
弹幕文本情感分类模型研究
——基于中文预训练模型与双向长短期记忆网络
2022-01-18 08:19:26陈志刚
湖北工业大学学报 2021年6期
陈志刚, 岳 倩, 赵 威
(1 湖北工业大学经济与管理学院, 湖北 武汉 430068; 2 华中科技大学武汉光电国家研究中心, 湖北 武汉 430074)
以视频为媒介,观众可以针对视频内容发送弹幕,以表达自己的观点及情绪。通过对弹幕进行情感分析,一方面可以对视频内容进行信息挖掘,提取精彩视频[1-2];另一方面可以获取用户的真实情感倾向,如通过对短视频平台弹幕文本进行情感分析[3],快速获得网民在疫情期间的情感倾向,为有关部门治理及改善网络舆情提供参考。
弹幕文本情感分析离不开情感分类研究。传统的弹幕文本情感分类方法,多为通过构建情感词典将文本内容与情感词典匹配,从而得到情感极性。如:邱全磊等[4]构建基于表情和语气词的情感词典;洪庆等[5]构建了网络弹幕常用词词典;王文韬等[6]构建了弹幕文本的积极词云和消极词云;司峥鸣等[7]构建了多维情感词典,完成了弹幕文本的情感分类。情感词典法虽能完成弹幕文本的情感分类任务,但其构建需要耗费大量的人力,不能满足效率和准确率的要求,同时对数据集的泛化能力和迁移能力较差。随着深度学习在自然语言处理领域的发展,越来越多的学者将深度学习技术用于文本情感分类任务中,取得了优于情感词典法、机器学习法的分类结果。因此,针对弹幕文本的情感分类,庄须强等[8]提出基于注意力机制的LSTM模型(AT-LSTM),并基于此完成精彩视频的提取;叶健等[9]利用卷积神经网络(CNN)完成情感倾向弹幕的分类,均取得了优于传统方法的准确率和效率;李稚等[10]构建CNN-LSTM模型完成弹幕文本情感分析,并结合心理学、市场营销等知识,提出网络视频平台营销策略。
上述深度学习的方法虽基于不同方面完成了弹幕文本的情感分类任务,但多数研究并未考虑弹幕文本特点,如弹幕文本内容简短,内容口语化、网络化,存在一词多义的现象。这些为弹幕文本的情感分类任务带来极大挑战。
针对上述问题,本文提出一种结合中文预训练模型(BERT-wwm)和双向长短期记忆网络(BiLSTM)的模型来完成弹幕文本的情感分类。首先,引入BERT-wwm替代现有研究中词向量提取方法Word2Vec,得到具有丰富语境信息的动态词向量。动态词向量能更好地适应上下文信息,解决弹幕文本的口语化、网络化及一词多义问题。其次,结合双向长短时记忆网络,通过前向和后向结合起来同时捕获整体文本的信息,可以对简短的弹幕文本内容获取更多的特征信息。最后,运用softmax函数得到分类结果。
1 BERT-wwm BiLSTM模型
1.1 相关技术
1.1.1预训练模型BERT-wwm传统的词向量表示是采用Word2Vec[11-12]、GloVe[13]等模型通过训练将词组表示为一系列静态词向量。这类词向量可以得到词语间的语义关系,但其得到的词向量是固定的,不会随上下文变化而改变。因此,这些静态词向量技术无法表征上下文,同时无法解决一词多义问题。虽然有学者对Word2vec进行改进、优化[14],解决了词向量特征稀疏性,但Word2vec得到的仍然是静态词向量,影响了文本情感分类的准确率。直至2018年,谷歌提出的预训练模型BERT可以结合上下文信息产生动态词向量[15]。BERT在EMLo[16]和GPT[17]的研究基础上,采用双向多层Transformer模型作为基础单元,通过Encoder特征抽取器对文本信息进行双向编码,得到的词向量不仅包含该词本身,还包含了该词与其他词的关系以及句子间的上下文信息[18]。在实际运用中,对BERT进行微调[19-23],使其更适用于具体的文本分类任务。2019年,哈工大Y Cui等人[24]提出用全词遮掩(Whole Word Masking)替代BERT中的mask任务,在机器读取理解、自然语言推理、情绪分类、句子对匹配、文档分类等数据集上有着更优秀的表现,并采用中文语料进行训练,据此提出了中文预训练BERT-wwm模型。
1.1.2长短时记忆网络LSTM作为RNN的变体,LSTM保留了RNN可以处理序列数据的优点,同时可以解决梯度消失的问题,非常适合时序数据(文本数据)的建模。Zhu等[25]利用LSTM完成评论文本的情感分类,Ren等[26]结合主题特征与LSTM对Twitter短文本进行情感分类。
LSTM能解决RNN梯度消失的问题,仰仗其门控机制。LSTM模型主要由当前记忆单元、遗忘门、输入门、输出门等4个元素组成。遗忘门ft控制前一步记忆单元中的信息有多大程度被遗忘掉;输入门it控制当前时刻的输入以多大程度更新到记忆单元中;输出门ot控制当前的输出有多大程度上取决于当前的记忆单元。
遗忘门是把t-1时的长期记忆输入Ct-1乘以一个遗忘因子ft。遗忘因子是由短期记忆ht-1以及xt来计算:
ft=σ(Wf×[ht-1,xt]+bf
(1)
其中,σ表示sigmiod函数,W表示矩阵乘法操作,ht-1表示上一时刻的记忆状态,xt表示此时刻的输入,b为函数的偏置。
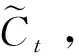
it=σ(Wi×[ht-1,xt]+bi
(2)
(3)
(4)
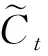
输出门先通过一个sigmiod函数计算出ht-1、xt中哪些部分需要被输出,再将输入门中得到的Ct经tanh函数处理,再将两者相乘得到:
ot=σ(Wo×[ht-1,xt]+bo
(5)
ht=ot×tanh(Ct)
(6)
1.1.3双向长短时记忆网络BiLSTM单向的LSTM模型信息是从前往后传输,容易丢失上下文信息。双向长短时记忆模型(Bidirectional Long Short-Term Memory, BiLSTM)增加了一个从后往前传递信息的隐藏层,通过正向和负向结合同时捕获整体文本的信息,可以利用上下文信息。Yao[27]提出了BiLSTM模型在中文分词方面是专家。Balikas[28]利用Word2Vec和BiLSTM模型完成文本的三元及五元情感分类任务,吴鹏[29]利用BiLSTM模型用于识别网民的负面情绪,在舆情领域有着重要的意义。Baziotis等[30]结合注意力机制,将BiLSTM模型用于基于主题的情感分类任务中。BiLSTM可分为3个步骤:1)前向的LSTM网络计算从左到右的隐特征;2)后向的LSTM网络计算从右到左的隐特征;3)将两个LSTM输出的结果进行拼接,得到BiLSTM,提取文本特征。
1.2 模型构建
本文提出的弹幕文本情感分类模型BERT-wwm-BiLSTM主要由输入层、隐含层和分类层组成(图1)。
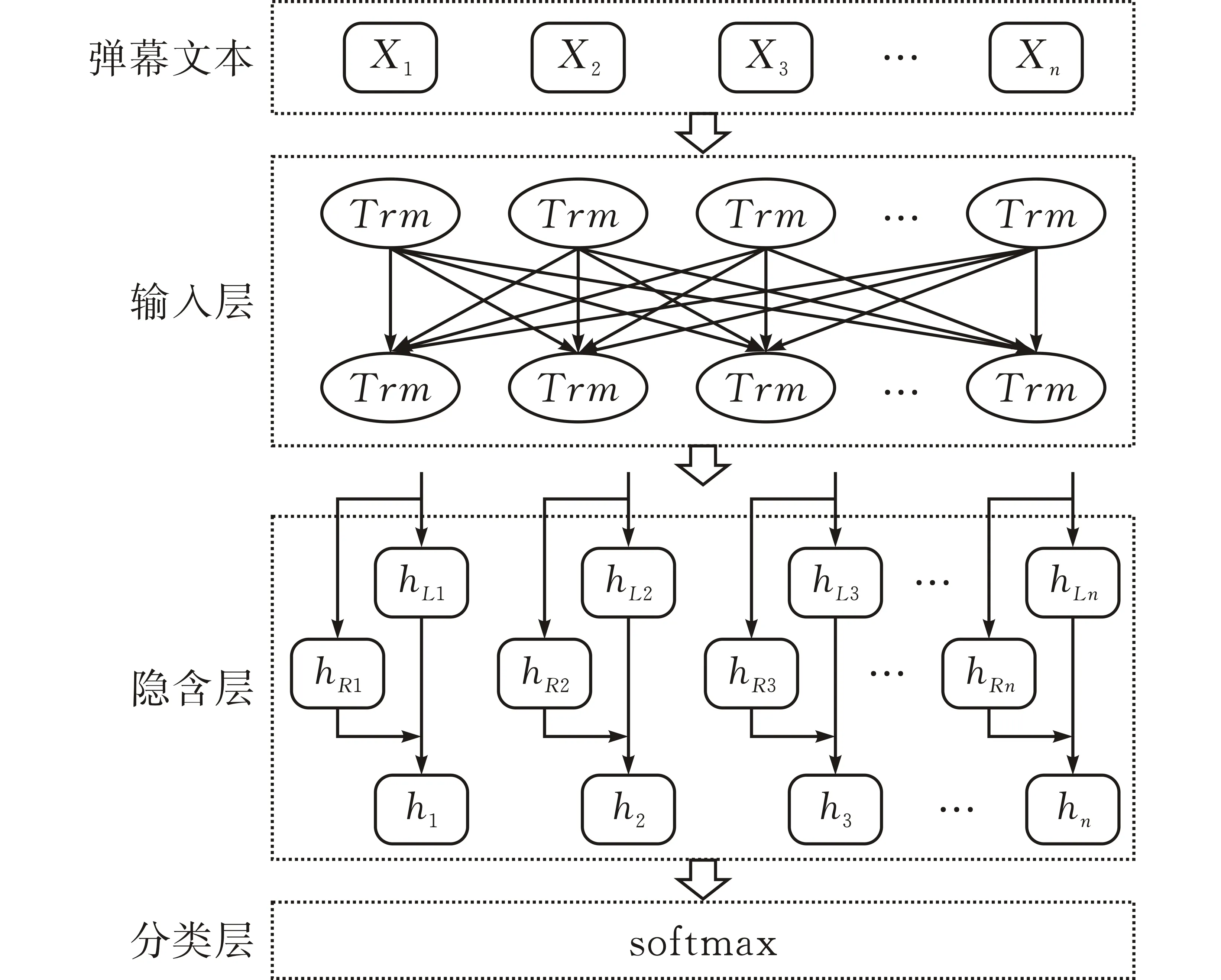
图 1 BERT-wwm-BiLSTM模型结构
首先,输入层是通过BERT-wwm预训练模型将输入的文本向量化,获取包含具有上下文语义的动态词向量;其次,采用BiLSTM作为隐含层,将BERT预训练得到的词向量作为BiLSTM网络的输入,经过神经网络的处理得到特征向量;最后,将隐含层的输出作为分类层的输入,利用softmax函数进行回归处理进而得到文本情感分类。
2 实验设置
2.1 实验环境
本操作系统为Ubuntu 18.04.5 LTS,服务器CPU为Intel(R) Xeon(R) Gold 5218,64核,CPU频率为 2.30 GHz。服务器内存为188G,显卡为Tesla V100,显存为32 G。深度学习网络代码通过Pytorch 1.7实现,采用Python3.6进行代码编写。
2.2 数据集获取及处理
2.2.1数据集的获取采用Python脚本爬取视频弹幕信息,视频来自bilibili和腾讯视频网站。图2展示了数据爬取的流程,爬取的部分弹幕如表1所示。

图 2 数据爬取流程

表1 部分弹幕情感标签
2.2.2数据预处理爬取的数据需要进行预处理,以保证数据集的高效性,从而训练得到有效的模型:1)去除重复数据防止重复数据造成模型过拟合;2)删除没有明显情感极性的弹幕;3)将表情转换为对应中文,颜文字转换为对应的情感词,辅助弹幕情感分类。经过上述处理之后,腾讯数据集共有21 532条,bilibili数据集有24 492条。之后进行人工标注数据集,标签‘0’表示消极情感,标签‘1’表示积极情感。表1展示了部分弹幕的情感标签。
2.3 评价指标
本文选取准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值作为评价指标。
2.4 参数设置
因为不同的参数会导致模型的学习能力不同,所以实验的结果很大程度依赖于模型的参数设置。本文所提出的模型实验参数主要包括BERT-wwm预训练模型参数以及BiLSTM网络参数。首先,对于BERT-wwm预训练模型,其参数已经定义好,不需要进行更改。BERT-wwm是由12层transformer组成,隐藏层维度为768,attention多头个数为12,总共参数量多达110M。其次,在BERT对训练预料进行了学习之后,BiLSTM则接着对数据进行特征提取,提升学习能力。在实验过程中,设置其网络层数为6层,隐藏层维度为384。
深度学习模型还需要设置合适的超参数,使得其学习能力最好。本文涉及的超参数包括学习率、训练周期数、批处理大小等。实验中的详细参数设置见表2。

表2 模型参数设置
3 实验结果及分析
3.1 实验一:学习能力测试
为了有效说明模型的学习能力,图3、图4展示了模型训练过程中训练集和验证集的损失及准确率随训练周期的变化。在深度学习训练中,训练集的作用是进行模型学习,验证集则是在每个周期学习之后检验学习的成果,再根据验证集的准确率来调整后续的学习。对于验证集而言,验证集损失值先下降,之后小幅度波动上升,这是由于部分学习错误的文本主导了验证集的损失值,在深度学习训练过程中属于正常现象。验证集的准确率则是相对平稳的小幅上升,说明模型学习的效果不错。
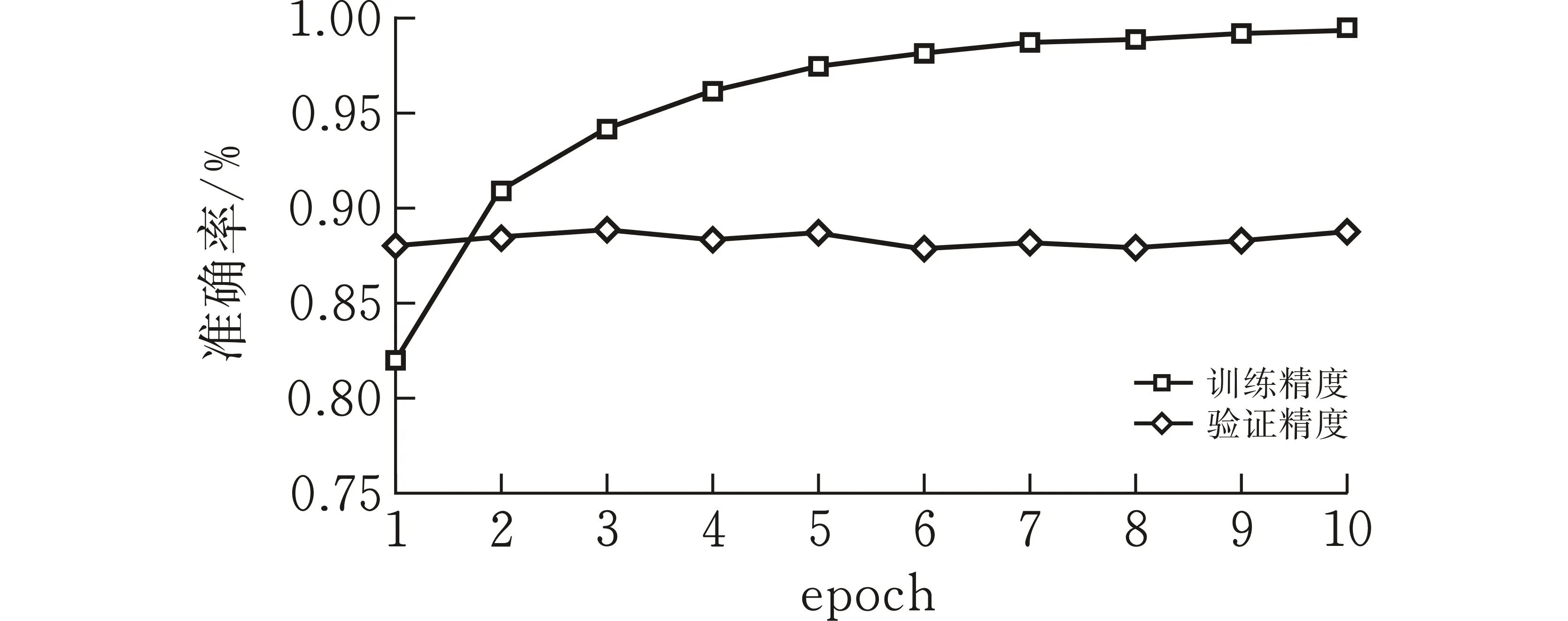
(a)bilibili数据集准确率变化曲线
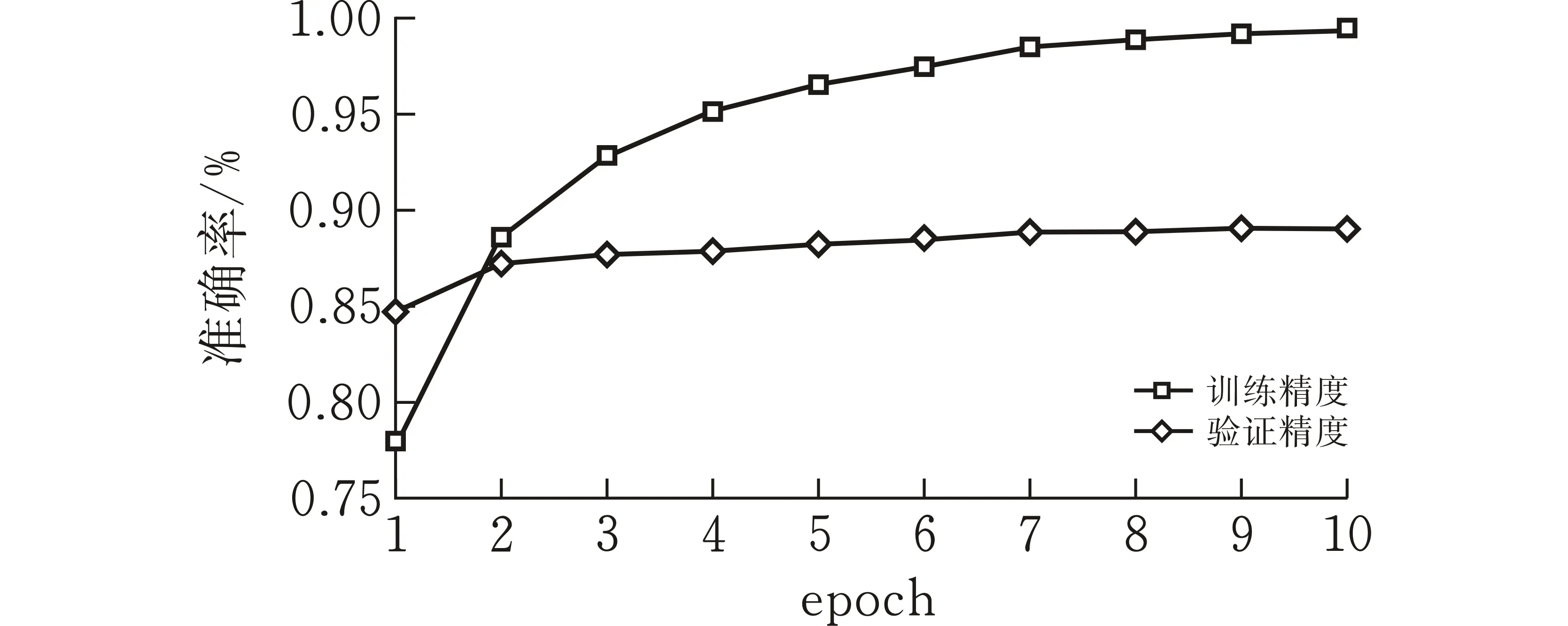
(b)腾讯视频数据集准确率变化曲线图 3 准确率随训练周期的变化
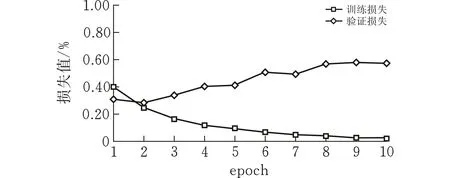
(a)bilibili数据集损失值变化曲线
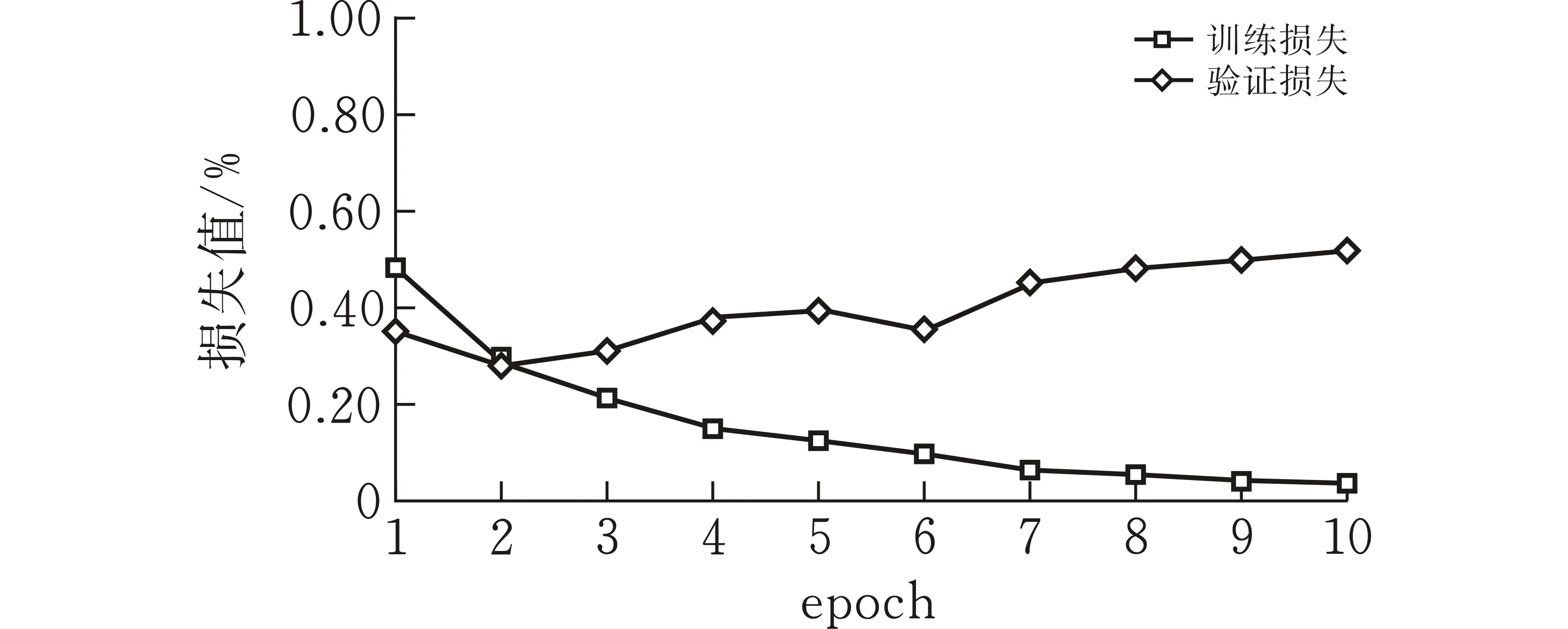
(b)腾讯视频数据集损失值变化曲线图 4 损失值随训练周期的变化
3.2 实验二:模型指标测试
模型经过10个周期的学习之后,即可通过测试集来评估模型的能力。表3及图5展示了BERT-wwm-BiLSTM模型在bilibili和腾讯视频数据集中的表现。在bilibili数据集中,准确率为90.55%,F1值为90.59%,p值为90.33%,R值为90.85%。在腾讯视频数据集中,准确率为90.81%,F1值为88.82%,p值为90.82%,R值为86.90%。
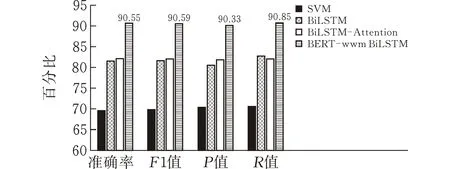
(a)bilibili数据集
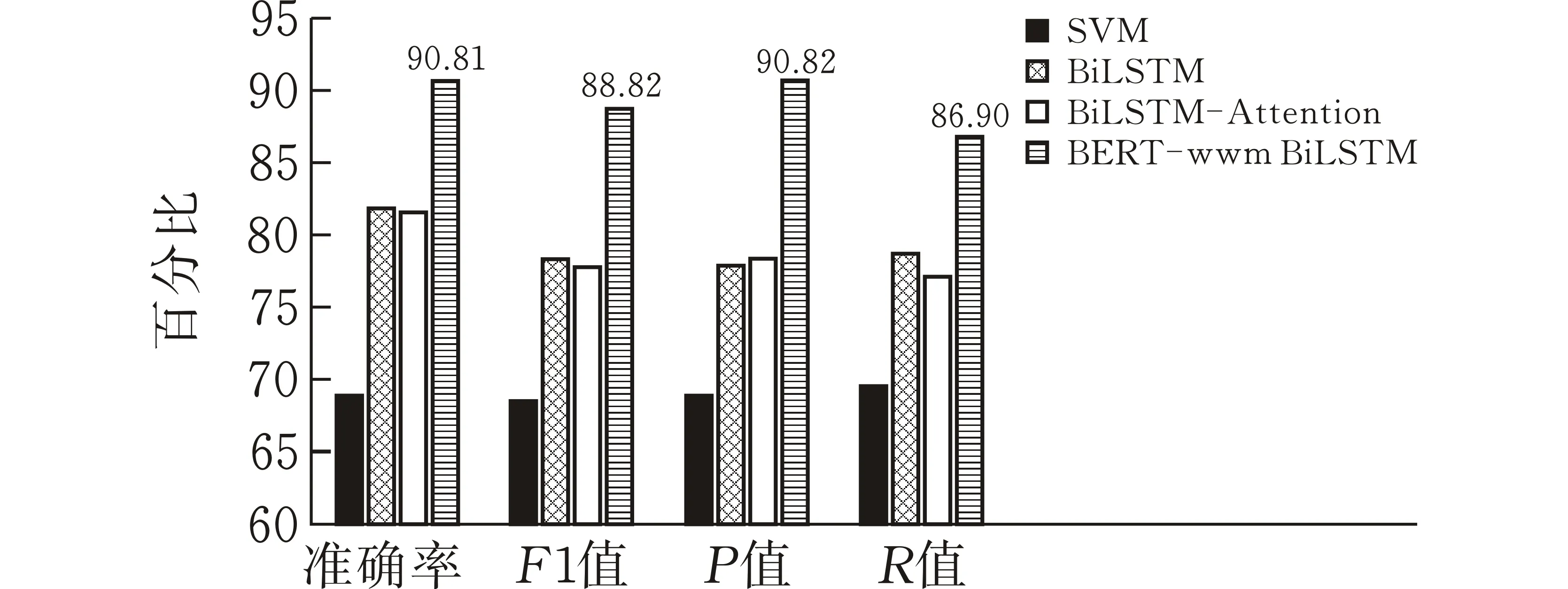
(b)腾讯视频数据集图 5 各模型评价指标对比
3.3 实验三:对比方案测试
选取机器学习算法SVM,双向长短时记忆网络BiLSTM,以及双向长短时记忆网络加注意力机制BiLSTM-Attention作为对比模型。由图3实验结果可知,本文模型BERT-wwm-BiLSTM在bilibili和腾讯视频数据集上的各个指标均显著优于对比模型。表3展示了不同模型的评价指标。相较于BiLSTM模型,本文模型准确率在bilibili和腾讯视频两个数据集上分别高出9.01%和8.88%,同时本文模型比BiLSTM-Attention模型准确率高出8.42%和9.07%。

表3 不同模型在两个数据集上的精确率、召回率和F1值 %
除此之外,本文模型BERT-wwm BiLSTM比对比模型在精确率、召回率和F1值3个指标上也有较大的提升。不同模型在bilibili数据集和腾讯视频数据集上的p、R、F1值结果如表3所示。由表格不难发现,本文模型BERT-wwm BiLSTM相较于其他对比模型,p、R和F1值均为所有模型中的最高值。F1值是p值和R值的调和平均数,可以综合考虑到精确率和召回率。相较于其他三个模型,本文模型BERT-wwm BiLSTM在F1值方面在两个数据集上分别高出19.80%、7.92%、7.54%以及20.08%、10.41%、10.95%,再一次证明了本文模型在弹幕文本情感分类任务中确实有效。
3.4 实验四:一词多义语句测试
预训练模型BERT-wwm得到动态词向量对一词多义的弹幕文本情感倾向的判断更加准确。表4展示了爬取的弹幕文本数据中部分一词多义的文本,以及本文模型和对比模型的分类结果。由表4可见,SVM对10句语料的判断无规律可循,对“异想天开”判断为消极情感,但对明显含有积极情绪的词“聪明、无微不至”也都判断为消极情感。BiLSTM、BiLSTM Attention对“现在很多人办事都想靠关系走捷径”以及“专门钻法律漏洞,可真聪明”都做出了错误的判断。“捷径”一词情感倾向性不明显,在不同的语境中表现出不同的情感,“聪明”含有明显的褒义,对比模型因此做出积极情感的判断,这与语境不符。由此可见,基于Word2Vec提取词向量的深度学习模型在一词多义语句上的表现差强人意。因此,本文模型对一词多义弹幕情感判断明显优于其他对比模型,对于语句“up主有点骄傲啊”判断失误,一方面由于该语句较短,上下文信息较少,另一方面也说明了模型还有改进的空间。
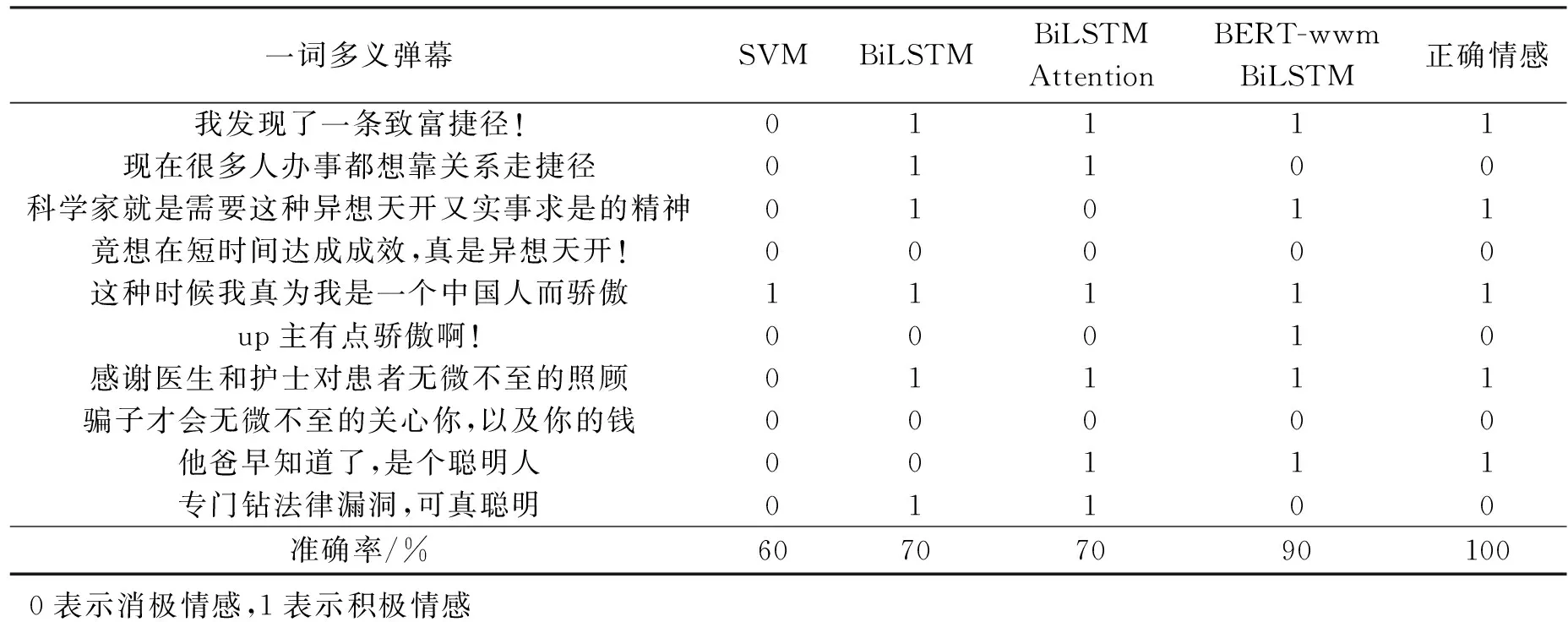
表4 部分一词多义弹幕文本情感分类结果对比
4 结束语
本文提出的BERT-wwmBiLSTM模型。引入BERT-wwm中文预训练模型得到有关上下文信息的动态词向量,用于解决弹幕文本口语化、网络化及一词多义的问题。之后将动态词向量传入BiLSTM网络中进行特征提取,双向的长短时记忆网络能更好地提取简短的弹幕文本特征。最后结合softmax分类层得到最终情感分类结果。数据集方面,通过爬虫技术在bilibili视频网站和腾讯视频网站得到弹幕数据集,并利用pytorch编程框架实现了提出的模型。试验评估方面,进行了模型的学习能力测试、模型的指标测试、对比试验测试以及文本实例预测测试。实验结果表明,本文提出的模型在文本预测中展现出优异的性能,可为弹幕文本分析提供较大帮助。
本文模型只适用于弹幕文本二分类情况,不能处理复杂的情感多分类。今后将改进模型,使其能够适应更复杂的情感分类任务。
猜你喜欢
中学生天地(B版)(2023年2期)2023-04-01 01:20:14
新高考·高一数学(2022年3期)2022-04-28 07:02:46
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
汉语世界(2021年2期)2021-04-13 02:36:18
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
小学科学(学生版)(2020年10期)2020-10-28 07:52:18
小哥白尼(野生动物)(2019年3期)2019-07-01 08:27:40
中国交通信息化(2018年5期)2018-08-21 03:37:40
