
基于迁移学习和GRU网络的新建小区负荷预测
2022-01-20 07:08孙志翔孙晓燕
电力需求侧管理 2022年1期
孙志翔,丁 彬,孙晓燕
(1.国网江苏省电力有限公司 连云港供电分公司,江苏 连云港 222000;2.中国矿业大学信息与控制工程学院,江苏 徐州 221116)
0 引言
目前,在国家电网公司所辖范围内,己经投入运行的配电变压器的总容量约为35亿kVA,如此大规模的配电变压器造成的电能损耗约为30~50 TWh/a,约占全电网中总发电量的3%和总损耗的30%。配电变压器损耗居高不下的原因有很多,例如延用高损配电变压器、过载、轻载、负荷不平均、功率区数低等,都会造成配电变压器能耗的增加等。配电变压器长期在轻载甚至空载状态下运行,大大影响了变压器的运行效率。全电网范围内轻载运行的配电变压器数量并不少,是供电企业节能降损工作的重点之一。所以,需要根据配电变压器的技术参数,结合不同时期的用电量与负载情况,加强对这些变压器的运行管理,确定其经济运行方式,以达到节约电能的目的。
变压器容量与负荷密切相关,要测算可释放的变压器容量,首先需预测已投入使用变压器及拟使用可释放容量变压器的新建小区的用电负荷。负荷预测在电力系统的规划和运行中起着重要作用。根据预测时间的不同,负荷预测可以分为4类:超短期负荷预测、短期负荷预测、中期负荷预测和长期负荷预测。
近年来,随着深度学习的发展,长短期记忆(long⁃short term memory,LSTM)网络在负荷预测中得到了成功应用。文献[1]提出了一种基于卷积神经网络和LSTM网络融合的负荷预测方法,并应用于孟加拉国电力系统,对电力负荷进行短期预测。文献[2]提出了一种基于堆叠长短期记忆网络的模型。在优化过程中,测试了数百个模型配置。将该模型的准确性与许多深度学习模型进行了比较,并与LTLF网络领域的相关工作进行了比较。文献[3]提出了一种考虑相关因素的变分模态分解和LSTM网络混合短时负荷预测方法,并采用贝叶斯优化算法进行了优化。文献[4]提出了一种LSTM网络,用于预测为期一年的月度电力需求时间序列。文献[5]提出了基于LSTM网络和轻梯度提升机的组合预测模型,采用实际负荷数据进行算例分析,结果表明所提方法能够有效结合两种模型的优点,在保留对时序数据整体感知的同时,兼顾非连续特征的有效信息,与其他模型相比具有更高的预测精度。
但是,上述研究都是基于待预测对象具有大量可利用历史数据的基础之上的。对于拟利用其他小区变压器可释放容量的新建小区,如何预测其未来需要的用电量,由于缺少任何先验知识,因此该负荷预测具有极大难度,传统的负荷预测方法不再简单适用。针对此,本文提出基于相似小区特征迁移的新建小区负荷预测方法。处理零样本新建设小区的中长期规划问题时,应以现有的周边成熟小区信息为依托,结合电网公司大数据平台,构建相似小区群体的数据网络,并利用迁移学习从数据网络中迁移出与新建设小区特征高度相似的数据信息及预测模型参数,最终完成新建设小区的中长期预测模型。不同于成熟小区的预测,新建设小区可供训练预测模型的数据量为0,成熟小区至少有几个月的历史数据,因此新建设小区的预测首先要实现从0到1,既而从1到多的过程,而完成从0到1的过程中,新建设小区的辅助信息必不可少。
鉴于此,针对新建小区可获得的信息情况,提出了相应的解决方法[6]。首先,分别针对数据完备情况下的新建设小区中长期预测,以及信息缺失情况下的新建设小区中长期预测,提出相应的预测方案。其中,数据完备是指:① 每户需在现有特征基础上提供个性化特征,为避免泄露隐私,可进行脱敏操作;② 所有小区的全部户主列表,即需要每家每户加上个性化特征的信息。为了完成新建设小区中长期的预测,分两步构建两个模型,分别对应于个体入住概率预测模型、起始预测模型、蕴含时序关系的中长期预测模型。要实现新建小区负荷的中长期时序预测,则需首先获取初始的与小区画像特征等因素相关的负荷数据。为此,入住概率预测和初始负荷预测采用基于因素关联关系的极端梯度增强算法(extreme gradient boosting,XGBoost)模型;基于该模型获得一定的基础数据后,再采用可以有效提取时序关系的门控循环单元(gated re⁃current unit,GRU)网络实现对负荷中长期的预测。
本文的主要贡献在于:① 零历史负荷样本下,分别针对新建小区在可获得充足的用户信息,以及无法获得用户隐私数据两种情况下的负荷预测,给出了基于特征相似度的算法框架;② 针对零初始负荷数据但又考虑负荷时序性特性的情况,提出了融合XGBoost和GRU的联合负荷预测策略。
1 数据完备情况下的新建小区中长期负荷预测
1.1 数据迁移
由于没有历史数据的支撑,处理零样本问题往往需要从提供的数据中进行迁移学习。这里采用客观分析,对小区画像,从所在区、占地面积、建筑面积、交房时间、户型、楼栋总数、总户数、车位数、装修状况、容积率、绿化率、均价及物业信息等方面确定小区个性化特征。迁移与新建设小区信息从房产咨询网站上各个小区的基础建设信息中获得。居民用电中,测算变压器容量时主要基于用户数量和建筑面积。此外,还需要考虑公共用电相关因素,因此这里选用建筑面积、户型、楼栋总数、总户数、车位数、装修情况、容积率、绿化率、均价为主要特征α。令α=[a1,a2,...,a9],并采用余弦相似度作为衡量成熟小区与新建设小区之间相似关系的技术手段,选择相似度高于95%的小区作为相似小区,并迁移其相关数据进行新建小区入住率和负荷的预测。特征指标如表1所示。

表1 小区间相似度衡量特征指标Table 1 Community similarity measure characteristic indexes
1.2 个体入住概率预测模型
在获取到与新建设小区特征相似度达到阈值的某小区样本集后,对于待预测的新建设小区而言,由于有足够完备的户主个性化信息,因此可以通过成熟小区的数据量训练一个入住概率预测模型,将新建设小区的各户户主信息输入,从而预测每户入住概率,为下一步用电量的估算做铺垫。
所需完备特征为用户编号、用户名称、用电地址、户主年龄、户口人数、户主职业、个人征信、电费缴纳方式、行业分类、用户类别、合同容量、运行容量、供电电压、定价策略、用电性质、月份等。通过分析,将已有特征整理为户主年龄、户口人数、户主职业、个人征信、电费缴纳方式、行业分类、用户类别、用电性质、季节、合同容量、供电电压、年、月份、年月差距。特征指标如表2所示。样本输入集如下所示

表2 样本集特征指标Table 2 Sample set characteristic indexes

将成熟小区的以上特征数据集作为训练集,完成XGBoost模型的训练,新建设小区的用户特征数据集作为测试集,测试集输入如下所示

1.3 起始预测模型
对新建设小区而言,在没有历史数据的前提下,模型的构建无法包含变化规律。因此首先要完成新建设小区前两个采样点的负荷预测,为下面构建蕴含时序关系的预测模型提供时序依据。与1.2节类似,输入特征仍为户主年龄、户口人数、户主职业、个人征信、电费缴纳方式、行业分类、用户类别、用电性质、季节、合同容量、供电电压、年、月份、年月差距。样本输入集如下所示


1.4 蕴含时序关系的长期预测模型
与LSTM相比较,GRU精简了门控单元个数,从而提升收敛速度而不影响精度。GRU结构如图1所示,只有两个门控结构:重置门rt与更新门zt。它将遗忘门和输入门合并为重置门,只保留遗忘功能,控制上一时刻状态信息的遗忘程度。重置门的值越小,表明历史信息遗忘的比例越大。更新门则决定前一时刻与当前时刻的信息结合程度,更新门的值越小,说明模型的输出更贴近前一时刻即上一隐层状态,同时配合合并细胞状态与隐藏状态达到简化模型结构的目的。模型表示如下

图1 GRU结构图Fig.1 Structure chart of GRU
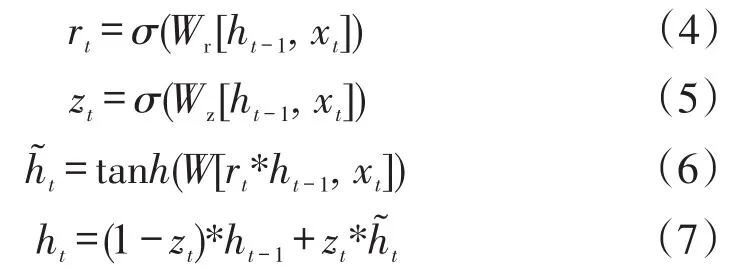
式中:ht为当前时刻的状态信息,维度由隐层节点数决定;σ为sigmoid激活函数;•为矩阵乘法;[],为左右变量的连接;*为矩阵的哈达玛积;Wz、Wr、W分别为更新门、重置门与当前记忆的权重。
在求得两个月数据之后,为了加强相邻月份间用电量的联系,同时方便日后的数据接入从而实现模型更新,构造出的新建设小区负荷预测模型需要涵盖时序关系。因此首先对特征进行重新构造,加入历史负荷特征,特征指标如表3所示,然后采用GRU神经网络对训练样本集进行建模,GRU时间窗口参数为2,训练精度达到要求后,将预测出的新建设小区前两个月负荷值作为历史负荷特征d1,12、d2,12,构造出待预测点对应的如下特征,即

表3 样本集特征指标Table 3 Sample set characteristic indexes


图2 基于特征相似小区的新建设小区负荷预测模型Fig.2 Load forecasting model of newly constructed community based on similar characteristic community
采用该方法预测,显然需要获取大量用电用户的个性化信息,特别是户主年龄、职业、个人征信、家庭人口等[7]。实际应用时,这些特征难以获取,那么,小区入住率和负荷预测的精度难以保障,上述方法的实用性就受到了极大的限制。因此,本文进一步考虑部分用户个性化隐私数据缺失下的新建小区中长期预测模型的构建。
2 数据信息缺失情况下的新建小区中长期负荷预测
因为相较于数据完备情况下的负荷预测,信息缺失使现有数据潜在价值无法被充分发掘。其中最为重要的是仅提供整个小区部分用户的信息导致所有用户每月入住概率信息无法获取,所以上述方法不再适用。为了完成此情况下新建设小区中长期的预测,需要重新选择小区画像特征[8],进而选择相似小区,对其进行数据迁移,构造新建设小区用户样本。本节将分3步构建3个模型,分别对应于第一个月的XGBoost预测模型、第二个月的XGBoost预测模型、蕴含时序关系的GRU中长期预测模型。
2.1 第一个月的预测模型
同1.1节采用余弦相似度作为衡量成熟小区与新建设小区之间相似关系的技术手段,在获取到与新建设小区特征相似度达到阈值95%的某小区样本集后,对于待预测的新建设小区来说,第一个预测点的难度是最大的,在没有历史数据的情况下常采用经验法。由于新建设小区第一个月的用电个体数量无法得知,且用电规律也无法挖掘,所以随之而来的不确定性问题也是显而易见的,因此第二步着重解决新建设小区第一个月的预测问题,从已有数据入手,决定采用XGBoost作为第一个月的预测模型,参数如表4所示。

表4 XGBoost参数Table 4 XGBoost parameteres
迁移的样本集特征为用户编号、用户名称、用电地址、行业分类、用户类别、合同容量、运行容量、供电电压、定价策略、用电性质、月份等。通过分析将已有特征整理为行业分类、用户类别、用电性质、季节、合同容量、总容量、供电电压、年、月份、上房年、上房月份、年月差距。其中总容量为已有数据的最后一个月的全体用户合同容量之和,并认为最后一个月上房率为100%。项目的最终目的是求小区配变容量,总容量虽不同于此,但却紧密相连,因此加入总容量特征是为了能在没有历史数据的前提下挖掘个体与总容量的关系,通过模型训练作用于负荷,并在最后反馈至小区配变容量。样本集为

从新建设小区角度出发,预测第一个点时,输入特征如表5所示。没有历史数据,所以选取XGBoost模型进行样本集的训练,从而完成新建设小区第一个月的拟合。以作为训练集,根据两个小区相似性作为入住率相似性的衡量标准(新建设小区第一个月的会有哪些用户用电并不知道,仅知道每户居民及物业设施的登记信息),将样本集年月差距为零的月入住率与新建设小区的用户登记信息个数相乘,得到验证样本数m,并从用户登记信息中随机挑选m条数据,从而确定验证集

表5 样本集特征指标Table 5 Sample set characteristic indexes

2.2 第二个月的预测模型
在进行第二个月的预测时,采用预测第一个月时的思想。考虑新建设小区第一个月的用户群体信息接入及更新,依据成熟小区的入住率构造出新建设小区的第二个月的用户信息。与此同时,总容量更改为实时总容量,即输入特征的月份的容量之和,并同样采取XGBoost模型,参数如表6所示,样本集为

表6 样本集特征指标Table 6 Sample set characteristic indexes


式中:m为新建设小区第二个月经构造后得到的用户个数。
2.3 蕴含时序关系的中长期预测模型
在求得两个月数据之后,为了加强相邻月份间用电量的联系,同时方便日后的数据接入,从而实现模型更新。构造出的新建设小区负荷预测模型需要涵盖时序关系,并且用户数量根据成熟小区的入住率进行构造更新,特征如表7所示。然后采用GRU神经网络对训练样本集进行建模,参数如表8所示,再利用迁移学习将预测模型参数迁移,并加入新建设小区样本进行训练。由于新构造样本没有历史数据,仍要采用2.2节所示模型进行预测处理。其中GRU时间窗口为2,输入为待预测点前两点对应的特征,即

表7 样本集特征指标Table 7 Sample set characteristic indexes

算法框架如图3所示。

图3 数据缺失时新建小区中长期负荷预测模型Fig.3 Medium⁃and long⁃term load forecasting model for new community when data is missing
3 实验结果
由于采集的用电数据存在丢失和异常的问题,因此在进行模型预测前对数据进行预处理,包括利用插值对丢失的数据进行填充、预测前针对异常值进行剔除、为消噪对数据进行分解或滤波。针对数据波动比较大的问题,可以对居民先聚类,然后将用电行为相似的用户归为一类,对聚类后的各类用户单独预测,然后聚合累加,从而提高居民用电负荷的预测精度。
W小区用电总负荷趋势图如图4所示,纵坐标中的每个点为W小区每两个月的总用电负荷(小区物业管理用电、城镇居民用电累加和)。该折线图统计分析了小区2020年1月至2020年11月的小区用户负荷数据。在统计期间,小区入住率由0.62%上升为33.07%,可较直观看出小区前期的用电负荷变化趋势,该期间用电总负荷整体呈上升趋势,其中2020年3月、2020年9月为两个用电极大值点。

图4 W小区用电总负荷趋势图Fig.4 Total electricity load trend chart of W community
由图4可知,随着入住率的提高,小区整体负荷稳步上升,但由于季节特点,在夏、冬季用户用电需求更大。构成折线的6个数据点间标准差为40035.44,因此波动性较大,与趋势图分析结果一致。
对所设置模型参数进行反复多次调整优化,选择了使得训练误差(损失函数)最小的算法参数设置,具体如表4、表8、表9所示。

表8 GRU参数Table 8 GRU parameteres

表9 XGBoost参数Table 9 XGBoost parameteres
以连云港市W小区为例,预测该小区2020年1月—2022年11月的用电情况,其中2020年1月—2020年10月小区有实际用电负荷数据,结果如表10和图5所示。

图5 新建设小区负荷预测结果Fig.5 New construction community load prediction result
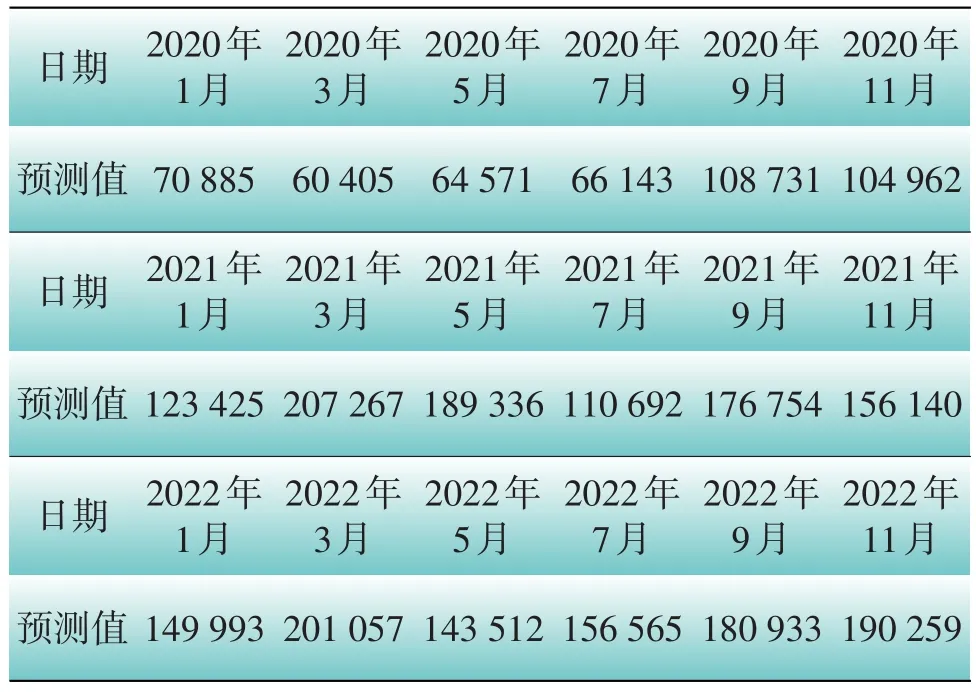
表10 新建设小区负荷预测结果Table 10 New construction community load prediction result diagram kWh
为了说明预测结果的精度,这里采用式(14)计算2020年1月—2020年10月期间预测值yt*和真实值yt之间的偏差,结果为13.8,即这10个月预测精度为86.2%。

而由表10及图5可以看出,在小区建设初期,由于入住率相对偏低,小区整体用电量较小;到2020年9月,小区用电量开始有明显增长趋势,原因是小区入住人口可能有所增加;2021年1月至2021年3月,小区用电量急剧增加,这个时段恰好是寒假和春节期间,用电量大量增加也是合理的;随后用电量开始有所回落,但是,2021年6、7月的用电量明显比4、5月低的多。此外,2022年5月的预测用电量比2021年5月减小了约4.5万kWh,原因可能是预测出现了较大偏差,如何评价无参考数据的预测可靠性是需要进一步考虑的问题。
4 结束语
本文分别在两种情况(数据信息完备和数据信息缺失)下完成对新建设小区的中长期负荷预测。首先,利用迁移学习的思想迁移出与新建设小区特征高度相似的特征数据集。其次,利用特征数据集作为训练集完成XGBoost回归模型的训练。然后,采用GRU神经网络对训练样本集进行建模,当模型达到预测精度时,从而完成蕴含时序关系的新建设小区的中长期负荷预测。最后,以W小区为例,得到了该小区在2020年1月—2022年11月时间段内的负荷预测结果。
在实际应用中,若能获得较为全面的信息,即表2、表3中相关的特征数据,则还需进一步分析这些特征与入住率和用电负荷间的相关性,根据相关性设计相应的预测模型;此外,由于该预测是针对无历史可验证数据的小区进行预测,如何对预测结果精度进行评价也将是需要进一步研究的内容。
猜你喜欢
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
长江大学学报(自科版)(2021年6期)2021-02-16
中学生数理化·中考版(2020年12期)2021-01-18
发明与创新·小学生(2020年4期)2020-08-14
活力(2019年15期)2019-09-25
小学生必读(中年级版)(2018年10期)2019-01-04
消费导刊(2018年8期)2018-05-25
发明与创新·小学生(2016年4期)2016-08-04
燃气轮机技术(2014年4期)2014-04-16
