基于结构相似性粗定位与背景差分细分割的运动目标检测方法
2022-01-14 07:18蒙晓宇
科学技术与工程 2021年36期
蒙晓宇,朱 磊,张 博,潘 杨
(西安工程大学电子信息学院,西安 710048)
运动目标检测为目标跟踪和识别奠定基础,是计算机视觉中的核心问题,也是视觉领域最基本的问题[1]。运动目标检测算法分为静态背景下的运动目标检测和动态背景下的运动目标检测,取决于监视场景与摄像机之间的相对运动。
目前,静态背景下的运动目标检测方法包括帧间差分法[2-3]、背景差分法[4-5]以及光流法[6-7];动态背景下的运动目标检测主要是背景运动补偿差分技术[8-9]。一般情况下视频监控通常采用静止的摄像头,因此可以直接利用背景差分法将输入图像与不含运动目标的背景图像求差分即可得到前景目标或背景。为准确地提取目标,Barnich等[10]提出了视觉背景提取算法(visual background extractor,ViBe),采用随机更新背景模型,该方法在复杂背景下不能有效抑制运动目标的残影,需要用较长的视频序列消除鬼影区域。Peng等[11]提出了人混合高斯模型(Gaussian mixture model,GMM),该方法利用较长时间内大量样本值的概率密度统计信息,该方法计算量较大,无法在短时间内提取准确的前景目标。在混合模型的基础上,李笑等[12]在此基础上引入四帧间差分,借助计数器调整高斯模型,提高高斯分量的自适应性,改进后的模型使得模型的时间复杂度降低,而且适用于多场景。郝晓丽等[13]提出了自适应学习率高斯混合背景建模,采用自适应的学习率更新背景模型,保证在动态背景下实时检测目标,由于天气、光照的影响,导致检测的前景目标完整度不是很高,对于抖动相机下的视频准确率略低于静止相机下的运动目标。同时抖动相机下的视频序列提取运动目标存在一定的困难,主要是恢复图像的原始位置。屠礼芬等[14]提出了背景自适应方案,通过角点检测提取感兴趣区域的特征点,通过特征点估计相机的抖动偏移量,最终使用背景差分法检测运动目标,由于背景差分对灰度信息不是很敏感,当背景模型中的灰度值和前景目标中的灰度值相近时,导致检测过程中出现空洞,目标检测不完整等情况。廖娟等[15]提出了相机抖动场景下运动信息的前景检测算法,构建非参数的背景运动信息分布模型,该方法需要大量的图像进行模型的更新,导致视频中前面的图像无法检测的问题。根据相机抖动、阴影反射各种实际问题,Kushwaha等[16]提出了一种在复杂小波域中使用动态背景建模和阴影抑制对目标进行分割的方法,该方法相比于其他方法在性能方面有很大的提升。近年来,运用深度学习方法已成为研究的热点,张汇等[17]提出了基于快速区域卷积神经网络(faster region convolutional neural network,Faster RCNN)的行人检测方法,利用卷积神经网络(convolutional neural network,CNN)网络提取图像的特征,通过聚类和构建区域建议网络提取可能含有行人的区域,在利用检测网络对其分类和判别,最后将行人目标框定出来。Faster RCNN是目前主流的目标检测方法,但速度上并不能满足实时要求,而YOLO(you only look once)算法[18]使用回归思想,直接在输入图像的多个位置上回归出该位置的目标边框及目标类别,因此在速度上优于Faster RCNN算法。徐国标等[19]针对远场景、小目标难以检测的问题对YOLO算法进行了改进,核心思想是以Darknet-53为基础网络,多尺度预测边界框,以运动目标图像坐标的偏移量作为边框长宽的线性变换来实现边框的回归,在检测准确性和准确率两方面得到提高,但计算量大,模型设计复杂,对硬件的要求较高。
深度学习方法准确率高,但计算量大,训练耗时,模型正确性验证复杂且麻烦对硬件要求较高,某些深度网络不仅训练而且线上部署也需要显卡GPU(graphics processing unit)支持;传统方法研究最多的是背景差分法,背景差分的思想是点对点间进行差分,而在相机抖动过程中,图像中的背景及前景目标相对于真实的图像所差别,该方法对于相机的频繁抖动性能大打折扣,导致大量的背景被误检为前景目标,出现多检错检的问题,在相机抖动的情况下即时对当前帧图像进行校正从而避免错检的情况,因此解决相机抖动问题是至关重要。
针对上述问题,提出一种既适用于静止相机又适用于频繁抖动相机下运动目标检测方法。针对上述问题做以下改进:①对背景帧(只包含背景的图像)和当前帧(包含前景目标及背景的图像)特征点匹配过程以每个特征点为中心设置搜索窗口计算相关值,减少了算法的运行时间;②对感兴趣区域进行特征点检测,对当前帧和背景帧中的特征点进行匹配,用匹配点对的偏移量来估计整幅图像的偏移量,并对当前帧图像进行校正;③在运动目标细分割过程中分别对彩色图像的各通道进行背景差分,避免了灰度信息对运动目标像素点的漏检。
1 基于特征匹配的运动目标检测
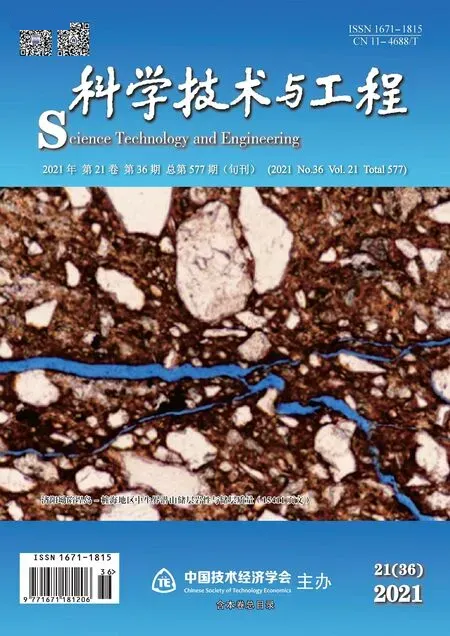
所提方法主要步骤为:一是基于尺度不变特征变换(scale-invariantfeature transform,SIFT)特征匹配的图像校正,该步骤使用SIFT[20]检测背景帧图像和当前帧图像的特征点,并对其特征点进行匹配得到特征点对,根据特征点对的偏移量估计相机的抖动参数;二是基于结构相似性估计的运动目标粗定位,通过结构相似性判断两幅图像的相似性确定运动目标区域;三是基于背景差分的彩色图像细分割,在粗定位基础上使用背景差分最终得到完整的运动目标。所提方法流程图如图1所示。
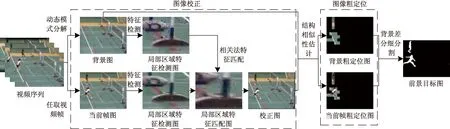
图1 基于特征检测的运动目标检测方法流程图Fig.1 The flow chart of moving target detection method based on fusion feature detection
基于结构相似性粗定位与背景差分细分割的运动目标检测方法首先利用文献[21]的动态模式分解方法对输入的视频序列提取彩色背景图像,对当前帧图像和背景图像使用SIFT特征检测提取两幅图像的特征点,并在小范围内采用相关法对两幅图像的特征点进行匹配,根据匹配点对在水平和垂直方向的偏移量估计相机抖动情况下当前帧图像相对背景图像的偏移量,达到校正图像消除相机抖动的目的,为后续步骤提供基础;其次,将校正后的当前帧图像和背景图像分成大小相同且互不重叠的图像块,对两幅图像相同位置的图像块利用结构相似性判断其相似度,其中图像块越相似说明该区域为背景,图像块越不相似说明该区域为目标区域,从而实现运动目标的粗定位。由于粗定位图像中既包含运动目标也包含少量的背景图像,后续步骤只需剔除掉小部分背景即可得到完整准确的前景运动目标,因此对粗定位得到的彩色当前帧图像及背景图像的各个通道利用背景差分法,最后根据形态学处理得到运动目标检测结果即前景目标图。
1.1 基于SIFT特征匹配的图像校正
由于视频监控中既包含静止的摄像头也包含抖动的摄像头,抖动摄像头采集的视频图像直接使用背景差分法检测运动目标时,将大量的背景误检为前景导致检测不准确,因此在检测前需要对图像进行校正。SIFT是一种检测局部特征的算法,对图像的视角变化、光照变化以及亮度信息具有很强的适应性[22]。因此采用SIFT算子提取图像特征检测图像特征点,该算法主要步骤包括关键点的检测和特征点的匹配。关键点的检测是将背景和当前帧图像利用高斯函数差分(difference of Gaussian,DOG),也就是在不同参数下的高斯滤波相减的结果与图像卷积,假设图像为I,当前帧图为IF,背景图为IB,由DOG空间的局部极值点组成整幅图像的特征点,特征检测公式为
D(x,y,σ)=[L(x,y,kσ)-L(x,y,σ)]
(1)
L(x,y,σ)=G(x,y,σ)I(x,y)
(2)
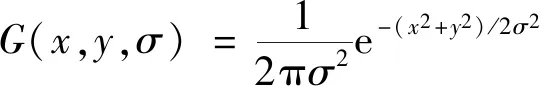
(3)
式中:D(x,y,σ)高斯函数差分;G(x,y,σ)为尺度可变高斯核函数;I(x,y)为原图像中各像素点;L(x,y,σ)为高斯核与图像的卷积;(x,y)为图像的像素点;k为相邻两个高斯尺度空间的比例因子;σ为图像的平滑程度。
通过相关法对检测的特征点进行匹配,相机的抖动一般不会大幅度的偏移,所以在小范围内采用图像窗口替代穷举法计算相关性,以当前帧图IB中任意一特征点为中心,选择N×N(N为窗口大小)大小的相关窗口,在背景帧图IF同样的位置选取2N×2N大小的搜索窗口,计算当前帧中位于该区域的特征点与背景图中特征点的相关性,相关窗口和搜索窗口越大匹配精度会更高,但由于相机的抖动局部特征没有发生变化,只是位置发生了偏移,而且位置的偏移量也不会超过图像大小的1/10,根据实验得出相关窗口取值不需要过大,选取N=7,这样不仅降低了计算量,在14×14的搜索窗口中,匹配的特征点对也相对较多,最终可以更加准确地得到图像的偏移量,相关搜索图如图2所示。
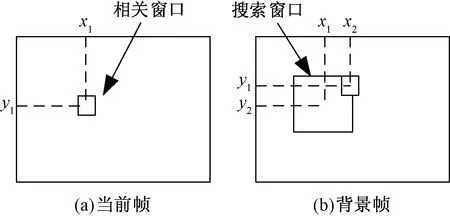
图2 相关搜索图Fig.2 Correlation search graph
首先计算特征点之间的相关性,相关值的定义为


(4)
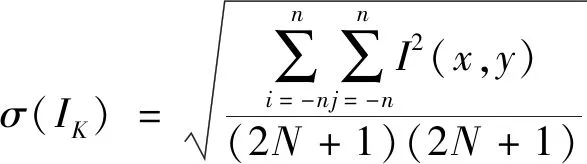
(5)
式(5)中:σ(IK)为标准差,K=B,F。
通过计算搜索窗内的所有特征点的相关值,选取相关值最大的特征点作为匹配点。通过对整幅图像的计算得到整幅图像的匹配点对,将当前帧和背景图得到的匹配点对表示在背景图像中,因为展示整个背景图无法看清每个特征点的偏移程度,所以展示部分匹配结果,如图3所示。
根据匹配点对的偏移量得到当前帧图相对于背景图在水平和垂直方向的偏移量,每对匹配点的水平和垂直方向的偏移量计算公式分别为
Δxi=xFi-xBi
(6)
Δyi=yFi-yBi
(7)
式中:xFi和xBi分别为背景图和当前帧图第i对特征匹配点对的横坐标;yFi和yBi分别为背景图和当前帧图第i对特征匹配点对的纵坐标。

*为当前帧中的特征点;+为背景图中的特征点图3 部分背景图与当前帧图的特征点匹配图Fig.3 Part of the background image and the feature point matching image of the current frame image
理想情况下所有匹配点对在水平和垂直方向的偏移量大小相等的,由于实际情况中噪声和复杂自然环境的影响,每对匹配点对在水平和垂直方向的偏移量有微小的变化。因此统计整幅图像水平方向Δxi和垂直方向Δyi偏移量的个数,将出现次数最多的Δxi和Δyi作为相机抖动的参数,假设背景中特征点的坐标为(u,v)(u和v分别为图像的特征点横、纵坐标),则当前帧匹配到的特征点通过校正后的坐标为(u+Δxi,v+Δyi),根据相机抖动参数补全当前帧图像,超出的图像的范围用背景图像补全,图4是对当前帧图像的校正,图4(a)为当前帧图像,当Δxi=3,Δyi=8时,校正后的图像如图4(b)所示为了显示更好的视觉效果,将补全的背景部分用黑色表示。如果是静止的摄像头在图像校正时其水平和垂直方向的偏移量为0,则该图片不需要进行背景补全。

图4 当前帧图像校正前后对比Fig.4 Comparison of the current frame image before and after correction
1.2 基于结构相似性的运动目标粗定位
在运动目标检测中常出现由于背景而导致误检和多检的情况,为缩小运动目标检测范围,减小背景图像对检测结果的不利影响,对校正后的当前帧图像利用结构相似性大致提取运动目标区域,由于实验中的每个视频序列都是同一相机在不同时间下拍摄,因此两幅图像背景大部分相同,仅在运动目标区域有所差别。结构相似性(structural similarity index,SSIM)[23]是一种测量两幅图像间的相似性程度指标,因此采用结构相似性对图像进行粗定位。一幅是背景图像,另一幅是校正后的当前帧图,通过计算两幅图像的相似性来检测目标的大致位置。
首先将背景图和校正后的当前帧图分成大小相同且互不重叠的结构块,结构块的大小直接影响后续检测的效果,相对来说结构块越大,检测的结果越准确,选取40*40大小的结构块,然后对两幅图像中相应大小的结构块使用结构相似性测量公式,计算两个结构块X、Y的相似性值,结构相似性公式为
SSIM(X,Y)=[l(X,Y)]ω[c(X,Y)]β×
[s(X,Y)]γ
(8)

(9)
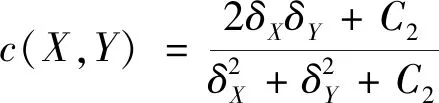
(10)
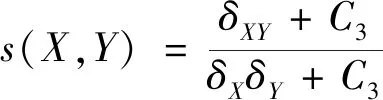
(11)
式中:l(X,Y)、c(X,Y)和s(X,Y)分别为图像块的亮度、对比度和结构相似度测量值;ω、β和γ分别为亮度分量、对比度分量和结构分量所占权重;μX和μY分别为图像块X和Y的像素均值;δX和δY分别为图像块X和Y的标准差;δXY为图像块X、Y的协方差;C1、C2和C3为常数。
通过计算背景图像和前景图像对应块得到每个40*40图像块的相似性值,结构相似性的取值范围在0~1,当两个图像块越相似,相似性值越接近于1,通过实验得到结构相似值为0.75时,对运动目标的粗定位效果最好,当结构相似值大于0.75时判定该结构块为背景区域,反之则为运动目标区域。经过结构相似性计算得到运动目标的大致位置,如图5所示,其中,图5(a)为校正后的当前帧图,图5(b)为通过文献[21]得到的背景图;图5(c)为经过结构相似性算法得到目标的粗定位二值图,图5(d)为粗定位的二值图像与当前帧的彩色图像点乘得到的粗定位彩色图。

图5 基于结构相似性运动目标粗定位结果图Fig.5 Result graph of rough localization of moving target based on structural similarity
1.3 基于背景差分的彩色图像细分割
根据基于结构相似性的运动目标粗定位得到运动目标区域,因为粗定位是对图像块进行处理,要么整个图像块保留,要么整个图像块剔除,导致得到的结果图不仅包含大量的前景运动目标而且包含小部分背景,接下来需要剔除掉多余的背景,选用最简单有效的背景差分法,背景差分法对两幅图像像素的对应位置点对点计算,点对点进行计算过程中仅涉及当前像素点,不会影响其他像素点,有效地提取前景运动目标,又因为单纯的灰度图像信息过于单一,当背景图像和运动目标图像中的灰度值相近时,背景差分法容易产生空洞现象,而粗定位可以得到当前帧和背景图像的彩色信息,由于彩色图像的信息远丰富于灰度图像的信息,因此采用彩色图像三通道分别进行背景差分,通过式(12)得到背景差分图像,由式(13)对差分图像阈值化处理,当差分值大于阈值时说明对应的两像素点之间存在明显差异,该像素点为运动目标像素点;当差分值小于阈值时,说明对应像素点之间的变化不明显,因此判定该像素点为背景像素点。
d=|IF(x,y)-IB(x,y)|
(12)
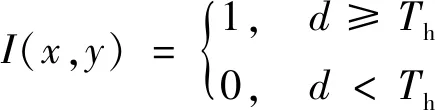
(13)
式中:IF(x,y)和IB(x,y)分别为彩色图像下当前帧和背景帧每个像素点;Th为前景与背景的分割阈值,阈值的选取至关重要,直接影响实验的结果,固定的阈值对于每幅固然是不合适的,因此采用最大类间方差法自适应计算阈值,该方法的错分率小并且对于每幅图像根据图像本身选择合适阈值;I(x,y)为通过背景差分后得到的前景目标图像。
通常情况下,采用图像的灰度信息进行背景差分,若当前帧图像和背景图像中的灰度信息相差不明显时,通过阈值处理后将会把前景目标当成是背景,这种检测的效果达不到最终效果,因此使用彩色图像进行背景差分,这样既包含灰度信息又包含亮度信息,最后通过与操作和形态学处理得到完整的运动目标图像,基于背景差分的彩色图像细分割如图6所示。

图6 基于背景差分的彩色图像细分割图Fig.6 Color image segmentation based on background difference
2 实验结果与分析
为验证本文方法能完整的提取运动目标,实验选用channet_2012数据集中的部分视频进行测试,其中包含抖动的相机场景下和静止的相机场景下视频共5种,相机抖动场景视频有羽毛球(badminton)和林荫大道(boulevard);相机静止场景视频有后门(backdoor)、行人(pedestrians)和交通(traffic),从视觉效果和参数指标两方面进行对比,选用具有代表性的背景建模算法GMM,ViBe和自适应的背景建模(即GMM+)[24]与本文方法进行比较,测试结果如图7所示,每一行表示不同算法对同一视频图像的实验结果。
从图7实验结果看出,各算法都可以检测到运动目标,ViBe算法和GMM算法都呈现出不同程度的前景丢失,GMM+算法对于前景目标的检测效果相对完整,但出现多检情况,由于背景差分过程中灰度信息的变化。在badminton视频、pedestrians视频和traffic视频中ViBe算法出现多检的情况,不能有效的抑制背景初始化时产生的前景目标,但对于较长的视频序列,能够将残影消除,如backdoor视频和boulevard视频;GMM算法相对于ViBe算法检测效果较好,检测到的运动目标较完整,但出现了大量的干扰像素和噪点,对背景像素的抑制不都完整,尤其是backdoor视频和traffic视频表现出大量的背景;GMM+算法采用自适应的学习率更新背景模型,相对于GMM算法和ViBe算法检测效果较好,不仅消除了干扰像素点而且目标边缘信息完整,GMM+算法对于车辆的检测效果比较好,但对于人物细节部分存在漏检,一方面人物的细节部分较多,另一方面人物面积相对于车辆面积较小,导致检测不准确。而本文方法不论目标是人物还是车辆检测效果都较好,目标轮廓清晰完整,无重影和噪点。

图7 各算法对视频图像的检测结果Fig.7 Detection results of various algorithms on video images
为了进一步验证各方法的检测效果,采用查全率(recall)、查准率(precision)、准确率(F-measure)3个标准指标作为运动目标检测的评价指标,准确率为查全率和查准率的加权调和平均。查全率、查准率和准确率指标值越大则表示检测效果越好,算法越可靠。查全率Re、查准率Pr和准确率Fm的计算公式分别为
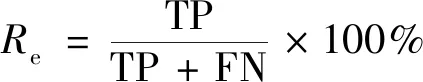
(14)
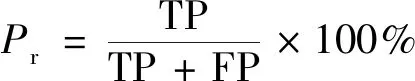
(15)

(16)
式中:TP为正确检测前景点的个数;FN为错误检测背景点的个数,即漏检测的前景点;FP为错误检测前景点的个数。
根据以上3个评价指标对本文方法进行验证,不同算法下各项参数指标对比结果如表1所示。

表1 各算法的前景检测指标参数对比Table 1 Comparison of foreground detection index parameters of each algorithm
表1给出5种场景下4种算法的前景检测结果指标对比,本文方法的各项参数指标均高于ViBe算法、GMM算法及改进的GMM算法,在5种场景下的准确率达到90%以上,因此本文方法既适用于静止相机下的目标检测又适用于抖动相机下的运动目标检测。
3 结论
提出了基于特征检测的运动目标检测方法可以应用于静止相机下和抖动相机下的运动目标检测,首先通过视频序列得到背景图像,使用SIFT算子检测背景图和当前帧图的特征点,通过特征匹配得到两幅图像间的匹配特征点对,根据特征点对的偏移量估计恢复整幅图像在水平和垂直方向的偏移程度;为了减少噪声和背景的干扰,对图像进行分块处理,根据结构相似性测量值得到粗定位的彩色运动目标图;为了得到精确完整的运动目标图像充分利用了彩色图像信息,对粗定位的彩色运动目标图进行背景差分。实验结果表明,所提出的方法相比于其他经典的算法,不论是车辆还是人物细节信息都比较完整,消除噪声的同时抑制的背景的干扰,检测准确率也得到提高。
猜你喜欢
数学杂志(2022年5期)2022-12-02
湘潭大学自然科学学报(2022年2期)2022-07-28
汽车工程师(2021年12期)2022-01-17
新世纪智能(数学备考)(2021年5期)2021-07-28
当代陕西(2020年14期)2021-01-08
河北画报(2020年8期)2020-10-27
奥秘(创新大赛)(2020年7期)2020-07-27
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
太空探索(2014年1期)2014-07-10