时,需要yt中每一个字符对应着原图像的位置和标签信息,但实际情况下由于样本图片中字体大小、样式、背景等的复杂性,使得输出的标签序列并不能一一对应上每一个元素字符,因此使用CTC解码器来完成。
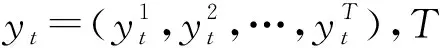
(1)
其中,l∈B-1(m)表示所有经过B变换之后为m的路径l。
利用CTC原理设计训练时的损失函数,定义训练集X={Ii,li},其中Ii为识别网络中的输入图片,li为对应的groundtruth,通过负对数似然函数(negative log-likelihood,NLL)作为识别模型的损失函数,如式(2)所示。
(2)
其中,yi为由编码器中CNN和RNN产生出来的标签序列。损失函数能够直接从输入图像Ii和对应的groundtruth中计算loss值,可以减少在图片上的人工标注信息,使得每对图像-标签数据能够在这个识别网络中进行训练,对于序列数据的识别具有很大的帮助。将STN修正网络与优化的CRNN网络结合起来,融合STN与CTC损失函数,形成一个端到端的文本修正与识别的模型,融合后的损失函数如式(3)所示。
(3)
结合修正网络与识别网络进行同步训练,直接输入训练集中的图片,经过修正网络处理,然后进入识别网络,输出识别结果,不需要中间过程,很大程度上简化了工作量,提高了文本识别效率。
3 实验结果与分析
自然场景下的文本识别常用的评判标准是 ICDAR上使用的两种:①平均编辑距离(average edit distance,AED),是指输入任意两个字符串,计算其中一个字符串变动到另外一个字符串这一过程中需要的最少编辑操作次数,编辑操作可以是替换、插入或者删除字符,计算出来的编辑距离越小,则两个字符串的相似程度越大。如字符串s1为“sstce”,字符串s2为“state”,将s1转换成s2时,删除s1中一个‘s’,将第一个‘c’替换为‘a’,然后插入一个‘t’,这两个字符串的编辑距离就为3。②单词识别正确率(word accuracy,WA),其计算方法如式(4)所示。

(4)
3.1 数据集
选取SynthText90k和SynthText作为训练数据集,选取SVT、IIIT5K和ICDAR2013作为测试数据集,3种数据集对比如表1所示。
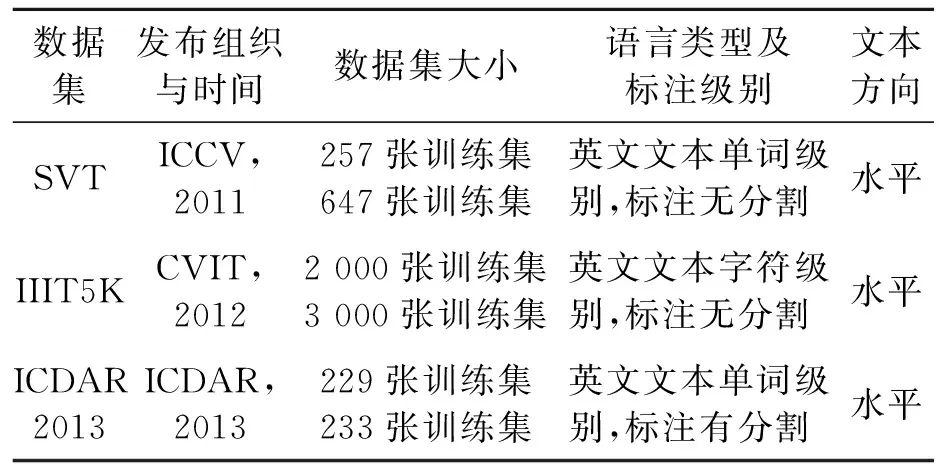
表1 SVT、IIIT5K、ICDAR2013数据集对比
3.2 网络配置与模型训练
对网络的主要部分CNN和RNN进行结构的改进。CNN上主要是利用了Resnet50进行文本特征提取,主要由6个残差块组成,其中第一个是对输入图片进行预处理操作,其余每个残差块由若干个1×1和3×3的残差单元组成,每个残差块中使用了批归一化(batch norm,BN)和ReLU激活函数处理,残差块的输入由上一个残差块产生的shortcut和经过卷积后的特征图相加组成。此外,第2个到第6个残差块的输出特征维度分别为32、64、128、256、512。残差块的内部结构如图3所示。
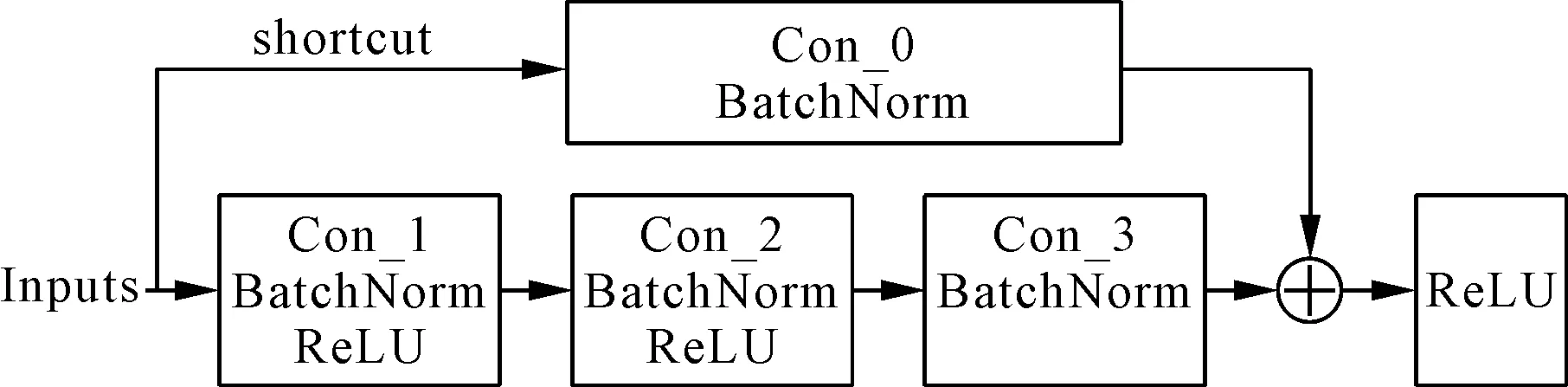
图3 残差块内部结构
在残差网络之后,是两层残差循环神经网络,每层包含256个resBiLSTM单元,两层LSTM的方向相反,当前输出与之前和之后状态有关,两层结合在一起组成BiLSTM结构。此外,每层通过一个快捷方式将BiLSTM的原始信息与其输出信息相加,进一步提取序列特征信息。优化后的CNN和RNN构成了Res_CRNN识别模型,结合编码器中网络结构信息,识别模型Res_CRNN配置参数,如表2所示。其中,s为步长,p为填充0的大小,conv为卷积核尺寸,括号后的数字代表每个残差包含的残差单元个数。

表2 Res_CRNN识别模型网络配置
训练时采用Synth90k和SynthText数据集,输入图片大小为640×205,batchsize大小设置为32,优化器采取Adadelta算法,其是改进的Adagrad算法,收敛速度较快,虽然其学习速率可以自适应,但通过人为设置的学习速率计划更有效,训练参数如表3所示。
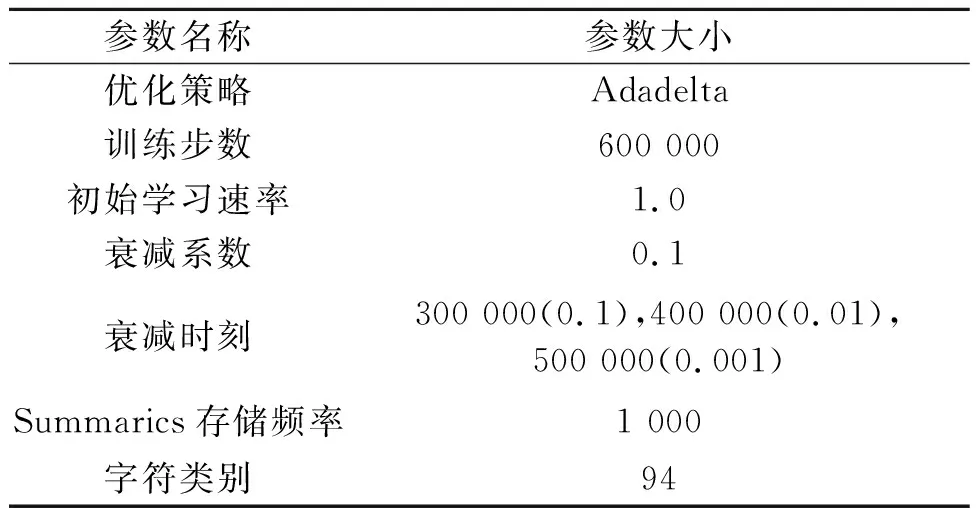
表3 训练模型的部分参数信息
3.3 经典算法比较
识别模型采用SVT、IIIT5K、ICDAR2013 3种数据集作为测试集进行验证。SVT数据集是Google从各个街景中获取的,测试数据集共有647张图片,这些图像分辨率低,可变性高,这样使SVT数据集在自然场景下的文本识别更具有现实意义。IIIT5K数据集主要包括门牌号、广告牌、海报等关键字作为搜索对象获取的图像,测试数据集采用了3 000张经过裁剪的单词图像和数字图像,这些图像背景复杂,文字样式变形,这对于自然场景的文本检测与识别更具挑战性和实际意义。ICDAR2013数据集是由文档分析与国际会议(ICDAR)建立的,检测与识别都有对应的训练集和测试集。本研究使用的测试数据集包括233张图片,都是经过裁剪过滤之后的图片,每张图片都包括顶点坐标、高度、宽度和文本内容。通过对CRNN网络优化和加上STN文本修正网络后的Res_CRNN模型进行对比分析,实验结果如表4所示,其中AED为平均编辑距离,WA为单词识别正确率。
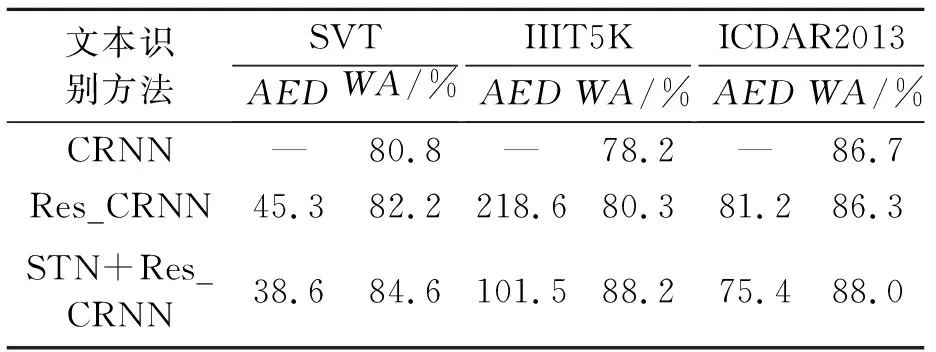
表4 3种识别方法在不同数据集上实验结果
由表4可知,改进后的识别模型Res_CRNN在SVT和IIIT5K上识别效果比CRNN分别高1.4%和2.1%,在ICDAR2013上差距不大;在Res_CRNN上加入STN文本修正网络后,识别精确度有了进一步的提升,在SVT、IIIT5K、ICDAR2013上识别精度分别提升了3.8%、10.0%和1.3%,平均编辑距离明显下降。
3.4 实验结果

图4 IIIT5K上STN+Res_CRNN识别效果
4 结论
通过采取STN文本修正方法,以及在改进的CRNN编码器网络结构的基础上,建立了Res_CRNN文本识别模型,该模型可在一定程度上提高文本的识别精度。但由于此次研究仅限于英文文本,未来可进一步完善设计方法,通过扩充训练集模型来提高对自然场景下各类文本的适应能力,以实现对多种语言类型的文本识别。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
