
基于机器学习的在线评论情感分析与实现
2022-01-18 05:47:12尚永敏赵榆琴
大理大学学报 2021年12期
尚永敏,赵榆琴
(大理大学数学与计算机学院,云南大理 671003)
近年来,京东、天猫、小米等网上购物平台迅速发展,人们越来越偏爱线上购物。平台商品品类丰富,消费者群体庞大,且消费者在平台留下大量评论。对于消费者,可通过手动浏览评论了解商品,但是对于生产商、分销商和卖家这类用户,逐条浏览每件商品评论将是一个非常耗时且难于分析的过程,且得出的结论不易理解,也缺乏客观证明。如果将这些评论信息进行分类、分析和整理,从中挖掘商品的优缺点,且能以快捷、准确、直观的方式提供给多类用户,为他们提供选择或改良商品的参考依据,则问题可有效解决。
情感分类主要有两种方法:基于机器学习和基于情感词典的分类。基于机器学习的分类,是有监督的学习,需要人工对语料集进行正负样本标注,再选用合适的算法去训练分类器,之后用新的数据训练模型得到预测的结果,从而计算出每条评论正负情感的概率〔1〕。目前常用的机器学习分类方法有朴素贝叶斯、支持向量机(support vector machines,SVM)和邻近法等。这些方法都被广泛应用于文本评论挖掘领域,并取得不错的效果。基于情感词典的分类无须人工标注,通过程度副词、语气词等进行正负情感打分,无监督学习得到分类结果。SnowNLP方法情感分析,它基于情感词典实现,可以方便地处理中文文本内容,所有的算法均为自动实现,并且自带了一些训练好的字典〔2-5〕。
LDA(latent dirichlet allocation)〔6〕是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。将分类好的情感视为一篇篇文档,文档中的每个词都以“一定概率选择了某个主题”。通过LDA模型,以确定的主题找到高概率出现的词语,则能分析出文档(包括正面情感集和负面情感集)中潜藏的主题信息,实现对情感的深度分析。
1 基于机器学习的评论数据情感分析方案设计
本文从京东采集3款主流笔记本在线评论数据。首先,对数据进行3项预处理:数据清洗、文本分词和停用词过滤。然后,分别使用SnowNLP分类方法、机器学习中SVM分类方法和朴素贝叶斯分类方法对预处理过的数据进行情感分类。之后,对3个模型的情感分类效果进行验证和评估,以确定适合评论数据分类的最优模型。最后,采用LDA主题模型,分主题对评论数据深入挖掘,按权重将情感分类的结果集进行分析和可视化,方案设计见图1。
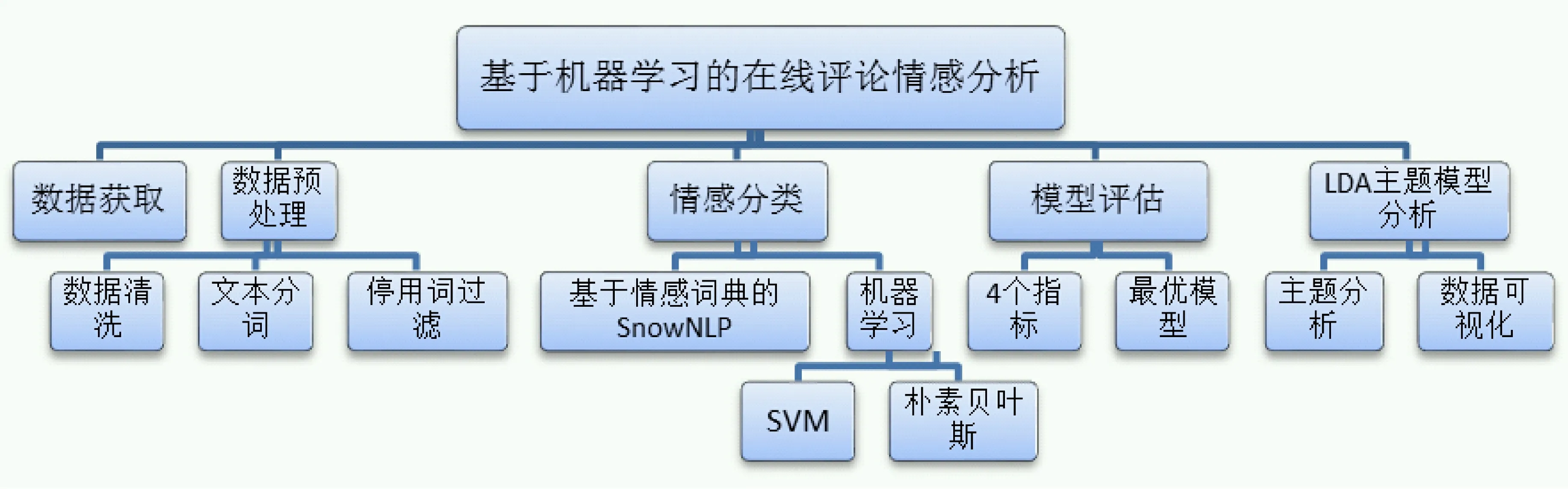
图1 基于机器学习评论情感分析方案图
2 数据获取及数据预处理
2.1 数据获取“华为荣耀magicbook14”“联想小新pro13”“惠普暗影精灵5”的销量和市场份额高,评论数据充足,为数据分析提供数据支持。本文采用八爪鱼采集器采集数据。见图2。

图2 数据采集流程图及部分数据获取结果
2.2 数据清洗从文本分析角度出发,若对不存在价值的文本内容进行文本分析,最终的分析结果必然会受到较大的影响。因此,在进行文本分析之前,先将文本内容进行数据清洗,包括文本去重和短句删除等过程。本文采用扩展库Pandas的drop_dupliate函数去除评论中的重复数据,采用conmments_data进行断句删除。数据清洗结果见表1。
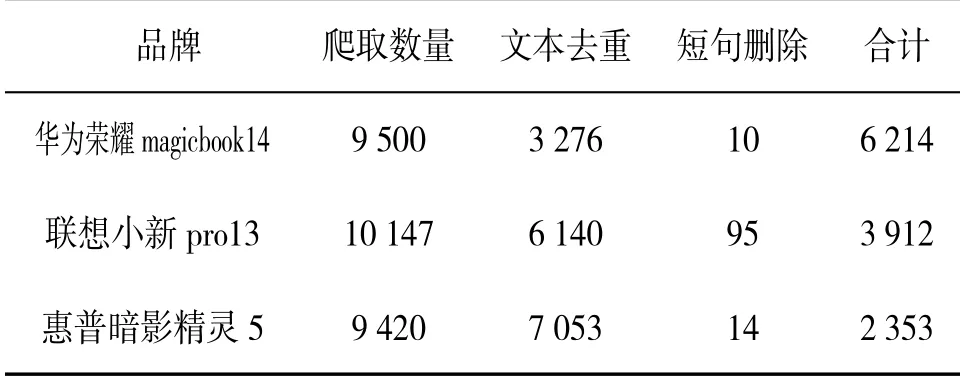
表1 3种品牌笔记本评论数据清洗结果
2.3 停用词过滤停用词是指那些没有实际意义的词,如“的”“了”等字眼。这些词对文本内容本质含义不影响,其信息含量较低,应去除。本文使用“哈工大”停用词典,以“华为荣耀magicbook14”为例,好评和差评的停用词过滤后的部分结果见图3。
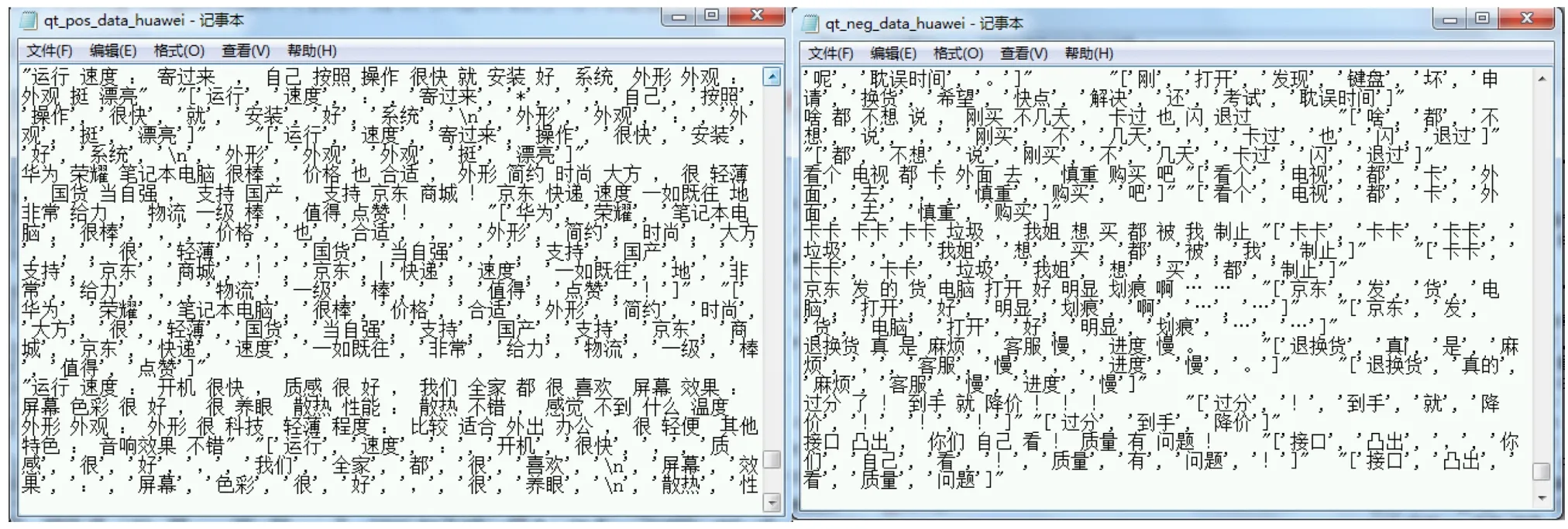
图3 “华为荣耀magicbook14”评论数据停用词过滤结果
2.4 文本分词本文选择在中文分词中表现非常出色的jieba分词包〔7〕。以“华为荣耀magicbook14”为例,好评和差评的部分分词结果见图4。
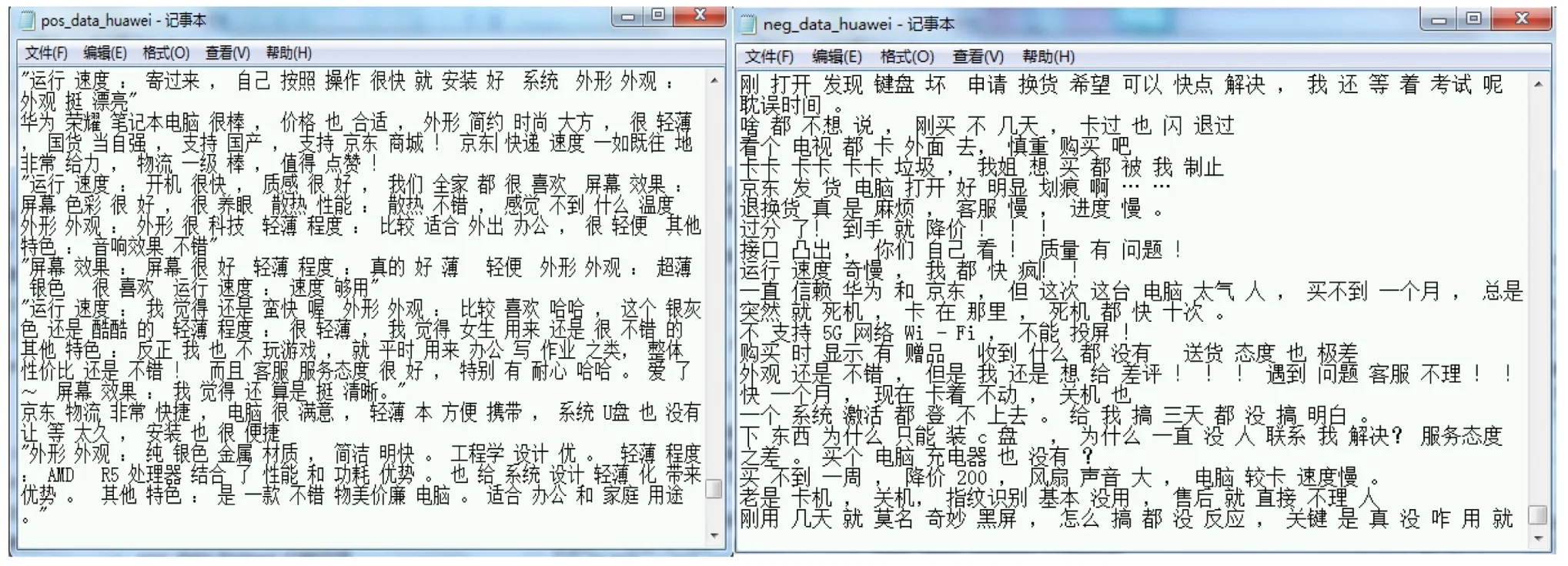
图4 “华为荣耀magicbook14”评论数据分词结果
3 情感分类及分析
3.1 分类方法原理SVM模型〔8〕于1995年提出,它可以进行预测、分类和异常检验,对于二元分类、线性不可分和变量的高维性方面具有优势。该模型主要用于有限的样本,最终目标是凸二次规划,通过找到最佳分割表面,对测试数据进行分类。SVM方法的解决过程为:先找到最佳超平面,然后分离待分类的数据,其间通过分类决策面的构建和分离间隔的不断调整,最终将数据分为两个最佳部分。
朴素贝叶斯方法是基于单词和类别之间的联合概率,基于已知的先验概率和条件概率来计算后验概率的分类。公式如下:
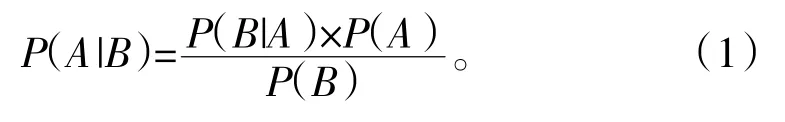
使用朴素贝叶斯和SVM两种方法都先对向量进行转化,再对分类器进行训练,其中训练集占比80%,测试集占比20%。最后进行预测分类。
SnowNLP方法,情感分数值在0~1之间,以0.5分界,大于0.5为正面情感,反之为负面情感〔9〕。但在本文代码实现中,为了使分词的情感更强烈,所以取0.6作为分界点。将概率大于等于0.6的评论标签赋值为1,小于0.6的评论标签赋值为-1,以方便将预测标签和实际标签进行比较,相同则判断正确。
3.2 分类方法实现及结果分类完成后,主要查看以下两个参数结果值〔10-11〕:
(1)宏平均(Macro Average):在计算均值时使每个类别具有相同的权重,最后结果是每个类别指标的算术平均值。
(2)加权平均(Weighted Average):当数据集中存在严重类别不平衡的问题时,就不适宜单纯使用宏平均,此时可以采取加权平均,根据每个类的样本量,给每个类赋予不同的权重。
在本文的评论数据集中,好评的数量远多于差评的数量,因此在评定机器学习分类模型时采用加权平均作为评估指标。
另外,采用Python中的第三方模块Sklearn来计算准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F值(Fscore)。
以“联想小新pro13”为例,3种方法分类效果见图5。
根据图5,SVM方法的分类精确率:正面情感(0.969)高,而负面情感(0.673)低;朴素贝叶斯方法的分类精确率:负面情感(1.000)高,而正面情感(0.695)低;SVM方法的准确率(0.815)比朴素贝叶斯方法的准确率(0.788)高。SnowNLP方法的正面情感精确率、负面情感精确率和准确率达到了0.908、0.935和0.926。
3.3 最优分类方法的选择如何评价分类效果的优劣是很重要的,好的评价指标有利于对分类方法效果进行评估,且可为模型不断进行优化提供依据。评估分类器性能,比较常见的指标是准确率、精确率、召回率、F值,3种分类方法的4项指标结果见表2,其中SnowNLP分类方法的4个指标均为最高。因此,分类效果最优的是基于情感词典的SnowNLP分类方法。
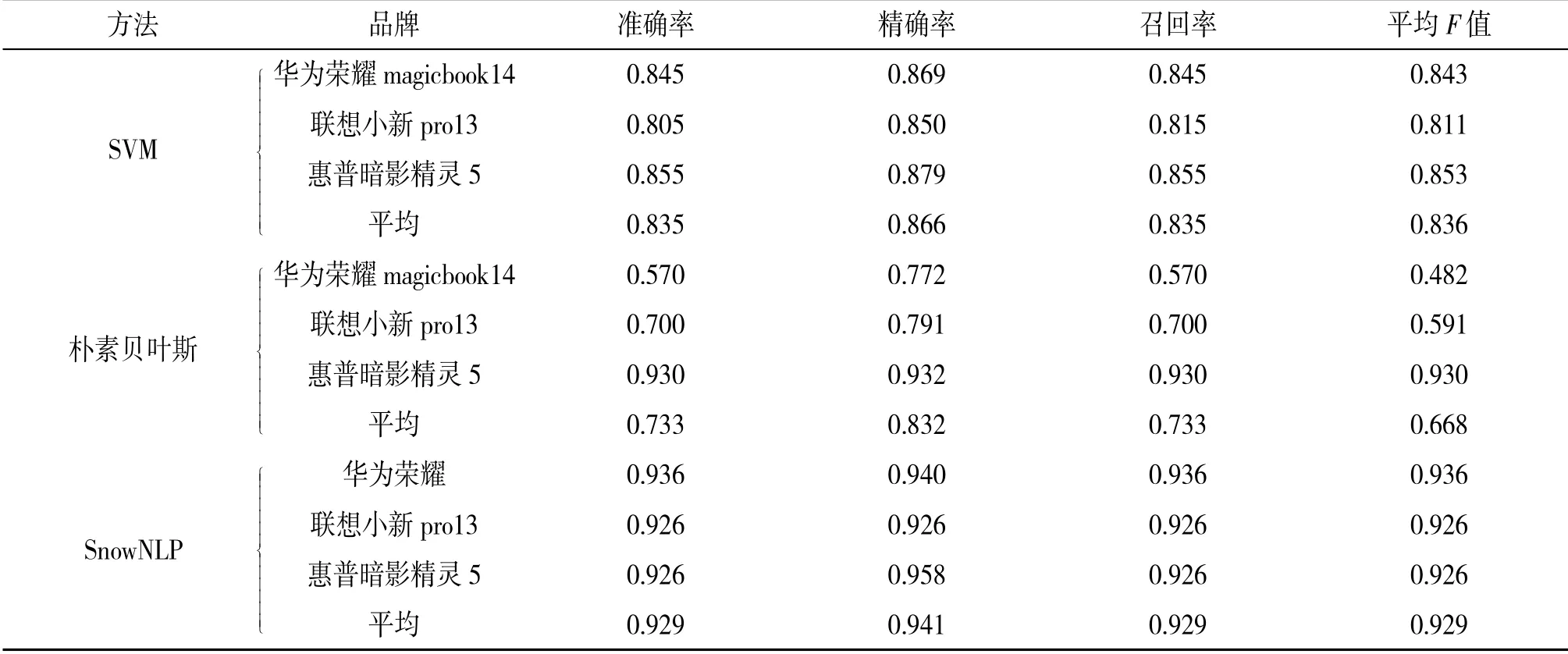
表2 3款笔记本3种模型分类指标对比表
4 LDA主题模型分析
LDA主题模型的算法原理可总结为:在给定一系列文档后,通过对文档进行分词,计算各个文档中每个单词的词频得到“文档-词语”矩阵,通过训练“文档-词语”矩阵,得到“主题-词语”矩阵和“文档-主题”矩阵,进而对文档中的主题进行分析〔12〕。每个词语在文档中出现的概率表示为:

分别选择3款笔记本SnowNLP方法情感分类后的好评集和差评集的若干个主题,提取关键词和每个关键词的权重,更好地挖掘商品的闪光点和问题点。
LDA主题模型分析过程如下:
1)使用上文分类好的好评集和差评集。
2)调用gensim库,使用corpora模块,构建词典,建立语料库。
3)使用model.LdaModel(nunl_topics)指定主题(topic)数量,进行LDA模型训练。
本文指定LDA主题模型的topic数量为3,进行LDA模型训练。以“联想小新pro13”为例,构建LDA主题模型,主题输出结果见图6。

图6 “联想小新pro13”主题输出结果
将好评集、差评集主题分析结果用柱状图显示,结果见图7。分析“联想小新pro13”好评集的LDA主题模型的结果,在3个主题中“轻薄”“运行”“速度”“屏幕”“外观”表现较为突出,说明用户对它的性能较认可,对该款电脑的整体评价是满意的。分析“联想小新pro13”差评集LDA主题模型的结果,“屏幕”的权重是最大的,其次是“电脑”“机器”“使用”等,反映了用户对于该款电脑的屏幕不满意。经过人工查阅“联想小新pro13”差评集,发现对于“屏幕”这一关键词指的是电脑出现黑屏、屏幕不居中、像素不好,蓝光画质不清晰这些问题。
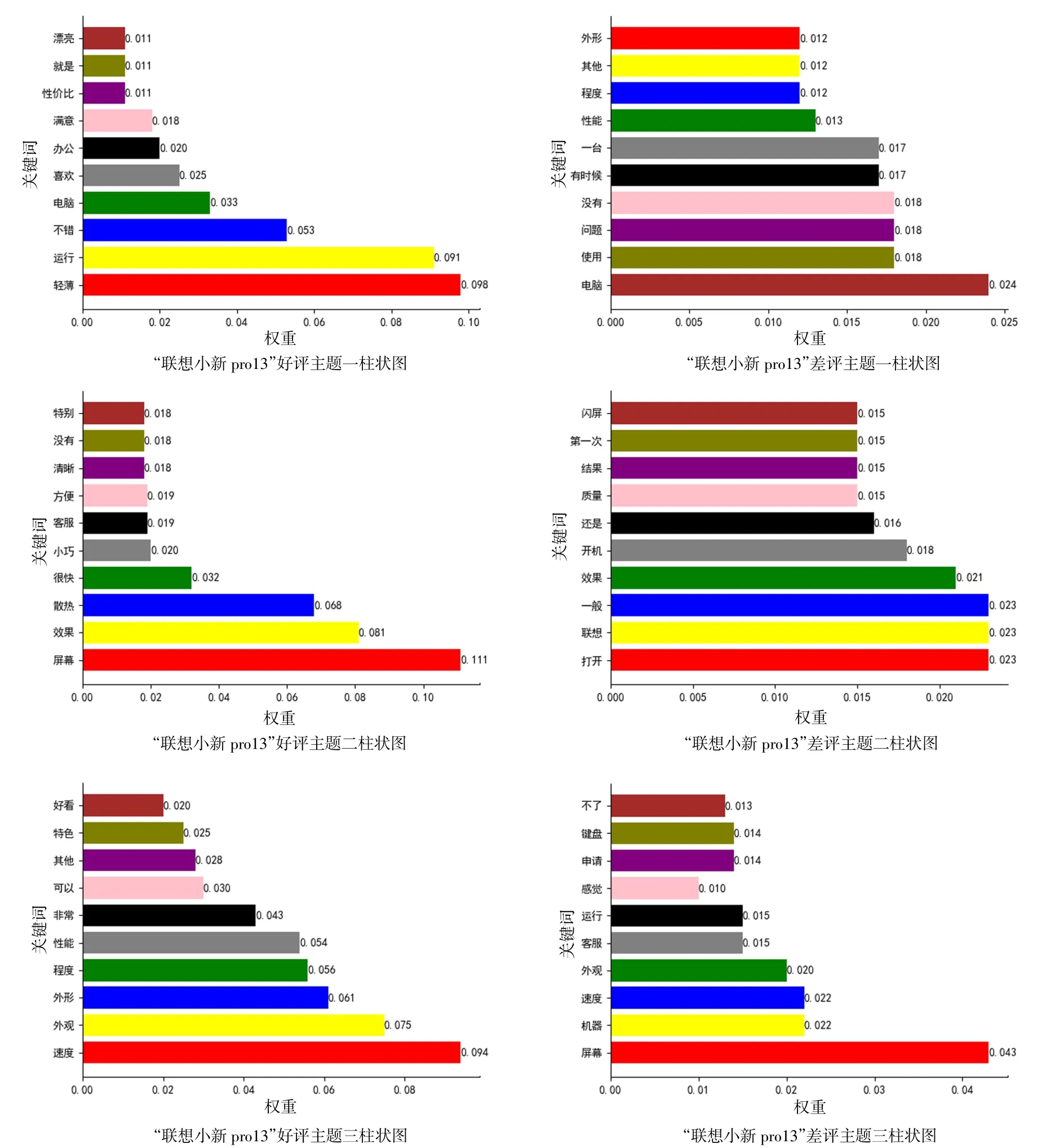
图7 “联想小新pro13”好评主题和差评主题柱状图结果
5 情感分析结果
总结各品牌优缺点,见表3。

表3 3款笔记本优缺点汇总表
根据各品牌的优缺点,整理提出商品改进的建议,主要有以下几点:
1)提高散热器和风扇的质量,解决风扇声音大的问题。
2)提高屏幕显示器的质量。在出厂前应做好检验工作,解决出现黑屏、屏幕不居中、屏幕有划痕等质量问题。
3)降价问题:商家应在商品主页面给予一定的解释,写明活动时间及做好保价申请服务。
6 结语
本文通过对在线评论数据选用3种分类方法进行情感分析,最终确定最优的方法是基于情感词典的SnowNLP库分类模型,其平均准确率、平均精确率、平均召回率和平均F值均在0.928以上。使用LDA主题模型对在线评论按主题情感进一步分析,将分析结果以可视化方式呈现出消费者对商品的关注点,为商家改进商品、制定生产和销售方案提供了有意义的参考和依据。
SnowNLP分类方法和LDA主题模型的结合使用,可针对多类在线评论数据进行情感分析,例如:学生评教信息、客户服务评价信息、业务员评价信息、社区活动民主测评信息、病人就医评价信息、试卷评价信息、意见征求信息等等。面对海量的在线评论信息,先分类出正面情感与负面情感,再根据不同主题细化分析,从而可以构建“至上而下、逐步细化”的树形数据分类方案,从而为信息收集方提供从大量数据中得到的算法最优、结果准确的数据分析结果提供理论依据和实施方案。另外,这些数据分析结果根据不同用户的需求以数据可视化形式展示出来,用户能从中获得信息、分析不足、总结经验,以进行预测和决策。
“互联网+”时代,人们的生活和学习已产生大量线上数据,评论信息只是海量数据中的一类,如何将基于机器学习的“SnowNLP+LDA”在线情感分析方案应用到其他行业,需要未来继续探索和实践。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中国生殖健康(2020年5期)2021-01-18 02:59:48
北极光(2019年12期)2020-01-18 06:22:10
小太阳画报(2019年10期)2019-11-04 02:57:59
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中国生殖健康(2018年5期)2018-11-06 07:15:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
信息安全研究(2016年4期)2016-12-01 06:06:54
