
基于神经网络的中文语音识别技术
2022-01-19 11:50:54代伟,刘洪
四川师范大学学报(自然科学版) 2022年1期
代 伟,刘 洪
(1.内江师范学院 人工智能学院,四川 内江 641112;2.四川大学 计算机学院,四川 成都 610065)
语音识别技术(Automatic voice recognition)是一种将语音信号转换为计算机可读文本的技术,是一个包含了声学、语音学、语言学、数字信号处理理论、信息论、计算机科学等众多学科交叉的领域.由于语音信号的多样性和复杂性,其信号质量易受环境、设备干扰和众多采集参数的影响.因此,当前语音识别系统基本上只能在一定的限制条件环境添加下获得满意的性能,或者说只能应用于某些特定的场合.同时,作为提升产品智能化程度的一个标志,语音识别技术大量用于生活当中,包括语音搜索、智能家居等.
语音识别首先可分为孤立词和连续词语音识别,1952 年在美国贝尔实验室、1962 年在IBM实验室都开发实现了基于孤立词(特定的数字及个别英文单词)的语音识别系统[1].连续词识别因为不同人在不同的场景下会有不同的语气和停顿,很难确定词边界,切分的帧数也未必相同,给连续语音识别造成了不小的挑战[2].
直到20 世纪80 年代,研究人员通过引入隐马尔科夫模型(Hidden markov model,HMM)在语音识别领域取得了里程碑式的突破[3].每个音素用一个包含6 个状态的HMM 建模,每个状态用高斯混合模型(Gaussian mixture model,GMM)拟合对应的观测帧[4],观测帧依据时间顺序将数据组合成观测序列.每个模型可以生成任意长度的观测序列,训练时将样本按音素划分到具体的模型,在训练数据的基础上通过算法学习每个模型中HMM 的转移矩阵、GMM的权重以及均值方差等参数.
其后,由于神经网络应用的不断兴起,研究人员将神经网络引入到语音识别领域,神经网络的引入主要是代替GMM 拟合观测帧数据.由于神经网络的在函数逼近上的强大能力[5],语音识别效果亦有较大提高.上述方法虽然在语音识别中取得了较好的效果,但基于音素的HMM 模型是依赖于专家知识人为设计和创建的识别模型,未必反映了语音声学的本质;其次,模型设计较为复杂且不易理解,不利于研究人员入门和改进.因此,研究人员一直在实验其他相关语音识别方法,端到端(End-toend)在此时应运而生.
End-to-end的语音识别方法是典型的深度学习模型方法,依赖于神经网络在特征自提取和表示方面的强大能力,不再人为预设对应的模型,直接从输入的语音频谱图映射到对应的文本标签,同时End-to-end的方法不再依赖基于上下文(Context dependent)的状态转移和对齐(Alignment)处理.
本研究在借鉴和改进已有的英文端到端识别方法基础上进行中文语音识别.首先,将语音信号分帧并转换为频谱图;随后,卷积神经网络(Convolutional neural network,CNN)在时间维将频谱图进行特征提取和压缩,压缩之后的特征以时间维输入到多层递归神经网络(Recurrent Neural Network,RNN)进行时序相关性建模;然后,使用CTC(Connectionist temporal classification)作为损失函数进行误差反向传递,神经网络输出单个汉字.
本文采用的网络结构如图1 所示,实验数据采用清华大学信息技术研究院语音和语言技术中心王东等[6]发布的开放语音数据集THCHS30,最终以CCER(Chinese character error rate)作为识别结果评判标准.
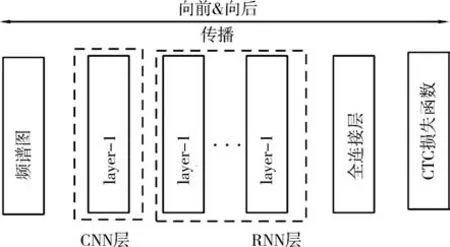
图1 多层神经网络结构Fig.1 The structure of the multi-layer neural network
1 频谱图MFCC
MFCC 是Mel-frequency cepstral coefficients 的缩写,其特征提取包含2 个关键步骤:首先将信号转化到梅尔频率,然后进行倒谱分析[7].
1.1 梅尔频率梅尔刻度是一种常用的语音信号分析方法,基于人耳对等距的音高(Pitch)变化的感官判断而定的非线性频率刻度.梅尔刻度的滤波器组在低频部分的分辨率高,跟人耳的听觉特性是相符的,这也是梅尔刻度的物理意义所在.梅尔频谱m和频率f的关系如下:
在频谱图生成过程中,首先,对时域信号进行傅里叶变换转换到频域;然后,再利用梅尔频率刻度的滤波器组对频域信号进行切分;最后,每个频率段对应一个数值.
1.2 倒谱分析倒谱分析是在对时域信号做傅里叶变换取对数之后,再进行反傅里叶变换,可以分为复倒谱、实倒谱和功率倒谱,通常语音信号处理采用功率倒谱[8].
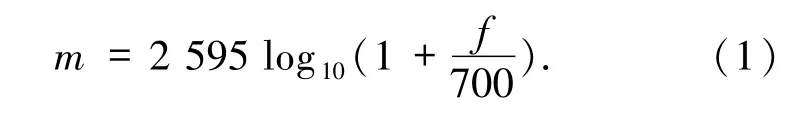
1.3 MFCC特征处理步骤1)预加重:高通滤波器处理,补偿语音信号受到发音系统所压抑的高频部分;
2)窗函数处理:使用汉明窗平滑信号,会减弱傅里叶变换以后旁瓣大小以及频谱泄露;
3)梅尔滤波器处理:将语音信号从时域转换到频域,并精简信号在频域的幅度值,然后进行对数处理,本文采用的滤波器组为39 个;
4)倒谱分析:反傅里叶变换(实际中常用离散余弦变换),然后通过低通滤波器获得最后的低频信号;
5)差分处理:由于语音信号是时域连续的,分帧提取的特征信息只反应了本帧语音的特性,为了使特征更能体现时域连续性,因此,在特征维度增加前后帧信息的维度,常用的是一阶差分和二阶差分.
2 模型结构
本研究采用的网络层类型包含CNN 和RNN.CNN用在时间维上对数据进行特征自提取和维度压缩,同时考虑到RNN 在模型训练时对时序数据记忆困难问题,采用改进的GRU(Gated Recurrent Unit)结构进行数据时序建模[9].
CNN是一种广泛用于计算机视觉领域[10]中的神经网络单元,其核心思想是模拟人类视觉特征,认为视觉不只是聚焦在感兴趣的像素上,还对其周围领域的像素产生响应,解决了图像空间相关性问题[11-12].同时,在局部采用共享权值,以降低模型训练难度,卷积操作具有位移、缩放及其他形式扭曲不变性,极大地降低了CNN 对目标在图像中的角度、缩放和扭曲的依赖性和敏感度,池化操作对局部区域提取显著性特征,压缩图像特征数据,降低数据维度,提取有用深层数据特征,基本操作如(2)式所示:
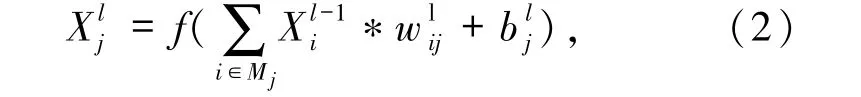
RNN是一种广泛用于时序数据建模的神经元结构[13],其核心思想为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出[14].理论上,RNNs 能够对任何长度的序列数据进行处理.但是在实践中,为了降低复杂性,往往假设当前的状态只与前面的几个状态相关,基本操作如(3)式所示:
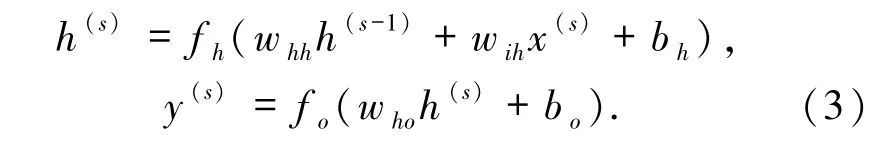
对于每一个隐状态s,其输入包含该时刻的输入x(s)以及上一时刻的隐状态h(s-1),输出y(s)依赖于h(s),w 表示不同输入输出之间的权重值,b 为权重偏置值.
本文采用1 个CNN层用于时间维特征提取和数据压缩,多个RNN 层用于时序时间建模[15],通过全连接层映射到语音识别词典表,全连接层采用softmax作为激活函数,输出为对应标签的概率值.
3 CTC
在传统的语音识别模型中,对语音模型进行训练之前,往往都要将文本与语音进行严格的对齐操作[16].这样不仅要花费人力、时间,同时预测出的标签只是局部分类的结果,无法给出整个序列的输出结果,往往要对预测出的标签做一些后处理才可以得到最终想要的结果.
2016 年,Graves 等[17]提出CTC(Connectionist temporal classification)算法用于解决时序数据的对齐问题,其核心思想是在标注符号集中不断加入空白符号blank,然后利用RNN 进行标注,最后把blank 符号和预测出的重复符号消除.例如标签“_a_bb”和“a_bbbb”最终均被处理为“ab”标签,上述表述中“_”代表blank,是发音之间的间隔.
对于给定长度为T的时间序列
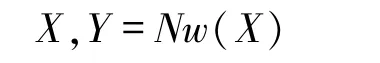
为网络的输出序列,y(k,t)表示输出单元k 在t 时刻被触发,即在t时刻标签为k 的概率.那么,输入观测值在输出集合(L′)上的时序数据概率分布可表示为(4)式,最终的标签输出概率为所有可能的路径之和,如(5)式所示:

4 实验
本文的实验数据为THCHS30,实验环境操作系统为Ubuntu16.04,处理器为Intel(R)Core(TM)i7-6800K@ 3.4 GHz,内存64 GB,显卡为2*NVIDIA GTX1080(2*8 GB显存).
深度学习神经网络相关实现基于Keras1.1.2和Theano 0.8.2 开源框架,程序开发语言为Python.实验设计包含以下部分:
1)通过实验验证不同的GRU 层数和神经元数量对识别效果的影响;
2)与传统语音识别方法(HMM/GMM 和HMM/DNN)的识别结果比较;
本文采用的识别结果评断因子为CCER,为了使识别出来的词序列和词序列真实值(truth)之间保持一致,需要进行替换(S),删除(D),或者插入(I)某些词,这些插入、替换、删除的词的总个数,除以标准的词序列中词的个数的百分比,定义如(6)式所示:
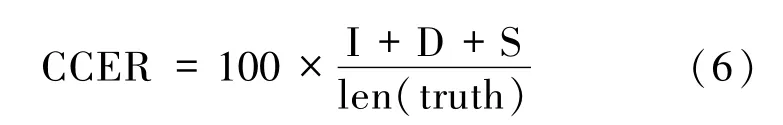
根据上述实验设定,本文进行了相关的仿真实验,实验1 的结果如表1 所示.
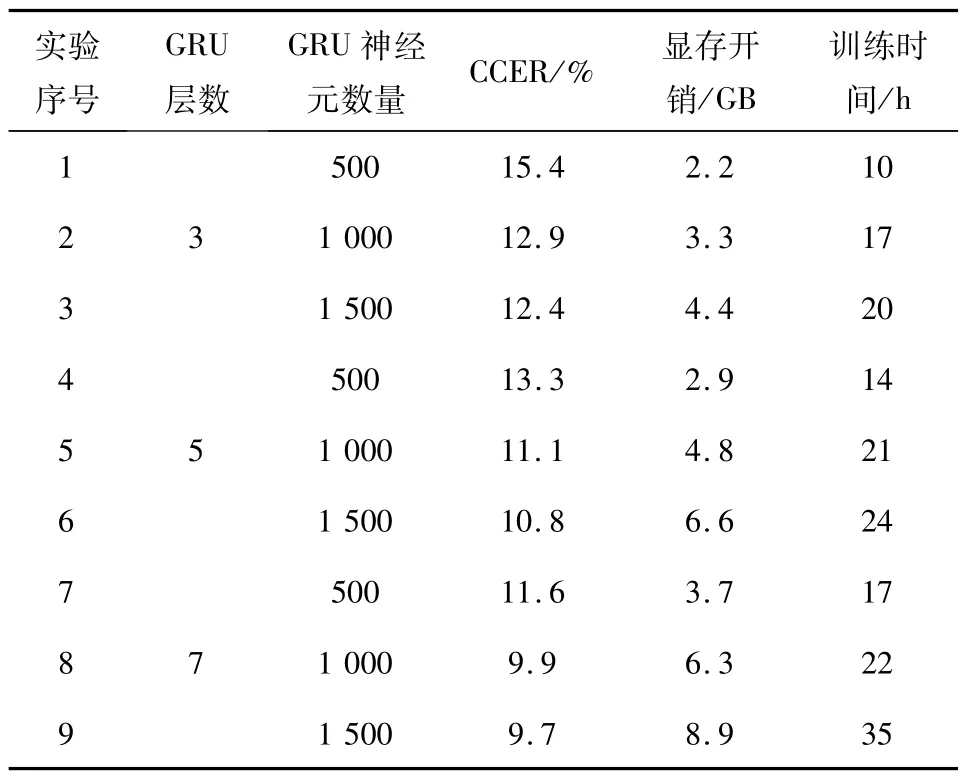
表1 神经网络结构验证实验结果Tab.1 Verification of the experimental results based on the neural network structure
针对已有训练数据集,在仿真实验过程中,本文做了9 组对比实验,包含3、5、7 层的GRU 网络结构和与之对应的500、1 000、1 500 个GRU 神经元.表1 中对应的CCER为多次实验所得的最好识别结果,显存开销和训练时间是为了对比增加GRU网络层数和神经元数量对整个模型造成的附加影响,其值均为大概值.
由表1 的结果可知,增加GRU 网络层数和神经元数量可在一定范围内提升最终的语音识别效果,由3*500 的15.4%提升到7*1 500的9.7%.在GRU 神经元数量从500 增加至1 000,在各个GRU层数量的情况下,最终的CCER 均能提升2%~3%,但是神经元数量从1 000 增加至1 500之后,CCER提升并不如之前的改进大,约为0.3%,这个现象说明1 000 为本文网络结构神经元的合适选择值.在增加GRU 网络层数和神经元数量的同时,模型训练的显存和时间开销明显增大,大约为3.5 倍.
在完成上述实验之后,再基于同一训练数据集进行一组对比实验,对比本文的端到端语音识别方法与传统的HMM/GMM算法和HMM/DNN算法的识别效果和训练时间,结果如表2 所示.
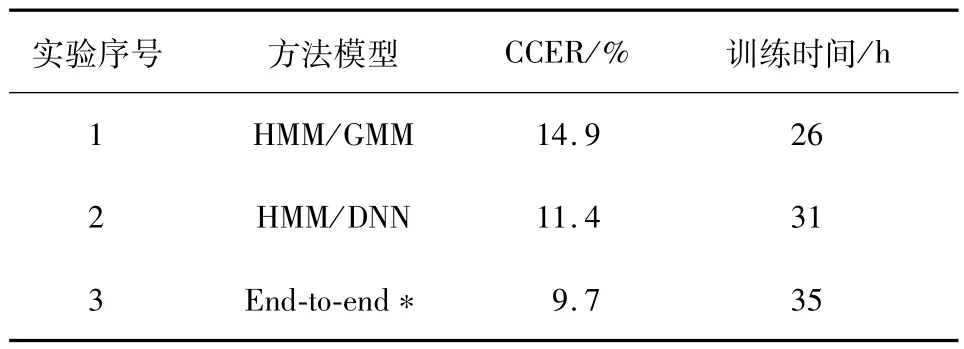
表2 语音识别对比实验结果Tab.2 Comparison of the experimental results based on the different algorithms
从表2 可知,本文所采用的方法在识别效果上均优于传统的HMM/GMM 算法和HMM/DNN 算法,但是训练时间上稍逊,但如果采用实验1 中第8个实验的结果,那么本文的方法在识别结果和训练时间消耗上均优于传统的语音识别算法.深究训练时间开销的原因可知,传统的HMM/GMM 算法和HMM/DNN算法在使用维特比算法解码时消耗了大量的训练时间,约占50%.在识别效果和时间上的优势也是当前端到端语音识别算法成为主流的根本原因.
5 结论
本文在传统语音识别算法人为设计模型较为复杂,且消耗训练时间较长的情况下,借鉴并改进端到端语音识别算法在英文识别中的结果,设计和实现了适合本文数据集的中文语音识别算法.通过与其他传统方法的识别结果比较,本文所采用的算法在能保证更好的识别效果的同时,降低模型训练消耗的时间;同时极大地降低了语音识别技术对专家知识的依赖性,利用神经网络强大的特征自学习和建模能力对数据分布进行拟合,端到端语音识别技术必将成为未来语音识别的主流技术.
以后,将从增加训练样本数据量、调整模型训练时的超参数等方面入手,进一步改进本文的模型识别结果.
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:36
自然杂志(2021年6期)2021-12-23 08:24:46
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
语言与文化论坛(2019年3期)2019-04-13 02:25:30
小说界(2018年5期)2018-11-26 12:43:42
现代装饰(2018年5期)2018-05-26 09:09:01
电源技术(2015年5期)2015-08-22 11:18:38
弹箭与制导学报(2015年1期)2015-03-11 15:32:06
