
动态人脸图像序列中表情完全帧的定位与识别
2022-01-19 12:42司马懿易积政陈爱斌周孟娜
应用科学学报 2021年3期
司马懿, 易积政, 陈爱斌, 周孟娜
1.中南林业科技大学人工智能应用研究所,湖南长沙410004
2.中南林业科技大学智慧物流技术湖南省重点实验室,湖南长沙410004
3.中南林业科技大学计算机与信息工程学院,湖南长沙410004
近几十年来,人脸表情识别已成为计算机视觉领域的研究焦点之一。研究者在不同的领域开发出了许多基于人脸表情识别的应用,例如:人机交互[1],精神健康状态分析[2],以及驾驶辅助系统[3]。这些应用涉及人类生活中的很多方面,并能够提高人们的生活水准。著名的心理学家Paul 根据人类心理状态变化提出将人脸表情分为6 类基础表情,主要包括生气、厌恶、恐惧、高兴、悲伤、惊讶。这项工作规范了人脸表情识别的研究种类,无论个体的种族和文化差异有多大,这6 类基础表情都能大致反映出人类的情绪状态。现阶段人脸表情识别主要分为两大方向:基于静态图像的人脸表情识别与基于动态序列的人脸表情识别,前者注重对单幅静态人脸表情图像的识别,重点分析静态图像中的空间域信息;后者不仅考虑静态的空间域信息,而且还考虑人脸表情序列的时域信息,利用连续表情序列时域上的动态信息来挖掘相邻序列帧之间的隐藏信息。然而,大多数基于动态序列的人脸表情识别方法并未考虑如何精准提取人脸表情序列。不同的表情序列会给模型带来不同的输入数据,如何获得精准的面部表情序列数据已成为一个值得关注的问题。
为了更准确地获得人脸表情序列以开展面部表情识别研究,本文提出基于嵌入网络的人脸表情序列的自动定位模型,该模型通过提取具有最大表情强度的完全帧,从而获取从起始帧开始至完全帧结束的人脸表情序列,最后利用两种预训练卷积神经网络对完全帧进行人脸表情识别,以此验证定位的表情完全帧具有代表性。
1 相关工作
现阶段人脸表情识别工作分为两个方向:基于静态图像的人脸表情识别与基于动态序列的人脸表情识别。与静态图像的人脸表情方法识别重点关注图像的空间域信息不同,基于动态序列的人脸表情识别方法还关注了时间域信息,因此现阶段大多数人脸表情识别研究方向主要基于动态序列的人脸表情识别。文献[4] 提出一种基于卷积神经网络(convolutional neural network, CNN)的人脸表情序列识别模型,该模型使用多层处理单帧表情卷积神经网络进行特征融合,最后对融合特征进行分类以实现人脸表情序列识别。文献[5] 结合视觉几何组网络(visual geometry group net, VGGNet)与长短期记忆(long short term memory,LSTM)网络对人脸表情序列进行学习与识别。文献[6] 提出了一个多层级注意力模型用于对视频序列进行表情识别,建立了一个CNN 与LSTM 网络相结合的CNN-LSTM 网络来实现人脸表情序列识别工作。文献[7] 建立一个共享浅层模块来提取输入人脸表情序列数据的局部和全局特征,并对这些特征进行融合以实现人脸表情识别。以上研究文献并未考虑如何获取准确的人脸表情序列数据,然而人工筛选、标定的人脸表情数据很容易包含冗余表情帧,这将会降低基于人脸表情序列的面部表情识别模型的性能。
现阶段人脸表情序列研究主要采取手工标注特征以及机器学习方法。文献[8] 认为面部特征点的运动过程应该经历一段时间,即特征点从初始状态到峰值状态最后回归初始状态,因此提出采用手工标注的特征点来追踪面部表情变化过程以进行面部表情序列识别。但是该方法并未考虑到面部表情序列数据中受试者头部姿势的状态改变,导致该研究只能针对头部姿势不变的人脸表情序列数据进行识别。文献[9] 提出了一个基于慢特征分析(slow feature analysis, SFA)的复杂的峰值表情检测方法,该方法将输入的三维几何特征序列特征向量经SFA 投影后得到最缓慢特征,最后通过选取信号幅值变化最大的帧为峰值表情帧,但是该方法计算复杂度较高且未给出表情序列定位准确率。文献[10-11] 通过追踪由主动外观模型(active appearance model, AAM)标记的面部特征点间运动趋势,拟合序列帧之间各特征点变化曲线的斜率,从而完成人脸表情序列截取工作。
2 人脸表情序列完全帧定位与识别
2.1 图像预处理
基于图像的识别方法是基于图像序列识别方法的基础。图像序列识别时要对人脸表情序列逐帧进行处理,因此需要对各帧进行预处理操作,本文采用Dlib 库来完成人脸表情图像裁剪工作。
Dlib 库主要包括两个关键图像预处理操作工具:1)人脸特征点标记(shape_predictor_68_face_landmarks);2)人脸区域检测器(get_frontal_face_detector)。Dlib 输出的是人脸图像中的68 个面部关键特征点,其分布区域主要位于眼睛的外边缘、下巴的上部、眉毛、鼻梁以及嘴唇附近。经过人脸特征点标记器对人脸表情图像序列标记面部特征点后,人脸区域检测器将对已被标记特征点的序列帧进行裁剪操作,裁剪后图像尺寸统一调整为128×128,去除样本的部分背景信息,以防止这些信息对人脸表情识别工作造成干扰,人脸区域检测器最终的输出主要包括面部表情区域。图像预处理总流程如图1 所示。
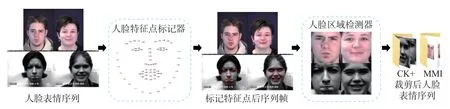
图1 图像预处理Figure 1 Image preprocessing
2.2 基于嵌入网络的完全帧定位模型
从人脸表情序列中准确地获取完全帧对人脸表情序列识别工作至关重要。现阶段人脸表情序列数据集大体分为两种表情变化类型:1)从平静表情状态开始,到峰值表情状态结束(例如:CK+ 数据集);2)从平静表情状态开始,经过峰值表情状态,最终回归平静表情状态。人脸表情序列的首帧(即起始帧)表情强度最低,经过一段变化过程达到具有最大表情强度的完全帧。
人脸表情序列识别研究的标准输入数据是从起始帧(序列第1 帧)开始至完全帧结束的序列图像。本文以面部图像序列起始帧为参考对象,来定位在欧氏距离空间中与起始帧距离最远的完全帧。由于人脸表情序列相邻帧间存在差异信息,本文采用三元组方法训练完全帧定位模型。在长度为M的第i个人脸表情序列ymi(m= 1,2,3,··· ,M) 中,嵌入网络利用Inception-ResNet v1 网络将序列帧逐帧嵌入到欧氏距离空间中f(y)∈R1,同时限制嵌入函数f(y),使其满足‖f(y)‖2=1。该模型利用平静帧yni作为参考项计算平静帧与人脸表情序列中的其他帧ymi之间的距离,从而选取出具有最大表情强度的完全帧yli。嵌入网络模型结构如图2 所示。
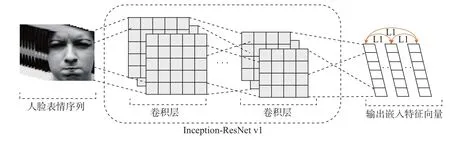
图2 嵌入网络结构Figure 2 Structure of embedding network
Inception-ResNet v1 网络主要包括3 种不同的Inception-ResNet 块(Inception-ResNet-A, Inception-ResNet-B, Inception-ResNet-C),2 种不同的Reduction 块(Reduction-A,Reduction-B)以及1 个Stem 块。ResNet 具有残差模块机制,这会使得网络模型随着网络深度加深而获取更深层特征信息的能力,因此将残差块机制嵌入到Inception 网络后能让Inception 架构以较低计算成本获取更高的网络性能,同时还能防止网络出现梯度消失与梯度爆炸的情况。Inception-ResNet v1 网络的具体结构如图3 所示。
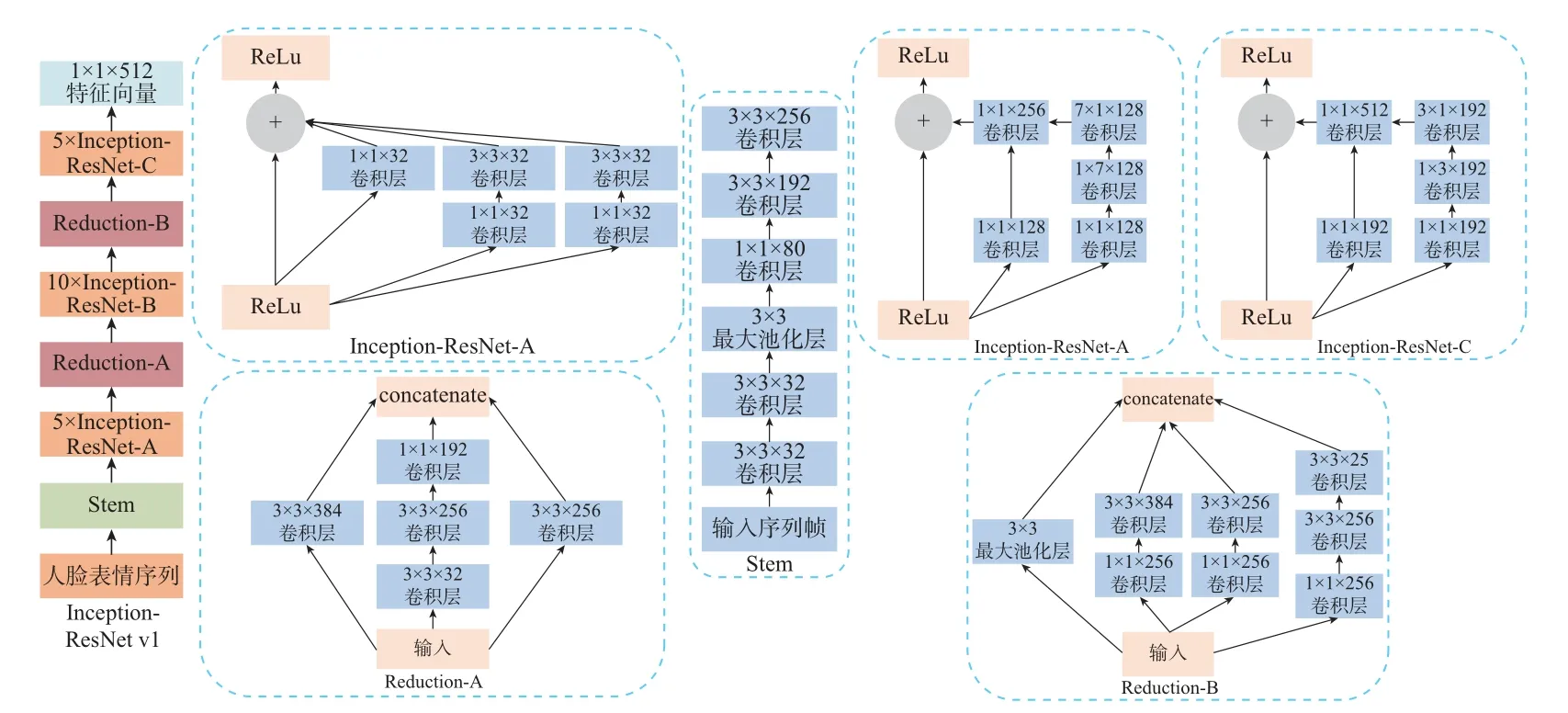
图3 Inception-ResNet v1 网络结构Figure 3 Structure of Inception-ResNet v1 network
在嵌入网络训练阶段中,人脸表情序列数据中的起始帧yni与完全帧yli被定义为正样本对,而其他序列帧ymi与完全帧yli被定义为负样本对,训练后的正负样本对间距需要满足以下条件:
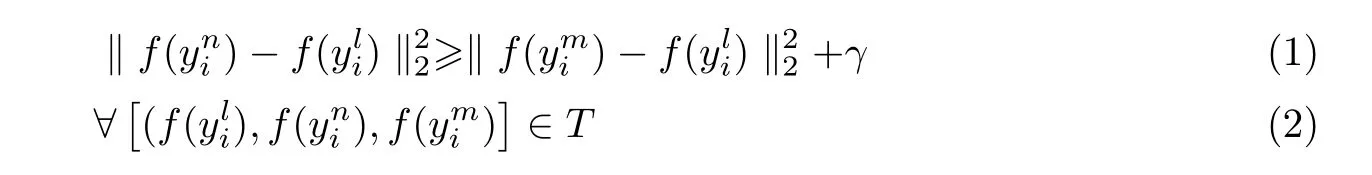
式中:γ为正负样本对距离的间隔阈值,其主要目的是保证定位的完全帧与平静帧之间的距离最大;T是该人脸表情序列中所有的三元组序列帧集合。嵌入网络优化目标函数Floss以实现损失的最小化,公式为
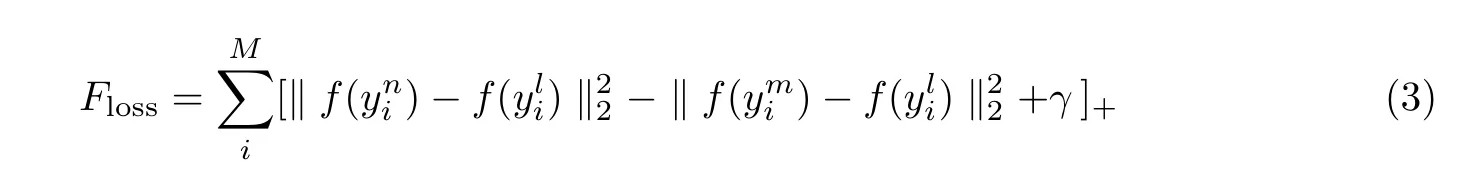
利用人脸表情序列获取各帧的特征向量后,计算各个特征向量之间的L1 距离(曼哈顿距离)并定位出与平静帧距离最远的完全帧。特征向量间的L1 距离计算公式为
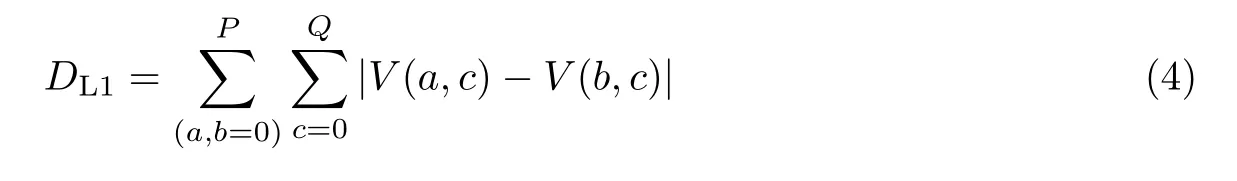
式中:V(a,c) 为特征向量,P为输入序列帧数量,Q为Inception-ResNet v1 输出的通道数。
2.3 基于预训练卷积神经网络的完全帧表情识别
为了验证完全帧定位工作的有效性,本文采用预训练卷积神经网络对完全帧进行人脸表情识别。VGG16 模型和ResNet50 模型在视觉分类任务上表现出色,因此本文选择加载来自ImageNet 数据集预训练权重的VGG16 模型与ResNet50 模型对完全帧进行人脸表情识别。基于预训练卷积神经网络的完全帧表情识别流程图如图4 所示。
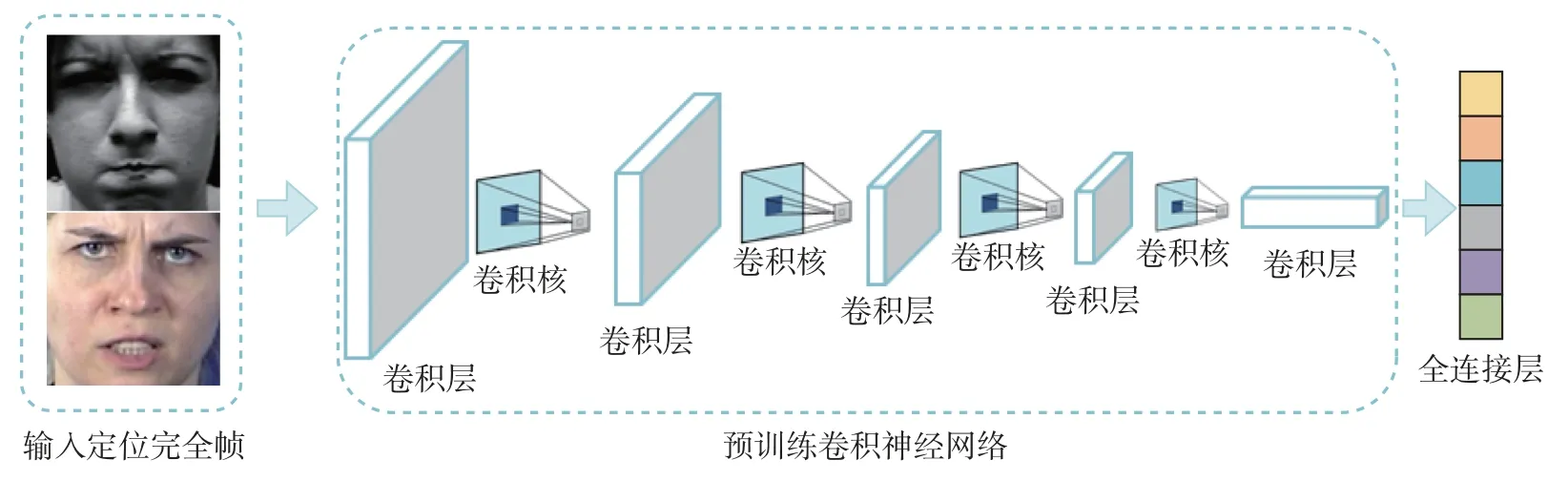
图4 完全帧人脸表情识别模型Figure 4 Fully frame facial expression recognition model
VGG16 模型主要包括13 个卷积层、3 个全连接层以及5 个最大池化层,其中16 个权重层(13 个卷积层与3 个全连接层)加载了由文献[12] 提供的在ImageNet 数据集上预训练后的权重参数。ResNet50 主要包括49 个卷积层、1 个全连接层层、1 个最大池化层、1 个平均池化层,其中50 个权重层(49 个卷积层与1 个全连接层)加载了由文献[13] 提供的在ImageNet 数据集上预训练后的权重参数。
3 实验结果与分析
3.1 实验数据集与参数设置
本文在两个广泛使用的人脸表情序列数据集(CK+, MMI)上进行了实验。
CK+ 数据集由来自123 位受试者所采集的593 个人脸表情序列组成,该数据集人脸表情序列的帧长范围为13~60 帧。CK+ 数据集采集于实验室环境下,该数据集中的每一个人脸表情序列都代表了7 类表情(生气、恐惧、厌恶、高兴、悲伤、惊讶、蔑视)中的某一类人脸表情。
MMI 数据集由来自32 位受试者所采集的236 个人脸表情序列组成,其人脸表情序列的帧长范围为20~120 帧。MMI 数据集采集于实验室环境下,该数据集每一个人脸表情序列都代表了6 类基础表情(生气、恐惧、厌恶、高兴、悲伤、惊讶)中的某一类人脸表情。
本文在2 个阶段的实验中都采用了迁移学习,加载预训练权重能够加快模型的收敛速度。在第1 阶段中,嵌入网络选择加载在CASIA-WebFace 人脸数据集上预训练的Inception-ResNet v1 权重参数,γ设置为0.15,模型训练集迭代次数为500。在第2 阶段中,采用加载ImageNet 预训练权重的VGG16 和ResNet50 作为分类网络进行对比试验,在VGG16 模型中采用动量随机梯度下降函数作为优化器,其中动量设置为0.85,学习率设为1×10−4;在ResNet50 模型中采用Adam 函数作为优化器,其中学习率设为1×10−3,模糊因子epsilon设为1×10−8,beta_1 设为0.9,beta_2 设为0.999。VGG16 模型与ResNet50 模型训练集迭代次数都为300。此外,VGG16 模型和ResNet50 模型的网络卷积层加载了在ImageNet 数据集上预训练的权重进行参数初始化。所有实验都在Keras 平台下进行。
3.2 完全帧人脸表情序列定位实验
在CK+ 数据集中,人脸表情序列情感状态由平静状态开始以峰值状态结束,因此取每一段人脸表情序列的最后一帧作为真实完全帧yg。在MMI 数据集中,人脸表情序列情感状态由平静状态开始经过峰值状态最终回归平静状态,因此取每一段人脸表情序列的中间帧为真实完全帧yg,邀请了3 位研究领域内教授进行投票,选取票数最高序列帧为真实完全帧。将定位的完全帧yl与真实完全帧yg之间的帧间距定义为θ,公式为

式中:numy为帧在人脸表情序列中的帧位置数。由于在人脸表情序列中逐帧间表情强度的增幅与减幅较微小,临近帧的表情强度差异无法通过肉眼进行分辨,于是本文定义相邻帧与完全帧在以下两种距离范围内同样具有情感代表性,条件如下:
条件1当θ≤1 时,即完全帧定位成功;
条件2当θ≤3 时,即完全帧定位成功。
在表1 的CK+ 数据集定位实验结果中,满足条件1 背景下的7 类表情完全帧定位平均准确率达到了94.12%。其中悲伤表情准确率为92.85%,表明有4 个样本定位的完全帧与真实完全帧之间的帧差超过了1 帧;同时恐惧表情获得了最高的识别准确率96.00%,这表明有2个样本定位的完全帧与真实完全帧之间的帧差超过了1 帧;蔑视表情的完全帧定位准确率最低为91.67%,这表明有3 个样本定位的完全帧与真实完全帧之间的帧差超过了1 帧。满足条件2 背景下的7 类表情完全帧定位平均准确率达到了98.31%。其中恐惧表情达到100% 的定位准确率,表明该类样本定位的完全帧与真实完全帧之间的帧差在3 帧以内;其次生气表情达到了98.98% 的准确率,这意味着有1 个样本定位的完全帧与真实完全帧之间的帧差超过了3 帧;悲伤表情获得了最低的准确率96.42%,这表明有1 个样本定位的完全帧与真实帧之间的帧差超过了3 帧。
在表1 的MMI 数据集定位实验结果中,满足条件1 背景下的6 类表情完全帧定位的平均准确率达到了94.18%。其中生气准确率为92.00% 意味着有2 个样本定位的完全帧与真实完全帧之间的帧差超过了1 帧;恐惧表情获得了最高的识别准确率97.91%,表明有1 个样本定位的完全帧与真实完全帧之间的帧差超过了1 帧;高兴表情的完全帧定位准确率为94.73%,这代表有2 个样本定位的完全帧与真实完全帧之间的帧差超过了1 帧。满足条件2 背景下的6 类表情完全帧定位平均准确率达到了98.08%。其中生气表情与恐惧表情达到了100% 的定位准确率,意味着该类表情所有样本定位的完全帧与真实完全帧之间帧差在3 帧以内;惊讶表情准确率为96.77%,表明有1 个样本定位的完全帧与真实帧之间的帧差超过了3 帧。
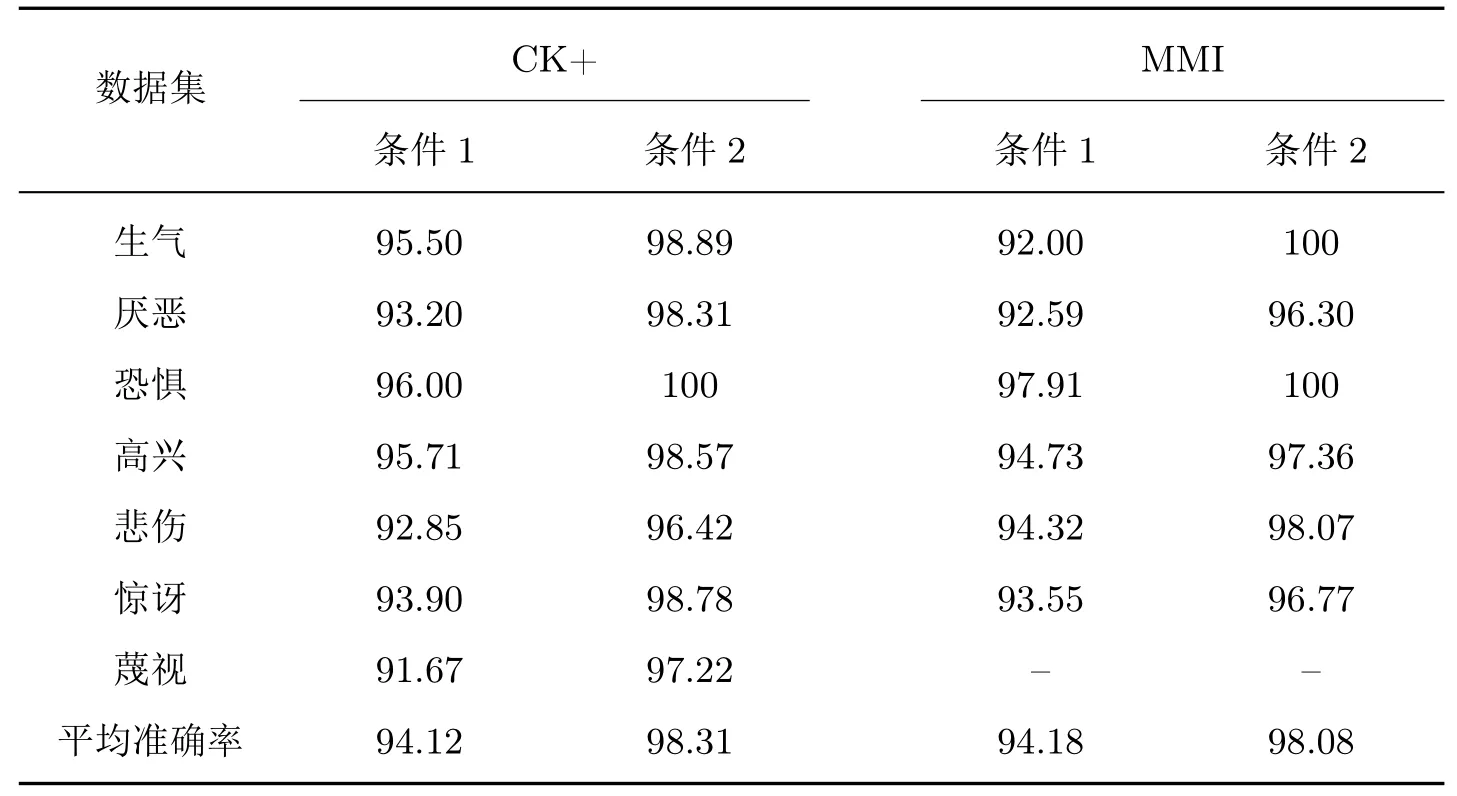
表1 CK+ 与MMI 数据集中的完全帧定位准确率Table 1 Accuracy of fully frame detection on CK+ and MMI databases %
3.3 完全帧人脸表情识别实验
本文利用嵌入网络在CK+ 和MMI 数据集上完成完全帧定位工作后,选取VGG16、ResNet50 两种模型对完全帧进行人脸表情识别。在CK+、MMI 数据集上两种模型的实验结果如表2 所示。图5 为VGG16 模型和ResNet50 模型在CK+数据集上实验的混淆矩阵。图6为VGG16 模型和ResNet50 模型在MMI 数据集上实验的混淆矩阵。

图5 CK+ 数据集上的人脸表情识别结果Figure 5 Facial expression recognition results on CK+ database
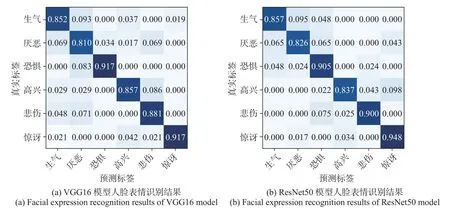
图6 MMI 数据集上的人脸表情识别结果Figure 6 Facial expression recognition results on MMI database
从表2 可知,在CK+ 数据集上的人脸表情序列定位工作表现良好,能够有效定位具有最大表情强度的完全帧。在CK+ 数据集中的两种加载了预训练权重参数网络模型的7 类人脸表情平均识别准确率达到96.41%,并且在两种模型的混淆矩阵中高兴和惊讶的识别准确率较高,这是由于上述两类表情特征明显,较其他类别表情的区分度更高;同时蔑视的表情识别难度较大,准确率较低分别为90.90% 和92.10%,这是由于蔑视表情个体的表征方式有所不同,且该类别样本个数较少,这导致训练数据较少以至于无法学习到更泛化的特征。
在MMI 数据集上两种模型的实验结果如表2 所示,在MMI 数据集上基于两种模型的6 类人脸表情平均识别准确率为87.55%。惊讶表情的特征更加明显且相对容易区分,其最高的识别准确率分别为91.70% 和94.80%。同时两种模型的厌恶表情识别准确率最低,分别为81.00% 和82.60%,从实验结果可知厌恶表情与生气表情容易混淆,高兴表情也有部分样本被误判为惊讶表情。MMI 数据集完全帧人脸表情识别的表现差于CK+ 数据集是由于MMI 数据集样本个体数量少且样本类别分布不均衡,另外佩戴的帽子、眼镜等装饰物也会对识别精度造成影响。本文利用VGG16 与ResNet50 模型对定位的表情完全帧进行情感识别,整体表现良好,并且ResNet50 表现更优,这是由于ResNet50 拥有的残差连接机制不再使用多个堆叠的层去直接拟合期望的特征映射,而是显式地利用它们拟合一个残差映射,这使得网络模型尽可能地避免因网络深度的加深而出现梯度下降和梯度爆炸的情况。
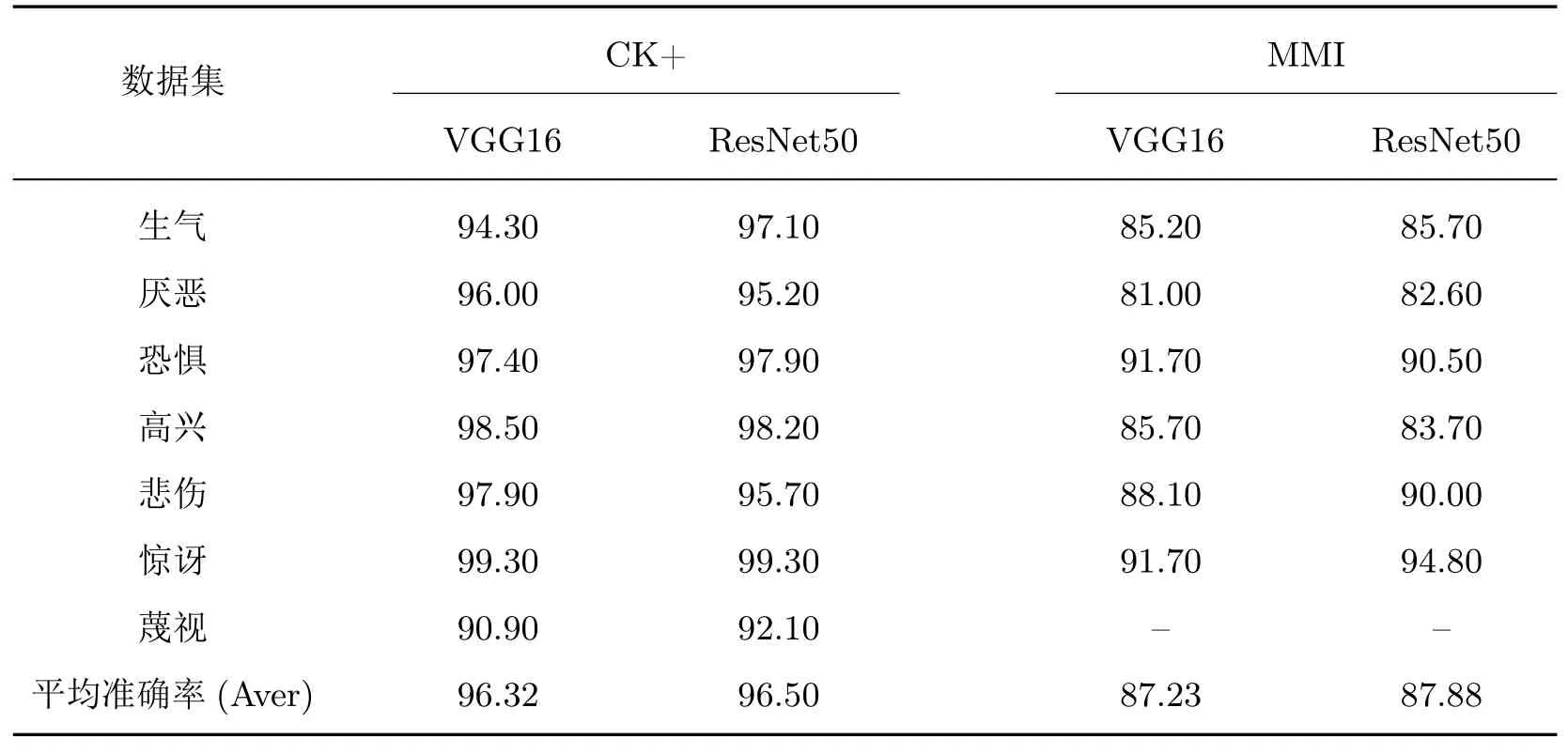
表2 在CK+ 与MMI 数据集上的完全帧情感识别准确率Table 2 Facial expression recognition of fully frame on the CK+ and MMI databases %
不同方法在CK+ 与MMI 数据集上的表情识别平均准确率结果如表3 所示,本文在两个经典卷积神经网络结构VGG16、ResNet50 上的完全帧人脸表情识别效果较好。与其他文献所提方法对比可知,嵌入网络能够有效提取人脸表情序列中具有表情强度最大的序列帧,这将有助于减少冗余人脸表情序列信息干扰,同时帮助面部表情识别人员更准确地获取规范的人脸表情序列数据。
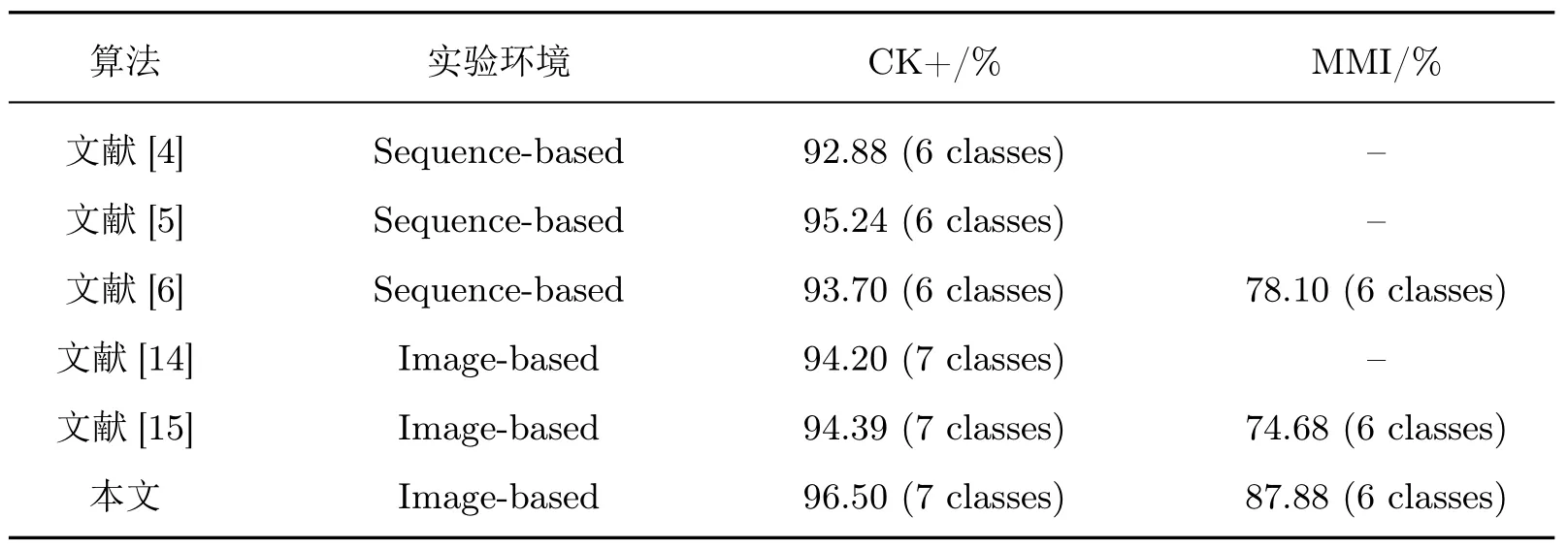
表3 不同方法在CK+ 与MMI 数据集上的平均识别率比较Table 3 Comparison of average recognition rate based different methods on CK+ and MMI databases
4 结 语
本文提出了一种基于嵌入网络的人脸表情序列定位模型,该模型能够将人脸表情序列帧嵌入特征向量并计算各特征向量之间的欧氏距离以获得具有最大表情强度的人脸表情帧,最终可以获得从起始帧至最大帧的人脸表情序列数据。实验结果表明该模型能够对具有最大表情强度的序列帧进行有效定位,这有利于规范基于动态图像序列的人脸表情识别研究的输入数据获取方式,减少冗余信息,而并非使用手工裁制或定义的人脸表情序列数据。在未来工作中,我们将考虑结合长短时记忆与注意力机制对规范的人脸表情序列数据进行识别以提高现有基于动态图像序列的人脸表情识别方法的整体性能。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年5期)2018-08-21
数学物理学报(2017年5期)2017-11-23
