
基于注意力和多尺寸卷积的超分辨率算法研究*
2022-01-18 02:58黄洪全陈延明
传感器与微系统 2021年12期
梁 超, 黄洪全, 陈延明
(广西大学 电气工程学院,广西 南宁 530004)
0 引 言
超分辨率图像重建(super resolution image reconstruction,SRIR)的目的是将已有的低分辨率(low-resolution,LR)图像转换成高分辨率(high-resolution,HR )图像,使其具有高频纹理细节和边缘结构[1]。然而,许多HR图像可以降采样为相同的LR图像,这就造成了一张LR图像对应多张HR图像,形成了一个不适定问题[2]。为了解决这个问题,目前已经提出了许多基于学习的方法来学习LR图像和HR图像之间的映射[3,4],例如SRCNN[5],VDSR[6],FSRCNN[7],ESPCN[8]等。
针对重建模型在网络结构的层数越来越深,计算量大,不能灵活处理高频和低频的信息的问题,本文提出了一种基于注意力和多尺寸卷积的图像超分辨率算法。其中包含多尺寸残差块,对同一张特征图进行多尺寸卷积融合处理;改进的通道注意力模块,达到充分利用信息的作用;压缩模块调整特征图的通道数,从而减少整体的计算量。
1 方法设计
1.1 模型结构
模型结构如图1,特征提取模块提取浅层特征,若干个级联的多尺寸残差块对特征进行融合加强,其中多次利用跳跃连接,把图像细节由前面的卷积层直接传递到后面的卷积层,获得更丰富的信息。流程如下:
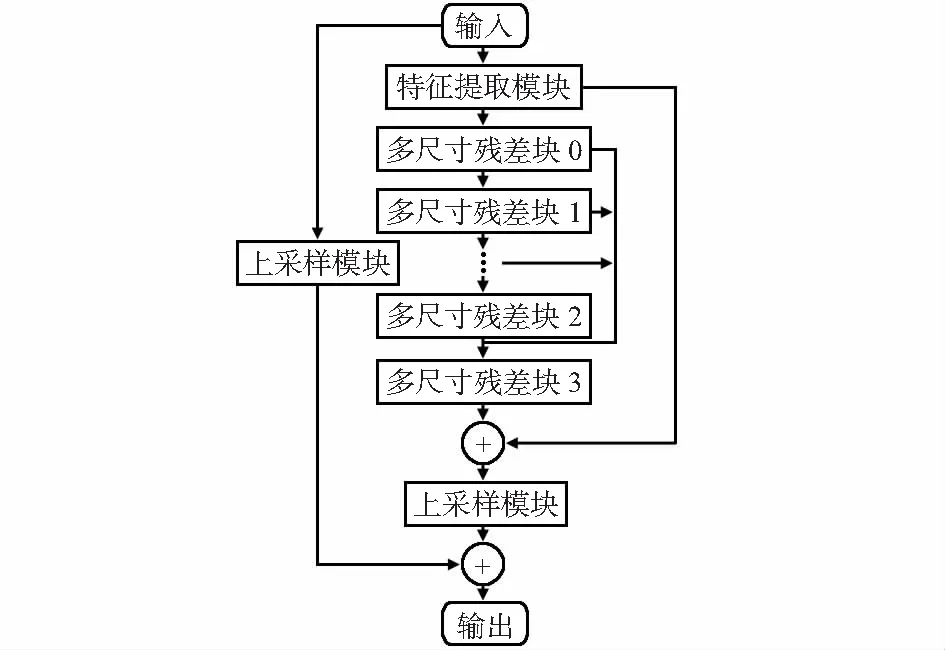
图1 模型流程示意
训练数据插值下采样得到输入数据,然后通过特征提取模块初步提取特征值,有
B0=f(x)
(1)
式中f()为特征提取的两个卷积层,B0为提取的特征,也是之后的输入。下一部分由若干多尺寸残差块叠加组成,即
Bk=Ek(Bk-1),k=1,…,n
(2)
式中Ek为第k个多尺寸残差块,Bk和Bk-1分别为第k个多尺寸残差块的输出与输入。最后一个多尺寸残差块输出通过跳跃链接和前几次的输出进行全局特征融合,即
Bn=concat(En(Bn-1),En-1(Bn-2),…,E2(B1))
(3)
采用亚像素卷积层作为上采样层得到超分辨率图片,即
y=SP(fcom(Bn)+B0)+SP(x)
(4)
式中SP(·)分别为亚像素卷积层,fcom(·)为压缩模块。
1.2 多尺寸残差块设计
如图2所示,描述的是多尺寸残差块结构。表示为

图2 多尺寸残差块结构
(Bl+1,A)=fattfcomp(concat((Bl,A)1,(Bl,A)2,
(Bl,A)3))
(5)
式中fcomp(·)为压缩模块(带有LReLU的1×1卷积层);fatt(·)为注意力模块;(Bl,A)1,(Bl,A)2,(Bl,A)3为三种尺寸卷积处理输出。(Bl+1,A)为最后输出。注意一点,压缩后的输出通道数应与原特征图的输出通道数保持一致。
多尺寸残差块有四大特点:
第一,去除BN(batch normalization)层。受到文献[9]方法的启发,在提出的多尺寸残差块上去除批量归一化层,利用激活函数LRelu。BN对超分辨率消极影响可以分两点:1)BN层在训练时,即通过最小批次数据上的均值和方差对这批数据进行归一化,在测试时,BN层将使用整个测试集数据的均值和方差。当测试集的数据量与训练最小批次差距过大时,BN层就会倾向产生不好的效果,而且会影响到整个模型的性能。2)在超分辨重建中图像颜色的恢复是很重要的一部分,但是超分辨率网络引入BN层将会对图像上的颜色进行归一化处理,最终重建图像的颜色将不会贴近原有颜色,从而降低重建图像质量。
第二,对同一特征图进行不同尺寸(3×3,5×5,7×7)的卷积处理,而且利用两次3×3卷积和三次3×3卷积替代大尺寸的5×5卷积和7×7卷积。因为堆叠小尺寸卷积的参数量要小于单独的大尺寸卷积,所以在保证感受野一样的同时,减少了模型参数计算量。例如用两个堆叠的3×3卷积代替5×5卷积,在计算参数方面,5×5卷积的参数个数为26×(5×5+1)个,两个级联的3×3卷积个数为20×(3×3+1+3×3+1)个,可以明显发现两个级联的3×3卷积的参数个数更少。
第三,针对在融合特征的时候,使得通道数过大的缺点,设计一个压缩模块进行降维(1×1卷积),减少计算量。
第四,通道注意力模型。采用像素均方差和GAP混合的方法来替换单纯的全局平均池化,其结构如图3所示。设输入为X=[x1,…,xc,…,xC],第c个特征图的大小为H×W,具体如式(6)

图3 通道注意力模型
Zc=HGC(xc)

(6)
受到残差通道注意力网络(residual channel attention network,RCAN)的启发,在全局平局池化和像素均方差后加入门控单元,实现自适应地调整通道特征。门控单元的计算如下
s=f(W2δ(W1Zc))
(7)
式中f()为Sigmoid 函数;δ()为RELU激活函数;W1,W2为第一层和第二层卷积,对应的都是全连接操作,只是两层的维度各不相同,其中W1的维度是C/r,r为缩放因子,而W2的维度是C;最后经过Sigmoid函数得到权重值,在与原输入特征图相乘,得到新的特征图,有
xnew=s·xc
(8)
1.3 上采样模块
上采样模块采用的是ESPCN(efficient sub-pixel convolutional neural network)提到的亚像素卷积层,亚像素卷积层能够有效地减少计算量,且提升一定的重建性能。如图4所示,其结构是2倍放大。亚像素卷积层的重建过程是将特征图像中每个像素r2的通道重新排列成一个r×r的区域,对应高分辨率图像中一个r×r大小的子块,从而大小为H×W×r2的特征图像被重新排列成rH×rW×1的HR图像。

图4 2倍放大示意图
2 实验结果
2.1 实验配置
利用DIV2K数据集充当训练集和验证集。DIV2K数据集是一种高质量的图像数据集,包含800张训练图像,100张验证图像。为了充分利用训练数据,对训练数据进行旋转、缩放、翻转来加强。在训练集中LR图像与HR图像是成对存在的,为了获得DIV2K训练集中的对应的LR图像,利用MATLAB R2017a中使用缩放因子为(2倍和4倍)的双三次插值对HR图像进行缩小。测试集选用的是Set5、Set14、BSD100和Urban100四个数据集。到此,数据集准备完毕。
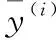
(9)
重建出的HR图像需要转换成YCbCr色彩模式,只在YCbCr 空间计算Y通道进行对比,得到峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)。
激活函数应用的是LReLU,利用Adam优化,mini-batch大小为16,初始学习率是0.000 2,每迭代训练2 000次学习率降为原来的50 %,总共迭代20 000次。在远程服务器上用一块2080TI GPU训练,其中采用深度学习框架TensorFlow1.13.1,Ubuntu18.04操作系统。
2.2 实验结果
本文将提出的新模型与目前6种超分辨率模型进行对比。首先是残差模块的选择,在图5中显示拥有8重、12重、24重多尺寸残差模块的2倍重建训练验证集PSNR曲线,随着多尺寸残差模块的增多,训练效果也在不断的上升,最高可以达到35.83 dB,但是训练的时间也在增多。例如12重的模型训练好需要15 h,24重的模型训练需要2天左右,更多的重数需要的训练时间更是成倍增加。根据表1所记录下的不同重数模型的参数量与实时重建速度,不只是训练时间的增加,计算量也是成倍增加,所以,在实际应用中需要根据实际场景进行对多尺寸残差块的选择。随后所有的测试都是基于24重多尺寸残差模块进行测试。

图5 不同重数模型验证集的PSNR曲线

表1 不同重数模型验证集的参数与实时速度
表2为4类测试集在不同方法下分别放大2倍和4倍的评估指标,其中加粗的表示效果最好,加下划线的表示效果第二好。很明显,在2倍尺度下和4倍尺度下本文提出的方法都表现出了较为明显的优势,较好的改善了图像的重建质量。

表2 测试集上与流行SR算法在2倍和4倍的指标对比(PSNR:db)
将未改进的注意模块和改进的注意力模块放到同一个模型中进行比较,记录PSNR和SSIM变化,结果如表3所示,本文改进的通道注意力有一定效果的提升。

表3 在Set5上2倍超分辨率重建的方法比较
2.3 实验效果
图6(a)为5种方法关于Set5测试集中女人(women)图像的4倍重建效果,可以明显发现其余四种方法的效果图的眼部未能够清晰重建,眼珠和眼白已经混合到一起,但是本文的效果图拥有较为完整的眼部。图6(b)为各种模型在2倍重建的实验效果,可以清晰发现本文方法在数字细节和线条结构方面,比其他的模型有明显增强。

图6 本文方法和其他算法在不同数据集和不同分辨率重建结果
3 结束语
本文提出了基于注意力和多尺寸卷积的单图像超分辨率算法,主要利用新的通道注意力模块和多尺寸残差块,先从网络的宽度上进行扩展,使模型能快速、充分地利用每层信息,然后通过注意力通道灵活运用特征图上的高低、频信息,最终达到能够拥有优秀的重建效果。实验结果表明:本文的方法比目前流行的方法拥有更不错的重建效果。接下来,将研究把训练图片不仅仅只是采用插值下采样,而是各种退化模型使训练图片更加接近实际生活。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
第二课堂(课外活动版)(2016年2期)2016-10-21
